







oracle 等待事件
一、简述
Oracle等待事件是在Oracle 7.0.12中引入的,当时等待事件大致有100多个;在Oracle 8.0中Oracle等待事件数目增加到150多个,在Oracle 8i中有大约220个等待事件;而在Oracle 9i中大约有400多个等待事件;在Oracle 10g中有约916个等待事件,在oracle 11g中有约1367个等待事件。
Oracle的等待事件数目在不断的增加,但都是可以通过v$event_name视图可以查询的到,还可以在v$system_wait_class中查看各类等待事件的等待时间和等待次数,通过v$system_wait视图查看Oracle自启动以来产生的等待事件,用来分析数据库的运行状态。
v$evnet_name视图里parameter1、parameter2、parameter3三个参数尤为重要,在不同等待事件中意义不同。
在Oracle中的等待事件大概分为两类:空闲(Idle)等待事件和非空闲(non-Idle)等待事件。
空闲等待事件是Oracle在空闲状态在等待某一个操作,这部分不用特别关注,下面重点讨论非空闲等待事件。
--10g
SQL> SELECT version
FROM product_component_version
WHERE substr(product, 1, 6) = 'Oracle'; 2 3
VERSION
--------------------------------------------------------------------------------
10.2.0.5.0
SQL> select count(*) from v$event_name;
COUNT(*)
----------
916
SQL> select count(*) from v$event_name where wait_class='Idle';
COUNT(*)
----------
63
--11g
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
PL/SQL Release 11.2.0.4.0 - Production
CORE 11.2.0.4.0 Production
TNS for Linux: Version 11.2.0.4.0 - Production
NLSRTL Version 11.2.0.4.0 - Production
SQL> select count(*) from v$event_name;
COUNT(*)
----------
1367
SQL> select count(*) from v$event_name where wait_class='Idle';
COUNT(*)
----------
96
Oracle等待事件有以下几种等待类型的等待事件,根据不同类型的等待事件进行讨论
SQL> select distinct wait_class from v$event_name;
WAIT_CLASS
--------------------
Administrative 管理类
此类等待事件是由于DBA的管理命令引起的,这些命令要求用户处于等待状态,比如,重建索引。【Waits resulting from DBA commands that cause users to wait (for example, an index rebuild)】
Application 应用程序类
此类等待事件是由于用户应用程序的代码引起的(比如:锁等待)【Waits resulting from user application code (for example, lock waits caused by row level locking or explicit lock commands)】
Cluster 集群类
此类等待事件和真正应用群集RAC的资源有关。(比如:gc cr block busy等待事件)【Waits related to Real Application Cluster resources (for example, global cache resources such as 'gc cr block busy'】
Commit 提交确认类
此类等待事件只包含一种等待事件--在执行了一个commit命令后,等待一个重做日志写确认(也就是log file sync)【This wait class only comprises one wait event - wait for redo log write confirmation after a commit (that is, 'log file sync')】
Concurrency 并发类
此类等待事件是由内部数据库资源引起的,比如闩锁。【Waits for internal database resources (for example, latches)】
Configuration 配置类
此类等待事件是由数据库或实例的不当配置造成的,比如,重做日志文件尺寸太小,共享池的大小等。【Waits caused by inadequate configuration of database or instance resources (for example, undersized log file sizes, shared pool size)】
Idle 空闲类
此类等待事件意味着会话不活跃,等待工作。比如,sql * net messages from client。【Waits that signify the session is inactive, waiting for work (for example, 'SQL*Net message from client')】
Network 网络类
和网络环境相关的一些等待事件,比如sql* net more data to dblink。【Waits related to network messaging (for example, 'SQL*Net more data to dblink')】
Other 其他类
此类等待事件通常比较少见。【Waits which should not typically occur on a system (for example, 'wait for EMON to spawn')】
Scheduler 调度类
Resource Manager related waits (for example, 'resmgr: become active')
System I/O 系统I/O类
此类等待事件通过是由后台进程的I/O操作引起的,比如DBWR等待,db file paralle write。【Waits for background process IO (for example, DBWR wait for 'db file parallel write')】
User I/O 用户I/O类
此类等待事件通常是由用户I/O操作引起的,比如db file sequential read。【Waits for user IO (for example 'db file sequential read')】
12 rows selected.
二、Concurrency相关等待
此类等待事件是DBA需要关注的,主要是由Oracle数据库内部产生的等待事件,出现此类等待事件说明当前数据库存在比较严重的性能问题,需要进行人工干预处理进行优化以实现数据库的快速运行。此类等待事件不会出现数据库非常严重的夯住,主要体现是某些SQL引起缓存游标争用问题或者是没有正确使用游标,主要在于查找SQL并优化相关表和SQL即可解决。
SQL> select name,PARAMETER1,PARAMETER2,PARAMETER3,WAIT_CLASS from v$event_name where wait_class='Concurrency';
NAME PARAMETER1 PARAMETER2 PARAMETER3 WAIT_CLASS
------------------------------------------------------- --------------- ------------------------- -------------------- --------------------
logout restrictor Concurrency
os thread startup Concurrency
Shared IO Pool Memory Concurrency
latch: cache buffers chains address number tries Concurrency
buffer busy waits file# block# class# Concurrency
db flash cache invalidate wait Concurrency
enq: TX - index contention name|mode usn<<16 | slot sequence Concurrency
latch: Undo Hint Latch address number tries Concurrency
latch: In memory undo latch address number tries Concurrency
latch: MQL Tracking Latch address number tries Concurrency
securefile chain update seghdr fsb Concurrency
enq: HV - contention name|mode object # 0 Concurrency
SecureFile mutex Concurrency
enq: WG - lock fso name|mode kdlw lobid first half kdlw lobid sec half Concurrency
latch: row cache objects address number tries Concurrency
row cache lock cache id mode request Concurrency
row cache read cache id Concurrency
libcache interrupt action by LCK location Concurrency
cursor: mutex X idn value where Concurrency
cursor: mutex S idn value where Concurrency
cursor: pin X idn value where Concurrency
cursor: pin S idn value where Concurrency
cursor: pin S wait on X idn value where Concurrency
latch: shared pool address number tries Concurrency
library cache pin handle address pin address 100*mode+namespace Concurrency
