







WSGI
全称:Python Web Server Gateway Interface(python web服务网关接口)
此WSGI接口 有2部分,分别为 server或者gateway端 和application或者framework端;
http请求处理过程如下图:
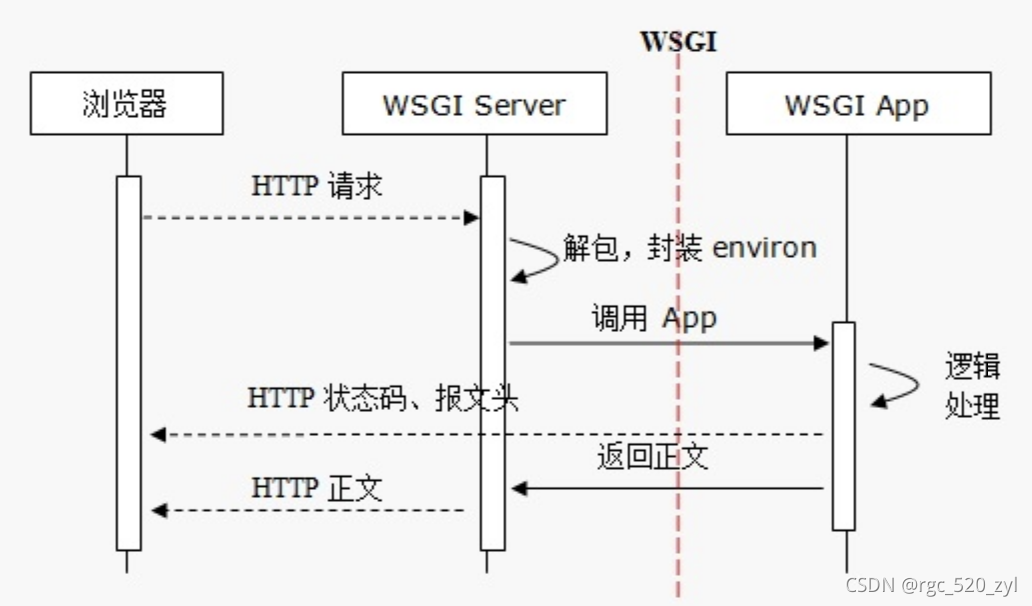
server端
作用
负责接收用户发起的http请求,进行简单处理后,将包装后的请求数据 调用一次application端的服务,处理具体的请求,处理完后再交给server端,封装后再交给用户;
flask框架中server端的依赖继承关系
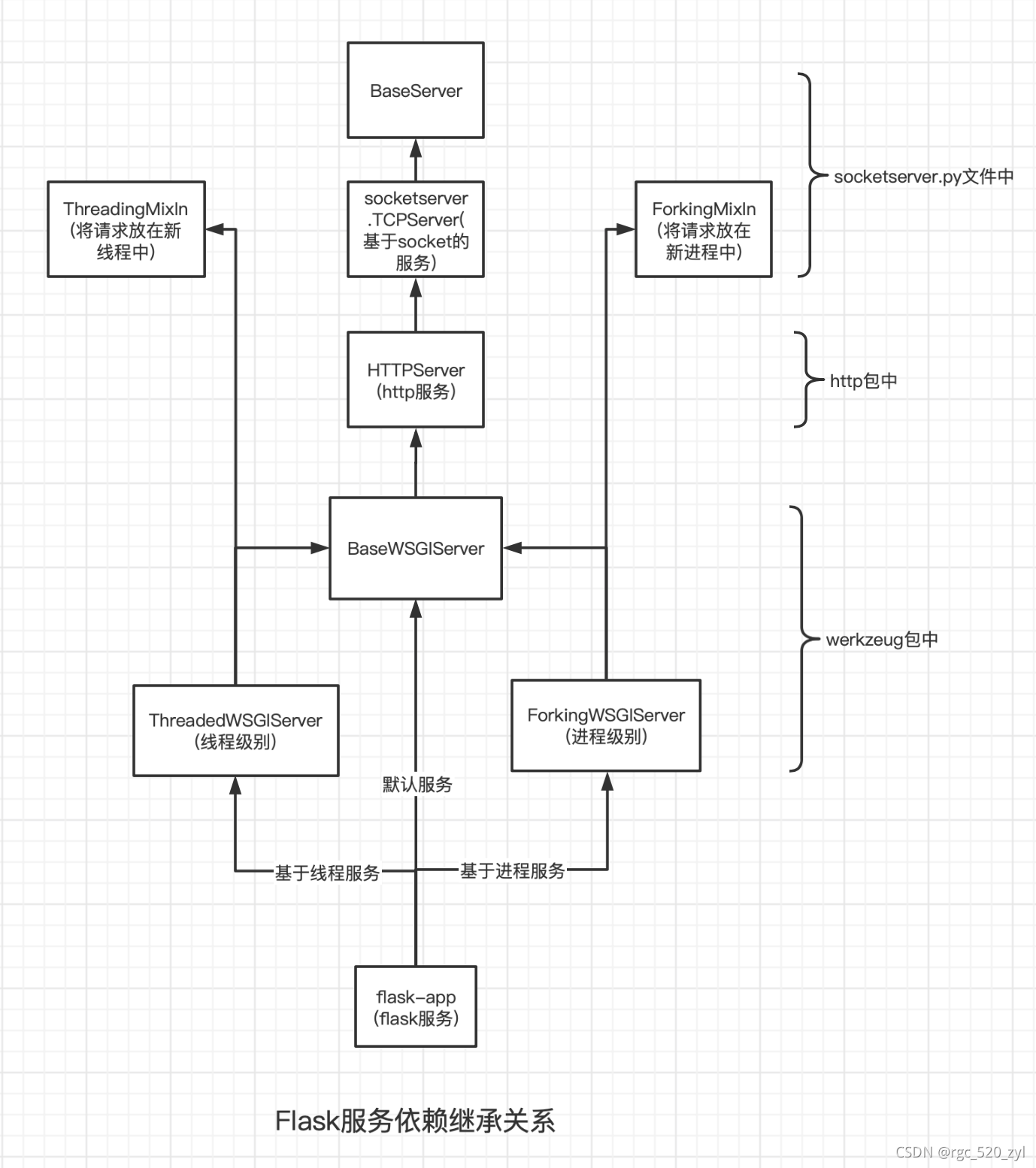
从如上图中能看出一个flask服务启动时的依赖关系,从tcp的socket端口服务,到上层的http服务,再到基于WSGI协议的服务;
一个请求进来时便是按照 从最底层socket服务到最顶层flask服务,一层层进行处理;
以基于线程的flask服务为例,在请求进来后,通过 ThreadedWSGIServer 生成一个新的线程来处理请求;
server端对application端的调用
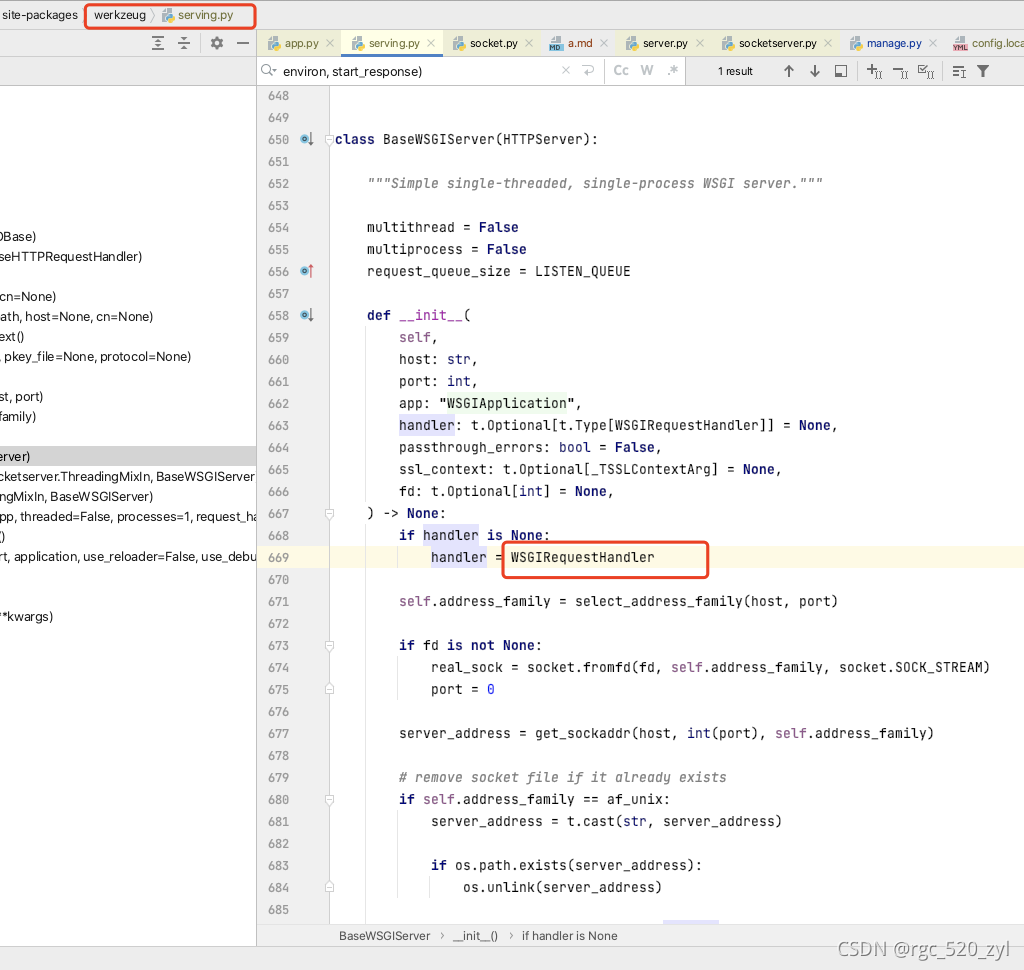
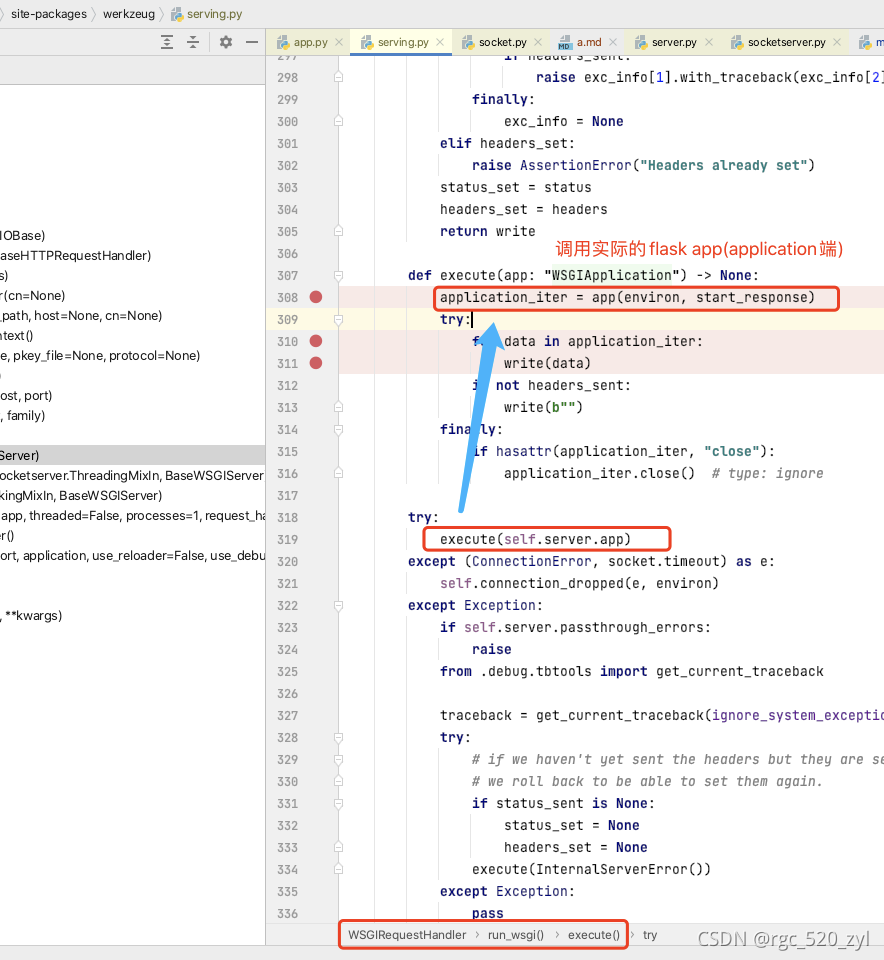
BaseWSGIServer类的handler属性是WSGIRequestHandler类,此类的execute方法执行实际的对 application端的调用;
