







 本文探讨了Web2.0的概念及其与Web1.0的区别,重点介绍了博客、RSS、SNS等新兴技术如何改变了互联网的面貌,使得用户既是内容的消费者也是创造者。
本文探讨了Web2.0的概念及其与Web1.0的区别,重点介绍了博客、RSS、SNS等新兴技术如何改变了互联网的面貌,使得用户既是内容的消费者也是创造者。
要理解WEB2.0,先得看WEB的历史。 World Wide Web,简称WWW,是英国人TimBerners-Lee 1989年在欧洲共同体的一个大型科研机构任职时发明的。通过WEB,互联网上的资源,可以在一个网页里比较直观的表示出来;而且资源之间,在网页上可以链来链去。在WEB1.0上做出巨大贡献的公司有Netscape,Yahoo和Google。 Netscape研发出第一个大规模商用的浏览器,Yahoo的杨致远提出了互联网黄页, 而Google后来居上,推出了大受欢迎的搜索服务。
搜索最大的贡献是,把互联网上海量的信息,用机器初步分了个线索。但是,光知道网页里有哪些关键字,只解决了人浏览网页的需求。所以,Tim-Berners-Lee在提出WWW不久,即开始推崇语义网(Semantic Web)的概念。为什么呢?因为互联网上的内容,机器不能理解。他的理想是,网页制作时和架构数据库时,大家都用一种语义的方式,将网页里的内容表述成机器可以理解的格式。这样,整个互联网就成了一个结构严谨的知识库。从理想的角度,这是很诱人的,因为科学家和机器都喜欢有次序的东西。Berners-Lee关心的是,互联网上数据,及能否被其它的互联网应用所重复引用。举一个例子说明标准数据库的魅力。有个产品叫LiberyLink。装了它后,到Amazon上去浏览时,会自动告诉你某一本书在用户当地的图书馆能否找到,书号是多少等。因为一本书有统一的书号和书名,两个不同的互联网服务(Amazon 和当地图书馆数据库检索)可以公享数据,给用户提供全新服务。
但是,语义网提出之后,曲高和寡,响应的人不多。为什么?因为指望要网页的制作者提供这么多额外的信息去让机器理解一个网页,太难;简直就是人给机器打工。这违反了人们能偷懒就偷懒的本性。看看Google的成功就知道。 Google有个Page Rank技术,将网页之间互相链接的关系,用来做结果排序的一个依据,变相利用了网页制作人的判断力。想一想网页的制作者们,从数量来说,比纯浏览者的数量小得多。但Google就这一个革新,用上了网页的制作者的一部份力量,已将其推上了互联网的顶峰。
所以互联网下一步,是要让所有的人都忙起来,全民织网,然后用软件,机器的力量使这些信息更容易被需要的人找到和浏览。如果说WEB1.0是以数据为核心的网,那我觉得WEB2.0是以人为出发点的互联网。 我们看一看最近的一些WEB2.0产品,就可以理解以上观点。
Blog: 用户织网,发表新知识,和其他用户内容链接,进而非常自然的组织这些内容。
RSS: 用户产生内容自动分发,定阅
Podcasting: 个人视频/声频的发布/定阅
SNS: blog+人和人之间的链接
WIKI: 用户共同建设一个大百科全书
从知识生产的角度看,WEB1.0的任务,是将以前没有放在网上的人类知识,通过商业的力量,放到网上去。WEB2.0的任务是,将这些知识,通过每个用户的浏览求知的力量,协作工作,把知识有机的组织起来,在这个过程中继续将知识深化,并产生新的思想火花;
从内容产生者角度看,WEB1.0是商业公司为主体把内容往网上搬,而WEB2.0则是以用户为主,以简便随意方式,通过blog/podcasting 方式把新内容往网上搬;
从交互性看,WEB1.0是网站对用户为主;WEB2.0是以P2P为主。
从技术上看,WEB客户端化,工作效率越来越高。比如像Ajax技术, GoogleMAP/Gmail里面用得出神入化。
我们看到,用户在互联网上的作用越来越大;他们贡献内容,传播内容,而且提供了这些内容之间的链接关系和浏览路径。在SNS里面,内容是以用户为核心来组织的。WEB2.0是以用户为核心的互联网。
那么,这种意义上的WEB2.0,和Tim Berners-Lee的语义网,有什么不同呢?语义网的出发点是数据的规整及可重复被机器调用,提出使用语义化的内容发布工具, 试图从规则和技术标准上使互联网更加有序。 Google等搜索引擎,在没有语义网的情况下,尽可能的给互联网提供了线索。 WEB2.0则是鼓励用户用最方便的办法发布内容(blog/podcasting),但是通过用户自发的(blog)或者系统自动以人为核心(SNS)的互相链接给这些看似凌乱的内容提供索引。 因为这些线索是用户自己提供,更加符合用户使用感受。互联网逐渐从以关键字为核心的组织方式和阅读方式,到以互联网用户的个人portal(SNS)为线索,或者以个人的思想脉络(blog/rss)为线索的阅读方式。WEB2.0强调用户之间的协作。WIKI是个典型例子。从这个角度看,互联网是在变得更有序,每个用户都在贡献:要么贡献内容,要么贡献内容的次序.
对下一代互联网的看法,还会有很多的讨论。有一点可以肯定,WEB2.0是以人为核心线索的网。提供更方便用户织网的工具,鼓励提供内容。根据用户在互联网上留下的痕迹,组织浏览的线索,提供相关的服务,给用户创造新的价值,给整个互联网产生新的价值,才是WEB2.0商业之道。
Web 2.0学习指南
历史很重要。对一个技术的学习也应当从历史出发,通过其在时间形成历史的流变,得以知晓现状,甚至能够预知未来。
那Web 1.0是什么呢?
他们说,记得静态HTML的WWW时代么?
(那个时代的WWW应用、人们的Web体验、对社会的影响如何?)
那么动态HTML和静态HTML下的Web相比,是多少版本?1.5?对了,他们是真这么叫的。
(在效果和影响上,与1.0相比,扩展和加深多少?)
要呈现的数据存储在数据库中,通过Web服务端的程序,应用户的请求,取出数据,加上事先设计的模板,动态的生成Html代码,发送到用户的浏览器那里。
他是1.0系列,应为用户在浏览器中所见和Web 1.0一样,它有0.5的升级,因为数据不是事先制作并发布,而是动态生成,和用户的需要交互生成。
那好,在加0.5,到Web 2.0,变化是在哪里呢?
(看到了正在崛起的和改变的,会继续朝着什么方向改变互联网和社会呢?)
更新:关于各个版本的差别,看看亚马逊的例子。
事情没有那么幸运,Web 2.0并不是一个具体的事物,而是一个阶段,是促成这个阶段的各种技术和相关的产品服务的一个称呼。所以,我们无法说,Web 2.0是什么,但是可以说,那些是Web 2.0。
WikiPedia的Web 2.0条目下列出了这些条件:
* CSS 和语义相关的 XHTML 标记
* AJAX 技术
* Syndication of data in RSS/ATOM
* Aggregation of RSS/ATOM data
* 简洁而有意义的 URLs
* 支持发布为 weblog
* RESTian (preferred) 或者 XML Webservice APIs
* 一些社会性网络元素
必须具备的要素有:
* 网站应该能够让用户把数据在网站系统内外倒腾。
* 用户在网站系统内拥有自己的数据
* 完全基于Web,所有的功能都能透过浏览器完成。
(以上内容引用自英文版维基百科)
虽然这只是一家之言,不过,对于其中谈到的几个要素,大家还是公认的。
- 基于RSS/ATOM/RDF/FOAF等XML数据的同步、聚合和迁移。
数据不再和页面和网站混粘在一起,它独立了,它跟着用户走。这是Web 2.0的很重要特征。这也是为什么Blog是Web 2.0的代表的原因。在网志上,常主角的是相互独立的一则则的网志。
独立,然后有物理表现。现在,就能让他们活跃起来。透过对XML数据的处理,这些内容能被自由的组合,被各种应用程序,不论是Web程序还是桌面程序等呈现和处理。
当然,最重要的是背后的人。
- 社会性因素。
内容跟着人走,内容又能够被用户自由的组合,也就是说,用户能够自由的借助内容媒介,创建起一个个的社群,发生各种社会性的(网络)行为。
此外还有标签以及建立在开放标签系统之上的Folksonomy。
- 第三个公认的因素是开放API,这个技术性稍强些,得另花时间研习,可以先看看例子:amazon、flickr、google map等。
从Web应用的产品/服务生产者角度来说,该如何创建Web 2.0的产品呢?
重要的是要抓住这么几点,一个是微内容(这里有定义),一个是用户个体。除了这两个最基本的之外,还可以考虑社群内的分享以及提供API。
微内容:英文是microcontent。用户所生产的任何数据都算是微内容,比如一则网志,评论,图片,收藏的书签,喜好的音乐列表、想要做的事情,想要去的地方、新的朋友等等。这些微内容,充斥着我们的生活、工作和学习,它的数量、重要性,还有我们对它的依赖,并不亚于那些道貌岸然、西装革履的正统文章、论文、书籍。
对微内容的重新发现和利用,是互联网所开创的平等、民主、自由风气的自然衍生,也是互联网相关技术消减信息管理成本之后的一个成果。
我们每天都生产众多的微内容,也消费着同样多的微内容。对于Web 2.0来说,如何帮助用户管理、维护、存储、分享、转移微内容,就成了关键。
用户个体。对于Web 1.0的典型产品/服务来说,用户没有具体的面貌、个性,它只是一个模糊的群体的代名词而已。但是对于Web2.0的产品和服务来说,用户是个实实在在的人。Web 2.0所服务的,是具体的人,而不是一个如同幽灵般的概念。并且,这个人的具体性,会因为服务本身而不断地充实起来。
如何为这个具体的个体服务,是Web 2.0设计的起点。
因此,一类可以被称作Web 2.0的产品/服务将是这样:
服务于用户个体的微内容的收集、创建、发布、管理、分享、合作、维护等的平台。
其他的呢?恐怕就设计到好些人提到的,微内容的XML表现;微内容的聚合;微内容的迁移;社会性关系的维护;界面的易用性等等。
以及是否就是开源、参与、个人价值、草根、合作等等?
Web2.0是许多方面起头并进又相互牵连的一个新的阶段的到来。因此,不同的人,有着不同的看法。那么,对于Web开发人员来说,Web2.0意味着什么呢?
他们说Web2.0阶段,Web是一个平台,或者说,Web正在变得可编程,可以执行的Web应用。野心家们设想这个它的终极目标是Web OS。
Web 1.0时候,Web只是一个针对人的阅读的发布平台,Web由一个个的超文本链接而成。现在的趋势发生了变化,Web不仅仅是Html文档的天下,它成了交互的场所。
Web 2.0 Conference网站的横幅引用Jeff Bezos的话说“Web 1.0 is making the internet for people,web 2.0 is making the internet better for computers”。
具体来讲,他们说Web成为一个开发环境,借助Web服务提供的编程接口,网站成了软件构件。
这些,就是Web Service的目标吧,信息孤岛通过这些Web Service的对话,能够被自由构建成适合不同应用的建筑来。
一些例子:del.icio.us、flickr、a9、amazon、yahoo、google、msn等提供的编程接口衍生出的各种应用。
为什么要开放APIs,这涉及到集市中的商业方面的技术策略。当然,还有更深层的原因,那是什么呢?
这种交互不仅体现在不同的网站服务之间,同时还体现在用户和Web之间在浏览器上的交互。这也是为什么在美味书签的收藏中Web2.0和AJAX如此相关的一个原因。
在Web页面上使用桌面程序有的那些便利,真的是很享受的事情。这恐怕也是Web可编程的一个方面,Web页面不再是标记和内容混合那样的简单,它就是一个可以编程的地方(是这样理解吧?)
有人反对说,AJAX的使用对搜索引擎不友好,只有Web 1.0的站长才关心这个事情吧,在Web 2.0时候,站长应该关心的是用户参与的便利、用户的自由度,至于搜索,有RSS/ATOM/RDF等,更本用不着操心,Google不是已经顺应这个趋势,让大家主动提交了么?
可编程的第三个方面,是否在于Web应用和桌面应用之间的无缝连接趋势的出现?类似这里说的“从工具上,是由互联网浏览器向各类浏览器、rss阅读器等内容发展”
编程的一个重要目的是对数据的操作,因此,对于网站来说,除了Web Service接口之外,最近为简便方式就是将内容以RSS/RDF/ATOM格式,或者有意义的XHTML格式输出,同时实现内容和表现的分离。
[Web 2.0是个历史学的概念,而非是个技术性的概念,它是对Web发展历史断代的成果。对这个概念的梳理,能帮助我更好的把握互联网正在发生的技术与文化。]
中文网志圈谈论的Web 2.0内容摘要:
- “Web 2.0是用来研究现象、发现规律的东西,不是用来招商引资、搭台唱戏的东西。当越来越多的互联网应用采取与用户互动的方式,越来越多的内容是由用户产生,越来越多的用户参与到互联网创造的过程中的时候,其实它代表了一种新的思潮。在这种思潮之下,一些新的技术开始出现,一些古老技术重新焕发了生机。随便你怎么表述这样一种现象,但现象本身是实实在在存在的,不管是叫它Web 2.0,还是社会化互联网。”[Keso:老冒给Web 2.0浇了一桶冷水]
- “我觉得最有价值的一个是, web应用的数据格式开始逐渐出现了交换“标准”...这些标准...更加容易被机器自动化处理...能帮助人更好地过滤和定制化信息。其次,更多的服务将以web service的形式来提供,...这使得web 服务可以被互相集成, 从而诞生更多新的服务...人的重要性被提高了。过去web更多注重在信息提供, 而现在的越来越多的应用更加关注人,也就是所谓“社会性”。此外web的可用性改进正在被越来越重视...”[老冒:朝web 2.0泼点冷水]
- “我认为Web x.x是人们为了区别不同时代Web的发展而使用的,而这些概念也是经过归纳出来的结果。抓住对方向,如Wikipedia中所提到的朝向互动及社会网络的方向发展,不论应用何种技术,只要能达到目的都是很好的。甚至作为一般的使用者,都可以不去理会Web x.x的讨论,因为我们都已经在使用这些技术或网站了。”[图书馆观点:Web 2.0]
- “RSS逐渐成为在线内容提供服务的标准发行平台。Blog以及user-generated内容的兴起。My Yahoo提供的RSS整合型服务。同时提出了值得密切关注的一些发展中领域,其中包括搜索技术,个性化,User-Generated内容(包括 blog,评论,图像和声音),音乐,短视频和Accessibility(易访问性)”[Owen:Mary Meeker新作 - 关于Digital World的发展报告的摘取]
- “我们谈论的Web2.0带给我们的是一种可读写的网络,这种可读写的网络表现于用户是一种双通道的交流模式,也就是说网页与用户之间的互动关系由传统的“Push”模式演变成双向交流的“Two- Way Communication”的模式。而对于Web服务的开发者来说,Web2.0带来的理念是服务的亲和力,可操作性,用户体验以及可用性。”[Owen:BaCKpACK-体验可读写的Web服务]
- “web 2.0是一种可以被分发的信息概述,web文档被格式化成了web数据。我们不会再看到不同旧地信息,现在我们所注意到是一种聚合、再混合内容的工具。”[songzhen:也说Web 2.0的翻译]
- “从这些应用中可以看到:如果基于传统的HTML,同样的功能实现将变得非常复杂和不稳定,数据的再生产和交换成本是很高的。所以:RSS这个标准最终要的贡献就是使得互联网的大部分网站变得可编程:类似的例子还有Blog中的:TrackBack Ping等机制,这些机制都是依赖XML/RPC实现的。当初为Lucene设计一个RSS/XML的接口也是为了这个初衷,它使得全文检索服务可以轻松的嵌入到各种应用中,通过关键词将各种内容之间实现更丰富的关联(Well Referenced)。”[车东:RSS,简单协议使得互联网可编程]
- “聚合的可能性以及如何更好地聚合(通常来说,更好的聚合应该基于个人知识管理和人际关系管理)很显然应该成为新一代或者说web2.0架构的核心之一。还有,你会重新发现,恰好是分散带动了聚合,聚合促进了分散,通过聚合的思维,互联网的网络状变得越来越丰富和密集,web2.0就变得越来越有趣味,它将web1.0时代的硕大节点即门户网站不断消解,去努力创造一个更加和谐的自然网络图谱。”[Horse:rss,聚合的无数可能]
- “新的web2.0网站都依赖于用户参与、用户主导、用户建设”。[Horse:Web 2.0这个词]
- Keso:Web 1.0与Web 2.0的区别
- “表面上看,Bloglines取代了门户,成为一个新的中心,但这里有一个重大的区别。门户是只读的,它带有某种锁定的性质。你可以离开门户,但你无法带走门户的内容。Bloglines则完全不同,你觉得它好用,就会继续使用,有一天你不再喜欢Bloglines,你完全可以导出你的OPML,到另一个 RSS订阅网站,或者干脆用客户端软件浏览同样的内容。所以,像Bloglines这样的网站,是可写的,你可以导入,也可以导出。就像你对信息拥有选择权,对服务提供商也同样拥有选择权,没有人可以锁定你,主动权在你自己手上。”[Keso:再说信息选择权]
- “Flickr、del.icio.us、Bloglines等Web 2.0服务,通过开放API获得了很多有趣、有用的想法,并借助外部的力量,让用户获得了更好的体验。更多大公司也加入到开放API的潮流中,Google、Yahoo!、Amazon、Skype。Google桌面搜索今年3月才开放API,很快就产生了大量的创造,大大扩充了可搜索的文件格式。”[Keso:开放API]
- “归纳:web1.0天天谈门户,web2.0谈个人化;web1.0谈内容,web2.0谈应用;web1.0商业模式,web2.0谈服务;web1.0谈密闭、大而全,web2.0大家谈开放、谈联合;web1.0网站中心化,web2.0谈个人中心化;web1.0一对一,web2.0谈社会性网络;web1.0不知道你是狗,web2.0你去年夏天干了什么我一清二楚甚至想要干什么呢。。。”[van_wuchanghua:发现了N.HOOLYWOOD,我还知道你今年夏天要干什么]
- “我认为Web2.0有下面几个方面的特性: 个性化的传播方式. 读与写并存的表达方式. 社会化的联合方式.标准化的创作方式. 便捷化的体验方式. 高密度的媒体方式.”[飞戈:Web2.0与未来的网络]
