







第7章 将文法与程序代码分离
将文法与文法处理程序混合在一起使得最终的程序不易维护,例如下面的代码。
grammar PropertyFile;
file : { « start file » } prop+ { « finish file » } ;
prop : ID '=' STRING '\n' { « process property » } ;
ID : [a-z]+ ;
STRING : '"' .*? '"' ;
grammar PropertyFile;
@members {
void startFile() { } // blank implementations
void finishFile() { }
void defineProperty(Token name, Token value) { }
}
file : {startFile();} prop+ {finishFile();} ;
prop : ID '=' STRING '\n' {defineProperty($ID, $STRING)} ;
ID : [a-z]+ ;
STRING : '"' .*? '"' ;
这种形式不易维护,因此将二者分离将会使程序更容易维护与扩展。在Antlr v4 中可以通过listener与visitor来完成分离的工作。
通过Parse-Tree Listeners来实现程序
为了将文法与分析程序分离,关键是通过分析器创建一颗分析树,随后遍历这颗树,并在遍历时触发相关的处理代码。这可以通过Antlr提供的树遍历机制来实现。在Antlr中可以通过内置的ParseTreeWalker来实现遍历,代码如下。
属性文件文法定义。
file : prop+ ;
prop : ID '=' STRING '\n' ;
文件内容可以是。
user="parrt"
machine="maniac"
根据文法,Antlr生成PropertyFileParser,并构建分析树,结果图1所示。
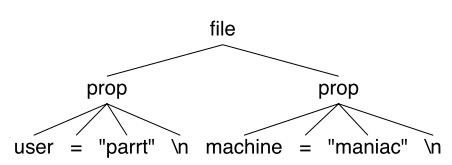
一旦得到这棵分析树,就可以通过ParseTreeWalker来访问所有结点,并在进入与退出结点时触发相应的处理方法。
接下来看一下PropertyFileParser中由Antlr根据文法文件所生成的接口。当Antlr ParseTreeWalker进入一个结点或退出一个结点时,会调用进入与退出方法。由于在属性文件文法描述中只有两个文法规则,因此最终Antlr会生成四个方法。
import org.antlr.v4.runtime.tree.*;
import org.antlr.v4.runtime.Token;
public interface PropertyFileListener extends ParseTreeListener {
void enterFile(PropertyFileParser.FileContext ctx);
void exitFile(PropertyFileParser.FileContext ctx);
void enterProp(PropertyFileParser.PropContext ctx);
void exitProp(PropertyFileParser.PropContext ctx);
}
FileContext与ProContext对象表示分析树结点,并与某个具体的规则相关联。同时这个两个对象还包含一些很有用的方法。为了方便使用,Antlr会生成PropertyFileBaseListener类,该类实现了接口中的方法,但方法体为空,具体的实现交给使用者完成。
public static class PropertyFileLoader extends PropertyFileBaseListener {
Map<String,String> props = new OrderedHashMap<String, String>();
public void exitProp(PropertyFileParser.PropContext ctx) {
String id = ctx.ID().getText(); // prop : ID '=' STRING '\n' ;
String value = ctx.STRING().getText();
props.put(id, value);
}
}
接下来看一下Antlr根据文法所生成的以及用户编写的类之间的关系。
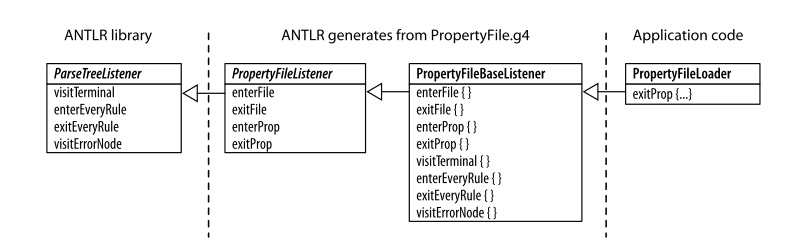
parsetReeListener在ANTLR运行时库中,其中每个listener会对下列方法做出响应。
- visitTerminal
- enterEveryRule
- exitEveryRule
- visitErrorNode
Antlr根据文法文件生成接口文件PropertyFileListener。该文件实现了PropertyFileListener接口,并提供了默认方法的实现。
而作为使用者仅需要创建PropertyFileLoader,该类继承PropertyFileBaseListener,并提供方法的具体实现。其中方法参数能够访问规则上下文对象PropContext。该对象与规则prop相关联。这个上下文对象对每个文法规则中的元素都有一个处理方法(对于prop来说是ID和STRING)。ID,STRING都是对终结符的引用。我们可以直接通过getText访问终结符中的文本数据,或通过getSymbol()方法。