application端
flask作为基于WSGI实现的application端框架,主要 通过 2种上下文机制 保证请求间 彼此的数据不会混用和编写优雅的处理请求代码;
RequestContext(请求上下文)
其包含主要属性如下:
app:此flask app对象的引用
request:请求相关数据如url/入参等等(from flask import request 其实导入的就是此对象),生命周期:在一次请求之间
url_adapter:应用的所有url和路由函数的对应关系,及此请求url等等
session:请求的session数据
g:对app_context的g属性的引用 ,生命周期:在一次请求之间
from flask import _request_ctx_stack
from flask import g # 从应用上下文栈中获取第一个应用上下文对象的g属性
request_context_user_id = _request_ctx_stack.top.g.user_id # 从请求上下文栈中获取第一个请求上下文对象的g属性
g_user_id = g.user_id
assert request_context_user_id == g_user_id
所以如上代码不会报错,以为获取的是同一个数据
其包含主要方法如下:
match_request():根据请求url匹配对应视图函数
push():将app_context推送到_app_ctx_stack中,然后将reqeust_context推送到_request_ctx_stack中,再执行url匹配路由操作(调用match_request()方法)
pop():将reqeust_context从_request_ctx_stack中弹出,再将app_context从_app_ctx_stack中弹出
enter():在使用"with app.request_context()"时调用,将此对象 push进 _request_ctx_stack中
exit():在使用"with app.request_context()"时调用,从_request_ctx_stack中pop掉此对象
主要作用
存储请求的数据及根据url寻找对应视图函数
生命周期
在一次请求之间
AppContext(应用上下文)
其包含主要属性如下:
app:此flask app对象的引用
url_adapter:应用的所有url和路由函数的对应关系,及此请求url等等
g:专门用来存储用户数据的对象,在flask程序中任何地方都可以直接调用,生命周期:在一次请求之间
from flask import g # 从应用上下文栈中获取第一个应用上下文对象的g属性
g.user_id = 1
其包含主要方法如下:
push():将app_context推送到_app_ctx_stack中
pop():将app_context从_app_ctx_stack中弹出
enter():在使用"with app.app_context()"时调用,将此对象 push进 _request_ctx_stack中
