







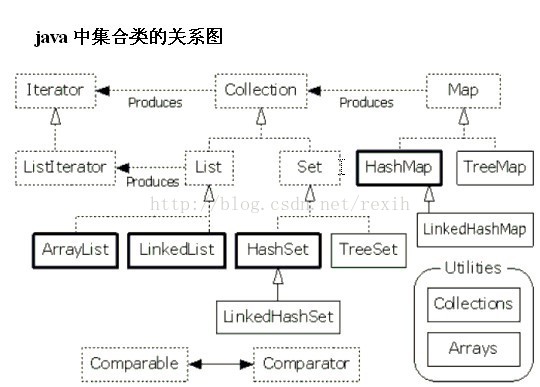
集合框架位于java.util.*
接口Collection<E>------子接口List<E>,Set<E>
数组和集合类同是容器,区别:
1.数组长度固定,集合长度可变
2.数组可以存储对象和基本数据类型,集合只能存储对象
List与Set的区别:
List是可重复的,可随机访问,不可排序,唯一性:equals;
Set是不重复的,不可随机访问,可排序,唯一性:ListSet - hashCode+equals/TreeSet - compareTo;
一、Collection<E>
根跟接口Collection定义了许多集合通用的方法:
1.添加
boolean add(E e)
boolean addAll(Collection<? extends E> c)//可以添加一个E的子系类的集合
2.删除
void clear()//清空集合
boolean remove(Objecto)//移除o
boolean removeAll(Collection<?>c)//移除集合对象中同时包含在c集合中的元素
boolean retainAll(Collection<?>c) //保留集合对象中同时包含在c集合中的元素
3.判断
boolean contains(Object o)//集合含有对象o则返回true
boolean containsAll(Collection<?> c)//若此集合对象含有集合c中所有元素则返回true
boolean isEmpty() //空集合则返回true
4.获取
int size()//返回集合中元素个数
Iterator<E> iterator()//返回在此 collection 的元素上进行迭代的迭代器。
Object[] toArray()//返回包含此集合中所有元素的数组。
<T> T[] toArray(T[] a)//前者的增强版
a返回的数组<T> T[]的运行时类型<T>是指定的数组a的运行时类型<T>
b若指定数组a可以容纳集合中的元素则返回此数组a,若a有剩余空间则用null填充
c如果a无法容纳则将分配一个具有指定数组a的运行时类型<T>的且其大小与数组元素数量相同的新数组。
//Collection<String> c
String[] newStringArray = c.toArray(new String[0]);//长度为0的String数组必定不能容纳c的元素,则分配一个与String数组同类型的String[]存放集合的元素,而这个新的String[]的长度与集合元素数量相同。
boolean equals(Objecto) //比较此 collection 与指定对象是否相等。
int hashCode()//返回此 collection 的哈希码值。
二、Iterator<E>
迭代器Iterator<E> 集合取出元素的方式,定义在集合内部。
共性:判断和取出,会自动消亡
可以通过集合的iterator()获取对应的对象的迭代器
Iterator itor=al.iterator();
方法:
boolean hasNext()//迭代器下一个指向元素是否存在
E next()//返回迭代器所指向的元素的索引,并将迭代器向后移动一个位置
void remove()//删除迭代器当前所指向的元素。每次使用next最多只能使用一次remove
ArrayList a=newArrayList();
for(Iterator itor =a.iterator();iter.hasNext();){
System.out.println(iter.next());
}
Iterator itor2 = a.iterator();
while(itor2.hasNext()){
System.out.println(iter.next());
}
三、List<E>
判断元素是否相同,依据的是元素的equals方法。(remove,contains底层使用的也是equals)
凡是可以直接处理下标的方法都是List所特有的
1.添加
void add(int index, E element)//在列表的指定位置插入指定元素
boolean addAll(int index, Collection<? extendsE> c) 将集合c中的元素从指定位置开始插入
2.删除
Eremove(int index)//移除列表中指定位置的元素并将之返回
3.修改
Eset(int index, E element)//用指定元素替换列表中指定位置的元素,返回原值
4.获取
E get(int index) //返回列表中指定位置的元素。
int indexOf(Object o)//返回o在集合中第一次出现的位置,若无则返回-1
int lastIndexOf(Object o) //返回o在集合中最后一次出现的位置,若无则返回-1
List<E> subList(int fromIndex, inttoIndex)//返回从fromIndex到toIndex(不含)的子列表
ListIterator<E> listIterator()//返回此列表元素的列表迭代器
ListIterator<E> listIterator(int index) //返回此列表元素从index开始的列表迭代器
Iterator只能删除不能添加。使用Iterator时不能既使用集合的方法,又使用迭代器方法。会发生ConcurrentModificationException异常。
在迭代器时,只能用迭代器的方法操作元素,只能对元素进行判断,取出,删除的操作。
ListIterator
List特用的迭代器,因为List是有序的,所以可以在迭代时进行增删等操作
方法:
添加void add(E e) //将指定的元素插入列表
删除void remove() //从列表中移除由 next 或 previous 返回的最后一个元素
修改void set(E e)//用指定元素替换 next 或 previous 返回的最后一个元素
向后迭代:
