






墙上挂了根长藤,长藤上面挂铜铃
《长藤挂铜铃》;词:元庸,曲:梅翁(姚敏),唱:逸敏,1959
您在阅读《软件方法》时如果发现错误,欢迎通过微信umlchina2告知。如果作者认为有道理,决定在下一次发布时根据您的意见修改,将付给您5.12元报酬,并在书中说明您的贡献。报酬通过微信支付。
(1)任何您认为的错误都可以,包括错别字。
(2)同一错误仅支付最先指正者报酬。
(3)请根据最新版本作指正。
下册内容目前指正人有(按指正时间排序):吴佰钊、王周文、刘学斌、成文华、黄树成、李蜀斌、杨雪鸿、王书伟、高洪江、张志坚。
8.1 分析工作流概述
8.1.1 知识的分离
在业务建模和需求工作流,我们一直把目标系统看作是一个整体,想办法推导出涉众在意的整体表现——需求。
系统为了满足需求,必须封装一定的知识。这些知识,没法从天上掉下来,需要软件开发人员一点一点放进去。接下来,我们将思考:
(1)如何准确表达系统需要封装的知识,让系统满足需求;
以及进一步
(2)如何合理组织系统需要封装的知识,低成本地让系统满足需求。
如果不能合理组织知识,当新需求到来时,准确表达也会越来越难。如果考虑到利润,很难停留在(1)而不追求(2)。
不管是纯粹在大脑里面打转转,还是借助了纸笔或建模工具来协助,以上的思考是逃不掉的。如果需要封装的逻辑很简单,人脑的容量和运算速度能够胜任,在大脑里打转转可以勉强应付。不过,能带来利润的系统都是复杂的(参见《软件方法(上)》1.8.1市场没有小系统),借助纸笔或建模工具来显式表达思考的过程很有必要,毕竟大脑容量和运算速度比一般人高出一个数量级的天才是很稀罕的。
有的人故意不显式表达,声称“大脑思考就够了”,背后的真相可能不是天才而是遮羞——你让他显式表达,他也表达不出来,因为没有掌握思考的方法。
思考的方法,也就是知识分离的方法,包括域和域之间的知识分离,以及域内部的知识分离。
8.1.2 核心域和非核心域
一个软件系统封装了若干领域的知识,其中一个领域的知识是系统不能抛弃或替换的,这个领域称为"核心域",其他领域称为"非核心域"。
图8-1展示了不同系统类型的核心域和非核心域概念:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
图8-1 不同系统类型的核心域、非核心域概念
以文档处理器为例,开发Microsoft Word和LibreOffice Writer所使用的编程语言和组件不一样,但文档、页、行、字等核心域概念是一样的。即使回到计算机诞生之前或者去到未来,这些概念也依然存在。
关于“核心域”和“非核心域”,一种常用的通俗说法是"业务"和"技术",但"业务"和"技术"的说法并不严谨。
有的开发人员在潜意识里是这样划分的:
*我懂且我感兴趣的知识→技术;(我懂Java编码,我对Java编码感兴趣,Java编码是技术)
*我懂但不感兴趣的知识→业务;(下单、收银、配送我懂一些,但不感兴趣,这些是业务)
*我不懂但感兴趣的知识→高科技;(我不懂深度学习,但很感兴趣,哇塞,高科技)
*我不懂且不感兴趣的东东→忽悠。(我不懂UML建模,也不感兴趣,妈的,忽悠)
有的开发人员则是这样划分的:
*和计算机无关→业务;
*和计算机有关→技术;
核心域不能以“懂”、“感兴趣”来判断。核心域不一定是非计算机领域,也可以是计算机领域,如图8-1中的操作系统。
另外,还要特地说明的是,本书中的“核心域”和Eric Evans《领域驱动设计》以及后续相关书籍中的“核心域”(Core Domain)意思不同。
本书中的“核心域”指软件系统中不可替换的那部分内容——这个以软件开发人员的知识是可以判断的。
EricEvans《领域驱动设计》知识体系中,把“领域”(相当于本书中的“核心域”)划分为"核心域"、“通用子域”、“支撑子域”等,例如“Delivery”是核心,“Customer”是通用,“Billing”是支撑——这个划分已经超出了软件开发人员的知识,我不认为软件开发人员有能力以及有必要做这样的判断。
一家商场之所以能击败其他对手,原因未必是下单部分有什么不同,倒有可能是在配送环节下了大力气,或者客户服务抓得好。没有经过商业竞争的思考,武断地认为某个子领域是“核心”是不合适的。
8.1.3 域之间的映射和协作
域和域之间的映射以及协作的规律,与域中的个体不直接相关。
例如,我们看一个"人员管理"领域的类图,如图8-2所示。

图8-2 核心域类图
如果将图8-2中的Person类映射为C#实现,可能会得到图8-3的C#代码:

图8-3 类的C#实现(用EnterpriseArchitect映射)
如果将图8-2中的类映射到关系数据库,会得到图8-4所示的数据库结构:

图8-4 将类图映射到数据库模型(用Enterprise Architect映射)
如果采用某种对象-关系映射器框架(例如微软的Entity Framework),Person对象和数据库中的Person表里的一行可能会这样联系起来:
person1=context.Persons.Find(ID)
如果将以上内容中的Person改成Dog,City改成Cat,映射的套路没有变化。如果我们调整了域之间的映射和协作的套路,得到的结果也会按照我们的调整有规律地变化,与域中的个体依然无关。
平时我们看到的一些“架构”,就是域之间映射和协作的一些套路。图8-5是现在常被提起的一些“架构”,可能在不同领域的系统中都会观察得到。

图8-5 一些常见的“架构”
既然域之间的映射有“套路”,过早地混合不同域的知识是不划算的。如图8-6所示,假设三个域要考虑的因素分别是a、b、c个,如果分开考虑,然后再找到域和域之间映射的规律,负担最小可以变成a+b+c;如果混在一起考虑,大脑的负担最大会达到a×b×c。a、b、c都大于√3时,相乘肯定要大于相加的。

