







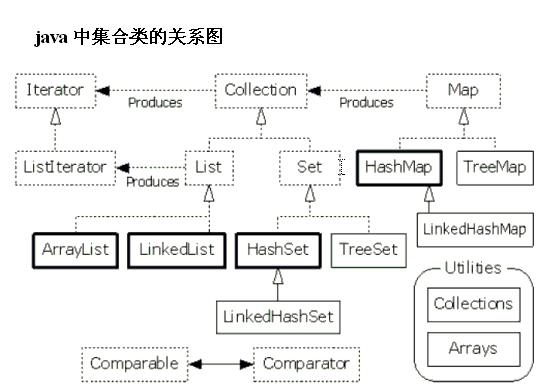
1 Set集合
1.1 Set集合概述
Set集合的元素是无序的,即存入的顺序和取出的顺序不一定是一致的。
Set集合中的元素不可以重复。
Set类是Collection的子类,所以Set集合的功能和Collection是一致的。
Set集合的取出方式只有一种:Iterator迭代器。
Set:元素是无序的(存入和取出的顺序不一定一致),元素不可以重复,保证了元素唯一性。
|--HashSet:哈希表结构,线程不同步。
|--TreeSet:二叉树结构,可以对Set集合中的元素进行排序。
1.2 HashSet集合
HashSet集合是Set集合的一种,所以具有Set集合的特点:元素无序且唯一。
HashSet是线程不同步的,无序、高效。
HashSet集合的数据结构是哈希表。
哈希表:
1,对集合元素对象中的关键字(特有数据),进行哈希算法的运算,得出一个具体的值,这个值成为哈希值。
2,哈希值就是这个元素的位置。
3,如果哈希值出现冲突,再去判断这个关键字对应的对象是否相同。如果对象相同,就不存储,因为元素重复。如果对象不同,就存储,在原来对象的哈希值基础 +1顺延。
4,存储哈希值的结构,我们称为哈希表。
5,既然哈希表是根据哈希值存储的,为了提高效率,最好保证对象的关键字是唯一的。
这样可以尽量少的判断关键字对应的对象是否相同,提高了哈希表的操作效率。
HashSet集合如何保证元素的唯一性?
是通过集合元素的两个方法:hashcode()和equals()来完成。
如果元素的HashCode值(哈希值)相同,才会判断equals是否为true。
如果元素的HashCode值不同,就不会再调用equals()方法。
碰到哈希表数据结构,就要想到hashcode()和equals(),比如HashSet、HashMap等。
注意:在HashSet集合中,对于判断元素是否已存在,以及删除等操作,依赖的方法是元素对象的hashcode()和equals()方法。
想删除元素,或判断元素,必须先判断hashcode(),再判断equals(),这就是HashSet集合的特点。
而在ArrayList集合中,判断元素是否已存在,只根据equals()方法。
HashSet集合代码示例:
import java.util.*;
class HashSetDemo2{
public static void main(String[] args){
HashSet hs = new HashSet();
hs.add(new Person("a1",11));
hs.add(new Person("a2",12));
hs.add(new Person("a3",13));
hs.add(new Person("a2",12)); //(a2,12)这个对象哈希地址值相同,再equals(),已有一个相同的对象
//这个(a2,12)就没有存入集合。
//sop("a1--:"+hs.contains(new Person("a1",11)));
Iterator it = hs.iterator();
while(it.hasNext()){
Person p = (Person)it.next();
sop(p.getName()+"..."+p.getAge());
}
}
public static void sop(Object obj){
System.out.println(obj);
}
}
class Person{
private String name;
private int age;
Person(String name,int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
/* hashCode()方法定义哈希值,哈希地址值相同,再判断是否是同一个对象,此时才用的equals(),
如果哈希地址值不同,就用不到equals()。
String定义了hashCode(); age*23 是为了防止不同对象姓名哈希值和age的和恰巧相同, */
public int hashCode(){
return name.hashCode()+age*23;
}
//自定义判断对象是否重复的规则
public boolean equals(Object obj){
if(!(obj instanceof Person))
return false;
Person p =(Person)obj;
System.out.println(this.name+"...equals..."+p.name);
return this.name.equals(p.name) && this.age==p.age;
}
}1.3 TreeSet集合
TreeSet集合的数据结构是二叉树。
TreeSet集合是Set集合的一种,同样有元素无序且唯一的特点。
TreeSet集合可以用来对Set集合中的元素进行排序。
TreeSet集合的代码示例:
import java.util.*;
class TreeSetDemo{
public static void main(String[] args){
TreeSet ts = new TreeSet();
ts.add("cba");
ts.add("abcd");
ts.add("aaa");
ts.add("bca"); //默认按照逐个字母的ASCII码值进行排序。
Iterator it = ts.iterator();
while(it.hasNext()){
sop(it.next());
}
}
public static void sop(Object obj){
System.out.println(obj);
}
}1.4 TreeSet集合第一种排序方式:元素自身必备比较性
TreeSet集合的第一种排序方式:让元素自身具备比较性。
元素需要实现Comparable接口,然后覆盖comparaTo()方法。这样元素自身就具备了比较性。
返回-1,则当前元素小于比较元素;返回1,则当前元素大于比较元素;返回0,则相同。
不做修改的默认顺序,也叫做自然顺序。
TreeSet第一种排序方式的代码示例:
import java.util.*;
class TreeSetDemo2{
public static void main(String[] args){
TreeSet ts = new TreeSet();
ts.add(new Student("lisi02",22));
ts.add(new Student("lisi007",20));
ts.add(new Student("lisi09",19));
ts.add(new Student("lisi01",19));
Iterator it = ts.iterator(); //迭代器遍历
while(it.hasNext()){
Student stu = (Student)it.next();
sop(stu.getName()+"..."+stu.getAge());
}
}
public static void sop(Object obj){
System.out.println(obj);
}
}
class Student implements Comparable { //该接口强制让学生具备比较性。
private String name;
