







文章目录
课程结构导航

基础 链接: link
核心 链接: link
高阶 链接: link
扩展 链接: link
第一章 Flink简介
1.Flink起源与设计理念


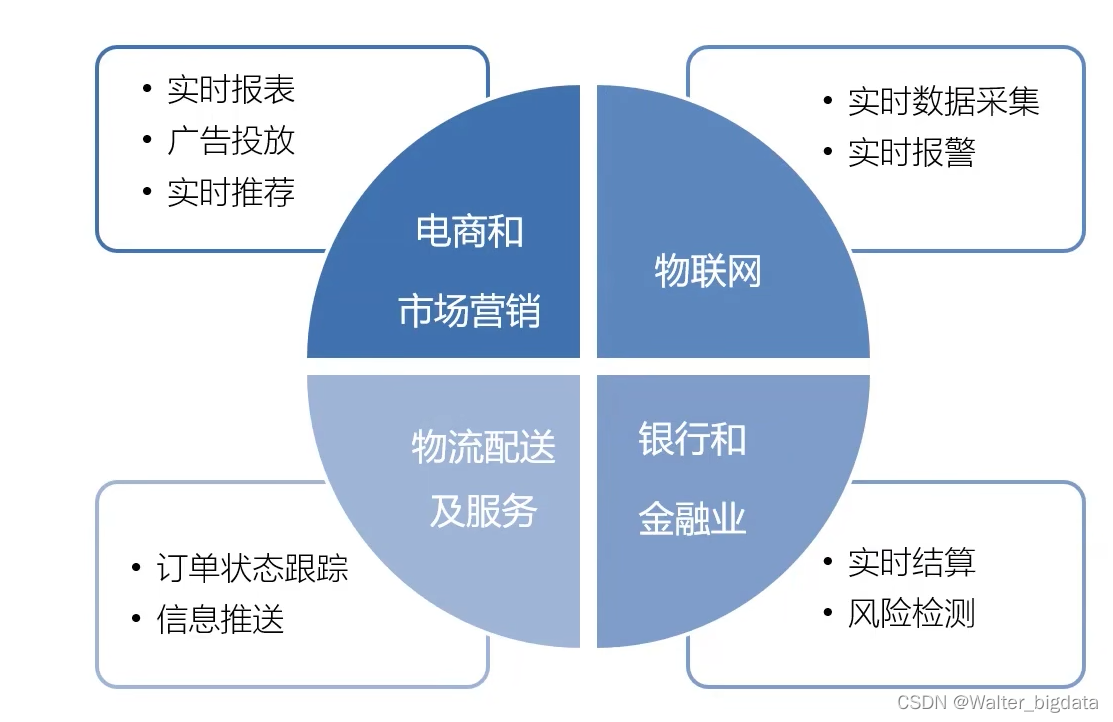
2.Flink在企业的应用
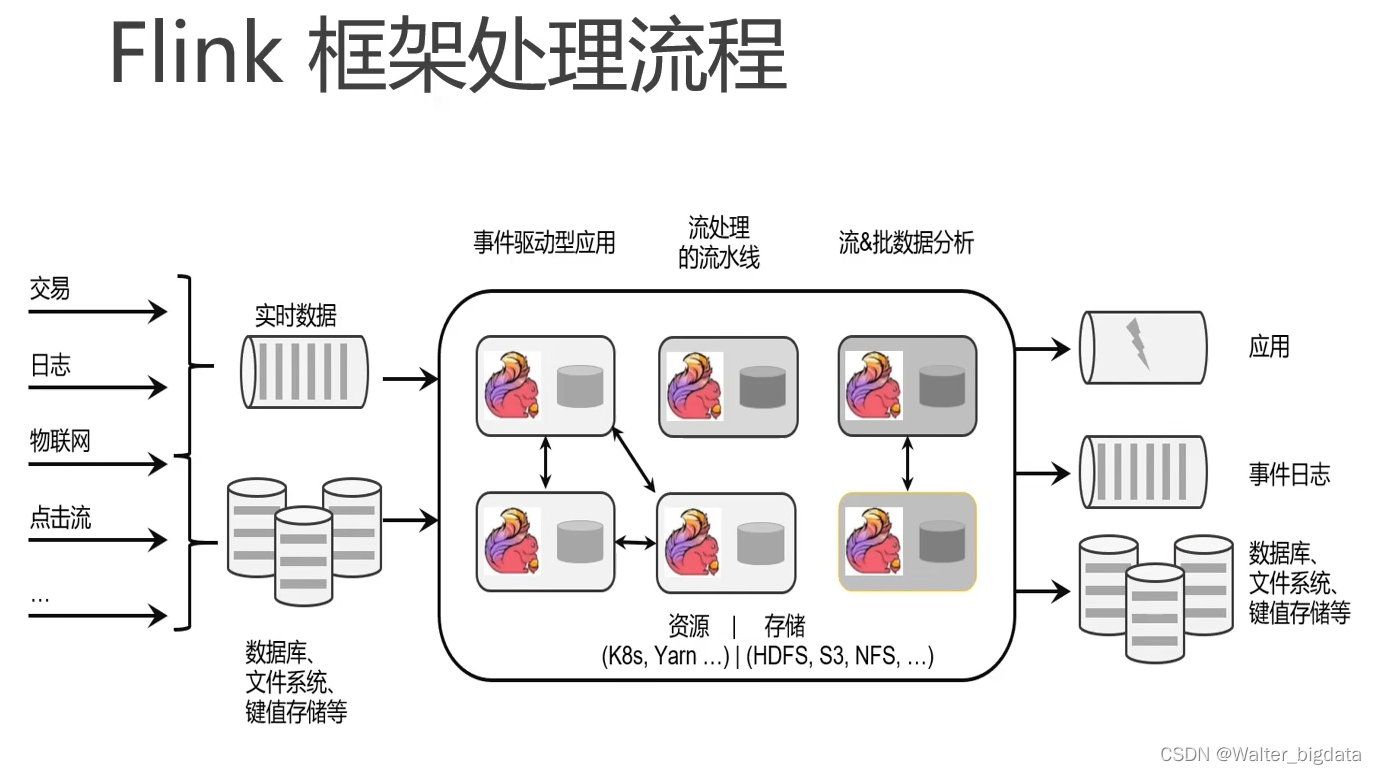

3.Flink的优势

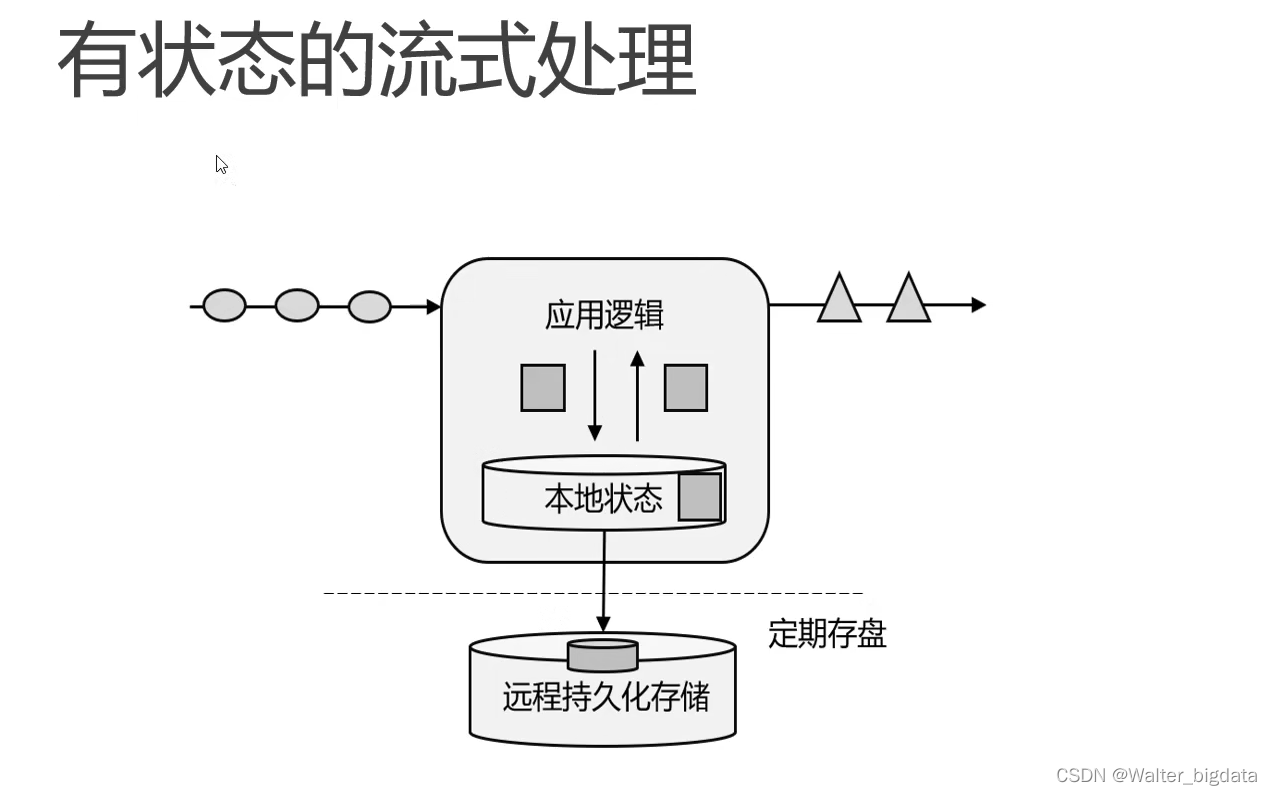
4.数据处理框架的演变
第一代实时架构(storm)
第二代实时架构(lambda架构)
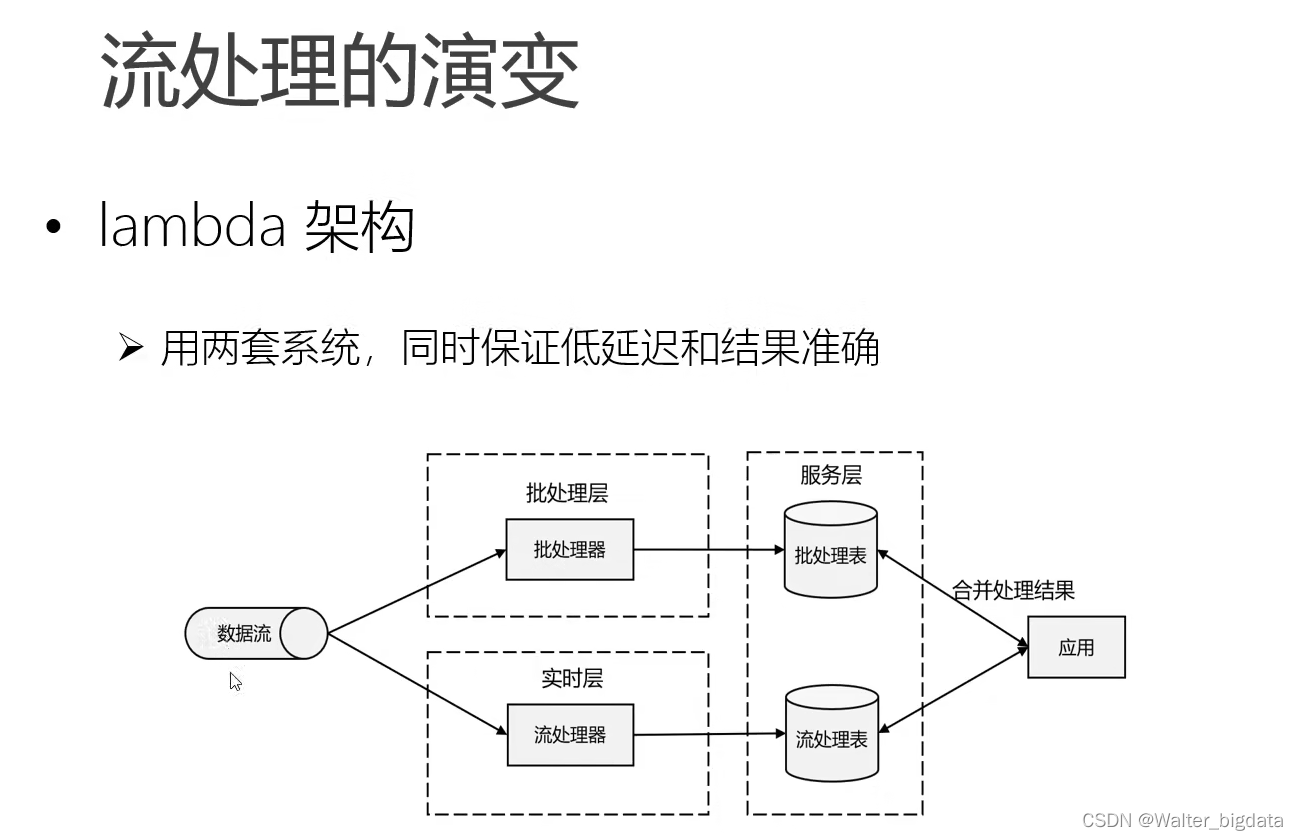
第三代实时架构kappa(Flink)