library cache lock handle address lock address 100*mode+namespace Concurrency
library cache load lock object address lock address 100*mask+namespace Concurrency
library cache: mutex X idn value where Concurrency
library cache: mutex S idn value where Concurrency
resmgr:internal state change location Concurrency
resmgr:sessions to exit location Concurrency
pipe put handle address record length timeout Concurrency
Streams apply: waiting for dependency Concurrency
1、 Library cache lock
这个等待事件发生在不同用户在共享中由于并发操作同一个数据库对象导致的资源争用的时候,比如当一个用户正在对一个表做DDL 操作时,其他的用户如果要访问这张表,就会发生library cache lock等待事件,它要一直等到DDL操作完成后,才能继续操作。
这个事件包含四个参数:
Handle address: 被加载的对象的地址。
Lock address: 锁的地址。
Mode: 被加载对象的数据片段。
Namespace: 被加载对象在v$db_object_cache 视图中namespace名称。
10gr2 rac:
sys@ORCL> select name from v$event_name where name like 'library%' order by 1;
2、 Library cache pin
这个等待事件和library cache lock 一样是发生在共享池中并发操作引起的事件,一个SQL需要将指定的shared pool中的对象pin住才能访问该对象,如果pin不住就会发生此等待。通常来讲,如果Oracle 要对一些PL/SQL 或者视图这样的对象做重新编译,需要将这些对象pin到共享池中。如果此时这个对象被其他的用户持有,就会产生一个library cache pin的等待。
这个等待事件也包含四个参数:
Handle address: 被加载的对象的地址。
Lock address: 锁的地址。
Mode: 被加载对象的数据片段。
Namespace: 被加载对象在v$db_object_cache 视图中namespace名称。
查询持有latch的对象
select Distinct /*+ ordered */ w1.sid waiting_session,
h1.sid holding_session,
w.kgllktype lock_or_pin,
od.to_owner object_owner,
od.to_name object_name,
oc.Type,
decode(h.kgllkmod, 0, 'None', 1, 'Null', 2, 'Share', 3, 'Exclusive',
'Unknown') mode_held,
decode(w.kgllkreq, 0, 'None', 1, 'Null', 2, 'Share', 3, 'Exclusive',
'Unknown') mode_requested,
xw.KGLNAOBJ wait_sql,xh.KGLNAOBJ hold_sql
from dba_kgllock w, dba_kgllock h, v$session w1,
v$session h1,v$object_dependency od,V$DB_OBJECT_CACHE oc,x$kgllk xw,x$kgllk xh
where
(((h.kgllkmod != 0) and (h.kgllkmod != 1)
and ((h.kgllkreq = 0) or (h.kgllkreq = 1)))
and
(((w.kgllkmod = 0) or (w.kgllkmod= 1))
and ((w.kgllkreq != 0) and (w.kgllkreq != 1))))
and w.kgllktype = h.kgllktype
and w.kgllkhdl = h.kgllkhdl
and w.kgllkuse = w1.saddr
and h.kgllkuse = h1.saddr
And od.to_address = w.kgllkhdl
And od.to_name=oc.Name
And od.to_owner=oc.owner
And w1.sid=xw.KGLLKSNM
And h1.sid=xh.KGLLKSNM
And (w1.SQL_ADDRESS=xw.KGLHDPAR And w1.SQL_HASH_VALUE=xw.KGLNAHSH)
And (h1.SQL_ADDRESS=xh.KGLHDPAR And h1.SQL_HASH_VALUE=xh.KGLNAHSH) ;
3、latch:cache buffers lru chain
在Oracle buffer中有两个主要的链表,一个用来记录buffer中的free buffer的链表,一个用来记录buffer cache中数据位置的链表(类似于buffer cache的索引表,记录buffer对象的逻辑位置),当用户读取数据到buffer cache中,或buffer cache根据LRU算法进行管理时,在当前buffer cache中没有找到目标对象,就需要从物理磁盘读取,就不可避免的要扫描LRU列表以获取free buffer或更改buffer状态。buffer cache为众多并发进程提供并发访问,所以在搜索的过程中,必须获取latch锁定内存结构,以防止并发访问对内存中的数据造成损坏。这个用于锁定LRU的latch就是cache buffers lru chain,造成这个等待的主要原因是当前buffer cache大小不能满足当前读取数据量的大小,不可避免要从磁盘中读取数据,同时还会伴随db file sequential read ,db file scattered read的等待。
cache buffers lru chain锁存器的默认数量:
DB_WRITER_PROCESSES <= 4 锁存器数= 4 * cpu数
DB_WRITER_PROCESSES > 4 锁存器数= db_writer_processes * cpu数
可以通过初始化参数_db_block_lru_latches来向上调整cache buffers lru chain锁存器的数量(不建议这么做,除非在oracle support的建议下)
解决方式:
(1) 适当增大buffer cache,这样可以减少读数据到buffer cache,减少扫描lru列表的次数
(2) 适当增加lru latch数量,修改_db_block_lru_latches参数.不建议这么做.
(3) 使用多缓冲池技术
4、latch:cache buffers chains
该等待事件同latch:cache buffers lru chain相似,延续③中提到的两个链表,用来记录数据位置的链表造成的等待就是latch:chache buffers chains,理想状态下,是要访问的数据对象在该链表中的都能找到,也就不会有此等待即buffer hit100%,在这个链表中查找过程中是需要持有latch保护内存结构不被破坏,如果查找特别慢(buffer hit低或者逻辑读大)都会引起该等待时间,如果找不到就需要在该链表中加latch,保护内存结构不被破坏,从③中提到的另一个链表中申请free buffer
产生原因
①低效率的SQL语句,多个并发低效的SQL语句同时执行,都设法获得相同的数据集,就造成cache buffers chains的争用,调整高buffer_gets的SQL语句可以缓解这类问题.(较小的逻辑读意味着较少的latch get操作,从而减少锁存器争用并改善性能。)
②有热点块(最常见原因)
检查是否存在热点块,p1raw.
select sid,event,p1raw,p2,p3,seconds_in_wait,wait_time,state
from v$session_wait
where event = 'latch free';
1> 查看cache buffers chains子latch情况:
select * from
(select addr,child#,gets,misses,sleeps,immediate_gets igets,immediate_misses imisses,spin_gets
from v$latch_children
where name = 'cache buffers chains'
order by sleeps desc) where rownum<11;
2> 检查相关块的信息
select b.addr,a.tch,a.ts#,a.dbarfil,a.dbablk,b.gets,b.misses,b.sleeps
from
(select *from
(select addr,ts#,file#,dbarfil,dbablk,tch,hladdr from x$bh order by tch desc)
where rownum<11) a,
(select addr,gets,misses,sleeps from v$latch_children where name = 'cache buffers chains' ) b
where a.hladdr = b.addr;
3>检查存在争用的具体对象
select distinct owner,segment_name,segment_type
from dba_extents a,
(select * from (select addr,tch,ts#,file#,dbarfil,dbablk from x$bh order by tch desc)
where rownum<11 ) b
where a.relative_fno = b.dbarfil
and a.block_id <= b.dbablk
and a.block_id + blocks > b.dbablk;
4> 检查相关的SQL语句
select /*+ rule */ hash_value,sql_text
from v$sqltext
where (hash_value,address) in
(select a.hash_value,a.address
from v$sqltext a,
(select distinct a.owner,a.segment_name,a.segment_type
from dba_extents a,
(select dbarfil,dbablk
from (select dbarfil,dbablk
from x$bh
order by tch desc
)
where rownum<11
) b
where a.relative_fno = b.dbarfil