- “用RAILS写的网站带有典型的读写网络的特征:RAILS创建的三个架构中的ACTIVE RECORD这个模块中,如果你读读它最重要的基类 ActiveRecord::Base,你会发现有CREAT,EDIT,SAVE,DESTROY这些方法已经天然包含在内了,这让实现一个数据库的CRUDS行为变得如此简单。由于这些类的方法直接和网页的名称映射到一起,这使得网页本身就像一个可以编缉的数据库的数据项。”[Blogdriver:RUBY ON RAILS,wEB2.0世界新生的创造力]
- “Greasemonkey一定名列前茅。这个通过User Script就能修改任何网页输出效果的插件极大的提高了用户阅读的自主性,一推出就引起了轰动,同时也引来了不少争议。”[Webleon:platypus,完全可写的互联网]
- “Web1.0到Web2.0的转变,具体的说,从模式上是单纯的“读”向“写”、“共同建设”发展;从基本构成单元上,是由“网页”向“发表/记录的信息”发展;从工具上,是由互联网浏览器向各类浏览器、rss阅读器等内容发展;运行机制上,由“Client Server”向“Web Services”转变;作者由程序员等专业人士向全部普通用户发展;应用上由初级的“滑稽”的应用向全面大量应用发展。 ”[Don:Web 2.0概念阐释]
Web 2.0阶段的一个重要特征是开放,和Web初期的开放有很大不同,有以下几种突出的表现:
内容方面。
- 内容的创作共用授权。它的广谱和可选择性,让它具有了足够的生命力。CC先是在网志圈中广泛采用,后来许多商业公司也纷纷采用CC方式(比如BBC);先是文本世界采用,后来逐渐推广到了多媒体世界,比如音频、视频、Flash动画等等。一场自由的文化(free culture)运动在各个方面悄然铺开。
- 内容来源方面的开放。和早期的Web阶段相比,由于使用相关设备的成本降低,利用相关技术的门槛减低,人们可以自由生产并发布各种内容,比如文本信息,比如语音记录,比如视频录制等。信息的生产和传播不再仅仅是商业资本或者技术精英的特权。在Web的新阶段,原来在商业、技术与大众之间的信息生产和传播的落差被削平。消除信息垄断和去中心化已经成为可能。不仅如此,信息的生产和消费的模式也发生了变化,从原来的生产/消费的对立,变成了参与式的信息集市。
Web主体方面。
- 商业网站也渐渐采取了开放的、参与的模式。除了内容上的CC授权出现之外。原来并不外露的内容,也随着blog、podcasting等的兴盛而对外开放。一些网站还在技术层面开放,比如开放源代码,比如开放APIs(编程接口),让自己成为一个平台,让用户可以参与衍生产品的创造,用户本身也是产品的生产者。不仅是内容、技术层面,在鼓励用户的参与上,也有相应的开放出现,比如一些新闻网站的RSS源的输出、引用通告(trackback)功能的采纳、blogthis便利的提供,无一不是让用户参与到内容生产、传播的各个环节。
- 个人信息层面的开放。有开放,才有交流,才有社会行为和形态产生。个人内容的开放是与一类Web 2.0服务的兴起有关。它涵盖了内容(文本、声音、影像、视频)、关系、行为等等。
Web 2.0下的门户网站建设
web2.0
博客的出现之所以被称为网络世界的革命,是因为其极大的降低了建站的技术门槛和资金门槛,而使每一个互联网用户都能方便快速的建立属于自己的网上空间。随着配套应用的快速发展,个人博客将在很短的时间内加速成长为类门户型的微型个人网站。博客走进千家万户和各行各业,从而将形成基于个人或小团体的以内容为导向的群体,而其中一定会出现的佼佼者将在很大程度上从门户频道乃至专业网站手里夺走部分甚至大部分读者。这在IT业界和互联网行业正在得到验证。
Web2.0的定义,我认为是在web1.0的服务基础上,是互联网络用户从信息接受者转变成为信息制造者和传播者,从受众转向主体,从单个个体转向社团的新型互联网服务模式。在这种情况下,为用户提供优秀的发布平台、便捷的沟通和展示平台、顺畅的进入和退出机制、高效的信息整合机制变的与提供高质量信息一样重要,甚至更加重要。Web2.0时代的竞争,将不仅仅是内容的竞争,而是综合服务的竞争,其中的关键点包括以上的数个方面。博客是web2.0的最主要的代表。
[文摘]web2.0是一个读写的互联网、一个依靠链接组织起来的互联网。
一边是写,写的人活跃在各种各样的“节点”上,使用各种工具向互联网上传递着数字化的内容,这些内容被保存在数据库、文件系统,甚至是行动中的手机、PDA;一边是读,读的人活跃在各种各样的“主页”上,这里的“主页”已经不能简单的称呼为某个网站的主页,而是互联网上N个活动的节点的主页,一个“主页”上的内容,可能来自几十个节点,“主页”的编写者同节点的所有者一样,也在使用各种各样的工具,从节点读取内容,“主页”的编写者的主要工作已经从创造内容变成了收集和整理内容。
博客
博客的出现,在很大程度上满足了用户由单纯的信息接受者向信息提供者转变的需要,从而得到快速的发展。博客通过RSS、博采、Trackback、TAG等技术,在个体之间已初步形成了社团氛围和初步的社团机制。可以预见,博客服务提供商们将能提供更多的技术手段来加强这种社团性联系,如SNS等。博客圈子的形成,将在另一层意义上大规模提高其内容产生质量和数量。
互动
博客与互联网络的互动、博客之间的互动客观上要求BSP提供商适时提供博客与博客网站之间的互动,需要博客网站为博客提供展示自己的舞台。只有这种互动,才能将博客内容提供质量提高,而进一步深化博客信息质量。从某种程度上说,博客网站的门户效应将极大影响某类博客的发展态势和发展程度,而博客门户也会因为博客发展程度的原因而停滞或加速发展。两者相辅相成。
在国内现有BSP竞争格局下,单纯的BSP服务和单纯的门户内容提供模式都是缺乏竞争力的。必须把两者结合起来,这就需要从博客网站和频道定位开始,逐步强化互动意识,探索互动的方法和技术。Web2.0时代的门户频道建设虽应从传统门户借鉴成功的经验和做法,更重要的是要探索出一条新路,挖掘自身网站博客的优秀内容。才能使2.0门户拥有大大超越1.0时代门户的资讯生产能力和整合、吸纳传统门户优秀内容的能力。极端的说,即便有更好的产品来取代博客,探索门户同博客的深度互动平台也必不可少。
[文摘] 随着支持RSS和XML-RPC的BLOG站点的兴起,WEB2.0的概念也跟着兴旺发达广为传播,就可以理解了。BLOG作为能够体现web2.0中“节点”概念几乎全部要素的一种形式,是存储和输出数字化内容的最佳载体。但是,纵观国内BLOG站点,多数都是提供了输入数据的界面,却没有能有效的让自己再次成为“节点”,实在是有些可惜。
博客相关技术
伴随博客出现而围绕博客服务的技术主要有:博采技术、内容聚合技术、同步技术、SNS技术和tag。博采技术为用户组织了随时摘取有用内容的有效工具,其前提是用户认知到这个信息;RSS技术则将有用的信息源聚合起来,随时将信息源提供的信息发送到用户平台,Trackback技术则将博客团体内其他成员的动向信息传递给用户,保持成员间的有效沟通;SNS技术用于凝聚社团的整体意识,tag是网民自主分类工具。可以说,基于博客单体的技术开发已形成体系并走向深化。与此对应的是,博客网站门户和频道的技术实现还停留在零的状态,甚至连第一代门户的技术都不如。
[文摘]如果把wikipedia中的web 2.0的描述当成“定义”或者“经典”是非常片面的。 其实wekipedia并没有能下出一个定义,只是说明了哪些东西属于目前所说的web 2.0的技术:
CSS + XHTML
AJAX (最近很红火的新概念老技术,我自己的理解和定义是:通过网页内的javascipt调用来减少web页面刷新的必要性来提高web可用性的一种古老技术)
通过RSS/ATOM同步数据
通过RSS/ATOM聚合数据
友好的URL (例如uuzone的blog url: www.uuzone.com/blog/mao 而不是www.uuzone.com/app/showblog.do?blogid=91829&show=1&session=iuewqiyq32 之类的url)
支持按照blog的方式来发表 (说实话我不理解,为什么支持按照blog的方式来发表就算web 2.0 )
采用REST(Representational State Transfer)的API或者XML的web service (其实REST本身就是很古老,而且定义不是非常严谨的。 不过我一直非常欣赏REST方式的web serivce界面)
社会性,能把东西分享给朋友等 ( 这就算2.0? )
其中还说了一些更general的东西:
系统的数据交换要很容易
一些数据应该由用户创建和拥有
完全是web based.
博客门户与博客的相互促进和发展
与传统门户主要为浏览者提供及时有效的信息不同,web2.0时代的门户,将承担以下的功能:1,与传统门户相同的内容服务功能;2,激励或激发专业博客生产内容;3,提供全息信息,聚合各方信息的功能;4,信息互动的功能;5,梳理信息功能;6,促进、激励博客群形成的功能;7,商业性的博客频道还须建立商业链。只有不断的进行此类功能的开发,才能给博客门户带来持续的竞争力。
[文摘] 当网民们打开IE输入news.sina.com.cn就可以看到新闻的时候(请不要把我想像成为和你一样的有觉悟),他们还有什么理由要去费劲的搜集RSS种子?
Web2.0现在有了原旨主义者们,缺少的是“职业者”们,他们才会是实实在在推动Web2.0在中国更广泛发展的中坚力量,这些“职业者”才会是真正把Web2.0给大众化的使者。
没有大众化的Web2.0只会继续迟缓在中国的普及力度,空想构建出来后,更需要实践者们去身体力行,我想keso在某种意义上来说更像是Raymond,而不是Linus,而如今中国的Web2.0,缺少的正是Linus和Redhat。
Linus让我们在中文Web2.0上不至于落后,以至于我如今除了Blog,好使的都是国外的产品;Redhat则能让更多的中国普通网民用更易于接受的方式去把Web2.0用起来。
内容生产的革命性变化给博客门户内容生产部门带来的革新
博客门户内容生产的意义在于拣选信息和高效呈现。博客门户平台担负着用户互动和内容呈现两大任务。博客个人门户和博客网站大门户的互动,必须建立在基于博客相关技术(外部技术)和集取网站博客内容的网站内容管理系统(内部技术)之上。
程序
传统编辑在进行编辑工作时,其工作重点是把握文章质量、页面呈现质量、图片质量以及专题制作质量。而在2.0环境下工作的编辑,更重要的是通过技术上一系列的拣选机制,把相关于门户呈现的内容博客文章聚集起来,实现大门户和小门户的互动。
网络编辑2.0
很多网志都在谈这个问题,不赘述。
关键点和实施难点
1)前期没有太多互动资源
2)资源整理难度大
3)如何形成有效的、可供阅读的信息集成网页
4)门户内容和互动内容的整合
发掘优秀博客,初期阶段以这些博客为主来进行内容互动,逐步激励和扩大内容合作的质和量,是解决的这些问题的可行方式。
[文摘] 当杨致远在图书馆里做搜索引擎的时候,他想到的是用大量的访问量来换取广告,10年以前他想到过会有一家像Google一样做搜索引擎的公司吗?马化腾在最初做OICQ的时候,想到过除了在QQ上做广告和靠qq.com做门户以外其他的来钱途径吗,可现在呢,QQ每天有多少钱是靠卖QQ号还是靠广告费呢,能想到的增值服务都慢慢被他们想出来.
信息时代啦,做事不要想的那么清楚,目光不要看的那么的远,脚踏实地一点,跟着技术的风,不会吃多少亏的.
再大的背景,再好的前景,没有技术含量,也最多像FM365一样昙花一现而已
前景
博客和博客门户的互动有没有前景?这个答案是肯定的。作为互联网世界的关键性节点,博客门户有最大的资源和实力迅速建设成为博客世界的最大的节点。内容原生性和滚雪球式的资讯发展形式,将带动博客门户内容建设成倍增长,远远超越传统门户的原始内容生产模式。可以说前景极为乐观。
建立博客和博客门户的互动,是这一切的开始。
web2.0是以用户为中心的讲究个性化服务和体验的"去中心化"的互联网,它不会洗心革面,也与"众"不同。
门户首当其“冲”
一场酝酿已久、但却突如其来的Web2.0风暴正在展开它潮湿的味道。Web2.0是什么?它会是互联网新的变革因素么?它将如何改变我们已经越来越依赖的互联网?
美国媒体巨子默多克宣布,已于7月18日与Intermix公司达成协议,将以5.8亿美元的现金收购对方,新闻集团从而将拥有MySpace.com网站47%的股份。MySpace.com目前是美国最热门的社会网络之一。
默多克曾在20世纪90年代中后期预言,互联网破坏的生意要比它创造的多,他也曾因为不接受互联网而被指责。如今又是什么力量让这个曾经对互联网退避三舍的媒体巨人重燃互联网热情?
这股新的力量被它的推动者们称为Web2.0,社会网络就属于这一现在炙手可热的概念。推动者们的论据之一是Web2.0光环下的博客早将2001年的“9·11事件”最真实地展现在世界的面前,而新近发生的伦敦大爆炸的消息也是第一时间从博客上传播开来。
Web2.0的推动者们认为,传统门户网站单向播放式的信息提供方式,使得用户处于一种被动接受的状态,而现在Web2.0将改变这一切,用户将可以成为信息的生产者。
门户又一次站在了风口浪尖。
“新浪和类似的传统门户都走进了死胡同?”国内有媒体发出这样的疑问。
2005年7月19日,原知名IT评论家方兴东将自己旗下的“博客中国”改版成为“博客网”,并提出了雄心勃勃的商业化计划。
“博客的出现,最大价值就在于它有潜质挑战传统的门户。”方兴东这样表达博客的潜力。
然而,传统门户似乎对这股新兴的力量并没有感到太大的惊讶。
“我认为博客根本不是什么新东西,它其实是BBS和个人专辑的一个混合体。从互联网上个世纪诞生那一刻起,其实就有这些东西了,博客只是它的一个新的名称。另一方面,RSS现在也很热,但是我感觉目前形势很难让人相信它会成为一个完全主流的应用。”新浪网总编辑及全球资深副总裁陈彤对《互联网周刊》表示。
Web2.0到底是什么?它是一种产业升级抑或概念炒作?它将给互联网行业带来哪些变化?它的商业价值在哪里?它会带来新一轮的投资热潮么?
面对Web2.0这个新生的概念,业内人士众说纷纭。《互联网周刊》通过大量采访业内相关人士,包括传统门户网站高层、Web2.0的操作者、独立评论人士以及风险投资者,试图对以上问题做出具体描绘。
门户首当其“冲”
“Web2.0并没有准确的定义,而是对现象的一种描述。让用户自己主导信息的生产和传播,从而打破了原来门户网站所惯用的单向传输模式。”Donews网站总编辑、IT评论家洪波对《互联网周刊》表示。
的确,作为一个新生的概念,Web2.0并没有一个精确的范畴。大部分接受采访的人士都认为,Web2.0相对于Web1.0(传统的门户网站为代表)具有更好的交互性和粘性。
交互性是指在Web2.0时代,用户将不只是被动地在网上阅读信息,而是同时成为信息的制造者。
“传统门户提供的是典型的一对多的广播式的服务,有大量信息的采集、编辑、把关、进行分类整理和编辑之后,再提供给所有人。而且门户的这种一对多的广播式服务客观上不断形成门户议程设置上的可能发生的公众暴力。首页上的新闻就是这么多条,编辑把关人的选择决定了你会看到什么,你会褒贬什么。”独立的IT评论家方刚如是说。
“Web2.0势必对原有的门户网站造成冲击,导致它们垄断信息的成本越来越高,效果越来越差。可以看到,很多人开始通过订阅RSS获取信息,而不仅是到门户网站上去浏览新闻。”洪波表示。
毫无疑问,Web2.0所代表的开放式的信息沟通方式必将对集中式的门户产生冲击。但是这样的冲击会有多大?
“Web2.0并不是一个革命性的改变,而只是应用层面的东西。目前这个需求到底有多大可能并不是很乐观,现在可能不会这么快对原来的门户网站带来明显的冲击。”著名风险投资IDGVC(IDG技术创业投资基金)的高翔对Web2.0的看法非常审慎。
但即使目前Web2.0所代表的应用并没有给传统的门户造成明显的冲击,其在用户粘性方面对门户的冲击将是可以确认的。用户粘性的冲击其实由来已久。垂直类专业网站是冲击门户用户粘性的第一股力量。当前程无忧、携程网等垂直专业网站纷纷崛起的时候,门户的用户便遭受了第一次的分流。
“如果说一个传统门户出现问题了,网民可以到另外一个门户看同样的内容。但是作为一个博客如果出故障了,那么网民将很难找到替代者。网民的劳动成果和生活都在这个网上,所以网民的忠诚度、参与程度会远远比Web1.0时代高得多。”方兴东这样形容Web2.0的用户粘性。
虽然门户网站对Web2.0这一概念并不感冒,但是众多Web2.0概念下的应用已经开始融入门户网站。新浪上月推出了互动式的搜索引擎爱问(iAsk),之前则已经推出了VIVI收藏夹和RSS,同时也在开始内部测试自己的博客服务。这些新的服务都带有明显的Web2.0特征。而另一门户搜狐则早在2003年就开始推出了自己的博客服务,不久前更是对自己的IT新闻频道进行大幅改版,Web2.0的相关应用在改版后的页面上随处可见。
Web2.0:如何被商业改变
目前所能看到的Web2.0对传统门户的冲击大都集中在新闻信息的传播方面,而在更多商业方面的冲击则还没有体现出来。
作为一个新生的概念,Web2.0目前所延伸出的应用还非常地少,主要的应用包括RSS、Blog、SNS、Tag以及WiKi等。而这些应用目前也并没有非常成熟的商业模式。
“应该说风险投资目前比较关注Web2.0的发展,但是IDG现在还没有实质的投入。Web2.0时代大家可能会更着重于挖掘个人的力量,但是你还是要找到合适的运用,不是每个应用都需要Web2.0。”IDGVC高翔说。
在国内,博客的商业化是最先被探索的。从2004年6月开始,以前的博客中国、现成的博客网便开始了商业化的尝试。
“具体来说,目前主要是三种收入模式,一种是广告;第二是无线增值业务;未来我们最有成长性的收入模式将是用户增值服务,这三块收入会是未来最核心的收入模式。”博客网现任CEO方兴东对博客网商业化的前景十分乐观。
这些商业模式依然没有摆脱Web1.0时代的套路。作为一个新兴的概念,Web2.0相关的商业探索显然还需要更多的努力。
“虽然从去年开始,国外投资者围绕Web2.0发生了众多资本运作和并购的案例,但是目前在全球都没有成熟的商业模式。有部分的网站通过收取会员费获得收入,但这显然不是长久之道。”高翔表示。
“有了用户资源也就有了盈利的可能。几年前,IM(即时通讯)也在探索盈利模式,而后来的事实证明,像腾讯这类赚有大量用户资源的公司,赚钱的途径是非常多的。”洪波却对Web2.0的前景非常看好。
Web2.0:新经济下一波高潮
