






1. 朴素贝叶斯算法
1.1 基本原理
朴素贝叶斯(Naive Bayes)分类器是一种基于贝叶斯定理并假设特征之间相互独立的概率分类模型。它的核心思想是:在已知某个数据点的各个特征的情况下,计算它属于某个类别的概率,从而进行分类。
朴素贝叶斯模型之所以被称为“朴素”,是因为它作出了一个很强的假设——所有特征之间是条件独立的。虽然这个假设在实际数据中往往不成立,但朴素贝叶斯在很多实际应用中却表现得相当不错,尤其是在文本分类、垃圾邮件识别等领域。
这背后的基础就是贝叶斯定理:
P ( C ∣ X ) = P ( X ∣ C ) ⋅ P ( C ) P ( X ) P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)} P(C∣X)=P(X)P(X∣C)⋅P(C)
其中:
- P ( C ∣ X ) P(C|X) P(C∣X):在特征 X X X 条件下属于类别 C C C 的后验概率
- P ( X ∣ C ) P(X|C) P(X∣C):在类别 C C C 条件下观察到特征 X X X 的似然
- P ( C ) P(C) P(C):类别 C C C 出现的先验概率
- P ( X ) P(X) P(X):特征 X X X 出现的边际概率,在分类时通常可以忽略(因为对所有类别都是一样的)
1.2 公式推导
假设有一个样本 X = ( x 1 , x 2 , . . . , x n ) X = (x_1, x_2, ..., x_n) X=(x1,x2,...,xn),每个 x i x_i xi 是一个特征值。我们希望计算该样本属于每个类别 C k C_k Ck 的概率,并选择概率最大的类别作为预测结果。
(1)先验概率(Prior Probability)
P ( C k ) = 训练集中类别为 C k 的样本数 训练集中样本总数 P(C_k) = \frac{\text{训练集中类别为 } C_k \text{ 的样本数}}{\text{训练集中样本总数}} P(Ck)=训练集中样本总数训练集中类别为 Ck 的样本数
表示某个类别在训练集中的比例。
(2)条件概率(Likelihood)
由于特征之间条件独立,整体的条件概率可以写成各个特征条件概率的乘积:
P ( X ∣ C k ) = ∏ i = 1 n P ( x i ∣ C k ) P(X|C_k) = \prod_{i=1}^n P(x_i | C_k) P(X∣Ck)=i=1∏nP(xi∣Ck)
即在类别 C k C_k Ck 条件下,各个特征 x i x_i xi 同时出现的概率等于它们分别出现的概率的乘积。
(3) 后验概率(Posterior Probability)
最终我们根据贝叶斯定理有:
P ( C k ∣ X ) = P ( C k ) ⋅ ∏ i = 1 n P ( x i ∣ C k ) P ( X ) P(C_k | X) = \frac{P(C_k) \cdot \prod_{i=1}^n P(x_i | C_k)}{P(X)} P(Ck∣X)=P(X)P(Ck)⋅∏i=1nP(xi∣Ck)
因为 P ( X ) P(X) P(X) 对所有类别都是一样的,我们只需比较分子部分:
C ^ = arg max C k [ P ( C k ) ⋅ ∏ i = 1 n P ( x i ∣ C k ) ] \hat{C} = \arg\max_{C_k} \left[ P(C_k) \cdot \prod_{i=1}^n P(x_i | C_k) \right] C^=argCkmax[P(Ck)⋅i=1∏nP(xi∣Ck)]
这就是朴素贝叶斯分类器的预测公式。
1.3 算法优势与局限性
优点:
- 简单高效:训练和预测速度快,适合大规模数据集。
- 对小数据集友好:不依赖大量数据,也能有不错表现。
- 可解释性强:概率模型,输出可以直接理解为属于某类别的概率。
- 在文本分类中效果优异:如垃圾邮件过滤、情感分析等。
缺点:
- 特征独立性假设不现实:在许多实际问题中,特征之间是相关的,这种假设会影响分类精度。
- 对数值特征不够灵活:原始朴素贝叶斯主要处理离散特征,连续特征需要额外处理(如高斯分布假设)。