and a.block_id <= b.dbablk
and a.block_id + a.blocks > b.dbablk
) b
where a.sql_text like '%'||b.segment_name||'%'
and b.segment_type = 'TABLE'
)
order by hash_value,address,piece;5、latch: shared pool
当一条连接发出请求时,就需要在shared pool中获取shared pool latch来锁住内存块,语句解析同时还会产生library cache latch。
产生原因:
①出现大量的 Share Pool Latch 和 Library Cache Latch,说明数据库库中存在大量的硬解析,这个时候就要查找那些 SQL 没有绑定变量。
②出现大量的 Library Cache Latch :
1) 当持有 Library Cache Latch 查找 Bucket 对应的 Chain 时候,发现存在高 Version 的 SQL,这个时候就要扫描这些对应的子游标,整个过程将一直持有 Latch,导致其他会话获取不到 Latch 进行操作。即parent cursor下挂载了多个child cursor,遍历执行计划解析句柄时间较长。
2) 大量的并发请求,而且不能实现 SQL 一次 Parse Call 多次 Execution。
6、latch: row cache objects
用来保护数据字典缓冲区(row cache的名字主要是因为其中的信息是按行存储的,而不是按块存储)。进程在装载、引用或者清除数据字典缓冲区中的对象时必须获得该latch。在oracle8i之前,这是一个独立latch。从oracle9i起,由于引入了多个子共享池的新特性,存在多个row cache objects子latch。Oracle10g中,该latch也有了一个独立的等待事件:row cache objects。
解决方法:
①确认SGA 中的share pool空间情况
select POOL,BYTES/1024/1024 FREE_MB from v$sgastat a where a.NAME like 'free%';
②判断library cache 命中率,miss_ratio大于0.2代表shared pool设置过小
select sum(gets) as gets,sum(getmisses) as misses,sum(getmisses)/sum(gets) as miss_ratio from v$rowcache;
在真个SQL语句执行过程中,生成执行计划的时候需要访问的数据字典次数更多,会产生更多的latch争用。
7.row cache lock
oracle客户端发出一条SQL需要现在library cache中进行SQL parse ,每一次parse都会对访问对象加lock,如果shared pool过小,部分对象被移除内存就会造成此等待,或者频繁的SQL parse也会造成此等待
产生原因:
①共享池过小,需要增加共享池。
②SQL parse过于频繁,对于共享池的并发访问量过大。
解决方式:
①查看shared pool使用情况
select * from v$sgastat where pool='shared pool' and name like 'free memory';
②查看library cache争用的dc对象
select * from v$rowcache where cache# = &p1;
8.buffer busy waits
Oracle当一个用户SQL更改目标对象时,会在buffer cache中对目标对象加latch,如果另一个会话需要持有这个目标对象,就需要等待当前会话持有完毕才能获得目标对象块的当前状态,此时产生的等待就是buffer busy waits,此等待时间在10g中较为常见,在11g做了拆分,分成了buffer busy waits、read by other session、gc buffer busy acquire、和gc buffer busy release 。
产生的主要原因是热点块的出现,当前SQL效率低下造成的
9.library cache: mutex S
Oracle中shared pool的结构是最复杂的,在library cache中所有的内存结构都是由一个一个bucket组成的,每个Bucket中存放了数库缓存对象句柄,对象句柄中存放着具体的对象信息,可能是package,function也可能是parent cursor,不同对象句柄之间通过指针形成库缓存对象句柄链表(Library Cache Object Handles(LBO)),相同哈希值的bucket存放在一个 Hash Bucket中,多个Hash Bucket共同构成了library cache,11g以前是由一个lach管理所有hash bucket的,虽然latch持有时间都是微妙级别的但还是产生了很多latch等待,11g之后每个hash bucket由单独的一个mutex管理,当Oracle需要访问library cache hash bucket时 mutex就产生了library cache: mutex S,虽然是共享访问,但还是会阻塞其他访问
10.library cache: mutex X
原理同library cache: mutex S,用户SQL需要持有目标library cache bucket 当前状态。
11.cursor: mutex X
延续library cache原理,在每个library cache object handle(LBO)中存在parent cursor,当用户SQL执行需要进行软解析时就需要持有当前cursor,如果以一个排他方式持有产生的等待就是cursor: mutex X
12.cursor: mutex S
以一个共享模式持有产生的等待就是cursor: mutex S
13.cursor: pin X
延续library cache理论,在LBO下parent cursor中存在一定的child cursor(执行计划解析句柄的实际存放位置,以一个full_hash_value方式存放<64位>,后32位是sql_id),当Oracle以排他模式访问child cursor的时候就会pin住cursor,产生cursor: pin X 等待事件
14.cursor: pin S
Oracle以共享模式访问child cursor的时候就会pin住cursor,产生cursor: pin S 等待事件
15.cursor: pin S wait on X
当child cursor产生争用的时候就是此等待。
三、Configuration相关等待
此类等待事件主要是Oracle数据库配置不当引起的相当严重的性能问题,当然出现此类等待事件也不一定是配置问题,也可能和服务器、磁盘IO等有关,Oracle的性能问题需要从一个全方面的角度去去排查。在实际生产中也遇到过许多类似的等待事件,它不全是由于Oracle配置不当才会出现此类等待事件,在磁盘IO满足不了当前系统等环境下也会产生此列等待事件。
SQL> select name,PARAMETER1,PARAMETER2,PARAMETER3,WAIT_CLASS from v$event_name where wait_class='Configuration';
NAME PARAMETER1 PARAMETER2 PARAMETER3 WAIT_CLASS
------------------------------------------------------- --------------- ------------------------- -------------------- --------------------
free buffer waits file# block# set-id# Configuration
checkpoint completed Configuration
write complete waits file# block# Configuration
write complete waits: flash cache file# block# Configuration
latch: redo writing address number tries Configuration
latch: redo copy address number tries Configuration
log buffer space Configuration
log file switch (checkpoint incomplete) Configuration
log file switch (private strand flush incomplete) Configuration
log file switch (archiving needed) Configuration
log file switch completion Configuration
flashback buf free by RVWR Configuration
enq: ST - contention name|mode 0 0 Configuration
undo segment extension segment# Configuration
undo segment tx slot segment# Configuration
enq: TX - allocate ITL entry name|mode usn<<16 | slot sequence Configuration
statement suspended, wait error to be cleared Configuration
enq: HW - contention name|mode table space # block Configuration
enq: SS - contention name|mode tablespace # dba Configuration
sort segment request Configuration
enq: SQ - contention name|mode object # 0 Configuration
Global transaction acquire instance locks retries Configuration
Streams apply: waiting to commit Configuration
wait for EMON to process ntfns Configuration
16、Log file switch
当前日志发生切换时,LGWR需要关闭当前日志组,打开下一个日志组,这个切换过程中,数据库的所有DML操作都处于停顿直至切换成功。出现此类的等待事件都是致命的,需要人工干预。
关于LOG FILE SWITCH等待事件有两个子等待事件:
①Log file switch(checkpoint incomplete)
当所有日志都写满后会尝试覆盖一个日志,如果这个日志没有完全写出,就会出现该等待。
在v$log 视图里记录了在线日志的状态。通常来说,在线日志有三种状态。
