







本文根据美国威斯康星州的乳腺癌诊断数据集,生成一个乳腺癌诊断的SVM分类器,并计算这个分类器的准确率。
数据源:https://github.com/cystanford/breast_cancer_data/
1、加载数据源
import pandas as pd
data = pd.read_csv(r'C:\Users\hzjy\Desktop\data.csv')2、数据探索
查看数据的基本情况:可以看到各字段数据没有缺失
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 32 columns):
id 569 non-null int64
diagnosis 569 non-null object
radius_mean 569 non-null float64
texture_mean 569 non-null float64
perimeter_mean 569 non-null float64
area_mean 569 non-null float64
smoothness_mean 569 non-null float64
compactness_mean 569 non-null float64
concavity_mean 569 non-null float64
concave points_mean 569 non-null float64
symmetry_mean 569 non-null float64
fractal_dimension_mean 569 non-null float64
radius_se 569 non-null float64
texture_se 569 non-null float64
perimeter_se 569 non-null float64
area_se 569 non-null float64
smoothness_se 569 non-null float64
compactness_se 569 non-null float64
concavity_se 569 non-null float64
concave points_se 569 non-null float64
symmetry_se 569 non-null float64
fractal_dimension_se 569 non-null float64
radius_worst 569 non-null float64
texture_worst 569 non-null float64
perimeter_worst 569 non-null float64
area_worst 569 non-null float64
smoothness_worst 569 non-null float64
compactness_worst 569 non-null float64
concavity_worst 569 non-null float64
concave points_worst 569 non-null float64
symmetry_worst 569 non-null float64
fractal_dimension_worst 569 non-null float64
dtypes: float64(30), int64(1), object(1)
memory usage: 142.3+ KB
data.columnsIndex(['id', 'diagnosis', 'radius_mean', 'texture_mean', 'perimeter_mean',
'area_mean', 'smoothness_mean', 'compactness_mean', 'concavity_mean',
'concave points_mean', 'symmetry_mean', 'fractal_dimension_mean',
'radius_se', 'texture_se', 'perimeter_se', 'area_se', 'smoothness_se',
'compactness_se', 'concavity_se', 'concave points_se', 'symmetry_se',
'fractal_dimension_se', 'radius_worst', 'texture_worst',
'perimeter_worst', 'area_worst', 'smoothness_worst',
'compactness_worst', 'concavity_worst', 'concave points_worst',
'symmetry_worst', 'fractal_dimension_worst'],
dtype='object')
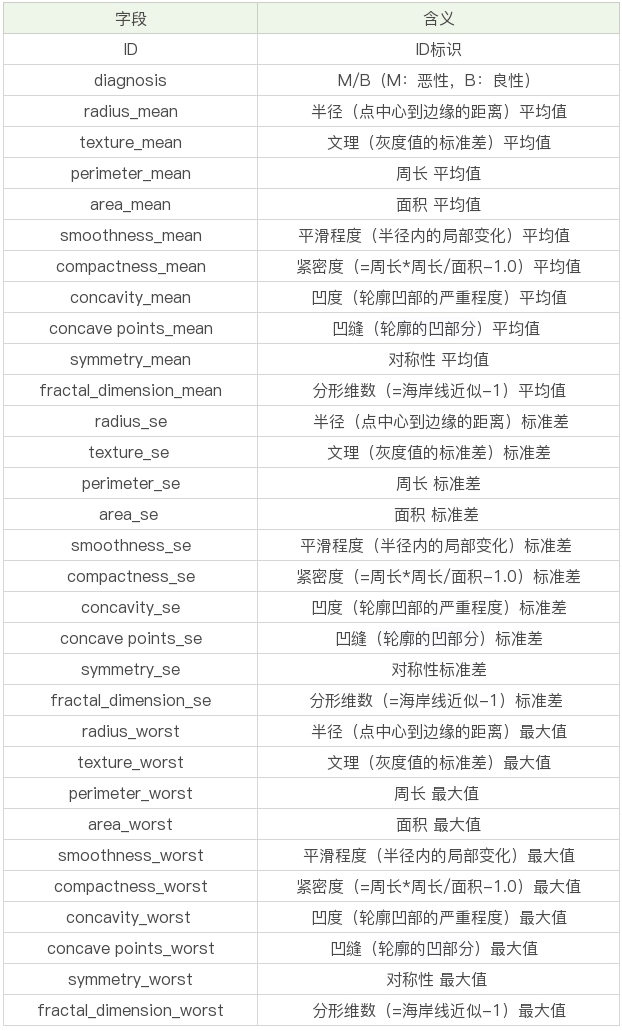
mean 代表平均值,se 代表标准差,worst 代表最大值,后30个特征值实际是10个特征值(radius、texture、perimeter、area、smoothness、compactness、concavity、concave points、symmetry和fractal_dimension_mean)的平均值、标准差和最大值。
3、数据清洗
1)“id”没有实际意思,可以去掉
data.drop('id',axis = 1,inplace=True)
2)“diagnosis”字段的取值即分类结果为B或M,可以用0和1来替代
data['diagnosis'] = data['diagnosis'].map({'M':1,'B':0})
3)后面30个字段可以分成3组
featurs_mean = list(data.columns[1:11])
featurs_se = list(data.columns[12:21])
featurs_worst = list(data.columns[22:31])
4、特征字段的筛选
1)看整体良性、恶性肿瘤的诊断情况
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.countplot(data['diagnosis'],label = 'Count')
2)观察下featurs_mean各变量之间的关系
corr = data[featurs_mean].corr()
plt.figure(figsize=(14,14))
sns.heatmap(corr,annot=True) #annot = True 显示每个方格的数据
热力图对角线上的为单变量自身的相关系数是1。颜色越浅代表相关性越大。
radius_mean、perimeter_mean 和 area_mean 相关性非常大,compactness_mean、concavity_mean、concave_points_mean
这3个字段也是相关的,因此我们可以取其中的一个作为代表。
3)进行特征选择
特征选择的目的是降维,用少量的特征代表数据的特性,这样也可以增强分类器的泛化能力,避免数据过拟合。
可以从相关性大的的每类属性中任意选一个作为代表,
所以从mean、se、worst中选择mean,从radius_mean、perimeter_mean 、 area_mean中选择radius_mean
以及从compactness_mean、concavity_mean、concave_points_mean中选择compactness_mean,这样就可以把原来的10个属性缩减为6个属性
5、准备训练集和测试集
from sklearn.cross_validation import train_test_split
train,test = train_test_split(data,test_size = 0.3) #抽取30%的数据作为测试集,其余作为训练集
train_X = train[features_remain] #抽取特征选择的数值作为训练和测试数据
train_y = train['diagnosis']
test_X = test[features_remain]
test_y = test['diagnosis']在训练数据之前,需要对数据进标准化,让数据处于同一个量级上,避免因为维度问题造成数据误差。
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() #采用Z-Score标准化,保证每个特征维度的数据均值为0,方差为1
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)6、让SVM做训练和预测
from sklearn import svm
from sklearn import metrics
model = svm.SVC() #创建SVM分类器
model.fit(train_X,train_y) #用训练集做训练
prediction = model.predict(test_X) #用测试集做预测
print('准确率:',metrics.accuracy_score(prediction,test_y))
#准确率: 0.9122807017543859得出结果准确率在90以上,说明训练结果还不错。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