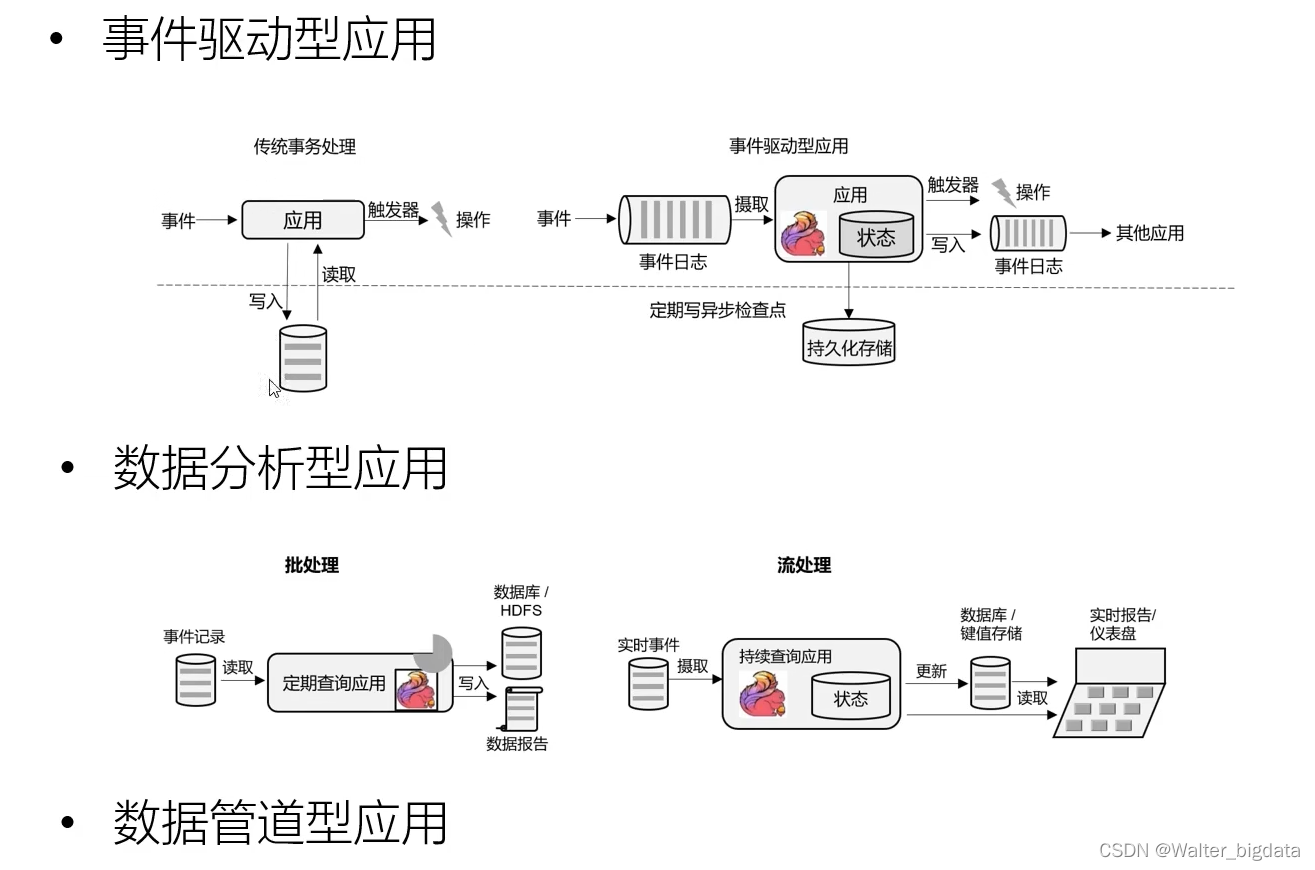
5.流处理的应用场景
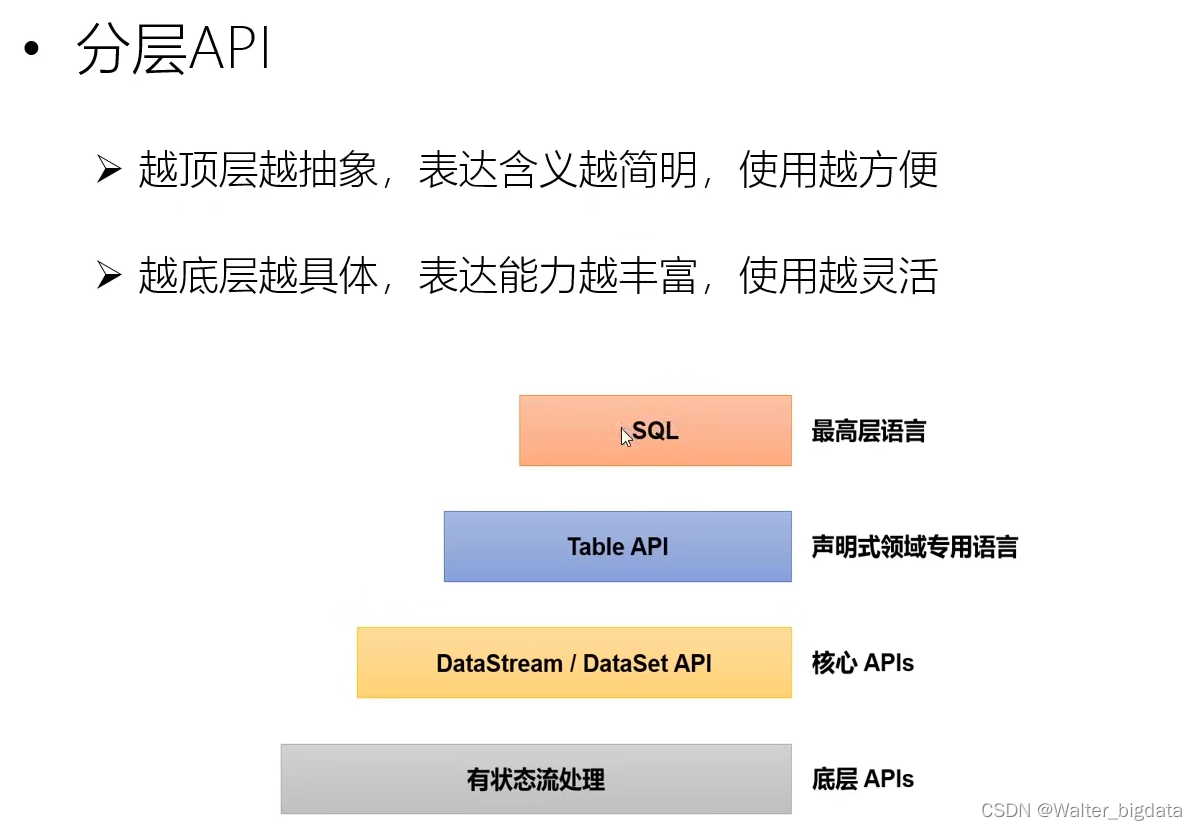
6.Flink分层API
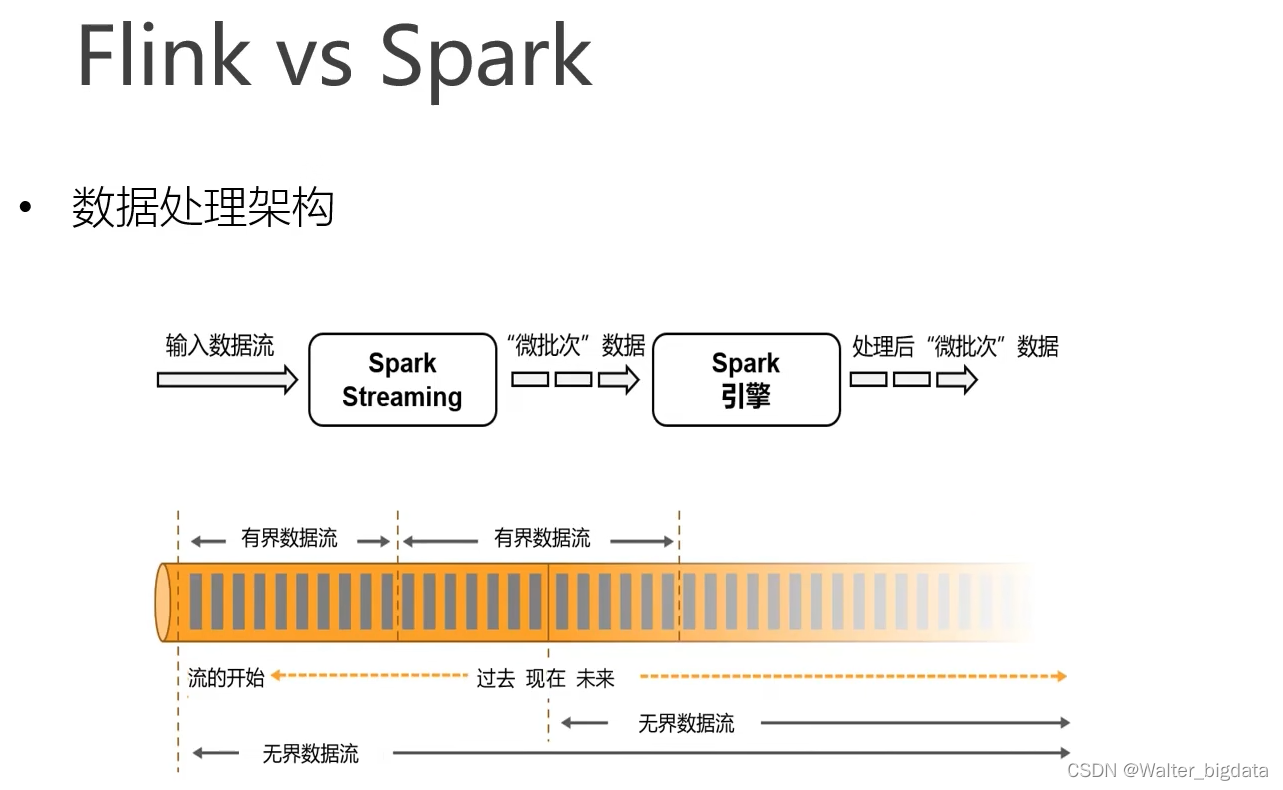
7.Flink与Spark的区别

第二章 Flink快速上手
对 Flink 有了基本的了解后,接下来就要理论联系实际,真正上手写代码了。Flink 底层是
以 Java 编写的,并为开发人员同时提供了完整的 Java 和 Scala API。在本书中,代码示例将全
部用 Java 实现;而在具体项目应用中,可以根据需要选择合适语言的 API 进行开发。
在这一章,我们将会以大家最熟悉的 IntelliJ IDEA 作为开发工具,用实际项目中最常见的
Maven 作为包管理工具,在开发环境中编写一个简单的 Flink 项目,实现零基础快速上手。
1.环境准备

2.创建maven项目
2.1 创建项目
2.2 创建项目添加项目依赖
在项目的 pom 文件中,增加<properties>标签设置属性,
然后增加<denpendencies>标签引入需要的依赖。我们需要添加的依赖
最重要的就是 Flink 的相关组件,包括
flink-java、
flink-streaming-java
flink-clients(客户端,也可以省略)。
另外,为了方便查看运行日志,
我们引入 slf4j 和 log4j 进行日志管理。
<properties>
<flink.version>1.13.3</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
在属性中,我们定义了<scala.binary.version>,这指代的是所依赖的 Scala 版本。这有一点
奇怪:Flink 底层是 Java,而且我们也只用 Java API,为什么还会依赖 Scala 呢?这是因为 Flink的架构中使用了 Akka 来实现底层的分布式通信,而 Akka 是用 Scala 开发的。我们本书中用到的 Scala 版本为 2.12。
2.3 配置日志管理
在目录 src/main/resources 下添加文件:log4j.properties,内容配置如下:
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
3.编写代码
3.1 批处理DataSet api(从1.12开始官方不再推荐使用DataSet api)
package com.scy.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) throws Exception {
//1.创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2.从文件读取数据
DataSource<String> lineDataSource = env.readTextFile("input/words.txt");
//3.将每行数据进行分词,转换成二元组类型
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
//将一行文本进行分词
String[] words = line.split(" ");
//将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.按照word进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
//5.分组内进行聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
//6.打印结果(alt+enter)抛出异常
sum.print();
}
}

可以看到,我们将文档中的所有单词的频次,全部统计出来,以二元组的形式在控制台打
印输出了。
需要注意的是,这种代码的实现方式,是基于 DataSet API 的,也就是我们对数据的处理
转换,是看作数据集来进行操作的。事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的 API 来实现。
所以从 Flink 1.12 开始,官方推荐的做法
是直接使用 DataStream API,在提交任务时通过将执行模式设为 BATCH 来进行批处理:
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
这样,DataSet API 就已经处于“软弃用”(soft deprecated)的状态,在实际应用中我们只
要维护一套 DataStream API 就可以了。这里只是为了方便大家理解,我们依然用 DataSet API
做了批处理的实现。
3.2 流处理DataStream api(推荐使用批流处理api)

3.2.1 读取文件
package com.scy.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建流失执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文件
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
//3.转换计算
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector< Tuple2<String, Long> > out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyStream = wordAndOneTuple.keyBy(data -> data.f0);
//5.求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyStream.sum(1);
//6.打印
sum.print();
//7.启动执行
env.execute();
}
}


3.2.2 读取文本流
Linux开启netcat链接
package com.scy.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文本流
DataStreamSource<String> lineDataStream = env.socketTextStream("node7", 7777);
//3.数据转换
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
//5.求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
//6.打印
sum.print();
//7.启动执行
env.execute();
}
}

import org.apache.flink.api.java.utils.ParameterTool;
// 从参数中读取主机名和端口号
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get("host");
Integer port = parameterTool.getInt("port");
//2.读取文本流
DataStreamSource<String> lineDataStream = env.socketTextStream(hostname, port);
第三章 Flink部署

3.1 快速启动一个 Flink 集群
3.1.1 环境配置(本环境使用hadoop2.7.2)

3.1.2 本地启动(本环境使用flink-1.13.3-bin-scala_2.12.tgz)

