







文章目录
D2FQ_Device-Direct Fair Queueing for NVMe SSDs
这篇论文发表在2021年的FAST会议上,主要讲的是基于NVMe的WRR机制解决队列的公平性问题。
Abstract
在FLIN:Enabling Fairness and Enhancing Performance in Modern NVMe Solid State Drives这篇论文中提出的FLIN模型提出通过绕过操作系统的io统一管理层,直接将应用程序的io请求队列与SSD链接。

下图所示为传统的IO调度机制,目前已知做得最好的算法是在2019年提出的MQFQ,它提出了由设备端来保证公平性的方式太过简单,无法承受恶意攻击或一些异常操作,提出不绕过操作系统,而是根据linux上已实现多队列操作的block I/O层为每个核心维护自己的请求队列,通过跟踪最小虚拟时间的指示器和用于跨核可伸缩通信的令牌树来保证公平性。

而本文所提的D2FQ则指出,随着低延迟ssd的引入,性能瓶颈正从I/O设备转移到CPU,而通过操作系统来维持多队列会占用CPU,使得CPU比其它方案更早饱和。基于NVMe WRR构建的D2FQ可以实现低CPU开销的公平排队I / O调度。
Introduction

典型的I / O调度程序在I / O处理过程中需要执行三个步骤(提交,仲裁,分发),而用NVMe的WRR机制来实现则可以实现提交即分发,避免了多队列的仲裁阶段。
D2FQ将NVMe WRR里的三个队列类抽象为具有不同I / O处理速度的三类队列,对于每个提交的I / O请求,D2FQ都会选择一个I / O命令队列,并立即向该队列分派一个I / O请求。
由于取消了仲裁步骤,并且在块层中统一了提交和分发步骤,因此D2FQ可以在I / O调度期间最大程度地减少CPU开销并提高I / O性能。
本文所提的D2FQ是在Linux内核中实现的。
Background
像前面所说的,块层会导致CPU周期和I / O延迟方面的开销。块I / O调度的高CPU成本可能会加剧具有快速SSD的现代数据密集型应用中的CPU瓶颈问题。因此,随着低延迟SSD的推出,性能瓶颈已从I / O设备转移到了CPU。
通过将I / O调度功能卸载到设备,可以减轻I / O调度的高开销。 网络接口卡(NIC)比SSD更早经历了微秒级I / O延迟的时代,在之前已经提出了许多方法来将分组调度卸载到NIC,并成功降低了CPU利用率。 类似地,将块I / O调度卸载到具有设备侧I / O调度功能的SSD是可行的,可以以此来降低块I / O调度的成本。
在许多按比例分配的I / O调度程序中,基于虚拟时间的公平排队因其节省工作的特性而成为SSD的有吸引力的解决方案。 他们可以最大化SSD吞吐量,同时每个租户获得的带宽与租户的重量成正比。
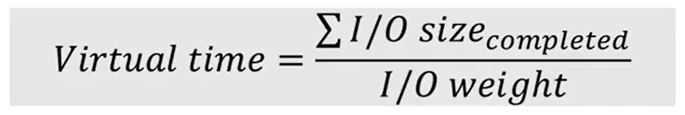
Virtual time: 虚拟时间。每个IO队列都会有其自身的虚拟时间,虚拟时间的计算方式是:IO队列已完成的IO量除以IO队列的权重。调度程序的目标是最小化所有流之间的虚拟时间间隔。

上图是NVMe WRR的工作模型。
WRR的实现机制为:
- 启用WRR后,命令队列被分为三个优先级类别(低,中和高),并且为每个优先级类别的队列分配了队列权重(1 – 256)。 因此,相同优先级类别中的队列共享队列权重。
- 启用WRR后,如果低,中和高队列的队列权重分别为1、2和3,SSD控制器将从高队列中获取三个I / O命令,然后从中队列中获取两个命令,然后 从低队列中获取一个。 优先级相同的队列以循环方式访问。
Device-Direct Fair Queuing

如图,当App1的虚拟时间较小,即小于变量m时,证明其受到了不公平待遇,需要将其分配到高队列中得到更高的IO分配权重;类似的,App3的虚拟时间太大,需要将其分配到低队列中,给其较低的IO分配权重;而App2和App4则相应的分到中队列。
1. Dynamic HL ratio adjustment
HL ratio指的是高队列的权重比上低队列的权重得出来的比值:
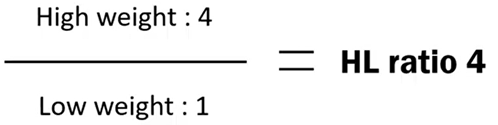
这时候,当HL ratio过高时,低队列中的IO请求权重太低,可能会造成太高的时间延迟;当HL ratio过低时,高队列的权重又不足于满足某些队列的需要:

因此,需要动态设置合适的HL ratio,即满足公平性又不会造成太大的延迟。
实现方法如下所示:
-
Increasing HL ratio

-
Decreasing HL ratio

2. Setting the queue class thresholds
较小的阈值可能会无意中增加流的尾部等待时间,尤其是那些留在虚拟时域中的流。 此类流仅用于使用高队列。 但是,由于跨过阈值,虚拟时间的少量增加会使此类流使用中或低队列。 这可能会加剧所有流的尾部等待时间,因为其他流可能会无意中使用高队列,并受到限制以抵消使用高队列的好处。
因此,在设置阈值时需要在短期公平性和尾部等待时间之间进行权衡。 根据用户关注的是尾部等待时间还是短期公平性,用户可以调整适当的阈值。
3. Sloppy minimum tracking
跟踪gvt等于跟踪一组值中的最小值,其中每个值同时更改。
在这方面,论文中的方案只维护了gvt持有者,拥有gvt这一变量,并且仅允许gvt持有者能够增加gvt。 其他流也可以更新gvt,但前提是它们的虚拟时间小于gvt。
当gvt持有者增加gvt但是超过了其他流量的虚拟时间时,可能会出现一些不准确的情况,因此违反了gvt并非最小的要求。
但是,gvt更新操作的简化带来的这种微小误差是不可避免的。 否则,每次gvt更新都需要检查所有流的虚拟时间。
Evaluation


Conclusion
D2FQ是基于NVMe WRR构建的低CPU开销公平排队I / O调度程序,保证了队列间的公平性,且有很高的调度性能。
- 与使用block IO调度相比,使用D2FQ时的CPU利用率降低了多达45%。
- 使用时高效利用了带宽,并且多个队列都能实现较低的延迟。
- 有很强的可扩展性,可以与其它多队列策略搭配使用,实现更优的效果。















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









