







#
#作者:韦访
#博客:https://blog.csdn.net/rookie_wei
#微信:1007895847
#添加微信的备注一下是CSDN的
#欢迎大家一起学习
#
------韦访 20190704
7、定义网络
继续往下分析,
# define model for multi-gpu
# 如果有多块GPU,将队列划分为多块,以分给每块GPU
q_inp_split, q_heat_split, q_vect_split = tf.split(q_inp, args.gpus), tf.split(q_heat, args.gpus), tf.split(q_vect, args.gpus)
output_vectmap = []
output_heatmap = []
losses = []
last_losses_l1 = []
last_losses_l2 = []
outputs = []
# 将任务分配到多块GPU上
for gpu_id in range(args.gpus):
with tf.device(tf.DeviceSpec(device_type="GPU", device_index=gpu_id)):
with tf.variable_scope(tf.get_variable_scope(), reuse=(gpu_id > 0)):
# 根据传入的model参数获取net,已经训练好了的模型路径,最后一层网络名
net, pretrain_path, last_layer = get_network(args.model, q_inp_split[gpu_id])
# 如果传入参数checkpoint,则pretrain_path直接用checkpoint的路径而不是默认的路径
if args.checkpoint:
pretrain_path = args.checkpoint
# 获取最后一层的输出 L 和 S
vect, heat = net.loss_last()
output_vectmap.append(vect)
output_heatmap.append(heat)
# 获取最后输出结果
outputs.append(net.get_output())
# 获取 stage2 后的每一层的输出 L 和 S
l1s, l2s = net.loss_l1_l2()
# 求每一层的L2范数 loss
for idx, (l1, l2) in enumerate(zip(l1s, l2s)):
loss_l1 = tf.nn.l2_loss(tf.concat(l1, axis=0) - q_vect_split[gpu_id], name='loss_l1_stage%d_tower%d' % (idx, gpu_id))
loss_l2 = tf.nn.l2_loss(tf.concat(l2, axis=0) - q_heat_split[gpu_id], name='loss_l2_stage%d_tower%d' % (idx, gpu_id))
losses.append(tf.reduce_mean([loss_l1, loss_l2]))
# 最后一层的L2 范数 loss
last_losses_l1.append(loss_l1)
last_losses_l2.append(loss_l2)
outputs = tf.concat(outputs, axis=0)如果你是土豪,有多块GPU,上面的代码就是满足你的,将队列划分成多块,再分给每块GPU去训练,我只有一个GPU。主要看get_network函数,
def get_network(type, placeholder_input, sess_for_load=None, trainable=True):
if type == 'mobilenet':
net = MobilenetNetwork({'image': placeholder_input}, conv_width=0.75, conv_width2=1.00, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v1_0.75_224_2017_06_14/mobilenet_v1_0.75_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_fast':
net = MobilenetNetwork({'image': placeholder_input}, conv_width=0.5, conv_width2=0.5, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v1_0.75_224_2017_06_14/mobilenet_v1_0.75_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_accurate':
net = MobilenetNetwork({'image': placeholder_input}, conv_width=1.00, conv_width2=1.00, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v1_1.0_224_2017_06_14/mobilenet_v1_1.0_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_thin':
net = MobilenetNetworkThin({'image': placeholder_input}, conv_width=0.75, conv_width2=0.50, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v1_0.75_224_2017_06_14/mobilenet_v1_0.75_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type in ['mobilenet_v2_w1.4_r1.0', 'mobilenet_v2_large', 'mobilenet_v2_large_quantize']: # m_v2_large
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=1.4, conv_width2=1.0, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_1.4_224/mobilenet_v2_1.4_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_w1.4_r0.5':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=1.4, conv_width2=0.5, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_1.4_224/mobilenet_v2_1.4_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_w1.0_r1.0':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=1.0, conv_width2=1.0, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_1.0_224/mobilenet_v2_1.0_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_w1.0_r0.75':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=1.0, conv_width2=0.75, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_1.0_224/mobilenet_v2_1.0_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_w1.0_r0.5':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=1.0, conv_width2=0.5, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_1.0_224/mobilenet_v2_1.0_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_w0.75_r0.75':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=0.75, conv_width2=0.75, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_0.75_224/mobilenet_v2_0.75_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_w0.5_r0.5' or type == 'mobilenet_v2_small': # m_v2_fast