3.1.3 集群启动


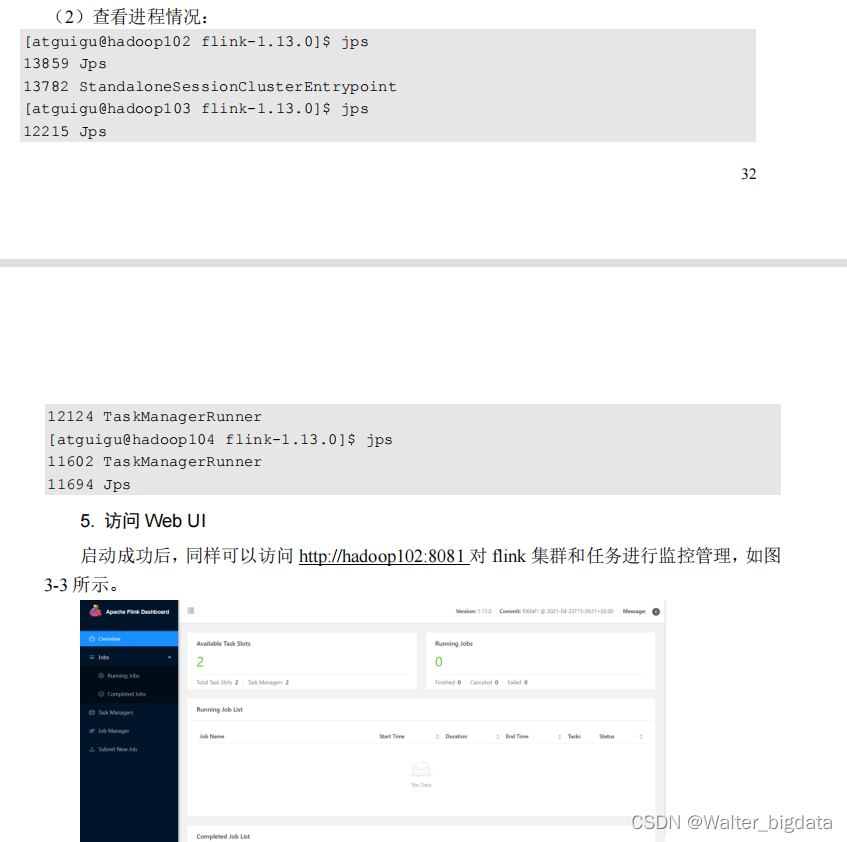
这里可以明显看到,当前集群的 TaskManager 数量为 2;由于默认每个 TaskManager 的 Slot
数量为 1,所以总 Slot 数和可用 Slot 数都为 2。
3.1.4 向集群提交作业
1.程序打包
(1)为方便自定义结构和定制依赖,我们可以引入插件 maven-assembly-plugin 进行打包。
在 FlinkTutorial 项目的 pom.xml 文件中添加打包插件的配置,具体如下:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>

2.在 Web UI 上提交作业
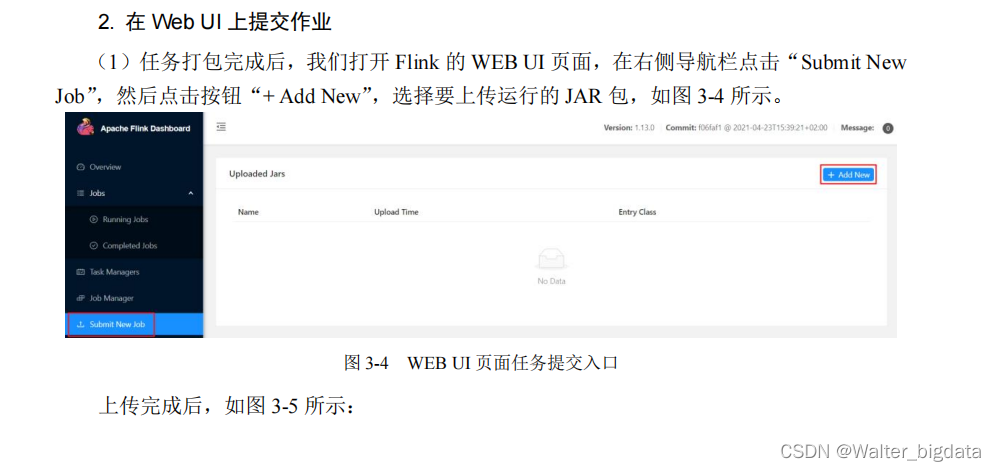
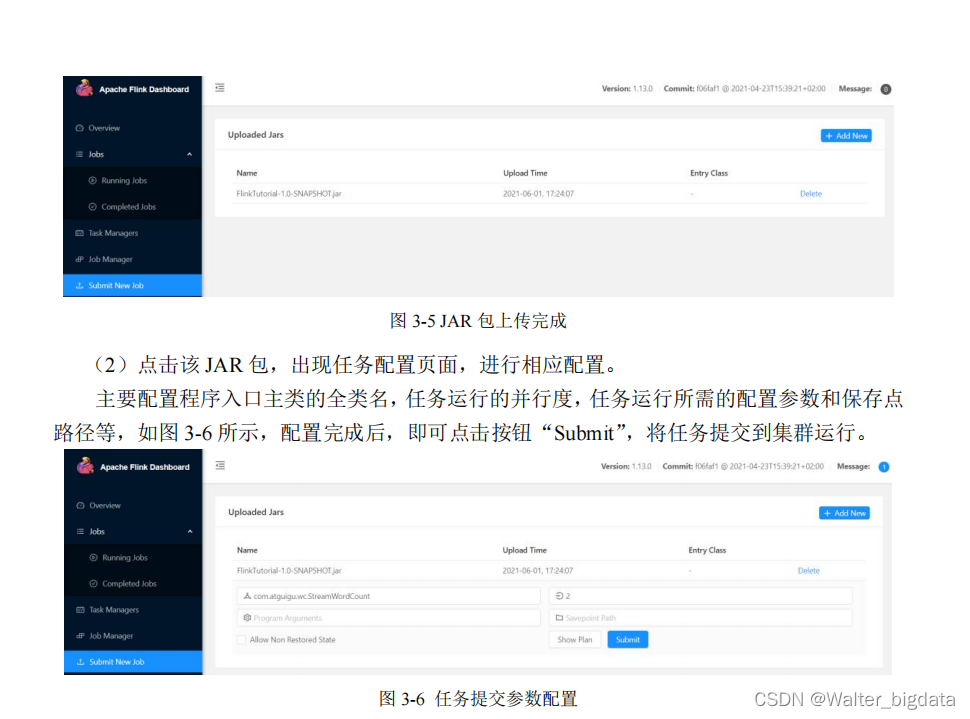
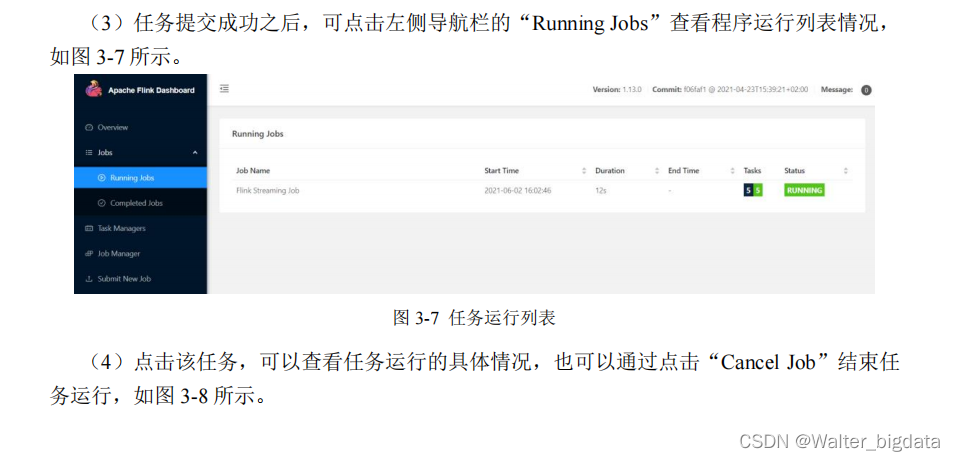
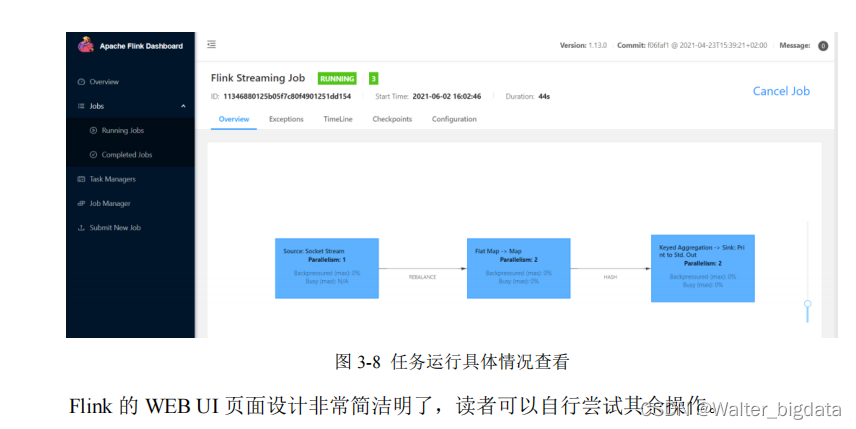
3.命令行提交作业
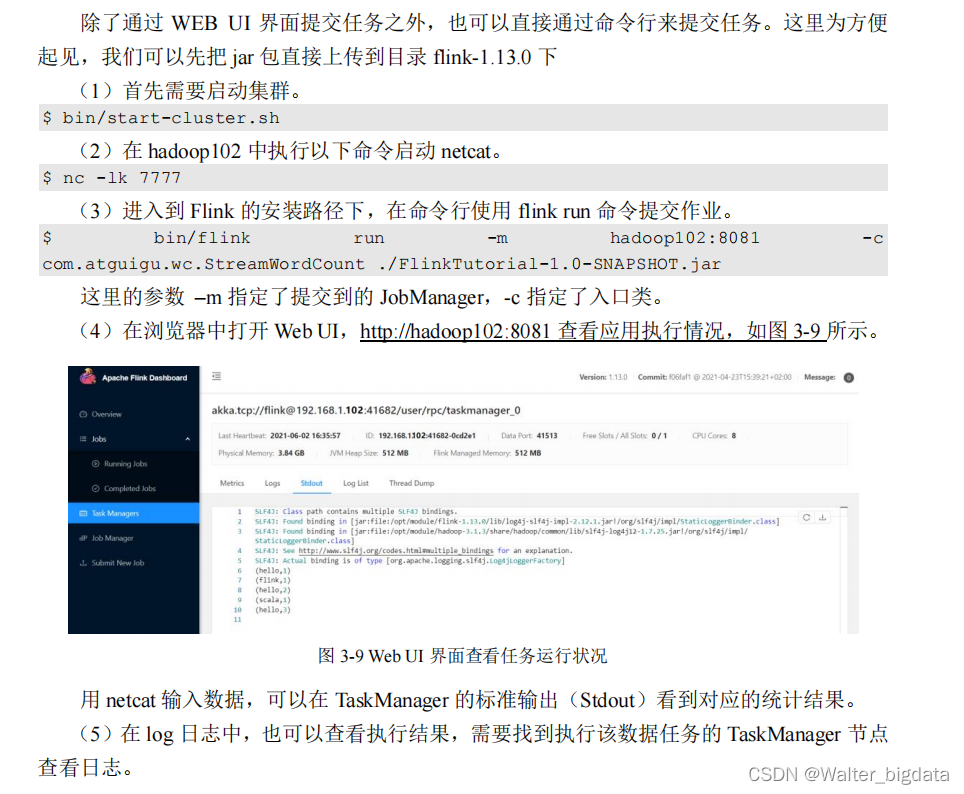
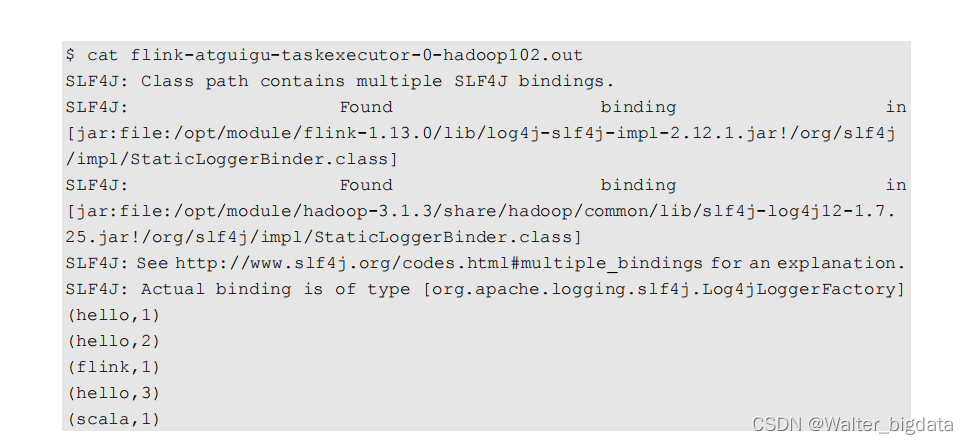
命令提交任务

命令取消任务

3.2 部署模式
3.2.1 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中
通过客户端提交作业,如图 3-10 所示。集群启动时所有资源就都已经确定,所以所有提交的
作业会竞争集群中的资源。
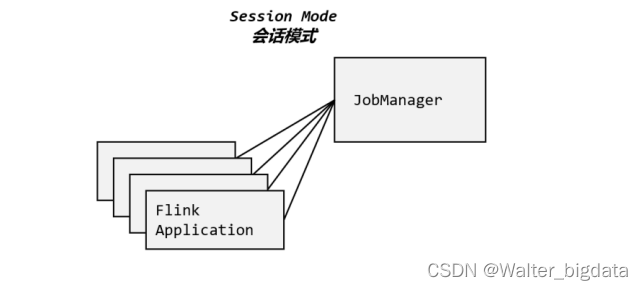