private int age;
Student(String name,int age){
this.name = name;
this.age = age;
}
//覆盖接口Comparable中的compareTo方法,让学生具备比较性
public int compareTo(Object obj){
if(!(obj instanceof Student))
throw new RuntimeException("不是学生对象");
Student s = (Student)obj;
System.out.println(this.name+"...compareTo..."+s.name);
if(this.age>s.age)
return 1;
if(this.age==s.age)
//年龄相同时按姓名排序。String类实现了Comparable接口。
return this.name.compareTo(s.name);
return -1;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
}1.5 TreeSet集合第二种排序方式:集合具备比较性
当元素自身不具备比较性,或者具备的比较性不是所需要的。
这时就需要让容器TreeSet自身具备比较性。
定义一个比较器Comparator,将比较器对象作为参数传递给TreeSet集合的构造函数。
自定义的Comparator的子类,需要覆盖compare()方法,据此进行比较,然后将这个子类对象传递给TreeSet的构造函数,TreeSet集合就具备了比较性。
两种排序方式,Comparator比较器的方式比较好。
需求:将上一节代码TreeSetDemo2,从按照年龄排序改成按照姓名排序。
定义一个类,实现Comparator比较器接口,覆盖compare()方法。
注意区别:Comparable接口中是compareTo()方法;而Comparator接口中是compare()方法。
同样是根据return的值来判断顺序。
请看代码示例:
import java.util.*;
class TreeSetDemo3{
public static void main(String[] args){
TreeSet ts = new TreeSet(new MyComparator()); //将比较器对象传递给TreeSet构造函数。
ts.add(new Student("lisi02",22));
ts.add(new Student("lisi007",20));
ts.add(new Student("lisi09",19));
ts.add(new Student("lisi01",19));
Iterator it = ts.iterator();
while(it.hasNext()){
Student stu = (Student)it.next();
sop(stu.getName()+"..."+stu.getAge());
}
}
public static void sop(Object obj){
System.out.println(obj);
}
}
class Student implements Comparable { //该接口强制让学生具备比较性:按年龄排序
private String name;
private int age;
Student(String name,int age){
this.name = name;
this.age = age;
}
public int compareTo(Object obj){ //覆盖接口Comparable中的方法,进行比较
if(!(obj instanceof Student))
throw new RuntimeException("不是学生对象");
Student s = (Student)obj;
System.out.println(this.name+"...compareTo..."+s.name);
if(this.age>s.age)
return 1;
if(this.age==s.age)
return this.name.compareTo(s.name); //年龄相同是按姓名排序。
//String类实现了Comparable接口。
return -1;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
}
class MyComparator implements Comparator{ //比较器方法:实现Comparator接口,传递给TreeSet构造函数
public int compare(Object o1,Object o2){ //从而使TreeSet集合具有比较性,按照姓名排序
Student s1 = (Student)o1;
Student s2 = (Student)o2;
return s1.getName().compareTo(s2.getName());
}
}1.6 TreeSet小练习
需求:根据字符串的长度进行排序。
使用第二中排序方式:比较器Comparator。
字符串String类的比较方法compareTo()比较的是自然顺序,不是我们想要的。
所以使用Comparator比较器方式。
比较时可以使用Integer基本数据类型包装类,比较int类型的自然顺序。
代码和注释:
import java.util.*;
class TreeSetTest{
public static void main(String[] args){
TreeSet ts = new TreeSet(new StrComparator()); //比较器传递给TreeSet构造函数。
ts.add("abcd");
ts.add("cc");
ts.add("cba");
ts.add("aaa");
ts.add("hahaha");
Iterator it = ts.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
class StrComparator implements Comparator{
public int compare(Object o1,Object o2){
String s1 = (String)o1;
String s2 = (String)o2;
/* if(s1.length() < s2.length())
return -1;
if(s1.length()==s2.length())
return 0;
return 1; */
//基本数据类型包装类Integer的compareTo()方法,比较自然顺序。
int num = new Integer(s1.length()).compareTo(new Integer(s2.length()));
if(num==0) //如果字符串长度相同,再比较自然顺序。
return s1.compareTo(s2); //调用String类的compareTo方法,根据自然顺序比较。(ASCII码)
return num;
}
}2 Map集合
2.1 Map集合概述
Map集合和Collection集合不同,Collection集合存储的是一个元素,一个一个的存。
Map集合存储的是键值对(键:key,值:value),一对一对的往里存,键和值有映射关系。
而且,要保证Map集合中“键”的唯一性。
