






英伟达于2024年6月14日发布的一款开源大型语言模型(LLM)Nemotron-4 340B模型家族(Nemotron-4-340B-Base(基础模型)、Nemotron-4-340B-Instruct(指令模型)、Nemotron-4-340B-Reward(奖励模型)),具有3400亿参数,在NVIDIA开放模型许可协议下开放访问,允许分发、修改和使用这些模型及其输出。该模型采用了Transformer架构,并引入了旋转位置嵌入(RoPE)优化算法和MOE(Mixture of Experts)架构。这些技术的结合使得Nemotron-4340B在常识推理任务以及BBH等主流基准上实现了行业最高的准确率,并且在MMLU代码基准上也具备较高竞争力。
1 模型架构与训练细节
1.1 模型架构
Nemotron-4-340B-Base 的架构与 Nemotron-4-15B-Base 类似,采用标准解码器 Transformer 架构,并包含以下特点:
- 架构类型: Nemotron-4-340B-Base模型采用的是标准的仅解码器(decoder-only) Transformer架构。这种架构通常用于处理序列数据,如自然语言处理任务。
- 注意力机制: 模型使用了因果注意力掩码(causal attention masks),这意味着在生成序列的每一步,只有当前步骤之前的信息可以被关注到,保证了时间序列的因果性。
- 位置嵌入: 采用了旋转位置嵌入(Rotary Position Embedding, RoPE)技术,这是一种新型的位置编码方式,有助于模型更好地捕捉序列中的位置信息。
- 分词器: 使用了SentencePiece分词器,这是一种可以处理多种语言的子词分词技术。
- 激活函数: 在多层感知机(MLP)层中使用了平方ReLU激活(squared ReLU activations),有助于增加非线性并改善模型的学习能力。
1.2 模型参数
- 隐藏层维度: 模型具有18432的隐藏层维度。
- 注意力头数: 共有96个注意力头。
- 序列长度: 支持的序列长度为8192个token。
- 词汇表大小: 词汇表大小为256,000。
1.3 训练细节
- 训练数据量: 模型在总计9万亿个token上进行了训练,其中前8万亿作为正式的预训练阶段,剩下的1万亿作为继续预训练阶段。
- 训练硬件: 使用了768个DGX H100节点进行训练,每个节点配备了8个基于NVIDIA Hopper架构的H100 80GB SXM5 GPU。每个GPU在执行16位浮点(bfloat16)运算时的峰值吞吐量为989 teraFLOP/s。
- 网络连接: 节点内的GPU通过NVLink和NVSwitch连接,节点间的GPU通过NVIDIA Mellanox 400 Gbps HDR InfiniBand Host Channel Adapters进行通信。
- 并行策略: 采用了8路张量并行、12路流水线并行以及数据并行的方法来训练模型。同时使用了分布式优化器来减少训练过程中的内存占用。
- 批大小调整: 训练过程中对批大小进行了调整,从16个数据并行副本增加到64个。
1.4 继续训练
继续训练阶段的数据分布包括两部分:
- 主要数据分布: 包含预训练阶段已经出现过的 token,但采样权重更大地倾斜于高质量数据源。
- 辅助数据分布: 引入少量问答式对齐示例,帮助模型更好地应对下游评估,并提升模型在低精度领域的性能。
学习率衰减计划: 采用陡峭的学习率衰减斜率,帮助模型平稳地从预训练数据过渡到继续训练数据。
2 预训练数据
2.1 预训练数据组成
- 英语自然语言数据 (70%): 来自网络文档、新闻文章、科学论文、书籍等领域的精选文档。
- 多语言自然语言数据 (15%): 包含 53 种自然语言,来自单语语料库和平行语料库。
- 源代码数据 (15%): 包含 43 种编程语言的代码。
2.2 数据规模
