






荐语
本文要介绍的是 2021 年 O’Reilly 出版的书籍 Software Architecture: The Hard Parts(后文简称 SAHP),某种程度上,它是 Fundamentals of Software Architecture(后文简称 FSA)的延续,两本书的主要作者相同。FSA 是基础篇,重点介绍了常见的 8 种架构模式;SAHP 是进阶篇,重点介绍了如何从单体架构演进到分布式架构。
软件架构,特别是分布式架构,是很复杂的。这世上不存在所谓的通用架构模式,针对特定的应用场景,架构师需要在数据一致性、可扩展性、性能等多个因素上进行权衡,这也是本书标题强调的 The Hard Parts。
FSA 里有一句名言,“Everything in software architecture is a trade-off.”。本书的重点就是要教会你,在单体架构演进到分布式架构的过程中,如何众多因素上进行权衡分析,以此来选择出一个符合实际业务场景的软件架构。
为什么叫 “The Hard Part”?
书的名字叫 Software Architecture: The Hard Parts,其中,Hard 有两层含义。
第一,软件架构很难。设计软件架构需要考虑的因素很多,架构师也必然会遇到各式各样的难题,而且它们往往没有通用的解决方法。软件工程的问题,很多时候可以通过 Google 搜索来解决;而软件架构的问题,只能根据实际的业务场景,在众多的考虑因素上进行权衡。所以,在软件架构上,不要试图找到最好的设计,而是要努力实现最不糟糕的权衡组合。
Don’t try to find the best design in software architecture; instead, strive for the least worst combination of trade-offs.
第二,软件架构是稳定的。Hard 取自于硬件的英文单词 Hardware,相比软件 Software,硬件是更稳定的一个,它是软件的基础。同理,软件架构是一款软件的架子、基础,好的架构通常都是稳定的,不轻易随软件的变更而变化。
SAHP 从内容上分成 2 大部分,第一部分讲拆分,如何拆分服务、数据,服务拆分的粒度如何控制等;第二部分讲协作,功能如何复用、工作流如何编排、分布式事务如何实现等。
软件架构的“UT”(Fitness Function)
我们通常会为程序编写单元测试 UT,防止因代码修改导致不在预期内的功能变化。UT 会集成到 CICD 流水线上,在构建阶段就能够拦截代码 Bug。
软件架构是易腐化的,特别是多人协作开发时,稍不注意就会向“大泥球”方向演进。因此,软件架构也需要“UT”,书中把它称为 Fitness Function。Fitness Function 也会集成到 CICD 流水线上,因此架构师就能及时清除架构的腐化,并阻止它。
这里是一个防止循环依赖的 Fitness Function 的例子:
public class CycleTest {
private JDepend jdepend;