接下来遍历分析树。并通过所实现的PropertyFileLoader来完成结点监听,触发处理方法。
// 创建分析树遍历器
ParseTreeWalker walker = new ParseTreeWalker();
// 创建监听器,并提供给遍历器
PropertyFileLoader loader = new PropertyFileLoader();
walker.walk(loader, tree); // walk parse tree
System.out.println(loader.props); // print results
基于Visitor的实现方法
为了生成基于访问者模式的代码,需要指定-visitor选项。Antlr会生成PropertyFileVisitor接口和PropertyFileBaseVisitor类,该类带有下列默认实现的方法。
public class PropertyFileBaseVisitor<T> extends AbstractParseTreeVisitor<T>
implements PropertyFileVisitor<T>
{
@Override public T visitFile(PropertyFileParser.FileContext ctx) { ... }
@Override public T visitProp(PropertyFileParser.PropContext ctx) { ... }
}
下面是访问者模式中设计到的类之间的关系。

Visitors 通过调用接口ParseTreeVisitor的visit方法来遍历分析树。该方法在AbstractParseTreeVisitor类中实现。而visitor与listener的一个重要区别是,visitor不需要创建ParseTreeWalker来遍历分析树,而是使用visitor方法来遍历。
PropertyFileVisitor loader = new PropertyFileVisitor();
loader.visit(tree);
System.out.println(loader.props); // print results为规则加标签实现精确处理
例如有文法
grammar Expr;
s : e;
e : e op=MULT e // MULT is '*'
| e op=ADD e // ADD is '+'
| INT
;
生成的listener如下。
public interface ExprListener extends ParseTreeListener {
void enterE(ExprParser.EContext ctx);
void exitE(ExprParser.EContext ctx);
...
}
由于在文法规则中有多个规则e,(e:op=MUL ,e op=ADD),为了在exitE中判断当前到底是离开哪个规则e,可以使用op标识符标签以及ctx(上下文对象)的方法,代码如下。
public void exitE(ExprParser.EContext ctx) {
if ( ctx.getChildCount()==3 ) {
// operations have 3 children
int left = values.get(ctx.e(0));
int right = values.get(ctx.e(1));
if ( ctx.op.getType()==ExprParser.MULT ) {
values.put(ctx, left * right);
}
else {
values.put(ctx, left + right);
}
}
else {
values.put(ctx, values.get(ctx.getChild(0))); // an INT
}
}
代码中通过op判断类型,最终进行正确的计算。exitE()方法中的MULT 是有ANTLR生成,并放在ExprParser中。
exitE()方法中的MULT 是有ANTLR生成,并放在ExprParser中。
public class ExprParser extends Parser {
public static final int MULT=1, ADD=2, INT=3, WS=4;
...
}
为了得到更精确的监听器事件,Antlr 提供#来在文法规则最左侧为文法加标签。
e : e MULT e # Mult
| e ADD e # Add
| INT # Int
;
加上标签后,Antlr会为每个规则e生成一个监听方法。这样就不在需要op 标示符标签了。
public interface LExprListener extends ParseTreeListener {
void enterMult(LExprParser.MultContext ctx);
void exitMult(LExprParser.MultContext ctx);
void enterAdd(LExprParser.AddContext ctx);
void exitAdd(LExprParser.AddContext ctx);
void enterInt(LExprParser.IntContext ctx);
void exitInt(LExprParser.IntContext ctx);
...
