









前一篇文章 编写http workshop脚本从网站下载音乐 示范了如何使用HttpClient访问API,以及Json数据的解析;
今天我们通过解析一个网页展示如何使用内置的LibXml2的功能解析HTML,提取我们关心的内容。
这里随便搜了2个资源类的网站,竟然使用的格式是一模一样的:
https://www.51miz.com/so-sound/86888.html
https://www.yespik.com/search-sound/86838.html一、分析页面结构
用浏览器F12,元素选中工具查看一下页面结构;或者保存页面为html,用vscode打开后格式化,
发现页面十分简单,每个资源的页面节点类似如下:

一般情况我们会使用xpath来查找节点列表,但是html与xml不一样就在于格式很多时候不规范,
使用容错方式解析后,xpath不一定能工作,这个时候就需要使用dom树遍历方式去查找节点,
xpathSimple函数可以指定 “节点名,1个属性名(可选),属性值(可选)”来查找。
-- 查找所有带有data-id属性的elements
nodes = doc:xpathSimple("div", "data-id", "");
n = nodes:size()
if n == 0 then
return 0
end其实也可以直接找子一层
-- 查找所有带有data-id属性的elements
nodes = doc:xpathSimple("div", "class", "SoundCotent");这样找到的一级节点下面有2个与信息有关的节点,
分别是文本地址:
<div class="SoundTitle">
<a target="_blank"
href="https://www.yespik.com/show-sound_293365.html">企业宣传片 希望未来</a>
</div>和资源链接:
<source
src="//img-bsy2.yespik.com/sound/00/29/33/65/293365_3d8657e566ff4b2aebffe9b09658f5bd.mp3"
type="audio/mpeg">
</audio>那么对应查找方式就是:文本部分查找
titles = item:xpathSimple("div", "class", "SoundTitle")
if (titles:size() > 0) then
title_a = titles:at(0):getChildByIndex("a", 0)
if not(title_a:isNull() ) then
titleStr = title_a:getValue()
titleStr = utf8ToAnsi(titleStr)
print(titleStr)
end
else
print("not found title")
goto continue
end资源节点查找:
audio = item:xpathSimple("source", "src", "")
if audio:size() > 0 then
src = audio:at(0):getAttrByName("src")
if not src:isNull() then
linkStr = "https:" .. src:getValue()
print(linkStr)
end
end 需要注意的是,通过xpath或者xpathSimple找到的是节点集合,需要自行判断里面的元素个数,有可能是0个(未找到);
二、脚本代码
完整的代码如下:
author = "范例"
version = 1.0
setting = {
name = "mizhi网音乐搜索",
dir = "d:\\MP3",
desc = "网站执行搜索后也会返回一个静态网页地址,猜测是使用nginx做加速, 比如https://www.51miz.com/so-sound/86888.html",
input1 = "网页地址",
input2 = "未使用",
input3 = "未使用",
}
client = HttpClient()
header = HttpHeader()
header:setItem('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36')
function search(url)
local urlSearch = url
local code = client:doGet(urlSearch, header)
printMessage("HTTP 应答: " .. code)
printMessage("开始解析html数据")
--printMessage(utf8ToAnsi(client:getBodyAsString()))
--printMessage(client:getBodyAsAnsiString())
body = client:getBodyAsString()
-- XML_PARSE_NOBLANKS + XML_PARSE_RECOVER