boolean hasNext() //以正向遍历列表时,如果列表迭代器有多个元素,则返回 true(换句话说,如果 next 返回一个元素而不是抛出异常,则返回 true)。
E next() //返回列表中的下一个元素。
int nextIndex()//返回下一个元素的索引,尾部为列表的大小
向前迭代:
boolean hasPrevious() //如果以逆向遍历列表,列表迭代器有多个元素,则返回 true。
E previous()//返回列表中的前一个元素。
int previousIndex()//前一个元素的索引,首部为-1
四、Vector
LinkedList 底层是链表,增删快,查询速度慢,线程不同步
ArrayList 底层是数组,增删慢,查询速度快,线程不同步
Vector 底层是数组,速度慢,但是线程安全
Vector
方法:(XxxElement是Vector特有方法)
void addElement(obj);//添加元素到末尾
E elementAt(int index)//返回指定索引处的组件。
void insertElementAt(Eobj, int index)//将对象obj作为此向量中的组件插入到index所指位置。
Vector取出元素的方法:
1.迭代listIterator()/iterator()
2.遍历中使用get(list的子类,可以使用for)
E get(int index)//返回向量中指定位置的元素。与E elementAt(int index)方法功能相同,但get是List接口的一部分,elementAt是特有方法
3.枚举:
Enumeration elements();//Vector特有取出方式(枚举)
Enumeration的两个方法:
boolean hasMoreElements();//相当于Iterator的hasNext()方法
nextElement();//相当于Iterator的next()方法
五、LinkedList
LinkedList:底层使用的是链表数据结构。特点:增删速度很快,查询稍慢。
特有方法:
1.添加
addFirst();
addLast();
2.获取
//获取元素,但不删除元素。如果集合中没有元素,会出现NoSuchElementException
getFirst();
getLast();
3.删除
//获取元素,并删除元素。如果集合中没有元素,会出现NoSuchElementException
removeFirst();
removeLast();
在JDK1.6以后,出现了替代方法。
1.添加
offFirst();
offLast();
2.获取
//获取元素,但是不删除。如果集合中没有元素,会返回null。
peekFirst();
peekLast();
3.删除
//获取元素,并删除元素。如果集合中没有元素,会返回null。
pollFirst();
pollLast();
六、set
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
|--HashSet:底层数据结构是哈希表。线程不同步。保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true。
|--TreeSet:可以对Set集合中的元素进行排序。默认按照字母的自然排序。底层数据结构是二叉树。保证元素唯一性的依据:compareTo方法return 0则相同。
Set集合的功能和Collection是一致的。
(一)HashSet-Hash表
特点:
1.元素重复性:元素不可以重复
判断重复的标准:
1.比较对象的hashcode
2.若hashcode相同则比较equals
contains()/remove()等操作底层依赖hasCode()以及equals()
2.存储顺序特性:无序存储。不是按添加顺序,而是按照hash值顺序存储,若hash值相同而equals为false则在前一个相同hashcode实例对象的后面存储新的对象。
若hashCode结果相同而equals结果为true,则表示两个对象为同一对象,则不予添加,返回false。
假设有类Testing,则HashSet<Testing>迭代后打印显示的是类似testing@c17164的结果。@前为类名,@后为实例对象的hash值
3.取出方法:只能通过迭代器取出添加进Set的实例对象。
4.线程安全性:线程不同步
5.存取速度:存取速度快
注意:当HashSet添加两个值相同的对象时,首先比较的是hash值,如果使用的是默认的hashCode,因存储位置不同,结果是不同的hash值的话,是不会再调用equals进行下一步比较,直接当作两个不同对象。
(二)TreeSet-二叉树
特点:
1.元素重复性:元素不可以重复
判断重复的标准:
1.TreeSet中的元素需要具有比较性,否则会产生ClassCastException
2.通过compareTo方法的返回值判断是否相同
String类的默认比较方法是Unicode编码顺序
2.存储特性:有序存储。但不能随机访问。按照所设定的排序方法进行排序。
3.取出方法:只能通过迭代器取出添加进Set的实例对象。
4.线程安全性:线程不同步
5.访问特性:中序遍历
实现排序的两种方法:(必须)
1.元素的类实现Comparable接口,覆盖int compareTo(T o)
2.如果元素不具备比较性(没有实现Comparable接口),或者默认的排序不是所需时,须要让集合自身具备比较性。
构造函数传入一个比较器参数
TreeSet<E>(Comparator<?super E> comparator)
Comparator接口需要实现intcompare(T o1, T o2)方法
Comparator接口与Comparable接口的区别:
Comparator位于java.lang.util.* Comparable位于java.lang.*;
需要实现int compare(T o1,T o2) 需要实现intcompareTo(T o)
当Comparable与Comparator都存在,以Comparator为主
七、Map
Map