当年试图传播互联网概念的新浪们,今日却成了Web2.0分子攻坚的头号敌人,而持有Web2.0技术的互联网革新者在刻意强调自己的Web2.0身份。而这些已经捋胳膊动手的Web2.0分子,却都又回到了1999年的状态——找钱。
每天,我们都在门户网站看新闻、用邮箱收收信、用QQ聊聊天……互联网生活不知从什么时候起开始变得僵化
当你每天固定登录三大门户网站,看着千篇一律的新闻页面和链接时,是否感到了窒息?当你用有限的生命面对无穷的网络信息时,是否感到了强大的压力?
有没有一种新的形式让我们活在一个高效、新鲜而有活力的网络世界里?
Web2.0(第二代互联网)——正在新崛起的互联网势力,它利用博客、内容聚合、社会性网络等技术,形成了全球性的新一轮互联网创新热潮。
谁毁了网络生活
“现在的互联网死气沉沉,所有2001年之后的幸存者都在睡大觉。中国的互联网用户被模式化了,新浪、搜狐等门户的新闻已经形成了固定的套路,每天一亿多网民都在过着近似的互联网生活。”
这是一位第一批互联网网民最真切的抱怨。
目前中国互联网95%的应用和流量都来自于浏览器,在网页泛滥的模式化互联网外,QQ和MSN两大即时聊天工具,电驴和BT两大P2P下载工具,成了目前中国互联网少有的日常佐菜。
实际上从商业态势上,新浪所开创的门户模式也在面临增长乏力的困境——网络广告增长乏力,更多收入都依赖于短信增值等电信支援。
所有的门户都意识到了自己的商业前途问题,但是庞大的公司架构,以及公开上市信息披露的需要,让门户大船并不容易掉头。
Web2.0——近几年新兴的一波互联网技术,以博客、内容聚合(RSS)、社会性网络(SNS)为主要体现形式,相比目前我们已经习惯的网络,它在真实性、个性化、交互性方面大大提升,声势浩大的Web2.0运动正在形成了全球性的新一轮互联网热潮。
这些Web2.0定义的典型技术,似乎成为了最近全球互联网蠢蠢欲动的技术援军。这些符合Web2.0的技术模式,都给传统互联网带来致命的打击。
技术创新再造网络
2003年底,从全美排名第一的商学院凯洛格毕业后,刘勇直接回到了中国。
怀揣着美国DFJ投资集团的数百万美元回到北京,刘勇迅速组建了一家名为亿友的交友网站。
到2005年7月,亿友网络已经开始赢利,用户数也达到上百万人。
刘勇是幸运的,DFJ是Hotmail、SUN、Skype、百度最早的投资机构,DFJ看好新一轮的Web2.0技术,而刘勇的亿友网站采用的社会性网络技术正是典型的Web2.0技术。
刘勇只是一个例子。事实上,与亿友公司几乎同时进入中国社会性网络市场大大小小企业多达数十家。
当定制阅读新闻的RSS技术,被雅虎、CNN等媒体网站的推崇,被很多中国互联网知识派当做技术法宝。但是这些Web2.0的技术模式却都存在着一些本质的非商业特性。
麻省理工的《技术观察》就曾经针对Web2.0的技术特性进行过分析,“博客、RSS、播客等符合Web2.0定义的技术,都在强调分众传播的对等信息交互,也就是信息接受者同时也是这些信息的创造者,若干的博客汇集成新的信息输出者,每个人在挤奶的时候还要喝奶,这其中自身的商业循环,绝不可能以浅薄的收费服务或者广告来衡量。”
“这是个技术驱动型的市场,创业公司有很多机会。”华登国际的计越告诉记者,在Web2.0的时代,中国和美国的差距并不大。
华登曾是新浪网最早的投资机构之一,最近在中国刚刚投资了一家网上虚拟物品交易公司。
“这些技术会成为新一代网络的基础架构,关键是谁先找到好的赢利模式。”IDG中国的毛丞宇认为,与美国相比,中国Web2.0还处于刚刚起步的阶段,这对一向擅长早期投资的IDG来说,机会正在到来。
所有这些试图操置Web2.0技术的新兴互联网分子们,跟七八年前的王志东和张朝阳没有什么本质区别,依靠互联网快速致富,依旧是Web2.0背后不公开的商业思维。
实际上,当年试图传播互联网概念的新浪们,今日却成了Web2.0分子攻坚的头号敌人,而持有Web2.0技术的互联网革新者在刻意强调自己的Web2.0身份。而这些已经捋胳膊动手的Web2.0分子,却都又回到了1999年的状态——找钱。
RSS的力量
有则笑话:一只母狼追赶一只白色公兔,公兔从数杈间逃走,母狼紧随其后。很不幸,母狼被卡住了,公兔遂强奸母狼迅速逃跑,母狼大怒挣脱后去追公兔。公免逃至一沼泽地边,沼泽地边有一躺椅,上有一报纸,已无路可逃,公兔急中生智,在沼泽地边打了个滚,变成一只灰兔,然后躺到椅子上,盖上报纸,装作游客。母狼追至沼泽地边,不见白兔,便问灰兔见过白兔经过否?灰兔掀开身上的报纸问:“是那只强奸了的母狼的白兔吗?”母狼听问,立即变得十分羞愧,说:“这么快就见报了?”
这则笑话题为“媒体的力量”,令人一番捧腹大笑后你是否联想到,从报纸、广播、电视到因特网、移动通讯,新旧媒介的更替,不仅改变了大众获取信息的途径和生活方式,而且为企业带来商机,甚至催生了一批崭新的行业。因为对于现代人,信息正如同淡水一样不可或缺,媒体正充当了“输送管道”的作用。然而,这一切随着RSS技术出现似乎又有了新的转变,如同你可以在水中加上适量的糖、冰块,甚至选择味道有点甜的矿泉水或者百分百蒸馏水,做为信息的受用者终于有了对信息的绝对选择权,换句话说,每个人都可以亲手设计自己喜爱的“报纸”,获得自己需要的信息,这就是RSS的力量。
一、RSS究竟为何物?
RSS到底是什么?它可以是“Rich Site Summary(丰富站点摘要)”、“RDF Site Summary(RDF站点摘要,RDF是一种语义网技术)”,还可以是“Really Simple Syndication(真正简易聚合)”。由于该技术出自不同的源头,不同的技术团体对其做出了不同的解释。但简单来说,RSS是站点用来和其他站点之间共享内容的一种简易方式(也叫聚合内容),通常被用于新闻和其他按顺序排列的网站,例如Blog。一段项目的介绍可能包含新闻的全部介绍等。或者仅仅是额外的内容或者简短的介绍。这些项目的链接通常都能链接到全部的内容。网络用户可以在客户端借助于支持RSS的新闻聚合工具软件,在不打开网站内容页面的情况下阅读支持RSS输出的网站内容。
关于RSS的演变有许多不同的传说,尽管它诞生之处曾被视作“扶不起的阿斗”而遭人遗弃,但从2004年Blog的兴起,RSS技术又重新引起人们的注意。
二、RSS只为“博客”而生吗?
RSS领导的是一次大众获取信息方式的革命,即由被业内人士称为“推技术”向“拉技术”的演变,按照这一线索回顾RSS的发展历史,可以将它大致分为两个阶段。
第一个阶段是RSS萌芽时期,即“推技术”的出现。早在MS推出IE 4时,为了与当时的竞争对手Netscape抗衡,推出了一个与Netscape相似的新闻频道。而Netscape也迅速做出回应,定义了一套描述新闻频道的语言,这就是RSS,其中参考了Dave Winer的scriptingNews格式规范。由于Netscape自当时起每况愈下,所以最终也没有发布一个正式的RSS规范(只发布了一个0.9版本)。而微软也在当时推出了支持自己IE的CDF(Channel Definition Format)数据规格,与RSS非常接近。微软试图用新闻频道的功能把“推”(Push)技术变成一个应用主流,并与Netscape抗衡。不过出乎预测的是,“推”技术自始至终没有找到合适的商业模式,而且伴随着其他各类网络特性的出现,也日益无法显现自身的优势。新闻频道在浏览器中的地位最终日暮西山,最后也在IE的后续版本中消失了。
第二个阶段应该是RSS发展时期,即“拉技术”的雏形。认为它更类似一种“拉技术”,是因为用户的收集器按特定时间间隔或特定操作控制,从提供信息的网站上更新资料无论IE还是Netscape的新闻频道的确落入低谷,但先前RSS并没有被业界人士所抛弃。特别是近年来,Blog从一个专业群体开始,逐步成为了网络上最热门的新话题。而RSS成为了描述Blog主题和更新信息的最基本方法。于是RSS这项技术被着名Blogger/Geek戴夫·温那(Dave Winner)的公司UserLand所接手,继续开发新的版本,以适应新的网络应用需要。新的网络应用就是Blog,因为戴夫·温那的努力,RSS升级到了0.91版,然后达到了0.92版,随后在各种Blog工具中得到了应用,并被众多的专业新闻站点所支持。在广泛的应用过程中,众多的专业人士认识到需要组织起来,把RSS发展成为一个通用的规范,并进一步标准化。一个联合小组根据W3C新一代的语义网技术RDF对RSS进行了重新定义,发布了RSS 1.0,并把RSS定义为“RDF Site Summary”。这项工作并没有与戴夫·温那进行有效的沟通,而戴夫则坚持在自己设想的方向上进一步开发RSS的后续版本,也并不承认RSS 1.0的有效性。RSS由此开始分化形成了RSS 0.9x/2.0和RSS 1.0两个阵营,也由此引起了在专业人群中的广泛争论。
那么RSS是否最终就停留在Blog的温暖怀抱里呢?也许各大门户网站早在以吸引眼球为目标的时代就开始领悟:任何能赢取大众注意的技术最终都会催生成功的商业模式。这里首先强调的还是大众对新技术的接受和认同,尽管确定合适的商业模式有待时日,但有了人气,赢得利润可能就是“万事具备,只欠东风”了。QQ如此,GOOGLE如此,那么精明的网络英雄们当然不会错过RSS。
于是,Yahoo、BBC、CNN、Amazon、Ebay等国外新闻站点,以及网典、Blogchina等中文网站都纷纷推出RSS新闻频道,同时所有标准的Blog站点也都支持RSS。鉴别这些也很简单,在所有提供RSS频道的站点上,都可以发现一个橙色的XML图标或者RSS图标,图标所链接的也就是RSS feed汇总文件的地址。通过专门的RSS阅读器就能很方便的把这些频道添加到个人收藏(后面会详细介绍)。
此外,一些网站也利用RSS技术为时下热门的“搜索”服务锦上添花。例如“My Yahoo!”个性化服务中添加了RSS聚合器可以自动反馈第三方的网站内容。这样,在访问雅虎的用户就可以链接其他网站的内容并同步更新;同时,雅虎还通过RSS整合自己提供的内容,如新闻、天气、体育和股票信息等。相比之下,Google的做法更为老道,自去年收购Blogger.com之后,Google自年初开始允许上百万用户将在线日记与其他站点进行同步。而为了争夺未来的标准,Google尝试抛开RSS,另辟蹊径,即使用Atom格式代替现在广泛使用的RSS。然而,无论Atom和RSS之争,最终花落谁家,以RSS技术为代表的“拉技术”已显现其主流趋势。
除此之外,迪斯尼公司利用这一技术发布视频新闻,苹果公司则利用它向用户通报其最新的音乐咨询,这些更预示着围绕RSS的一场群英会正拉开帷幕。
三、RSS,我该拿什么来爱你?
如果对RSS还心存不解,那么用过之后你就会深有感触,甚至一发而不可收拾的爱上它。
首先,用户需要安装RSS阅读器,目前国外有很多优秀的软件,例如RSSReader、FreeDemon、SharpReader、iSpace Desktop等,国内也有诸如周博通、看天下等软件。
安装之后,就需要在支持RSS的网站上订阅自己喜欢的内容。以天极网的RSS频道(Http://rss.yesky.com)为例,登录之后:
1、在页面中找到有XML 字样图标,点击想要订阅频道的XML图标(如果已经给出了URL 链接,可以复制后直接跳到第3步) 。
2、在出现的新页面中复制IE 地址栏中的URL。
3、添加为RSS阅读器的收藏频道。以iSpace Desktop为例,点击工具栏中的“新频道”,在弹出的“频道属性”窗口的“一般资料”选项卡中将刚才复制的URL地址粘贴到“Newsfeed地址”中,在“分组”选项卡中选择合适的频道分组后点击“确定”,iSpaceDesktop便会自动连接上该频道获取RSS 新闻列表。
按照以上方法,用户可以完全定制自己的新闻频道,在倡导个性化服务的时代里,RSS所实现的一切都是如同IBM所说的随需应变(On-demand),凭借RSS的力量,它似乎很快就会虏获大众的芳心。
互联网时代注定是不安分的,因为每一个新概念的出现都能触动某些人敏感的商业嗅觉。因此Blog、RSS、Wiki百科等被定义为Web 2.0的技术一经出现,便让整个互联网蠢蠢欲动起来。然而,当许多Blogger还在捍卫自己的博客领地,为Blog是否应当商业化争论不休时,他们也许没有想到互联网投资者已经调转目光,投向因Blog而重获新生的RSS。在投资者精明的头脑中,正在勾勒从RSS到商业模式的蓝图。凭借RSS的力量,现有互联网格局真的会一如他们所愿而重新洗牌呢?
一、橙色小标签背后的争论
随着越来越多的Blog和各大门户网站支持RSS,越来越多的网页上都在显眼的地方多出一个标有XML或RSS的橙色标签,仿佛给原本已五光十色的网页又添加了一粒辛迪-克劳馥式的美人痣,迅速成为一种互联网上的时尚标志。然而,对RSS的争论从它诞生之初就似乎没有停止过,即使今非昔比的RSS随着Blog的兴起而无限风光,其中最为激烈的争论还是来自个人门户的Blogger们。
吴鹍在他的Blog中发布的 “RSS必是下一个垃圾 拒绝使用RSS的十个理由” 一文,在Blogger中引发了有关RSS是否有用的争论。文中的十条理由对RSS的无用性据理力争,其中他认为自己的阅读方式是海量阅读,不会选择个性化,矛头直指RSS之前引以为豪的个性化服务,而有其他Blogger也对此形象的比喻为在获取自己感兴趣的房价、股票或者汽车等新闻之外,用户还可能偶尔关心一下“芙蓉姐姐”,这需要的仍是传统门户网站模式下的海量阅读方式。然而,另外一批以Keso为代表的Blogger认为,RSS把信息的选择权重新归还到个人手中,使信息选择自由相对于个人来说变得宽广。尽管这种自由是相对的,真正的选择权还是把握在媒体手中,但仍不能否认RSS使网民有了更多的话语权。
如果说来自个人门户的争论更多的是从纯技术或其接受程度角度审视RSS,那么门户网站及其投资者考虑更多的是RSS的商业价值。也有人指出RSS出现后,网民可能只需要RSS阅读器,而不是IE,通过更新频道而不是输入网址访问门户,就能获得他们需要的信息,这样会影响门户,特别是门户网站的广告收入。而Keso认为利用RSS可以使个人门户与门户双赢。门户们可以用RSS加强与门户以外信息的整合,涉足个性化信息领域。而个人门户,包括Blog等,借助RSS可以更方便地享受到门户所提供的信息服务。其次,个人门户应该是在门户的基础上建立起来的,因为现在的网络环境也好,将来的网络环境也好,相连是必然的趋势。最后,他指出RSS目前对门户来说没有冲击,对传统论坛的冲击才是明显的。而对于门户来说,传统论坛夺走了门户很大的一部分流量,门户真正放心不下的是外面那些凝聚力很强的圈子,如何吸引他们才是真正困难的,RSS没有什么技术含量,相反,可能门户们更期望借助RSS重新找回凝聚力。
无论有关RSS的争论最终结果如何,设计出RSS的商业模式并得以应用才是最有说服力的,而FeedBurner的出现似乎令争论双方都大吃一惊,人们看到一种崭新的信息服务模式。
二、FeedBurner模式的诱惑
走近FeedBurner
Feedburner是一家位于芝加哥的Startup公司,成立于2004年2月,2004年7月获得Portage Ventures 7位数字的风险投资。该公司在商业上将自己定位于渠道提供商和RSS预处理程序,作为第三方(Third Party)服务,建立一种完全基于RSS渠道的经营模式,他们既非内容提供商(Conetent Provider),也非一般情况下的服务提供商(Service Provider),而是在内容与服务之间建立一种容器模式的渠道服务,作为读者/订阅来说,是获取信息的渠道,而作为内容提供方来说,则是信息传播的的渠道。而在这个容器之上,他们提供了各种增值服务诸如流量统计,个性化处理,并同时建立起他们的商业模式,如Amazon的广告,RSS广告等等。
公司CEO Dick Costolo认为他们的商业模式主要是基于RSS的广告模式,用户可以通过Feedburner的服务在RSS中嵌入Amazon的广告,如果这些RSS广告点击而在Amazon产生消费的话,用户也可以通过Amazon Affiliate计划获得一定的收入。而目前Feedburner已经拿到至少一项关于RSS广告模式的专利权,并且正在开发类似Google Adsense基于相关性内容的RSS广告技术,也将申请相关专利权。除了RSS广告模式,Feedburner的RSS流量统计也是一项很有潜力的服务,许多用户使用Feedburner正是得益于可以通过它来观察通过RSS访问Blog的情况。而同时,对于Feedburner来说,大量的数据统计也是非常宝贵的信息,这些都是进行市场研究和分析目标用户广告投放的有价值资源。最后,通过与其他RSS-related服务如Flickr,Furl等,以及与内容提供商如媒体,报纸等网站建立合作伙伴关系,进一步的在渠道上开发商业机会。
简单来讲,这种商业模式包括三方面:
首先是广告,就是在RSS中插入广告。这个思路主要是着眼于一些内容发布者可能乐于通过自己的内容赚钱,FeedBurner就可以扮演类似Google AdSense这样的角色。
第二方面是增值服务,如提供更详尽的统计分析服务,即将推出的Total Stats Pro就是这样一种服务。我之前曾介绍过FeedBurner的RSS访问统计,对于那些关注读者喜好的出版者来说,RSS访问统计的价值不言而喻,这就像电视台的收视率调查,或在线广告的点击分析一样重要。
第三方面是提供大宗RSS源的管理服务。一些客户需要对他们大量的RSS源进行有效率的管理,这方面FeedBurner可以做得很专业。
隐现新型网络信息供应链
按照传统的网络行业分类标准,网络信息服务可分为三个层次:基础层、应用层、内容和商务层。这种分类方法不仅很有层次性,也表现出网络行业协作和服务关系顺序,类似传统行业供应链中的上下游关系(如图1左)。其中,基础层包括网络设备、操作系统软件、通信环境、接入服务等网络产业运营所必须的基本设施,服务对象是应用层,例如思科、电信营运商、ISP等。应用层提供网络软件、网络设计、数据库、网站开发等技术应用服务,为内容和商务网站提供服务,例如IBM, HP, ORACLE、微软等。内容和商务层直接面向最终消费者服务。内容是互联网上的媒介平台服务,也就是ICP,包括综合门户、垂直门户,网上社区,网上交易代理平台等,是无形商品的服务型交易,不存在实物的转移,收入来源有服务费和广告费等,例如YAHOO, SINA等。商务层即网上商店,内容和 商务层由于都是通过互联网直接向消费者提供有形的或是无形的商品和服务并获取收入,因此同属互联网商业的范畴,然而,FeedBurner的出现从某种程度上改变了现有“供应链”,即将内容提供商和渠道服务商分离,消费者通过渠道服务商获得信息而非直接从内容提供商获取,另一方面信息渠道服务商通过上述FeedBurner的商业模式赢得利润。