图8-6 过早混合不同域的知识会增加大脑负担
过早地混合不同域的知识,会加重开发人员大脑的负担,导致开发人员腾不出脑力来思考核心域中更深刻的问题,只好稍微折腾一下如图8-5的“域之间的架构”,心里安慰自己,我有“架构”了!却忘了,其实还没有触碰到最需要大脑去思考的核心域概念和逻辑。而这又很可能会被巧妙地当成遮羞布——不是我不思考,而是要想的事情太多了顾不过来啊!
而这种微妙心态的进一步发展,就会导致开发人员有意无意地混合不同域的知识,把复杂度弄成a×b×c,以此达到通过废话刷工作量——以最少的思考得到最多的“成果”。
我经常听软件组织的架构师向我介绍他们所开发系统的“架构”,口沫横飞,说的基本上都是图8-5的“域之间的架构”。好啊,真棒,我知道了。还有呢?没了?
构思那些“域之间的架构”是某些厂商或者方法学家的工作,我们挑一个适合自己项目的套路用上就行了。有什么问题,可以去请教用这个套路用得好的先行者。
“域内部的架构”,那些核心域概念和复杂逻辑,这是系统最值钱的地方。要是我们没有办法理清楚,别人是帮不到我们的。这才是大脑最该用的地方!
平时我们说“需求变了”,大多数情况是功能需求变化,导致系统所封装的核心域逻辑需要调整,而不是“域之间的架构”需要调整,所以没有必要整天津津乐道“域之间的架构”。
一些以“领域驱动设计”为名的文章,所举例子就1-2个领域类,然后就开始讨论Entity、Service、Repository、DTO、六边形架构……不是说这个知识没用,问题是软件组织缺的是这个嘛?
*调查:您看过的以“领域驱动设计”为名的文章,里面有几个领域类?*
在一些软件开发技术大会常可以看到这样的场景:某电子商务网站的架构师上台讲了一通,接着某视频网站的架构师上台也讲了一通,咦,两个演讲内容如此相似?原来,他们讲的都是自己系统中“域之间的架构”,而不是核心域内部的机制。究其原因也许并非不为,而是不能——架构师对自己所开发系统的核心域研究太浅。
许多“网红程序员 ”在网上谈论的内容大多是某种语言或框架的新特性,少有探讨他当前所开发系统的复杂领域逻辑,也是同样的原因:并非不为,而是不能。
说了那么多,归纳起来就是一句话:
8.1.4 重视分析工作流
分析,就是从核心域的视角构思系统的内部机理。
在现在的很多软件组织中,分析工作流的技能是非常被忽视的。很多开发人员上手就直接编码,原因并不是软件开发项目的领域逻辑简单到了不需要分析的地步,或者他在大脑里就完成了分析的工作,而是开发人员缺乏分析的技能,只好瞎碰了事,而且为了遮掩自己的无能,还会想各种办法来遮羞。
就像高考的时候,前面几道题比较容易,可以扫一眼就写答案。越往后题目越来越难,学霸会拿出草稿纸,列出已知条件,正推、逆推……理出解题思路,然后再答。
学渣就麻烦了,根本没有学习相关的知识和解题方法,怎么办?
遮羞利器(1):时间。
例如,抱怨考试时间太紧张,来不及思考,只好胡乱写个答案,甚至故意提前交卷,力图给人造成一种“如果时间允许,我是能做对的”的印象——真相是,给再多的时间也不会。
对应到软件开发,就是以“时间紧”、“敏捷”为借口掩盖自己没有能力剖析复杂逻辑的事实。
遮羞利器(2):空间。
例如,考试时故意选择不好写的笔和劣质的草稿纸,力图给人造成一种“如果纸和笔再好一点,我是能做对的”的印象——真相是,不会就是不会,给他再好的纸笔也不会。
对应到软件开发,就是借助“口头交流”、“白板”等容量小的介质,掩盖内容的苍白。白板就这么大,所以客观上你总不好意思让我用白板剖析复杂的逻辑吧?
伽罗瓦在决斗前一天晚上仓促写下自己的数学思想,不停哀叹“我没有时间了”。唉,早干嘛去了,不过伽罗瓦是真懂。

图8-7 伽罗瓦决斗前一天的手书
费马在书的空白处写下“费马猜想”,还写“我确信我发现一种美妙的证法,可惜这里的空白处太小,写不下”,估计费马是忽悠。
此处提到此二人纯属作者关于“时间”、“空间”不够的随意联想,无其他含义。
遮羞利器(3)听起来就比较高大上了:重构。
上世纪80年代末,BillOpdyke(https://cseweb.ucsd.edu/~wgg/Abstracts/gristhesis.pdf)和Bill Griswold(http://laputan.org/pub/papers/opdyke-thesis.pdf)等人归纳了一些调整代码结构的手法,称为“重构”,后经Martin Fowler等人推广而广为流传。
“重构”的知识可以看作是建模知识的一个子集。如果开发人员真的熟练掌握重构的手法,很多情况下他已经有能力直接建模领域逻辑得到更合理的结构,根本不需要先走很多弯路再回正路。
还是用考试类比:如果考生能够察觉针对某道题的某个解答的“坏味道”并改正,那么面对试题和空白答卷的时候,他也可能有能力察觉试题所考查的知识点以及采分点,给出合适的回答,并不需要故意做错再改过来。
如果考生别有用心把“重构”当遮羞布,结合前面两个遮羞利器,就会出现“我本来打算把我的答卷重构一下,但是没有时间了”,“我本来打算把我的答卷重构一下,但是答卷写满了没空间了”。
开发人员可以照此办理——“我先写快而脏的代码,然后再重构”,然后结合遮羞利器“时间”(此处“空间”不好借)——“没想到啊,时间来不及了”。
摸着石头过河是难免的,但应该在不得不摸的时候才摸,不应该假装看不见已有的路和桥,无论大小事都主动追求摸着石头过河,而且,很多人不是假装看不见路,而是真的看不见路——就是个睁眼瞎。要是开发人员以“重构”为理由拒绝思考,很可能他的“重构”也是空话。
不过,大脑不用思考,凭感觉摸着石头过河不停刷工作量,也是一种幸福。
8.1.5 分析相关历史的简单回顾
1958年,John W. YoungJr.和Henry K. Kent发表“Abstractformulation of data processing problems”,第一次提出在独立于实现的抽象级别上定义系统的规范。