Active: 这个日志上面保护的信息还没有完成checkpoint。
Inactive: 这个日志上面保护的信息已完成checkpoint。
Current: 当前的日志。
产生原因:
日志组设置不合理,日志组数量少。
解决方式:
合理设置redo组数量。
②Log file switch(archiving needed)
在归档模式下,这个等待事件发生在在线日志切换(log file switch)时,需要切换的在线日志还没有被归档进程(ARCH)归档完毕的时候。 当在线日志文件切换到下一个日志时,需要确保下一个日志文件已经被归档进程归档完毕,否则不允许覆盖那个在线日志信息(否则会导致归档日志信息不完整)。
产生原因:
①归档目录磁盘IO问题,归档日志写出缓慢。
②日志组设置不合理,日志组小或者单个日志大小过小。
③arch进程数量少,以至于写出较慢,10g默认是2个,11g默认是4个。
解决方式:
①移动归档到IO磁盘比较好的磁盘存储。
②合理设置日志组和单个日志大小。
③调整log_archive_max_processes参数。
17、Log file sync
这是一个用户会话行为导致的等待事件,当一个会话发出一个commit命令时,LGWR进程会将这个事务产生的redo log从log buffer里面写到磁盘上,以确保用户提交的信息被安全地记录到数据库中。对于回滚操作,该事件记录rollback到回滚完成的操作
会话发出的commit指令后,需要等待LGWR将这个事务产生的redo 成功写入到磁盘之后,才可以继续进行后续的操作,这个等待事件就叫作log file sync。如果系统产生的redo很多每次写的较少,一般是频繁的触发lgwr,可能导致过多的redo相关latch的竞争。
产生原因:
①当前数据库在进行大量的commit操作。
②lgwr写出效率低下(日志组IO,切换是否正常)
解决方式:
①使用批量提交。
②redo组使用快盘
③使用nologging/unrecoverable选项(慎用)
若有log file sequential read等待事件同时出现可能是io导致的性能问题。
18、 Log buffer space
用户进程产生归档数据需要申请redo allocation latch在log buffer中申请一定的空间,当log buffer 中没有可用空间来存放新产生的redo log数据时,就会发生log buffer space等待事件。
产生原因:
①产生的redo log的数量大于LGWR 写入到磁盘中的redo log 数量。
②日志切换太慢(log switch)。
解决方法:
①增加redo buffer的大小。
②提升磁盘的I/O性能
19、latch:redo copy
10g之前一个进程产生的redo信息现在pga中保存,然后在进程需要将redo信息copy到log buffer时会产生redo copy latch,获得了该latch,才能把redo copy到log buffer中。10g之后用户redo信息不再存放在pga中,而是在shared pool中开辟一块区域Private Redolog Strands(多个),用于存放用户产生的redo,消除了redo copy等待,Oracle认为内存中的"copy"是非常高效的。
_log_simultaneous_copies 定义了允许同时写redo的redo copy的数量
redo allocation latch
在获取redo copy latch之后紧接着要申请获取redo allocation latch来申请redo log buffer中redo空间,分配完以后 redo allocation latch释放,Oracle才能把pga中的redo信息写出到log buffer中分配的redo空间中,copy完成之后redo copy latch 释放,在完成redo copy之后,process通知lgwr执行写出到online redo(这个过程会获取一个redo writing latch去检查lgwr是否被激活或着已经被post,若lgwr已经被激活或者被post就会使用redo writing latch),这个过程latch竞争过多会引起Log File Sync的等待事件。
20、 Free buffer waits
当一个会话将数据块从磁盘读到内存中时,它需要到内存中找到空闲的内存空间来存放这些数据块,当内存中没有空闲的空间时,就会产生这个等待;除此之外,还有一种情况就是会话在做一致性读时,需要构造数据块在某个时刻的前映像(image),此时需要申请内存来存放这些新构造的数据块,如果内存中无法找到这样的内存块,也会发生这个等待事件。
当数据库中出现比较严重的free buffer waits等待事件时,可能的原因是:
(1)data buffer 太小,导致空闲空间不够
(2)内存中的脏数据太多,DBWR无法及时将这些脏数据写到磁盘中以释放空间
这个等待事件包含2个参数:
File#: 需要读取的数据块所在的数据文件的文件号。
Block#: 需要读取的数据块块号。
四、User I/O相关等待
此类等待事件是由于用户I/O引起的,一般会造成比较严重的性能问题,需要DBA去关注。
SQL> select name,PARAMETER1,PARAMETER2,PARAMETER3,WAIT_CLASS from v$event_name where wait_class='User I/O';
NAME PARAMETER1 PARAMETER2 PARAMETER3 WAIT_CLASS
------------------------------------------------------- --------------- ------------------------- -------------------- --------------------
Parameter File I/O blkno #blks read/write User I/O
Disk file operations I/O FileOperation fileno filetype User I/O
Disk file I/O Calibration count User I/O
Disk file Mirror Read fileno blkno filetype User I/O
Disk file Mirror/Media Repair Write fileno blkno filetype User I/O
direct path sync File number Flags User I/O
Datapump dump file I/O count intr timeout User I/O
dbms_file_transfer I/O count intr timeout User I/O
DG Broker configuration file I/O count intr timeout User I/O
Data file init write count intr timeout User I/O
Log file init write count intr timeout User I/O
Shared IO Pool IO Completion User I/O
local write wait file# block# User I/O
buffer read retry file# block# User I/O
read by other session file# block# class# User I/O
db flash cache single block physical read User I/O
db flash cache multiblock physical read User I/O
db flash cache write User I/O
db file sequential read file# block# blocks User I/O
db file scattered read file# block# blocks User I/O
db file single write file# block# blocks User I/O
db file parallel read files blocks requests User I/O
direct path read file number first dba block cnt User I/O
direct path read temp file number first dba block cnt User I/O
direct path write file number first dba block cnt User I/O
direct path write temp file number first dba block cnt User I/O
flashback log file sync User I/O
cell smart table scan cellhash# User I/O
cell smart index scan cellhash# User I/O
cell statistics gather cellhash# User I/O
cell smart file creation cellhash# User I/O
Archive Manager file transfer I/O count intr timeout User I/O
securefile direct-read completion User I/O
securefile direct-write completion User I/O
BFILE read User I/O
utl_file I/O User I/O
external table read filectx file# size User I/O
external table write filectx file# size User I/O
external table open filectx file# User I/O
external table seek filectx file# pos User I/O
external table misc IO filectx iocode P3 User I/O
dbverify reads count intr timeout User I/O
TEXT: File System I/O User I/O
ASM Fixed Package I/O blkno bytes filetype User I/O
ASM Staleness File I/O blkno #blks diskno User I/O
cell single block physical read cellhash# diskhash# bytes User I/O
cell multiblock physical read cellhash# diskhash# bytes User I/O
cell list of blocks physical read cellhash# diskhash# blocks User I/O
21、db file sequential read