- 容易受到零概率影响:如果某个特征值在训练集中未出现,会导致整个乘积为零,影响后验概率(需引入平滑技术解决)。
2. 西瓜数据集介绍
2.1 数据集描述
“西瓜数据集”是机器学习入门中一个非常经典的分类数据集,常用于讲解和实现基本的分类算法。该数据集通过若干个特征来描述西瓜的外观和内部质量,并据此判断是否为“好瓜”。
数据集中共有 17 个样本,每个样本包含如下特征:
- 色泽(如:青绿、乌黑、浅白)
- 根蒂(如:蜷缩、稍蜷、硬挺)
- 敲声(如:浊响、沉闷、清脆)
- 纹理(如:清晰、稍糊、模糊)
- 脐部(如:凹陷、稍凹、平坦)
- 触感(如:硬滑、软粘)
- 密度(浮点数,如:0.697)
- 含糖率(浮点数,如:0.460)
- 好瓜(类别标签,是 / 否)
其中前 6 个为离散特征,后 2 个为连续特征,最后一个为分类标签。
数据样例如下所示:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.481 | 0.149 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 软粘 | 0.245 | 0.057 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.343 | 0.099 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 否 |
| 14 | 浅白 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 平坦 | 软粘 | 0.360 | 0.370 | 否 |
| 16 | 浅白 | 蜷缩 | 沉闷 | 清晰 | 稍凹 | 硬滑 | 0.593 | 0.042 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 稍凹 | 硬滑 | 0.719 | 0.103 | 否 |
其中,以训练集中编号为 1 的样本为测试样本,其他16条样本为训练集:
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | ? |
2.2 数据预处理
在使用朴素贝叶斯算法之前,需要对数据进行适当的预处理,尤其是区分和处理好离散特征与连续特征:
(1)离散特征处理
对于“色泽、根蒂、敲声、纹理、脐部、触感”这些离散特征,可以使用频率统计法计算条件概率。
(2) 连续特征处理
“密度”和“含糖率”是数值型特征,朴素贝叶斯对连续特征的处理通常有两种方式:
- 离散化:将连续变量划分为若干个区间,转为分类特征
- 高斯假设(Gaussian Naive Bayes):假设特征值服从某个类别下的正态分布,计算概率密度函数值。
本项目中若使用离散化处理,可通过如下方式:
data['密度_bin'] = pd.cut(data['密度'], bins=[0, 0.4, 0.6, 0.8, 1], labels=['低', '中低', '中高', '高'])
data['含糖率_bin'] = pd.cut(data['含糖率'], bins=[0, 0.1, 0.25, 0.4, 0.5], labels=['低', '中低', '中高', '高'])
3. 朴素贝叶斯分类器实现步骤
步骤1:数据读取与准备
我们使用 Python 的 pandas 库读取西瓜数据集。
首先将前面整理好的16条样本构造成 DataFrame。
其中,数据样例中编号为 1 的样本作为测试数据,其余编号为 2~17 的样本作为训练数据。分类标签为“好瓜”一列,取值为“是”或“否”。
对于离散型特征(如色泽、根蒂、敲声、纹理、脐部、触感),我们直接统计频数进行建模;
对于连续型特征(如密度、含糖率),我们可以采用离散化处理后作为类别特征使用,也可以高斯分布估计进行处理。这里先采用离散化处理。
# 加载数据并进行离散化处理
def loadDataSet():
data = pd.DataFrame([
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']
], columns=['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率', '好坏'])
