







更多专业的人工智能相关文章,微信搜索 : robot-learner , 或扫码

根据统计上的贝叶斯公式,为了获得条件概率
![]() ,
,
可以做如下转换:
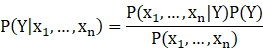
其中P(Y) 被称为先验概率,比如训练样本中样本好坏比例为9:1,则
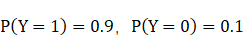 。
。
同时上式中
![]()
为不同样本标签下的自变量分布情况。而上式中的
![]()
作为分母,通常不需要再计算或者说概率不需要归一化,因为我们只需要比较上式的分子大小就可以比较出在给定所有自变量的情况下不同目标变量的概率大小。
朴素贝叶斯算法的关键在于从训练数据中计算
![]()
而这个计算可以相当复杂,因为它涉及到许多自变量。我们知道维度越多,需要的数据也是呈指数级增加的。为了解决这个问题,朴素贝叶斯算法做了这样一个假设:各个自变量在给定目标变量的情况下是条件独立的。体现在公式上,如下式所示:

打个比方:如果今天早上地铁出了故障,那么我们都知道小刘和小王的迟到就不可能是独立事件。但是,在已经考虑地铁出了故障的前提下,小刘和小王的迟到就是彼此独立的事件。因为在同样遇到地铁故障的情况下,小刘和小王的处理应变能力完全是随机的,他们是否会迟到的结果就是彼此独立的。当然在算法要解决的实际问题中,各个自变量是否真的满足条件独立的假设,是一个大大的未知数。但是基于这个假设,算法所需要的数据空间从指数增长变成了线性增长。如果问题满足条件独立的假设,朴素贝叶斯是最佳的算法。如果假设不成立,因为分类问题寻找的是数据之间的分割线,在实际问题中,分类的效果也通常比较好。

综上所述,朴素贝叶斯算法最终把相对复杂的问题转化为:
- 根据训练数据去计算已经知道目标变量Y的情况下,各个自变量单独的概率分布P(Xi|Y)。计算每一个自变量维度的条件概率分布,需要我们结合实际数据去假设分布函数。常用的分布函数可以是一维高斯分布 (Gaussian distribution),简单多项式分布(Polynomial distribution),或者二项分布(Binomial distribution)。
- 根据训练数据去计算各个目标变量值的比例。
- 代入上述公式,可以比较目标变量Y为不同值1或0时候概率大小,从而给该事件预测标签。















 6200
6200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









