







 本文深入探讨了最大最小值归一化与L2范数归一化两种常见数据预处理方法的特点。最大最小值归一化针对数据集的特征维度进行调整,保持数据分布信息;L2范数归一化则能将样本分布于超球表面,保留原始特征向量间的位置关系。
本文深入探讨了最大最小值归一化与L2范数归一化两种常见数据预处理方法的特点。最大最小值归一化针对数据集的特征维度进行调整,保持数据分布信息;L2范数归一化则能将样本分布于超球表面,保留原始特征向量间的位置关系。
最大最小值归一化和L2范数归一化是很常用的两种数据预处理方法,本文总结了这两种方法的一些特点。
1、最大最小值归一化
一般而言,归一化是针对于数据集中某个特征维度进行的,在sklearn中,数据的组织形式为[n_samples,n_features],最大最小值归一化的定义如下。
之所以要按照不同特征维度进行归一化,是因为如果将每个样本进行最大值最小值归一化,数据的分布信息将会丢失。
2、L2范数归一化
L2范数归一化可以将每一个样本归一化,也可以将所有样本的各个维度进行归一化,在sklearn中提供了一个归一化的方法
sklearn.preprocessing.normalize(X, norm=’l2’, axis=1, copy=True, return_norm=False)
该方法默认使用的axis=1,也就是说该方法默认是将每个样本进行了L2归一化,代码如下所示。
# encoding: utf-8
from sklearn.preprocessing import normalize
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(10)
data = np.random.randn(10,2)
plt.scatter(data[:,0],data[:,1],c="g")
data_n = normalize(data,norm="l2",axis=1,copy=True,return_norm=False)
plt.scatter(data_n[:,0],data_n[:,1],c="r")
plt.legend(["original","normalized"])
for i in range(len(data)):
v1 = np.linalg.norm([data[i][0],data[i][1]])
v2 = np.linalg.norm([data_n[i][0],data_n[i][1]])
if v1>v2:
x, y = data[i][0], data[i][1]
else:
x, y = data_n[i][0],data_n[i][1]
plt.plot([0,x],[0,y],"k")
theta = np.arange(0, 2*np.pi, 0.01)
cx = np.cos(theta)
cy = np.sin(theta)
plt.plot(cx,cy)
plt.show()结果如下图所示,其中绿色点是原始数据点,红色点是L2归一化之后的点,L2归一化之后的数据点全部落在了以原点为中心,半径为1 的圆周上,并且原始数据点和L2归一化之后的点以及原点共线。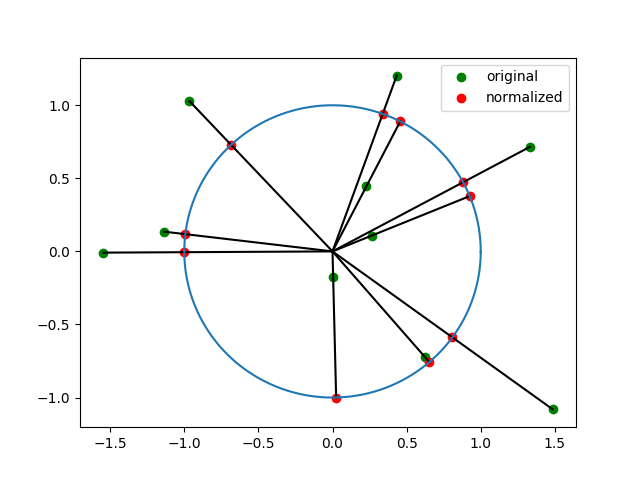
每个样本的L2范数为1,即样本分布在一个超球的表面,对于2维特征向量就是一个圆周。如果有两个样本点和原点共线,那么这两个样本L2范数归一化之后的结果相同。
如果将每个特征维度进行归一化,由于每个维度2范数归一化之后的值肯定会小于1,所以不管原来的特征向量值有多大,2范数归一化的特征向量都在一个半径为1的超球之内,并且可以保持原始特征向量之间的位置关系,代码和结果如下。
# encoding: utf-8
from sklearn.preprocessing import normalize
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(10)
data = np.random.randn(10,2)
plt.subplot(121)
plt.scatter(data[:,0],data[:,1],c="g")
data_n = normalize(data,norm="l2",axis=0,copy=True,return_norm=False) # 参数axis=0
plt.subplot(122)
plt.scatter(data_n[:,0],data_n[:,1],c="r")
plt.show()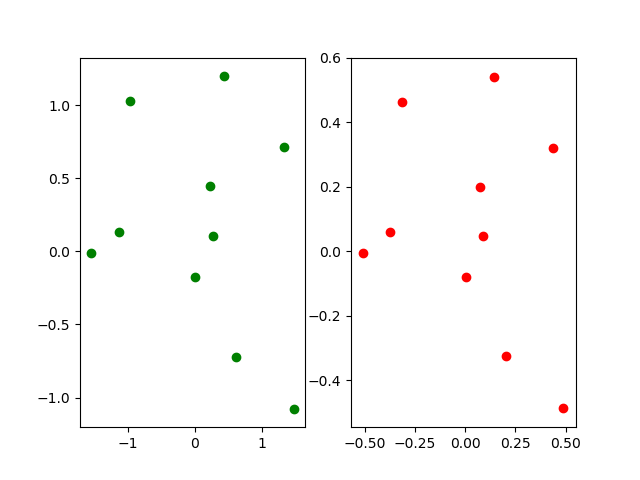
从上图可以看出对每个维度进行L2归一化之后,数据的整体分布没有改变,并且数据的正负性也没有改变,相比而言将样本的每一个维度归一化到[0,1]之后,每个维度都会出现极值0和1,相当于用一个超矩形(这个超矩形由每个维度的最大最小值形成),将这个超矩形移动缩放成每个维度都是[0,1]组成的超矩形。
3、总结与思考
-
对所有样本本身进行L2范数归一化,得到的归一化的样本点全部分布在一个以原点为中心,半径为1的超球体上。
- 对所有样本的同一个维度进行L2范数归一化,不会改变样本数值的正负性。而将样本的同一个维度归一化到[0,1]之后,样本所有的数值都变成了正数,测试集归一化之后可能会出现负值。(猜想:这个时候由于训练集中没有负值,那么模型的泛化性能就降低了?实际中有些时候归一化到[0,1]模型效果会更好些)。

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