图1 两种网络信息服务供应链
然而,对于这种新型商业模式也存在一些问题:
1、用户数量少。在国内,RSS技术的普及和市场的发展正处于启蒙时期。据看天下不完全推算,目前国内的RSS用户数大约在20万左右,而全球用户估计在1000万左右。然而网络经济的规模效应表明,只有当用户数量大到一定规模时,网络经济的边际成本实际为零,这样就能赢得更多的利润。因此RSS商业模式的成功还有待时日。
2、商业模式单一。尽管继FeedBurner之后又出现诸如Feedsky等一些追随者,但似乎仍跳不出“广告”赢利的怪圈,而这一点又偏偏与RSS的初衷相背。如果抛开FeedBurner提供的统计服务等,它是否又会回到门户网站中广告漫天飞舞的样子?这都有待于新的商业模式出现。
3、供应链中的利益分配。在信息渠道服务商与内容提供商之间的利益分配问题,关系到这种商业模式还能继续走多远。因为,信息的主要来源还是诸如门户等内容提供商,即使Blogger能笔耕不缀,写出更多的Blog,但离开门户他们本身的信息获取也成了无源之水。
因此,尽管FeedBurner的成功在平静已久的互联网业中博得满堂喝彩,但距离RSS的成功尚路漫漫且困难重重。
三、RSS敢问路在何方?
在RSS这条产业链中,以下方面是值得投资者考虑的领域:广告、搜索、阅读器、分析工具、聚合门户、商业及服务领域的RSS应用。
广告:随着RSS的流行,广告必将进入这个领域,而且目前已经有不少公司正在进行这方面的尝试。此外,对RSS内容进行分析进而提供上下文相关广告内容的技术也将会是RSS广告领域的重要投资点,不过毫无疑问,Google始终是这个领域一个最大的潜在竞争对手;
搜索:RSS搜索领域才刚刚开始发展,还存在许多创新的机会,这些创新也就是重要的投资点所在;
阅读器:RSS阅读器存在客户端与在线阅读两大阵营,而未来的阅读器除了更方便用户订阅外,有两个继续发展的方向:一是加强对信息的处理能力,帮助读者对付由于RSS造成的信息过载问题,让RSS阅读器成为个人的重要知识管理的工具,二是日后加强对付RSS广告的能力,就像现在的火狐、Maxthon等浏览器不断加强广告屏蔽功能一样;
分析工具:基于RSS的读者分析工具似乎是目前整个价值链中发展最为落后的一环,而RSS的商业化,无疑离不开读者分析。Feedburner虽然目前处于这个领域的领先地位,但RSS非集中化的趋势必然会要求出现更多的RSS读者分析工具;
聚合门户:RSS标准化的机器可识别格式使得信息的传播和聚合成为一件更为容易的事,因此通过聚合不同的RSS源,就有可能可以方便地构建出一个新闻门户,成为传统门户的竞争对手;
商业及服务领域的RSS应用:RSS的价值不仅仅体现在新闻上,它同样在商业数据的传递上可能发挥重要的作用,因此在商业与服务领域的RSS应用方面存在一定的创新与投资的机会。
结束语
正如keso所言,“RSS的商业机会,就像1997年的IM一样说不清”,尽管现在更多的是说不清,但至少大家还坚信其存在。连软件业巨头微软似乎也意识到这个曾被他们冷落的技术,如今又焕发出惊人的力量,于是他们于上月中旬宣布,下一代Windows操作系统Longhorn将具备支持RSS聚合新闻的功能。对此,FeedBurner等不知道是该高兴主流公司对RSS的支持,还是该担心又一个争夺猎物的强大对手来了。
新浪网新闻总编陈彤谈web2.0
记者:您认为什么是WEB2.0,因为最近这个概念炒得特别热。
陈彤:这个概念最近的确炒得特别多。我的印象中WEB2.0可能是以博客和RSS等为核心的一个技术叫WEB2.0。目前我个人对web2.0还没有清晰的概念。
记者:你觉得以RSS和博客为代表的所谓web2.0会对互联网有什么样的影响?
陈彤:我认为博客根本不是什么新东西,它其实是BBS和个人专辑的一个混合体。从互联网上个世纪诞生那一刻起,其实就有这些东西了,博客只是它的一个新的名字,我看不出它有什么新的技术含量。另一方面,RSS现在也很热,但是我感觉起码目前形势RSS很难让我相信它会成为一个主流的应用。
记者:你认为以RSS为代表的web2.0不会对互联网有什么深入的影响么?
陈彤:现在看不太出来。现在以博客为代表的WEB2.0,我觉得其实是某些群体的炒作。一部分是追求新奇的网络研究人员,还有一部分就是追求风险投资的网站经营者。但是互联网真正的基础,我觉得今后并不在于这些小范围的技术革新,真正的应用应该是宽带互联网,多媒体将是互联网的主导。
记者:但是很多推崇web2.0的人士认为,在web2.0时代网民可以有更多自己创造的内容?
陈彤:阐述观点而不是描述事实的文本形式的博客,比垃圾邮件强不了多少。因为对于那些深思熟虑或能够自圆其说的观点,作者更愿意将它们率先印成铅字,在传统媒体上刊登,或在有影响的门户和垂直网站上发表。比如说海啸,大家看的是你对事实的一个描写,而不是说你的观点,观点在互联网时代是不值钱的。
记者:那么博客的未来是什么呢?
陈彤:可能真正有价值的是多媒体形式的博客,它包括音、视频的作品和静止图片。但不是每一个人都有能力制作多媒体形式的博客。比如社科院最近刚刚公布一个互联网的调查,一直使用博客的网民只占1%,经常使用的也只占3%,所以显然博客是一个很边沿的应用。网络新闻的同样的比例是65.9%,这个根本不是一个数量级的。博客目前只是某一个圈子内的人群所使用东西,比如说IT记者,可能不过如此了。
记者:你怎么看待现在新浪所面临的互联网的竞争格局?
陈彤:我认为在可预见的将来,互联网公司主要的这个模式,还不外于这三点,网络游戏,无线增值以及网络广告,包括搜索其实也是通过网络广告实现的。目前还看不太出来能够有一个占据巨大份额的一个新的经营模式,我认为现在是不清晰的。
记者:前段时间有媒体认为新浪的模式正在走向没落?
陈彤:互联网的发展从来就没有哪个模式是建筑在理论家的预言上的,我想它需要实在。如果说做互联网媒体,不需要快速,不希望海量的话,都可以去尝试一下,别停留在理论阶段。新浪这种新闻模式不会改变。
记者:您在互联网呆了这么长的时间,对互联网的感受是什么呢?
陈彤:我的感受就是认准一个方向要执着,要大胆地取舍。另外,不要被理论家的理论所干扰,在过去的几年中一些很有发展前景的网站就转型了,非常可惜,比如FM365,263。前提还是要认准自己的特点,根据自己的特点来确定自己的业务模式。
Web 2.0:新应用 新体验
最近,一位美国网民在网上写下了这样一段真实体验:在upcoming.org网站上,他通过Tag搜索到一条事件预告信息—法国巴黎正在举行一场音乐盛会,于是,他点击了“Attend”按钮,参加该事件。很快,他不仅看到了网站上其他的参与者信息,而且还查到与他同在达拉斯的网友也报名参加了。在该事件列表的旁边,他还欣喜地发现了GoogleMaps和Yahoo!Maps的地图搜索链接,当他点击后,该音乐节在巴黎的具体方位和交通情况,甚至还有该场馆的实景图片均一目了然。在了解了所有应知信息后,他决定与同城的乐迷一起订阅机票,飞赴巴黎,现场参加该音乐节。
Tag、GoogleMaps……,类似的互联网创新应用正给人们带来异乎寻常的网络体验。人们试图将这些新鲜但又模糊的体验,归纳整理甚至定义出新的概念,“Web 2.0”由此应运而生。
在寻找区分Web 1.0体验和Web 2.0体验的差异上,人们总结出了几条大致的特征:与前几年的网络应用相比,用户从内容的消费者变成了内容的创造者;用户从聚集在门户网站和BBS等公共空间,到分散至个体网络日志(Blog)的包产到户和全民织网。信息正在日益呈现离散的趋势,分散的“信息岛”与曾经一统天下的门户网站也形成了分庭抗礼之势。
但是,这些都只是表象而已。该如何用一些明确的指标来衡量这些模糊的差异化特征呢?是什么导致了这些现象的产生?这些新的应用带来了怎样新的体验?应用创新又如何通过技术创新来表现出来?
搜索引擎引爆Web新应用
“传播速度、书写成本、学习成本和管理成本等几个因素应该成为考量所谓的WebN.0的重要指标。”雅虎中国公司搜索事业部高级经理、资深Blogger车东谈到。他认为,在所谓的Web1.0时代,人们的信息消费主要集中在门户网站或社区型的BBS等公共空间上,那时,普通人想要拥有自己的网站绝非易事。你必须要掌握一些网页设计的基本知识,如HTML、ASP、PHP等,才能做出个像模像样的网站来。即便是对网站的书写和管理,也常常需要和各种编程语言打交道。那时的互联网也主要掌握在一些较为强势的企业、社团或集体手中。网民很少能拥有自己的话语权。即便网民将个人内容发布在BBS或个人网站上,由于搜索工具的匮乏,内容的影响力和传播力也仍然十分有限。更多的情况下,个体的声音是作为一个个的信息孤岛而存在的。
然而,当技术已经不能成为阻碍个人书写的门槛,甚至让人们忘掉它的存在时,上网书写的成本和学习成本就变得极其低廉。想拥有自己网站的人根本不必费时费力去学习网页设计和编程,而只需要简单注册,就可以拥有自己的网络日志。搜索引擎的无处不在,也让各种信息在全球范围内实现了充分而自由的共享。
车东认为:“每当技术门槛降低一个数量级,那么用户数就会相应增加几个数量级。”因此,引爆Web 2.0热潮的恰恰是搜索引擎。它为数以百万甚至千万的信息孤岛的互联,提供了强大的工具。正因为这一点,网民创造内容和分享知识的热情才被充分地点燃。
但流行应用的引爆,必须是在具备了充足的条件和充分的资源积累情况下才会实现。北京博客时代信息技术有限公司(下称“博客时代公司”)副总裁卢亮分析说:宽带接入的普及、用户数的基数基础、网络标准化的日渐普及以及充足的技术储备,都是这些新应用迅速产生和流行的重要原因。
Tag、Rss方便信息交换共享
在这些新的应用中,普遍具有Tag、Rss、Ajax等技术共同的形态特征。
Tag—“标签”的出现,成为这些新应用的典型特征。
Tag是由用户自主定义的社会分类。车东说,通过Tag分类,人们可以方便地搜索到各种信息。为了更方便地搜索,国外的用户还在不断地创造新词,加大标签的信息含量。例如,在著名的书签收藏网站del.icio.us上,通过Tag,不同用户还可以进行交叉查询,用户可通过关键词找到其他用户收藏的网站,也可以通过大家共同收藏的URL找到其他用户。这就相当于将自己的知识收藏发布到了全球网络上。用户在提供信息的同时,也从他人的信息中受益。
而被车东视为“轻量级API”的RSS也在很大程度上方便了信息的交换和共享。
RSS是一个站点用来和其他站点共享内容的一种简易方式(也叫“聚合内容”),通常被用于新闻和其他按某种顺序排列的网站,例如Blog。
一段项目的介绍可能包含新闻的全部介绍等,或者仅仅是额外的内容或者简短的介绍。这些项目的链接通常都能链接到全部的内容。网络用户可以在客户端借助于支持RSS的新闻聚合工具软件(例如SharpReader,NewzCrawler、FeedDemon),在不打开网站内容页面的情况下阅读支持Rss输出的网站内容。同时,有的聚合工具也提供在线RSS阅读。 网站提供RSS输出,有利于让用户发现网站内容的更新。
如今,RSS内容的聚合形式也越来越趋于多样化,如视频和音频格式等多媒体信息源也都开始支持RSS输出。这样,网民就可以自主定制信息的内容,而不必聚在门户网站上吃“大锅饭”,这也被视为Web 2.0的典型特征之一。
Ajax让Web设计人性化
此外,新的应用之所以能够吸引到数以百万乃至千万级的用户,易用性的大大提升也是其中一个重要原因。而应用性的实现可以说是Web技术的发展所带来的明显变化之一。眼下,最炙手可热的Web技术便是Ajax。Ajax是Asynchronous、JavaScript 和XML的简称,换言之,异步交互(Asynchronous)、基于JavaScript 脚本和XML封装数据是Ajax的三大特征。它使得用户可以任意修改网页上的个人信息,且无需向服务器重新发送请求和刷新页面,这样不仅大大提高了用户体验,而且还在很大程度上缓解了服务器的数据处理压力。这就是Ajax技术的魅力所在。
著名的图像网站Flickr.com就是利用Ajax技术的一个出色成功案例。它被用户称为图片管理领域的Google。Flickr.com的用户在管理图片时,可以非常方便地对图片的标题、描述以及标签等进行任意修改,当用户将鼠标掠过这些标签和描述时,会发现页面出现动感的书写框,提示你键入任何想添加和修改的文字,当你提交后,页面却无需刷新,几乎是所见即所得,非常方便。这些人性化的设计就是Ajax的典型应用。
博客时代公司北美市场总监文心对此称赞说:“Flickr.com最精彩的地方并非创意,而是易用性。他们将Web服务的用户体验做得十分到位,整个服务已经上升到了艺术的高度。网络服务对易用性的要求越来越高,并且已经成为一项非常重要的技术指标,而易用性也早已脱离一般网页美工、图像的范畴。”
Flickr.com成立于加拿大温哥华,公司的前身并非是一家纯软件开发企业,而是游戏软件公司,因此他们的企业文化更富有想象和创新力。正是由于这种特殊的背景,使他们凭借着出色的UI(User Interface)设计技巧和强大的后台技术,切入图片分享领域,并仅花了1年时间,就吸引了200万左右的免费用户和几十万收费用户。今年3月,雅虎公司(Yahoo)花费巨资收购了该网站,据知情人士透露,购并的资金在4,000~6,000万美元之间。
当然,Flickr.com并非是唯一对Ajax表示青睐的案例。在古狗公司(Google)的GoogleMaps里面也体现了Ajax的魅力。GoogleMaps可以允许用户任意放大、缩小和移动图片,这种平滑的迁移做得十分出色,这正是依靠Ajax实现的,而且也是GoogleMaps和其他的同类产品的最大区别。Google Earth客户端软件,也体现了Ajax技术的应用思想。打开软件,浩瀚的宇宙中,蔚蓝色的星球—虚拟地球在体验者面前缓缓旋转。在用户输入想查询的目的地比如纽约后,立刻就像乘坐了模拟飞行器,“坐地日行八万里”,很快就飞到了纽约上空,高速公路、摩天大楼、河流都清晰可见。Google Earth把一个普通的应用软件做成了3D 动画模型,使得用户得到了愉悦的体验。
博客时代公司卢亮介绍说,Ajax技术早已存在,以前在3D游戏中就有所应用。而Google公司把这项技术重新挖掘出来,从而极大地发挥了这一技术的潜能。因此,他认为,技术储备早就成熟,只是需要合适的契机,将他们调配起来。就像Google公司对Ajax的挖掘那样,魔杖一挥,点石成金。
微软公司(Microsoft)也在利用Ajax技术与Google公司竞争。在美国旧金山举行的互联网及地理信息服务会议“Where 2.0”上,微软公司首次公开演示了类似产品 “MSN Virtual Earth” 。MSN Virtual Earth是在2005年5月举行的一次会议上,由微软公司董事长比尔·盖茨(Bill Gates)宣布推出的一项服务,计划免费提供。它也是通过Ajax技术来实现图像管理。据称,该产品功能更为强大,如对地面立体图像提供45度角的俯视;图像更为清晰,可支持任意速度的视图推移;此外,在未来还可能与MsnSpace进行整合。微软公司还宣称:该产品与Google Earth最大的不同在于,MSN Virtual Earth无需下载专门的客户端软件。
后web 2.0时代更值得期待
从目前一些新萌生出来的网站上,我们还能够窥见后“Web 2.0时代”的一些新的特征:高效便捷的个人知识管理、立体化多媒体形式的细分和富客户界面的流行应用等。