Map(注意HashTable和HashMap的相同和不同)
HashTable:底层是哈希表数据结构,不可以存入null键和null值,该集合是线程同步的,(键和值不能为空,效率较低)。
HashMap:底层是哈希表数据结构,可以存入null键和null值,该集合是线程不同步的,(键和值可以为空,效率较高)。
TreeMap:底层是二叉树数据结构,线程不同步,该集合可以用于给Map集合的键进行排序。
2.2 Map集合共性方法:
1,添加。
put(K key, V value):添加一个键值对,返回原来与“键”对应的“值”,没有则返回null。
putAll(Map<? extends K, ? extends V> m):从指定映射中将所有映射关系复制到此映射中。
2,删除。
clear():清空所有键值对。
removed(Object key):如果存在指定键的键值对,移除此键值对,并返回Value值。若不存在指定键的键值对,返回null。
3,判断。
containsValue(Object value):是否包含有值为value的键值对,有的话返回true。
containsKey(Object key):是否包含有键为key的键值对,有的话返回true。
isEmpty():判断集合是不是空的。
4,获取。
get(Object key):根据“键”返回“值”。
size():返回“键值对”的个数。
values():返回一个Collection集合,此集合中存储的是当前Map集合中所有“值”。
Map集合共性方法的简单代码示例:
import java.util.*;
class MapDemo{
public static void main(String[] args){
Map<String,String> map = new HashMap<String,String>(); //集合的多态
/* 添加元素
put方法的返回值是,返回原来与“键”对应的“值”,没有则返回null。
这三个put方法都是返回null。 */
map.put("01","zhangsan");
map.put("02","lisi");
map.put("03","wangwu");
System.out.println("containsKey: "+map.containsKey("022")); //判断
//System.out.println("remove: "+map.remove("02")); //删除元素
System.out.println("get: "+map.get("02")); //获取,get()根据“键”返回“值”。
//可以通过get()方法的返回值来判断一个键是否存在,通过返回null来判断。
//获取Map集合中所有的值。
Collection<String> coll = map.values();
System.out.println("coll: "+coll);
System.out.println("map: "+map);
}
}2.3 Map集合的两种取出方式
Set<K> keySet();
Set<Map.Entry<K,Y>> entrySet();
Map集合的取出原理:将Map集合转换成Set集合,再通过迭代器取出。
1,keySet:将Map集合中所有的“键”存入到Set集合,因为Set有迭代器。
所以能使用迭代方式去除所有的“键”,再根据get方法,获取对应的“值”。
2,entrySet:将Map集合中的映射关系取出,这个映射关系就是Map.Entry类型,即“键值对”。
那么Map.Entry获取到后,就可以通过Map.Entry中的getKey和getValue方法,获取映射关系中的“键”和“值”。
接口Map.Entry介绍:
其实Entry也是一个借口,它是Map接口中的一个内部接口。
interface Map{
public static interface Entry{ //子接口
public abstract Object getKey();
public abstract Object getValue();
}
}
Map集合两种取出方式的代码示例:
import java.util.*;
class MapDemo2{
public static void main(String[] args){
method_keySet();
method_entrySet();
}
public static void method_keySet(){
Map<String,String> map = new HashMap<String,String>();
map.put("02","zhangsan");
map.put("03","lisi");
map.put("01","wangwu");
//先获取Map集合的所有“键”的Set集合,keySet();
Set<String> ks = map.keySet();
//有了Set集合,就可以获取其迭代器。
Iterator<String> it = ks.iterator();
while(it.hasNext()){
String key = it.next();
String value = map.get(key); //有了“键”,可以通过Map集合的get方法取得对应的“值”
System.out.println("ketSet_Key: "+key+" ketSet_value: "+value);
}
}
public static void method_entrySet(){
Map<String,String> map = new HashMap<String,String>();
map.put("02","zhangsan");
map.put("03","lisi");
map.put("01","wangwu");
/* 将Map集合中的映射关系取出,存入到Set集合中。
此entrySet()方法返回值类型是Map.Entry<String,String>。 */
Set<Map.Entry<String,String>> en = map.entrySet();
Iterator<Map.Entry<String,String>> it = en.iterator();
//迭代器的next()方法返回类型与Iterator的元素类型一样。
while(it.hasNext()){
Map.Entry<String,String> me = it.next();
String key = me.getKey();
String value = me.getValue();
System.out.println("entrySet_Key: "+key+" entrySet_value: "+value);
}
}
}2.4 HashMap集合
底层是哈希表数据结构,可以存入null键和null值,该集合是线程不同步的,(键和值可以为空,效率较高)。
HashMap集合小练习:
需求:
每一个学生对象都有都有对应的归属地(学生Student,地址String)。
学生属性:姓名,年龄。注意:姓名和年龄相同的,视为同一个学生。
保证学生的唯一性。
思路:
1,Student类描述学生。
2,定义一个Map容器,将学生作为“键”,地址作为“值”,存入。
3,获取Map集合中的键值对,再依次获取键和值。
代码:
import java.util.*;
