






Datawhale 知识图谱组队学习 Task 5 Neo4j 图数据库查询
一、 Neo4介绍
- Neo4j是一个世界领先的开源图形数据库,由Java编写。图形数据库也就意味着它的数据并非保存在表或集合中,而是保存为节点以及节点之间的关系;
- Neo4j的数据由下面3部分构成:节点、边和属性;
- Neo4j除了顶点(Node)和边(Relationship),还有一种重要的部分——属性。无论是顶点还是边,都可以有任意多的属性。属性的存放类似于一个HashMap,Key为一个字符串,而Value必须是基本类型或者是基本类型数组。
在Neo4j中,节点以及边都能够包含保存值的属性,此外:可以为节点设置零或多个标签(例如Author或Book)每个关系都对应一种类型(例如WROTE或FRIEND_OF)关系总是从一个节点指向另一个节点(但可以在不考虑指向性的情况下进行查询)
二、 Neo4j 介绍
3.1 Cypher 介绍
- Cypher 介绍:作为Neo4j的查询语言,“Cypher”是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询。Cypher还在继续发展和成熟,这也就意味着有可能会出现语法的变化。同时也意味着作为组件没有经历严格的性能测试。
- 设计的目的:一个人类查询语言,适合于开发者和在数据库上做点对点模式(ad-hoc)查询的专业操作人员(我认为这个很重要)。它的构念是基于英语单词和灵巧的图解。
- 思路:Cyper通过一系列不同的方法和建立于确定的实践为表达查询而激发的。许多关键字如like和order by是受SQL的启发。模式匹配的表达式来自于SPARQL。正则表达式匹配实现实用Scala programming language语言。
- 与命令式语言的区别:Cypher是一个申明式的语言。对比命令式语言如Java和脚本语言如Gremlin和JRuby,它的焦点在于从图中如何找回(what to retrieve),而不是怎么去做。这使得在不对用户公布的实现细节里关心的是怎么优化查询。
3.2 Neo4j 图数据库 查询
- 连接neo4j数据库之后,在浏览器中使用http://localhost:7474/browser/网址查看数据库,初始账户跟密码都是neo4j
- 首先查看图数据库
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZzbW46hP-1610371911333)(./assets/展示图2.jpg)]](https://img-blog.csdnimg.cn/20210111213347199.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MzjmPdq9-1610371911335)(task05.assets/image-20210111205743988.png)]](https://img-blog.csdnimg.cn/20210111213407347.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
图 1 展示图 1

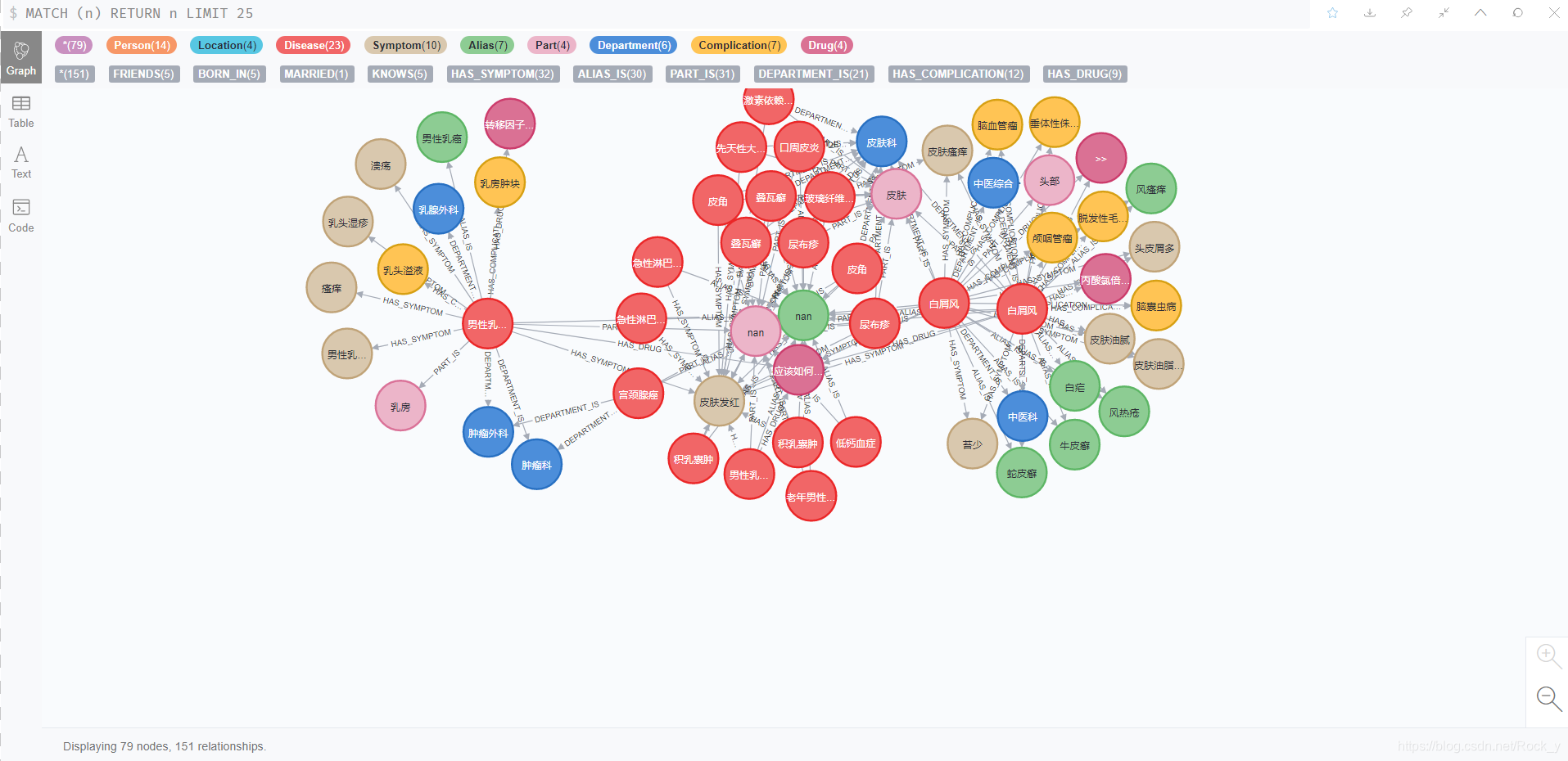
图 2 展示图 2
- 导入的数据的知识图谱
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AsRM4NPc-1610371911340)(./assets/种类.png)]](https://img-blog.csdnimg.cn/20210111213628785.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