@BeforeEach
void init() {
jdepend = new JDepend();
jdepend.addDirectory("/path/to/project/persistence/classes");
jdepend.addDirectory("/path/to/project/web/classes");
jdepend.addDirectory("/path/to/project/thirdpartyjars");
}
@Test
void testAllPackages() {
Collection packages = jdepend.analyze();
assertEquals("Cycles exist", false, jdepend.containsCycles());
}
}
架构量子(Architecture Quantum)
作者提出了架构量子(Architecture Quantum)的概念。量子在物理学中指参与基本相互作用的任何物理实体的最小量;架构量子则是指在软件架构中能够独立部署的最小集合。书中定义如下:
An architecture quantum is an independently deployable artifact with high functional cohesion, high static coupling, and synchronous dynamic coupling.
提起独立部署的最小集合,大家可能最先想到的是服务,但架构量子还需要把服务所依赖的数据库、UI 等考虑进来。
最典型的,单体架构的架构量子数量就是 1,如下图所示:
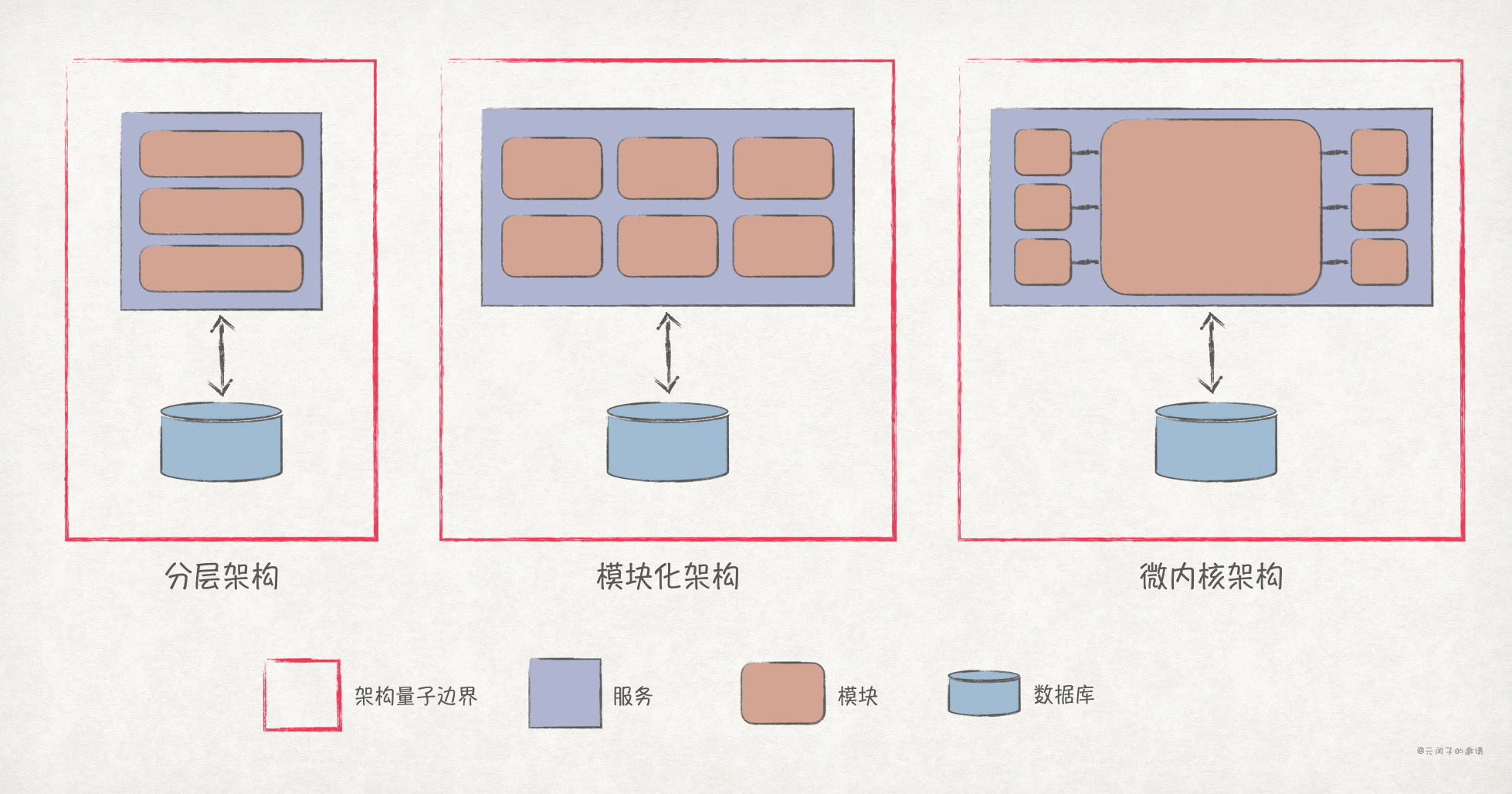
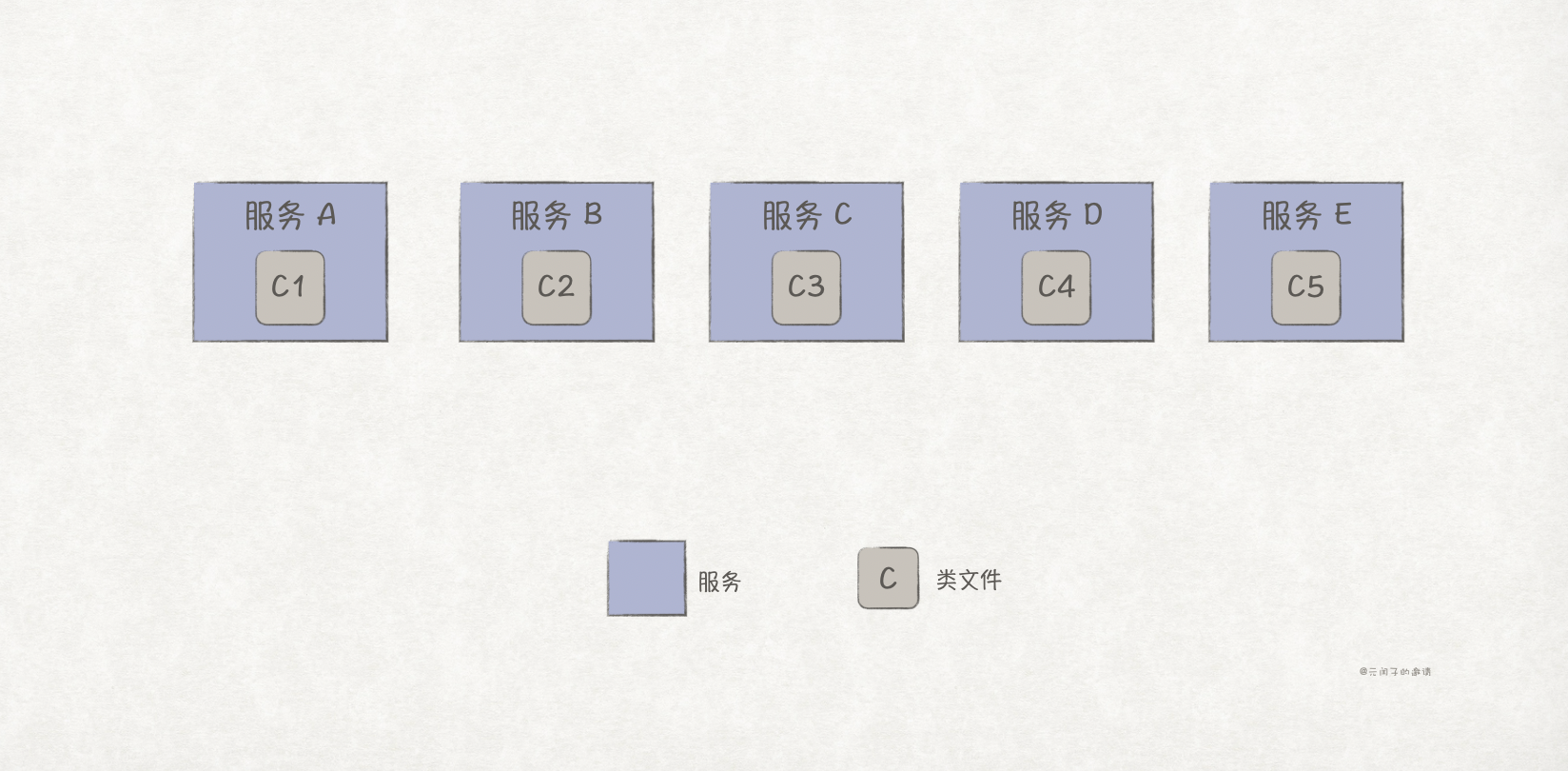
另一个典型,微服务架构的架构量子数量为 n,其中 n 为微服务数量,如下图所示:

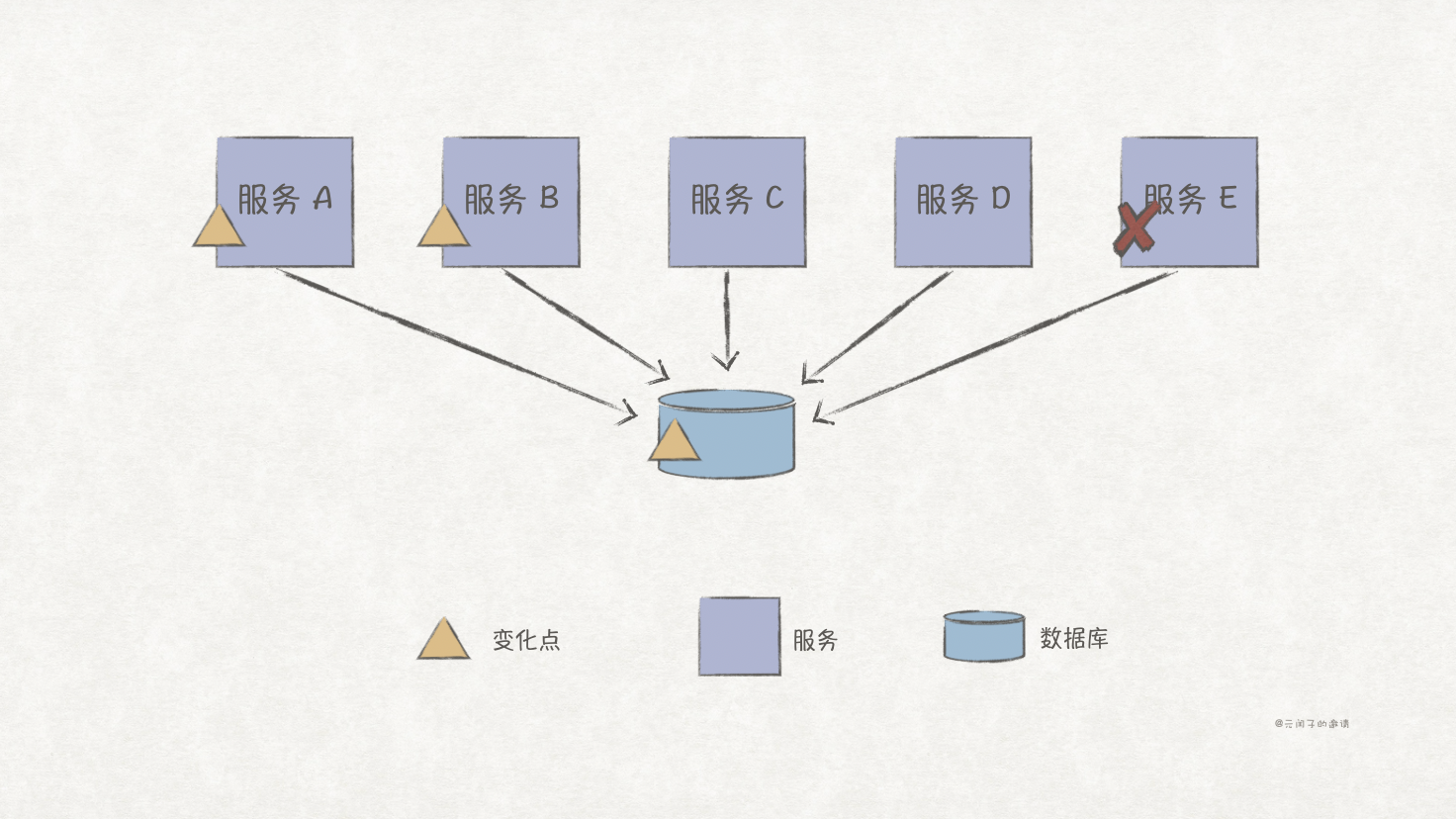
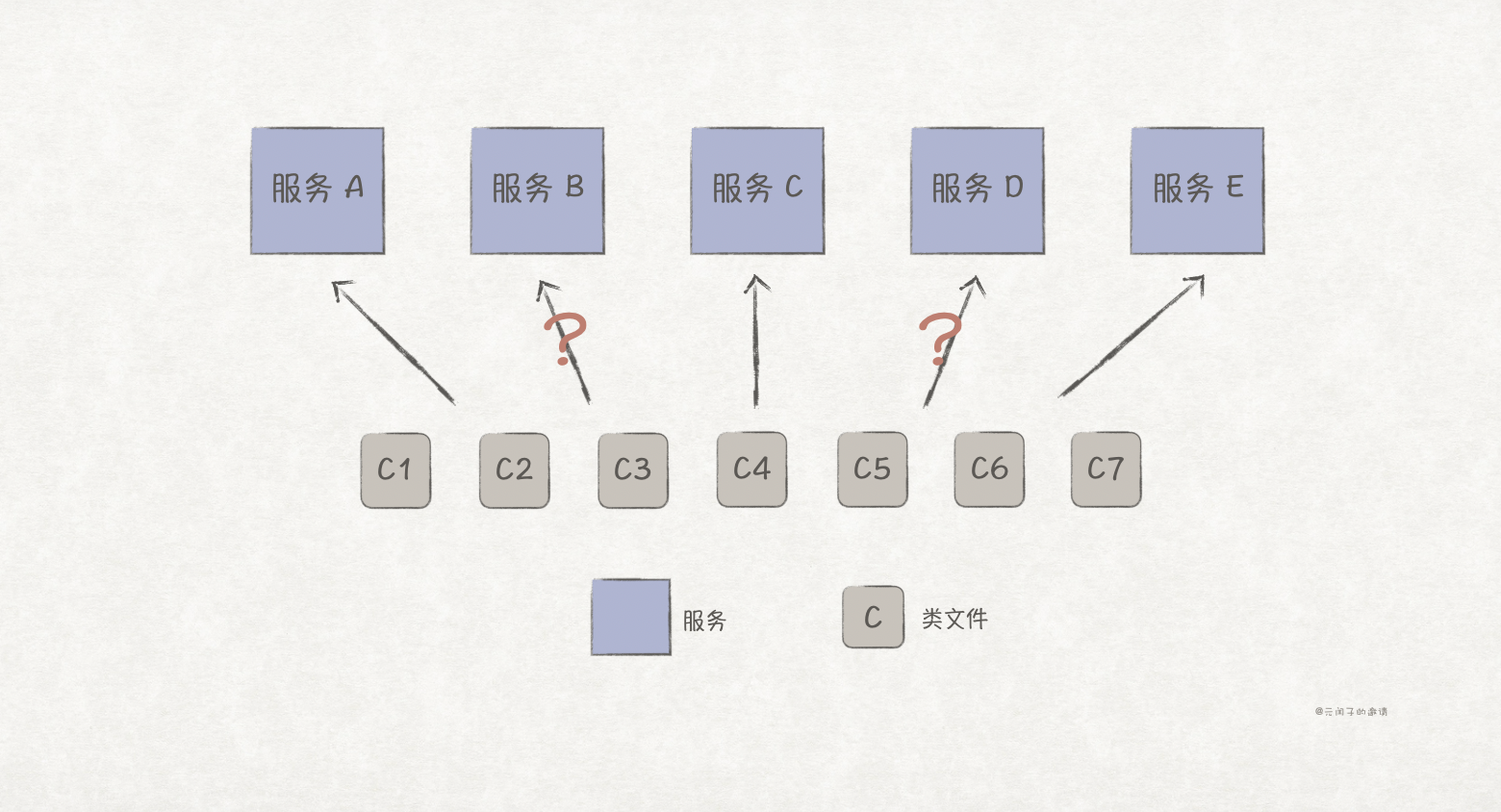
微服务架构是典型的分布式架构,但分布式架构的架构量子并不一定都为 n,比如服务化架构,虽然有多个服务,但它们依赖同一数据库。现假设服务 A 对数据表做了升级,因而重新部署;那么依赖同一张表的服务 B 也因适配新数据表而重新部署。所以,服务 A 和 服务 B 并不具备独立部署的性质,如下图所示:

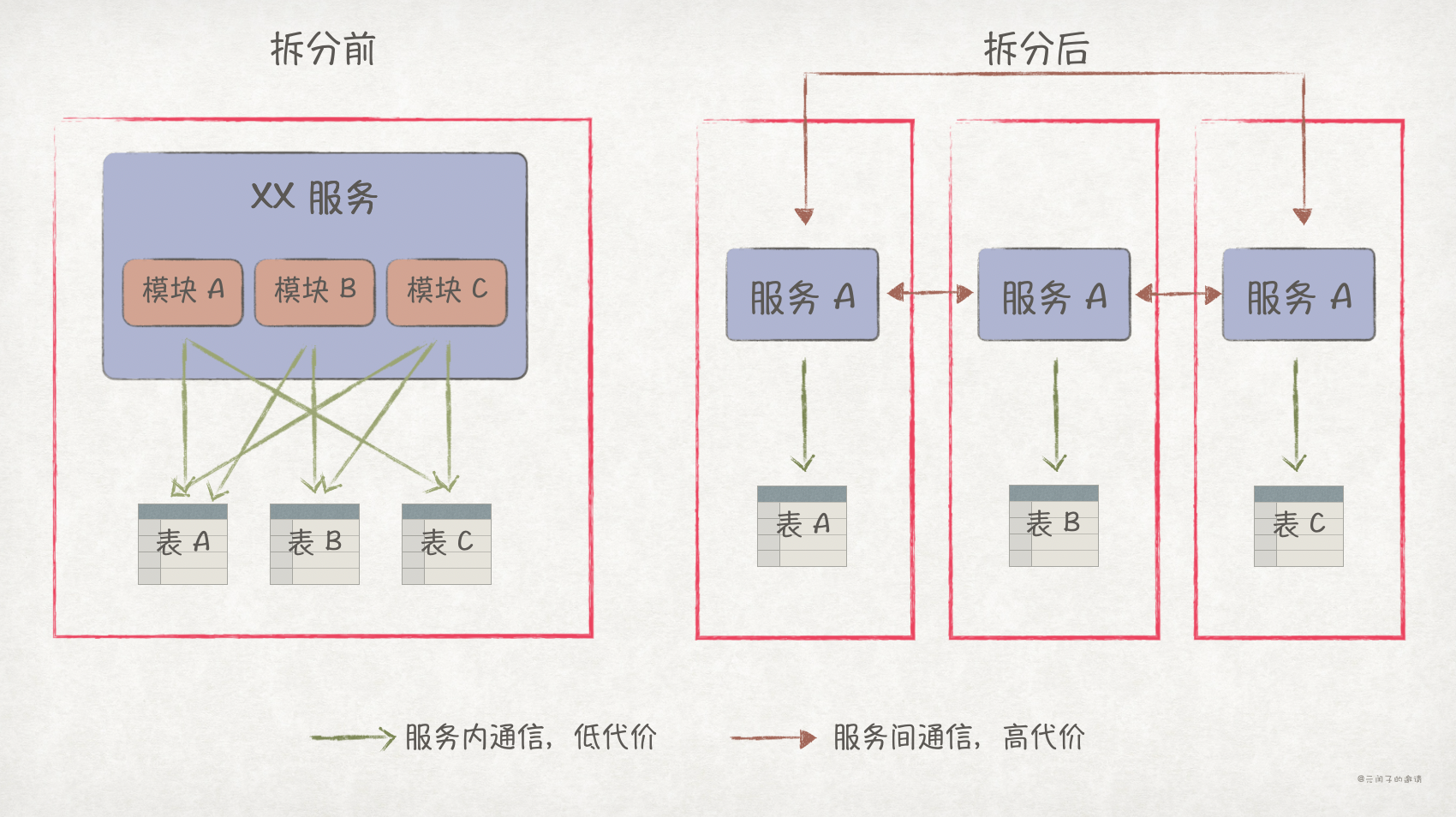
拆分
软件中的耦合
服务拆分一般可以依据以下 3 个步骤:
- 找到软件中哪些模块耦合在一起。
- 分析清楚它们是如何耦合在一起的。
- 评估改变它们的耦合关系对系统的影响,并对影响进行权衡分析,得出最终的拆分方式。
书中对耦合的定义如下:
Two parts of a software system are coupled if a change in one might cause a change in the other.