}
在事件方法中共享信息
无论收集还是计算数据,都会传递参数或返回值。现在的问题是,Antlr会自动生成监听器方法,这些方法没有具体的返回值与参数。而生成visitor方法,该方法也没有具体的参数。因此,本节将学习利用一些机制让事件方法传递数据,而不用修改事件方法签名。接下来以计算器为例,提供三种不同的计算器的实现。第一种方法是使用visitor方法返回值,第二种是使用栈,第三种是注解分析树结点来存储感兴趣的数据。
通过Visitors来遍历分析树
构建基于visitor的计算器的最简单方法是让事件方法与返回子表达式值的规则关联。例如visitAdd会返回两个子表达式相加的结果。visitInt()将会返回一个整数值。传统的visitor并不会为其visit方法指定返回值。为了返回数据,为我们所实现的类中的方法添加返回值。
public static class EvalVisitor extends LExprBaseVisitor<Integer> {
public Integer visitMult(LExprParser.MultContext ctx) {
return visit(ctx.e(0)) * visit(ctx.e(1));
}
public Integer visitAdd(LExprParser.AddContext ctx) {
return visit(ctx.e(0)) + visit(ctx.e(1));
}
public Integer visitInt(LExprParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
}
EvalVisitor从Antlr的AbstractParseTreeVisitor类继承了visit()方法,visitor通过这个方法触发对子树的遍历。
通过栈存储返回值
因为Antlr生成的监听器时间方法没有返回值,所以要在不同的方法中用到返回值,可以通过栈来存储。在存储时一定要注意参数的顺序,以保证计算结果的正确,完整演示代码如下。
public class Evaluator extends LExprBaseListener{
Stack<Integer> stack = new Stack<Integer>();
@Override
public void exitMult(MultContext ctx) {
int right = stack.pop();
int left = stack.pop();
stack.push(right * left);
System.out.println(stack.peek());
}
@Override
public void exitAdd(AddContext ctx) {
int right = stack.pop();
int left = stack.pop();
stack.push(right + left);
System.out.println(stack.peek());
}
@Override
public void exitInt(IntContext ctx) {
stack.push(Integer.valueOf(ctx.INT().getText()));
System.out.println(stack.peek());
}
}
public class Main {
public static void main(String[] args) {
String exp = "1+2*3+4";
ANTLRInputStream inputStream = new ANTLRInputStream(exp);
LExprLexer lexer = new LExprLexer(inputStream);
CommonTokenStream tk = new CommonTokenStream(lexer);
LExprParser parser = new LExprParser(tk);
Evaluator evaluator = new Evaluator();
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(evaluator, parser.e());
}
}
程序最终打印出表达式的值11。
注释分析树
除了通过栈,返回值保存临时数据,也可以将临时结果存放在分析树的结点上。如下图是表达式1+2*3的注释分析树。图中箭头所指数字为结点所存储的临时结果。
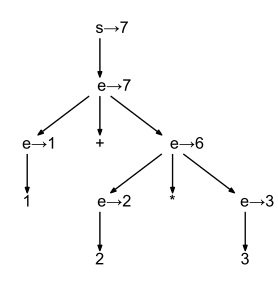
以文法LExpr.g4 为例。
LExpr.g4
e : e MULT e # Mult
| e ADD e # Add
| INT # Int
;
最简单的为分析树结点添加数据的方法是使用Map。Antlr提供了一个名为ParseTreeProperty简单的帮助类,其中ParseTreeProperty的代码如下。
public class ParseTreeProperty<V> {
protected Map<ParseTree, V> annotations = new IdentityHashMap<ParseTree, V>();
public V get(ParseTree node) {
return annotations.get(node);
}
public void put(ParseTree node, V value) {
annotations.put(node, value);
}
public V removeFrom(ParseTree node) {
return annotations.remove(node);
}
}如过要使用自定义Map,确保自定义Map是继承于IdentityHashMap,而不是HashMap,而结点相等判断则通过identity方法完成。两个结点可能相等,但在内存中可能并不是同一个物理结点。随后使用put,get方法添加临时数据。使用ParseTreeProperty实现的表达式计算代码如下。
public class Evaluator extends LExprBaseListener{
public ParseTreeProperty<Integer> values = new ParseTreeProperty<Integer>();
@Override
public void exitS(SContext ctx) {
values.put(ctx, values.get(ctx.e()));
System.out.println(values.get(ctx));
}
@Override
public void exitMult(MultContext ctx) {
int left = values.get(ctx.e(0));
int right = values.get(ctx.e(1));
values.put(ctx, left * right);
System.out.println(left * right);
}
@Override
public void exitAdd(AddContext ctx) {
int left = values.get(ctx.e(0));
int right = values.get(ctx.e(1));
values.put(ctx, left + right);
System.out.println(left + right);
}
@Override
public void exitInt(IntContext ctx) {
String intText = ctx.INT().getText();
values.put(ctx, Integer.valueOf(intText));
}
}
public class Main {
public static void main(String[] args) {
String exp = "1+2*3+4";
ANTLRInputStream inputStream = new ANTLRInputStream(exp);
LExprLexer lexer = new LExprLexer(inputStream);
CommonTokenStream tk = new CommonTokenStream(lexer);
LExprParser parser = new LExprParser(tk);
Evaluator evaluator = new Evaluator();
ParseTreeWalker walker = new ParseTreeWalker();
SContext s = parser.s();
walker.walk(evaluator, s);
System.out.println(evaluator.values.get(s));
}
}
前文共提到三种方法,Visitor下方法的返回值、使用栈存储数据及使用Map存储数据。在具体应用的过程各种可以根据实际需求来选择,或结合使用。














 5220
5220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