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=0.5, conv_width2=0.5, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_0.5_224/mobilenet_v2_0.5_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_1.4':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=1.4, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_1.4_224/mobilenet_v2_1.4_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_1.0':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=1.0, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_1.0_224/mobilenet_v2_1.0_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_0.75':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=0.75, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_0.75_224/mobilenet_v2_0.75_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type == 'mobilenet_v2_0.5':
net = Mobilenetv2Network({'image': placeholder_input}, conv_width=0.5, trainable=trainable)
pretrain_path = 'pretrained/mobilenet_v2_0.5_224/mobilenet_v2_0.5_224.ckpt'
last_layer = 'MConv_Stage6_L{aux}_5'
elif type in ['cmu', 'openpose']:
net = CmuNetwork({'image': placeholder_input}, trainable=trainable)
pretrain_path = 'numpy/openpose_coco.npy'
last_layer = 'Mconv7_stage6_L{aux}'
elif type in ['cmu_quantize', 'openpose_quantize']:
net = CmuNetwork({'image': placeholder_input}, trainable=trainable)
pretrain_path = 'train/cmu/bs8_lr0.0001_q_e80/model_latest-18000'
last_layer = 'Mconv7_stage6_L{aux}'
elif type == 'vgg':
net = CmuNetwork({'image': placeholder_input}, trainable=trainable)
pretrain_path = 'numpy/openpose_vgg16.npy'
last_layer = 'Mconv7_stage6_L{aux}'
else:
raise Exception('Invalid Model Name.')
pretrain_path_full = os.path.join(_get_base_path(), pretrain_path)
if sess_for_load is not None:
if type in ['cmu', 'vgg', 'openpose']:
if not os.path.isfile(pretrain_path_full):
raise Exception('Model file doesn\'t exist, path=%s' % pretrain_path_full)
net.load(os.path.join(_get_base_path(), pretrain_path), sess_for_load)
else:
try:
s = '%dx%d' % (placeholder_input.shape[2], placeholder_input.shape[1])
except:
s = ''
ckpts = {
'mobilenet': 'trained/mobilenet_%s/model-246038' % s,
'mobilenet_thin': 'trained/mobilenet_thin_%s/model-449003' % s,
'mobilenet_fast': 'trained/mobilenet_fast_%s/model-189000' % s,
'mobilenet_accurate': 'trained/mobilenet_accurate/model-170000',
'mobilenet_v2_w1.4_r0.5': 'trained/mobilenet_v2_w1.4_r0.5/model_latest-380401',
'mobilenet_v2_large': 'trained/mobilenet_v2_w1.4_r1.0/model-570000',
'mobilenet_v2_small': 'trained/mobilenet_v2_w0.5_r0.5/model_latest-380401',
}
ckpt_path = os.path.join(_get_base_path(), ckpts[type])
loader = tf.train.Saver()
try:
loader.restore(sess_for_load, ckpt_path)
except Exception as e:
raise Exception('Fail to load model files. \npath=%s\nerr=%s' % (ckpt_path, str(e)))
return net, pretrain_path_full, last_layer这里提供了很多个网络给我们选择,我们使用的是cmu网络,所以,用的是CmuNetwork类,这个类实现的就是我们论文里第3点讲的那个网络,
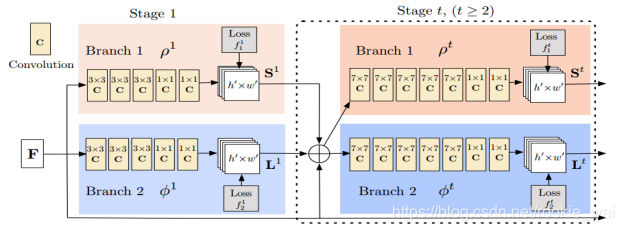
来看下代码怎么实现,
class CmuNetwork(network_base.BaseNetwork):CmuNetwork类继承了network_base.BaseNetwork类,来看看network_base.BaseNetwork类的__init__函数做了什么,
class BaseNetwork(object):
def __init__(self, inputs, trainable=True):
# The input nodes for this network
self.inputs = inputs
# The current list of terminal nodes
self.terminals = []
# Mapping from layer names to layers
self.layers = dict(inputs)
# If true, the resulting variables are set as trainable
self.trainable = trainable
# Switch variable for dropout
self.use_dropout = tf.placeholder_with_default(tf.constant(1.0),
shape=[],