也即如果 A 的变化可能会导致 B 也跟着变,那么 A 和 B 就是耦合的。作者认为,耦合有两种:
- 静态耦合(Static coupling)。常见于单体架构中,比如软件对操作系统、编程框架、静态库/动态库等的依赖。静态耦合通常发生在编译时,在架构量子的边界之内。
- 动态耦合(Dynamic coupling)。常见于分布式架构中,比如服务间通信、工作流、分布式事务等。
然而,耦合在软件系统中是必然存在的,它不应该是驱动拆分的主要因素。
驱动服务拆分的因素
清晰的业务述求是拆分的唯一驱动力,好的软件,必然是敏捷的、能够快速响应市场需求、具备竞争力的优势,映射到软件架构语言上,主要是软件的可维护性(Maintainability)、可测试性(Testability)、可部署性(Deployability)、可扩展性(Scalability)和可用性(Availability)。

可维护性
可维护性(Maintainability)指在软件中新增/改变/删除特性的容易程度,可维护性越高,就越能拥抱变化。相比于分布式架构,单体架构的可维护性更差,新需求会导致整个系统的变更,这显然无法满足敏捷的要求。

可测试性
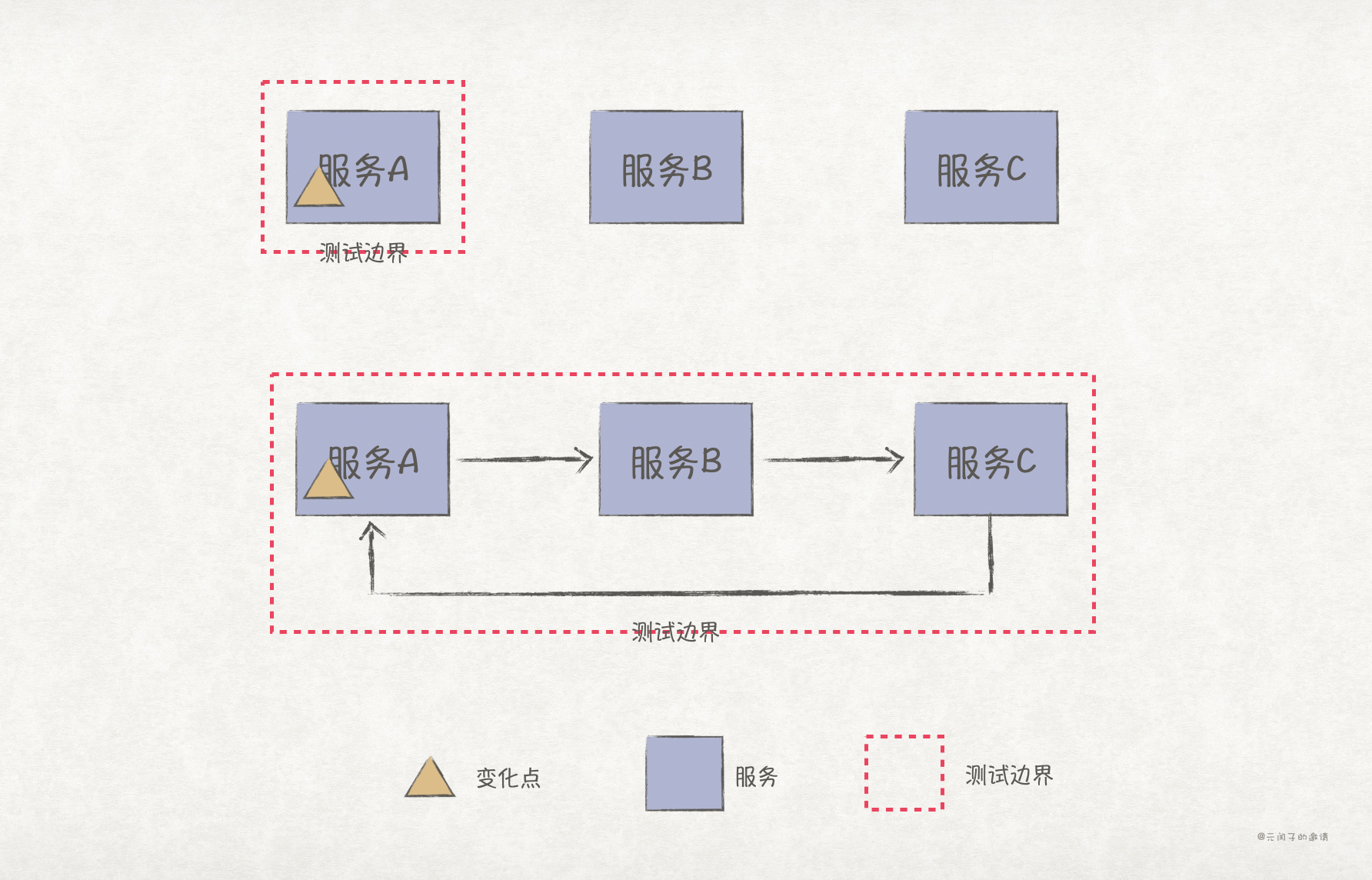
可测试性(Testability)指软件中完成自动化测试的容易程度。假设应用的测试集是固定的。如果采用单体架构,每次变更上线都必须执行一次全量的测试用例;如果是分布式架构,因为已经按业务领域进行了服务拆分,当某个领域服务变更上线时,只需执行该领域的测试用例即可,测试时长和范围大大减少。
当然,如果变更内容涉及服务间通信,如 API 接口变更,那么相关的服务的用例都需要重新执行。
可部署性
可部署性(Deployability)不仅是软件部署的容易程度,还包含部署的频率以及部署对系统的影响。跟可测试性类似,单体架构下,每次变更都会导致系统的重新部署;分布式架构下,只有实际变更的服务才需重新部署,因而新特性导致系统不可用的风险会更低。同理,如果服务拆分粒度太细,服务间的通信、分布式事务等动态耦合也会使得部署风险的提升。
可扩展性
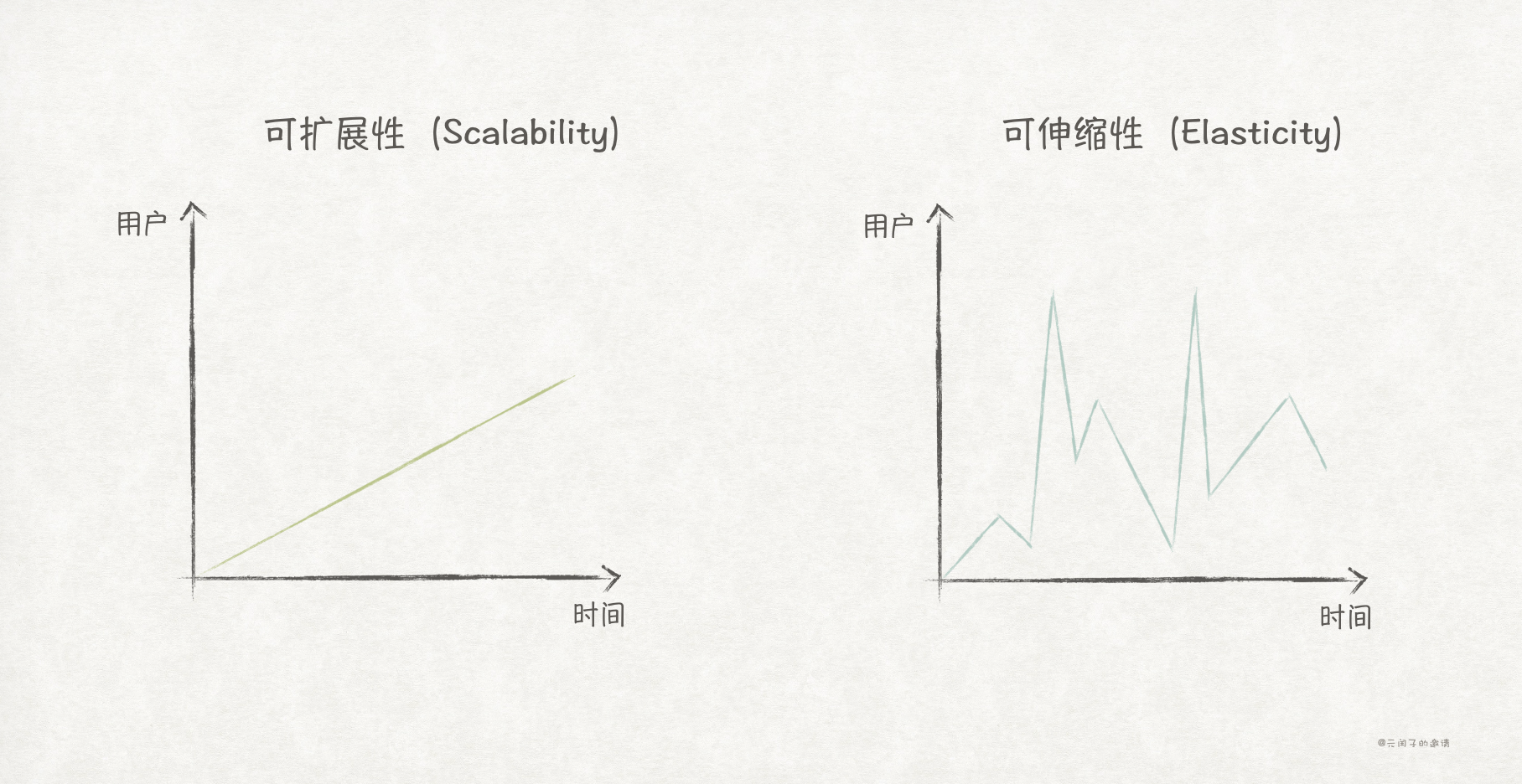
可扩展性(Scalability)指在用户负载逐步上升时,系统仍然能够快速响应的能力。另一个容易混淆的性质是可伸缩性(Elasticity),指系统在面临瞬间高峰负载时仍然能够快速响应的能力。
可用性
可用性(Availability)指系统在部分异常时能够保持服务不中断的能力。单体架构可用性很低,多实例部署并不能应对程序 Bug 导致的可用性问题;分布式架构下,如果服务间动态耦合较深, 可用性一样会很低。
服务拆分方法论
书中介绍了 2 种服务拆分方法,Component-Based Decomposition 和 Tactical Forking。前者基于组件进行拆分,适用于代码结构划分清晰的单体架构;后者则是做减法,不断删除不想要的代码,适用于代码结构模糊的单体架构。