class HashMapTest{
public static void main(String[] args){
HashMap<Student,String> map = new HashMap<Student,String>();
map.put(new Student("zhangsan",21),"Beijing");
map.put(new Student("lisi",22),"Shanghai");
map.put(new Student("wangwu",23),"Wuhan");
map.put(new Student("wangwu",23),"Changsha");
//获取存储键值对的Set集合。
Set<Map.Entry<Student,String>> s = map.entrySet();//迭代器
Iterator<Map.Entry<Student,String>> it = s.iterator();
while(it.hasNext()){
Map.Entry<Student,String> me = it.next();
Student key = me.getKey();
String value = me.getValue();
System.out.println("学生姓名:"+key.getName()+" 学生年龄:"+key.getAge()+" 地址:"+value);
}
}
}
class Student implements Comparable<Student> { //实现Comparable接口,使Student具有比较性。
public String name;
public int age;
Student(String name,int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
public int hashCode(){ //hashCode()和equals()保证唯一性。保证“键”的唯一性。
return name.hashCode()+age*23;
}
public boolean equals(Object obj) {
if(!(obj instanceof Student))
throw new ClassCastException("类型不匹配"); //ClassCastException 是 RuntimeException的子类,可以不处理。
Student s = (Student)obj;
return this.name.equals(s.name) && this.age==s.age;
}
public int compareTo(Student s){ //重写Comparable接口的compareTo()方法,定义比较性。
int num = new Integer(this.age).compareTo(new Integer(s.age));
if(num==0)
return this.name.compareTo(s.name);
return num;
}
}2.5 TreeMap集合
底层是二叉树数据结构,线程不同步,该集合可以用于给Map集合的键进行排序。
TreeMap集合小练习:
需求:按照学生对象的姓名进行排序。
因为数据是以“键-值”对的形式存在,所以要使用可以排序的Map集合:TreeMap。
TreeMap集合的构造方法可以传递Comparator比较器,而HashMap不可以。
集合构造方法传递Comparator比较器,可以使集合自身具备比较性。
代码:
import java.util.*;
class TreeMapTest{
public static void main(String[] args){
TreeMap<Student,String> tm = new TreeMap<Student,String>(new StuNameComparator());
tm.put(new Student("zhangsan",22),"Beijing");
tm.put(new Student("lisi",21),"Shanghai");
tm.put(new Student("wangwu",23),"Wuhan");
tm.put(new Student("wangwu",23),"Changsha");
Set<Map.Entry<Student,String>> en = tm.entrySet();
Iterator<Map.Entry<Student,String>> it = en.iterator(); //迭代器
while(it.hasNext()){
Map.Entry<Student,String> me = it.next();
Student key = me.getKey();
String value = me.getValue();
System.out.println("学生姓名:"+key.getName()+" 学生年龄:"+key.getAge()+" 地址:"+value);
}
}
}
class Student {
public String name;
public int age;
Student(String name,int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
public int hashCode(){ //hashCode()和equals()保证唯一性。保证“键”的唯一性。
return name.hashCode()+age*23;
}
public boolean equals(Object obj) {
if(!(obj instanceof Student))
throw new ClassCastException("类型不匹配"); //ClassCastException 是 RuntimeException的子类,可以不处理。
Student s = (Student)obj;
return this.name.equals(s.name) && this.age==s.age;
}
/* public int compareTo(Student s){ //重写Comparable接口的compareTo()方法,使集合的元素具备比较性。
int num = new Integer(this.age).compareTo(new Integer(s.age));
if(num==0)
return this.name.compareTo(s.name);
return num;
} */
}
class StuNameComparator implements Comparator<Student> { //实现Comparator比较器,使集合自身具备比较性。
public int compare(Student s1,Student s2){
int num = s1.getName().compareTo(s2.getName());
if(num == 0)
return new Integer(s1.getAge()).compareTo(new Integer(s1.getAge()));
return num;
}
}2.6 TreeMap集合练习
需求:
“sdfssdsdqwqewdfzzxcxc”获取该字符串中的字母出现的次数。
希望打印结果:a(1)c(2)......