3.2.2 单作业模式(Per-Job Mode)
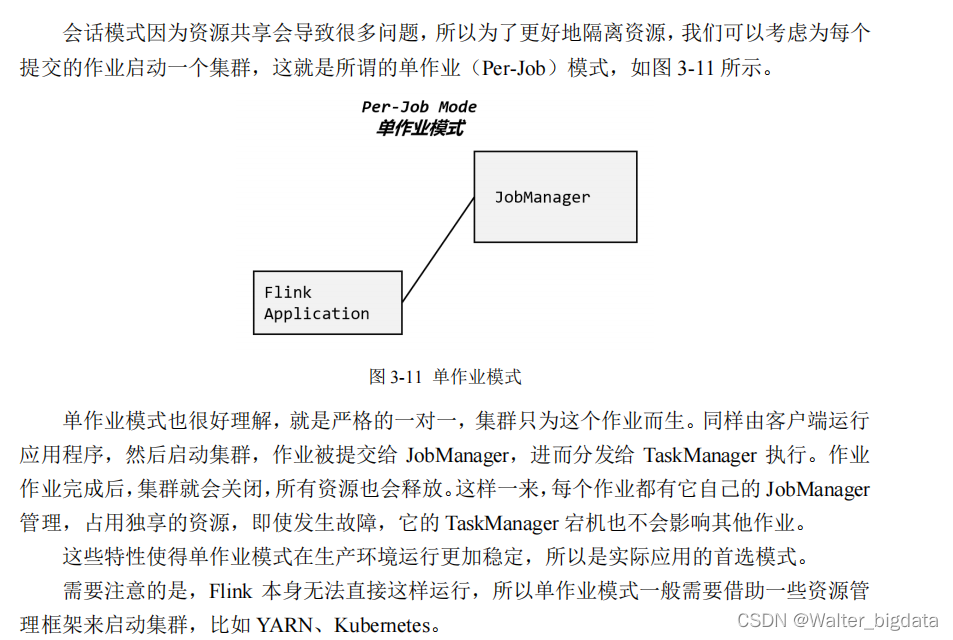
3.2.3 应用模式(Application Mode)
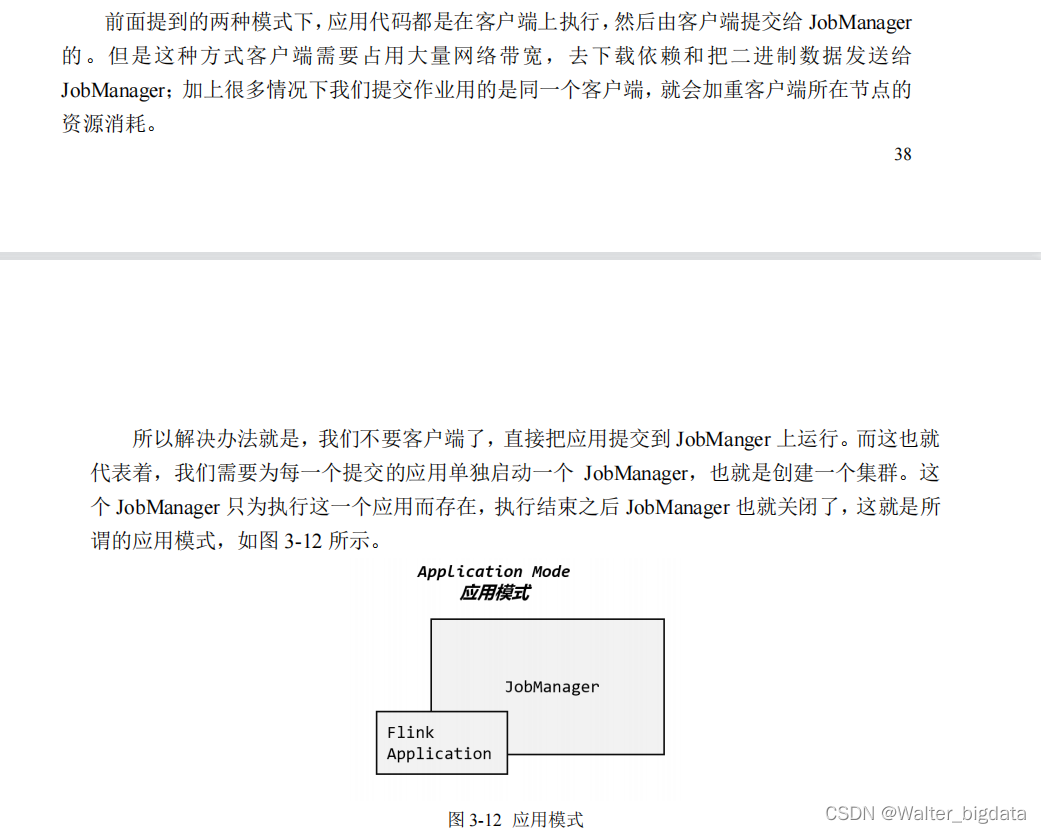

3.3 独立模式(Standalone)

3.3.1 会话模式部署
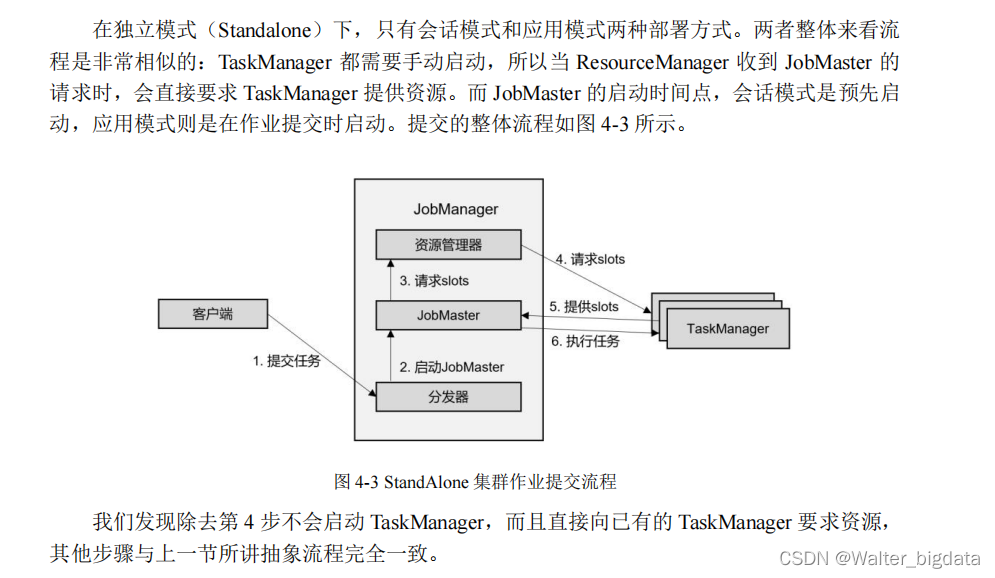
可以发现,独立模式的特点是不依赖外部资源管理平台,而会话模式的特点是先启动集群、
后提交作业。所以,我们在第 3.1 节用的就是独立模式(Standalone)的会话模式部署。
3.3.2 单作业模式部署
在 3.2.2 节中我们提到,Flink 本身无法直接以单作业方式启动集群,一般需要借助一些资
源管理平台。所以 Flink 的独立(Standalone)集群并不支持单作业模式部署。
3.3.3 应用模式部署(使用很少 )
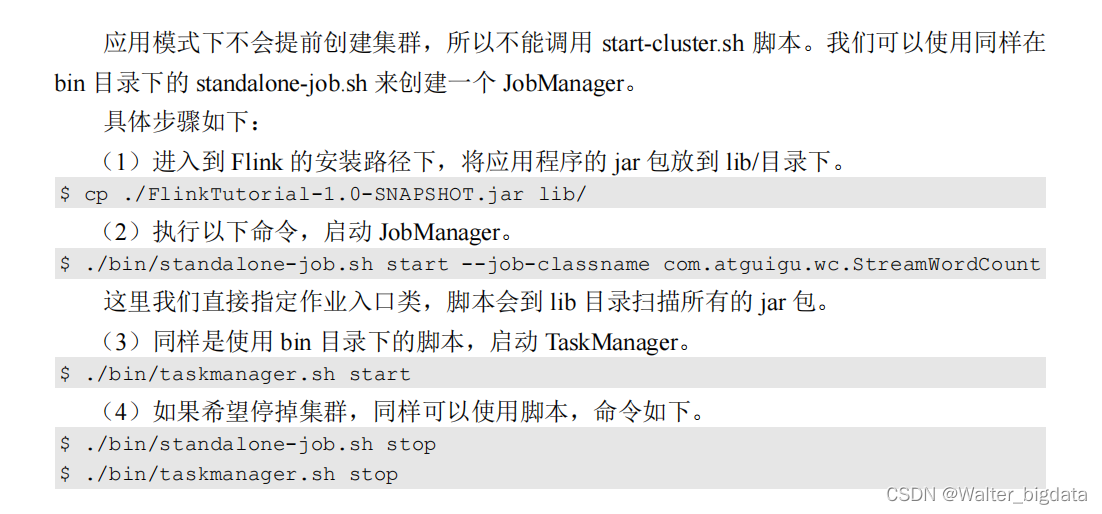
3.3.4 高可用(High Availability )



3.4 YARN 模式 **
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他
第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资源
调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架
集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。所
以接下来我们就将学习,在强大的 YARN 平台上 Flink 是如何集成部署的。
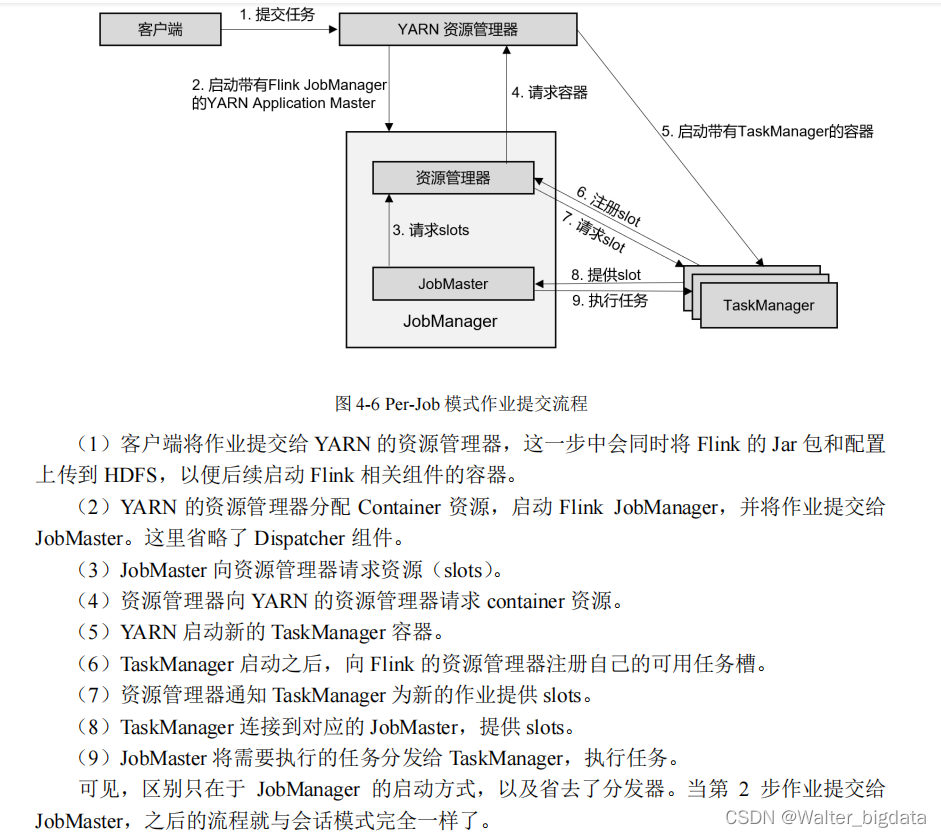
整体来说,YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager,
Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署
JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业
所需要的 Slot 数量动态分配 TaskManager 资源。
3.4.1 相关准备和配置
在 Flink1.8.0 之前的版本,想要以 YARN 模式部署 Flink 任务时,需要 Flink 是有 Hadoop
支持的。从 Flink 1.8 版本开始,不再提供基于 Hadoop 编译的安装包,若需要 Hadoop 的环境
支持,需要自行在官网下载 Hadoop 相关版本的组件 flink-shaded-hadoop-2-uber-2.7.5-10.0.jar,
并将该组件上传至 Flink 的 lib 目录下。在 Flink 1.11.0 版本之后,增加了很多重要新特性,其
中就包括增加了对Hadoop3.0.0以及更高版本Hadoop的支持,不再提供“flink-shaded-hadoop-*”
jar 包,而是通过配置环境变量完成与 YARN 集群的对接。
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有 Hadoop,保证 Hadoop
版本至少在 2.2 以上,并且集群中安装有 HDFS 服务。
具体配置步骤如下:
(1)按照 3.1 节所述,下载并解压安装包,并将解压后的安装包重命名为 flink-1.13.0-yarn,
本节的相关操作都将默认在此安装路径下执行。
(2)配置环境变量,增加环境变量配置如下:
$ sudo vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath` **
这里必须保证设置了环境变量 HADOOP_CLASSPATH。
(3)启动 Hadoop 集群,包括 HDFS 和 YARN。
[atguigu@hadoop102 ~]$ start-dfs.sh
[atguigu@hadoop103 ~]$ start-yarn.sh

3.4.2 会话模式部署
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN session)
来启动 Flink 集群。具体步骤如下:
1.启动集群
(1)启动 hadoop 集群(HDFS, YARN)。
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
$ bin/yarn-session.sh -nm test