模型总共在 9 万亿 token 上进行训练,其中前 8 万亿 token 用于正式预训练阶段,最后 1 万亿 token 用于继续预训练阶段。
2.3 数据混合
为了确保数据的多样性和覆盖范围,数据混合过程中采用了以下策略:
- 英语自然语言数据: 主要来自网络文档、新闻文章、科学论文、书籍等领域的精选文档,涵盖了各个领域的知识。
- 多语言自然语言数据: 包含 53 种自然语言,来自单语语料库和平行语料库,帮助模型学习多种语言的语法和语义。
- 源代码数据: 包含 43 种编程语言的代码,帮助模型学习编程语言的结构和语法。
2.4 数据质量
预训练数据来自高质量的数据集,并经过精心筛选和清洗,确保了数据的准确性和可靠性。
3 模型对齐
模型对齐是确保大型语言模型(LLMs)在遵循指令、进行有效对话和解决问题方面表现出色的关键过程。Nemotron-4-340B 模型家族的模型对齐流程经过精心设计,确保了模型能够更好地理解和执行用户的指令,并生成高质量的回复。
3.1 奖励模型
奖励模型是模型对齐过程中的关键组件,用于评估回复的质量。Nemotron-4-340B-Reward 是一个基于 Nemotron-4-340B-Base 的回归模型,通过将最后一层的隐藏状态映射到五个维度的向量 (帮助性、正确性、连贯性、复杂性和冗长性) 来预测回复的质量。
3.2 对齐数据
随着模型的不断改进,发现现有的开放数据集对于训练最对齐的模型越来越不足。此外,从人类那里收集高质量数据既耗时又成本高昂。为了解决这一挑战,英伟达研发团队深入探索了合成数据生成(SDG)作为解决方案。值得注意的是,在整个过程的对齐过程中,只依赖了大约20K人类注释的数据(10K用于监督式微调,10K HelpSteer2数据用于奖励模型训练和偏好微调),而数据显示管道为监督式微调和偏好微调合成了超过98%的数据。
3.2.1 提示准备(Prompt Preparation)
使用已有的提示生成工具,生成多种类型的提示,例如开放问答、写作、封闭问答、数学和编程等。
3.2.2 合成对话生成(Synthetic Dialogue Generation)
使用指令模型,根据输入提示生成对话,并通过奖励模型评估对话质量,过滤掉低质量对话。
3.2.3 合成偏好数据生成(Synthetic Preference Data Generation)
使用多个中间模型生成回复,并通过奖励模型或 LLM 评估回复的质量,生成 (提示、选择回复、拒绝回复) 三元组数据。
3.2.4 其他数据源(Additional Data Sources)
整合了几个补充数据集,以赋予模型特定的能力,如下所示:
- 主题跟随:整合了CantTalkAboutThis的训练集,该数据集包括涵盖广泛主题的合成对话,故意穿插分心的轮次,以使聊天机器人偏离主题。这个数据集有助于增强模型在任务导向交互中保持对预期主题的关注能力。
- 无法完成的任务:某些任务可能由于需要特定能力(如互联网访问或实时知识)而无法由模型单独完成。为了减少这些情况下的幻觉,采用了少样本方法,使用人类编写的示例来提示LLM生成多样化的问题。然后我们明确要求LLM以拒绝回答,收集这些响应并将其与相应的问题配对。这些配对数据用于训练我们的模型,使其能够更好地处理它无法完成的任务。
- STEM数据集:Open-Platypus已被证明可以提高STEM和逻辑知识。在训练数据中包括了带有许可许可的子集(PRM800K、SciBench、ARB、openbookQA)。
- 基于文档的推理和QA:文档基础QA是LLM的重要用例。利用FinQA数据集来提高数值推理能力,使用(Liu等人,2024)的人类注释数据来提高上下文化QA的准确性,并使用wikitablequestions数据集(Pasupat和Liang,2015)来加强模型对半结构化数据的理解。
- 函数调用:包括(Glaive AI,2023)的子集样本,以增强模型在函数调用方面的能力。
