







theano logistic regression讲解
逻辑模型是一个基于概率的线性分类器。它的参数是w和b。 通过把输入向量映射到一个超平面集合上来实现分类,每个超平面对应一个分类。从超平面到输入向量的距离反应了这个概率,就是说输入属于这个分类的概率。数学上,一个输入属于某个分类的公式可以表达为下面的公式:
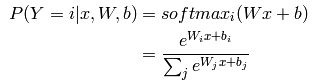
这个公式的意思是,当已知一个输入x,根据猜想的参数(w,b)得到的softmax就是它归属于i的概率的计算公式。
i代表的是第几个样本,j代表的是y的1~k个取值的第j个取值。
斯坦福大学的一个网站仔细的讲解了这个推倒过程:
http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
下面的argmax_i就比较容易理解了,就是求其中1~k个概率中,最大的那个。
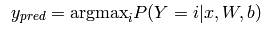
下面的代码可以实现上述两个公式的计算:
#initialize with 0 the weights W as a matrix of shape (n_in, n_out)
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
# initialize the biases b as a vector of n_out 0s
self.b = theano.shared(
value=numpy.zeros(
(n_out,),
dtype=theano.config.floatX
),
name='b',
borrow=True
)
# symbolic expression for computing the matrix of class-membership
# probabilities
# Where:
# W is a matrix where column-k represent the separation hyperplane for
# class-k
# x is a matrix where row-j represents input training sample-j
# b is a vector where element-k represent the free parameter of
# hyperplane-k
self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b)
#上述输出是一个概率向量
# symbolic description of how to compute prediction as class whose
# probability is maximal
self.y_pred = T.argmax(self.p_y_given_x, axis=1)
#这个x轴指的是竖着选,还有一个是横着选的,就是axis=2了。
因为模型的参数在训练过程必须是持久的状态,我们创建了连个共享的变量,w,b。
这个做法也同时把他们作为了一个形式的变量,但是也初始化了他们的值。dot和softmax操作是用来计算概率的,p_y_given_x是一个向量变量。
如果要一个具体的预测值,我们还需要一个argmax的操作,将会告诉你p_y_given_x最大的那个是第几个(index)
当然,我们现在定义的模型,没作啥实际的用处,因为参数仍然在初始状态,下面的章节将会说明如何去学习一个优化的模型。
定义一个代价函数
学习的过程就是最小化一个代价函数。在多分类逻辑回归模型中,常用的就是负的似然函数作为代价函数。这个相当于在\theta决定的模型下,对数据集D的一个最大似然估计。用大白话来讲,就是针对特定的数据集 D,对参数\theta进行调整,使最后的预测准确率最高,代价最小即可。我们先开始来定义代价函数:
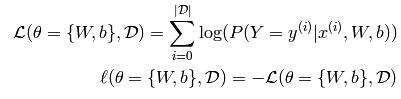
公式的意思就是说,在一个数据集D上,遍历计算softmax的对数值,最后求和,就是代价函数。也就是说要概率最大的值。再来看看加州理工学院的视频的看法。为什么逻辑回归非要使用负对数likelihood函数,就不清楚了,文章提的是说常用的就是这个。暂且不去研究啦。
所有的书都是致力于最小化的话题,梯度下降是目前最简单的最小化任意非线性函数的方法了。本教程将会使用批量随机梯度下降的方法。
下面的代码定义了每一个小的批次的损失值的计算公式:
# y.shape[0] is (symbolically) the number of rows in y, i.e.,
# number of examples (call it n) in the minibatch
# T.arange(y.shape[0]) is a symbolic vector which will contain
# [0,1,2,... n-1] T.log(self.p_y_given_x) is a matrix of
# Log-Probabilities (call it LP) with one row per example and
# one column per class LP[T.arange(y.shape[0]),y] is a vector
# v containing [LP[0,y[0]], LP[1,y[1]], LP[2,y[2]], ...,
# LP[n-1,y[n-1]]] and T.mean(LP[T.arange(y.shape[0]),y]) is
# the mean (across minibatch examples) of the elements in v,
# i.e., the mean log-likelihood across the minibatch.
return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])上面的这个代码和计算公式有点出入,需要详细研究. 本来按道理,就是把所有的输入的集合计算一遍,求得对数的和即可,值了为什么要这个表达式呢:[T.arange(y.shape[0]
要看下文来确定为什么。
创建一个逻辑回归类
class LogisticRegression(object):
"""Multi-class Logistic Regression Class
The logistic regression is fully described by a weight matrix :math:`W`
and bias vector :math:`b`. Classification is done by projecting data
points onto a set of hyperplanes, the distance to which is used to
determine a class membership probability.