# 连续特征离散化
data['密度'] = pd.cut(data['密度'], bins=[0, 0.4, 0.6, 0.8, 1], labels=['低', '中低', '中高', '高'])
data['含糖率'] = pd.cut(data['含糖率'], bins=[0, 0.1, 0.25, 0.4, 0.5], labels=['低', '中低', '中高', '高'])
testSet = ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '中高', '高']
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率']
return data, testSet, labels
步骤2:计算先验概率
先验概率是指训练集中各类别(好瓜或坏瓜)的出现频率:
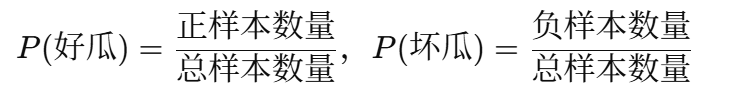
根据训练集(样本编号2-17)统计:
好瓜(是)共有 7 个样本
坏瓜(否)共有 9 个样本
因此: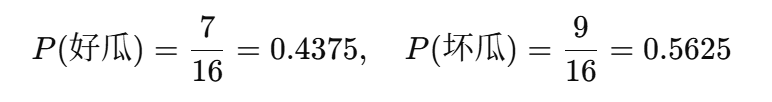
具体代码实现:
# 计算先验概率P(c)
def prior():
dataSet = loadDataSet()[0] # 载入数据集
countAll = len(dataSet)
countG = (dataSet['好坏'] == "好瓜").sum()
countB = (dataSet['好坏'] == "坏瓜").sum()
P_G = countG / countAll
P_B = countB / countAll
return P_G, P_B
# 测试
data, testSet, labels = loadDataSet()
P_G, P_B = prior()
print(f"好瓜的先验概率 P(好瓜) = {P_G:}")
print(f"坏瓜的先验概率 P(坏瓜) = {P_B:}")
运行结果:

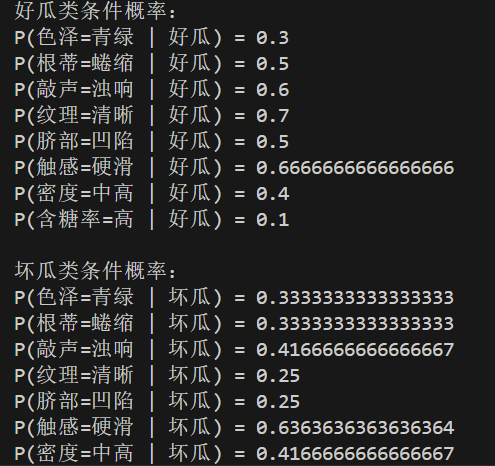
步骤3:计算条件概率
对于测试样本的每个特征,我们统计在训练集中,类别为“好瓜”或“坏瓜”条件下,各个特征值的出现频率。
例如:特征“色泽”为“青绿”
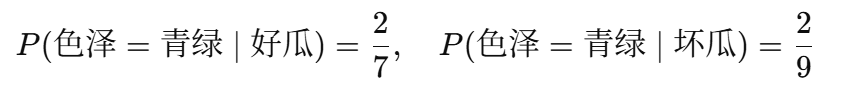
依此类推,计算其他所有特征的条件概率。
⚠️ 若某个特征值在某一类中从未出现,则条件概率为 0,会导致后验概率为 0,因此我们可使用拉普拉斯平滑避免该问题(详见后续第四部分)。
具体代码实现:
# 计算条件概率P(c|xi)
def P(index, cla):
dataSet, testSet, labels = loadDataSet() # 载入数据集
countG = sum(1 for _, row in dataSet.iterrows() if row['好坏'] == "好瓜")
countB = sum(1 for _, row in dataSet.iterrows() if row['好坏'] == "坏瓜")
lst = [
row for _, row in dataSet.iterrows()
if row['好坏'] == cla and row[labels[index]] == testSet[index]
]
denom = countG if cla == "好瓜" else countB
prob = len(lst) / denom if denom > 0 else 0
return prob
#运行测试
data, testSet, labels = loadDataSet()
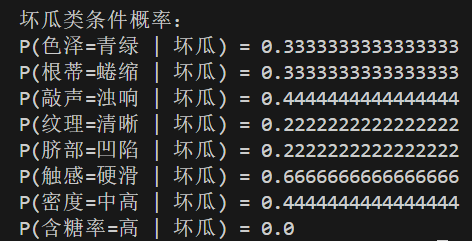
print("好瓜类条件概率:")
for i in range(len(labels)):
print(f"P({labels[i]}={testSet[i]} | 好瓜) =", P(i, "好瓜"))
print("\n坏瓜类条件概率:")
for i in range(len(labels)):