db file sequential read这个等待事件是非常常见的User I/O相关的等待事件,通常显示与单个数据块相关的读取操作,在大多数情况下,读取一个索引块或者通过索引读取一个数据块时,都会记录这个等待。在Oracle 10g以后将此类等待事件归为User I/O,其中这里的sequential也并非指的是Oracle 按顺序的方式来访问数据,和db file scattered read一样,它指的是读取的数据块在内存中是以连续的方式存放的。在实际生产中此类等待事件过多可能是没有正确使用索引或者驱动表引起的,事实上使用索引访问表的时候也会产生一定的db file sequential read等待事件,此类等待事件不必过多的关注。
读取方式如下图所示:
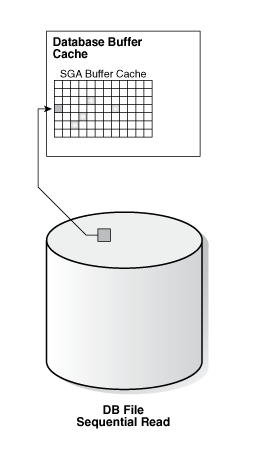
在V$SESSION_WAIT这个视图里面,这个等待事件有三个参数P1、P2、P3,其中P1代表Oracle要读取的文件的绝对文件号即File#,P2代表Oracle从这个文件中开始读取的起始数据块的BLOCK号即Block#,P3代表Oracle从这个文件开始读取的BLOCK号后读取的BLOCK数量即Blocks,通常这个值为1,表明是单个BLOCK被读取,如果这个值大于1,则是读取了多个BLOCK,这种多BLOCK读取常常出现在早期的Oracle版本中从临时段中读取数据的时候。
这个等待事件有三个参数:
File#: 要读取的数据块所在数据文件的文件号。
Block#: 要读取的起始数据块号。
Blocks:要读取的数据块数目(这里应该等于1)。
产生原因
db file sequential read等待使性能出现问题,这些性能问题大多数发生在低效的索引扫描、行迁移、行链接引发附加的I/O过程中,产生的原因有很多。
解决方式
①低效的sql语句或低效的索引扫描经常被使用时,因不必要的物理I/O增加,可能增加db file sequential read等待。此类问题可结合语句重建索引或者收集统计信息和直方图来提高SQL的执行效率,之前讨论过统计信息相关内容,此处不再赘述。
②buffer cache过小,反复发生物理I/O,因此可能增加db file sequential read等待,此类问题同时还会发生free buffer waits等待的概率较高。如果大量发生free buffer waits等待,应该考虑检查buffer cache的命中率,适当扩展buffer cache的大小。还可考虑利用多重缓冲池,有效使用高速缓存区。利用多重缓冲池减少db file sequential read等待的原理,与减少db file scattered read等待的原理相同。
③物理IO慢引起的db file sequential read等待事件,如果平均等待时间长,缓慢的I/O系统成为原因的可能性高。
可以利用v$filestat视图,可分别获得各数据文件关于Multi Block I/O和Single Block I/O的活动信息。
SELECT F.FILE#,
F.NAME,
S.PHYRDS,
S.PHYBLKRD,
S.READTIM, --所有的读取工作信息
S.SINGLEBLKRDS,
S.SINGLEBLKRDTIM, --SINGLE BLOCK I/O
(S.PHYBLKRD - S.SINGLEBLKRDS) AS MULTIBLKRD, --MULTI BLOCK I/O次数
(S.READTIM - S.SINGLEBLKRDTIM) AS MULTIBLKRDTIM, --MULTI BLOCK I/O时间
ROUND(S.SINGLEBLKRDTIM /
DECODE(S.SINGLEBLKRDS, 0, 1, S.SINGLEBLKRDS),
3) AS SINGLEBLK_AVGTIM, --SINGLE BLOCK I/O 平均等待时间(CS)
ROUND((S.READTIM - S.SINGLEBLKRDTIM) /
NULLIF((S.PHYBLKRD - S.SINGLEBLKRDS), 0),
3) AS MULTIBLK_AVGTIM --MULTI BLOCK I/O 平均等待时间(CS)
FROM VFILESTATS,VFILESTATS,VDATAFILE F
WHERE S.FILE# = F.FILE#;
22、db file scattered read
在实际生产数据库中此类等待事件也是非常常见的,在V$SESSION_WAIT这个视图里面,这个等待事件有三个参数P1、P2、P3,其中P1代表Oracle要读取的文件的绝对文件号,P2代表Oracle从这个文件中开始读取的起始BLOCK号,P3代表Oracle从这个文件开始读取的BLOCK号后读取的BLOCK数量。
从V$EVENT_NAME视图可以看到,该等待事件有3个参数:
File#: 要读取的数据块所在数据文件的文件号。
Block#: 要读取的起始数据块号。
Blocks:需要读取的数据块数目。
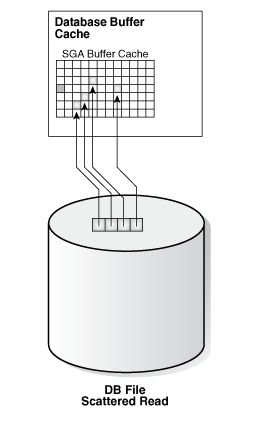
起始数据块号加上数据块的数量,意味着Oracle增在等待多块连续的读操作完成,当用户发出每次I/O需要读取多个数据块这样的SQL 操作时或者说当Oracle从磁盘上读取多个BLOCK到不连续的高速缓存区的缓存中,会产生这个等待事件,这类等待可能会与Full Table Scan 或者Index Fast Full Scan 相关,通常大量的db file scattered read等待出现可能是索引缺失导致的 。每次读取的数据块数可通过db_file_multiblock_read_count参数在限制。
可同于以下语句定位对象:
SELECT EVENT, P1, P2, P3, ROW_WAIT_OBJ#
FROM GV$SESSION
WHERE EVENT = 'db file scattered read';
SELECT OBJECT_NAME, OBJECT_TYPE
FROM DBA_OBJECTS
WHERE OBJECT_ID = ROW_WAIT_OBJ#;
db file scattered read事件与db file sequential read事件相同,是oracle中最经常发生的等待事件。因为从数据文件读取块时只能执行Multi Block I/O或Single Block I/O。
解决方式:
①查找主要发生db file scattered read等待的sql语句。如果不必要的执行Full Table Scan或Index Full San,修改sql语句或创建更合理的索引就可以解决。注意不要盲目创建索引。
②buffer cache过小,会反复需要物理I/O,相应的db file scattered read等待也会增加。这时free buffer waits等待事件一同出现的几率较高。检查buffer cache的命中率,适当扩展buffer cache的大小。
③检查表结构,适当修改热点表为分区表。
④物理IO慢引起的db file scattered read事件 ,如果平均等待时间长,缓慢的I/O系统成为原因的可能性高。
可以利用v$filestat视图,可分别获得各数据文件关于Multi Block I/O和Single Block I/O的活动信息。
SELECT F.FILE#,
F.NAME,
S.PHYRDS,
S.PHYBLKRD,
S.READTIM, --所有的读取工作信息
S.SINGLEBLKRDS,
S.SINGLEBLKRDTIM, --SINGLE BLOCK I/O
(S.PHYBLKRD - S.SINGLEBLKRDS) AS MULTIBLKRD, --MULTI BLOCK I/O次数
(S.READTIM - S.SINGLEBLKRDTIM) AS MULTIBLKRDTIM, --MULTI BLOCK I/O时间
ROUND(S.SINGLEBLKRDTIM /
DECODE(S.SINGLEBLKRDS, 0, 1, S.SINGLEBLKRDS),
3) AS SINGLEBLK_AVGTIM, --SINGLE BLOCK I/O 平均等待时间(CS)
ROUND((S.READTIM - S.SINGLEBLKRDTIM) /
NULLIF((S.PHYBLKRD - S.SINGLEBLKRDS), 0),
3) AS MULTIBLK_AVGTIM --MULTI BLOCK I/O 平均等待时间(CS)
FROM V$FILE_STAT S,V$DATAFILE F
WHERE S.FILE# = F.FILE#;
23、db file parallel read/wirte
这是一个后台等待事件,它同样和用户的并行操作没有关系,它是由后台进程DBWR产生的,当后台进程DBWR向磁盘上写入脏数据时,会发生这个等待。
DBWR会批量地将脏数据并行地写入到磁盘上相应的数据文件中,在这个批次作业完成之前,DBWR将出现这个等待事件。如果仅仅是这一个等待事件,对用户的操作并没有太大的影响,当伴随着出现free buffer waits等待事件时,说明此时内存中可用的空间不足,这时候会影响到用户的操作,比如影响到用户将脏数据块读入到内存中。
当出现db file parallel write等待事件时,可以通过启用操作系统的异步I/O的方式来缓解这个等待。当使用异步I/O时,DBWR不再需要一直等到所有数据块全部写入到磁盘上,它只需要等到这个数据写入到一个百分比之后,就可以继续进行后续的操作。
这个等待事件有两个参数:
Requests: 操作需要执行的I/O次数。
Timeouts: 等待的超时时间。
在11g中新增了prefetch的特性,会对目标数据进行预读取,也可能导致这个等待事件的产生。
关闭prefetch特性
set pagesize 9999
set line 9999
col NAME format a40
col KSPPDESC format a50
col KSPPSTVL format a20
SELECT a.INDX,
a.KSPPINM NAME,
a.KSPPDESC,
b.KSPPSTVL
FROM x$ksppi a,
x$ksppcv b
WHERE a.INDX = b.INDX
and lower(a.KSPPINM) IN ('_db_block_prefetch_quota','_db_block_prefetch_limit','_db_file_noncontig_mblock_read_count');
ALTER SYSTEM SET "_db_block_prefetch_quota"=0 SCOPE=SPFILE SID='*';
ALTER SYSTEM SET "_db_block_prefetch_limit"=0 SCOPE=SPFILE SID='*';
ALTER SYSTEM SET "_db_file_noncontig_mblock_read_count"=0 SCOPE=SPFILE SID='*';
24、 db file single write
这个等待事件通常只发生在一种情况下,就是Oracle 更新数据文件头信息时(比如发生Checkpoint)。
当这个等待事件很明显时,需要考虑是不是数据库中的数据文件数量太大,导致Oracle需要花较长的时间来做所有文件头的更新操作(checkpoint)。