3.4.3 单作业模式部署
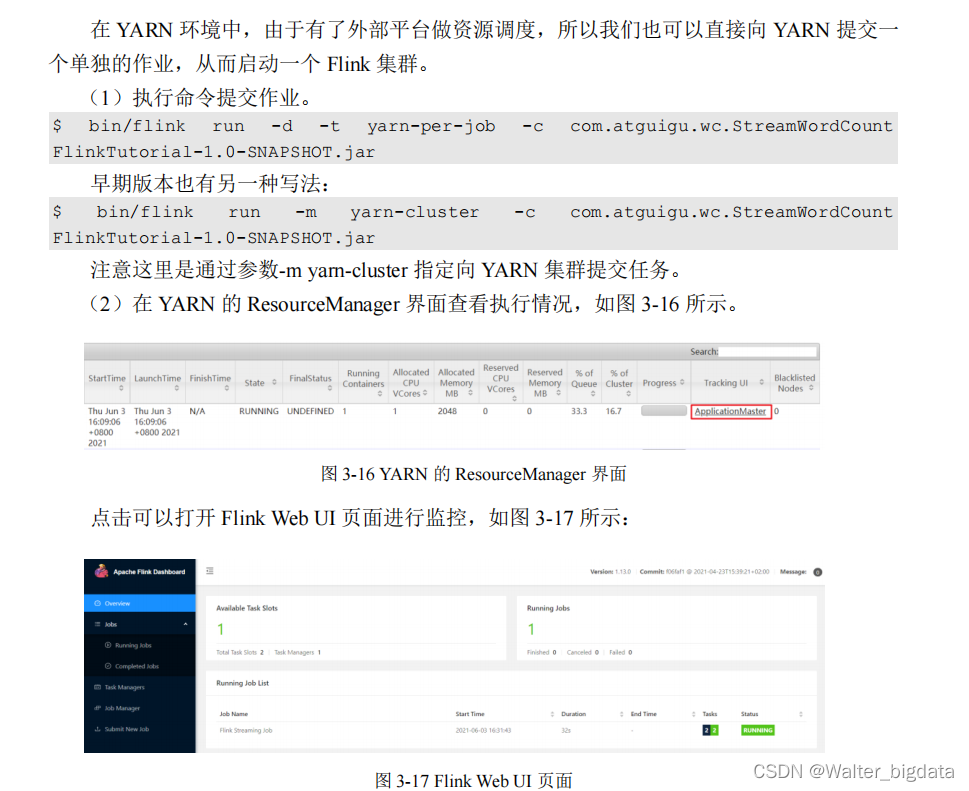
3.4.4 应用模式部署
3.4.5 高可用

3.5 K8S 模式
容器化部署是如今业界流行的一项技术,基于 Docker 镜像运行能够让用户更加方便地对
应用进行管理和运维。容器管理工具中最为流行的就是 Kubernetes(k8s),而 Flink 也在最近
的版本中支持了 k8s 部署模式。基本原理与 YARN 是类似的,具体配置可以参见官网说明,
这里我们就不做过多讲解了。
3.6 本章总结

第四章 Flink运行时架构
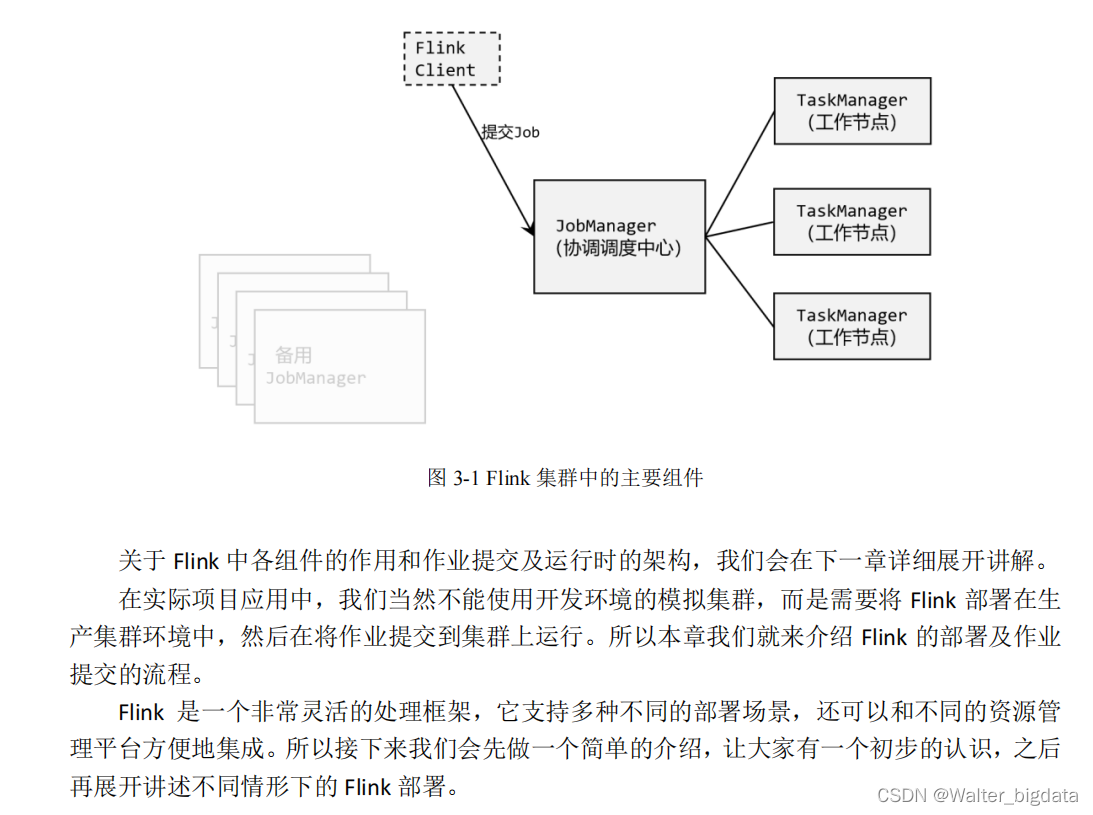
4.1 系统架构

4.1.1 整体构成
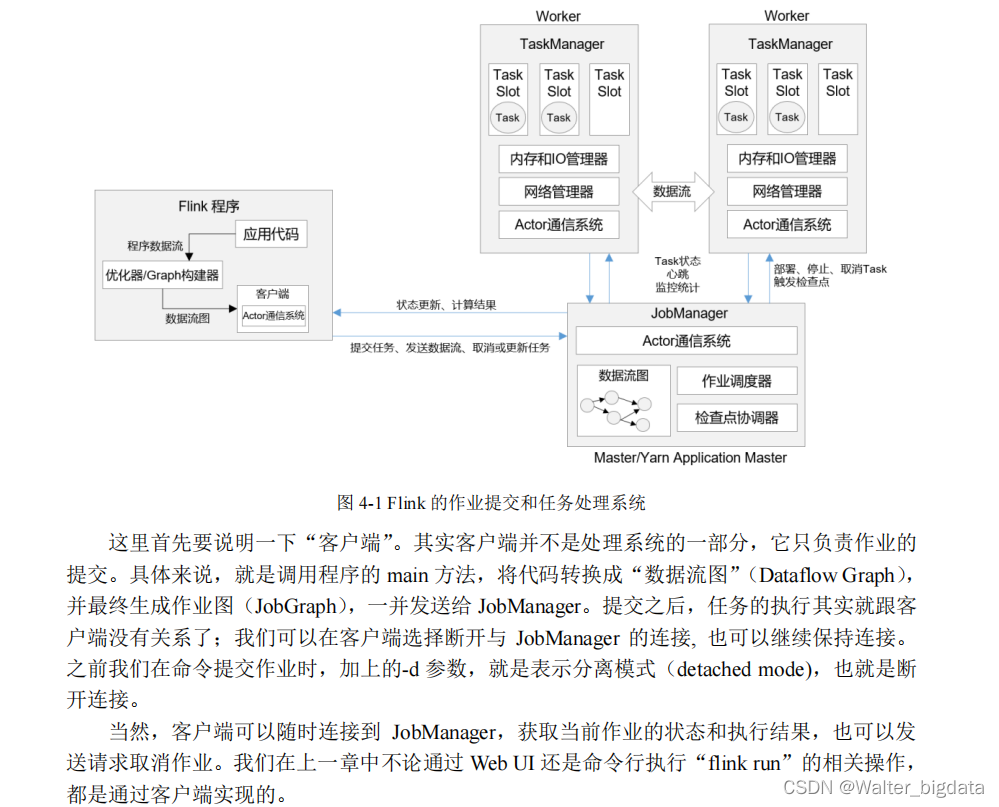
Flink 的运行时架构中,最重要的就是两大组件:作业管理器(JobManger)和任务管理器
(TaskManager)。对于一个提交执行的作业,JobManager 是真正意义上的“管理者”(Master),
负责管理调度,所以在不考虑高可用的情况下只能有一个;而 TaskManager 是“工作者”
(Worker、Slave),负责执行任务处理数据,所以可以有一个或多个。Flink 的作业提交和任务
处理时的系统如图 4-1 所示

4.1.2 作业管理器(JobManager)
JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。也就
是说,每个应用都应该被唯一的 JobManager 所控制执行。当然,在高可用(HA)的场景下,
可能会出现多个 JobManager;这时只有一个是正在运行的领导节点(leader),其他都是备用
节点(standby)。
JobManger 又包含 3 个不同的组件,下面我们一一讲解。



4.1.3 任务管理器(TaskManager)

4.2 作业提交流程
4.2.1 高层级抽象视角
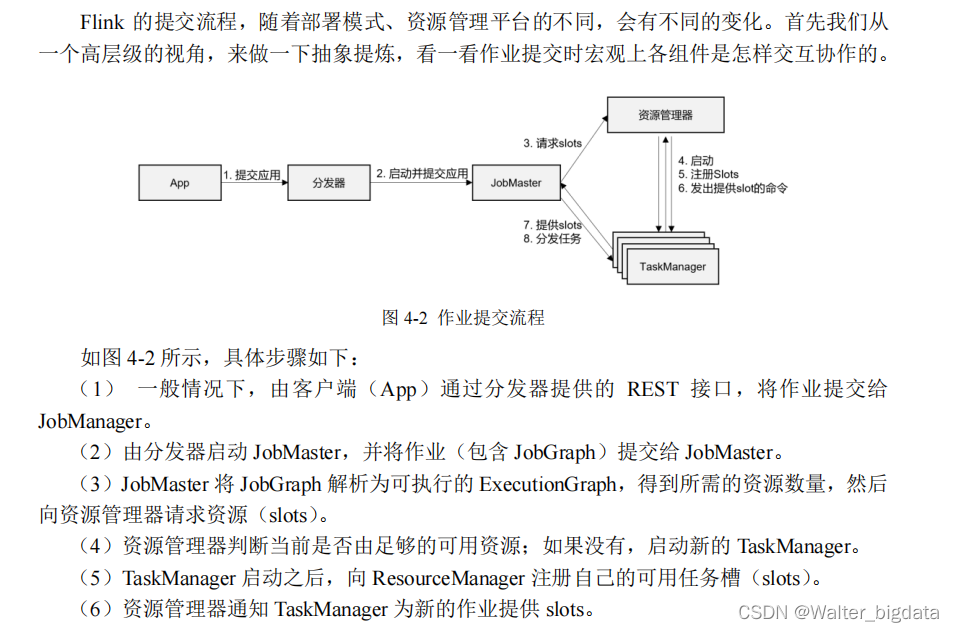

4.2.2 独立模式(Standalone)
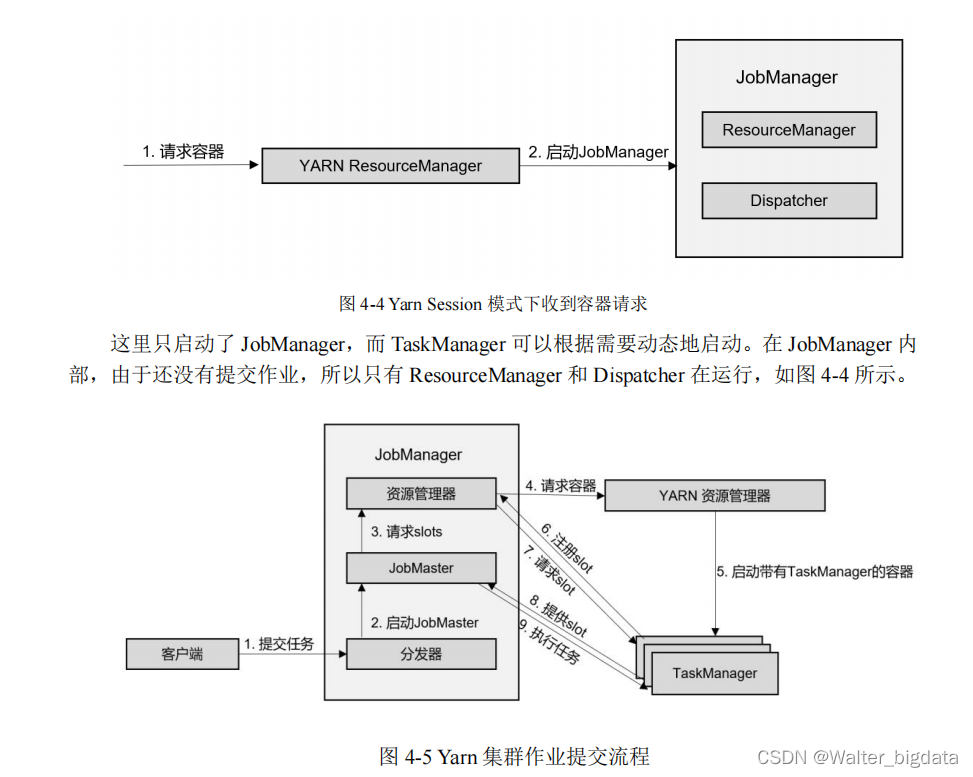
4.2.3 YARN 集群 **
1.会话(Session)模式
在会话模式下,我们需要先启动一个 YARN session,这个会话会创建一个 Flink 集群。