"""
def __init__(self, input, n_in, n_out):
""" Initialize the parameters of the logistic regression
:type input: theano.tensor.TensorType
:param input: symbolic variable that describes the input of the
architecture (one minibatch)
:type n_in: int
:param n_in: number of input units, the dimension of the space in
which the datapoints lie
:type n_out: int
:param n_out: number of output units, the dimension of the space in
which the labels lie
"""
# start-snippet-1
# initialize with 0 the weights W as a matrix of shape (n_in, n_out)
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
# initialize the biases b as a vector of n_out 0s
self.b = theano.shared(
value=numpy.zeros(
(n_out,),
dtype=theano.config.floatX
),
name='b',
borrow=True
)
# symbolic expression for computing the matrix of class-membership
# probabilities
# Where:
# W is a matrix where column-k represent the separation hyperplane for
# class-k
# x is a matrix where row-j represents input training sample-j
# b is a vector where element-k represent the free parameter of
# hyperplane-k
self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b)
# symbolic description of how to compute prediction as class whose
# probability is maximal
self.y_pred = T.argmax(self.p_y_given_x, axis=1)
# end-snippet-1
# parameters of the model
self.params = [self.W, self.b]
# keep track of model input
self.input = input
def negative_log_likelihood(self, y):
"""Return the mean of the negative log-likelihood of the prediction
of this model under a given target distribution.
.. math::
\frac{1}{|\mathcal{D}|} \mathcal{L} (\theta=\{W,b\}, \mathcal{D}) =
\frac{1}{|\mathcal{D}|} \sum_{i=0}^{|\mathcal{D}|}
\log(P(Y=y^{(i)}|x^{(i)}, W,b)) \\
\ell (\theta=\{W,b\}, \mathcal{D})
:type y: theano.tensor.TensorType
:param y: corresponds to a vector that gives for each example the
correct label
Note: we use the mean instead of the sum so that
the learning rate is less dependent on the batch size
"""
# start-snippet-2
# y.shape[0] is (symbolically) the number of rows in y, i.e.,
# number of examples (call it n) in the minibatch
# T.arange(y.shape[0]) is a symbolic vector which will contain
# [0,1,2,... n-1] T.log(self.p_y_given_x) is a matrix of
# Log-Probabilities (call it LP) with one row per example and
# one column per class LP[T.arange(y.shape[0]),y] is a vector
# v containing [LP[0,y[0]], LP[1,y[1]], LP[2,y[2]], ...,
# LP[n-1,y[n-1]]] and T.mean(LP[T.arange(y.shape[0]),y]) is
# the mean (across minibatch examples) of the elements in v,
# i.e., the mean log-likelihood across the minibatch.
return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])
# end-snippet-2
def errors(self, y):
"""Return a float representing the number of errors in the minibatch
over the total number of examples of the minibatch ; zero one
loss over the size of the minibatch
:type y: theano.tensor.TensorType
:param y: corresponds to a vector that gives for each example the
correct label
"""
# check if y has same dimension of y_pred
if y.ndim != self.y_pred.ndim:
raise TypeError(
'y should have the same shape as self.y_pred',
('y', y.type, 'y_pred', self.y_pred.type)
)
# check if y is of the correct datatype
if y.dtype.startswith('int'):
# the T.neq operator returns a vector of 0s and 1s, where 1
# represents a mistake in prediction
return T.mean(T.neq(self.y_pred, y))
else:
raise NotImplementedError()通过下面的代码来实例化它
# generate symbolic variables for input (x and y represent a
# minibatch)
x = T.matrix('x') # data, presented as rasterized images
y = T.ivector('y') # labels, presented as 1D vector of [int] labels
# construct the logistic regression class
# Each MNIST image has size 28*28
classifier = LogisticRegression(input=x, n_in=28 * 28, n_out=10)最终我们定义一个代价函数,然后去求最小值:
# the cost we minimize during training is the negative log likelihood of
# the model in symbolic format
cost = classifier.negative_log_likelihood(y)
下面我们来训练这个模型
为了实现识别算法,你可能需要手工根据参数来求导数,这个对于复杂的模型,会非常的有挑战,在theano,这个工作是非常简单的,它自动的执行了一些数学的变换,去提高数字的稳定性。
下面的代码就代表了简单的计算梯度的公式:
g_W = T.grad(cost=cost, wrt=classifier.W)
g_b = T.grad(cost=cost, wrt=classifier.b)下面的方法train_model,执行了梯度下降的一个步骤,
# specify how to update the parameters of the model as a list of
# (variable, update expression) pairs.
updates = [(classifier.W, classifier.W - learning_rate * g_W),
(classifier.b, classifier.b - learning_rate * g_b)]
# compiling a Theano function `train_model` that returns the cost, but in
# the same time updates the parameter of the model based on the rules
# defined in `updates`
train_model = theano.function(
inputs=[index],
outputs=cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}
)
update 方法做了两件事情,它是成对出现的,第一个是更新w,通过w=w-learning_rate*g_w,
这里的given其实是计算此次迷你批的x和y是如何计算的,别的没啥神秘的。
- train_model的输入是迷你批的索引,和批大小和在一起,可以确定输入x,和 标签y.
- 返回值是一个代价函数,它是针对此次迷你批的代价函数。
- 每一次函数调用,此函数首先计算出来x,y,然后计算代价函数,最后更新updates list
每个时间单位t ,train_model被调用,它将会计算和返回迷你批的代价,也会执行一个训练数据的一步,整个学习算法这样在一个循环中进行了。
测试模型
见下一章















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









