









大约从硕士阶段就听说过 SVM 了,但是没有真正用过,这几天刚好看了看相关的内容,就简单写一下心得,供以后查阅用。
支持向量机是一个二分分类方法,比较适合判断只有两个类别的分类问题,对于多类别的分类,需要对 SVM 的部分代码进行修改。
从几何意义上看,SVM 的基本思想是找到一个分类的直线(或平面,或者非线性曲线或平面),将两个类别的数据分开。(两条平行线的距离: w x = a wx=a wx=a, w x = b wx=b wx=b,距离为 ∣ b − a ∣ ∥ w ∥ 2 \frac{|b-a|}{\|w\|_2} ∥w∥2∣b−a∣)
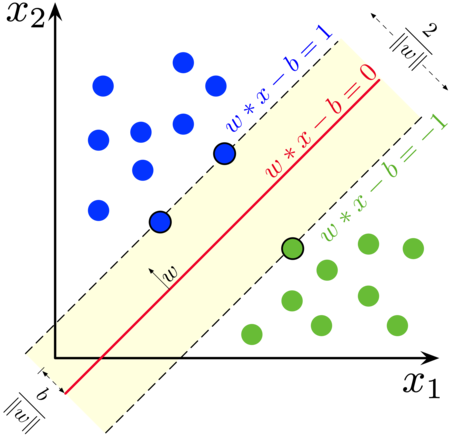
在数学原理上,优化目标是让中间的分割线离两类数据边缘的距离最大。构建一个数学优化模型,并利用拉格朗日对偶模型求解,具体可以参考这篇博客,比英文维基百科介绍地都清楚:
https://blog.csdn.net/BIT_666/article/details/79865225
Python 中的 Sklearn 包有现成的 SVM 模型可以调用,下面的代码利用 SVM对乳腺癌判别分析,来源于 《Python 数据分析与应用》:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
cancer = datasets.load_breast_cancer()
cancer_data = cancer['data']
cancer_target = cancer['target']
cancer_data_train, cancer_data_test, cancer_target_train, \
cancer_target_test = train_test_split(cancer_data, cancer_target, test_size = 0.2)
# 数据标准化
stdScaler = StandardScaler().fit(cancer_data_train)
cancer_trainStd = stdScaler.transform(cancer_data_train)
cancer_testStd = stdScaler.transform(cancer_data_test)
# 建立 SVM 模型
svm = SVC().fit(cancer_trainStd, cancer_target_train)
print('建立的SVM模型为: \n', svm)
# 预测训练集结果
cancer_target_pred = svm.predict(cancer_testStd)
print('预测前20个结果为:\n', cancer_target_pred[:20])
# 预测和真实一样的数目
print('预测对的结果数目为:' , np.sum(cancer_target_pred == cancer_target_test))
输出结果:
建立的SVM模型为:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=‘ovr’, degree=3, gamma=‘scale’, kernel=‘rbf’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
预测前20个结果为:
[1 1 1 0 0 1 1 0 0 0 1 1 0 1 1 0 1 0 1 1]
预测对的结果数目为: 113















 2581
2581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