2.单作业(Per-Job)模式
在单作业模式下,Flink 集群不会预先启动,而是在提交作业时,才启动新的 JobManager。
4.3 一些重要概念
我们现在已经了解 Flink 运行时的核心组件和整体架构,也明白了不同场景下作业提交的
具体流程。但有些细节还需要进一步思考:一个具体的作业,是怎样从我们编写的代码,转换
成 TaskManager 可以执行的任务的呢?JobManager 收到提交的作业,又是怎样确定总共有多
少任务、需要多少资源呢?接下来我们就从一些重要概念入手,对这些问题做详细的展开讲解。
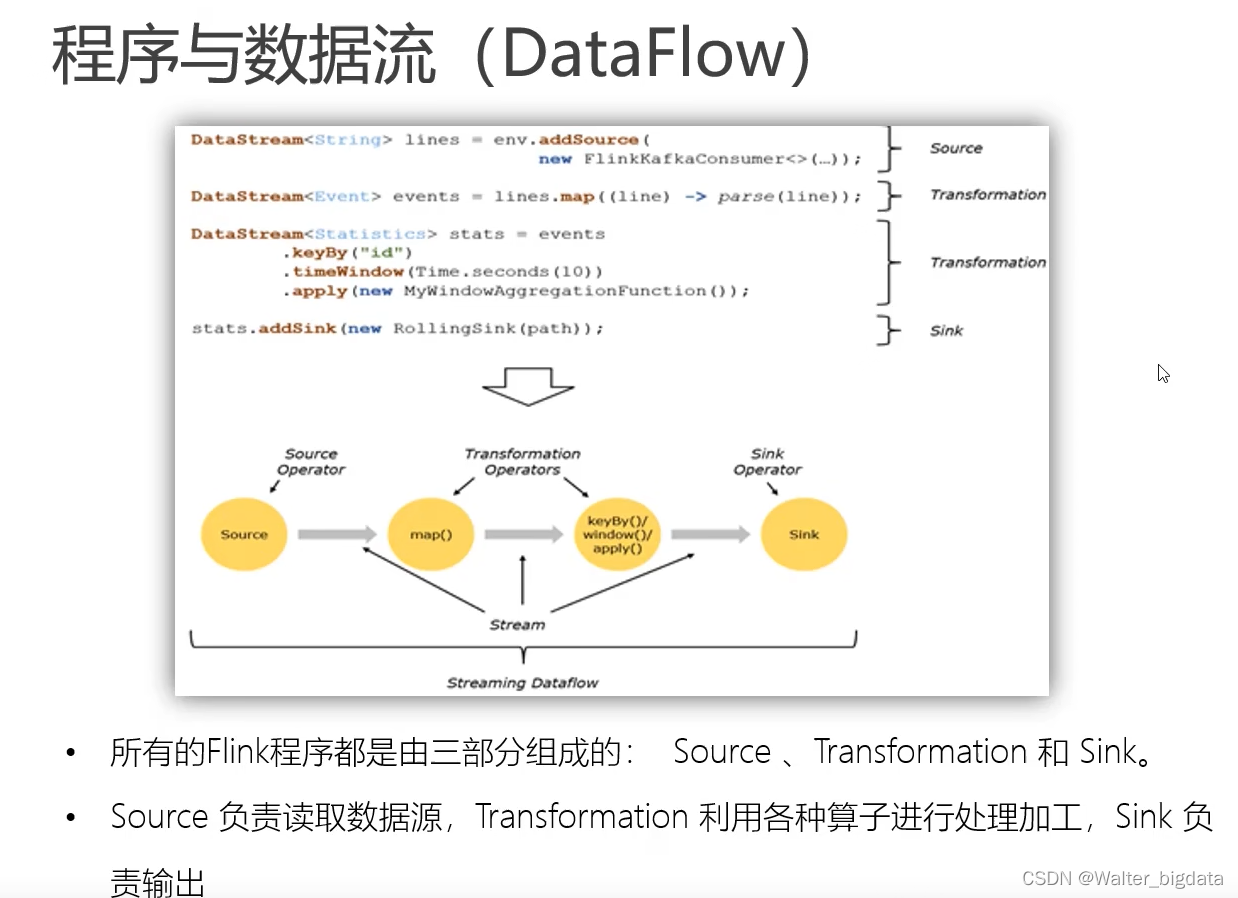
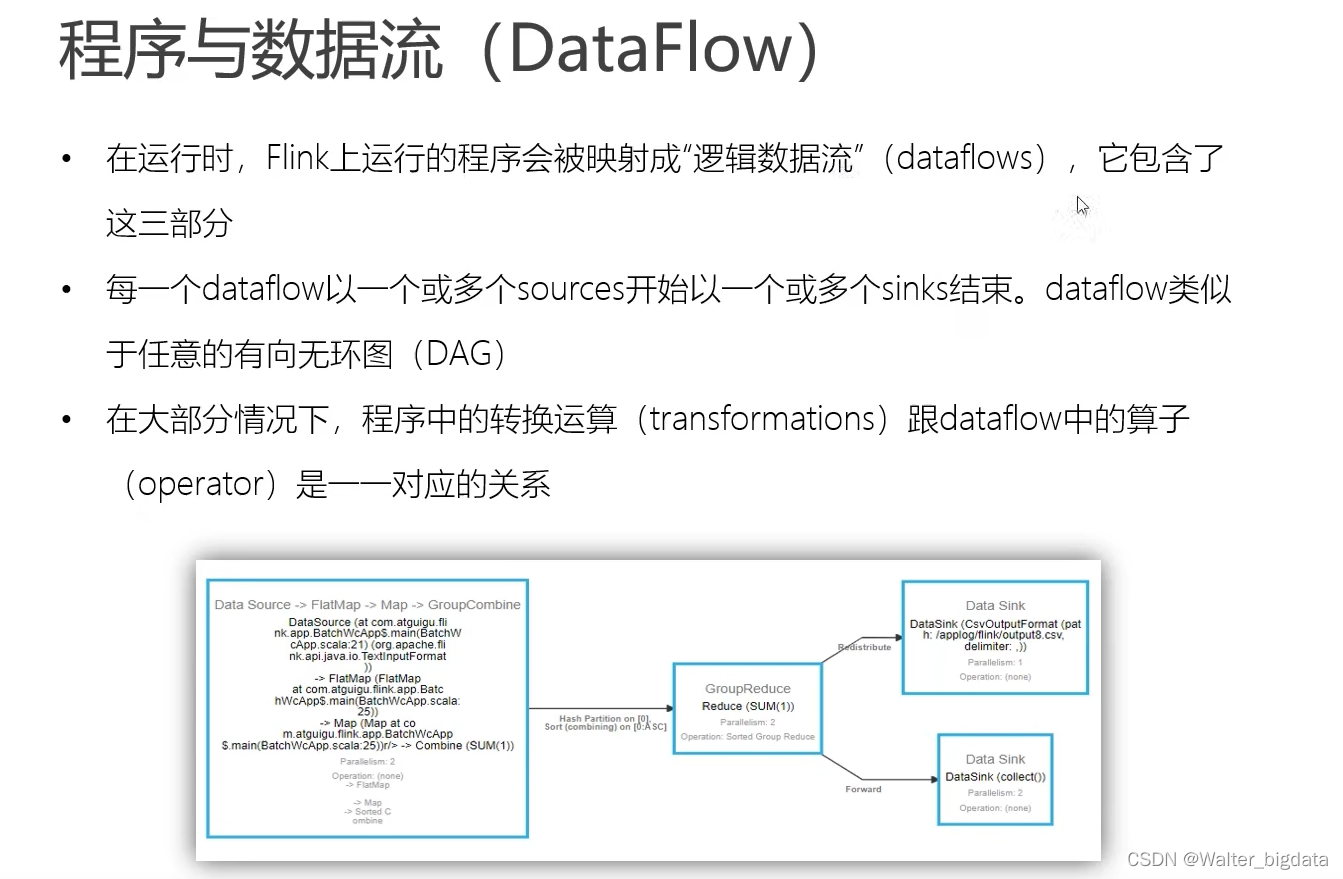
4.3.1 数据流图(Dataflow Graph)
Flink 是流式计算框架。它的程序结构,其实就是定义了一连串的处理操作,每一个数据
输入之后都会依次调用每一步计算。在 Flink 代码中,我们定义的每一个处理转换操作都叫作
“算子”(Operator),所以我们的程序可以看作是一串算子构成的管道,数据则像水流一样有序
地流过。比如在之前的 WordCount 代码中,基于执行环境调用的 socketTextStream()方法,就
是一个读取文本流的算子;而后面的 flatMap()方法,则是将字符串数据进行分词、转换成二
元组的算子。


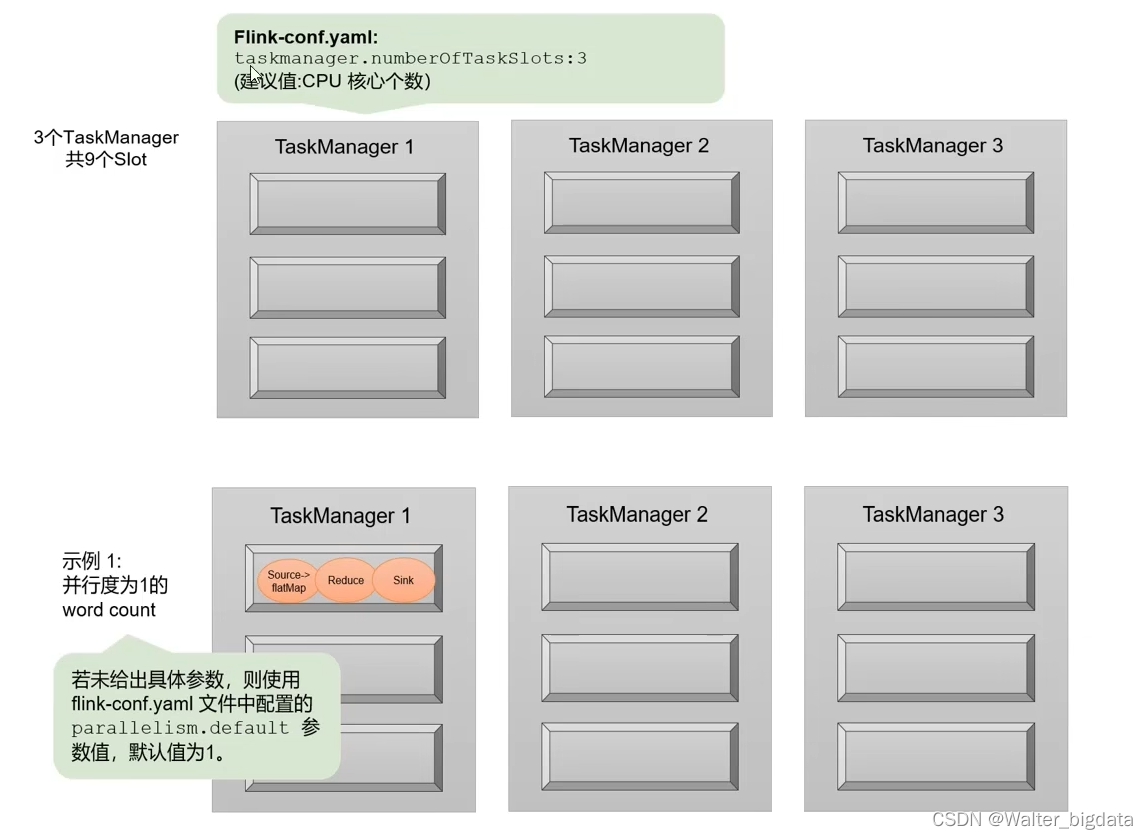
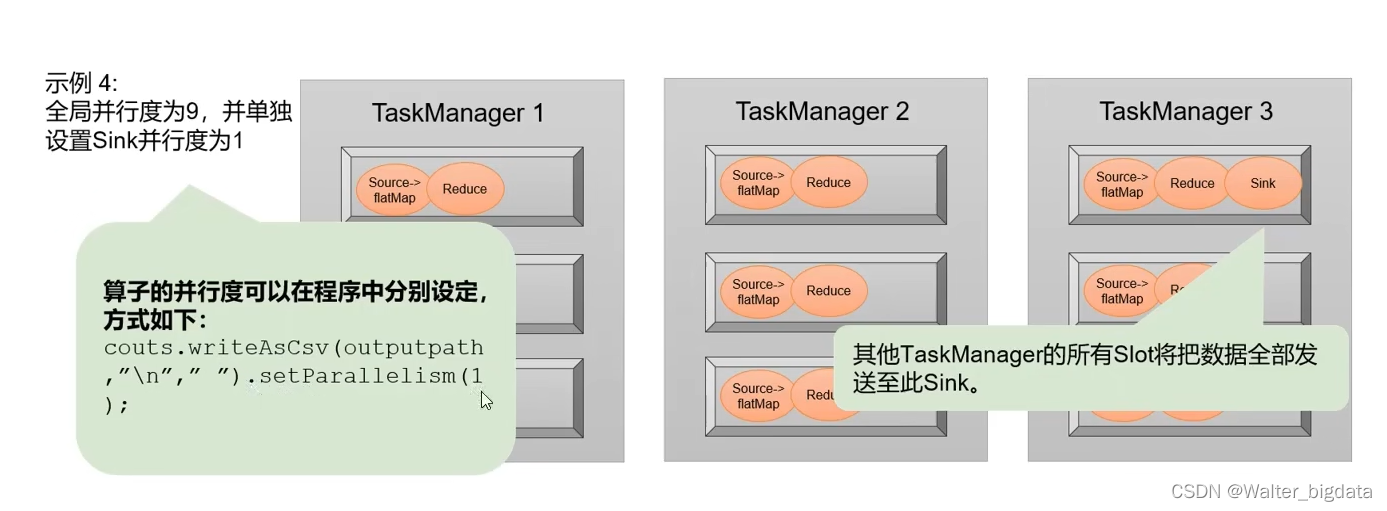
4.3.2 并行度(Parallelism)
1. 什么是并行计算