name='use_dropout')
self.setup()一些基本的初始化以后,调用setup函数,而这个setup函数主要在CmuNetwork类里实现的,代码如下,
def setup(self):
# 用了 VGG19 的前10层,对后基层网络进行了微调
(self.feed('image')
.normalize_vgg(name='preprocess')
.conv(3, 3, 64, 1, 1, name='conv1_1')
.conv(3, 3, 64, 1, 1, name='conv1_2')
.max_pool(2, 2, 2, 2, name='pool1_stage1', padding='VALID')
.conv(3, 3, 128, 1, 1, name='conv2_1')
.conv(3, 3, 128, 1, 1, name='conv2_2')
.max_pool(2, 2, 2, 2, name='pool2_stage1', padding='VALID')
.conv(3, 3, 256, 1, 1, name='conv3_1')
.conv(3, 3, 256, 1, 1, name='conv3_2')
.conv(3, 3, 256, 1, 1, name='conv3_3')
.conv(3, 3, 256, 1, 1, name='conv3_4')
.max_pool(2, 2, 2, 2, name='pool3_stage1', padding='VALID')
.conv(3, 3, 512, 1, 1, name='conv4_1')
.conv(3, 3, 512, 1, 1, name='conv4_2') # 这里上去的都是VGG19的前10层网络
.conv(3, 3, 256, 1, 1, name='conv4_3_CPM')
.conv(3, 3, 128, 1, 1, name='conv4_4_CPM') # ***** 得到原始图片的特征图F
##########################################################################################
# stage 1 ,分别得到 S1 和 L1
.conv(3, 3, 128, 1, 1, name='conv5_1_CPM_L1')
.conv(3, 3, 128, 1, 1, name='conv5_2_CPM_L1')
.conv(3, 3, 128, 1, 1, name='conv5_3_CPM_L1')
.conv(1, 1, 512, 1, 1, name='conv5_4_CPM_L1')
.conv(1, 1, 38, 1, 1, relu=False, name='conv5_5_CPM_L1'))
(self.feed('conv4_4_CPM')
.conv(3, 3, 128, 1, 1, name='conv5_1_CPM_L2')
.conv(3, 3, 128, 1, 1, name='conv5_2_CPM_L2')
.conv(3, 3, 128, 1, 1, name='conv5_3_CPM_L2')
.conv(1, 1, 512, 1, 1, name='conv5_4_CPM_L2')
.conv(1, 1, 19, 1, 1, relu=False, name='conv5_5_CPM_L2'))
##########################################################################################
# stage2,将上一个stage得到的 S 和 L,再加上原始图片特征图F当成输入
# L1 是矢量图 L, L2 是热图(置信图)S
(self.feed('conv5_5_CPM_L1',
'conv5_5_CPM_L2',
'conv4_4_CPM')
.concat(3, name='concat_stage2')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage2_L1')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage2_L1')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage2_L1')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage2_L1')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage2_L1')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage2_L1')
.conv(1, 1, 38, 1, 1, relu=False, name='Mconv7_stage2_L1'))
(self.feed('concat_stage2')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage2_L2')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage2_L2')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage2_L2')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage2_L2')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage2_L2')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage2_L2')
.conv(1, 1, 19, 1, 1, relu=False, name='Mconv7_stage2_L2'))
##########################################################################################
# stage3,将上一个stage得到的 S 和 L,再加上原始图片特征图F当成输入
(self.feed('Mconv7_stage2_L1',
'Mconv7_stage2_L2',
'conv4_4_CPM')
.concat(3, name='concat_stage3')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage3_L1')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage3_L1')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage3_L1')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage3_L1')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage3_L1')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage3_L1')
.conv(1, 1, 38, 1, 1, relu=False, name='Mconv7_stage3_L1'))
(self.feed('concat_stage3')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage3_L2')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage3_L2')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage3_L2')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage3_L2')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage3_L2')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage3_L2')
.conv(1, 1, 19, 1, 1, relu=False, name='Mconv7_stage3_L2'))