print(f"P({labels[i]}={testSet[i]} | 坏瓜) =", P(i, "坏瓜"))
运行结果:
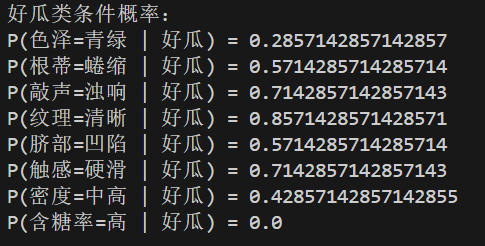
步骤4:分类预测
根据朴素贝叶斯公式:
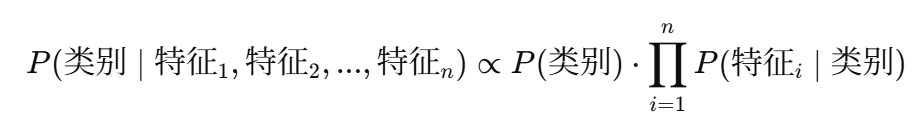
分别计算样本属于“好瓜”和“坏瓜”的后验概率:
对于“好瓜”类别:

对于“坏瓜”类别:

将上述所有条件概率代入,计算两个结果,比较其大小,概率更大的即为分类结果。
最终分类:
根据计算结果,如果:
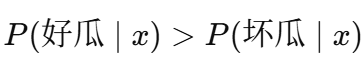
则判定为“好瓜”,否则为“坏瓜”。
在不使用平滑的情况下,该样本分类结果可能受“零概率”影响,因此推荐使用拉普拉斯平滑技术(详见第四部分)。
# 预测后验概率P(c|xi)
def bayes():
# 计算类先验概率
P_G, P_B = prior()
# 计算条件概率
P0_G = P(0, "好瓜") # P(青绿|好瓜)
P0_B = P(0, "坏瓜") # P(青绿|坏瓜)
P1_G = P(1, "好瓜") # P(蜷缩|好瓜)
P1_B = P(1, "坏瓜") # P(蜷缩|坏瓜)
P2_G = P(2, "好瓜") # P(浊响|好瓜)
P2_B = P(2, "坏瓜") # P(浊响|坏瓜)
P3_G = P(3, "好瓜") # P(清晰|好瓜)
P3_B = P(3, "坏瓜") # P(清晰|坏瓜)
P4_G = P(4, "好瓜") # P(凹陷|好瓜)
P4_B = P(4, "坏瓜") # P(凹陷|坏瓜)
P5_G = P(5, "好瓜") # P(硬滑|好瓜)
P5_B = P(5, "坏瓜") # P(硬滑|坏瓜)
P6_G = P(6, "好瓜")# P(密度为中高|好瓜)
P6_B = P(6, "坏瓜")# P(密度为中高|坏瓜)
P7_G = P(7, "好瓜")# P(含糖量为高|好瓜)
P7_B = P(7, "坏瓜")# P(含糖量为高|坏瓜)
# 计算后验概率
isGood = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G * P6_G * P7_G
isBad = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B * P6_B * P7_B
return isGood, isBad
#运行测试
isGood, isBad = bayes()
print(f"好瓜后验概率 P(好瓜|x) = {isGood:.6f}")
print(f"坏瓜后验概率 P(坏瓜|x) = {isBad:.6f}")
print("\n预测结果:", "好瓜" if isGood > isBad else "坏瓜")
运行结果:

这里的好瓜坏瓜的概率均为0,原因是测试集中含糖率为高这一特征,在训练集中没有出现过,因此概率为0,导致后验概率也为0,从而造成预测结果不准确。所以我们要引入拉普拉斯平滑修正。
4. 改进与拓展
4.1 拉普拉斯平滑
在朴素贝叶斯中,如果某个特征值在某类下从未出现,则该类别的后验概率将变为0,从而完全被排除。为避免此类零概率问题,可以引入拉普拉斯平滑:
平滑公式:
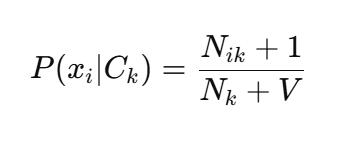
其中:
-
N i k N_{ik} Nik:类别 C k C_k Ck 下特征 x i x_i xi 出现的次数
-
N k N_k Nk:类别 C k C_k Ck 的样本总数
-
V V V:该特征可能的取值个数
条件概率使用拉普拉斯平滑修正:(只需要修改计算先验概率与条件概率的函数)
# 进行拉普拉斯修正
def prior():
dataSet = loadDataSet()[0]
countG = (dataSet['好坏'] == "好瓜").sum()
countB = (dataSet['好坏'] == "坏瓜").sum()
total = len(dataSet)
N_classes = 2 # 类别总数(好瓜和坏瓜)