2.并行子任务和并行度
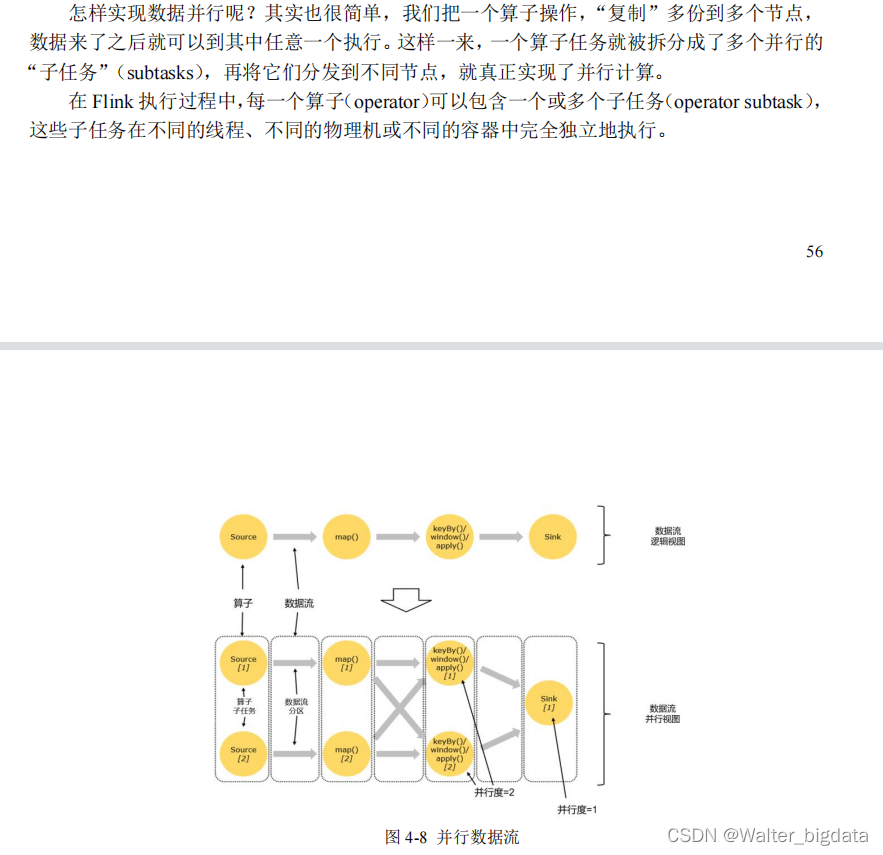

3. 并行度的设置
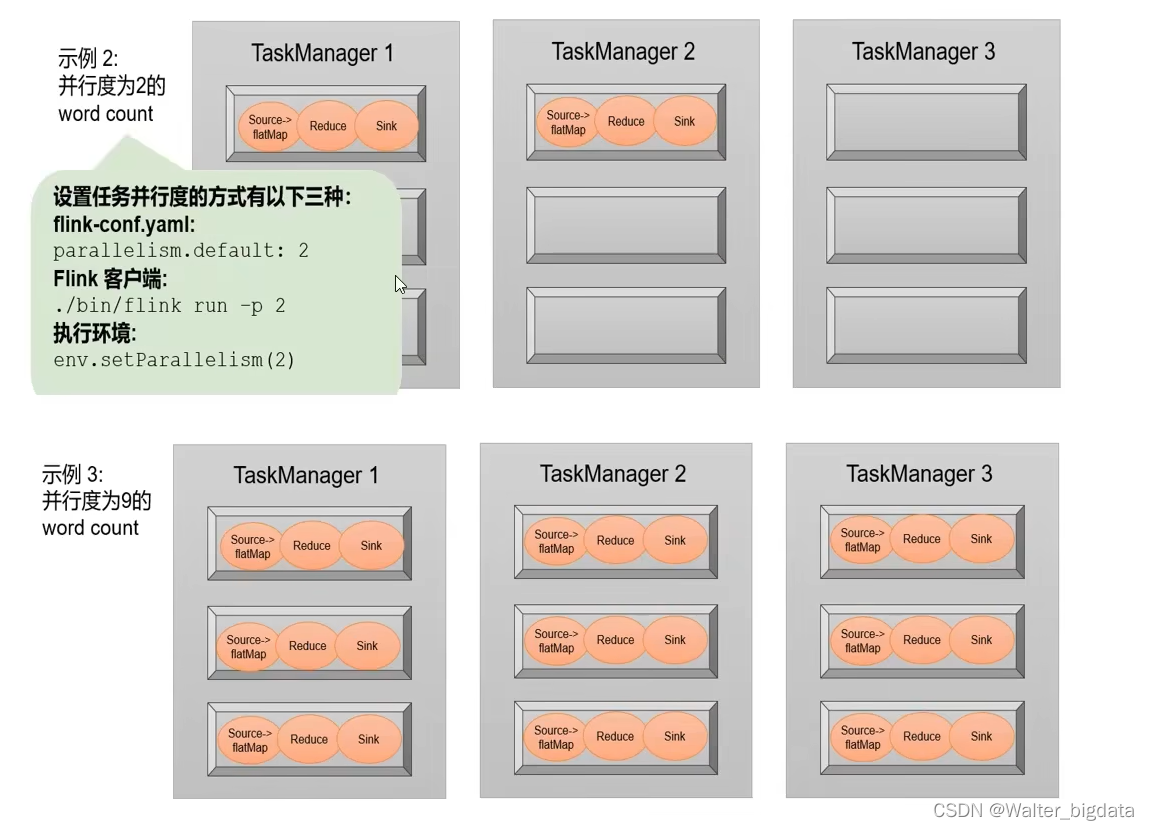
1.代码中设置
2.提交应用时设置
3.配置文件中设置
我们可以总结一下所有的并行度设置方法,它们的优先级如下:
(1)对于一个算子,首先看在代码中是否单独指定了它的并行度,这个特定的设置优先级
最高,会覆盖后面所有的设置。
(2)如果没有单独设置,那么采用当前代码中执行环境全局设置的并行度。
(3)如果代码中完全没有设置,那么采用提交时-p 参数指定的并行度。
(4)如果提交时也未指定-p 参数,那么采用集群配置文件中的默认并行度。
这里需要说明的是,算子的并行度有时会受到自身具体实现的影响。比如之前我们用到的
读取 socket 文本流的算子 socketTextStream,它本身就是非并行的 Source 算子,所以无论怎么
设置,它在运行时的并行度都是 1,对应在数据流图上就只有一个并行子任务。这一点大家可
以自行在 Web UI 上查看验证。
那么实践中怎样设置并行度比较好呢?那就是在代码中只针对算子设置并行度,不设置全
局并行度,这样方便我们提交作业时进行动态扩容。
4.3.3 算子链(Operator Chain)
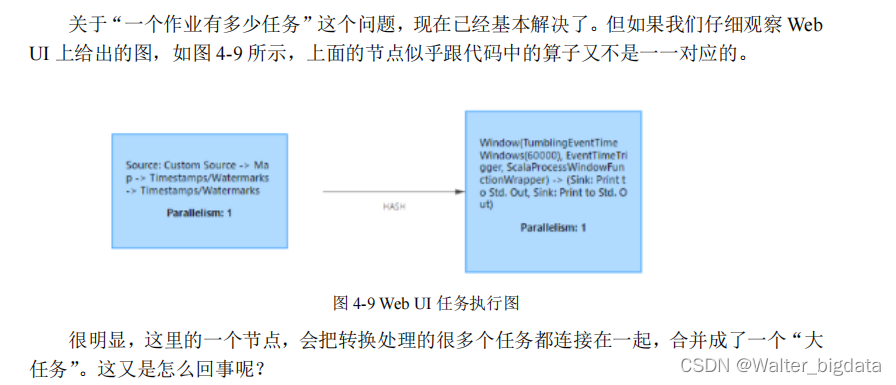
1. 算子间的数据传输
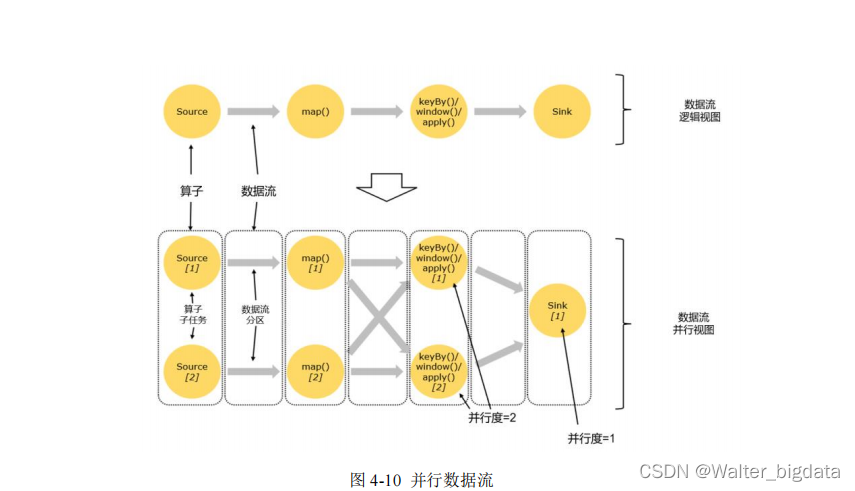

2. 合并算子链
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个
“大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如图 4-11 所示。每个 task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
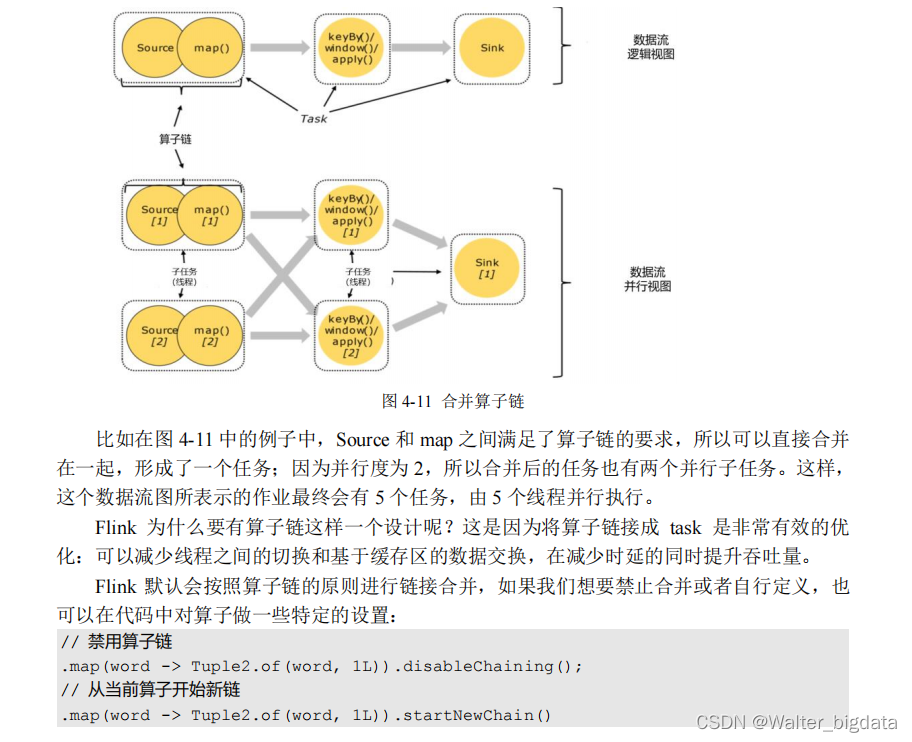
总结:并行度相同并且满足one-to-one直通传输模式既可以合并算子变成一个任务
4.3.4 作业图(JobGraph)与执行图(ExecutionGraph)