目前,在backpack.com网站上,用户可以围绕自己的个人日常工作或生活计划(如婚礼或工作安排等),将日志、本地文档、照片和To-do-list等多种形式的个人信息,在同一页面有序和层次分明地管理起来。有专家认为,这种个人信息管理还是初始阶段,今后更细分、更专业化的管理应用有可能会成为后Web 2.0针对高端用户较有吸引力的主打功能之一。同时,立体化多媒体内容细分趋势逐渐清晰。播客(Podcast)的火爆再一次点燃了网民的热情。除了主流的综合站点包括Blog托管站点,对用户提供视频和音频节目的DIY以外,国外的Odeo.com,国内的土豆网站以及更多的同类网站,正在走细分化道路。他们既可以与博客共生共存,又完全可以走自我孵化发育的道路,我们不难想象,他们必定会给用户带来更专注更人性化的创新体验。
此外,富客户界面也许会成为流行性的应用。微软公司目前正在进行测试的基于富客户界面的wallop.com网站,已经吸引了无数年轻人。它的所有页面和功能全部是基于Flash制作的。除了基于Flash的华丽界面设计,丰富流畅的功能,它的Blog、Rss和SNS看上去与其他网站似乎没什么不同,但它确实在体验和视觉上带来了强烈冲击。虽然现在登陆还比较缓慢,但未来随着网络基础设施的发展,酷酷的富客户界面应用也许会成为更多人的新宠。
开放API魔力
在Web 2.0这股新应用大潮中,开放API已经成为不可忽视的趋势。
“标准就是生产力”,如今这已成为放之四海而皆准的真理。目前,很多网站从设计之初就自觉地遵循各种工业化标准,而且也纷纷开放了自己的应用程序接口(API)。如亚马逊公司(Amazon)、雅虎公司、Google公司、电子港湾公司(eBay)等。这样,就非常便于各种网站之间交换数据和通信。
对于公司来说,标准就是生产力。Google公司显然深谙此道。它所推出的诸多产品都是基于开放的API标准。这样,Google公司无需花费力气做更多的市场推广,其他公司就会主动地整合它的应用。例如,美国著名的分类广告网站Craigslist整合了Google Maps的应用,在该公司推出的housingmaps (http://housingmaps.com/)上,纽约和旧金山的电子地图已经密密麻麻地布满了各种商店的方位点。如果用户在出售的房屋信息中对某所房子有一定的兴趣,就可以直接点击该地址,它会自动呈现在地图上,房子的照片也会出现在方位点的旁边,并可获得你从自己的居所到达该地的交通路线图。这种立体化的购物感受,也许会激发出更多的富有创意的应用来,这就是开放API的魔力。
主流单用户Blog程序介绍
几个月没关心blog了,blog程序局势发生了很大的变化,尤其在国内,在原有的那些程序功能越来越强大的同时,还出现了很多不错的blog,但国外没出几个好的,MT还居于霸主地位,也许在未来几年内MT的地位是不会动摇的,国内ASP的L-blog已经成为主流,php里,多用户的Plog发展最快,其他功能都差不多,用的人比较多的是wordpress,exBlogMix,bo-blog,另外几个国产blog发展也很快。具体的功能区别我也说不上来了,大家一个一个去研究吧。
我选用blog的最基本要求就是:免费,这个最重要,呵呵;完美支持中文,包括显示和搜索;支持分类;可以发表评论,但最好有评论审核功能;支持RSS,z在我看来,不支持rss只能叫做日记本,不能称作blog;支持TrackBack,方便被人引用;有WYSIWYG编辑器;可以上传文件;模板最好和程序分离,方便修改;可以发草稿,方便以后修改。我收集的这些都具备了blog的基本功能,国外blog程序现在有上百个,但真正好用的不多。
现在很多人在找多用户blog,我列出的大部分都说自己支持多用户,但实际上多用户有两种,一种是多人共同维护一个blog,另一种是每个人有独立的blog,更多的人需要后一种,asp里的oblog和missblog,php里的Plog,asp.net里的Dottext,这几个比较好用。
下载地址我没有列出,都可以在官方网站下载。
ASP
PJ Blog :http://www.pjhome.net ,演示地址:http://www.8266.org 全有网重点推荐此程序,1.X版本为Loveyuki的修改版本,现在已经推出了独立开放的2.X,非常容易使用,很人性化,不断的完善和升级。
L-Blog: http://www.loveyuki.com 由Loveyuki自主开发的基于 ASP+Access 的小型单用户BLOG,作者比较勤奋,更新很快,现在还有很多L-blog的修改版提供,模板有的非常漂亮。
Dlog: http://webdream.duoluo.com/ 国人开发比较早的一个blog了,最新版是V2.2 ,现在已经停止了开发,但已经是一个完善的程序了!
Misslog: http://www.misslog.com/blog 多用户blog,使用UTF-8编码,支持简繁转换!
theAnswer: http://bravetime.com/dev/ 程序和界面都非常规范,现在已经是sourceforge的一个开源项目了
cixiblog: http://blog.ic5.cn/blog asp+sqlserver存储过程+xml+asp缓存技术的多用户网络日志程序
oblog: http://www.oioj.net 是多用户版本的Blog,实现了Blog的大部分功能,发展很快,现在已经出了SQL商业版本了。
blogx: http://www.blanksoft.com/blogx/
天畅博客: http://www.skycx.com/blog/ 非常简单小巧,但不支持RSS
另外几个国外比较看得上眼的:
dblog: http://www.dblog.it/dblog/
BP Blog: http://www.betaparticle.com/blog/
Matthew1471’s BlogX: http://blogx.co.uk/Main.asp
ASP.NET
DotText: http://scottwater.com/Dottext/default.aspx 非常强大的多用户blog,国内很多大型网站在用,但安装调试非常复杂,有很多汉化版下载。
BlogX: http://www.simplegeek.com/CategoryView.aspx/BlogX 这里有一个blogx的中文修改版 http://www.blanksoft.com/blogx.asp
dasBlog: http://www.dasblog.net 新出来的程序,功能也比较齐全
PHP
b2: http://www.cafelog.com php blog的老祖宗,操作简单,容易上手,现在好像停止了开发。
b2evolution: http://www.b2evolution.net B2多用户版,有很多风格和插件。
wordpress: http://www.wordpress.org 在B2的基础上开发的,添加了很多功能,国内用户很多,。
pivot: http://www.pivotlog.net PHP+XML,没有使用数据库,有中文语言包,
nucleus: http://www.nucleuscms.org 这个也是比较老牌的程序了,有中文语言包!
exBlogMix: http://exblog.fengling.net 功能很强大的blog,更新很快,推荐使用。
M-logger: http://miracle.shakeme.net 文本储存数据。
bo-blog: http://www.bo-blog.com/ 文本数据库,现在发展的很快。
drupal: http://www.drupal.org 著名的开源程序,功能非常强大,多用户,有多种插件和皮肤下载!
O-BLOG: http://her.com.ru/ 需在PHP+MYSQL环境下运行,采用 SMARTY 模板,HTMLAREA编辑器
R-Blog: http://rays.512j.com/ 采用PHPLIB模版引擎,程序与美工基本分离,改版比较方便
boeiblog: http://myblog.boei.cn 新出来的blog程序,简单易用,模板很多。
SaBlog: http://www.4ngel.net/project/sablog.htm 安全天使小组开发的一个简单易用的blog,支持模板
Pmschine: http://www.pmachine.com 这个估计是blog的元老了,不过现在已经商业化了,新版本名叫Expression Engine,在国内可以免费下载!
bBlog: http://dev.bblog.com/ 一个非常简洁好用的blog,汉化版: http://www.xptop.com/lei/
serendipity: http://www.s9y.org 功能很多,每个功能以模块方式安装,界面也很容易修改。
bMachine: http://boastology.com 同时支持文本数据库和MySQL数据库,支持中文搜索。
Plog http://www.plogworld.org/ php blog里的最好作品了,真正的多用户,博客中国,blogit都是用这个改的。
Plainslash: http://www.51zhao.com/plainslash/ 文本blog程序,作者很久没更新了,但现在blog的基本功能都有了。
Simple Blog : http://www.bigevilbrain.com/sphpblog 国外的一个文本的小型blog,代码和界面都很简洁。
Tatter Toolkit : http://www.tattertools.com 韩国人开发的 Blog,界面美观,功能很全。汉化中文站:http://e345.com.ru
myphpblog: http://www.myphpblog.org/
sunlog: http://www.sunlog.org
RCBlog: http://rcsoft.co.nr/
Twoblog: http://www.twoblog.com/
CGI
MT: http://www.movabletype.org 就是我现在用的,世界上用户最多的blog程序,自动生成html!后缀可以自己设置,支持文本数据库和mysql,mssql等!
Greymatter: http://www.noahgrey.com/greysoft/ 是一个类似 Movable Type 的Blog程序非常简单,也是生成静态文件。
HUS Reviv: http://supermanc.51.net/norman/blog.cgi 国人开发的,功能很强大,但由于cgi语言的问题,安装调试比较复杂,而且很占资源。
Blosxom: http://www.blosxom.com 很老的一个程序了,也可能是世界上最小的blog系统了,只有一个文件却实现了blog的大部分功能!
JSP:
DLOG4J: http://dlog4j.sourceforge.net/ 国人开发的,已经申报SourceForge项目 中文官方站: http://www.javayou.com
TM: http://www.terac.com朋友andy开发的一个功能强大的blog,支持文件上传、RSS、评论、WYSIWYG 编辑器等功能,多种语言(含简体中文)
snipsnap: http://snipsnap.org/space/startwiki和blog结合的东东,开源项目,支持多国语言。
使用开源软件Lilina构建RSS聚合器
随着Blog和Wiki在互联网上的蓬勃发展,RSS作为使用XML描述和同步网站内容的格式,正在逐渐的被人们所熟知。国内外的一些著名媒体网站如BBC、百度、新浪等也都推出了基于RSS技术的新闻聚合服务,网友们可以根据自己的需要选择自己喜欢的新闻资讯频道,使用RSS聚合器(Aggregator)进行阅读获取最新的文章消息。一般来说,RSS聚合器分为3种:第一种是桌面型的RSS聚合器,如国外的FreeDemon和国内的看天下阅读器和周博通阅读器等;第二种是网上运营商所提供的RSS新闻聚合页面服务,比较著名的有del.icio.us和天天网摘等;最后一种就是用户自己管理的在线RSS聚合器,这种聚合器也是基于Web方式管理和使用的,但要求使用的用户拥有Web服务器并安装PHP及MySQL等,下面我们要介绍的就是基于PHP建立的一个新闻聚合程序Lilina。
介绍
Lilina是采用PHP语言编写的开放源码的RSS新闻聚合器,虽然简单,但是功能还是比较强大,使用起来也比较上手。它无需使用MySQL等数据库的支持,而是基于文本方式进行存储,所有得到的信息均存储到cache目录下进行解析使用web页面进行显示。RSS的解析采用非常优秀的MagpieRSS库进行处理,而且Lilina本身内部就包含了MagpieRSS库,无须另外安装。它具有自动发现(Auto-Discovery)的特性,使用接口比较简单。
安装
Linina的官方主页是:http://lilina.sourceforget.net ,当前的最新版本是0.7。从网站上下载到源程序包lilina-0.7.tar.gz后,在本地解压,并提交到web服务器的文件夹下,这里我们假设所使用的web服务器的地址为:http://www.myweb.com ,提交的文件夹名为lilina。这里需要注意的是,一定要保证lilina目录下的.myfeeds.data和cache目录是具有可写属性的。
配置
提交完lilina目录后,我们需要对lilina进行配置,配置文件为lilina目录下的conf.php,其内容一般如下,我们一般只需要修改最上面的几行即可:
| <? $BASEURL = ’http://www.myweb.com/lilina’ ; // lilina目录的web地址 $USERNAME = ’user’ ; // 管理员名 $PASSWORD = ’pass’ ; // 管理员密码 $SITETITLE = "My lilina news aggregator" ; // lilina页面标题 $OWNERNAME = "user" ; //用户名 $OWNEREMAIL = "admin@myweb.com" ; //管理邮件 $DATAFILE = ’./.myfeeds.data’ ; //数据文件 $TIMEFILE = ’./.time.data’ ; //时间文件 $GOOGLE_KEY = ’’ ; // 使用google API关键字. 详细信息可以访问 http://www.google.com/apis/ /* 这里是对del.icio.us进行的操作,一般最好无须配置,作者给出了原因如下: IMPORTANT NOTE! Setting ENABLE_DELICIOUS to 1 will make lilina poll del.icio.us for tags. THIS MAY RESULT TO DEL.ICIO.US BANNING YOUR IP!!! Until del.icio.us officially allows such use, it is better to leave this to 0. */ $ENABLE_DELICIOUS = 0 ; /* 缓存失效时间,默认为1个小时,可以根据需要进行修改,单位为秒。 可以通过强制调用 index.php?force_update=1 的办法进行强制失效处理 */ define(’MAGPIE_CACHE_AGE’,60 * 60*1); ?> |
使用
经过以上的配置,就可以开始使用Lilina来做RSS新闻聚合了,首先我们打开http://www.myweb.com/lilina/edit.php ,这时我们可以看到如下的页面图1:

