






多模态大型语言模型(MLLMs)在过去几年中取得了爆炸性的增长。利用大型语言模型(LLMs)中丰富的常识知识,MLLMs在处理和推理各种模态(如图像、视频和音频)方面表现出色,涵盖了识别、推理和问答等一系列任务,所有这些任务都使用语言作为中间表示。然而,现有的MLLMs在理解网页截图和生成表达其潜在状态的HTML代码方面出奇地差。
为了解决现有 MLLM 在网页理解和代码生成方面的局限性,本文提出了 Web2Code 基准。Web2Code 包含一个大规模的网页到代码数据集,用于指令微调和一个评估框架,用于测试 MLLM 的网页理解和 HTML 代码翻译能力。
源代码下载:https://github.com/MBZUAI-LLM/web2code
1 数据集的构建
数据集构建是Web2Code项目的核心部分,它涉及创建和优化网页图像与HTML代码配对的数据,以及生成与网页理解相关的问答对。
1.1 创建新的网页图像-代码对数据 (DWCG)
- 使用 GPT-3.5 生成 60K 个 HTML 页面,遵循 CodeAlpaca 提示。
- 使用 Selenium WebDriver 从生成的 HTML 代码中创建网页图像截图。
- 将网页图像-代码对转换为指令跟随数据格式,类似于 LLaVA 数据格式,以便用于训练 MLLM。
1.2 精炼现有的网页代码生成数据 (DWCGR)
- 利用 Pix2code 和 WebSight 数据集来增强模型在 HTML 代码生成任务上的能力。
- 使用 GPT-4 将 Pix2code 数据集中的随机字母替换为有意义文本,并将网页精炼为包含产品着陆页、个人作品集、博客等类别的多样化网页。
- 将所有数据转换为 LLaVA 指令跟随数据格式。
1.3 创建新的文本问答对数据 (DWU)
- 使用 GPT-4 生成基于网页代码的问答对数据,用于网页理解任务。
- 为 24.35K 个网页数据生成 10 个问答对,共计 243.5K 个数据点。
- 问答对涵盖了网页的结构、设计、内容等方面,以确保模型能够全面理解网页信息。
1.4 精炼现有的网页理解数据 (DWUR)
- 将 WebSRC 数据集集成到训练中,以提高模型在网页理解任务上的能力。
- 对 WebSRC 数据集中的问答对进行筛选,确保其相关性和质量。
- 使用 GPT-4 评估和提升答案的质量,将数据集精炼为 51.5K 个高质量的指令数据。
1.5 数据集统计和分析
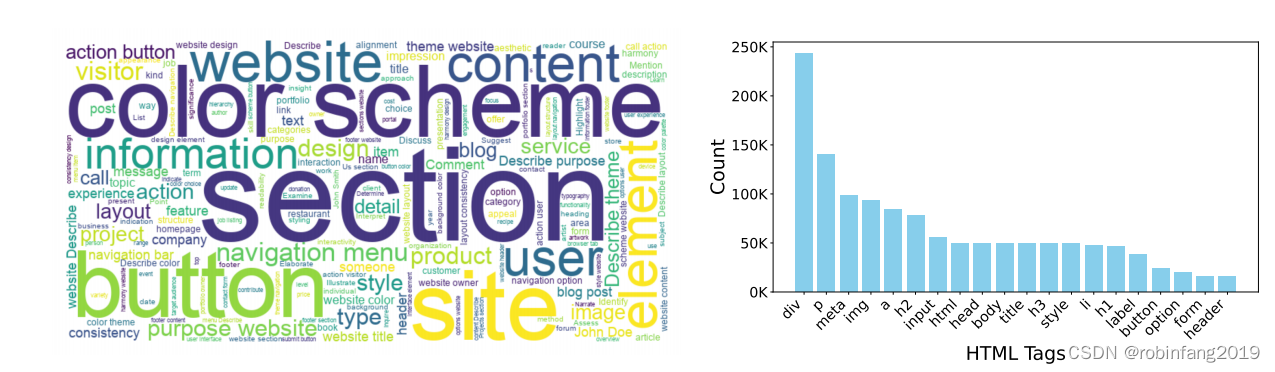
- 图表展示了问答数据集中答案集的词云,突出了数据中结构性和设计元素的重要性。
- 图表展示了 GPT-3.5 生成 HTML 数据中最常见的 HTML 标签分布,表明生成的页面包含丰富的元素,结构完整。
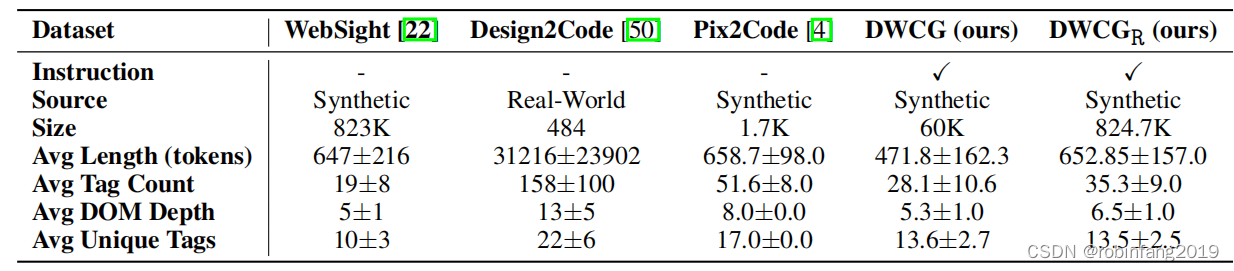
- 表格将 Web2Code 数据集与其他现有数据集进行了比较,例如 WebSight、Design2Code 和 Pix2Code,结果表明 Web2Code 数据集更大、更复杂、更具挑战性。