图8-8 来自 “An abstractformulation of data processing problems”(Young JW, KentHK,1958)的截图
1959年,CODASYL(数据系统语言会议)成立。1962年,CODASYL提出了一个和Young/Kent类似的模型,称为“信息代数”(Information Algebra)。
1970-1980年代是结构化分析方法的时代,主要贡献者有Börje Langefors、Chris Gane、Trish Sarson、Tom DeMarco、Pin-Shan Chen、E. F. Codd等人。结构化分析的主要建模方法是数据流图和实体-关系图,这两者的结合,让软件开发人员有能力剖析大型系统。

图8-9 来自 Structuredanalysis and system specification(DeMarco T,1979)的截图

图8-10 来自 The Entity–Relationshipmodel: Towards a unified view of data(Chen PPS,1976)的截图
1982年,Nastec公司开发出了DesignAid,这是第一款CASE(计算机辅助软件工程)工具。随后,其他CASE工具陆续出现。据PC Magazine的1990年1月30刊统计,当时已经有超过100家公司提供了将近200款CASE工具。



图8-11 来自PC Magazine1990年1月30日刊的截图(被圈住的内容说明了工具的数量)
1980年代后期,面向对象的思想开始用于分析和设计。然后,UML统一了表示法。这部分历史已经在本书第1章“UML简史”部分讲述,此处不再赘述。

图8-12 来自 ObjectOriented Analysis, 2nd Edition(Coad P, Yourdon E, 1990)的截图

图8-13 来自 Objectlifecycles. Modeling the world in states(Shlaer S,Mellor SJ, 1992)的截图
8.1.6 互联网和敏捷的影响
互联网浪潮以及敏捷运动的冲击打断了分析的传承。
互联网浪潮到来之前,软件系统的竞争焦点是功能。
我1997年毕业,先到高校当了一年老师,然后才去软件公司做程序员。第一个参与开发的系统是酒店管理系统。这样的系统用的人不多,服务器一台,每个部门放上一台客户端电脑就差不多了,但功能很多,入住退房、收银、客房,餐饮、娱乐、财务、电话计费、各种报表等等,能不能把领域逻辑理清楚非常关键。
互联网的兴起带来了这样一种系统:这种系统功能很简单,开发这种系统时需要思考的领域逻辑很少,但是这样的系统可以通过互联网让非常多的人使用,问题的关键变成了“如何在大用户量下保持性能”。
典型的例子是1996年出现的hotmail,推出一年多时间就有1200万的用户。hotmail是一个基于web的电子邮件系统,这样的系统,开发出来并没有太大难度,竞争的关键在于有没有背景、有没有钱买基础设施,有没有钱做推广……。
可能有人会说“邮件系统也有逻辑啊!”当然,这同样是一个领域,也有逻辑,但是其中的绝大多数逻辑已经被前人探索得很清楚,甚至有实际的可用组件提供,并不需要web电子邮件系统的开发人员从头思考。
很多开发人员就进入了类似的“互联网公司”,开发或维护类似的系统。因为不需要剖析复杂的领域逻辑,开发人员有没有掌握分析的技能已经无所谓,于是,很多打着“敏捷”旗号的“方法”就在这类公司大行其道,导致软件开发人员的分析能力普遍退步。
经常有人和我说,潘老师,敏捷这一套做工厂管理系统之类的可能不太行,但不得不承认,做互联网很管用噢!
当然管用了!
有个巫医发明了一种治疗方法。他坦言,我这个方法对付癌症可能不太行,但对付感冒很管用噢!你不信,找个感冒患者来!
感冒患者找来了,医生让患者躺在一张绘有八卦图案的方桌上,然后绕着患者绕了八八六十四圈**(看到没,他也是有一套方法的!)**,然后对患者说,回去该吃吃该喝喝,五天之内就好了!
果然,患者好了。
医生四处宣传他的治疗方法,由于此方法简单易学,迅速收获了大批粉丝。

图8-14 电影《破坏之王》截图
给软件开发人员一段文字描述,让他提炼和表达其中的领域概念和关系(通过ER图、类图……甚至口述表达都可以)。基于我在训练班上的体会,能在这个测试中给出合格结果的开发人员占全体开发人员的比例,如果在2000年占百分之x的话,二十年之后的2020年,这个比例是否能占到千分之x都值得怀疑。
随着互联网的成熟,大部分组织都变成了“互联网组织”。以往以“互联网公司”著称的巨头们变成了行业领袖,宣称“我是做互联网的”已经不足以包装自己,必须要对领域深入挖掘了。
但是,开发人员“敏捷”惯了,怎么办呢?还能回得去吗?

图8-15 分析技能下降之后,还能回得去吗?
8.1.7 伪创新
于是,就出现了各种伪创新。
有的人(国外国内都有)没有掌握相应技能,也不愿意认真学习已有的知识,凭着一些朦胧的“领悟”,就“发明”了一些“新”方法,这就是伪创新。
软件开发的一些伪创新前些年打的是“敏捷”的旗号,最近几年打的是“领域驱动设计”的旗号。仔细观察,背后的人很多是重叠的。
伪创新,例一:
图8-16摘自2017年出版的某本名字中带有“Domain-Driven Design”的书,看起来有点像图8-9,对吧?但是图8-16的内容和绘制于1979年的图8-9比起来,水分要多得多。

图8-16 来自2017年出版的某本名字中带有“Domain-Driven Design”的书的截图
这么大一张图,除了Place Order和Ship Order这两个概念之外,剩下的就是废话刷工作量了。右半边,ShipOrder、Ship-Order、Shipping(咦?怎么没有和左边一样前面加个Order叫Order-Shipping呢,这样还可以多几个字母刷工作量)、OrderShipped,这是在上英语语法课吗?
相当于把2个概念刷了4倍工作量,得到2×4=8个结果。
信息浓度=2/8×100%=25%。
从图8-16的表示规律可以看出来,方框是workflow,进入箭头是command,出去箭头是event。既然如此,每个标签文字后面其实可以不用加“workflow”、“command”、“event”等字样,但是,不加怎么显得我工作量大呢?
考虑到这一点,信息浓度估计20%吧。或者反过来说,一条信息刷到5倍。
图8-16还有一个问题,混合了非核心域的知识,会造成之前说的a×b×c,具体在什么地方,留给读者观察。
伪创新,例二:
图8-17摘自2019年出版的另外一本名字中带有“Domain-Driven Design”的书。展示的就是打着“领域驱动设计”旗号的伪创新之一:事件风暴(EventStorming)。