图1 |
填写好配置文件中设置的用户名和密码之后,进入到管理页面,就可以任意添加自己喜欢的RSS源了,如图2所示。第一行文本框用来添加RSS源的地址,第二行文本框可以用来导入OPML文件(格式化的XML文件,用来记录RSS源的一个XML集合文件),已经添加的RSS地址在页面上都会在添加后显示出来。

图2 |
经过添加操作之后,我们就可以打开Lilina的主页面来欣赏我们自己定制的新闻频道了,如图3所示。

图3 |
最上面一行的链接,24h、48h、week和all分别可以代表选择不同时间段的新闻内容,expand表示同时显示标题和新闻简介,collapse表示收起所有的新闻简介,只显示标题。图3的页面上显示了2005年6月24日笔者的新闻聚合内容,红色字体显示的是标题,灰色字体表示新闻的来源,页面的右边为RSS源的总体介绍和图标。点击页面上的红色字体可以打开新闻简介,如图4所示。如果你对这条新闻感兴趣,只要点击红色字体后面紧跟着的灰色新闻来源,即可链接到这条新闻的真正页面上,详细了解新闻信息。

图4 |
当然,也许你认为这样的页面不是很好看,如果你了解CSS样式表的话,你也可以参考lilina里的style.css的模版编辑自己的样式表,并修改lilina目录下的index.php文件中的如下行所示:
| <title><?=$SITETITLE?></title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> /* 修改href后的内容为自己定义的样式表格式 */ <link rel="stylesheet" type="text/css" href="/style.css" media="screen"/> <link rel="shortcut icon" href="favicon.ico" type="image/x-icon" /> |
这里可以展示Lilina提供的另外一个页面样式,如图5所示:

图5 |
结束语
通过以上的介绍,一个基于Lilina的个人新闻聚合页面就建立起来了,我们完全可以对它进行扩充,把它作为个人主页的一个部分展示出来。目前网络上已经有使用Lilina构建的个人新闻聚合主页存在了,比较著名的如国内车东先生的主页:http://www.chedong.com 。相信随着Lilina程序的不断完善,一定会给大家带来更加完善和满意的聚合功能。
10分钟架设Blog实践
blog的火热已经好一阵子了,如果你还不知道什么是blog,可以在我们网站中搜寻blog这个关键词,或者是到google上搜寻blog或部落格,就会看到一堆blog的信息(实际上google先前才刚把blogger.com这个免费blog空间提供网站买下来)。
想要开始blog的方式大略分为两种,一种是到blog空间提供网站注册,如先前所提的blogger.com或upsaid.com,注册完后就可以开始blog了,感觉很像网际网络刚开始风行时,各入口网站提供免费网页空间一样,只是现在网站会提供使用者一套管理接口,让使用者可以轻松的写文章,而不需花费大量的心思在程序维护上。
另外一种就是自己架设一个blog,而其中又分为两种,一种是购买虚拟主机,不过要先确认你的虚拟主机供货商有没有提供数据库及CGI程序(或其它blog需求的SSI语言)的执行权限,如果你的虚拟主机供货商没有提供上述的服务,你可能要多花点钱购买这些服务。
第二种则是在自己的计算机上架设,好处是没有储存空间限制,此外想要怎么动,怎么乱搞都可以,但缺点是整个过程稍微麻烦一点,还有必须要有不错的上传频宽,当造访人数不多时,家用的ADSL就够用了,但如果有一天你的blog红透半边天,那么上传速度缓慢的ADSL恐怕会让你的读者感到痛苦。
虽然在自己的计算机上架设blog好象有点缺点,但是自由度相对的也比较大,这里,我们就教你如果十分钟在你的计算机上架设好blog。
前置作业
如果要在自己的计算机上架设blog,必须先从架设一个web server开始,在Windows的系统上,虽然从win2k开始就已经内建了IIS这套web server,但不如使用网络上整合web server、database server及SSI语言的免费套件包,如AppServ及Foxserv都是蛮有名的套件,不过Foxserv从3.1beta1之后就没再更新了,所以这里我们采用AppServ为范例。
AppServ现在改成2.4.x及2.5.x两种版本发布,差别在于2.4.x的版本是采用较稳定的PHP 4xx为核心,适合架站使用,而2.5.x是采用PHP5.x,目的是要给程序开发者做测试用,但PHP5对目前就有的函式支持不多,所以作者就采用两种不同的版本来做区别。而为了稳定,我们使用AppServ2.4.1版本,其中包括:
· Apache 1.3.31
· PHP 4.3.8
· MySQL 4.0.20
· Zend Optimizer2.5.3
· phpMyAdmin 2.6.0-rc1
· Perl 5.8.4
首先先下载AppServ2.4.1,然后选择执行,基本上就像在windows上安装任何一个软件一样,只要不断的按下一步即可。


将管理者email改成你的email 
输入使用者帐号密码,并将Chrset改成big 

选择激活Apache及MySQL 
Apache激活中 |
安装完后,请打开你的浏览器,在网址列上输入http://localhost/,如果出现AppServ的预设网页就表示安装成功了。

|
接下要做一些小修改,请使用笔记本之类的编辑软件修改C:/AppServ/www/phpMyAdmin/config. inc.php这个档案,找到
$cfg[’PmaAbsoluteUri’] = ’’;
修改为
$cfg[’PmaAbsoluteUri’] = ’http://localhost/phpMyAdmin’;
还有
i][’auth_type’] = ’config’;
i][’user’] = ’root’;
i][’password’] = ’’;
如果你要采取自动登入的话,就不用作修改,但这样十分危险,等于是任何人都可以登入到你的数据库中,所以建议修改成:
i][’auth_type’] = ’http’;
这样会在登入到phpmyadmin时询问帐号密码,这时预设管理帐号是root,预设密码是空白,使用者可登入后选择更改密码。
登入后记得要更改密码 输入新密码后按修改即可。


|
正式开工
接下就是正式的架设blog了,目前网络上blog架设工具非常多,我们选择wordpress这个软件作为范例,目前wordpress已经进行到1.2版,而在国内有网友zonble从wordpress的前身b2开始做的中文化。在之前1.03版时想要使用中文化的wordpress还不是非常方便,但目前zonble所做的中文安装包已经简化非常多,这里我们使用2004 09 01安装包作为范例。
先用phpmyadmin新增一个wordpress专用的数据库,本例中我们命名为wordpress。

|
接下来到OSSF项目中下载2004 09 01安装包,然后解压缩到网站预设的目录中,在本例中为C:/AppServ/www,预设会解压缩出两个资料夹,接下来请修改wordpress里面的wp-config-sample.php如下
define(’DB_NAME’, ’wordpress’);// The name of the database
这里输入刚刚新增的数据库名
define(’DB_USER’, ’root’);// Your MySQL username
这里输入你的数据库管理者帐号
define(’DB_PASSWORD’, ’your password’); // ...and password
里输入你的数据库管理者密码
define(’DB_HOST’, ’localhost’);// 99% chance you won’t need to change this value
这个通常不需要更改
修改完后存为wp-config.php,然后打开浏览器,在网址列输入http://localhost/wordpress/wp-admin/install.php (如果你有更改你的目录,请打正确的目录名称),然后跟着指示步骤一步一步做,三个步骤后,你会得一组wordpress随机给的一组密码,接着用admin及新得到的密码登入到管理区。

