






原文链接:https://zhuanlan.zhihu.com/p/161540817
基本概念
RoI
RoI(Region of Interest)是通过不同区域选择方法,从原始图像(original image)得到的候选区(proposal region)。需要注意的一点是RoI并不等价于bounding box, 它们可能看起来像,但是RoI只是为了进一步处理而产生的候选区域。
bounding box
boundding box* 指的是检测目标的边界矩形框。
量化
量化(quatization)是指将输入从连续值(或大量可能的离散取值)采样为有限多个离散值的过程。也可以理解为,将输入数据集(如实数)约束到离散集(如整数)的过程。
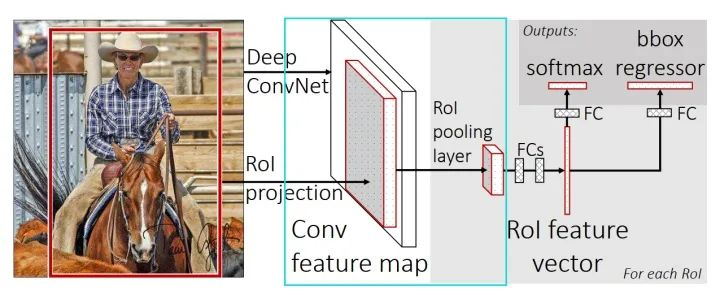
RoI Pooling 原理
RoI Pooling在Fast RCNN 中被首次提出。
RoI Pooling 直接从feature map 里截取各个兴趣区域(Region of Interest, RoI)的feature, 并换为为相同大小的feature输出。
RoI Pooling = crop feature + resize feature
执行步骤
1)前置条件
对于输入图片,通过候选区域方法发网得固定大小数量(Faster RCNN中为256)的候选区域坐标,。
将整个输入图片喂入基网络(如vgg, resnet等)提取图片的特征(Fast RCNN 中为vgg网络的conv5层特征)。
下面以输出目标特征图尺寸大小为2×2×512 进行说明