基于组件的拆分(Component-Based Decomposition)
组件(Component)被定义为应用中具备特定角色和职责的构建块(building block),通常在编程语言中以命名空间或者目录的形式组织。比如,在下图目录结构中,命名空间 penultimate.ss.ticket.assign 就表示 Ticket Assign 组件。

值得注意的是,组件下只包含文件,上图中 assign 为组件,而 ticket 为 子领域(subdomain)。
基于组件进行服务拆分可以分成 6 步走,书中把每一步总结成一个模式,整体的 roadmap 如下:
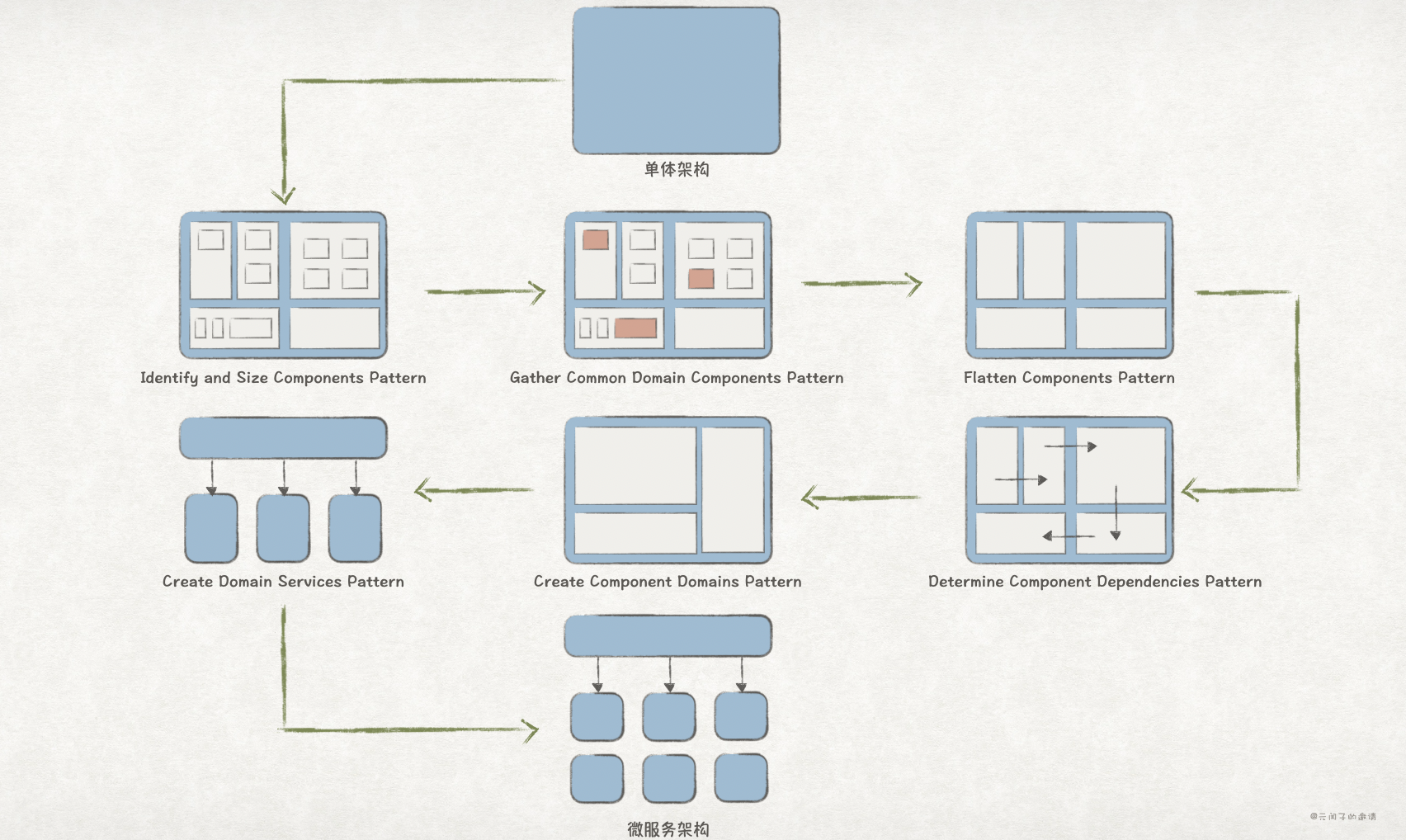
明确组件及其大小模式(Identify and Size Components Pattern)
第一步,明确系统中的组件,及其大小。组件的定义如前文所述,那么组件的大小如何判定呢? 组件内包含的文件数量?类的数量?代码行数?书中给的建议是语句(statement)的数量,在编程语言中,语句通常以特殊的字符结束,比如在 Java 或 C/C++ 中以分号 ; 结束。从语句数量的多少,大概就能够看出该组件的职责有多少,以及它的复杂程度。
在进行这一步的分析时,建议按照如下的表格把当前的组件梳理清楚:
| 组件名 | 组件命名空间 | 语句数量占比 | 语句数量 | 文件数量 |
|---|---|---|---|---|
| Login | ss.login | 2% | 1865 | 3 |
| Billing Payment | ss.billing.payment | 5% | 4,312 | 23 |
| Billing History | ss.billing.history | 4% | 3,209 | 17 |
| Reporting | ss.reporting | 33% | 27,765 | 162 |
| Ticket | ss.ticket | 8% | 7,009 | 45 |
| Ticket Assign | ss.ticket.assign | 9% | 7,845 | 14 |
| … | … | … | … | … |
这样,我们就能对当前系统组件的情况一目了然,比如上表中 Reporting 组件显然是一个大组件,需要重点审视是否需要拆分。
聚合公共领域组件模式(Gather Common Domain Components Pattern)
第二步,识别属于公共领域的组件,把它们整合到一起,方便后面能够快速拆分出公共服务。
比如下述的例子,Customer Notification、Ticket Notify 和 Survey Notify 三个组件都属于通知领域,那么我们就可以把它们整合到一起。