登入到管理区中 
恭喜, 你已经可以开始blog了! |
一开始的样版是wordpress预设的样板,有点呆板,如果你不喜欢可以去网络上找寻热心的网友们自行设计的样板来套用,或者可以到OSSF里中文wordpress项目找资源,或者等待我们下次的blog教学。
AJAXTags标记初探
AjaxTags项目是在现有的Struts HTML标记库的基础上,添加对AJAX支持。 AjaxTags改写了Struts标签类org.apache.struts.taglib.html.FormTag和org.apache.struts.taglib.html.BaseHandlerTag,并使用Struts的plugin技术,使得Struts提供了对AJAX的支持。 以下是jsp中简单的示例:
| <html:form action="example1" ajaxRef="example1"> First Name: <html:text property="firstName" size="25" value="Frank" /> <br> Last Name: <html:text property="lastName" size="25" value="Zammetti" /> <br> <html:button property="button" value="Click to do Ajax!" ajaxRef="button" /> </html:form> Result:<br> <span id="example1_resultLayer"> </span> |
注意:ajaxRef属性。 ajaxRef属性中内容是在ajax-config.xml中定义的,例如本示例的配置部分如下:
| <!DOCTYPE ajaxConfig PUBLIC "ajaxConfig" "ajaxConfig"> <ajaxConfig> <!-- Define a custom request handler that generates XML for example 2 --> <handler name="CustomXMLGenerator" type="request"> <function>customGenerateXML</function> <location>customXMLGenerator.js</location> </handler> <!-- Configuration for example 1 --> <form ajaxRef="example1"> <element ajaxRef="button"> <event type="onclick"> <requestHandler type="std:QueryString"> <target>example1.do</target> <parameter>firstName=firstName,lastName=lastName</parameter> </requestHandler> <responseHandler type="std:InnerHTML"> <parameter>example1_resultLayer</parameter> </responseHandler> </event> </element> </form> </ajaxConfig> |
在配置文件中定义了该表单的属性,以及按钮触发的事件和回写结果的处理方法。采用很巧妙的封装方法实现了Struts的AJAX调用。当然Ajaxtags离实用阶段还有相对长的一段距离,但它提供了一种在现有的软件架构上高效率开发ajax应用程序的可行性方案。
Ajax的错误处理机制探讨
当前web技术中最热门的词语是什么?是AJAX。AJAX框架组件的核心是XMLHttpRequest JavaScript对象,它允许客户端开发人员在不中断用户操作、不利用隐藏页面的情况下,通过HTTP发送和接收XML文档。现在,有些人可能会感到恐惧,因为它突然允许那些可能过多地使用了验证窗体和动画图像的客户端开发人员负责传递XML文档和处理HTTP头信息,但是,没有风险就没有收益。我们不用害怕,我将演示如何使用XMLHttpRequest来添加一些以前不可能的、行不通的特性,它同时还减少了错误,提高了产品质量。
JavaScript中的XMLHttpRequest和XML DOM
首先,我们需要建立一些规则。特殊的XMLHttpRequest对象和一般的XML DOM都受到了最新的浏览器(IE、Mozilla、Safari、Opera)的广泛支持,尽管在一般情况下,微软对于自己的实现会稍微增加一些东西,需要某些特殊的处理。尽管我们更多的朋友直接实现了XMLHttpRequest,但是IE还是要求你用相同的属性实例化一个ActiveXObject。在Apple开发者关系站点上可以找到相关的概述和所有特性列表。
下面是一个基本的例子:
| var req; function postXML(xmlDoc) { if (window.XMLHttpRequest) req = new XMLHttpRequest(); else if (window.ActiveXObject) req = new ActiveXObject("Microsoft.XMLHTTP"); else return; // 失败了 req.open(method, serverURI); req.setRequestHeader(’content-type’, ’text/xml’); req.onreadystatechange = xmlPosted; req.send(xmlDoc); } function xmlPosted() { if (req.readyState != 4) return; if (req.status == 200) { var result = req.responseXML; } else { // 失败了 } } |
这种强大的功能的潜在用户是很多的,对于它可能实现的功能的探索才刚刚开始。但是在你试图在web上的建立XML功能之前,我建议你设置一个"安全网"来保证你的抱负(想法)不会受到打击。
JavaScript错误处理基础
JavaScript已经出现很久了,它的早期版本比较原始,缺少特性,仅仅是实现了而已。最新的浏览器不但支持C++和Java中try/catch/finally关键字,而且实现了onerror事件,而这个事件可以捕捉运行时出现的任何错误。它的使用是非常直接的:
| function riskyBusiness() { try { riskyOperation1(); riskyOperation2(); } catch (e) { // e是一个Error类型的对象,至少有两个属性:name和message } finally { // 清除消息 } } window.onerror = handleError; // 捕捉所有错误的安全网 function handleError(message, URI, line) { // 提示用户这个页面可能无法正常响应 return true; // 停止默认的消息 } |
JavaScript中的XMLHttpRequest和XML DOM
首先,我们需要建立一些规则。特殊的XMLHttpRequest对象和一般的XML DOM都受到了最新的浏览器(IE、Mozilla、Safari、Opera)的广泛支持,尽管在一般情况下,微软对于自己的实现会稍微增加一些东西,需要某些特殊的处理。尽管我们更多的朋友直接实现了XMLHttpRequest,但是IE还是要求你用相同的属性实例化一个ActiveXObject。在Apple开发者关系站点上可以找到相关的概述和所有特性列表。
下面是一个基本的例子:
| var req; function postXML(xmlDoc) { if (window.XMLHttpRequest) req = new XMLHttpRequest(); else if (window.ActiveXObject) req = new ActiveXObject("Microsoft.XMLHTTP"); else return; // 失败了 req.open(method, serverURI); req.setRequestHeader(’content-type’, ’text/xml’); req.onreadystatechange = xmlPosted; req.send(xmlDoc); } function xmlPosted() { if (req.readyState != 4) return; if (req.status == 200) { var result = req.responseXML; } else { // 失败了 } } |
这种强大的功能的潜在用户是很多的,对于它可能实现的功能的探索才刚刚开始。但是在你试图在web上的建立XML功能之前,我建议你设置一个"安全网"来保证你的抱负(想法)不会受到打击。
JavaScript错误处理基础
JavaScript已经出现很久了,它的早期版本比较原始,缺少特性,仅仅是实现了而已。最新的浏览器不但支持C++和Java中try/catch/finally关键字,而且实现了onerror事件,而这个事件可以捕捉运行时出现的任何错误。它的使用是非常直接的:
| function riskyBusiness() { try { riskyOperation1(); riskyOperation2(); } catch (e) { // e是一个Error类型的对象,至少有两个属性:name和message } finally { // 清除消息 } } window.onerror = handleError; // 捕捉所有错误的安全网 function handleError(message, URI, line) { // 提示用户这个页面可能无法正常响应 return true; // 停止默认的消息 } |
实际的例子:把客户端错误传递到服务器上
现在我们知道了XMLHttpRequest和JavaScript错误处理的一些基础知识了,我们来看一个同时使用了两者的实现例子。你可能认为JavaScript错误可以很简单地在流行的"黄色死亡三角"中显示出来,但是仍然有一些错误传递到了几家篮筹股公司的公共web站点的质量部门了。
因此,我将提供一个用于捕捉错误并把错误记录到服务器上的方法,这样其他人就可能修补这些问题。首先,我们考虑客户端。客户端必须提供一个类,它被用作日志记录器(Logger)对象,可以透明地处理各种细节信息。
下面是我们建立的构造函数:
| // 类的构造函数 function Logger() { // 字段 this.req; // 方法 this.errorToXML = errorToXML; this.log = log; } |
接下来,我们定义了一个方法,它会把Error对象序列化为XML。在默认情况下,Error对象只有两种属性,分别是name和message,但是我们还是使用了第三个属性(location),它有时候是有用的。
| // 把错误映射到XML文档中 function errorToXML(err) { var xml = ’<?xml version="1.0"?>/n’ + ’<error>/n’ + ’<name>’ + err.name + ’</name>/n’ + ’<message>’ + err.message + ’</message>/n’; if (err.location) xml += ’<location>’ + err.location +’</location>’; xml += ’</error>’; return xml; } |
接着是log方法。这是脚本最基本的部分,它真正地实现了上述的原理。请注意,我们在调用中使用的是POST方法。从本质上说,我在此处建立的是一个定制的web服务,它是只读的,并为每个成功的请求建立新记录。因此,POST是唯一适当的选择。
| // 日志记录类的log方法 function log(err) { // 查看特性 if (window.XMLHttpRequest) this.req = new XMLHttpRequest(); else if (window.ActiveXObject) this.req =new ActiveXObject("Microsoft.XMLHTTP"); else return; // 失败了 // 设置方法和URI this.req.open("POST", "/cgi-bin/AjaxLogger.cgi"); // 设置请求头信息。REFERER 是顶层URI,如果它发生在一个包含的.js文件中 // 那么它的位置与错误的位置可能不同 this.req.setRequestHeader(’REFERER’, location.href); this.req.setRequestHeader(’content-type’, ’text/xml’); // 请求完成的时候调用的函数 this.req.onreadystatechange = errorLogged; this.req.send(this.errorToXML(err)); // 如果请求在10秒钟内没有完成,就出现一些错误消息 this.timeout = window.setTimeout("abortLog();", 10000); } |
类的最后一部分建立了一个Logger类实例。这个类应该只有一个实例。
| // 只有一个日志记录器实例 var logger = new Logger(); |
最后的两个函数只是用于琐碎事务管理的。如果在记录错误的时候出现了问题,除了干扰用户之外,我们几乎不能做任务事务。但是,这种情况永远不会出现。这些不是类的方法,因为事件没有指向我们的对象的指针,但是它会指向我们建立的logger实例。
| // 我们试过了,但是连接错误,没有希望了 function abortLog() { logger.req.abort(); alert("Attempt to log the error timed out."); } // 请求的状态发生改变的时候调用 function errorLogged() { if (logger.req.readyState != 4) return; window.clearTimeout(logger.timeout); // 请求完成了 if (logger.req.status >= 400) alert(’Attempt to log the error failed.’); } |
前面的所有代码都被包装到一个.js文件中了,我们可以在站点的任何(或每一个)页面中包含这个文件。下面是如何包含这个文件的例子:
| <script type="text/javascript" src="/Logger.js"></script> <script type="text/javascript"> function trapError(msg, URI, ln) { // 在对象中包装我们未知的错误 var error = new Error(msg); error.location = URI + ’, line: ’ + ln; // 添加自定义属性 logger.log(error); warnUser(); return true; // 停止黄色三角形 } window.onerror = trapError; function foo() { try { riskyOperation(); } catch (err) { //添加自定义属性 err.location = location.href + ’, function: foo()’; logger.log(err); warnUser(); } } function warnUser() { alert("An error has occurred while processing this page."+"Our engineers have been alerted!"); location.href = ’/path/to/error/page.html’; } </script> |
现在你已经知道如何把日志记录器集成到HTML页面中了,剩余的工作就是定义一种接收和转换消息的方法了。我选择使用最底层的通用命名方法,在Perl中建立了一个CGI脚本,这个脚本使用了我喜欢的一些模块,它使用XML::Simple来分析post数据,使用CGI::Carp把结果直接导入到httpd错误日志,这样可以节约系统管理员的时间,因为他不需要查看另外一个日志了。这个脚本还包含了很多良好的示例,它们适当地记录了不同的成功和失败条件。
| use CGI; use CGI::Carp qw(set_progname); use XML::Simple; my $request = CGI->new(); my $method = $request->request_method(); # 方法必须是POST if ($method eq ’POST’) { eval { my $content_type = $request->content_type(); if ($content_type eq ’text/xml’) { print $request->header(-status =>’415 Unsupported Media Type’, -type => ’text/xml’); croak "Invalid content type: $content_type/n"; } # 如果方法是POST,内容既不是URL编码也不是多部分形式, #那么整个post会被填充到一个参数中:POSTDATA。 my $error_xml = $request->param(’POSTDATA’); my $ref = XML::Simple::XMLin($error_xml); my ($name, $msg, $location) =($ref->{’name’}, $ref->{’message’}, ’’); $location = $ref->{’location’} if (defined($ref->{’location’})); # 改变日志中的名字 set_progname(’Client-side error’); my $remote_host = $request->remote_host(); carp "name: [$name], msg: [$msg], location: [$location]"; }; if ($@) { print $request->header(-status => ’500 Internal server error’,-type => ’text/xml’); croak "Error while logging: $@"; } else { # 这部分响应代码表明操作成功了,但是客户端不应该期待任何内容 print $request->header(-status => ’204 No content’,-type => ’text/xml’); } } else { print $request->header(-status => ’405 Method not supported’,-type => ’text/xml’); croak "Unsupported method: $method"; } |
已经完成了!现在,当某些难以理解的JavaScript进入系统的时候,你就可以期待着自己的日志监视器开始闪红灯,你的客户端开发人员在深夜接到电话了。
Ajax程序设计入门
一、使用Ajax的主要原因
2、把以前的一些服务器负担的工作转嫁到客户端,利于客户端闲置的处理能力来处理,减轻服务器和带宽的负担,从而达到节约ISP的空间及带宽租用成本的目的。
二、引用
Ajax是Asynchronous JavaScript and XML的缩写。
Ajax并不是一门新的语言或技术,它实际上是几项技术按一定的方式组合在一在同共的协作中发挥各自的作用,它包括:
·使用XHTML和CSS标准化呈现;
·使用 DOM实现动态显示和交互;
·使用XML和 XSLT进行数据交换与处理;
·使用XMLHttpRequest进行 异步数据读取;
·最后用JavaScript绑定和处理所有数据;
Ajax的工作原理相当于在用户和服务器之间加了—个中间层,使用户操作与服务器响应异步化。并不是所有的用户请求都提交给服务器,像—些数据验证和数据处理等都交给Ajax引擎自己来做,只有确定需要从服务器读取新数据时再由Ajax引擎代为向服务器提交请求。

图2-1

图2-2
| var xmlhttp = new XMLHttpRequest(); |
·微软的XMLHTTP组件在JS中的应用
|
var xmlhttp = new ActiveXObject(Microsoft.XMLHTTP);
XMLHttpRequest 对象方法var xmlhttp = new ActiveXObject(Msxml2.XMLHTTP);
/**
* Cross-browser XMLHttpRequest instantiation. */ if (typeof XMLHttpRequest == ’undefined’) { XMLHttpRequest = function () { var msxmls = [’MSXML3’, ’MSXML2’, ’Microsoft’] for (var i=0; i < msxmls.length; i++) { try { return new ActiveXObject(msxmls[i]+’.XMLHTTP’) } catch (e) { } } throw new Error("No XML component installed!") } } function createXMLHttpRequest() { try { // Attempt to create it "the Mozilla way" if (window.XMLHttpRequest) { return new XMLHttpRequest(); } // Guess not - now the IE way if (window.ActiveXObject) { return new ActiveXObject(getXMLPrefix() + ".XmlHttp"); } } catch (ex) {} return false; }; |
| 方法 | 描述 |
| abort() | 停止当前请求 |
| getAllResponseHeaders() | 作为字符串返问完整的headers |
| getResponseHeader("headerLabel") | 作为字符串返问单个的header标签 |
| open("method","URL"[,asyncFlag[,"userName"[, "password"]]]) | 设置未决的请求的目标 URL, 方法, 和其他参数 |
| send(content) | 发送请求 |
| setRequestHeader("label", "value") | 设置header并和请求一起发送 |
XMLHttpRequest 对象属性
| 属性 | 描述 |
| onreadystatechange | 状态改变的事件触发器 |
| readyState | 对象状态(integer): 0 = 未初始化 1 = 读取中 2 = 已读取 3 = 交互中 4 = 完成 |
| responseText | 服务器进程返回数据的文本版本 |
| responseXML | 服务器进程返回数据的兼容DOM的XML文档对象 |
| status | 服务器返回的状态码, 如:404 = "文件末找到" 、200 ="成功" |
| statusText | 服务器返回的状态文本信息 |
2、JavaScript
JavaScript是一在浏览器中大量使用的编程语言,,他以前一直被贬低为一门糟糕的语言(他确实在使用上比较枯燥),以在常被用来作一些用来炫耀的小玩意和恶作剧或是单调琐碎的表单验证。但事实是,他是一门真正的编程语言,有着自已的标准并在各种浏览器中被广泛支持。
3、DOM
Document Object Model。
DOM是给 HTML 和 XML 文件使用的一组 API。它提供了文件的结构表述,让你可以改变其中的內容及可见物。其本质是建立网页与 Script 或程序语言沟通的桥梁。
所有WEB开发人员可操作及建立文件的属性、方法及事件都以对象来展现(例如,document 就代表“文件本身“这个对像,table 对象则代表 HTML 的表格对象等等)。这些对象可以由当今大多数的浏览器以 Script 来取用。
一个用HTML或XHTML构建的网页也可以看作是一组结构化的数据,这些数据被封在DOM(Document Object Model)中,DOM提供了网页中各个对象的读写的支持。
4、XML
可扩展的标记语言(Extensible Markup Language)具有一种开放的、可扩展的、可自描述的语言结构,它已经成为网上数据和文档传输的标准。它是用来描述数据结构的一种语言,就正如他的名字一样。他使对某些结构化数据的定义更加容易,并且可以通过他和其他应用程序交换数据。
5、综合
Jesse James Garrett提到的Ajax引擎,实际上是一个比较复杂的JavaScript应用程序,用来处理用户请求,读写服务器和更改DOM内容。
JavaScript的Ajax引擎读取信息,并且互动地重写DOM,这使网页能无缝化重构,也就是在页面已经下载完毕后改变页面内容,这是我们一直在通过JavaScript和DOM在广泛使用的方法,但要使网页真正动态起来,不仅要内部的互动,还需要从外部获取数据,在以前,我们是让用户来输入数据并通过DOM来改变网页内容的,但现在,XMLHTTPRequest,可以让我们在不重载页面的情况下读写服务器上的数据,使用户的输入达到最少。
基于XML的网络通讯也并不是新事物,实际上FLASH和JAVA Applet都有不错的表现,现在这种富交互在网页上也可用了,基于标准化的并被广泛支持和技术,并且不需要插件或下载小程序。
Ajax是传统WEB应用程序的一个转变。以前是服务器每次生成HTML页面并返回给客户端(浏览器)。在大多数网站中,很多页面中至少90%都是一样的,比如:结构、格式、页头、页尾、广告等,所不同的只是一小部分的内容,但每次服务器都会生成所有的页面再返回给客户端,这无形之中是一种浪费,不管是对于用户的时间、带宽、CPU耗用,还是对于ISP的高价租用的带宽和空间来说。如果按一页来算,只能几K或是几十K可能并不起眼,但像SINA每天要生成几百万个页面的大ISP来说,可以说是损失巨大的。而AJAX可以所为客户端和服务器的中间层,来处理客户端的请求,并根据需要向服务器端发送请求,用什么就取什么、用多少就取多少,就不会有数据的冗余和浪费,减少了数据下载总量,而且更新页面时不用重载全部内容,只更新需要更新的那部分即可,相对于纯后台处理并重载的方式缩短了用户等待时间,也把对资源的浪费降到最低,基于标准化的并被广泛支持和技术,并且不需要插件或下载小程序,所以Ajax对于用户和ISP来说是双盈的。
Ajax使WEB中的界面与应用分离(也可以说是数据与呈现分离),而在以前两者是没有清晰的界限的,数据与呈现分离的分离,有利于分工合作、减少非技术人员对页面的修改造成的WEB应用程序错误、提高效率、也更加适用于现在的发布系统。也可以把以前的一些服务器负担的工作转嫁到客户端,利于客户端闲置的处理能力来处理。
四、应用
举个应用的例子,是关于级联菜单方面的Ajax应用。
我们以前的对级联菜单的处理是这样的:
为了避免每次对菜单的操作引起的重载页面,不采用每次调用后台的方式,而是一次性将级联菜单的所有数据全部读取出来并写入数组,然后根据用户的操作用JavaScript来控制它的子集项目的呈现,这样虽然解决了操作响应速度、不重载页面以及避免向服务器频繁发送请求的问题,但是如果用户不对菜单进行操作或只对菜单中的一部分进行操作的话,那读取的数据中的一部分就会成为冗余数据而浪费用户的资源,特别是在菜单结构复杂、数据量大的情况下(比如菜单有很多级、每一级菜又有上百个项目),这种弊端就更为突出。
如果在此案中应用Ajax后,结果就会有所改观:
在初始化页面时我们只读出它的第一级的所有数据并显示,在用户操作一级菜单其中一项时,会通过Ajax向后台请求当前一级项目所属的二级子菜单的所有数据,如果再继续请求已经呈现的二级菜单中的一项时,再向后面请求所操作二级菜单项对应的所有三级菜单的所有数据,以此类推……这样,用什么就取什么、用多少就取多少,就不会有数据的冗余和浪费,减少了数据下载总量,而且更新页面时不用重载全部内容,只更新需要更新的那部分即可,相对于后台处理并重载的方式缩短了用户等待时间,也把对资源的浪费降到最低。
此外,Ajax由于可以调用外部数据,也可以实现数据聚合的功能(当然要有相应授权),比如微软刚刚在3月15日发布的在线RSS阅读器BETA版;还可以利于一些开放的数据,开发自已的一些应用程序,比如用Amazon的数据作的一些新颖的图书搜索应用。
总之,Ajax适用于交互较多,频繁读数据,数据分类良好的WEB应用。
五、Ajax的优势
2、无刷新更新页面,减少用户实际和心理等待时间;
首先,“按需取数据”的模式减少了数据的实际读取量,打个很形象的比方,如果说重载的方式是从一个终点回到原点再到另一个终点的话,那么Ajax就是以一个终点为基点到达另一个终点;