这个等待事件有三个参数:
file#: 需要更新的数据块所在的数据文件的文件号。查询文件号的SQL语句是:SELECT * FROM v$datafile WHERE file# = ;
block#:需要更新的数据块号,如果BLOCK号不是1,可检查正在写入的对象
SELECT segment_name , segment_type ,
owner , tablespace_name
FROM sys.dba_extents
WHERE file_id =
AND
BETWEEN block_id AND block_id + blocks -1;
blocks:需要更新的数据块数目(通常来说应该等于1),或Oracle写入file#的数据文件中从BLOCK#开始写入的BLOCK的数量。头一般来说都是BLOCK1,操作系统指定的文件头是BLOCK0,如果BLOCK号大于1,则表明Oracle正在写入的是一个对象而不是文件头。
25、direct path read/write
direct path read是Oracle通过pga直接读取数据块的一种方式,由于直接通过pga读取数据块减少了数据块在sga中的latch争用,同样也给pga带来了一定的压力,可通过_small_table_threshold参数设定,在Oracle 11gr2之前版本中默认为读取表大小大于buffer cache大小的2%*5倍大小,即buffercache大小的10%才会使用direct path read方式读取数据块,但在11g以后不再有5倍的限制,即超过buffer cache2%就会使用此方法,由于在生产中可能会出现频繁的大表访问,此特性无异于给pga造成一定压力,严重时候会使pga耗尽业务无法登陆,一般情况下建议关闭此特性。
直接路径读/写 等待事件的3个参数分别是:file#(指绝对文件号)、first block#和block数量。
这个等待事件有三个参数:
file number: 等待I/O读取请求的文件的绝对文件号
first dba: 等待I/O读取请求的第一个BLOCK号
block cnt: 以first block为起点,总共有多少个连续的BLOCK被请求读取
由参数P1与P2推得访问的数据对象:
select s.segment_name, s.partition_name
from dba_extents s
where between s.block_id and (s.block_id + s.blocks -1) and s.file_id =&file_id
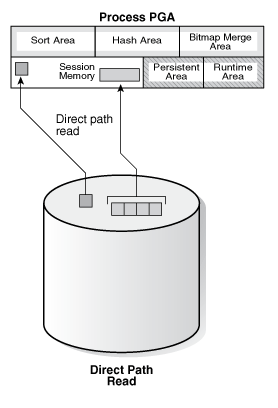
db file sequential read、db file scattered read、direct path read是常见的集中数据读方式,下图简要描述了这3种方式的读取示意。

产生原因:
直接路径读(direct path read)通常发生在Oracle直接读取数据到PGA时,这个读取不需要经过SGA。这类读取通常在以下情况被使用:
① 大量的磁盘排序I/O操作 在排序操作(ORDER BY、GROUP BY、UNION、DISTINCT、ROLLUP、合并连接)时,由于PGA中的SORT_AREA_SIZE空间不足,无法在PGA中完成排序,需要利用TEMP表空间进行排序。当从TEMP表空间中读取排序结果时,会产生direct path read等待。注意,从Oracle 10g开始表现为direct path read temp等待事件。在DSS/OLAP系统中,存在大量的direct path read是很正常的,但是在OLTP系统中,通常显著的直接路径读都意味着系统应用存在问题,从而导致大量的磁盘排序读取操作。
② 大量的Hash Join操作,利用Temp表空间保存Hash区,使用Hash连接的SQL语句,将不适合位于内存中的散列分区刷新到Temp表空间中。为了查明匹配SQL谓词的行,临时表空间中的散列分区被读回到内存中,此时会产生direct path read等待。
③ SQL语句的并行查询,并行查询从属进程 使用并行扫描的SQL语句也会影响系统范围的direct path read等待事件。在并行执行过程中,direct path read等待事件与从属查询有关,而与父查询无关,运行父查询的会话基本上会在PX Deq:Execute Reply上等待,从属查询会产生direct path read等待事件。
④ 预读操作
⑤ 串行全表扫描(Serial Table Scan),大表的全表扫描,在Oracle 11g中,全表扫描的算法有新的变化,根据表的大小、高速缓存的大小等信息,默认为读取结果集大小大于buffer cache大小的10%就会使用 direct path read特性,可通过隐含参数“_serial_direct_read”关闭,决定是否绕过SGA直接从磁盘读取数据,也被称为自适应直接读(Adaptive Direct Read)。Oracle 10g的全表扫描是通过db file scattered read读取到Buffer Cache中,在Oracle 11g中,认为大表全表扫描时使用直接路径读,可能比数据文件离散读(db file scattered read)速度更快,使用的latch也更少,即对于大表执行直接路径读效率更好,而对于小表通过将其缓存可能受益更大。Oracle通过隐含参数“_small_table_threshold”来界定大表小表的临界。
直接路径写(direct path wirte)等待事件和direct path read 正好相反,是会话将一些数据从PGA中直接写入到磁盘文件(数据文件或临时文件)上,而不经过SGA。
1. 直接路径加载(使用append方式加载数据、CREATE TABLE AS SELECT)
2. 并行DML操作
3. 磁盘排序使用临时表空间排序(内存不足)
最常见的直接路径写,多数因为磁盘排序导致。对于这一写入等待,应该找到I/O操作最为频繁的数据文件(如果有过多的排序操作,很有可能就是临时文件),分散负载,加快其写入操作。
如果系统存在过多的磁盘排序,会导致临时表空间操作频繁,对于这种情况,可以考虑为不同用户分配不同的临时表空间,使用多个临时文件,写入不同磁盘或者裸设备,从而降低竞争提高性能。
这类型的写请求主要是用于直接装载数据的操作(create table as select)、并行的DML操作、不在内存中排序的I/O以及写入没有cache的LOB段操作。
关于该等待事件,以下的几点需要注意:
1. 从PGA写入数据文件,一个会话可以发布多个写入请求和连续的处理。
2. 直接写入可以按同步或异步方式执行,取决于平台和DISK_ASYNC_IO参数的值。
3. 通常用于在数据加载(APPEND提示、CTAS-CREATE TABLE AS SELECT)、并行DML操作时写入到临时段。
4. 在使用异步IO时,direct path write事件产生的等待时间不准确,所以通过v$sesstat视图来获得直接写入次数来评估该事件的影响情况:
SELECT A.NAME,
B.SID,
B.VALUE,
ROUND((SYSDATE - C.LOGON_TIME) * 24) HOURS_CONNECTED
FROM V$STAT_NAME A,V$SESSTAT B, V$SESSION C
WHERE A.STATISTIC# = B.STATISTIC#
AND B.SID = C.SID
AND B.VALUE > 0
AND A.NAME = 'PHYSICAL WRITES DIRECT'
order by b.value;
--判断该事件正在读取什么段(如:散列段、排序段、一般性的数据文件)
SELECT a.event,
a.sid,
c.sql_hash_value hash_vale,
decode(d.ktssosegt,
1,
'SORT',
2,
'HASH',
3,
'DATA',
4,
'INDEX',
5,
'LOB_DATA',
6,
'LOB_INDEX',
NULL) AS segment_type,
b.tablespace_name,
b.file_name
FROM v$session_wait a,dba_datafiles b,v$session c, x$ktsso d
WHERE c.saddr = d.ktssoses(+)
AND c.serial# = d.ktssosno(+)
AND d.inst_id(+) = userenv('instance')
AND a.sid = c.sid
AND a.p1 = b.file_id
AND a.event = 'direct path read'
UNION ALL
SELECT a.event,
a.sid,
d.sql_hash_value hash_value,
decode(e.ktssosegt,
1,
'SORT',
2,
'HASH',
3,
'DATA',
4,
'INDEX',
5,
'LOB_DATA',
6,
'LOB_INDEX',
NULL) AS segment_type,
b.tablespace_name,
b.file_name
FROM v$session_wait a,
dba_temp_files b,
v$parameter c,
v$session d,
x$ktsso e
WHERE d.saddr = e.ktssoses(+)
AND d.serial# = e.ktssosno(+)
AND e.inst_id(+) = userenv('instance')
AND a.sid = d.sid
AND b.file_id = a.p1 - c.VALUE
AND c.NAME = 'db_files'
AND a.event = 'direct path read';
如果是从临时文件中读取排序段的会话,则表明SORT_AREA_SIZE或PGA_AGGREGATE_TARGET的设置是不是偏小。如果是从临时文件中读取HASH段的会话,则表明HASH_AREA_SIZE或PAG_AGGREGATE_TARGET的设置是不是偏小。
当direct path read等待事件是由于并行查询造成的(读取的是一般的数据文件而非临时文件),父SQL语句的HASHVALUE与子SQL语句的HASHVALUE不同,可以通过以下SQL查询产生子SQL语句的父SQL语句:
SELECT DECODE(A.QCSERIAL#, NULL, 'PARENT', 'CHILD') STMT_LEVEL,
A.SID,
A.SERIAL#,
B.USERNAME,
B.OSUSER,
B.SQL_HASH_VALUE,
B.SQL_ADDRESS,
A.DEGREE,
A.REQ_DEGREE
FROM V$PXSE_SSION A,V$SESSION B
WHERE A.SID = B.SID
ORDER BY A.QCSID, STMT_LEVEL DESC;解决方式:
①检查SQL语句。不必要的排序操作会导致CPU浪费、PGA区域浪费、磁盘I/O浪费。