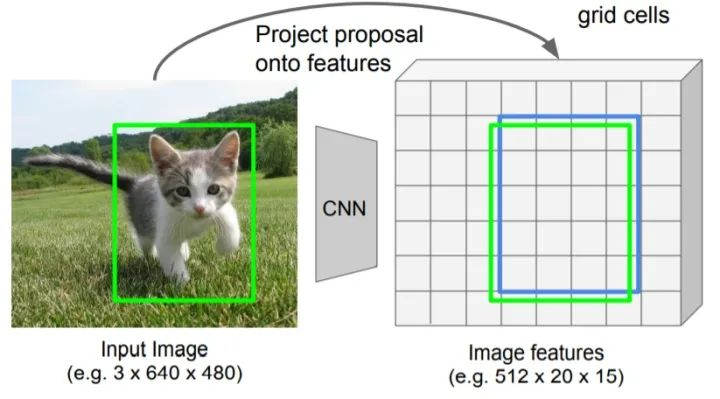
对齐到网格单元(snap to grid cell)
首先将一个浮点数RoI量化为特征映射的离散粒度。表现为RoI对应的特征图的与原始特征图的网格单元对齐。这里为第一次量化操作。
下图中绿色框为RoI对应的实际区域(由于经过特征尺度变换,导致RoI的坐标会可能会落到特征图的单元之间), 蓝色框代表量化(网格对齐)后的RoI所对应的特征图。(得到到量化特征图尺寸为 5×7×512 )
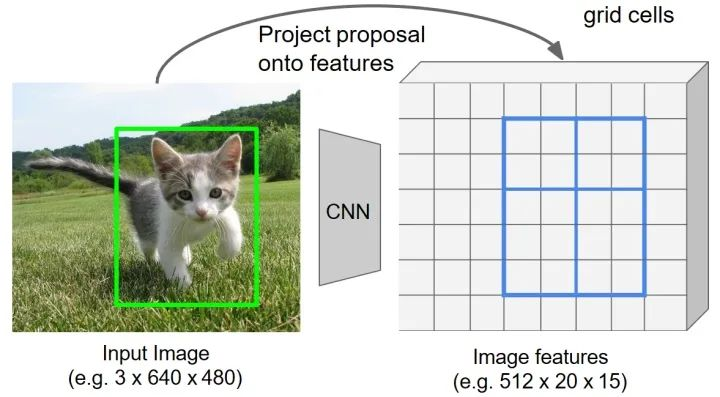
2)划分网格为子区域(bin)
粗略地将网格分为H×W (Fast RCNN 中设为 7×7)个子网格区域。将上一步得到的量化RoI 特征进一步细分为量化的空间单元(bin)。这里进行了第二次量化操作。
为了得到输出的特征图为 2×2×512,这里的量化操作就是将上一步的到量化特征图划分为 2×2个特征单元。如果无法通过直接均分得到量化的子区域,通过分别采取向上取整(ceil)和向下取整(floor)的到对应的单元尺寸大小。以当前 4×5尺寸的特征图为例,对于宽度方向4/2=2,,但是对于高度方向由于5/2=2.5 , 通过向上和向下取整整,确定高度方向特征子区域的大小分别为2和3。
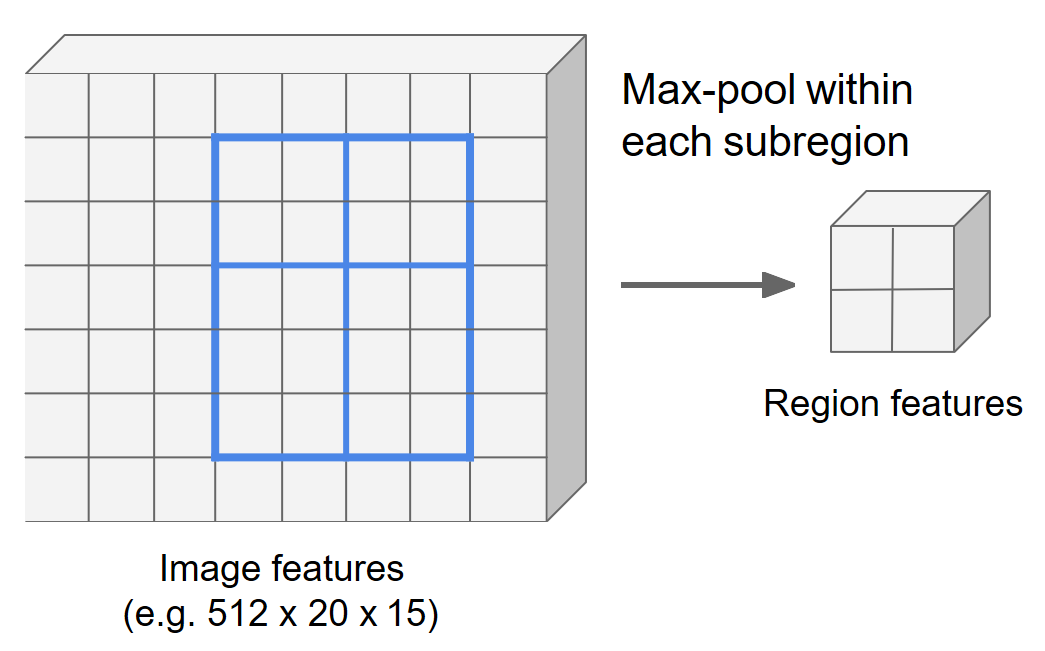
3)最大池化操作
在每一个子区域执行聚合操作得到单元的特征值(一般是最大池化)。对上一步得到的 2×2个子区域分别做最大池化操作,得到2×2×512的目标特征图。
执行结果
通过RoI Pooling, 对于具有不同特征大小的的输入区域, 都可以得到相同大小输出特征。