##########################################################################################
# stage4,将上一个stage得到的 S 和 L,再加上原始图片特征图F当成输入
(self.feed('Mconv7_stage3_L1',
'Mconv7_stage3_L2',
'conv4_4_CPM')
.concat(3, name='concat_stage4')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage4_L1')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage4_L1')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage4_L1')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage4_L1')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage4_L1')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage4_L1')
.conv(1, 1, 38, 1, 1, relu=False, name='Mconv7_stage4_L1'))
(self.feed('concat_stage4')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage4_L2')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage4_L2')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage4_L2')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage4_L2')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage4_L2')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage4_L2')
.conv(1, 1, 19, 1, 1, relu=False, name='Mconv7_stage4_L2'))
##########################################################################################
# stage4,将上一个stage得到的 S 和 L,再加上原始图片特征图F当成输入
(self.feed('Mconv7_stage4_L1',
'Mconv7_stage4_L2',
'conv4_4_CPM')
.concat(3, name='concat_stage5')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage5_L1')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage5_L1')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage5_L1')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage5_L1')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage5_L1')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage5_L1')
.conv(1, 1, 38, 1, 1, relu=False, name='Mconv7_stage5_L1'))
(self.feed('concat_stage5')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage5_L2')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage5_L2')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage5_L2')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage5_L2')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage5_L2')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage5_L2')
.conv(1, 1, 19, 1, 1, relu=False, name='Mconv7_stage5_L2'))
##########################################################################################
# stage6,将上一个stage得到的 S 和 L,再加上原始图片特征图F当成输入
(self.feed('Mconv7_stage5_L1',
'Mconv7_stage5_L2',
'conv4_4_CPM')
.concat(3, name='concat_stage6')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage6_L1')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage6_L1')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage6_L1')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage6_L1')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage6_L1')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage6_L1')
.conv(1, 1, 38, 1, 1, relu=False, name='Mconv7_stage6_L1'))
(self.feed('concat_stage6')
.conv(7, 7, 128, 1, 1, name='Mconv1_stage6_L2')
.conv(7, 7, 128, 1, 1, name='Mconv2_stage6_L2')
.conv(7, 7, 128, 1, 1, name='Mconv3_stage6_L2')
.conv(7, 7, 128, 1, 1, name='Mconv4_stage6_L2')
.conv(7, 7, 128, 1, 1, name='Mconv5_stage6_L2')
.conv(1, 1, 128, 1, 1, name='Mconv6_stage6_L2')
.conv(1, 1, 19, 1, 1, relu=False, name='Mconv7_stage6_L2'))
##########################################################################################
# 最后一层,将得到的 S6 和 L6 拼接
with tf.variable_scope('Openpose'):
(self.feed('Mconv7_stage6_L2',
'Mconv7_stage6_L1')
.concat(3, name='concat_stage7'))怎么样?对比论文的图看,是不是茅塞顿开了?继续回到train.py的main函数,
8、学习率
得到网络以后,就是一些损失值的保存,有备注了就不讲了,继续往下看,
with tf.device(tf.DeviceSpec(device_type="GPU")):
# define loss
# 计算每张图片的L1和L2总损失
total_loss = tf.reduce_sum(losses) / args.batchsize
# 计算每张图片的L1总损失
total_loss_ll_paf = tf.reduce_sum(last_losses_l1) / args.batchsize