exit():在使用"with app.app_context()"时调用,从_request_ctx_stack中pop掉此对象
主要作用
存储app的配置数据和用户数据(g),方便开发时优雅的调用;
生命周期
在一次请求之间
_request_ctx_stack(请求上下文栈)数据结构及应用思想
其数据结构大致如下(以线程/协程 启动服务为例):
{
'线程/协程ID A': {"stack":["<RequestContext Obj1>", "<RequestContext Obj2>"]},
'线程/协程ID B': {"stack":["<RequestContext Obj1>", "<RequestContext Obj2>"]}
}
存储方式:通过在进程的内存空间中维护一个公共的所有线程/协程均可访问的dict数据结构,此dict的key必须为线程/协程ID(唯一标识), value是个子dict,子dict的key固定为statck,子dict的value必须是list结构(此list就是栈结构,先进先出), 里面存储此线程/协程对应的请求上下文对象
作用:在视图函数中处理请求过程中,如果需要获取此请求的入参等数据,直接根据 此线程/协程ID 去此dict中取对应数据即可,而且dict结构保证了查询时间复杂度一直为O(1);
生命周期:一直存在,直到flask应用进程结束
_app_ctx_stack(应用上下文栈)数据结构及应用思想
其数据结构大致如下(以线程/协程 启动服务为例):
{
'线程/协程ID A': {"stack":["<AppContext Obj1>", "<AppContext Obj2>"]},
