







 本文介绍了组合分类方法,包括装袋、提升(如Adaboost)和随机森林。针对类不平衡数据,提出了过抽样、欠抽样和阈值移动的解决方案。组合分类通过集成多个基分类器,提高分类准确性和模型稳定性。
本文介绍了组合分类方法,包括装袋、提升(如Adaboost)和随机森林。针对类不平衡数据,提出了过抽样、欠抽样和阈值移动的解决方案。组合分类通过集成多个基分类器,提高分类准确性和模型稳定性。
组合分类方法简介
基本思想:组合分类把k个学习得到的模型(或基分类器)M1,M2,···,Mk组合在一起,旨在创建一个改进的复合分类器模型M*。使用给定的数据集D创建k个训练集D1,D2,···,Dk,其中Di用于创建分类器Mi。现在给定一个待分类的新数据元组,每个基分类器通过返回类预测进行投票。组合分类器基于基分类器的投票返回类预测。
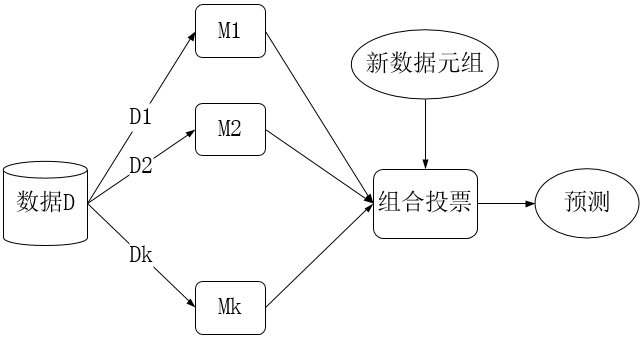
目前常用的组合分类器有:装袋、提升和随机森林。下面就对这三种分类器依次作介绍。
装袋(bagging)
算法:装袋。装袋算法——为学习方案创建组合分类模型,其中每个模型给出等权重预测。
输入:
- D:d个训练元组的集合
- k:组合分类器中的模型数
- 一种学习方案(例如,决策树算法、后向传播等)
输出:组合分类器——复合模型 M∗
方法:
- for i = 1 to k do
- 通过对 D 有放回抽样,创建自助样本
Di - 使用 Di 和学习方法导出模型 Mi
- endfor
使用组合分类器对元组x分类:让k个模型都对x分类并返回多数表决
注意:这里的每个基分类器具有相同的投票权重
提升(boosting)
在提升方法中,权重赋予每个训练元组。迭代地学习 k 个分类器。学习得到分类器
Adaboost(Adaptive Boosting)是一种流行的提升算法。
算法:Adaboost.一种提升算法——创建分类器的组合。每个给出一个加权投票。
输入:
- D:类标记的训练元组集。
- k:轮数(每轮产生一个分类器)。
- 一种分类学习方案。
输出:一个复合模型。
方法:
- 将D中每个元组的权重初始化为 1/d
- for
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5115
5115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