# 计算每张图片的L2总损失
total_loss_ll_heat = tf.reduce_sum(last_losses_l2) / args.batchsize
# 计算每个batch 的L1和L2总损失
total_loss_ll = tf.reduce_sum([total_loss_ll_paf, total_loss_ll_heat])
# define optimizer
# 设置学习率
# 每个epoch执行的步数
step_per_epoch = 121745 // args.batchsize
global_step = tf.Variable(0, trainable=False)
if ',' not in args.lr:
starter_learning_rate = float(args.lr)
# learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
# decay_steps=10000, decay_rate=0.33, staircase=True)
# 学习率余弦衰减
learning_rate = tf.train.cosine_decay(starter_learning_rate, global_step, args.max_epoch * step_per_epoch, alpha=0.0)
else:
lrs = [float(x) for x in args.lr.split(',')]
boundaries = [step_per_epoch * 5 * i for i, _ in range(len(lrs)) if i > 0]
learning_rate = tf.train.piecewise_constant(global_step, boundaries, lrs)上面也是一些损失的计算,还有学习率的设置,
9、优化器
继续往下看,
# 优化器
optimizer = tf.train.AdamOptimizer(learning_rate, epsilon=1e-8)
# optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.8, use_locking=True, use_nesterov=True)
# 关于tf.GraphKeys.UPDATE_OPS,这是一个tensorflow的计算图中内置的一个集合,其中会保存一些需要在训练操作之前完成的操作,并配合tf.control_dependencies函数使用。
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
# tf.control_dependencies,该函数保证其辖域中的操作必须要在该函数所传递的参数中的操作完成后再进行
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(total_loss, global_step, colocate_gradients_with_ops=True)
logger.info('define model-')
# define summary
tf.summary.scalar("loss", total_loss)
tf.summary.scalar("loss_lastlayer", total_loss_ll)
tf.summary.scalar("loss_lastlayer_paf", total_loss_ll_paf)
tf.summary.scalar("loss_lastlayer_heat", total_loss_ll_heat)
tf.summary.scalar("queue_size", enqueuer.size())
tf.summary.scalar("lr", learning_rate)
merged_summary_op = tf.summary.merge_all()
这里就是设置优化器,用的是adam梯度下降法,
10、定义占位符
继续往下看,
# 定义验证集和示例的占位符
valid_loss = tf.placeholder(tf.float32, shape=[])
valid_loss_ll = tf.placeholder(tf.float32, shape=[])
valid_loss_ll_paf = tf.placeholder(tf.float32, shape=[])
valid_loss_ll_heat = tf.placeholder(tf.float32, shape=[])
sample_train = tf.placeholder(tf.float32, shape=(4, 640, 640, 3))
sample_valid = tf.placeholder(tf.float32, shape=(12, 640, 640, 3))
train_img = tf.summary.image('training sample', sample_train, 4)
valid_img = tf.summary.image('validation sample', sample_valid, 12)
valid_loss_t = tf.summary.scalar("loss_valid", valid_loss)
valid_loss_ll_t = tf.summary.scalar("loss_valid_lastlayer", valid_loss_ll)
merged_validate_op = tf.summary.merge([train_img, valid_img, valid_loss_t, valid_loss_ll_t])上面就是定义占位符了,又到了熟悉的配方,熟悉的味道了。
11、会话
继续看,
# 用于保存模型
saver = tf.train.Saver(max_to_keep=1000)
# 创建会话
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
logger.info('model weights initialization')
sess.run(tf.global_variables_initializer())
# 加载模型
if args.checkpoint and os.path.isdir(args.checkpoint):
logger.info('Restore from checkpoint...')
# loader = tf.train.Saver(net.restorable_variables())
# loader.restore(sess, tf.train.latest_checkpoint(args.checkpoint))
saver.restore(sess, tf.train.latest_checkpoint(args.checkpoint))
logger.info('Restore from checkpoint...Done')
elif pretrain_path:
logger.info('Restore pretrained weights... %s' % pretrain_path)
if '.npy' in pretrain_path:
# 如果是npy的格式
net.load(pretrain_path, sess, False)
else:
try:
loader = tf.train.Saver(net.restorable_variables(only_backbone=False))
loader.restore(sess, pretrain_path)
except:
logger.info('Restore only weights in backbone layers.')
loader = tf.train.Saver(net.restorable_variables())
loader.restore(sess, pretrain_path)
logger.info('Restore pretrained weights...Done')
logger.info('prepare file writer')
file_writer = tf.summary.FileWriter(os.path.join(logpath, args.tag), sess.graph)
# 启动队列
logger.info('prepare coordinator')
coord = tf.train.Coordinator()
enqueuer.set_coordinator(coord)
enqueuer.start()
logger.info('Training Started.')