# 拉普拉斯修正后的先验概率
P_G = (countG + 1) / (total + N_classes)
P_B = (countB + 1) / (total + N_classes)
return P_G,P_B
#计算离散属性的条件概率P(xi|c)
def P(index, cla):
dataSet, testSet, labels = loadDataSet() # 载入数据集
label = labels[index]
count_class = sum(1 for _, row in dataSet.iterrows() if row['好坏'] == cla)
attr_values = dataSet[label].unique()
num_values = len(attr_values) # 该属性取值种类数
match_count = sum(
1 for _, row in dataSet.iterrows()
if row['好坏'] == cla and row[label] == testSet[index]
)
# 拉普拉斯修正
prob = (match_count + 1) / (count_class + num_values)
return prob
计算结果:
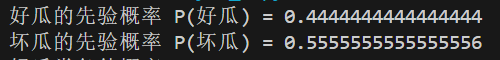
运行结果:

完整代码:
import pandas as pd
# 加载数据并进行离散化处理
def loadDataSet():
data = pd.DataFrame([
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']
], columns=['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率', '好坏'])
# 连续特征离散化
data['密度'] = pd.cut(data['密度'], bins=[0, 0.4, 0.6, 0.8, 1], labels=['低', '中低', '中高', '高'])
data['含糖率'] = pd.cut(data['含糖率'], bins=[0, 0.1, 0.25, 0.4, 0.5], labels=['低', '中低', '中高', '高'])
testSet = ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '中高', '高']
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率']
return data, testSet, labels
# 进行拉普拉斯修正
def prior():
dataSet = loadDataSet()[0]
countG = (dataSet['好坏'] == "好瓜").sum()
countB = (dataSet['好坏'] == "坏瓜").sum()
total = len(dataSet)
N_classes = 2 # 类别总数(好瓜和坏瓜)
# 拉普拉斯修正后的先验概率
P_G = (countG + 1) / (total + N_classes)
P_B = (countB + 1) / (total + N_classes)
return P_G,P_B
# 测试
data, testSet, labels = loadDataSet()
P_G, P_B = prior()
print(f"好瓜的先验概率 P(好瓜) = {P_G:}")
print(f"坏瓜的先验概率 P(坏瓜) = {P_B:}")
#计算离散属性的条件概率P(xi|c)
def P(index, cla):
dataSet, testSet, labels = loadDataSet() # 载入数据集
label = labels[index]
count_class = sum(1 for _, row in dataSet.iterrows() if row['好坏'] == cla)
attr_values = dataSet[label].unique()
num_values = len(attr_values) # 该属性取值种类数