|--Hashtable:底层是哈希表数据结构,不可以存入null键null值。该集合是线程同步的。JDK1.0,效率低。
|--HashMap:底层是哈希表数据结构。允许使用null键null值,该集合是不同步的。JDK1.2,效率高。
|--TreeMap:底层是二叉树数据结构。线程不同步。可以用于给Map集合中的键进行排序。
Set底层就是使用了Map集合。
(一)特点
1.双列集合,存储的是键(key)值(value)对。一对一对往里存
2.要保证键key的唯一性。
(二)Map集合的常用方法
1.添加
V put(K key,Vvalue);//添加元素,如果出现添加时,相同的键,那么后添加的值会覆盖原有键对应值,并put方法会返回被覆盖的值。
void putAll(Map<? extends K,? extends V> m);//添加一个集合
2.删除
clear();//清空
V remove(Object key);//删除指定键值对,并返回被删除键值对的值
3.判断
containsKey(Objectkey);//判断键是否存在
containsValue(Objectvalue)//判断值是否存在
isEmpty();//判断是否为空
4.获取
V get(Object key);//通过键获取对应的值
size();//获取集合的长度
Collection<V> value();//获取Map集合中所有所谓值,返回一个Collection集合
(三)Map集合的两个视图
Map集合的两个视图(实现了Collection接口/子接口对象的视图)
键集,键值对集,(还有一个视图是值集合)
KeySet和EntrySet不是HashSet和TreeSet,而是实现了Set接口的某个其他类。而Set接口扩展了Collection接口,可以使用集合的所有方法
1. keySet
Set<K> keySet():将Map中所有的键存入到Set集合。因为Set具备迭代器。所以可以通过迭代方式取出所以键的值,再通过get方法。获取每一个键对应的值。
//Map<String,String> m=newHashMap<String,String>();
Set<String> keyS=m.keySet();
for(Iterator<String>itor=keyS.iterator();itor.hasNext();){
Stringtmp=itor.next();
System.out.println(m.get(tmp))
}
2. entrySet
Set<Map.Entry<K,V>> entrySet():将Map集合中的映射关系存入到Set集合中,而这个关系的数据类型就是:Map.Entry
其实,Entry也是一个接口,它是Map接口中的一个内部接口(内部接口默认是public和static)。
interface Map{
public staticinterface Entry{
public abstract Object getKey();
public abstract Object getValue();
}
}
定义在Map内部的原因:
1. Map中存储的是键值对,先有Map才会有键值对,是Map的内部事务。
2.是Map映射表中的元素使用Entry,应当可以直接访问Map中的内部成员。(内部类,为了使用外部类的成员)
//Map<String,String> m=newHashMap<String,String>();
Set<Map.Entry<String,String>>entryS=m.entrySet();
for(Iterator<Map.Entry<String,String>>itor=entryS.iterator();itor.hasNext();){
Map.Entry<String,String>tmp=itor.next();
Stringkey=tmp.getKey();
Stringvalue=tmp.getValue();
}
集合框架中的两个工具类Collections和Arrays
八、Collections
(一)特点
1.包装类,完全由 在 collection 上进行操作 或 返回 collection 的静态方法组成。它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。
2.如果为此类的方法所提供的collection或类对象为null(提供的参数为null),则这些方法都将抛出 NullPointerException。
3.在Collections工具类中大部分方法是用于对List集合进行操作的,如比较,二分查找,随机排序等。
4.没有对外提供构造函数
(二)常见操作方法
1.反转
reverse(List<?>list);// [List]反转list集合中元素的顺序
Comparator reverseOrder();//返回一个比较器,强行逆转了实现Comparable接口的对象的自然顺序
Comparator reverseOrder(Comparator<T>cmp);//返回一个比较器,强行逆转了指定比较器的顺序
2.排序[List]
void shuffle(List<?> list);//使用默认随机源对list集合中的元素进行随机排序
void sort(List<T> list);//根据自然顺序对list集合中的元素进行排序
void sort(List<T> list,Comparator<? super T> c);//根据指定比较器c的排序方式对list集合进行排序
3.查找
T max/min(Collection<? extends T> coll);//根据集合的自然顺序,获取coll集合中的最大(小)元素
T max/min(Collection<? extends T> coll,Comparator<? super T>comp);//根据指定比较器comp的顺序,获取coll集合中的最大(小)元素
使用二分法查找前应当先用sort排序否则结果将不确定
int binarySearch(List<? extends Comparable<? super T>> list,T key);//[List]二分法搜索list集合中的指定对象
