






 粗糙集理论是数据挖掘的重要工具,用于决策和维度约简。它涉及属性重要性、依赖度、属性约简及决策规则的定义。属性约简旨在去除冗余和不重要的属性,保持决策系统的有效性。决策规则描述了对象的决策逻辑。通过属性约简和决策规则,粗糙集理论能帮助简化复杂数据,提高决策效率。
粗糙集理论是数据挖掘的重要工具,用于决策和维度约简。它涉及属性重要性、依赖度、属性约简及决策规则的定义。属性约简旨在去除冗余和不重要的属性,保持决策系统的有效性。决策规则描述了对象的决策逻辑。通过属性约简和决策规则,粗糙集理论能帮助简化复杂数据,提高决策效率。
粗糙集理论的简单应用
粗糙集理论常用于数据挖掘领域中的决策以及维度约简。下面稍微介绍一下:
属性的重要性、属性约简和核
设有决策系统
S
=
(
U
,
C
∪
D
,
V
,
f
)
S=(U,C\cup D,V,f)
S=(U,C∪D,V,f),则决策属性D在条件属性C下的正域(简称D的C正域)定义为:
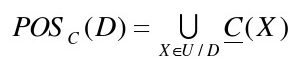
D的C正域是中通过用分类U/C表达的知识能够准确的划入U/D
类的对象的对象集合,
决策属性D对条件属性C的依赖都定义为:
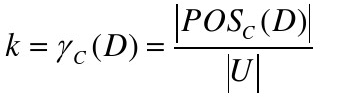
依赖度表示在条件属性集下能够准确切划入决策分类U/D的对象占论域中的总队形数的比率,表达了决策属性对条件属性的的依赖程度。
属性子集
C
′
∈
C
C'\in C
C′∈C的属性重要程度定义为:
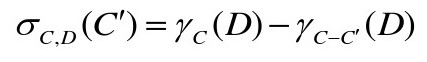
特别的,当
C
′
=
{
a
}
C'=\{a\}
C′={a}时,属性
a
∈
C
a\in C
a∈C关于D的重要性为:
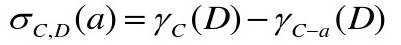
属性约简
定义:在保持决策表条件属性和决策属性的前提下,删除其中不相关或者不重要的属性。
定义:对于一个给定的决策系统, S = ( U , C ∪ D , V , f ) S=(U,C\cup D,V,f) S=(U,C∪D,V,f),如果 P O S C ( D ) POS_C(D) POSC(D)= P O S C − a ( D ) POS_{C-a}(D) POSC−a(D),则称属性a为C中D可省略,否则属性a为C中D不可省略。
定义:对于一个给定的决策系统,条件属性集c的D约简时c的一个非空子集P,如果满足
(1)任意
a
∈
P
a\in P
a∈P,
a
a
a都是D不可省略的
(2)
P
O
S
P
(
D
)
POS_P(D)
POSP(D)=
P
O
S
C
(
D
)
POS_C(D)
POSC(D)
则称P是C的一个约简。
C中所有的约简记
R
E
D
D
(
C
)
RED_D(C)
REDD(C),C中所有不可省略属性的集合称之为C的核,记为
C
O
R
E
D
(
C
)
CORE_D(C)
CORED(C)
决策规则和算法
决策表中的每一个对象都可以看作是一条决策规则。因此,决策表实际上是一组逻辑组合规则。
定义:在逻辑决策语言中,蕴含
θ
\theta
θ和
ϕ
\phi
ϕ称为决策逻语言中的决策规则,
θ
\theta
θ和
ϕ
\phi
ϕ分别称为决策规则的前件和后件。
(后面概念很多,这里不详述了,具体见如下ppt)




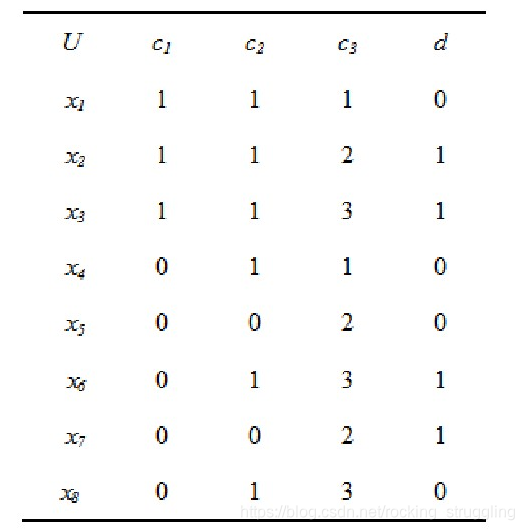
算例分析:
对于如下信息系统(决策表):



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