| 组件 | 命名空间 | 职责 |
|---|---|---|
| Customer Notification | ss.customer.notification | 通用通知 |
| Ticket Notify | ss.ticket.notify | 票务业务通知 |
| Survey Notify | ss.survey.notify | 调查问卷业务通知 |
整合之后的组件如下,后续就能基于该组件拆分出一个通知服务了。
| 组件 | 命名空间 | 职责 |
|---|---|---|
| Notification | ss.notification | 包含通用通知、票务通知、调查问卷通知等公共通知的能力 |
组件扁平化模式(Flatten Components Pattern)
第三步,避免组件与类文件在同一层级下,比如下图中,.survey 子领域下既有类文件,又有组件 .templates。
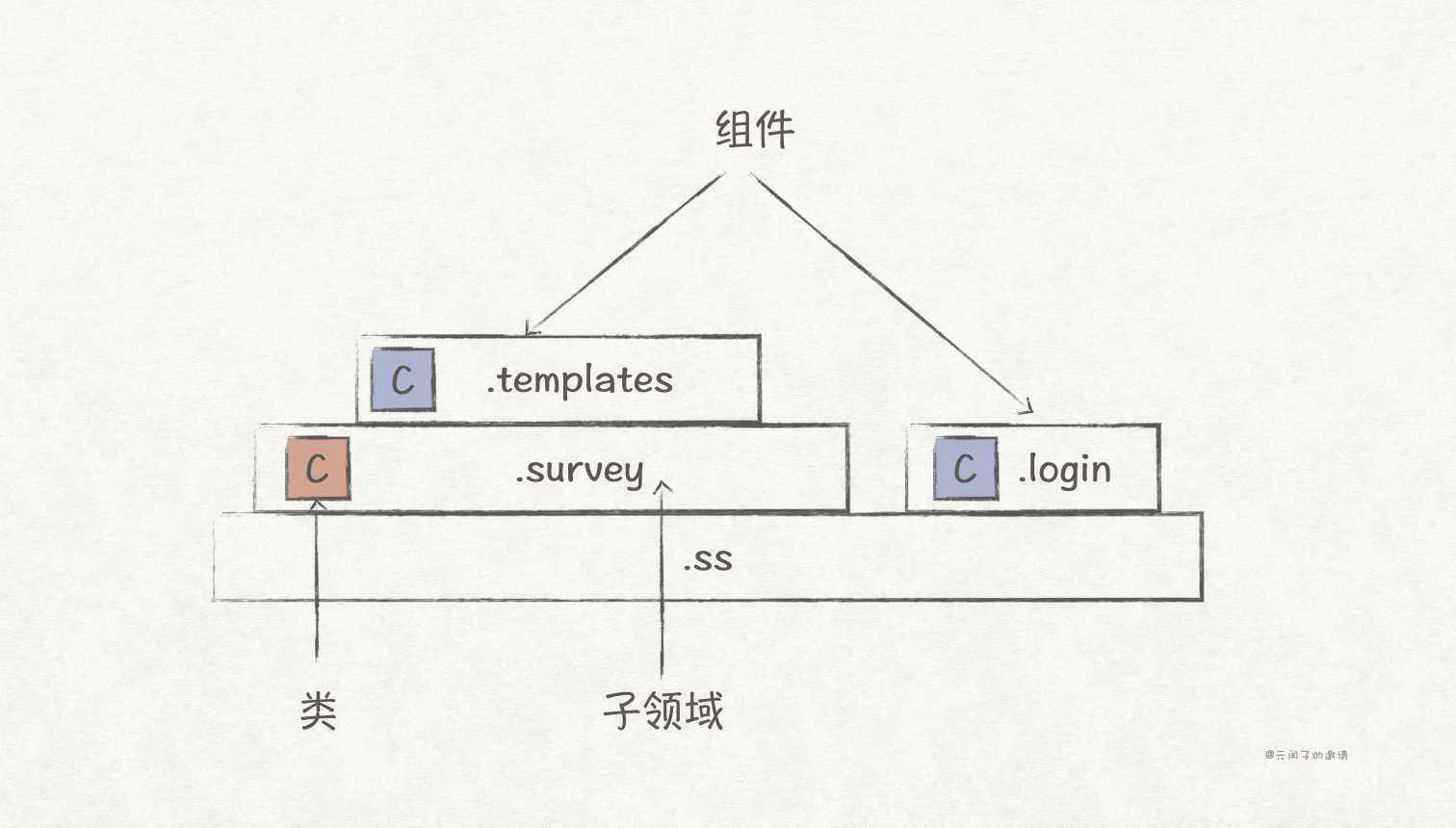
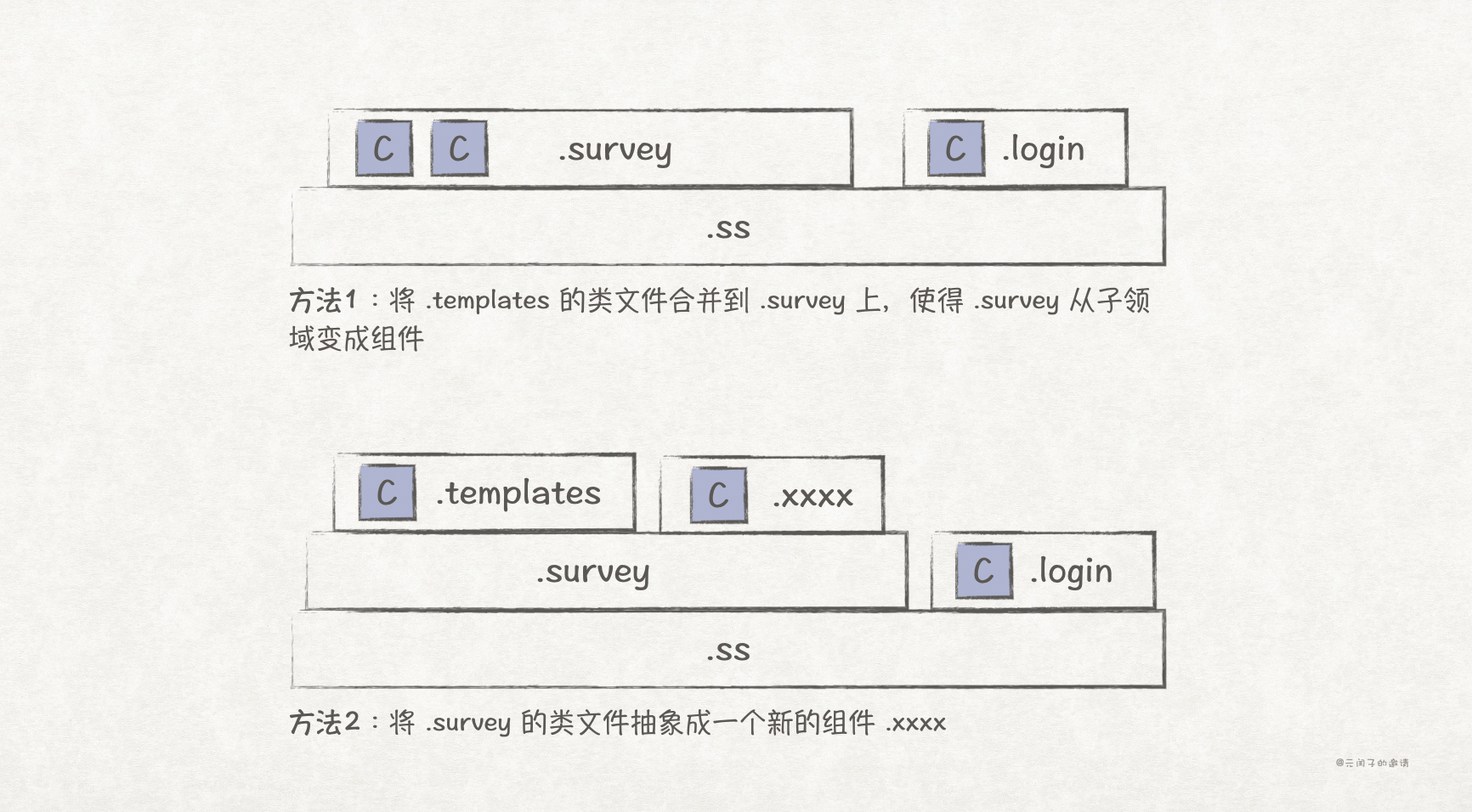
针对这种方向,我们有 2 种扁平化解决方案。(1)将 .templates 组件合并到 .survery 组件下;(2)将 .survery 子领域下的类文件抽象成新的组件。
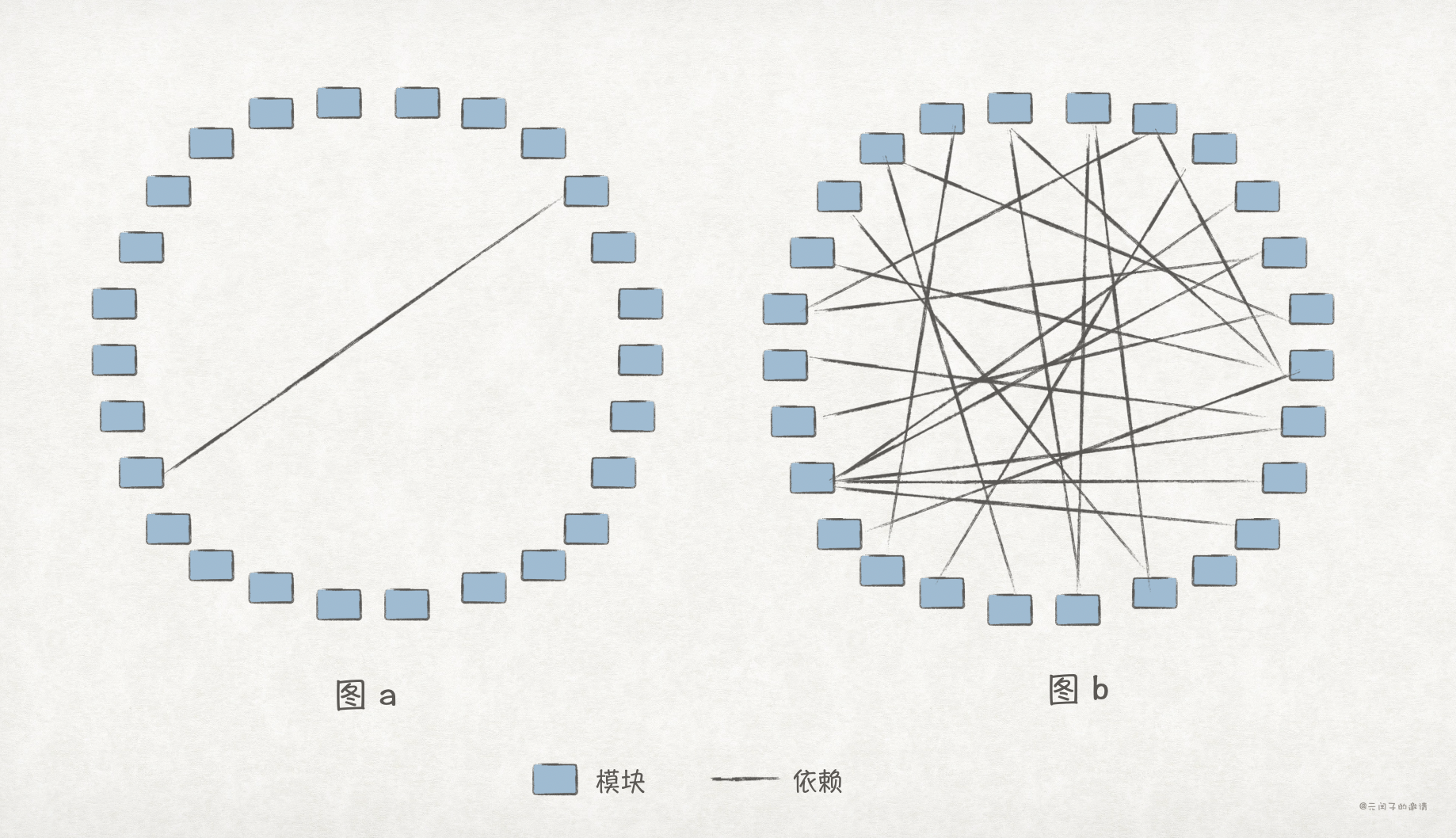
明确组件依赖关系模式(Determine Component Dependencies Pattern)
第四步,明确组件间的依赖关系。当组件 A 中引用了组件 B 中的类/接口/方法/变量时,我们称组件 A 依赖组件 B。明确组件间依赖能够让我们清楚拆分的代价。
比如,在下图 a 中的依赖关系下,拆分是低代价的,可能只须进行简单的代码重构,就能顺利地完成拆分;而在图 b 的依赖关系下,拆分的代价变得高昂,须要对代码进行大规模的重写,才可能完成拆分。
聚合领域组件模式(Create Component Domains Pattern)
第五步,尽可能地将组件归属到同一领域之下,这样就能够拆分出粒度较大的服务。这样做的原因是,从单体架构演进到分布式架构时,演进的第一步建议是服务化架构(service-based architecture),然后再到其他架构,如微服务架构。
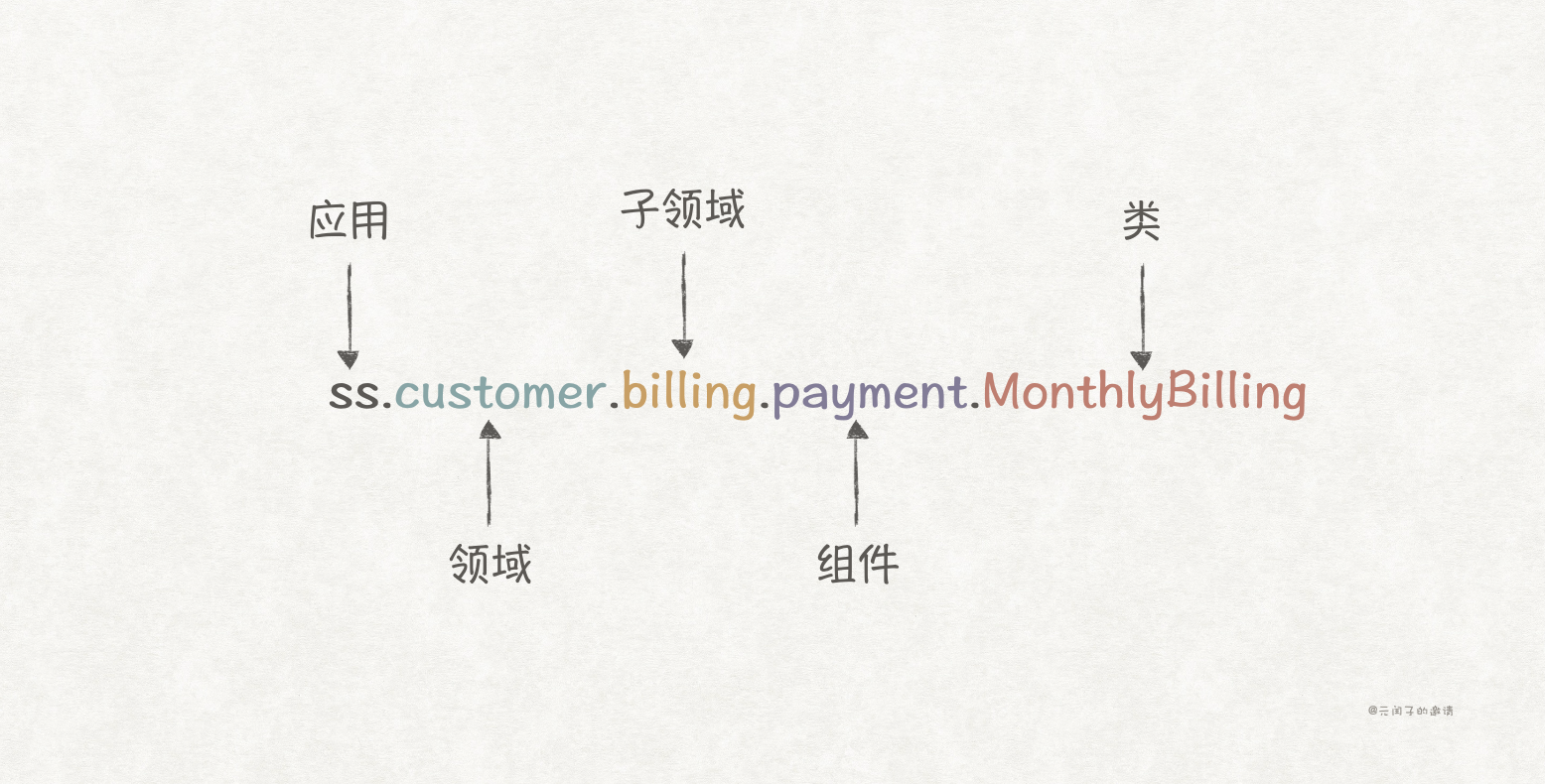
在实践该模式前,先了解命名空间的组成,以 ss.customer.billing.payment.MonthlyBilling 为例,它的各层级含义如下:
假设有如下组件:
| 组件 | 命名空间 |
|---|---|
| Billing Payment | ss.billing.payment |
| Billing History | ss.billing.history |
| Customer Profile | ss.customer.profile |