通过结果发现,每一个字母都有对应的次数。
说明字母和次数之间都有映射关系。
注意:当发现有映射关系时,可以选择Map集合,因为Map集合中存放的就是映射。当数据之间存在着映射关系时,就要先想到Map集合。
思路:
1,将字符串转换成字符数组,因为要对每一个字母进行操作。
2,定义一个Map集合,因为打印结果的字母有顺序,所以使用TreeMap集合。
3,遍历字符数组:
将每一个字母作为“键”去查Map集合。
如果返回null,就将该字母和数字1存入Map集合(字母是键,数字1是值)。
如果返回不是null,则说明该字母在Map集合已经存在并有对应次数。
那么就获取该次数并进行自增,然后将该字母和自增后的次数,存入Map集合。
4,将Map集合中的数据变成指定的字符串形式返回。
代码示例:
import java.util.*;
class TreeMapTest2 {
public static void main(String[] args){
charCount("sdfssdsdqwqewdfzzxcxc");
}
public static void charCount(String str){
char[] chs = str.toCharArray();
//泛型中的是引用类型,所以要用基本数据类型包装类。
TreeMap<Character,Integer> tm = new TreeMap<Character,Integer>();
for(int x=0;x<chs.length;x++){
Integer value = tm.get(chs[x]); //Map集合的get方法,根据“键”返回“值”
if(value==null)
tm.put(chs[x],1);
else{
value = value+1;
tm.put(chs[x],value);
}
}
System.out.println(tm);
StringBuilder sb = new StringBuilder(); //利用缓冲区StringBuider,打结果。
Set<Map.Entry<Character,Integer>> en = tm.entrySet();
Iterator<Map.Entry<Character,Integer>> it = en.iterator();
while(it.hasNext()){
Map.Entry<Character,Integer> me = it.next();
Character ch = me.getKey();
Integer in = me.getValue();
sb.append(ch+"("+in+")");
}
System.out.println(sb);
}
}3. Map集合扩展知识:集合嵌套集合
集合嵌套集合,即集合的元素中包含集合。
Map集合被使用,是因为具备映射关系。
"yureban" "01" "zhangsan"
"yureban" "02" "lisi"
"jiuyeban" "01" "wangwu"
"jiuyeban" "02" "zhaoliu"
代码示例:
import java.util.*;
class MapDemo3{
public static void main(String[] args){
HashMap<String,String> yure = new HashMap<String,String>();
yure.put("01","zhangsan");
yure.put("02","lisi");
HashMap<String,String> jiuye = new HashMap<String,String>();
jiuye.put("01","wangwu");
jiuye.put("02","zhaoliu");
HashMap<String,HashMap<String,String>> czbk = new HashMap<String,HashMap<String,String>>();
czbk.put("yureban",yure);
czbk.put("jiuyeban",jiuye);
//getStudentInfo(jiuye);
//getStudentInfo(yure);
//遍历czbk集合,获取所有的教室
Iterator<String> it = czbk.keySet().iterator();
while(it.hasNext()){
String key = it.next();
HashMap<String,String> value = czbk.get(key);
getStudentInfo(value);
}
}
public static void getStudentInfo(HashMap<String,String> roomMap){
Iterator<String> it = roomMap.keySet().iterator();
while(it.hasNext()){
String id = it.next();
String name = roomMap.get(id);
System.out.println(id+":"+name);
}
}
}















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