图8-17 来自2019年出版的某本名字中带有“Domain-Driven Design”的书的截图
我把图8-17里提到的概念提炼出来,画了1个类和4个小人,如图8-18。数一数,包括类名称在内,图8-18一共有16个概念。

8-18 我提炼图8-17的概念画的图
有了图8-18,可以准备开车……不,准备刷工作量了!
(1)创建对象,销毁对象,刷2个蓝色纸片,就是图8-17中的Create an ad和Removead(怎么前面没有an了,刷得不整齐,重刷!)。
这个步骤刷出2个蓝色纸片。
(2)多重性为1的属性(从图8-17看应该是title、text和sell price),每个刷1个蓝色纸片,就是图8-17中的Change the ad title(怎么不和后面两个一致都用Update,刷得不整齐,重刷!)、Update the ad text和Update ad sell price(怎么前面没有the了,刷得不整齐,重刷!)。
这个步骤刷出3×1=3个蓝色纸片。
另外,本来这些都是Ad的属性,直接称title、text和sell price即可,不必再加前缀,但不加怎么能刷出工作量呢?一定要加!
(3)多重性为多的属性(从图8-17看应该是picture和category),每个刷2个蓝色纸片,Add***和Remove***。
这个步骤刷出2×2=4个蓝色纸片。
另外,本来这些都是Ad的属性,图8-17中写Add***和Remove***即可,不用加to Ad、from Ad,但不加怎么能刷出工作量呢?一定要加!
(4)每个操作刷1个蓝色纸片。
这个步骤刷出6×1=6个蓝色纸片。
咦?这些改变状态的操作看着怎么和属性没有什么关系呢?是属性漏了,还是操作错了?估计作者也不太了解操作、状态和属性的关系吧。
(5)把(1)-(4)步产出的所有的蓝色纸片变换词序,每个旁边加一个橙色纸片。
这个步骤结束后,得到(2+3+4+6)×2=30个方框形状的纸片,或者说,15对。
(6)把图8-16中的4个小人和每对方框任意组合,得到大约15个黄色小人。
最终,我们从往墙上贴了30+15=45张小纸片,数量和内容正好和图8-17中的纸片相同。
信息浓度=16/45×100%=36%。再考虑到那些刷上去的Ad,估计差不多33%的浓度。或者反过来说,一条信息刷到3倍。
要注意,这仅仅是其中一个类Ad,其他类照此办理,今年的工作量可算是有交代了。
是不是创始人英明神武,只不过其他人把经念歪了?感兴趣者可以去自行看“事件风暴”的作者AlbertoBrandolini的书,看看书里面讲了什么。
*调查:您看过的以“领域驱动设计”为名的文章,有类似的刷工作量的情况吗?欢迎在本文下留言。*
这些伪创新在思想上都有共同的错误:一一对应,内外不分。
世界之所以复杂,或者说,系统之所以复杂,就是因为很多关系不是一一对应的。
组织的一个流程可能由多个系统(包括人肉系统和非人系统)协作完成,一个系统可以参与组织的多个流程;系统的一个用例(如果读者没有掌握上册讲解的用例的知识,就当作是功能吧)可能由系统的多个类协作完成,一个类可以参与系统的多个用例。类的一个操作可能会影响多个属性,一个属性可能会被多个操作影响……
正是因为如此,才需要软件开发人员大脑来找出最佳的映射方案,这才是人的脑力需要花费的地方。
而这种思考是有一定门槛的,不是所有人都能胜任。
如果一个人不能胜任,而又不愿意花时间去学习,当有一种“一一对应刷工作量”的伪创新出现在他面前时,自然而然就会产生一种虚幻的“受用”感觉,欢快地投入伪创新的怀抱——
“哥也是有方法的人了!”
最近几年的微服务浪潮中,类似“以用例为依据分割系统”甚至“以业务流程为依据分割系统”等明显内外不分的言论为什么能流传开,就是因为足够简单,方便一一对应刷工作量。
***********
初中数学里要学习全等三角形、相似三角形、SSS、SAS……,到了高中以后学了正弦定理、余弦定理等解三角形的知识……就不会再回去用初中的方法解题了。
但是,不是所有人都能学会高中的知识,比如说张三。
张三可能会这样解释:
“我这个人能力比较弱,只能掌握全等三角形、相似三角形的方法。”
这样的说法没有问题。
张三还可能会这样解释:
“这个题目比较简单,用全等三角形、相似三角形的方法做足够了,而且这样更方便广大人民群众理解。”
这样的说法也可以。不过,竞争对手不是傻子,市场中哪里有什么"简单题目"!能带来利润的题目都很复杂。
但是,张三如果这样说:
“全等三角形、相似三角形的知识比高中三角函数的知识更深刻。”
这就是自欺欺人了。
更要警惕的是,有一个李四,也许和张三一样没有掌握高中方法,也许掌握了高中方法但是为了忽悠张三们,偷偷把"全等三角形"改名为"叠合三角形",然后和张三宣传:
“我发明了"叠合三角形"新方法,比高中的三角函数有用,三角函数过时了。”
这就是可恶了。
***********
回到前面举的伪创新例子。如果说熟练掌握类图、状态机图等建模技能,并发现了其中的缺点,站在前人的肩膀上创新,这完全可以。
在不了解已有知识的情况下,拍脑袋搞出伪创新,甚至向大众宣传伪创新,也是个人自由。
但是,宣传伪创新时,像上面李四那样胡说“我这个方法比***好”,就不对了。
事实上,一旦付出努力,咬咬牙掌握了更严谨和更高效的方法,是羞于再回头去使用那些打着“敏捷”或“领域驱动设计”旗号的伪创新的。
8.1.8 本书使用的分析方法
分析模型描述系统要封装的核心域知识。
至于用什么建模概念来思考和描述核心域知识,可以有很多种选择。例如,“人”用不同的建模概念描述,可以说它是一个“类”,也可以说它是一个“类型”、一个“实体”。
本书使用面向对象的建模概念来描述分析模型,从三个视角来描述:
分析类模型:描述系统中各个类以及类之间的关系。
分析状态机模型:描述某个类的各个行为的逻辑。
分析交互模型:描述某些类在实现某个用例时的协作。
而面向对象的分析模型的表达形式,也可以有多种选择:语音、文本、图形等。
有的人觉得当前许多编程语言的表达能力已经很强,认为用文本已经足够,抗拒用图形来表达领域知识。
但是,和只有自上而下顺序的文本相比,能够朝四个方向扩展的平面图形(如果有三维模型就更好了)更容易让建模人员看出领域概念之间的联系。例如,图8-19和8-20的内容,如果没有图形的帮助,直接用文本一行一行地构造分析模型,人脑的负担非常重。

