









首先看到这个题目,很多人的第一感觉就是使用 Random 随机类,循环生成随机数。也就是我原来写过的一篇文章java之生成不重复的随机数里面的代码,如下图:

这段代码可以生成size个begin到maxNum范围内的随机数,并且不会重复。看起来似乎没有什么问题,仔细审题就会发现题目是要求稳定的时间复杂度的。那么上图中的代码的隐患就在于Random 中的 nextInt 方法,如果它循环时多次产生重复的随机数,就会导致它的时间复杂度不是稳定的。
现在问题发现了,那么我们如何解决呢?很显然,nextInt 方法是jdk中的代码,而且它作为随机数的生成,从概率上讲,循环时多次生成相同的随机数理论上来说也是合理的。所以我们必须要换一种思维方式,不能以随机数为主,只能以随机数为辅。
1.随机打乱法
public class TestRandom {
public static void main(String[] args) {
System.out.println(getRandomNum(5,100));
}
public static List<Integer> getRandomNum(int start, int end){
List<Integer> list=new ArrayList<>();
for(int i=start+1;i<end;i++){
list.add(i);
}
Random random=new Random();
for(int i=list.size()-1;i>0;i--){
int num=list.get(i);
int randomIndex=random.nextInt(i);
int randomNum=list.get(randomIndex);
list.set(i,randomNum);
list.set(randomIndex,num);
}
return list;
}
}这种方式是从侧面使用了随机数:先将指定范围内的数据存到 List 中,然后倒序遍历,将每一个数据随机和前面的数据交换。
这个方法没有使用Random生成随机数,而是先生成指定范围内的数字,然后通过随机的方式将数字打乱,因为这里是随机产生的下标randomIndex,并且将下标上的值和数组末尾的值进行交换,所以即使随机多次生成重复的下标,此下标上的值也是不一样的,解决了上述循环时多次产生重复的随机数导致时间复杂度不稳定的问题,从而达到题目的要求。
这个方法的思路其实和快排的思路很类似,算是一个快排变种的思路,快排是在原数组中比较得到有序的数组,这种方式是在原数组中打乱原有的数据,从而得到期望的随机数。都是在原有的空间上做操作得到期望的结果,保证了空间复杂度的稳定。
2.随机删除法
public class TestRandom {
public static void main(String[] args) {
System.out.println(getRandomNumByDelete(5,10));
}
public static List<Integer> getRandomNumByDelete(int start, int end){
List<Integer> list=new ArrayList<>();
for(int i=start+1;i<end;i++){
list.add(i);
}
List<Integer> result=new ArrayList<>();
Random random=new Random();
for(int i=list.size();i>0;i--){
int randomIndex=random.nextInt(i);
result.add(list.remove(randomIndex));
}
return result;
}
}这个方案和第一个类似,还是先将指定范围内的数据存到 List 中,然后随机产生下标,从原List中删除,放到另一个List中即可。其实就相当于先将数据放到一个数组中,然后随机从这个数组将数据放到另一个数组中。这种方式由于List是一个动态数组,所以即使多次产生重复的随机数下标,也不会有什么影响。
这个方式理解起来相对会更简单点,唯一的问题是时间复杂度不稳定,因为每次随机删除数据,必然会导致其他数据的移动,无法保证其时间复杂度的稳定。当然咱们可以换个思路去解决这个问题
2.1 随机删除法时间复杂度稳定版
public class TestRandom {
public static void main(String[] args) {
System.out.println(getRandomNumByDelete(5,10));
}
public static List<Integer> getRandomNumByDelete(int start, int end){
List<Integer> list=new ArrayList<>();
for(int i=start+1;i<end;i++){
list.add(i);
}
List<Integer> result=new ArrayList<>();
Random random=new Random();
for(int i=list.size();i>0;i--){
int randomIndex=random.nextInt(i);
int data=list.get(randomIndex);
int tailData=list.get(i-1);
list.set(randomIndex,tailData);
list.set(i-1,data);
result.add(data);
}
return result;
}
}这段代码的改进就是换了一个思路,没有使用删除,而是将每次产生的随机下标 randomIndex 上的数和集合末尾的数据进行交换,然后将randomIndex上的数放到另一个数组中即可。这种方式你会发现其实和方案一是一样的,只不过是多了一个result来存放产生的随机数。所以若是生产使用,建议还是使用方案一。
这个思路其实和归并排序的思路类似,都需要额外的空间去得到结果。
扩展与发散:
你能想到的,别人也可以!方案一的这种思路在jdk中已经被实现了,Collections.shuffle() 就是这种思路,现在我们来看下它的源码实现:


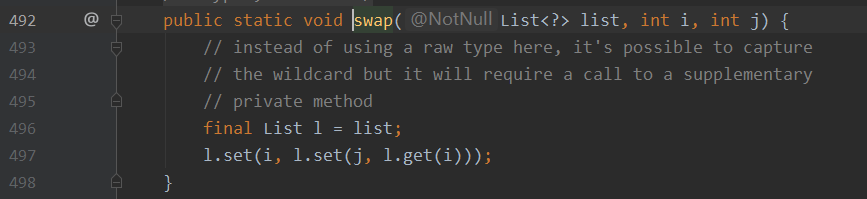
可以看到 shuffle 方法中的代码,其实和方案一的思路是一样的,就是先产生随机下标 rnd.nextInt(i) ,然后 swap 方法中将下标 i 和 下标 j 上的数据互换,这样就List集合中的数据打乱了,也就是随机生成的了,并且还可以保证其时间复杂度的稳定。所以生产上直接用Collections.shuffle()就可以了。
总结:
这道面试题的难点其实在于你是否能跳出当前的思维,去重新思考问题。那这道题随机数的生成就是随机的,循环产生重复的随机数虽然是小概率事件,但也依然存在。所以这道题的思路是先生成对应的数组数据,然后将里面的数据打乱,再获取对应的随机数即可。














 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