1.6 数据集分布
- Web2Code 数据集包含 1179.7K 个指令数据点,包括 884.7K 个网站图像-代码对和 295K 个问答对。
- 问答对由 243.5K 个 GPT-4 基于问答对和 51.5K 个 WebSRC 图像基于问答对组成。
- 评估数据集包含 1198 个网页截图图像,来自 WebSight、Pix2Code、GPT-3.5 基于数据和人工作业。
- 此外,还使用了 5,990 个“是/否”问答对,使用 GPT-4 Vision API 生成,用于 WUB 基准测试。
2 评估框架
Web2Code 提出了一个包含两个方案的评估框架,用于评估 MLLM 的网页理解和代码生成能力。

2.1 网页理解基准 (WUB)
这是一个离线评估,使用“是/否”问题进行评估。
- 该基准包含 5,990 个高质量问答对,由 GPT-4 Vision API 生成,基于 1,198 个网页截图图像。
- 每个问题的答案都是“是”或“否”。
- 将模型对问题的预测答案与真实答案进行比较,最终准确率作为评估指标。
2.2 网页代码生成基准 (WCGB)
这是一个在线评估,基于图像相似度进行评估。
- 该基准评估 MLLM 从网页图像生成 HTML 代码的能力。
- 将预测的 HTML 代码转换为图像,并与真实图像进行比较。
- 评估考虑了 10 个不同的方面,进一步分为四个评估矩阵,使用 GPT-4 Vision API 进行评分。
2.2.1 WCGB 评估的四个方面
- 视觉结构和对齐: 评估网页元素的结构和布局、元素对齐、比例精度和视觉和谐。
- 颜色和美学设计: 评估颜色方案、美学相似性、整体美学吸引力。
- 文本和内容一致性: 评估字体特征、文本内容匹配、数字和特殊字符精度。
- 用户界面和交互性: 评估用户界面一致性、设计语言和 UI 元素的外观。
2.3 评估指标
- WUB:准确率 (%)
- WCGB:视觉结构和对齐、颜色和美学设计、文本和内容一致性、用户界面和交互性的分数 (0-10)
2.4 定量评估
表格展示了不同 LLM 核心和不同数据配置在 WCGB 和 WUB 基准测试上的性能。
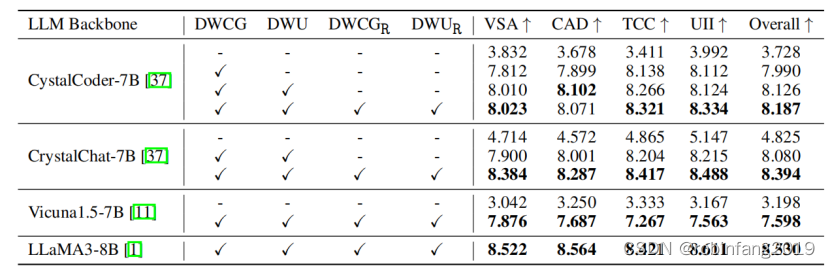
结果表明,Web2Code 数据集可以显著提高 MLLM 的网页理解和代码生成能力,而现有数据集则导致性能下降。
2.5 定性评估
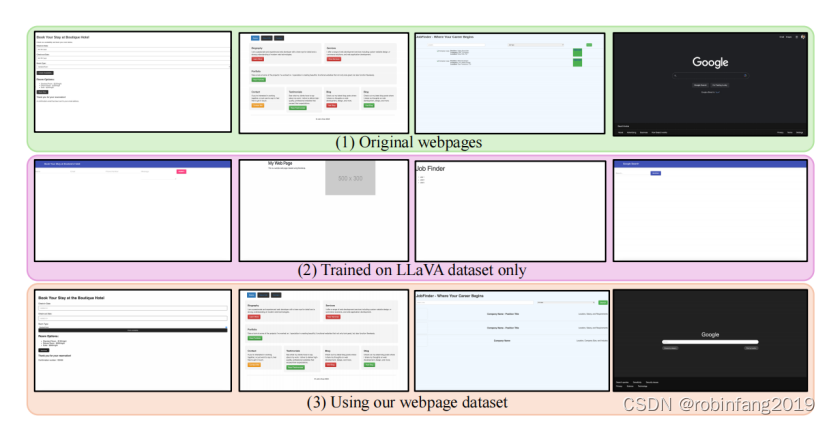
图表展示了使用不同 LLM 核心生成的网页图像与真实图像之间的比较。
结果表明,Web2Code 数据集可以提高模型生成网页图像的质量。
通过提出的评估框架,我们证明了Web2Code数据集在增强MLLMs的网页理解和网页到HTML翻译能力方面是有效的,同时现有的数据集可能导致性能下降。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