②合理设置pga大小。在进程上分配的工作区大小内一次性实现的排序称为One pass sort。与此相反的情况称为Multi pass sort。发生Multi pass sort时,排序工作过程中将排序结果读写到排序段(sort segment)区域,因此发生direct path read temp、direct path write temp等待。如果该等待大量发生,就可以适当提高pga_aggregate_target值解决
oracle在调优指南上推荐如下设定pga_aggregate_target值。
OLTP:pga_aggregate_target=(total_mem * 80%) * 20%
OLAP:pga_aggregate_target=(total_mem * 80%) * 50%
26、read by other session
WAITEVENT: "read by other session" Reference Note (文档 ID 732891.1)
当多个进程访问同一个数据块,而此数据块不在内存中,这时会有一个进程将它从磁盘读到内存时,其它读取此数据块进程的状态就是 read by other session;因为Oracle内存不允许多个进程同时读到同一个数据块到内存,其它进程只能等待。
当我们查询一条数据时,Oracle第一次会将数据从磁盘读入 buffer cache。如果有两个或者多个session请求相同的信息,那么第一个session会将这个信息读入buffer cache,其他的session就会出现等待。
P1 = file# Absolute File# (AFN) This is the file number of the data file that contains the block that the waiting session wants.
P2 = block# This is the block number in the above file# that the waiting session wants access to. See Note:181306.1 to determine the tablespace, filename and object for this file#,block# pair.
P3 = class# Block class
通过P1,P2值获取对象
SELECT SEGMENT_NAME, SEGMENT_TYPE, OWNER, TABLESPACE_NAME
FROM DBA_EXTENTS
WHERE FILE_ID = FILE#
AND BLOCK#
BETWEEN BLOCK_ID AND BLOCK_ID + BLOCKS - 1;
还可以从session中获取对象
SELECT A.ROW_WAIT_OBJ#,
B.OBJECT_NAME,
A.SQL_ID,
A.SID,
A.BLOCKING_SESSION,
A.EVENT,
A.P1TEXT,
A.P1,
A.P2TEXT,
A.P2,
A.P3TEXT,
A.P3,
A.WAIT_CLASS
FROM V$SESSION A, DBA_OBJECTS B
WHERE A.ROW_WAIT_OBJ# = B.OBJECT_ID
AND A.EVENT='read by other session';
查出具体的SQL语句
SELECT HASH_VALUE, SQL_TEXT
FROM V$SQLTEXT
WHERE (HASH_VALUE, ADDRESS) IN
(SELECT A.HASH_VALUE, A.ADDRESS
FROM V$SQLTEXT A,
(SELECT DISTINCT A.OWNER, A.SEGMENT_NAME, A.SEGMENT_TYPE
FROM DBA_EXTENTS A,
(SELECT DBARFIL, DBABLK
FROM (SELECT DBARFIL, DBABLK
FROM X$BH
ORDER BY TCH DESC)
WHERE ROWNUM < 11) B
WHERE A.RELATIVE_FNO = B.DBARFIL
AND A.BLOCK_ID <= B.DBABLK
AND A.BLOCKS > B.DBABLK) B
WHERE A.SQL_TEXT LIKE '%' || B.SEGMENT_NAME || '%'
AND B.SEGMENT_TYPE = 'TABLE')
ORDER BY HASH_VALUE, ADDRESS, PIECE;27、 local write wait
出现这个等待表示会话在等待自己的写操作。在磁盘发生严重问题时会发生,这在正常的系统中极少发生,在TRUNCATE一个大表而这个表在缓存中的时候,会话必需进行一个local checkpoint,这个时候会话会等待local session wait. 可以采用分区表。 把truncate 操作改成drop partition 的操作。
造成此等待事件的原因:
1) 磁盘损坏
2) 若执行TRUNCATE操作很慢,则可能由于表及其表上的索引的初始化值过大。
五、System I/O相关等待事件
此类等待事件主要是Oracle系统I/O引起的等待事件,同样也会引起比较严重的性能问题,需要关注。
SQL> select name,PARAMETER1,PARAMETER2,PARAMETER3,WAIT_CLASS from v$event_name where wait_class='System I/O';
NAME PARAMETER1 PARAMETER2 PARAMETER3 WAIT_CLASS
------------------------------------------------------- --------------- ------------------------- -------------------- --------------------
Clonedb bitmap file write blkno size System I/O
Log archive I/O count intr timeout System I/O
RMAN backup & recovery I/O count intr timeout System I/O
Standby redo I/O count intr timeout System I/O
Network file transfer count intr timeout System I/O
io done msg ptr System I/O
RMAN Disk slave I/O wait count wait flags timeout System I/O
RMAN Tape slave I/O tape operation operation flags timeout System I/O
DBWR slave I/O wait count wait flags timeout System I/O
LGWR slave I/O wait count wait flags timeout System I/O
Archiver slave I/O wait count wait flags timeout System I/O
File Repopulation Write filename_hash blkno System I/O
control file sequential read file# block# blocks System I/O
control file single write file# block# blocks System I/O
control file parallel write files block# requests System I/O
recovery read System I/O
RFS sequential i/o System I/O
RFS random i/o System I/O
RFS write System I/O
log file sequential read log# block# blocks System I/O
log file single write log# block# blocks System I/O
log file parallel write files blocks requests System I/O
db file parallel write requests interrupt timeout System I/O
db file async I/O submit requests interrupt timeout System I/O
flashback log file write log# block# Bytes System I/O
flashback log file read log# block# Bytes System I/O
cell smart incremental backup cellhash# System I/O
cell smart restore from backup cellhash# System I/O
kfk: async disk IO count intr timeout System I/O
cell manager opening cell cellhash# System I/O
cell manager closing cell cellhash# System I/O
cell manager discovering disks cellhash# System I/O28、Log file sequential write/read
log file sequential write
从log buffer写出到redo日志文件中,这个写操作是常规的操作 ,如果存在多个redo group,就会出现log file sequential write等待。
log file sequential read
这个等待事件通常发生在对redo log信息进行读取时,比如在线redo 的归档操作,ARCH进程需要读取redo log的信息。
这个操作直到I/O操作完成之后才会完成,这个事件通常了LOG FILE SYNC时间比较来衡量log file的写入成本。
这个等待事件包含三个参数:
Log#: 发生等待时读取的redo log的sequence号。
Block#: 读取的数据块号。
Blocks: 读取的数据块个数。
29、Log file single write
这个等待事件仅发生在更新redo log文件的文件头时,当为日志组增加新的日志成员时或者redo log的sequence号改变时,LGWR 都会更新redo log文件头信息。这个等待很少出现,无需过多关注。
这个等待事件包含三个参数:
Log#: 写入的redo log组的编号。
Block#:写入的数据块号。
Blocks:写入的数据块个数。
六、Cluster类等待
此类等待事件是Oracle RAC环境下才会产生的等待事件,是多个节点在缓存融合下进行资源交互产生的等待事件。此类等待事件在Oracle RAC环境下很常见,在Oracle 10g以后引入了一个人RDM新特性(Oracle会在固定时间点进行主控节点转换),此特性会给Oracle RAC产生额外的远端获取数据块的成本,产生大量的GC等待事件,故在实际生产环境中DBA建议关闭该特性。即使关闭该特性将Oracle RAC相关心跳参数调至最优也不可避免会有GC等待,这主要是应用连接在不同节点产生的各个节点相同资源的争用(在Oracle 11g以后 DBA不建议应用使用scan IP连接数据库)