图5-1

图5-2
其次,即使要读取比较大的数据,也不用像RELOAD一样出现白屏的情况,由于Ajax是用XMLHTTP发送请求得到服务端应答数据,在不重新载入整个页面的情况下用Javascript操作DOM最终更新页面的,所以在读取数据的过程中,用户所面对的也不是白屏,而是原来的页面状态(或者可以加一个LOADING的提示框让用户了解数据读取的状态),只有当接收到全部数据后才更新相应部分的内容,而这种更新也是瞬间的,用户几乎感觉不到。总之用户是很敏感的,他们能感觉到你对他们的体贴,虽然不太可能立竿见影的效果,但会在用户的心中一点一滴的积累他们对网站的依赖。
3、更好的用户体验;
4、也可以把以前的一些服务器负担的工作转嫁到客户端,利于客户端闲置的处理能力来处理,减轻服务器和带宽的负担,节约空间和带宽租用成本;
5、Ajax由于可以调用外部数据;
6、基于标准化的并被广泛支持和技术,并且不需要插件或下载小程序;
7、Ajax使WEB中的界面与应用分离(也可以说是数据与呈现分离);
8、对于用户和ISP来说是双盈的。
六、Ajax的问题
2、用JavaScript作的Ajax引擎,JavaScript的兼容性和DeBug都是让人头痛的事;
3、Ajax的无刷新重载,由于页面的变化没有刷新重载那么明显,所以容易给用户带来困扰――用户不太清楚现在的数据是新的还是已经更新过的;现有的解决有:在相关位置提示、数据更新的区域设计得比较明显、数据更新后给用户提示等;
4、对流媒体的支持没有FLASH、Java Applet好;
七、结束语
抛开这些不管,Web设计者们对设计交互式的Web没有什么更好的办法,却对我们做桌面软件的同事投去少许羡慕的目光.桌面应用程序有丰富的界面以及对于Web程序来说无法比拟的响应能力。同样,Web的快速发展,在我们所提供的体验和用户从桌面应用程序所得到的体验间产生巨大的差距
而如今差距正在消失。请看看“Google建议(Google Suggest)”. 观察它按你的输入显示建议条目的更新速度,几乎是立即更新的。再看看"Google Maps". 放大,用你的鼠标搬动和滚动。这些动作几乎是立即响应的,不用等待页面刷新。
"Google Suggest"和"Google Maps" 是采用Ajax技术的两个典型例子。Ajax是Asynchronous JavaScript and XML的简称,它表现出一个Web开发上的根本转变,那就是,Web上可能做些什么.
Ajax的定义
Ajax不是一个技术,它实际上是几种技术,每种技术都有其独特这处,合在一起就成了一个功能强大的新技术。Ajax包括:
- XHTML和CSS
- 使用文档对象模型(Document Object Model)作动态显示和交互
- 使用XML和XSLT做数据交互和操作
- 使用XMLHttpRequest进行异步数据接收
- 使用JavaScript将它们绑定在一起
传统的web应用模型工作起来就象这样:大部分界面上的用户动作触发一个连接到Web服务器的HTTP请求。服务器完成一些处理---接收数据,处理计算,再访问其它的数据库系统,最后返回一个HTML页面到客户端。这是一个老套的模式,自采用超文本作为web使用以来,一直都这样用, 但看过《The Elements of User Experience》的读者一定知道,是什么限制了Web界面没有桌面软件那么好用。

图1: 传统Web应用模型(左)与Ajax模型的比较(右).
这种旧的途径让我们认识到了许多技术,但它不会产生很好的用户体验。当服务器正在处理自己的事情的时候,用户在做什么?没错,等待。每一个动作,用户都要等待。
很明显,如果我们按桌面程序的思维设计Web应用,我们不愿意让用户总是等待。当界面加载后,为什么还要让用户每次再花一半的时间从服务取数据?实际上,为什么老是让用户看到程序去服务器取数据呢?
Ajax如何不同凡响
通过在用户和服务器之间引入一个Ajax引擎,可以消除Web的开始-停止-开始-停止这样的交互过程. 它就像增加了一层机制到程序中,使它响应更灵敏,而它的确做到了这一点。
不像加载一个页面一样,在会话的开始,浏览器加载了一个Ajax引擎---采用JavaScript编写并且通常在一个隐藏frame中。这个引擎负责绘制用户界面以及与服务器端通讯。Ajax引擎允许用异步的方式实现用户与程序的交互--不用等待服务器的通讯。所以用户再不不用打开一个空白窗口,看到等待光标不断的转,等待服务器完成后再响应。

图 2: 传统Web应用的同步交互过程(上)和Ajax应用的异步交互过程的比较(下).
通常要产生一个HTTP请求的用户动作现在通过JavaScript调用Ajax引擎来代替. 任何用户动作的响应不再要求直接传到服务器---例如简单的数据校验,内存中的数据编辑,甚至一些页面导航---引擎自己就可以处理它. 如果引擎需要从服务器取数据来响应用户动作---假设它提交需要处理的数据,载入另外的界面代码,或者接收新的数据---引擎让这些工作异步进行,通常使用XML, 不用再担误用户界面的交互。
谁在使用Ajax
在采用Ajax的开发上面,Google做了巨大的投资。去年Google所有主要的产品都用了这项技术---Orkut, Gmail, 以及最近的beta版的Google Groups, Google Suggest和Google Maps---它们全是Ajax的应用。(要想了解更多这些Ajax实际的技术细节,请看它们的分析文章:Gmail, Google Suggest, Google Maps). 其它的像:Flickr, 采用许多人们喜欢的Ajax特性, 还有Amazon的A9.com搜索引擎也采用类似的技术。
这些项目证明了Ajax不只是学术上的,也有许多真实世界成功应用。这不是什么实验室里的技术。Ajax的应用可大可小,从非常简单的,像单一功能的Google Suggest到非常复杂的Google Maps.
web2.0与Web1.0的区别是什么?
Web2.0到底是什么,它与Web1.0之间存在哪些区别,什么样的网站可以称之为Web2.0?这些问题似乎现在还没有一个大家比较公认的答案。del.icio.us上的Web2.0标签中也可以看到很多各式各样的网站,到底Web2.0为什么是Web2.0,它的特性是什么,收集整理了一些人的观点,作为自己学习的资料。
文章较长,就不在首页放全文了。
———————————————————-
Wikipadia:维基百科上关于Web2.0的条目中有两段涉及Web2.0的特色:
1、O’Reilly和Battelle总结了他们认为的表现了Web 2.0应用特色的一些关键原则:
* 将Web作为平台;
* 将数据变成“Intel Inside”;
* 分享和参与的架构 驱动的网络效应;
* 通过带动分散的、独立的开发者把各个系统和网站组合形成大汇集的改革;
* 通过内容和服务的联合使轻量的业务模型可行;
* 软件采购循环(software adoption cycle)的终结(“永久的Beta版”)
* 软件凌驾于单一设备的层次之上;
* 拉动长尾的能力。
2、如果一个网站使用了以下一些技术作为特色的话,就说他是利用了Web 2.0技术:
技术方面:
* CSS, 语义化有效的XHTML标记,和Microformats
* 不突出的丰富应用技术(例如Ajax)
* 数据的联合,RSS/ATOM
* RSS/ATOM数据的聚合
* 规则且有意义的URL
* 支持对网志发帖子
* REST 或者是XML Web服务API
* 某些社会性网络方面
通用概念:
* 网站不能是封闭的——它必须可以很方便地被其他系统获取或写入数据。
* 用户应该在网站上拥有他们自己的数据。
* 完全地基于Web —— 大多数成功的Web 2.0网站可以几乎完全通过浏览器来使用
曾登高:Web 2.0是代指所有用户体验型的网络服务,这句话有2个重点,用户体验型和网络服务。网络服务不是指技术上常说的Web Services,他泛指一切在互联网上提供个性化服务的应用。注重用户体验是Web 2.0被经常提起的主要原因。这不仅仅是因为用户可以来参与,更多地是因为互联网服务更加人性化和个性化。
Don:Web1.0到Web2.0的转变,具体的说,从模式上是单纯的“读”向“写”、“共同建设”发展;从基本构成单元上,是由“网页”向“发表/记录的信息”发展;从工具上,是由互联网浏览器向各类浏览器、rss阅读器等内容发展;运行机制上,由“Client Server”向“Web Services”转变;作者由程序员等专业人士向全部普通用户发展;应用上由初级的“滑稽”的应用向全面大量应用发展。
zheng:从Web应用的产品/服务生产者角度来说,该如何创建Web2.0的产品呢?重要的是要抓住这么几点,一个是微内容(这里有定义),一个是用户个体。除了这两个最基本的之外,还可以考虑社群内的分享以及提供API。
一类可以被称作Web2.0的产品/服务将是这样:服务于用户个体的微内容的收集、创建、发布、管理、分享、合作、维护等的平台。其他的呢?恐怕就设计到好些人提到的,微内容的XML表现;微内容的聚合;微内容的迁移;社会性关系的维护;界面的易用性等等。(zheng的学习Web2.0系列都是很值得认真阅读的)
Vazi: Web 2.0:基于 RSS/ATOM规范(XML与HTML混合规范);由网站提供服务,让网站用户发布及浏览;Web2.0是信息源的去中心化了,而信息服务依然有着一个中心向众多的用户提供服务。
jgovernor :web 1.0 - content produced by someone else(内容来自某人)/architecture of consumption(消费架构)/attempts to create walled gardens(创建一个有围墙的花园)/download culture(下载的文化)/read only(只读)
web 2.0 - content produced by the user(内容来自用户)/architecture of partipation(参与架构)/
building value through open fields(建造一个开放的有价值的田园)/remix culture(混合的文化)/read/write (读写)
Alex Barnett:(中文版见这里)
web 1.0 - centralized/individual/content/readable/transmission/deliberate/static/rigid
web 2.0 - distributed/social, memetic/services and APIs/writeable/syndication/spontaneous, emerging/ connected, dynamic/loosely couple
文心:Web2.0带给我们的是一种可读写的网络,这种可读写的网络表现于用户是一种双通道的交流模式,也就是说网页与用户之间的互动关系由传统的“Push”模式演变成双向交流的“Two-WayCommunication”的模式。而对于Web服务的开发者来说,Web2.0带来的理念是服务的亲和力,可操作性,用户体验以及可用性。
飞戈:Web2.0有下面几个方面的特性:个性化的传播方式,读与写并存的表达方式,社会化的联合方式,标准化的创作方式,便捷化的体验方式,高密度的媒体方式。
谢文:Web 2.0 是以个人为基础,以满足个性化需求为手段,通过鼓励建立人与人之间的关系,形成社区化的生活方式的平台。
igooi:创新性、用户的参与性、注重用户体验、开放平台、SNS Feature,我所欣赏的web2.0理念是:不断创新,注重用户体验,开放平台和鼓励用户的参与创造。
雄杰:Web2.0最大的特点是,每一个用户身上都会带有许多的标签,以前我们面对的是一个一个帖子,一条一条的信息,以后我们可能更多要面对和服务的是这些带有标签的ID,针对带有标签的ID提供个性服务。
David Cowan:Web2.0天生具备病毒性传播的特征,而且是借助用户产生的内容而自我发展
詹膑:web2.0的网站特点:分散化,小型站点的发展;用户主导、用户参与、用户建设;输入输出与cms的组织方式,可读写;用户忠诚与用户(社区)文化;服务型
老冒:
选择多,量身定做,可以自由组合,标准化,口碑,大伙儿参与(here)
Web2.0更像一面旗帜,而不是技术和服务革新;web 2.0下的Internet市场是细分的市场;Social 特性是 web 2.0的成功关键;聚合,微内容,个人门户是web 2.0的关键应用;商业模式主要来源于服务收费而非广告;web 2.0主要将靠口碑营销;web 2.0时代不再有“小生意”(here)
Decentralize,Ajax和类似技术,Blog, RSS, Wiki, 网摘等特定应用或技术…,API, Developer站点等,专注,单一服务,轻量级公司,收购大量的人气BBS、搞一大堆情色交友站点和一味提高流量,这些在Web2.0下其实并非关键。(here)
最后是两张图:
rashmi: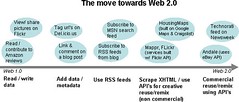
Tim O’Reilly: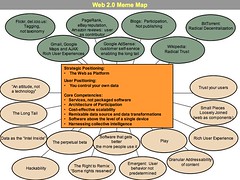
web 2.0的内容列表,仅供参考:
1.Give us your email address, we'll let you know when it's ready!
2.Public beta alpha
3.Tags
4.Feeds for everything
5.Built with Rails
6.Sprinkled with Ajax
7.Yellow fade
8.Blue gradients
9.Big icons
10.Big fonts
11.Big input boxes
12.REST API
13.Google Maps mashup
14.Share with a friend
15.TypePad blog for a peek inside the team
16.Feature screencasts
17.Hackathons for new features
18.Development wiki
19.Business model optimized for the long tail
20.It's Free!/AdSense revenue stream

















 1876
1876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









