







RLHF:在线方法与离线算法在大型语言模型校准中的博弈
一、引言
在人工智能领域,大型语言模型(LLM)的校准已成为一个备受关注的热点。基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,简称RLHF)作为一种有效的校准方法,已逐渐在GPT-4、ChatGPT等先进模型中展现出其独特优势。然而,随着离线对齐算法的迅速崛起,RLHF所面临的挑战也日益严峻。本文将从RLHF的基本概念入手,探讨在线方法与离线算法在大型语言模型校准中的优劣,并通过实验和代码实例加以佐证。
二、RLHF概述
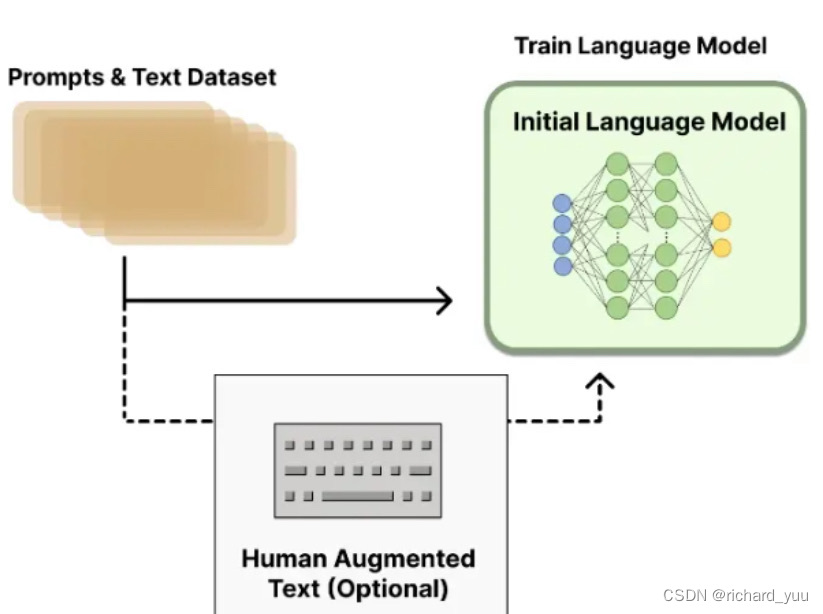
RLHF是一种结合人类反馈与强化学习的技术,旨在通过人类反馈来优化语言模型的输出。其基本思想是通过预先训练好的语言模型生成多个候选输出,然后由人类对这些输出进行排序或评分。这些排序或评分作为奖励信号,被用于指导模型在后续生成中“更喜欢”某些结果。通过这种方式,模型可以逐步学会根据人类偏好生成更安全、更准确的输出。
RLHF在大型语言模型校准中的应用主要体现在以下几个方面:
提高模型输出的安全性和可信度。通过人类反馈,模型可以学会避免生成不恰当或有害的内容。
增强模型对特定任务的理解和执行能力。例如,在文本分类或语言翻译等任务中,RLHF可以帮助模型更好地理解人类意图并生成更符合要求的输出。
缓解
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5062
5062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









