







 内存伪共享是多线程并发场景中的性能问题,由共享同一缓存行的独立变量引起。当不同线程修改这些变量时,会导致缓存行频繁载入和剔除,降低性能。为避免伪共享,可以使用填充或跨区分配确保变量不位于同一缓存行。Java对象内存布局中,对象头和字段顺序会影响伪共享的发生,了解这些细节有助于进行性能优化。
内存伪共享是多线程并发场景中的性能问题,由共享同一缓存行的独立变量引起。当不同线程修改这些变量时,会导致缓存行频繁载入和剔除,降低性能。为避免伪共享,可以使用填充或跨区分配确保变量不位于同一缓存行。Java对象内存布局中,对象头和字段顺序会影响伪共享的发生,了解这些细节有助于进行性能优化。
博主注:在考虑优化多线程并发的内存使用场景时, 由于CPU缓存机制不尽相同, 建议至少确保有128字节距离, 一般通过设置不使用哑元(dummy)或者跨区分配来避免命中同一缓存行, 以减少不同处理器由于缓存行相同造成的缓存行频繁载入和剔除的性能消耗.
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局,或找个工具告诉我们。Intel VTune就是这样一个性能分析工具。本文中我将解释Java对象的内存布局以及我们该如何填充缓存行以避免伪共享。
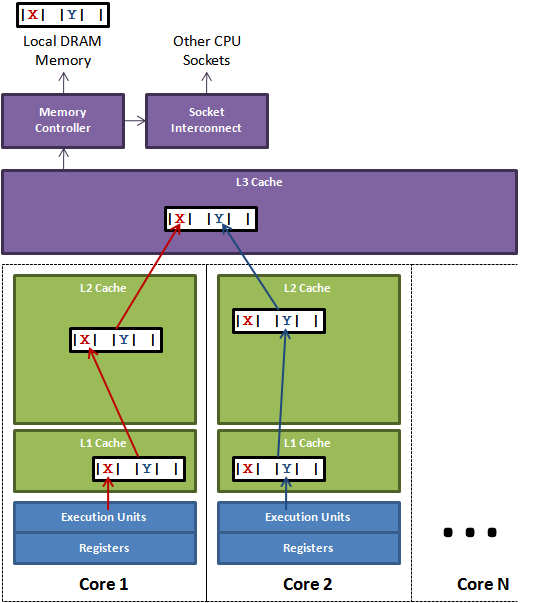
图1说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