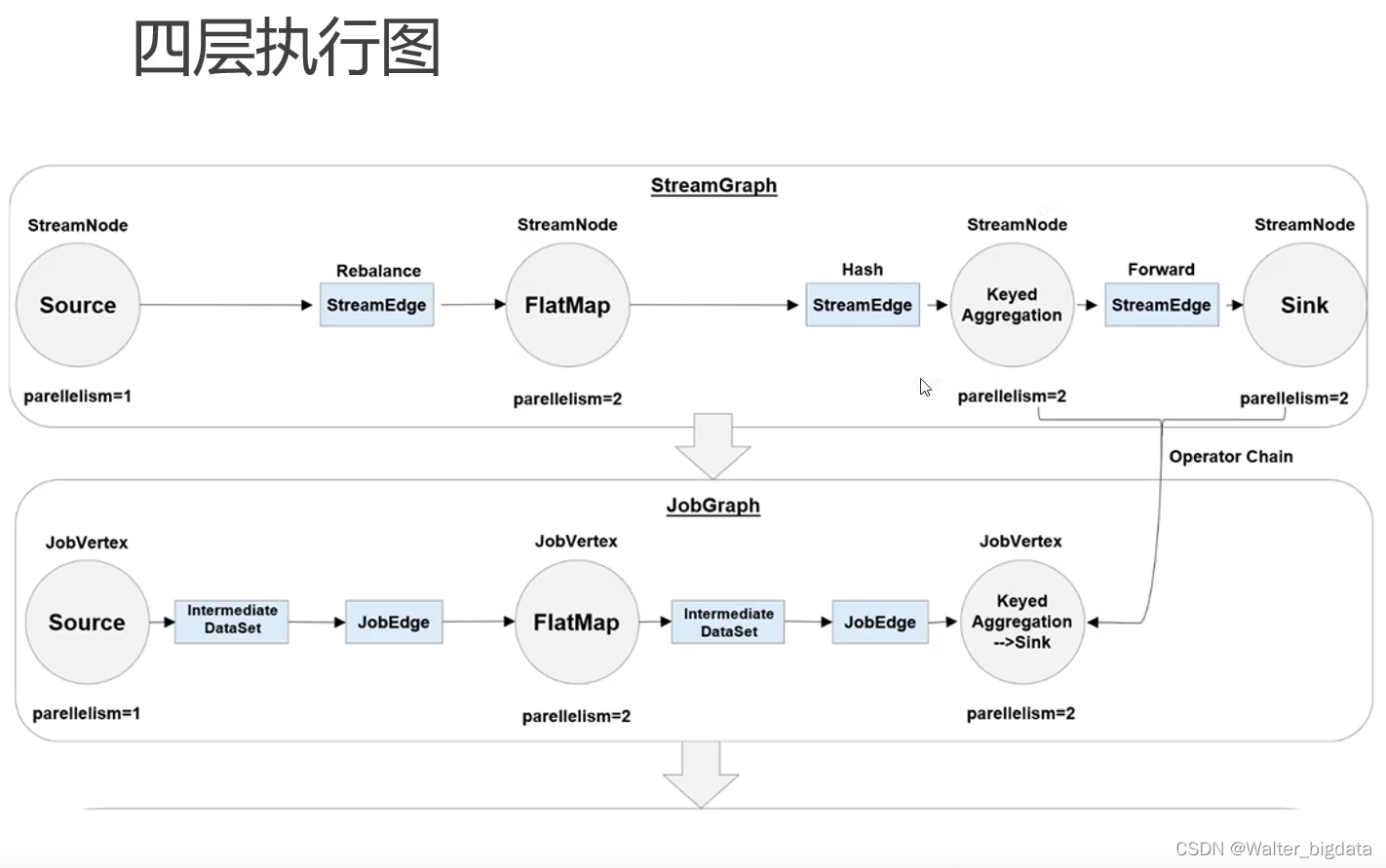
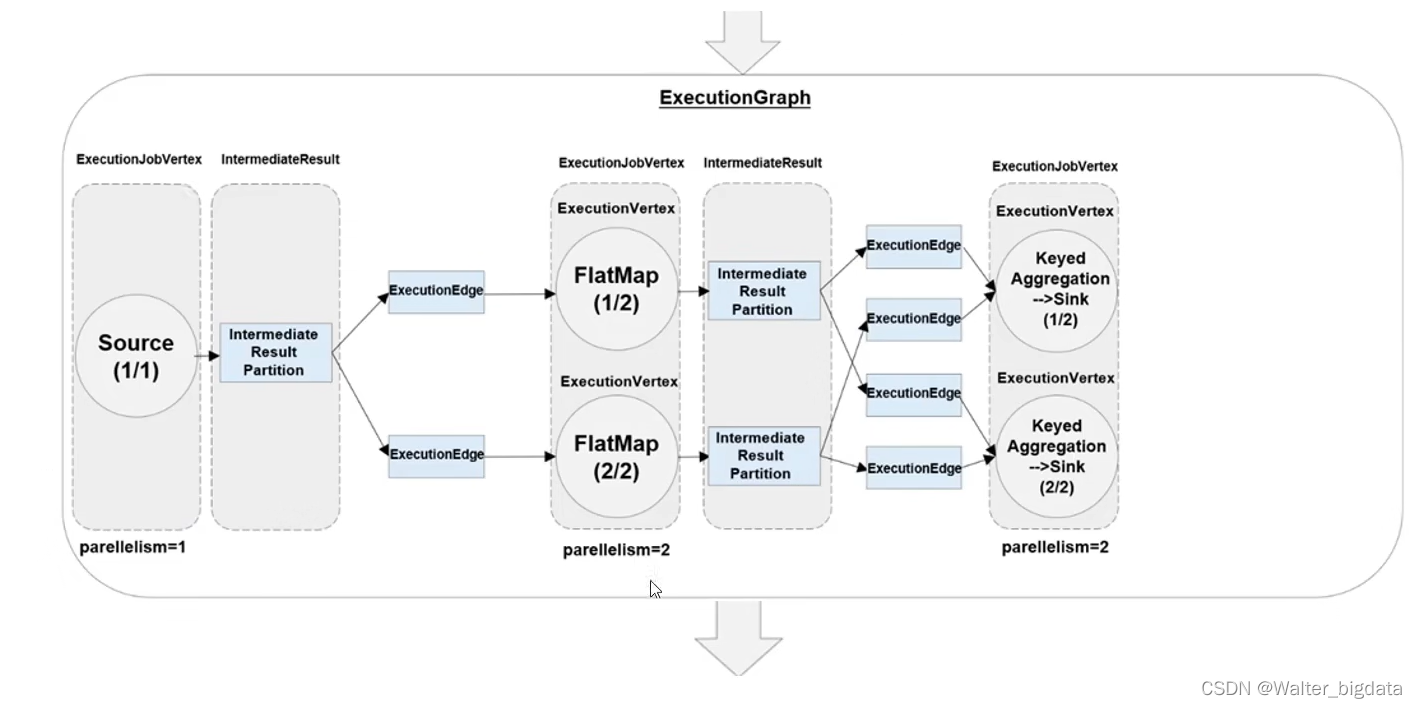
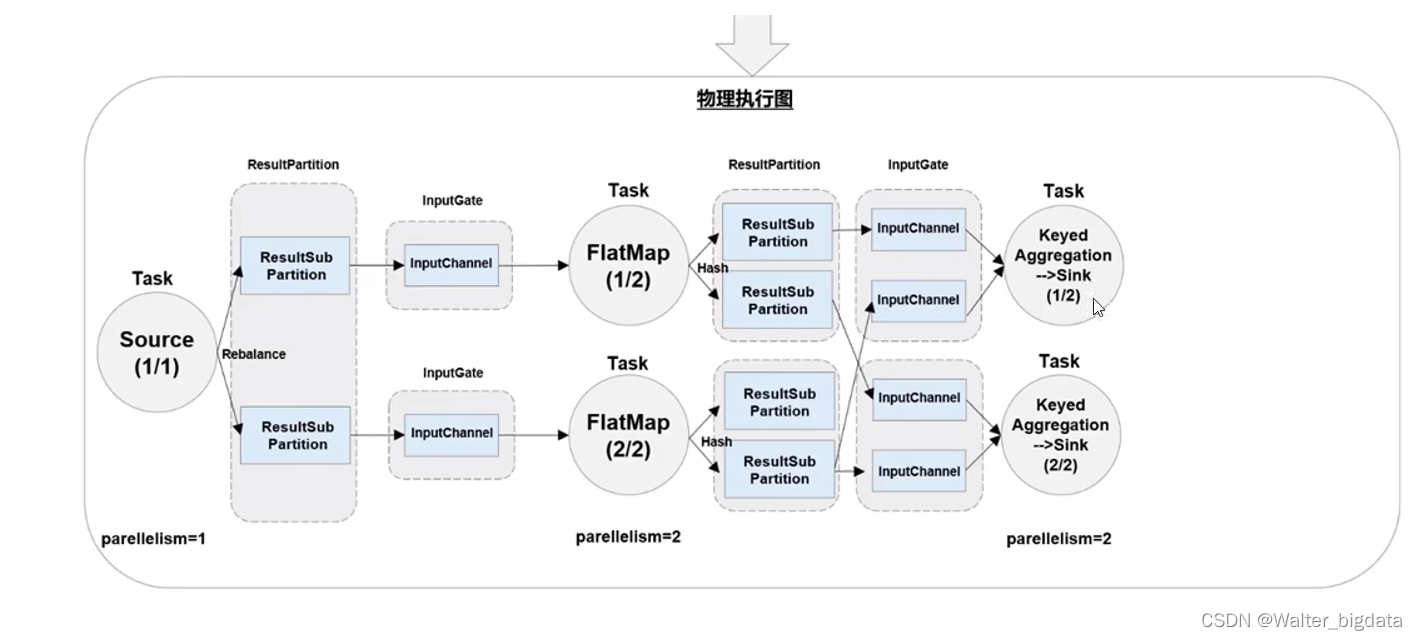
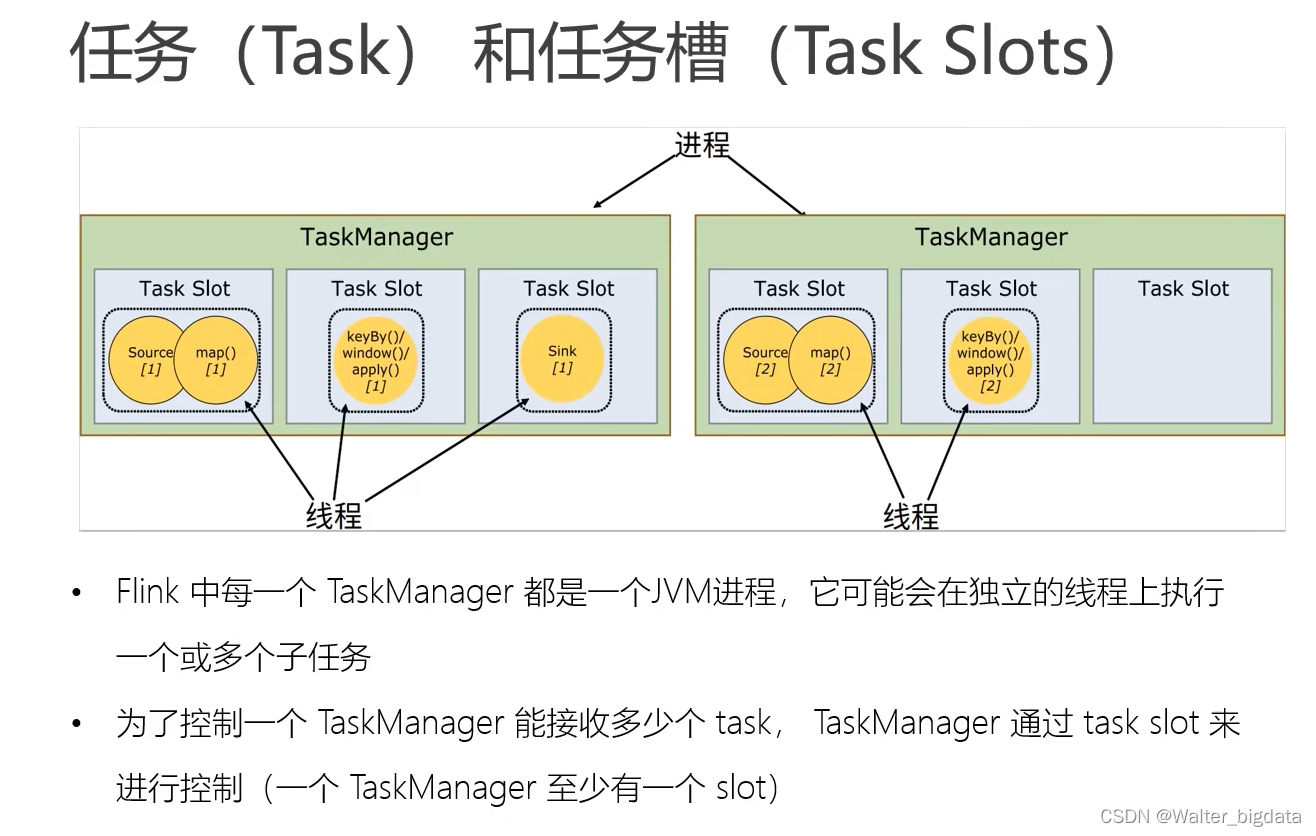
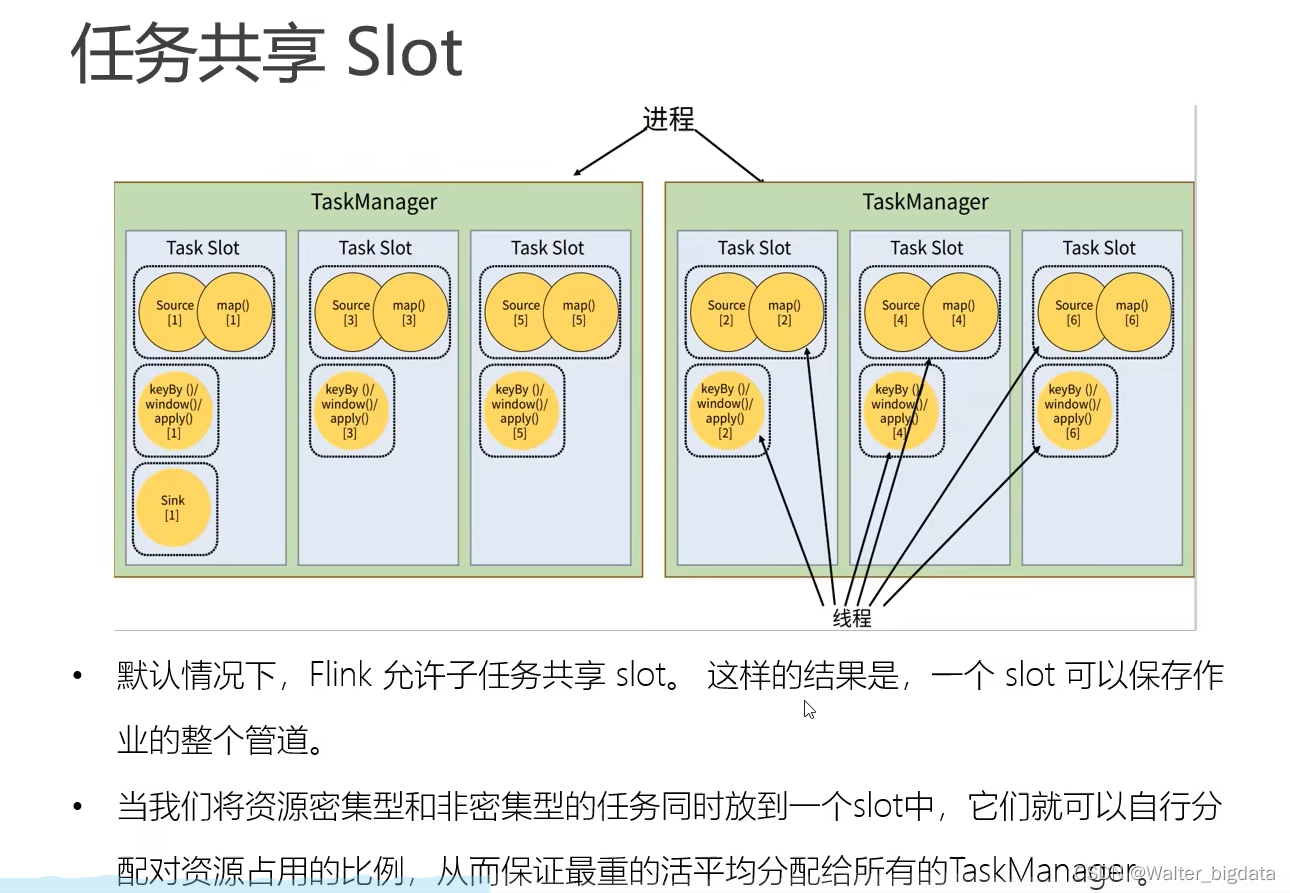
4.3.5 任务(Tasks)和任务槽(Task Slots)
通过前几小节的介绍,我们对任务的生成和分配已经非常清楚了。上一小节中我们最终得
到结论:作业划分为 5 个并行子任务,需要 5 个线程并行执行。那在我们将应用提交到 Flink
集群之后,到底需要占用多少资源呢?是否需要 5 个 TaskManager 来运行呢?

例子















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