match_count = sum(
1 for _, row in dataSet.iterrows()
if row['好坏'] == cla and row[label] == testSet[index]
)
# 拉普拉斯修正
prob = (match_count + 1) / (count_class + num_values)
return prob
# 测试
data, testSet, labels = loadDataSet()
print("好瓜类条件概率:")
for i in range(len(labels)):
print(f"P({labels[i]}={testSet[i]} | 好瓜) =", P(i, "好瓜"))
print("\n坏瓜类条件概率:")
for i in range(len(labels)):
print(f"P({labels[i]}={testSet[i]} | 坏瓜) =", P(i, "坏瓜"))
# 预测后验概率P(c|xi)
def bayes():
# 计算类先验概率
P_G, P_B = prior()
# 计算条件概率
P0_G = P(0, "好瓜") # P(青绿|好瓜)
P0_B = P(0, "坏瓜") # P(青绿|坏瓜)
P1_G = P(1, "好瓜") # P(蜷缩|好瓜)
P1_B = P(1, "坏瓜") # P(蜷缩|坏瓜)
P2_G = P(2, "好瓜") # P(浊响|好瓜)
P2_B = P(2, "坏瓜") # P(浊响|坏瓜)
P3_G = P(3, "好瓜") # P(清晰|好瓜)
P3_B = P(3, "坏瓜") # P(清晰|坏瓜)
P4_G = P(4, "好瓜") # P(凹陷|好瓜)
P4_B = P(4, "坏瓜") # P(凹陷|坏瓜)
P5_G = P(5, "好瓜") # P(硬滑|好瓜)
P5_B = P(5, "坏瓜") # P(硬滑|坏瓜)
P6_G = P(6, "好瓜")# P(密度为中高|好瓜)
P6_B = P(6, "坏瓜")# P(密度为中高|坏瓜)
P7_G = P(7, "好瓜")# P(含糖量为高|好瓜)
P7_B = P(7, "坏瓜")# P(含糖量为高|坏瓜)
# 计算后验概率
isGood = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G * P6_G * P7_G
isBad = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B * P6_B * P7_B
return isGood, isBad
#运行测试
isGood, isBad = bayes()
print(f"好瓜后验概率 P(好瓜|x) = {isGood:.6f}")
print(f"坏瓜后验概率 P(坏瓜|x) = {isBad:.6f}")
print("\n预测结果:", "好瓜" if isGood > isBad else "坏瓜")
4.2 支持连续特征的高斯朴素贝叶斯
若不进行离散化,也可采用高斯分布估计来建模密度与含糖率:
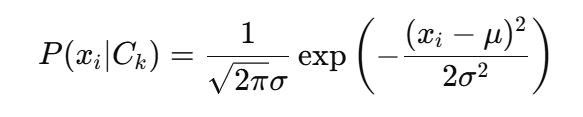
其中
μ
\mu
μ 和
σ
\sigma
σ 是类别
C
k
C_k
Ck 下特征
x
i
x_i
xi 的均值和标准差。
5. 实验小结
通过本次实验,我深入学习并实现了朴素贝叶斯分类算法,结合了高斯分布处理连续特征与拉普拉斯平滑处理离散特征的策略,对西瓜数据集进行了有效建模与分类预测。
在实际操作过程中,我体会到理论与实践结合的重要性。例如,书本上提到高斯朴素贝叶斯适用于处理连续型变量,在实验中,我亲手计算了不同类别下密度和含糖率的均值与方差,并带入公式计算后验概率,切身体会到了概率模型的直观与高效。
此外,拉普拉斯平滑虽然是一个简单的技巧,却在样本量较小时发挥了关键作用,避免了条件概率为0而导致整个预测失效的问题,让我意识到算法中“细节决定成败”的道理。

















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