time_started = time.time()
last_gs_num = last_gs_num2 = 0
initial_gs_num = sess.run(global_step)
last_log_epoch1 = last_log_epoch2 = -1
while True:
# 开始训练
_, gs_num = sess.run([train_op, global_step])
# 当前epoch
curr_epoch = float(gs_num) / step_per_epoch
# 训练到指定次数了,退出
if gs_num > step_per_epoch * args.max_epoch:
break
if gs_num - last_gs_num >= 500:
# 训练500步输出一次损失
train_loss, train_loss_ll, train_loss_ll_paf, train_loss_ll_heat, lr_val, summary = sess.run([total_loss, total_loss_ll, total_loss_ll_paf, total_loss_ll_heat, learning_rate, merged_summary_op])
# log of training loss / accuracy
batch_per_sec = (gs_num - initial_gs_num) / (time.time() - time_started)
logger.info('epoch=%.2f step=%d, %0.4f examples/sec lr=%f, loss=%g, loss_ll=%g, loss_ll_paf=%g, loss_ll_heat=%g' % (gs_num / step_per_epoch, gs_num, batch_per_sec * args.batchsize, lr_val, train_loss, train_loss_ll, train_loss_ll_paf, train_loss_ll_heat))
last_gs_num = gs_num
if last_log_epoch1 < curr_epoch:
file_writer.add_summary(summary, curr_epoch)
last_log_epoch1 = curr_epoch
if gs_num - last_gs_num2 >= 2000:
# 训练2000次保存一次
# save weights
saver.save(sess, os.path.join(modelpath, args.tag, 'model_latest'), global_step=global_step)
average_loss = average_loss_ll = average_loss_ll_paf = average_loss_ll_heat = 0
total_cnt = 0
if len(validation_cache) == 0:
for images_test, heatmaps, vectmaps in tqdm(df_valid.get_data()):
validation_cache.append((images_test, heatmaps, vectmaps))
df_valid.reset_state()
del df_valid
df_valid = None
# log of test accuracy
# 输出测试准确率
for images_test, heatmaps, vectmaps in validation_cache:
lss, lss_ll, lss_ll_paf, lss_ll_heat, vectmap_sample, heatmap_sample = sess.run(
[total_loss, total_loss_ll, total_loss_ll_paf, total_loss_ll_heat, output_vectmap, output_heatmap],
feed_dict={q_inp: images_test, q_vect: vectmaps, q_heat: heatmaps}
)
average_loss += lss * len(images_test)
average_loss_ll += lss_ll * len(images_test)
average_loss_ll_paf += lss_ll_paf * len(images_test)
average_loss_ll_heat += lss_ll_heat * len(images_test)
total_cnt += len(images_test)
logger.info('validation(%d) %s loss=%f, loss_ll=%f, loss_ll_paf=%f, loss_ll_heat=%f' % (total_cnt, args.tag, average_loss / total_cnt, average_loss_ll / total_cnt, average_loss_ll_paf / total_cnt, average_loss_ll_heat / total_cnt))
last_gs_num2 = gs_num
sample_image = [enqueuer.last_dp[0][i] for i in range(4)]
outputMat = sess.run(
outputs,
feed_dict={q_inp: np.array((sample_image + val_image) * max(1, (args.batchsize // 16)))}
)
pafMat, heatMat = outputMat[:, :, :, 19:], outputMat[:, :, :, :19]
sample_results = []
for i in range(len(sample_image)):
test_result = CocoPose.display_image(sample_image[i], heatMat[i], pafMat[i], as_numpy=True)
test_result = cv2.resize(test_result, (640, 640))
test_result = test_result.reshape([640, 640, 3]).astype(float)
sample_results.append(test_result)
test_results = []
for i in range(len(val_image)):
test_result = CocoPose.display_image(val_image[i], heatMat[len(sample_image) + i], pafMat[len(sample_image) + i], as_numpy=True)
test_result = cv2.resize(test_result, (640, 640))
test_result = test_result.reshape([640, 640, 3]).astype(float)
test_results.append(test_result)
# save summary
summary = sess.run(merged_validate_op, feed_dict={
valid_loss: average_loss / total_cnt,
valid_loss_ll: average_loss_ll / total_cnt,
valid_loss_ll_paf: average_loss_ll_paf / total_cnt,
valid_loss_ll_heat: average_loss_ll_heat / total_cnt,
sample_valid: test_results,
sample_train: sample_results
})
if last_log_epoch2 < curr_epoch:
file_writer.add_summary(summary, curr_epoch)
last_log_epoch2 = curr_epoch
saver.save(sess, os.path.join(modelpath, args.tag, 'model'), global_step=global_step)
logger.info('optimization finished. %f' % (time.time() - time_started))上面就是真正的训练了,不想解释了,懒,后续我会将带有注释的源码上传,你们自己看吧。下一将,就分析怎么使用这个网络。
如果您感觉本篇博客对您有帮助,请打开支付宝,领个红包支持一下,祝您扫到99元,谢谢~~
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