缺点
每一次量化操作都会对应着轻微的区域特征错位(misaligned), 这些量化操作在RoI和提取到的特征之间引入了偏差。这些量化可能不会影响对分类任务,但它对预测像素精度掩模有很大的负面影响。
RoI Align 原理
RoI Align 在 Mask RCNN 中被首次提出。
针对RoI Pooling在语义分割等精细度任务中精确度的问题提出的改进方案。
执行步骤
下面以输出目标特征图尺寸大小为2×2×512进行说明
1)遍历候选每个候选区域,保持浮点数边界不做量化(不对齐网格单元);同时平均分网格分为 H×W (这里为2×2)个子网格区域,每个单元的边界也不做量化。
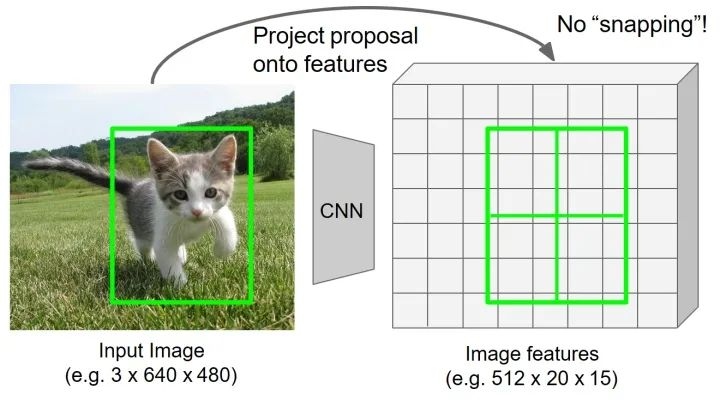
2)对于每个区域选择4个规则采样点(分别对应将区域进一步平均分为四个区域,取每个子区域的中点)。

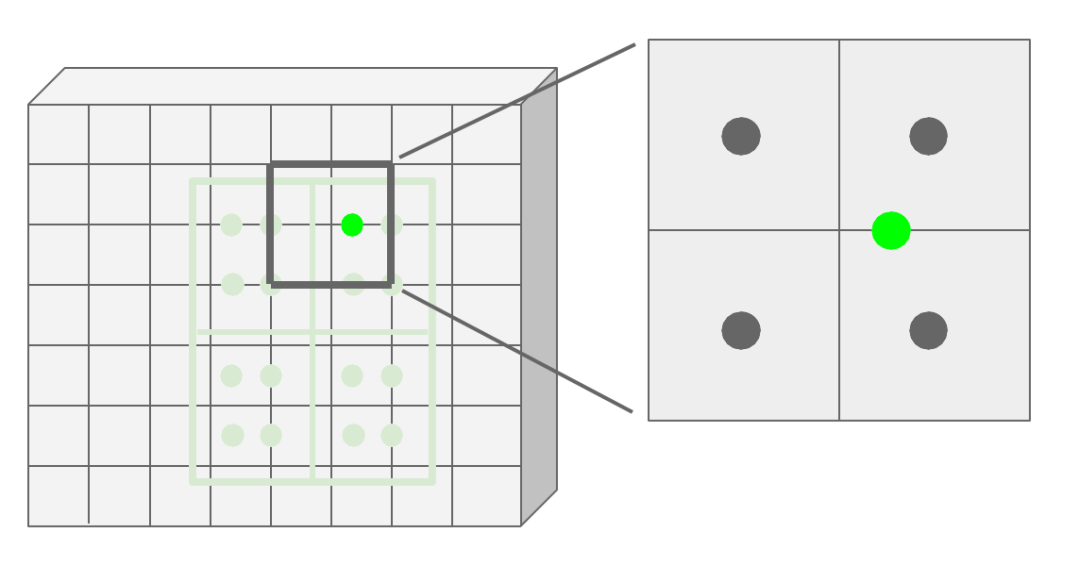
3)利用双线性插值计算得到四个采用点的像素值大小。下图为一个规则采样点所对应的邻近区域示意图
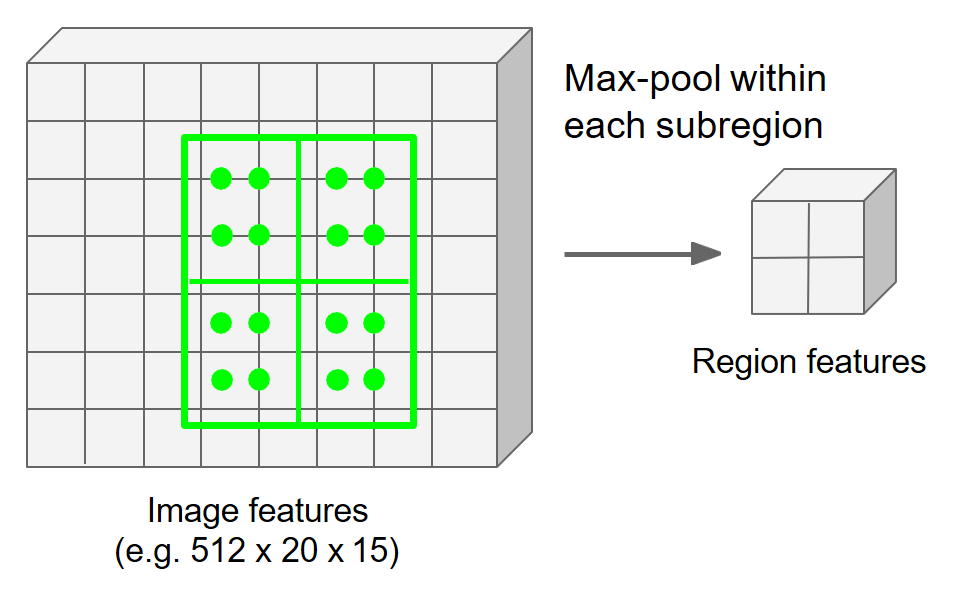
4)利用最大池化(max pooling)或平均池化(average pooling)分别对每个子区域执行聚合操作,得到最终的特征图。
执行结果
通过RoI Align, 对于具有不同特征大小的的输入区域, 都可以得到相同大小输出特征。















 1423
1423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