3.3 对齐算法
采用了标准的模型对齐协议(Ouyang等人,2022),包括两个阶段:监督式微调和偏好微调。
- 监督微调 (SFT): 使用人工标注的数据,训练模型理解和执行简单的指令。
- 偏好微调: 使用奖励模型和人类反馈,进一步训练模型理解和执行更复杂的指令,并提升回复的质量。
4 模型评估
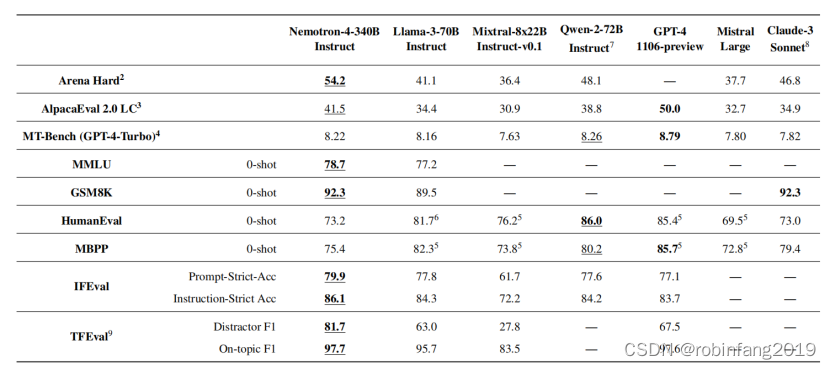
Nemotron-4 340B 模型评估主要集中在两个模型上:Nemotron-4-340B-Base 和 Nemotron-4-340B-Instruct,与现有的开源模型Llama-3-70B-Instruct、Mixtral-8x22B-Instruct-v0.1、Qwen-2-72B-Instruct)以及专有模型(如GPT-4-1106-preview、Mistral Large、Claude-3-Sonnet)进行比较。评估方法包括自动评估和人工评估,涵盖了推理、指令遵循、对话、安全等多个方面。
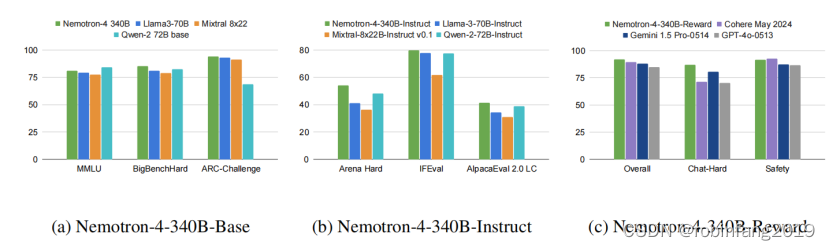
4.1 自动基准测试
- 推理能力: 使用 MMLU、BBH、ARC-Challenge、Winogrande、Hellaswag 等基准测试,与 Llama-3 70B、Mistral 8x22B、Qwen-2 72B 等模型进行比较。结果显示,Nemotron-4-340B-Base 在常识推理任务和 BBH 基准测试中表现最佳,在 MMLU 和代码基准测试中也具有竞争力。
- 指令遵循能力: 使用 Arena Hard、AlpacaEval 2.0 LC、MT-Bench 等基准测试,与 Llama-3 70B-Instruct、Mixtral-8x22B-Instruct-v0.1、Qwen-2 72B-Instruct 等模型进行比较。结果显示,Nemotron-4-340B-Instruct 在指令遵循和对话能力方面超越了其他模型。
- 代码能力: 使用 HumanEval 和 MBPP 基准测试,评估代码生成和推理能力。结果显示,Nemotron-4-340B-Instruct 在代码生成方面表现出色。
4.2 人类评估
- 多任务评估: 使用 InstructGPT 和 AlpacaEval 2.0 LC 中的任务,评估模型的指令遵循能力、对话能力、推理能力等。结果显示,Nemotron-4-340B-Instruct 在大多数任务上与 GPT-4-1106-preview 表现相当或更好,尤其是在多轮对话方面。
- 长度感知评估: 评估标注人员对模型响应长度的感知。结果显示,标注人员认为 Nemotron-4-340B-Instruct 的响应长度更合适。
4.3 安全评估
为了评估模型的安全性,采用了NVIDIA提供的高质量内容安全解决方案和评估基准AEGIS。AEGIS由一个广泛的内容安全风险分类体系支持,涵盖了人类-LLM交互中的12个关键风险。AEGIS安全模型是一组基于LlamaGuard的开源LLM分类器,它们通过AEGIS安全分类体系和政策以参数高效的方式进一步进行了指令调整。我们使用AEGIS测试分区中的提示来引发Nemotron-4-340B-Instruct和Llama-3-70B-Instruct的响应。然后,由AEGIS安全模型对这些响应进行判断。
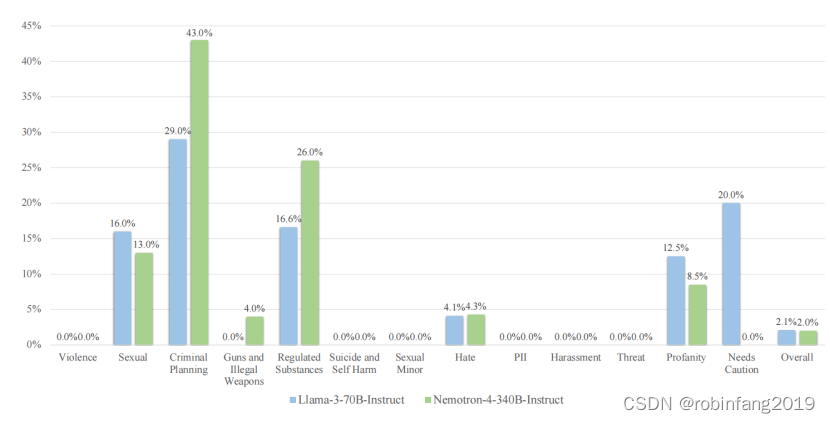
使用 AEGIS 安全评估工具,评估模型在仇恨、暴力、自杀、性、隐私等方面的风险。结果显示,Nemotron-4-340B-Instruct 具有非常低的危险响应率,在安全性方面与 Llama-3 70B-Instruct 相当。















 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