图 3 图谱类型
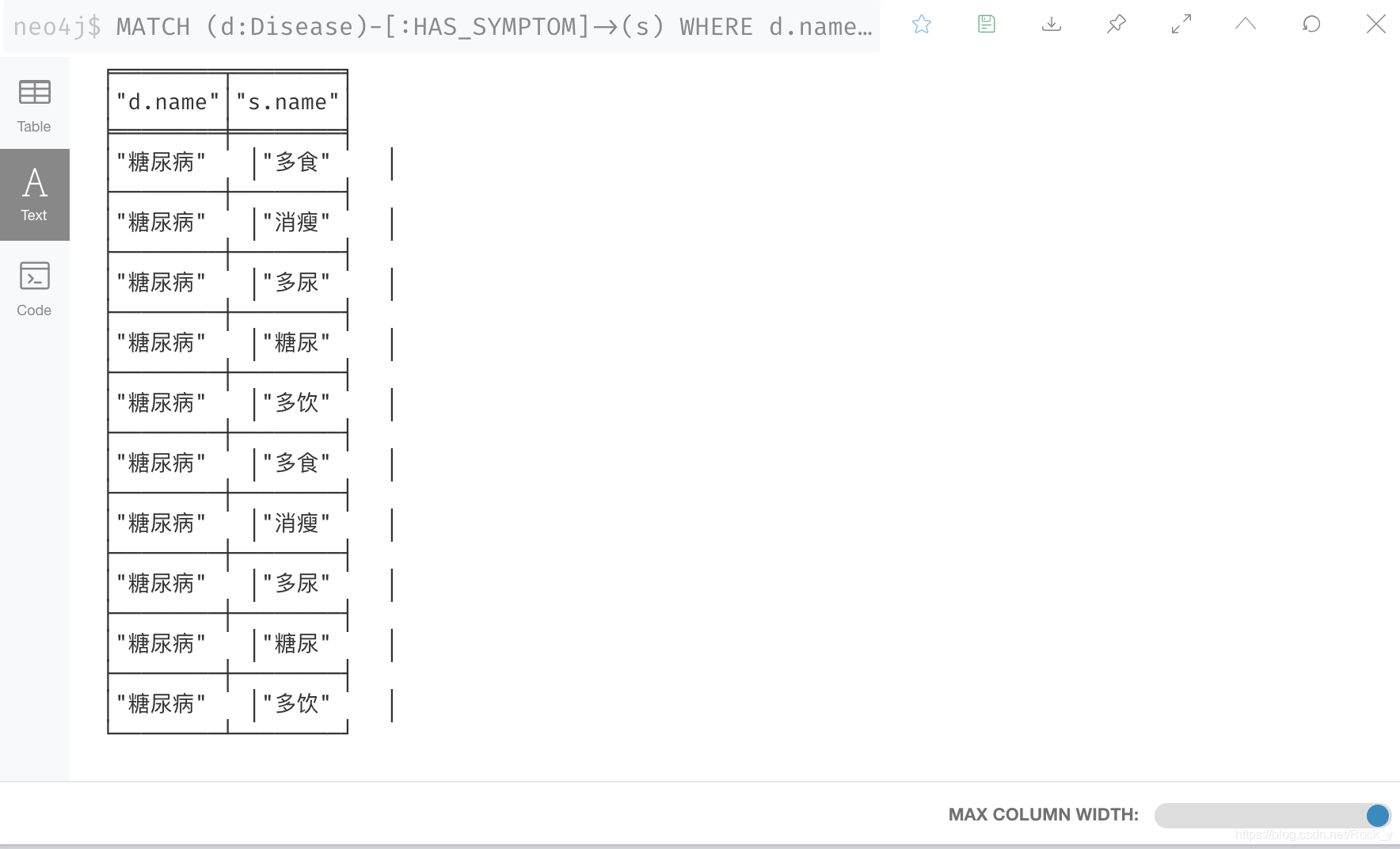
- 我们首先查询症状:输入语句:
MATCH (d:Disease)-[:HAS_SYMPTOM]->(s) WHERE d.name='糖尿病' RETURN d.name,s.name
返回可以是Table,Text,跟code
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w7TnCFlo-1610371911341)(./assets/table.jpg)]](https://img-blog.csdnimg.cn/20210111213648884.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7JuJ6R5H-1610371911342)(task05.assets/image-20210111205852074.png)]](https://img-blog.csdnimg.cn/20210111213658344.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
图 4 查询结果 表格展示
![> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WK7nAeCV-1610371911342)(./assets/Text.png)]](https://img-blog.csdnimg.cn/2021011121380450.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
图 5 查询结果 文本展示
![> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NwbyZcu4-1610371911343)(./assets/code.jpg)]](https://img-blog.csdnimg.cn/20210111213833518.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
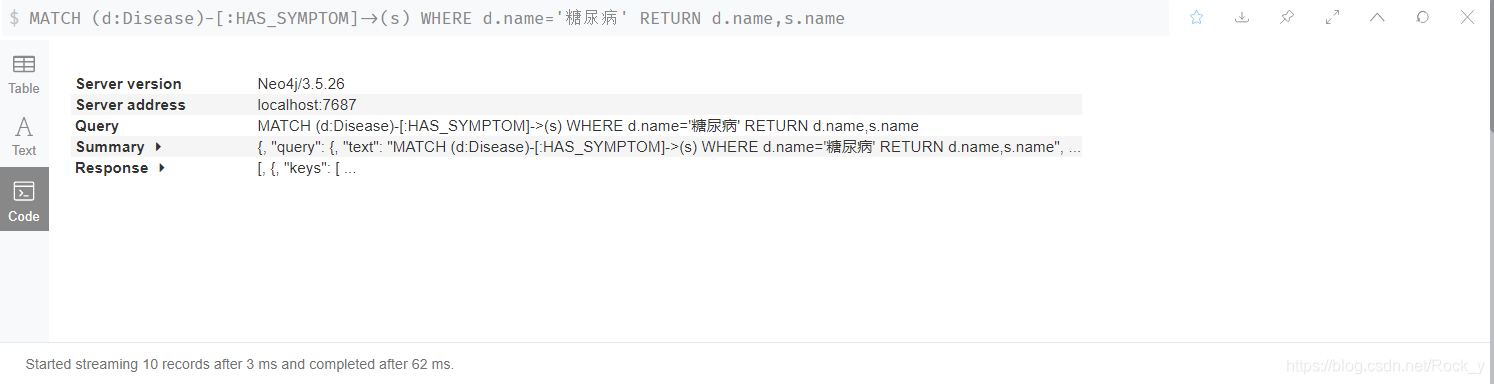
图 6 查询结果 代码展示
四、 基于知识图谱的问题系统 主体类 AnswerSearching 框架介绍
class AnswerSearching:
def __init__(self):
pass
# 主要是根据不同的实体和意图构造cypher查询语句
def question_parser(self, data):
"""
主要是根据不同的实体和意图构造cypher查询语句
:param data: {"Disease":[], "Alias":[], "Symptom":[], "Complication":[]}
:return:
"""
pass
# 将问题转变为cypher查询语句
def transfor_to_sql(self, label, entities, intent):
"""
将问题转变为cypher查询语句
:param label:实体标签
:param entities:实体列表
:param intent:查询意图
:return:cypher查询语句
"""
pass
# 执行cypher查询,返回结果
def searching(self, sqls):