int binarySearch(List<? extendsComparable<? super T>> list,T key,Comparator<? super T> comp);//[List]根据指定比较器comp的顺序,二分法搜索list集合中的指定对象
4.替换[List]
void fill(List<? super T> list, T obj);//全部替换一个元素。将list集合中的全部元素替换成指定对象obj
boolean replaceAll(List<T> list,T oldVal,T newVal);//指定内容的元素的替换。用newVal替换集合中的oldVal值
void swap(List list,int i,int j);/在指定列表的指定位置处交换元素
5.同步的集合
List<T> synchronizedList(List<T> list);// [List]返回支持的同步(线程安全的)List集合
Map<K,V> synchronizedMap(Map<K,V> m);// [Map]返回支持的同步(线程安全的)Map集合
(三)Collections和Collection的区别
Collection是集合框架中的一个顶层接口,它里面定义了单列集合的共性方法。
它有两个常用的子接口:
List:对元素都有定义索引。有序的。可以重复元素。
Set:不可以重复元素。无序
Collections是集合框架中的一个工具类。该类中的方法都是静态的。提供的方法中有可以对list集合进行排序,二分查找等方法
通常常用的集合都是线程不安全的。因为要提高效率。如果多线程操作这些集合时,可以通过该工具类中的同步方法,将线程不安全的集合,转换成安全的。
九、Arrays
Arrays - 用于操作数组的工具类,全部是静态方法
1.获取
复制copyOf():复制指定的数组,截取或用 0/null填充(如有必要),以使副本具有指定的长度。
statictypename [] copyOf(typename[]original,int newLength)
比如:static int[]copyOf(int[] original, int newLength)
static int[] copyOfRange(int[]original,intfrom,int to)
二分法搜索binarySearch(),
staticint binarySearch(typename[]a,intfromIndex,int toIndex,typename key)
比如:static intbinarySearch(double[] a, int fromIndex, int toIndex, double key)
返回的是key在数组中的位置。如果没找到则返回(-(插入点) - 1)
2.修改
替换fill(typename[] a,typename key )
fill(typename[]a,int fromIndex,int toIndex,typename key )
排序sort(typename[] a)
sort(typename[]a,int fromIndex,int toIndex)
sort(T[]a,intfronIndexmint toIndex,Comparator<? super T>comp)
3.三个常用的方法
equals:Object的只能比较单个对象,Arrays中的静态equals可以比较2个数组
hashCode: Object的返回的是单个对象的哈希值,Arrays中静态的hashCode可以返回一个代表整个数组的元素的hash值,方便整个类对象计算hash值
toString:对于数组来说,默认的toString 返回的是地址,而不是内容,而Arrays中的静态toString则可以返回整个数组的内容。
import java.util.Arrays;
public classtest2 {
public static void main(String[] args) {
//equals
//static boolean equals(T[] a1, T[] a2)
System.out.println(Arrays.equals(new int[]{1,2,3},new int[]{1,2,3}));//true
//hashCode
//static int hashCode(T[] a)
System.out.println(Arrays.hashCode(new String[]{"hello","bye"}));//-1220836323
//toString
//static String toString(T[] a)
System.out.println(Arrays.toString(new double[]{3.14,1.23}));//[3.14, 1.23]
}
}
4.数组变为集合
List<T> asList(T... a);//将数组转换为集合
1将数组转换成集合,不可使用集合的增删方法,因为数组的长度是固定的。如果进行增删操作,则会产生UnsupportedOperationException的编译异常。
2如果数组中的元素都是对象,则变成集合时,数组中的元素就直接转为集合中的元素。
3如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在。
集合变数组– 限制对元素的操作,让其他的对数组的调用不可以增加或者删除元素:
每个集合类都有toArray()方法
<T> T[] toArray(t[] a)
集合元素数目大于数组长度,重新建立一个新数组存放集合的元素。
集合元素数目小于数组长度,用null填充
创建一个等大数组:
String[] arr=al.toArray(newString[al.size()]);
String[] arr2=al.toArray(new String[0]);















 3771
3771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