SQL> select name,PARAMETER1,PARAMETER2,PARAMETER3,WAIT_CLASS from v$event_name where wait_class='Cluster';
NAME PARAMETER1 PARAMETER2 PARAMETER3 WAIT_CLASS
------------------------------------------------------- --------------- ------------------------- -------------------- --------------------
retry contact SCN lock master Cluster
gc buffer busy acquire file# block# class# Cluster
gc buffer busy release file# block# class# Cluster
pi renounce write complete file# block# Cluster
gc current request file# block# id# Cluster
gc cr request file# block# class# Cluster
gc cr disk request file# block# class# Cluster
gc cr multi block request file# block# class# Cluster
gc current multi block request file# block# id# Cluster
gc block recovery request file# block# class# Cluster
gc cr block 2-way Cluster
gc cr block 3-way Cluster
gc cr block busy Cluster
gc cr block congested Cluster
gc cr failure Cluster
gc cr block lost Cluster
gc cr block unknown Cluster
gc current block 2-way Cluster
gc current block 3-way Cluster
gc current block busy Cluster
gc current block congested Cluster
gc current retry Cluster
gc current block lost Cluster
gc current split Cluster
gc current block unknown Cluster
gc cr grant 2-way Cluster
gc cr grant busy Cluster
gc cr grant congested Cluster
gc cr grant unknown Cluster
gc cr disk read Cluster
gc current grant 2-way Cluster
gc current grant busy Cluster
gc current grant congested Cluster
gc current grant unknown Cluster
gc freelist Cluster
gc remaster file# block# class# Cluster
gc quiesce Cluster
gc object scan Cluster
gc recovery Cluster
gc flushed buffer Cluster
gc current cancel le Cluster
gc cr cancel le Cluster
gc assume le Cluster
gc domain validation file# block# class# Cluster
gc recovery free Cluster
gc recovery quiesce file# block# class# Cluster
gc claim Cluster
gc cancel retry Cluster
ASM PST query : wait for [PM][grp][0] grant Cluster
lock remastering Cluster

30、gc current block 2-way
此等待是一个实例对当前实例中的一个数据块进行授权,将该数据块的主控权转移到当前实例中时进行块争用发生的等待,一搬是‘写/写’争用。如下图所示,当请求实例发出一条请求,例如insert,当前节点没有对目标对象数据块的权限,访问主控节点寻找持有该数据块的节点,主控节点对自己持有数据块锁降级,lms进程制作cr副本授权给请求实例,这个过程产生的等待就是gc current block 2-way。

31、gc current block 3-way
此等待同gc current block 2-way等待相似,在主控节点扔未找到目标数据块,就需要主控节点去寻找持有该数据块的节点,lms进程制作cr副本授权给请求实例,对于该数据块请求实例改变为主控实例,这个过程等待事件就是gc current block 3-way。此等待事件只有在Oracle rac节点数大于2节点的环境中才会出现,实际上由于rac共享磁盘IO性能问题,很少会能看到大于2节点的数据库,故此等待生产中遇到的不多。

32、gc cr block 2-way
当前节点访问一个数据块,例如select,当前节点没有持有该对象,访问主控节点,从主控节点访问该对象,由于主控节点持有该对象在执行update尚未提交,需要lms进程制作cr块的副本授权给当前节点,此过程产生的等待就是 gc cr block 2-way。
33、gc cr block 3-way
同上等待事件类似,不再详细讨论。
34、gc cr grant 2-way
当前节点访问一个数据块,当前节点没有持有该对象,访问主控节点,主控节点缓存中没有持有该数据块需要从数据块中读取,lms进程授权当前节点从磁盘中读取目标数据块,这个等待就是gc cr grant 2-way。
35、gc cr grant 3-way
同上等待事件类似,不再详细讨论。
36、gc buffer busy acquire
此等待是集群中热点块的等待事件,当远端用户SQL需要访问目标对象,而当前对象在当前节点中被会话持有,就会产生此等待。
37、gc buffer busy release
此等待是集群中热点块的等待事件,当远端用户SQL需要持有目标对象当前状态,而当前对象在当前节点中被会话持有,就会产生此等待。
七、Administrative类等待
此类等待事件主要是由DBA命令而产生的,一般不对数据库系统产生致命影响或者不是由数据库系统直接影响的,是由DBA的某些操作引起的。
八、Application类等待
此类等待事件是由应用程序产生的在等待某些资源,不对数据库产生致命影响
SQL> select name,PARAMETER1,PARAMETER2,PARAMETER3,WAIT_CLASS from v$event_name where wait_class='Application';
NAME PARAMETER1 PARAMETER2 PARAMETER3 WAIT_CLASS
------------------------------------------------------- --------------- ------------------------- -------------------- --------------------
enq: PW - flush prewarm buffers name|mode 0 0 Application
enq: RO - contention name|mode 2 0 Application
enq: RO - fast object reuse name|mode 2 0 Application
enq: KO - fast object checkpoint name|mode 2 0 Application
enq: TM - contention name|mode object # table/partition Application
enq: TX - row lock contention name|mode usn<<16 | slot sequence Application
Wait for Table Lock Application
enq: RC - Result Cache: Contention name|mode chunkNo blockNo Application
Streams capture: filter callback waiting for ruleset Application
Streams: apply reader waiting for DDL to apply sleep time Application
SQL*Net break/reset to client driver id break? Application
SQL*Net break/reset to dblink driver id break? Application
External Procedure initial connection Application
External Procedure call Application
enq: UL - contention name|mode id 0 Application
OLAP DML Sleep duration Application
WCR: replay lock order wait for scn's wait for scn's lo 4 bytes Application
九、commit相关等待
此类等待事件是Oracle在commit命令发出后Oracle产生的一些列等待,主要是在归档模式下的日志写出和日志切换等待(log file sync)
十、Network类等待事件
此类等待事件主要是Oracle通过网络去连接数据库产生的(dblink),在Oracle架构中dba不建议使用dblink来部署Oracle架构,此类方法十分低效,而且还可能会触发Oracle的bug(在使用低版本连接Oracle 11.2.0.4版本以上的Oracle数据库时会触发bug Doc ID 2361478.1)
十一、Scheduler相关等待事件
此类等待事件主要是Oracle相关调度引发的等待,不需要关注。
十二、other相关等待事件
此类等待事件比较多,在Oracle11g中有985个,但在实际生产中产生的很少,不需要特别关注。














 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