"""
执行cypher查询,返回结果
:param sqls:
:return:str
"""
pass
# 根据不同意图,返回不同模板的答案
def answer_template(self, intent, answers):
"""
根据不同意图,返回不同模板的答案
:param intent: 查询意图
:param answers: 知识图谱查询结果
:return: str
"""
pass
五、 代码分模块介绍
-
在Python中我们使用py2neo进行查询
-
首先安装py2neo,
pip install py2neo注意:在运行下面代码的时候会提示需要安装ahocorasick包,此时不能直接
pip install ahocorasick应该将ahocorasick变成pyahocorasick,
应该将ahocorasick变成pyahocorasick,
pip install pyahocorasick -
连接上neo4j数据库
from py2neo import Graph
graph = Graph("http://localhost:7474", username="neo4j", password="neo4j")
- 根据不同的实体和意图构造cypher查询语句
def question_parser(data):
"""
主要是根据不同的实体和意图构造cypher查询语句
:param data: {"Disease":[], "Alias":[], "Symptom":[], "Complication":[]}
:return:
"""
sqls = []
if data:
for intent in data["intentions"]:
sql_ = {}
sql_["intention"] = intent
sql = []
if data.get("Disease"):
sql = transfor_to_sql("Disease", data["Disease"], intent)
elif data.get("Alias"):
sql = transfor_to_sql("Alias", data["Alias"], intent)
elif data.get("Symptom"):
sql = transfor_to_sql("Symptom", data["Symptom"], intent)
elif data.get("Complication"):
sql = transfor_to_sql("Complication", data["Complication"], intent)
if sql:
sql_['sql'] = sql
sqls.append(sql_)
return sql
- 将问题转变为cypher查询语句
def transfor_to_sql(label, entities, intent):
"""
将问题转变为cypher查询语句
:param label:实体标签
:param entities:实体列表
:param intent:查询意图
:return:cypher查询语句
"""
if not entities:
return []
sql = []
# 查询症状
if intent == "query_symptom" and label == "Disease":
sql = ["MATCH (d:Disease)-[:HAS_SYMPTOM]->(s) WHERE d.name='{0}' RETURN d.name,s.name".format(e)