local opt = 256 + 1
doc = parseXmlString(body, "", opt)
if doc:isNull() then
print("解析html错误")
return 0
end
-- 查找所有带有data-id属性的elements
nodes = doc:xpathSimple("div", "data-id", "");
n = nodes:size()
if n == 0 then
return 0
end
count = 0
for i = 0, n-1 do
local titleStr = ""
local linkStr = ""
local lenStr = ""
item = nodes:at(i)
titles = item:xpathSimple("div", "class", "SoundTitle")
if (titles:size() > 0) then
title_a = titles:at(0):getChildByIndex("a", 0)
if not(title_a:isNull() ) then
titleStr = title_a:getValue()
titleStr = utf8ToAnsi(titleStr)
print(titleStr)
end
else
print("not found title")
goto continue
end
audio = item:xpathSimple("source", "src", "")
if audio:size() > 0 then
src = audio:at(0):getAttrByName("src")
if not src:isNull() then
linkStr = "https:" .. src:getValue()
print(linkStr)
end
end
tms = item:xpathSimple("div", "class", "SoundEndTime fl end-time")
if tms:size() > 0 then
lenStr = tms:at(0):getValue()
print(lenStr)
end
singer = "椰子音效"
album_name = ""
--printMessage(singer .. " | " .. titleStr .. " | " .. album_name .. " | ".. linkStr)
--downloadMp3(music_url, singer, song_name)
--downloadMp3(music_url, keyWord, song_name)
local tbl = {
singer = singer,
song = titleStr,
album = album_name,
tags = titleStr,
size = lenStr,
url = linkStr,
}
-- 当解析到某个音乐条目的时候,可以使用此函数通知界面
count = count + 1
notifyData(1, tbl)
::continue::
end --for
return count
end
function lua_main(url, pageIndex, pageSize)
printMessage("准备搜索")
printMessage(keyWord)
--printMessage("engine name is ".. engine_name())
--printMessage("engine version is ".. engine_version())
printMessage("当前目录:" .. setting.dir)
-- https://www.51miz.com/so-sound/86888.html
local n = 0
n = n + search(url)
return n
end
function downloadMp3(music_url, singer, song)
subDir = combinePath(setting.dir, singer)
mkDir(subDir)
fileName = subDir .. "\\".. song .. ".mp3"
printMessage(fileName)
code = client:doGetToFile(music_url,header, fileName)
print(code)
end
脚本的使用方法就是在浏览器里面看到有资源需要导出,就在输入栏中填写地址,解析即可:
比如链接:
https://www.51miz.com/so-sound/1558589.html我们解析后如下:
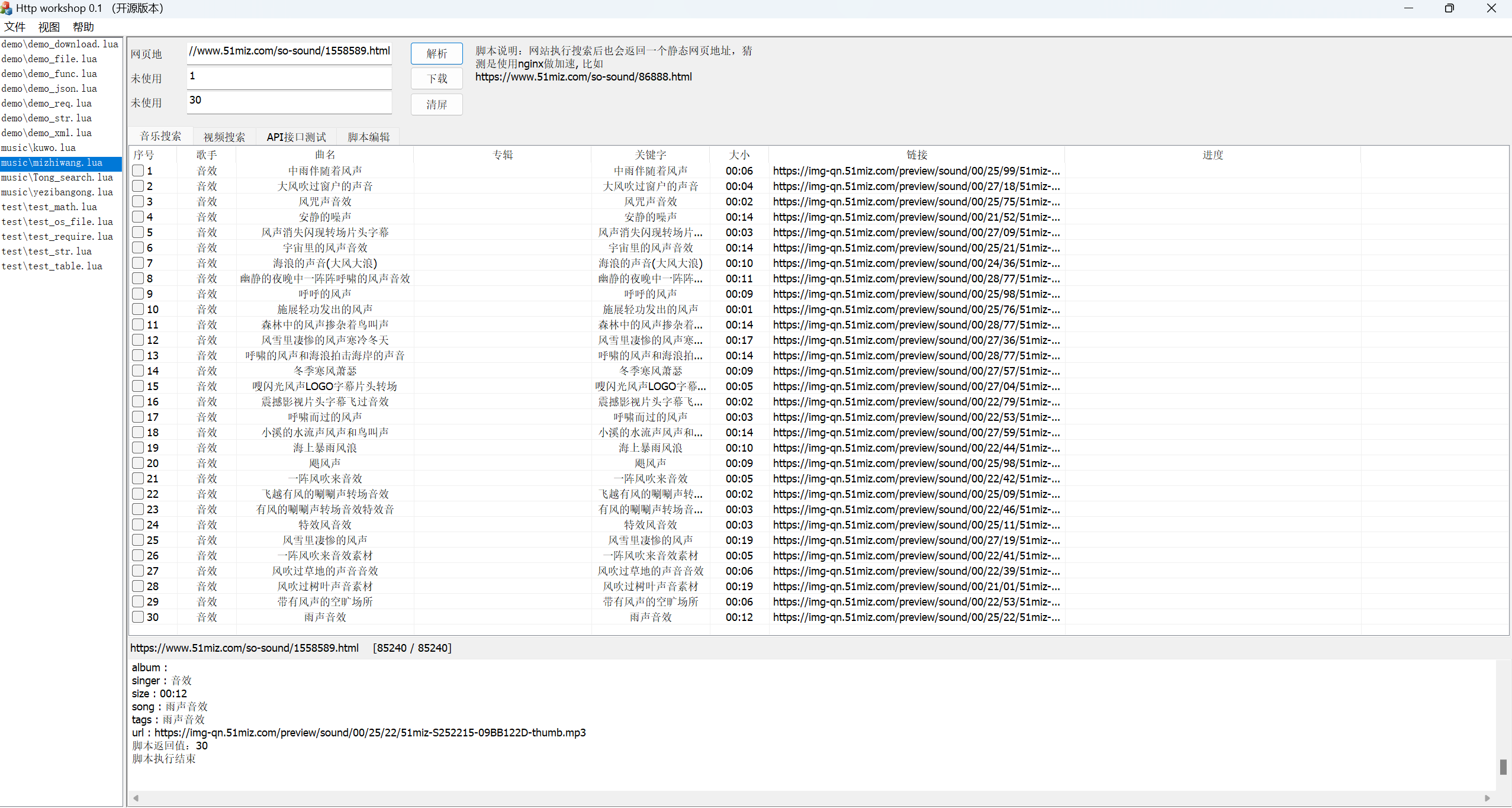
end here.















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