| Support Contract | ss.supportcontract |
因为上述组件从业务功能上看都属于 Customer 领域,那么,我们可以把这些组件都归到 customer 命名空间下:
| 组件 | 命名空间 |
|---|---|
| Billing Payment | ss.customer.billing.payment |
| Billing History | ss.customer.billing.history |
| Customer Profile | ss.customer.profile |
| Support Contract | ss.customer.supportcontract |
创建领域服务模式(Create Domain Services Pattern)
经过前 5 步之后,我们可以得到功能内聚的领域了,最后一步就是将这些领域拆分成独立的服务。
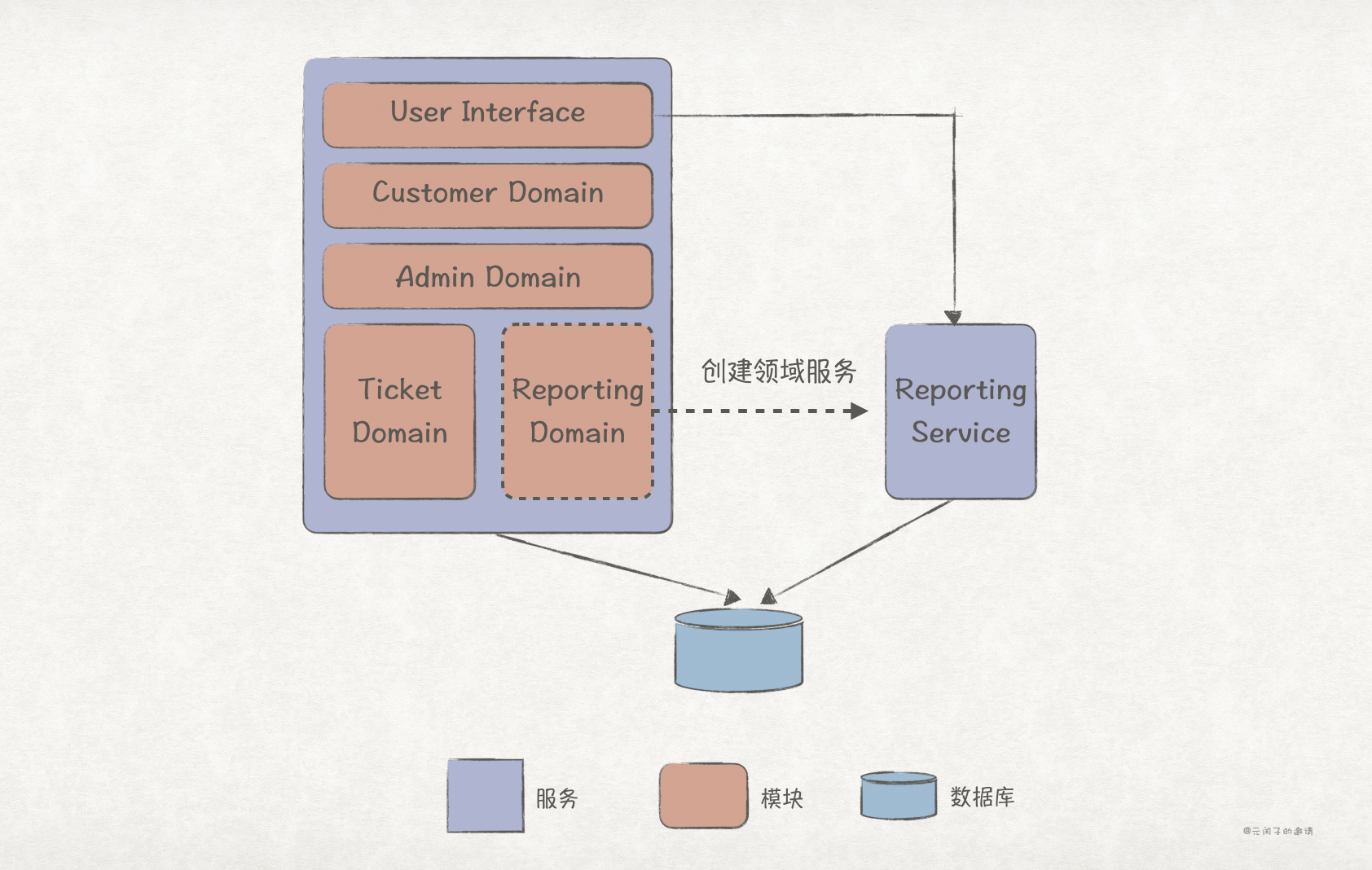
Tactical Forking
Component-Based Decomposition 的拆分思路可以看成是抽取(Extraction),而 Tactical Forking 则是删除(Deletion),删除你不想要的代码,直至达成拆分目的。
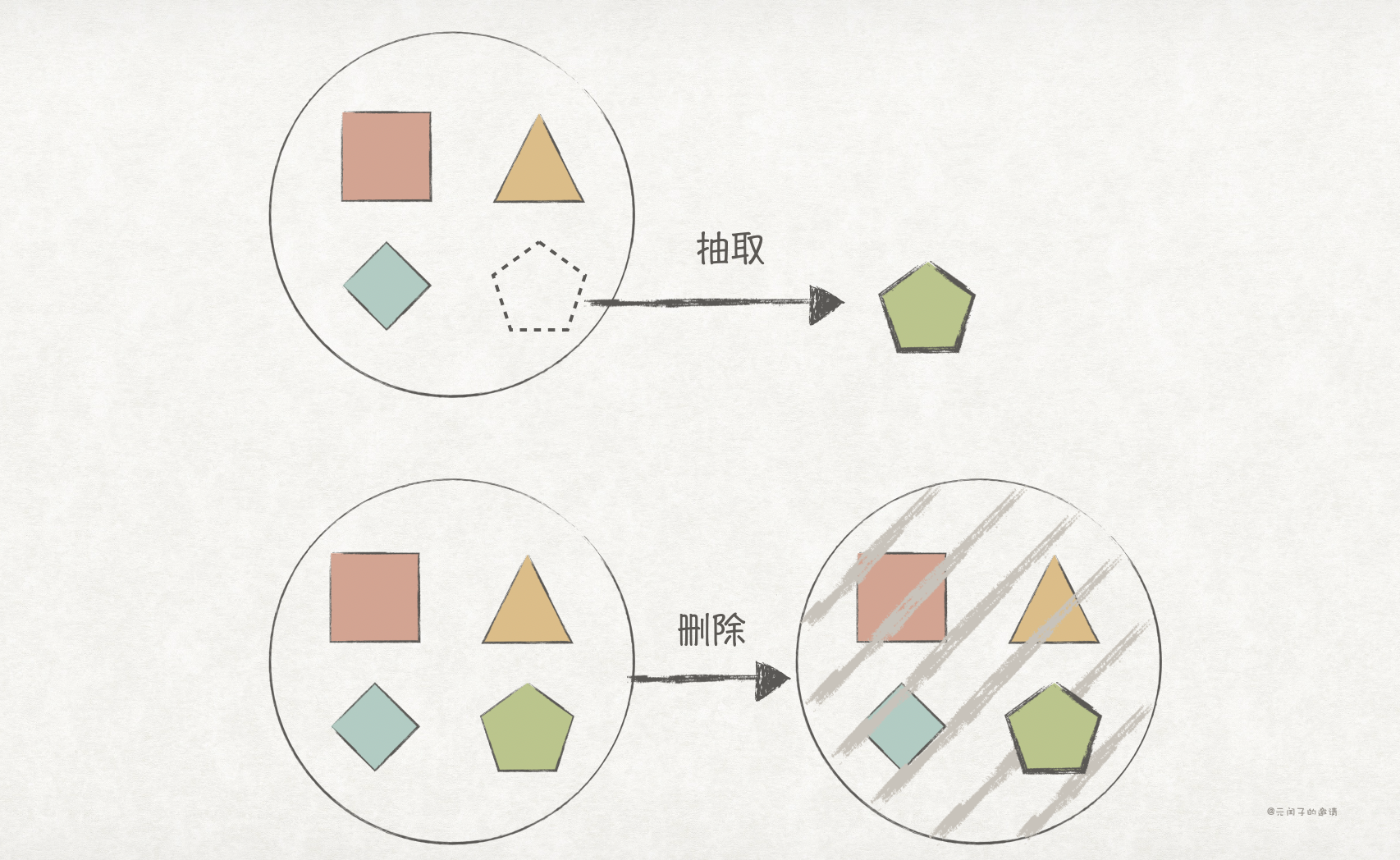
假设有一应用,包含 3 个模块,现需要对应用拆分成 2 个服务,分别由 2 个团队来负责维护。其中,团队 A 负责正方形和棱形;团队 B 负责三角形。

那么,采用 Tactical Forking 进行服务拆分的步骤如下:
- 复制整个应用,这样每个团队都各自拥有一份应用代码。
- 各团队分别删除不需要的代码模块,这里,团队 A 逐渐删除三角形代码、团队 B 逐渐删除正方形和棱形代码。
- 反复执行删除操作,直至完成拆分。

Tactical Forking 的优势在于落地简单,无须过多的前置分析,且删除代码总比抽取模块要容易得多;缺点也很明显,一方面剩余的代码没经过优化依旧是“大泥球”,另一方面可能会导致两个团队间存在重复的代码。
驱动数据拆分的因素
通过前文所述的服务拆分方法论,我们已经成功将单体架构应用拆分成服务化架构应用,但各服务之间仍然共享一个数据库,数据需要进行拆分吗?
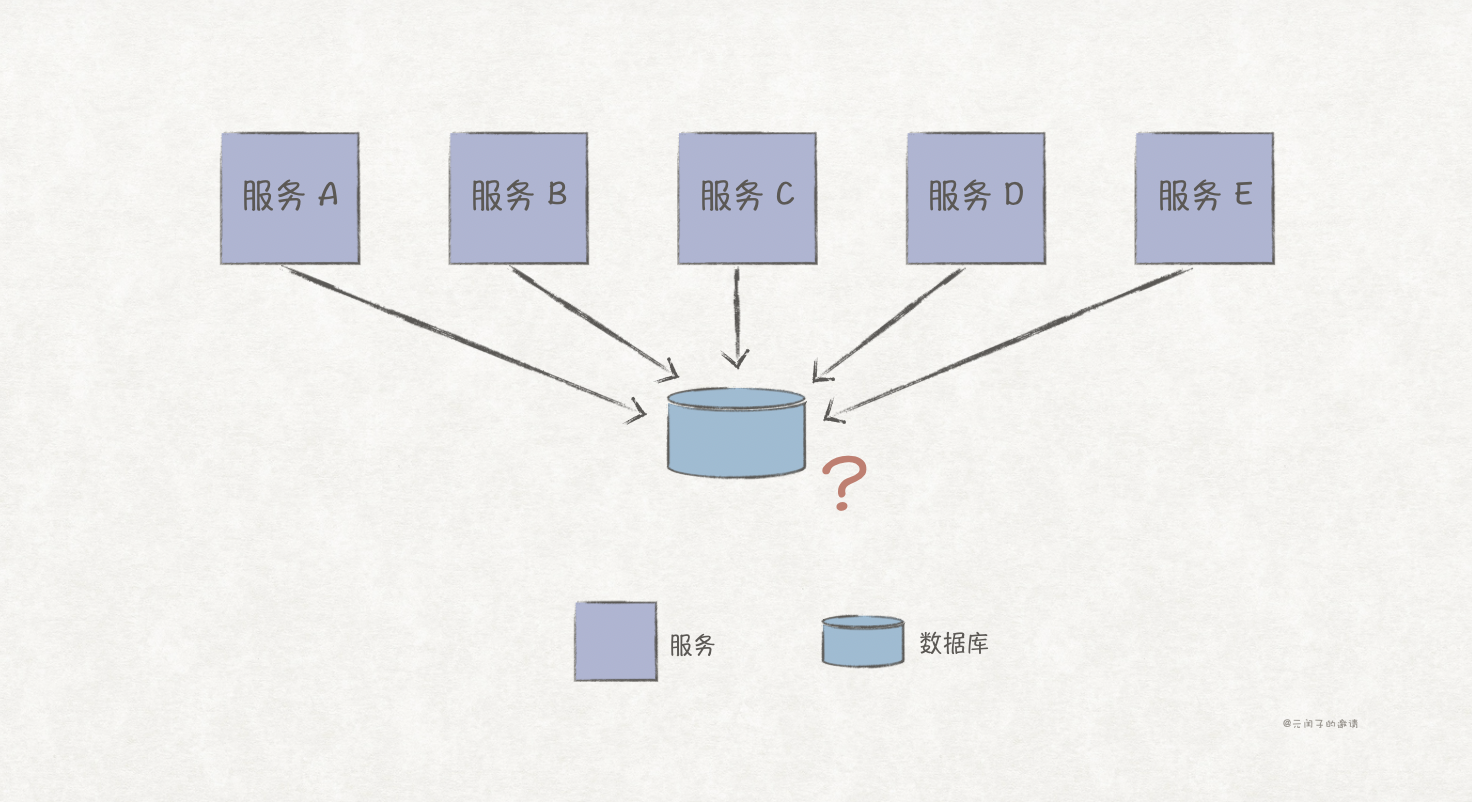
驱动数据拆分的因素主要有 6 个,分别是变更影响范围、数据库连接数、可扩展性、容错性、架构量子以及数据库类型的选择。
变更影响范围
服务化架构下,可能会存在多个服务依赖同一数据表的情况,这时如果该数据表做了变更,比如列名修改,那么依赖此表的服务都要进行变更升级。
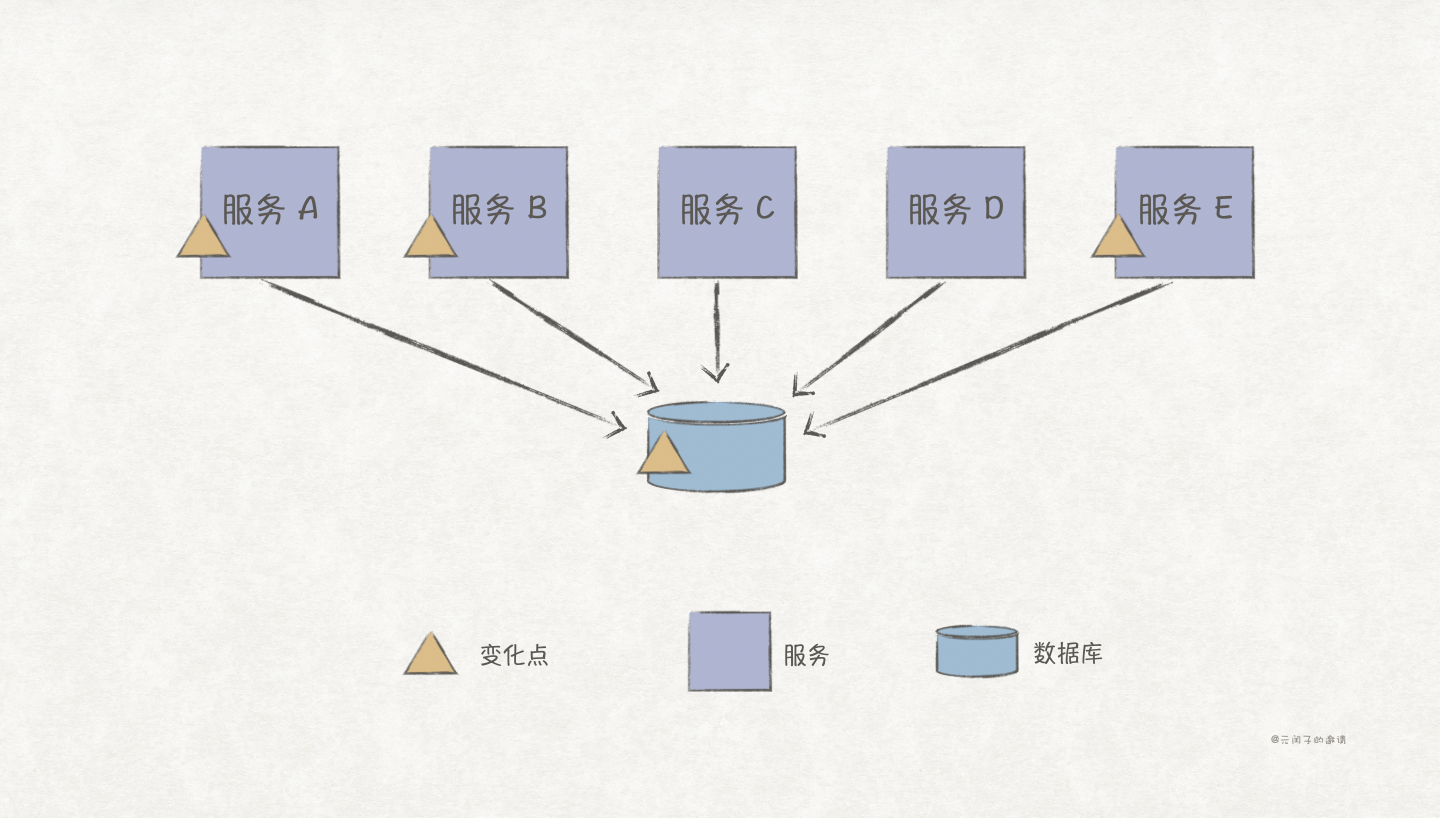