图8-19 餐饮领域的类图

图8-20 来自 PracticalUML Statecharts in C/C++(Samek M, 2008)的截图,计算器的状态机图
说到这里,又不可避免地要提醒,故意选择文本的形式来表达领域知识,有可能也是一种遮羞利器。图8-19和8-20的内容如果用文本表达,可能会得到很多页文本——这就有了理由:因为工作量太大了,所以很多地方无法做深入的思考,可以原谅!
本书使用类图、状态机图和序列图三种UML图形来表达面向对象的分析模型。UML类图表达分析类模型,UML状态机图表达分析状态机模型,UML序列图表达分析交互模型。

图8-21 本书的分析方法所使用的UML图形
需要说明的是,虽然我们用的是面向对象的分析方法,也就是说,用面向对象的概念来剖析核心域知识,但不意味着你的系统一定要用特定的“面向对象”编程语言、存储方式或物理分布形式来实现。
也许你使用的编程语言是面向过程语言,例如C;也许你使用的编程语言是函数式语言,例如F#;也许你使用的存储系统是关系数据库系统,例如SQL Server;也许你使用的存储系统是非关系数据库系统,例如MongoDB;也许你的系统运行在同一台机器上,也许是分布在很多台机器上……
不管你的系统的实现方式和运行形态如何,从分析过渡到设计时,变化的只是分析到设计的映射套路。如果设计所使用的非核心域比较“面向对象”,那么映射套路会比较直观一些,否则,就需要一定的转换。但不论如何,如前文所说,这个套路和具体的核心域知识没有关系,我们并不需要针对每一个核心域概念逐一花费脑力去思考它。
我们之所以选择在分析工作流使用面向对象的分析方法,是因为从思考深度和表示的严谨程度来看,面向对象的分析方法以及UML表示法目前仍然是剖析和整理领域逻辑的最佳选择。
本书在设计工作流的内容,会展示分析模型和各种实现方式的映射套路。事实上,在实现本书的案例时,部分实现会使用函数式编程语言。
8.1.9 案例的更换-发糕智能建模工具
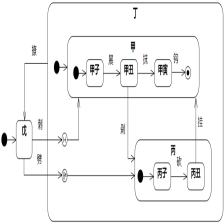
《软件方法(上)》以及下册2018发布的电子版本,使用的案例是“UMLChina系统2018”。案例中大量讨论了给众多联系人发邮件的领域逻辑,类图如图8-22。
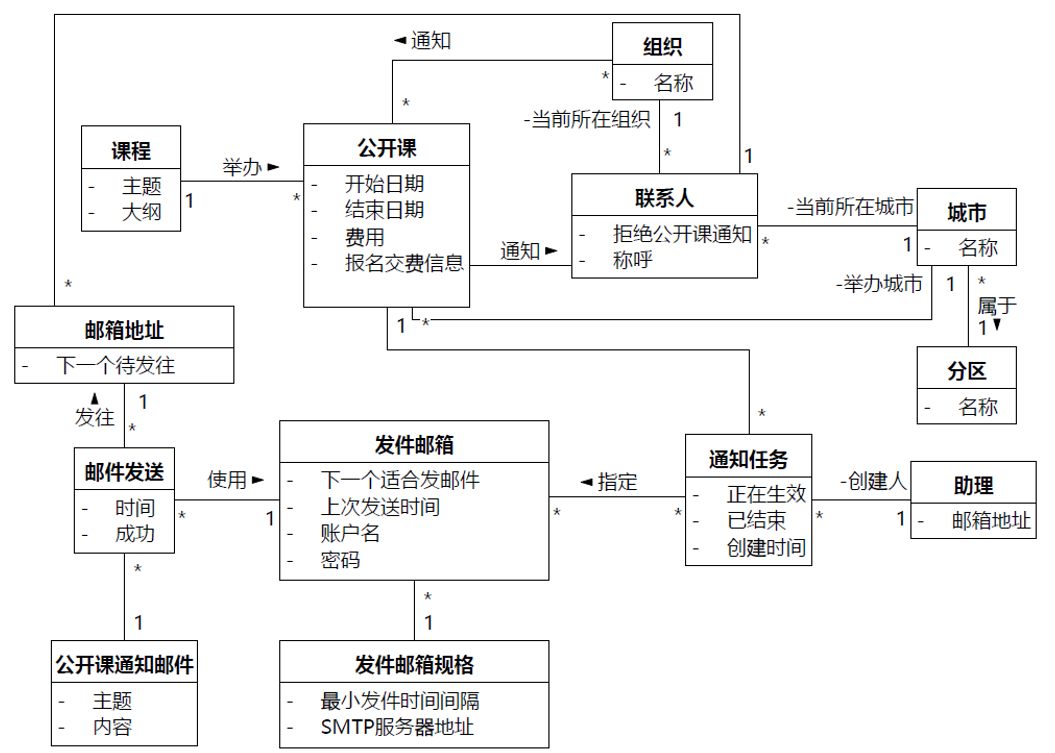
图8-22 本书下册2018版本第8章的案例类图
时过境迁,原先使用邮件、短信甚至QQ的场合绝大部分已经改成使用微信。现在,UMLChina已经很少使用发邮件和发短信的方式来通知学员,除了每年年底会发邮件询问最新邮政地址以便邮寄贺年卡。
而在微信上群发通知,姑且不论实现的难度,从现在的礼仪上来说,是容忍度极低的。所以,我们也不会针对微信的好友批量地发活动消息,只会在微信群里发。
另一个变化是,自媒体平台(公众号、抖音、B站等)成了首要的展示门户,自有网站的重要性大幅下降。
基于以上变化,本书下册的案例不再使用原有的“UMLChina系统”,改为另一个我们正在研发的、封装《软件方法》知识的智能建模工具——暂时命名为“发糕”。
已写完毕的2018版本第8章的“UMLChina系统2018”案例剖析,继续作为附件保留。《软件方法(上)》再版时使用什么案例,到时再看。
为什么要自行研发一款建模工具?
UML规范提供了各种建模元素并给出了语义,但是,在软件开发中挑选哪些元素来建模,元素之间如何串联起来,没有做出规定。
当前的各种建模工具也没有在建模方法学方面下功夫,很多精力花在:
*支持更多的图;
*添加更多的项目管理功能;
*映射到更多编程语言和存储平台。
一些号称“新式”的建模工具,实际上就是把现有工具的一些简单功能搬到网络上,可以在浏览器上使用而已,然后就号称“创新”了。
我们试图制作一款以《软件方法》所述方法学为核心的建模工具。
《软件方法》所叙述的方法学挑选了一些元素来表示模型,如图8-23。