'线程/协程ID B': {"stack":["<AppContext Obj1>", "<AppContext Obj2>"]}
}
存储方式:通过在进程的内存空间中维护一个公共的所有线程/协程均可访问的dict数据结构,此dict的key必须为线程/协程ID(唯一标识), value是个子dict,子dict的key固定为statck,子dict的value必须是list结构, 里面存储此线程/协程对应的应用上下文对象
作用:在视图函数中处理请求过程中,如果需要获取此应用的配置或全局变量g,直接根据 此线程/协程ID 去此dict中取对应数据即可,而且dict结构保证了查询时间复杂度一直为O(1);
生命周期:一直存在,直到flask应用(app)进程结束
current_app
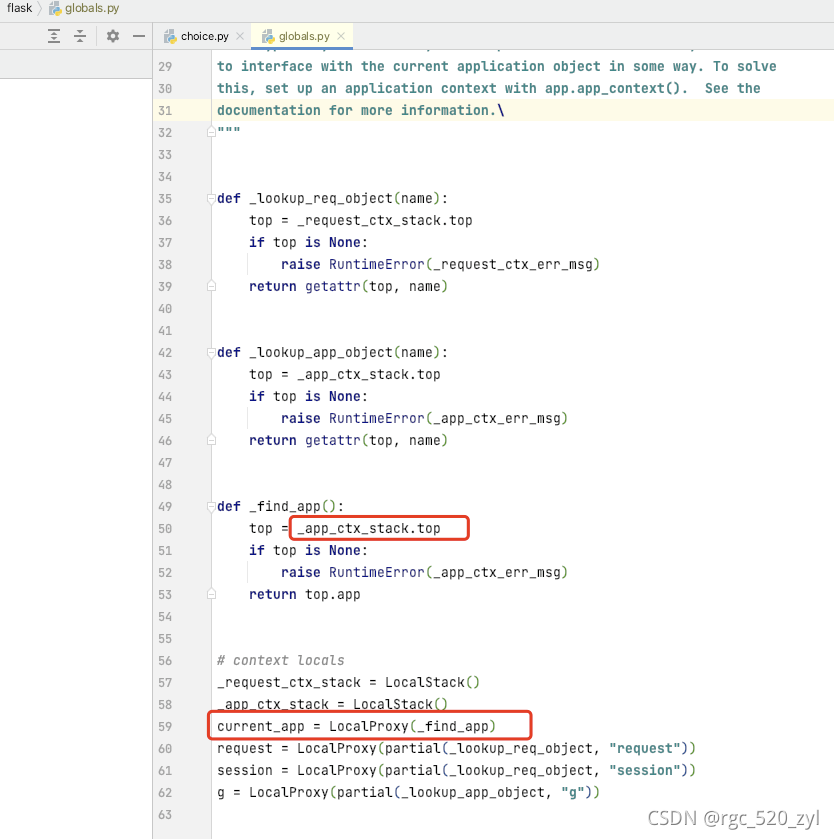
从代码中可以看出 current_app是 从 _app_ctx_stack中获取的一个AppContext对象,所以其生命周期和 AppContext相同,都是在一个请求之间(不要只看网上结论,要自己看源码论证);
一个请求进来时 上下文对栈的操作顺序
1.将应用上下文放入 应用上下文栈中
2.将请求上下文放入 请求上下文栈中
3.调用full_dispatch_request()方法 处理请求 直到请求处理完成
4.将请求上下文从 请求上下文栈中pop出来
5.将应用上下文从 应用上下文栈中pop出来
问题
并发处理请求时,会出现 正在处理的请求,其上下文对象就被从上下文栈中删除的情况吗?