一种更危险的情况是,数据库变更发生时,服务 E 却忘记同步变更了,那么服务 E 相关的业务将不可用。
为了避免这种情况发生,我们可以根据系统的限界上下文进行数据拆分。限界上下文内的服务访问各自的数据库,变更的影响范围得到了控制;限界上下文间的数据访问通过服务接口进行,即使数据表结构变更了,只要服务接口不变,数据消费端也不会受此影响。

数据库连接数
数据库连接很耗资源,因此我们常用数据库连接池来提升系统性能,一方面可以进行复用,另一方面也能够限制连接数。
分布式架构下,服务通常会存在多个实例,当系统大到一定规模时,很可能就会出现数据库连接数达到上限的情况,这时,我们就要考虑分库了。
可扩展性
服务化架构下,初始阶段我们可以通过增加服务实例来提升系统性能,但最后,数据库一定会成为性能瓶颈,从而影响了系统的可扩展性。这时,我们就要考虑分库了。

容错性
服务化架构下,如果数据库出现故障,那么整个系统都会不可用。分库之后,数据库的故障只会影响相关的服务,容错性大大增强。

架构量子
假设一个系统中,服务 A 和 B 更关注数据的强一致性,而服务 C、D 和 E 这只需最终一致性节课,但因共享数据库的存在,使得系统的架构量子始终为 1,它们无法根据自己的架构特征来进行对应的设计。分库之后,这个问题也解决了。服务 A 和 B 共享一个数据库,通过数据库的 ACID 保证数据的强一致性;服务 C、D、E 有独立的数据库,架构更解耦。

数据库类型的选择
和架构量子类似,一个系统中,服务 A 和 B 提供 OLTP 服务,而服务 C、D、E 提供 OLAP 服务,那么它们的数据库选型可能就完全不一样,前者可能会选择关系型数据库,而后者这可能会选择数据仓库。
数据库的选型通常会考虑如下几个因素,架构师需要根据实际的业务属性进行权衡:
- 学习曲线。
- 数据建模的难度。
- 可扩展性/吞吐量。
- 可用性/分区容错性。
- 数据一致性。
- 读写优先级。
- 编程语言支持、产品成熟度、SQL 支持、社区活跃度等其他因素。
不建议数据拆分的场景
然而,并不是所有场景都需要数据拆分:
- **数据模型中,表与表之间存在较多的依赖的场景,**如外键、触发器、视图、存储过程等。这种情况下,拆分的难度会很大,而且强行拆分后也会使得系统更加复杂。
- 业务流程依赖数据库事务来实现的场景。共享数据库使得事务具备了 ACID 的性质,分库之后,分布式事务将会使得系统变得复杂,而且也很难保证 ACID。
数据拆分的步骤
书中总结数据拆分的 5 个步骤。
第一步:明确数据领域
分析数据模型,根据系统的限界上下文,梳理出系统的数据领域。
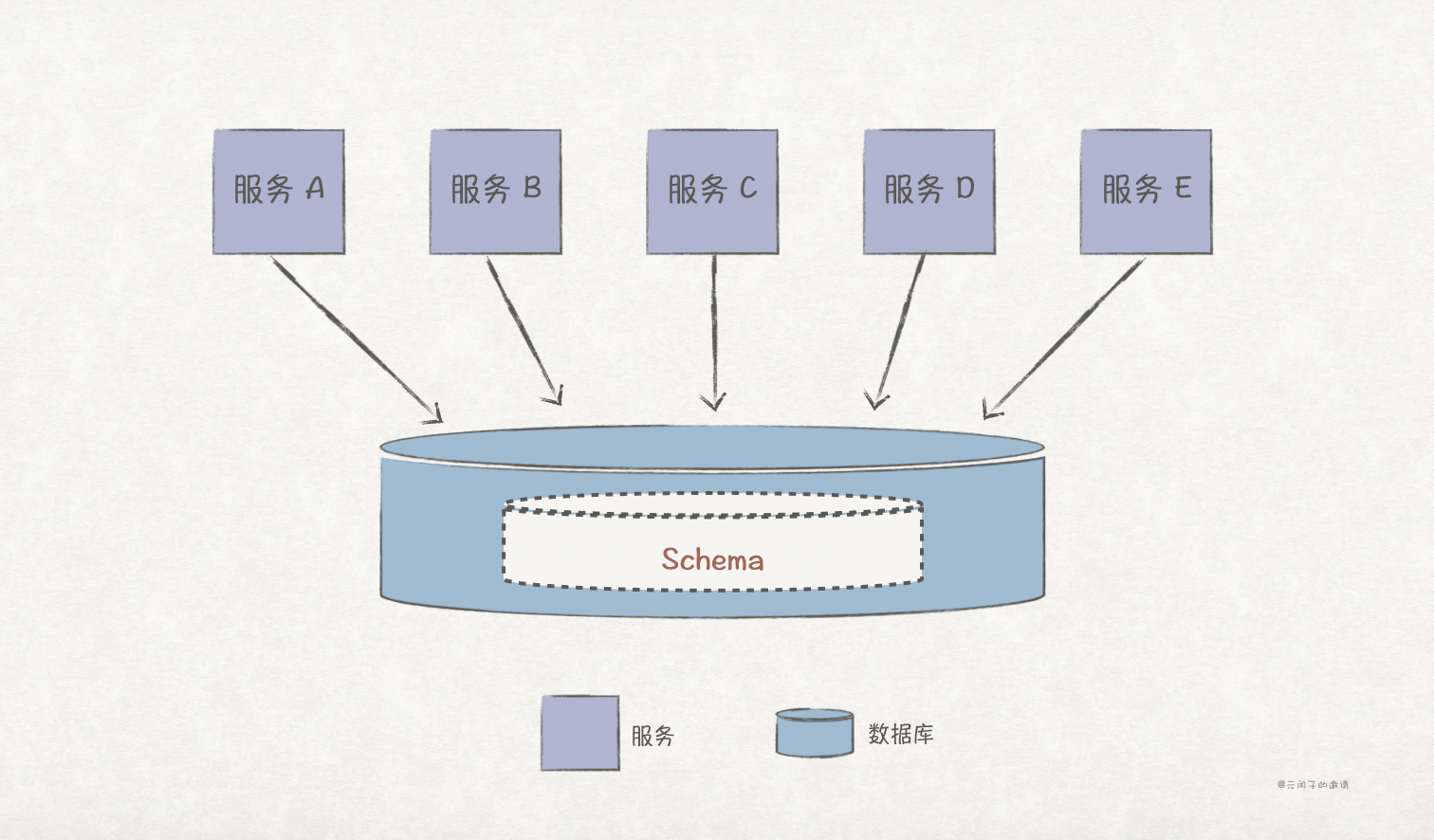
第二步:数据表聚类
在数据库中针对每个数据领域建立一个 schema,将数据表们分别归属到各自的 schema 之下。

在进行数据表归类时,我们常常会遇到这样的场景,服务 A 和 B 都依赖数据表 T,那么,数据表 T 应该归属到哪个服务上呢?
