






本文讲述自编码器(Auto Encoder,下文简称AE),将按照以下的思路展开讲解,力图使得初学者能看懂其中要义。目录如下:
1.AE的基本原理
2.AE的用途
3.基于MNIST数据集的AE的简单python实现
1.AE的基本原理
AE,是神经网络模型的一种,是一种全连接网络模型,而且进行无监督学习,下图是简单的AE结构。
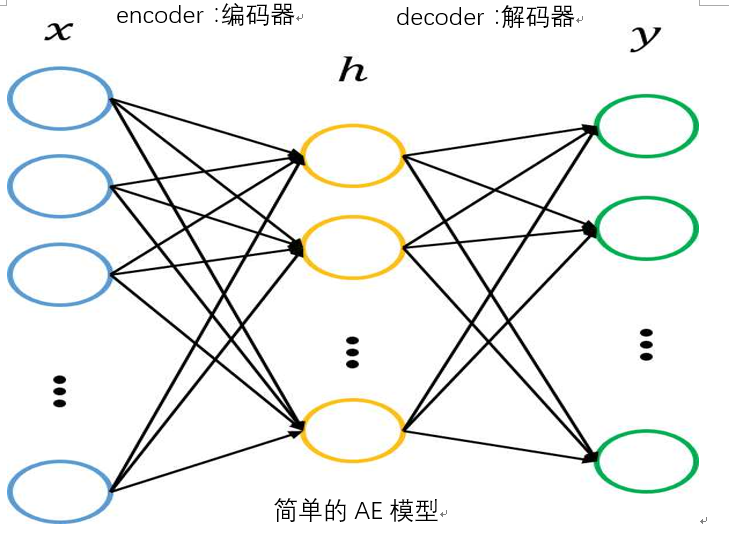
从上图可以看出AE模型主要由以下构建组成:
1)编码器,即为输入层和第一个隐层之间的部分,主要进行特征提取,也称编码过程
2)解码器,隐层到输出层之间部分,把隐层提取到的特征重新还原输出
AE是相对简单的全连接模型,因为AE模型往往是对称的,也就是说编码过程和解码过程的网络组织是一样的,举个简单的例子:现有一5层的AE模型,若输入层神经元个数为200个,那么输出层神经元个数也是200个,第一个隐层有100个神经元,那么输出层的前一层也有100个神经元。AE模型的训练过程和全连接网络模型的训练过程是一样的。
2.AE的应用场景
我们学习一种算法,要明白算法的原理精髓,还要知道该算法的应用场景。AE的主要用途概括主要有两个: A.特征提取,去燥,降维,信息补全; B.为深层网络确定相对合理的网络初始化参数。下面对这两种用途做详细介绍。
首先,AE是非常有效的数据降维模型,降维和信息补全对应了两种不同的网络架构,不严格的讲,隐层神经元个数少于输入层神经元个数,就认为该AE模型可以进行数据降维,AE的降维效果和著名的PCA(principal component analysis,主成分分析)降维算法有过之而无不及,PCA只能进行线性特征降维,而AE的范围就不仅局限于此了。隐层神经元个数若大于输入层神经元个数,这种AE模型是可以进行缺失信息填补的,至于去燥,现有的Denoising Autoencoder 模型就能够对原始数据进行去燥处理。
再次,AE的另一个主要作用是为深层网络确定相对合理的网络初始化参数,了解深度学习的博友都知道,深层网络由于其网络层次往往较深,如果我们用随机化参数进行模型的训练,很多情况下会出现梯度消失或者梯度爆炸这样的情形,因此,如果能在深层模型训练之前给每一层的权值赋予相对合理对的权值,就能有效避免梯度消失和梯度爆炸问题。
3.基于MNIST数据集的AE的python实现
import os import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import matplotlib.pyplot as plt os.environ['TF_CPP_MIN_LOG_LEVEL']='2' #读取mnist数据集 mnist=input_data.read_data_sets("MNIST_data",one_hot=True) input_num=784 hidden_num=256 learning_rate=0.01 epoch=50 batch_size=550 example_to_show=5 #权重字典 weights={'encode_weight':tf.Variable(tf.truncated_normal([input_num,hidden_num])), 'decode_weight':tf.Variable(tf.truncated_normal([hidden_num,input_num]))} #偏置字典 biases={'encode_bias':tf.Variable(tf.truncated_normal([hidden_num])), 'decode_bias':tf.Variable(tf.truncated_normal([input_num]))} input=tf.placeholder(tf.float32,[None,input_num]) def encode(input): return tf.nn.sigmoid(tf.add(tf.matmul(input, weights['encode_weight']), biases['encode_bias'])) def decode(input): return tf.nn.sigmoid(tf.add(tf.matmul(input,weights['decode_weight']), biases['decode_bias'])) #定义误差 output=decode(encode(input)) cost = tf.reduce_mean(tf.pow(input - output, 2)) # 最小二乘法 optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost) #训练模型 with tf.Session() as sess: init=tf.global_variables_initializer() sess.run(init) total_batch = int(mnist.train.num_examples / batch_size) print(total_batch) for time in range(epoch): for batch in range(total_batch): batch_xs, batch_ys = mnist.train.next_batch(batch_size) #获取需要用到的数据,y_batch不会用到 _, c = sess.run([optimizer, cost], feed_dict={input: batch_xs}) print("Epoch:",(time + 1), "cost=", round(c,6)) encode_decode = sess.run( output, feed_dict={input: mnist.test.images[:example_to_show]}) f, a = plt.subplots(2, 5, figsize=(5, 2)) for i in range(example_to_show): a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28))) a[1][i].imshow(np.reshape(encode_decode[i], (28, 28))) plt.show()
才疏学浅,不正确之处,欢迎指正!
参考:http://blog.csdn.net/u013719780/article/details/53788061















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