每个线程阻塞执行,虽然通过 队列pop方式 删除上下文对象,但是由于是阻塞执行,能保证此线程处理请求是顺序执行,不会出现 请求还在执行就被删除上下文对象的情况;
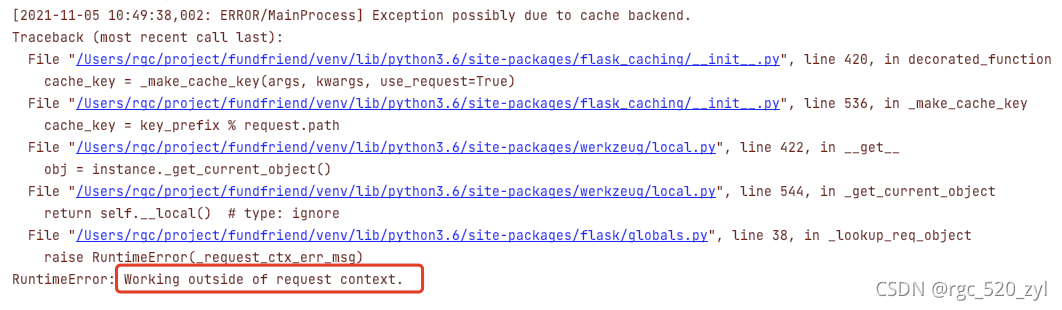
RuntimeError: Working outside of request context. 错误解决方法
起因:在celery worker执行的任务中用到了 @cache.cached() 此方法,由于此方法默认使用请求url作为缓存key,于是尝试获取请求上下文中的数据,但是此处是在worker任务中,没有请求上下文,所以报错如下;
解决方法: 使用 @cache.cached(key_prefix=‘self_key’) 自定义一个key,这样就不会尝试请求url;就不会报错;
总结:一般遇到此类错误,都是在请求处理之外的地方尝试获取上下文对象,才会出现;
总结
- 基于WSGI这一规范,flask内置的Werkzeug提供了WSGI的server端,flask app作为应用端,其自身的上下文机制 能够保证请求间的数据不会相互污染,且让开发人员能够优雅的编写代码;
- flask内置的server只提供线程/进程 级别的并发方式,生产服可以使用 基于协程的gunicorn作为server;
- flask中生命周期最长的只有 flask app(直到进程结束);其他的 g,request,current_app,app_context,reqeust_context都是在一个请求之间; 因为从 对象的生成和销毁来说,虽然 app_context的app属性是flask app对象的引用;但是app_context在请求结束后会被pop,所以生命周期只在一个请求之间;
- flask上下文机制 其实就是 一个 大的dict,其key为线程或协程ID,value为一个子dict,子dict的key必须为stack,子dict的value为list;每个请求因为都在单独的一个线程或协程中,通过线程或协程ID就能找到dict中对应的值,且请求处理完成后,list中的数据就会被清空,这样 即使下个请求使用同一个线程或协程 也不会出现问题;

















 8296
8296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