图8-23 《软件方法》所选择的表示元素
建模的推导过程可能如图8-24。

图8-24 《软件方法》的建模过程
我们希望在工具中封装这些知识,包括UML表示法没有涵盖的内容,例如愿景、用例规约等。
也就是说,我们把《软件方法》的知识作为核心域,制作一款封装《软件方法》知识的工具。可以这样说,在下册学习分析设计技能的过程中,我们不仅可以学习建模,还可以学习到对建模的建模。
例如,《软件方法》第2章讲述了愿景以及思考愿景的方法,一些内容截图如图8-25。

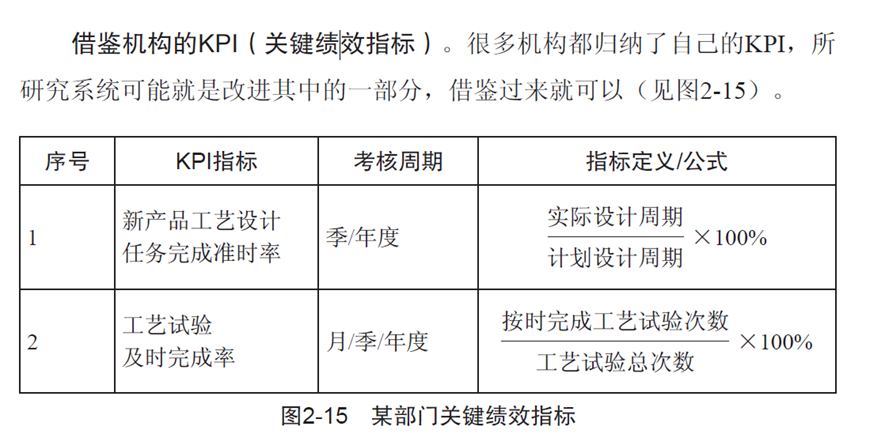

图8-25 《软件方法》第2章截图
对以上知识建模,可能会得到图8-26这样的类图:

图8-26 《软件方法》愿景部分知识的分析类图
愿景建模部分的界面可能如图8-27。

图8-27 愿景建模功能的界面样例
在建模过程中,我们可以在工具中凝固书上所说的:借鉴机构KPI,逐步逼近定位目标组织……等思想,让建模人员更快速和更准确地推导出需求。
通过研发智能建模工具,也可以反哺《软件方法》。随着对方法学内容一步步的领域建模,《软件方法》中如果存在不严谨的内容,在建模思维的扫视之下,将会得到完善。
8.1.10 “发糕”名字的来源——兼谈IT起名
这小节内容本不应该属于下册,应该放在上册第2章“愿景”更合适,但由于第2章当时没有写到这方面内容,所以暂时放在这里。
起名可以分为三种类型:
(1)直接起名
直接用品类的名字起名,例如IBM、Microsoft、Enterprise Architect……包括UMLChina。
IBM是InternationalBusinessMachines(国际商业机器)的缩写,公司创建于1911年。IBM最开始做打字机,后来做计算机,都属于“商业机器”;Microsoft诞生于1975年,当时软件还属于顾客购买计算机时赠送的附属品,还没有“软件业”的概念。
在品类形成的初期,直接起名可以帮助抢占先机,但是不利于将来的延伸。
IBM研发和收购了许许多多的软件,所谓五大软件品牌,都没有得到期望的结果。幸亏IBM是缩写,如果使用全名,对IBM软件的形象就更不利了。
Microsoft的“soft”也让人感觉擅长软件,不擅长硬件,其实微软的笔记本电脑水准很高。
直接起名还有一个问题:容易模仿和混淆。
你来一个UMLChina,他来一个ChinaUML、UMLCn、CnUML,然后你就被淹没在茫茫人海之中。
建模工具Enterprise Architect属于直接起名,两个通用词汇连在一起,如果使用Enterprise Architect碰到问题,用搜索引擎搜索解决方案,和EA相关的内容混杂在大量企业架构、企业架构师的内容之中。