for e in entities]
# 查询治疗方法
if intent == "query_cureway" and label == "Disease":
sql = ["MATCH (d:Disease)-[:HAS_DRUG]->(n) WHERE d.name='{0}' return d.name,d.treatment," \
"n.name".format(e) for e in entities]
# 查询治疗周期
if intent == "query_period" and label == "Disease":
sql = ["MATCH (d:Disease) WHERE d.name='{0}' return d.name,d.period".format(e) for e in entities
...
- 执行cypher查询,返回结果
def searching(sqls):
"""
执行cypher查询,返回结果
:param sqls:
:return:str
"""
final_answers = []
for sql_ in sqls:
intent = sql_['intention']
queries = sql_['sql']
answers = []
for query in queries:
ress = graph.run(query).data()
answers += ress
final_answer = answer_template(intent, answers)
if final_answer:
final_answers.append(final_answer)
return final_answers
- 根据不同意图,返回不同模板的答案
def answer_template(intent, answers):
"""
根据不同意图,返回不同模板的答案
:param intent: 查询意图
:param answers: 知识图谱查询结果
:return: str
"""
final_answer = ""
if not answers:
return ""
# 查询症状
if intent == "query_symptom":
disease_dic = {}
for data in answers:
d = data['d.name']
s = data['s.name']
if d not in disease_dic:
disease_dic[d] = [s]
else:
disease_dic[d].append(s)
i = 0
for k, v in disease_dic.items():
if i >= 10:
break
final_answer += "疾病 {0} 的症状有:{1}\n".format(k, ','.join(list(set(v))))
i += 1
...
运行结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kclzp1oc-1610371911345)(task05.assets/image-20210111213108675.png)]](https://img-blog.csdnimg.cn/20210111213917853.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
数据量还是太少了呀!














 9033
9033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