图8-28 搜索enterprisearchitect,头两个确实是EA,从第三个开始就不是了
(2)隐喻起名
名称中不直接包含品类名,而是用一个能联想到品类的名字,例如Google、百度、知乎、闲鱼、滴滴、饿了么、陌陌……。
Google是一个搜索引擎,名字来源于googol,即10的100次方,暗示后面有海量的信息供搜索。域名用google.com而不用search.com之类,原因当然不是买不起域名。如果起名search.com,可能就会有人山寨esearch.com、isearch.com,而Google这个词和起名者的创意相关,如果有人山寨了一个iGoogle,其他人也会联想到iGoogle里的Google怎么来的,山寨起来不划算,不如另起个名字,比如百度。
隐喻式起名虽然和品类的绑定没那么直接,可以延伸到其他品类,但也不是没有影响。百度搞地图、文库还好,搞外卖、商城之类搜索不是关键要素的领域就够呛了,除非不用百度的名字。
(3)无厘头起名
名字来自起名者灵光一闪,和品类没有内在联系,例如Dell、Apple、小米、京东、盒马、喜马拉雅、荔枝……,包括本书的案例“发糕”。
Dell是因为创始人姓Dell,Apple是因为乔布斯当时经常吃苹果,小米是因为大家早餐喝小米粥,京东是因为爱情。
从十多年前开始,我的胃就不好,后来我太太和我说,主食吃发酵食品,比如馒头、发糕等等。于是我即使出差时也注意把主食改为馒头、发糕,尤其喜欢点“西贝”的发糕(此处不是恰饭,虽然我很想恰。欢迎各餐饮企业来洽谈恰饭事宜,反正我吃过的发糕也不只西贝一家)。
现在,我的胃肠已经很好了。当然,还有其他的原因了,例如不喝酒、三餐之外不进食。
(仅供参考,有一定年纪的同学,隔1-2年可以做一回胃肠镜套餐。不疼,10秒麻翻,醒过来就做好了。)
虽然无厘头用的词可能也是通用词,但是词义和品类没有内在联系。苹果不是卖水果的,小米不是卖杂粮的。这和Enterprise Architect不同,Enterprise Architect确实就是奔着“企业架构师”去的。
因为词义和品类没有内在联系,在初期的营销中,必须卖力宣传,而且要和品类一起连起来宣传。例如,Apple最开始叫Apple Computer。有一段时间霸占电梯广告的“瓜子二手车直卖网”,也是连在一起说。光说瓜子,大家以为是卖炒货的。
等到大家对品牌有认识了,再把品类名称去掉。“Apple Computer”把“Computer”去掉,喜马拉雅FM、荔枝FM现在把FM去掉了,“盒马鲜生”也去除“鲜生”,只保留“盒马”。
因为名字不绑定品类,通过宣传给名字赋予某种“气质”之后,就可以延伸到其他品类。Microsoft搞房地产比较别扭,Apple搞房地产,就是创新、精致、有点贵的房地产;小米搞房地产,就是性价比高的房地产,“年轻人第一套房”。

图8-29 小米的广告
我对选择起名方式的看法:
如果在品类形成初期,对该品类看好,下决心锚定这个品类,而且有信心成为各品牌的领先者,就用直接起名好了,显得霸气;如果想要灵活变化,就无厘头起名。
UMLChina和《软件方法》都是直接起名。
UMLChina这个名字,好处是形象鲜明,在UML普及初期很有帮助。一看“UML+China”,就觉得是UML在中国的代表,在中国如果需要UML服务,就是它了。其实,除了我自己和OMG里个别人有过Email联系,UMLChina和OMG并没有官方合作关系,也没有绑定到哪家工具厂商。
好处的另一面就是坏处。
一个坏处是会让人认为“只会UML”。有时,来联系业务的是IT组织的人力资源专员或培训公司的行政老师(女性居多),她们没有软件开发的经历,会问“潘老师,您这边除了UML的培训之外,还有没有针对产品经理或架构师的培训”。我不得不向对方解释方法、过程和工具等概念,以及UML和这些有什么关系。还有,要是OMG把UML改了名字,UMLChina这个名字就杯具了。
另一个坏处是走不出中国。毕竟在很多领域,China和“领先”还不能联系在一起。当然,目前还没有面对这方面的烦恼。
UMLChina如果不用直接起名,用隐喻起名,您觉得叫什么合适?欢迎在评论留言。
UMLChina如果不用直接起名,用无厘头起名,您觉得叫什么合适?欢迎在评论留言。
严格来说,UML不是品类,是品牌。品类是建模语言,UML是OMG这个“厂家”的一个品牌,只不过UML相对于其他建模语言品牌显得太突出,已经接近于品类。类似的例子还有可乐。可乐本来是品牌,后来大家大脑里逐渐建立起这样的概念:那种黑褐色的糖水叫可乐(Cola),于是可乐就成了品类。可口可乐,百事可乐、非常可乐、天府可乐……是可乐的品牌。
同理,《软件方法》也是直接起名,不另外起品牌名字,例如“潘氏方法”、“鲸鱼方法”、“灵便方法”,即使搜索时淹没在海量信息中也无所谓。这也是表达一种信心。
直接起名的书还有“The Art of Computer Programming”。

图8-30 “The Art ofComputer Programming”封面
至于“发糕”嘛,因为《软件方法》的知识是公开的,人人都可以基于方法学开发相应的工具,也许其他人做的工具更好呢?所以就不敢直接起名了,先起一个无厘头的名。
特别声明:以上思考和我对建模的思考不一样,仅属于业余爱好,所以思考的价值不敢确定,仅供参考。竞争成败因素很多,起名因素占的比例难说有多少。
扫码或访问http://www.umlchina.com/book/quiz8_1_1.html完成在线测试,做到全对以获得答案。

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(待续)
如果想早点了解后续内容,也可以带您的项目来参加这个训练,由我在课上剖析项目:

8.2 建模步骤3-1 识别类和属性
8.2.1 三种分析类
当使用面向对象的方法来分析系统时,我们假设系统由"对象"这样一种东西构成,对象封装了数据和行为。
在分析工作流,我们认为系统中的对象在一个虚的"对象空间"中运行。这个空间不是内存,也不是硬盘,只是人脑中的一个逻辑空间,将它想象成宇宙空间也未尝不可。在"对象空间"中,速度不是问题,对象的创建和对象之间的通信都非常快。

图8-31 虚的"对象空间"
以上内容可以用来判断你思考的问题是分析问题还是设计问题。
分析模型受到设计的污染,很容易导致批量的废话刷工作量,导致没有时间思考应该思考的问题(当然,这也可能是某些人乐意的)。
我们可以针对分析模型里的元素,一个一个问“如果性能不成问题,速度无穷快,这个东西还有必要存在吗”,如果答案为否,那么从分析模型中把它删掉。
注意上文提到的"假设"二字。面向对象就是一个假设,如果不认可“系统由对象构成”,也可以分析系统的核心域逻辑,只不过用的方法不叫“面向对象方法”。
面向对象的思考方式比目前的其他思考方式要好一点,原因不是计算机喜欢面向对象或者面向对象更接近于计算机的底层(计算机更"喜欢"人类用机器语言编码,一千万行指令写在一起依次执行),而是面向对象的思考方式更能帮助人脑去剖析复杂问题。
但这并不意味着面向对象的思考方式比其他的思考方式更容易掌握(参见前文提到的全等三角形和三角函数类比),而且随着你掌握了更强有力的思考工具,更复杂的问题就会扑面而来。这些问题之前已经存在,只是之前你没有能力发现以及对付它们——就像“古人很少死于癌症”一样。
在接受“面向对象”假设的前提下,我们接下来就要做第一步思考:系统由什么样的对象来构成。
在这一步思考中,我们通过抽象思维把具有共同特征的对象集合归纳为"类",对象看作类的实例。
归类是人类认知的一种基本技能,其哲学讨论可以追溯到柏拉图的理型论(Theory ofForms)。
依照Ivar Jacoson在“Object-Oriented Software Engineering: A Use Case Driven Approach”(Jacobson 1992)中的思想,在分析工作流我们进一步假设系统中存在三种类:边界类(Boundary Class)、控制类(Control Class)和实体类(Entity Class)。
在模型中,我们通过不同的构造型(Stereotype)来表达三种分析类,如图8-23。

图8-32 三种分析类的构造型
一些UML工具(如Enterprise Architect、Visual Paradigm)已经内置了这些分析类构造型。和第3章讲到业务工人、业务实体的时候一样,如果使用的建模工具没有内置这些构造型,可以自己添加,或者不用构造型区分,通过给类起名"某某界面",“某某控制”,也有助于了解该类在系统中扮演的角色。
图8-33展示了三种分析类的责任、和用例的关系以及命名。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
图8-33 分析类的责任、和用例的关系以及命名。
注意,图8-33中,"每个有接口的外系统映射一个边界类"里的"外系统"不仅仅包括系统执行者,还包括仅接受系统输出信息的外系统。
以上册案例中的"时间→发送公开课通知"用例为例。该用例进行过程中,系统会向软件开发人员发送公开课通知,同时还要向UMLChina助理反馈发送通知的进展。软件开发人员和UMLChina助理在这个用例中仅仅是接受输出,没有输入信息给系统,但系统可以分别设置一个边界类来封装向软件开发人员和UMLChina助理反馈信息的责任,如图8-34所示。

图8-34 外系统映射边界类,用例映射控制类
分析工作流的边界类不暗示任何实现方案。在总责任相等的前提下,它和实现的映射是多样的,可以用图形界面实现,也可以用非图形界面(包括文本、声音……)实现。
即使使用图形界面实现,也不能简单认为一个边界类对应一个窗体。一个边界类的责任可以拆解到多个窗体上,一个窗体也可以和多个外系统交互。如何组织这些责任,应该从外系统的角度来考虑,而不是从用例或实体类的角度来考虑。
图8-35中,“助理接口”边界类被圈住的几个责任来自不同用例的步骤,但在使用图形界面实现时,可以放在面向助理的、通知专用的窗体中。

图8-35 边界类责任的组织
类似的例子还有:一份申请,需要通过系统审批三次,也就是三个不同的用例。在图形界面实现中,可能不需要准备三个窗体,部门主管、财务、副总三个审批人可以在同一窗体上工作,但部门主管、财务、副总各自有对应的分析边界类。
如果某个外系统和系统的交互很多,对应边界类的责任可能会有很多。另一种做法是按"外系统+用例"的组合映射边界类,这样可以减少一个边界类上的操作个数。不过,这样的做法已经暗示“按用例来划分边界”,所以还是建议尽量保持一个外系统一个边界类,如果操作很多,可以将从外系统角度观察可能要分在一组的操作移到一起,EA等工具可以随意定制属性和操作的上下显示顺序。
控制类是可选的,如果在分配责任时发现控制类只起到传递的作用,没有起到分解和分配的作用,那么就可以把控制类去掉。
图8-36展示了三种分析类之间的协作。

图8-36 三种分析类在系统中的协作
执行者先把消息发给边界类对象,边界类对象能履行的就履行,无法履行的责任,再发给控制类对象。控制类对象就像总裁办,不做具体工作,只是将责任分解后分配给实体类对象。
实体类可以按照它们之间的耦合程度组成若干聚合,类似于公司的部门。聚合之间还可以再组成更大的聚合,类似于大部门中有小部门。也有可能有的类既不聚合其他类,也不被其他类聚合,类似于自成一个部门。
控制类对象发送消息时,先发给聚合的整体对象,再由整体对象分配(可能还有分解)给聚合内的其他对象,如果聚合内的对象还聚合了更小的对象,还可以继续分配。最后,由边界类对象反馈信息,完成一个交互回合。
边界类与执行者、控制类与用例的映射关系很明显,所以识别边界类和控制类不需要太多思考。思考的主要工作量应该花在识别实体类上。一个用例需要哪些实体类协作实现、如何协作,一个实体类会参与哪些用例的实现,这是一个多对多的映射,需要由分析员的大脑决定哪种映射最好。
有的分析方法学如ICONIX提倡Robustness Diagram,认为可以通过它来帮助寻找类。开发人员一用确实感觉很舒服,噼里啪啦就发现好多类,有一种"我已经取得了不小成绩"的错觉,不过要是仔细看看,就知道"发现"的多是边界类、控制类。这些类用不着刻意去发现,只要按照图8-33的套路映射即可。最难的工作——寻找实体类以及它们之间的协作,Robustness Diagram却是寥寥带过。所以,本书不推荐开发人员额外花时间画RobustnessDiagram。应该把精力放在识别实体类上,画分析序列图时再直接按照上面的套路映射相应的边界类、控制类。
[2020.01加一套题]UMLChina建模竞赛题大全-题目全文+分卷自测(11套110题)
全程字幕-25套UML+Enterprise Architect/StarUML建模示范视频
[幻灯更新]5月27-30晚-剔除“伪创新”和“无领域”的领域驱动设计-网课
[新增:鸵鸟]软件开发团队的脓包:皇帝的新装、口号党、鸵鸟、废话迷
《软件方法》书中自测题-题目全文+分卷自测(1-8章)16套111题
中文书籍中对《人月神话》的引用(完结,共110本):软件工程通史1930-2019、实用Common Lisp编程……
CTO也糊涂的常用术语:功能模块、业务架构、用户需求……[20210217更新]
















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