书中给出了以下几种归类方法:
1、数据表拆分。针对服务 A 和 B 分别依赖数据表 T 的不同列的场景,我们可以将表 T 一分为二,Ta 和 Tb。

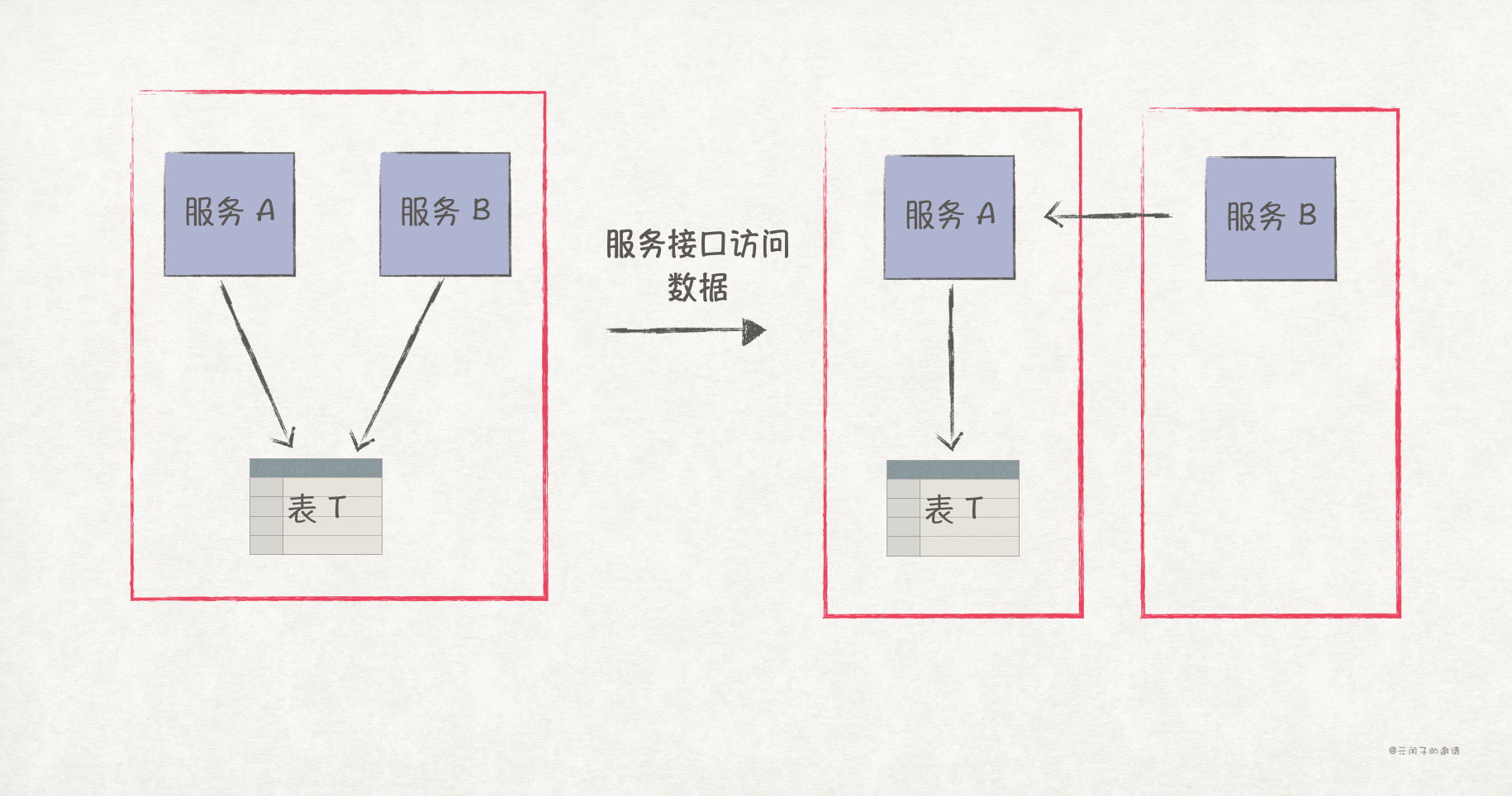
2、服务接口访问数据。根据业务优先级将表 T 归属给服务 A,服务 B 通过调用 A 的接口访问相关数据。
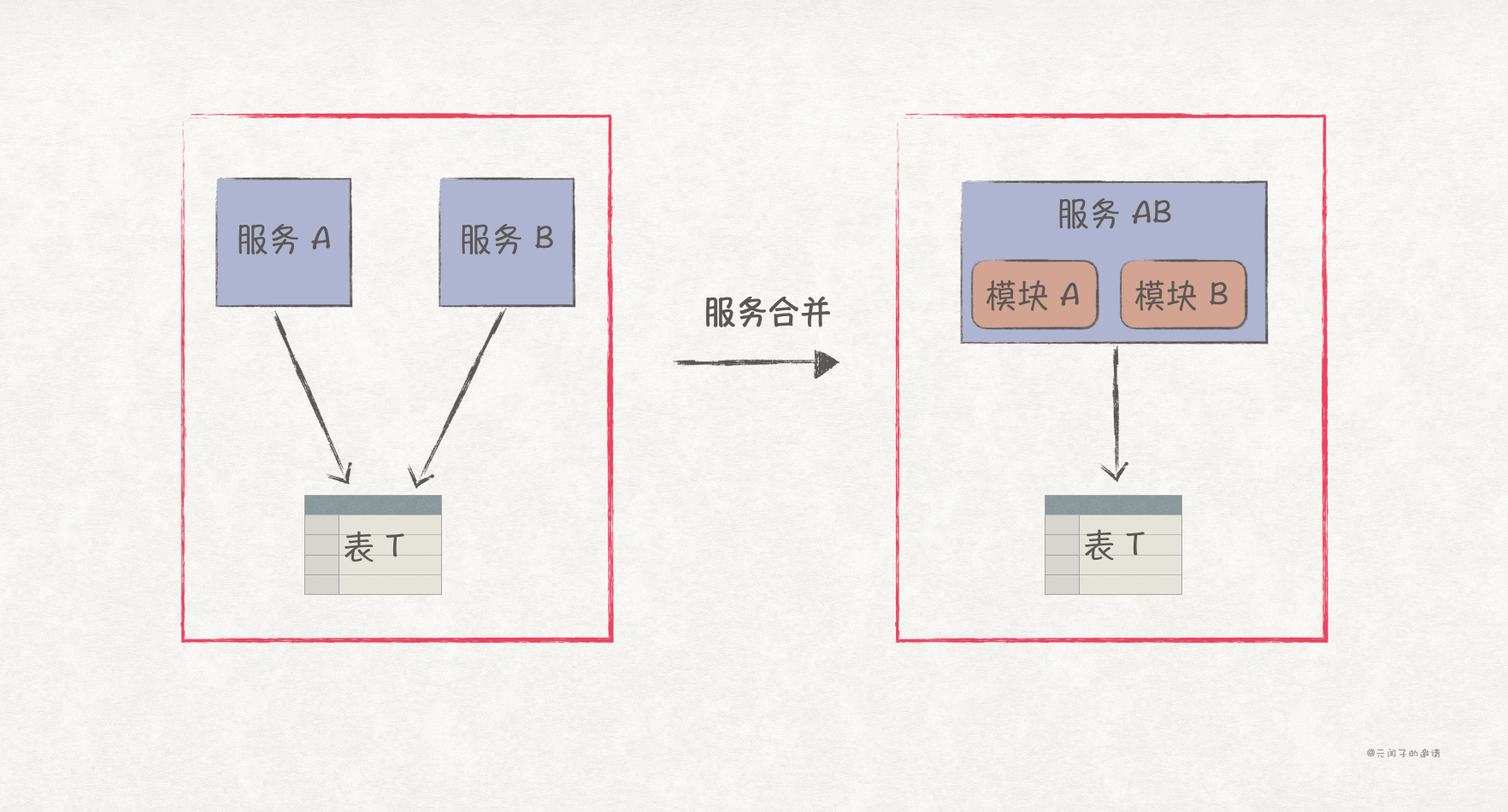
3、合并服务。如果是在无法归属,说明服务 A 和 B 耦合较深,它们就不应该拆分成独立的服务,应该合并在一起。
第三步:隔离数据库连接
对服务的数据库连接配置进行调整,使其连接到对应的 schema 之上。如果业务流程需要 2 个 schema 的数据,则通过服务接口调用来进行数据关联。
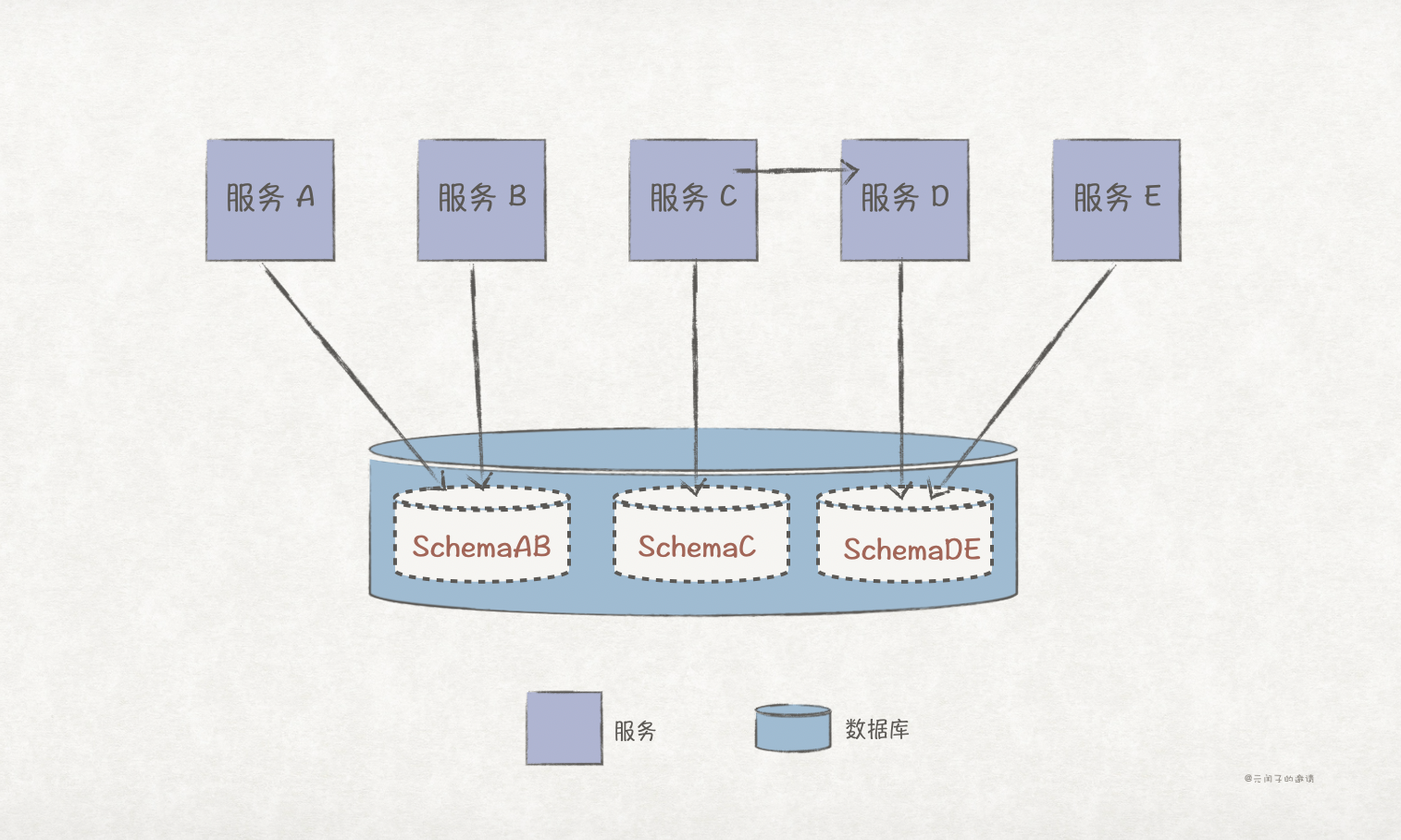
第四步:备份 schema
将 schema 复制到独立的数据库之中,因为数据的同步需要时间,这一步中,业务流程仍然访问共享数据库。
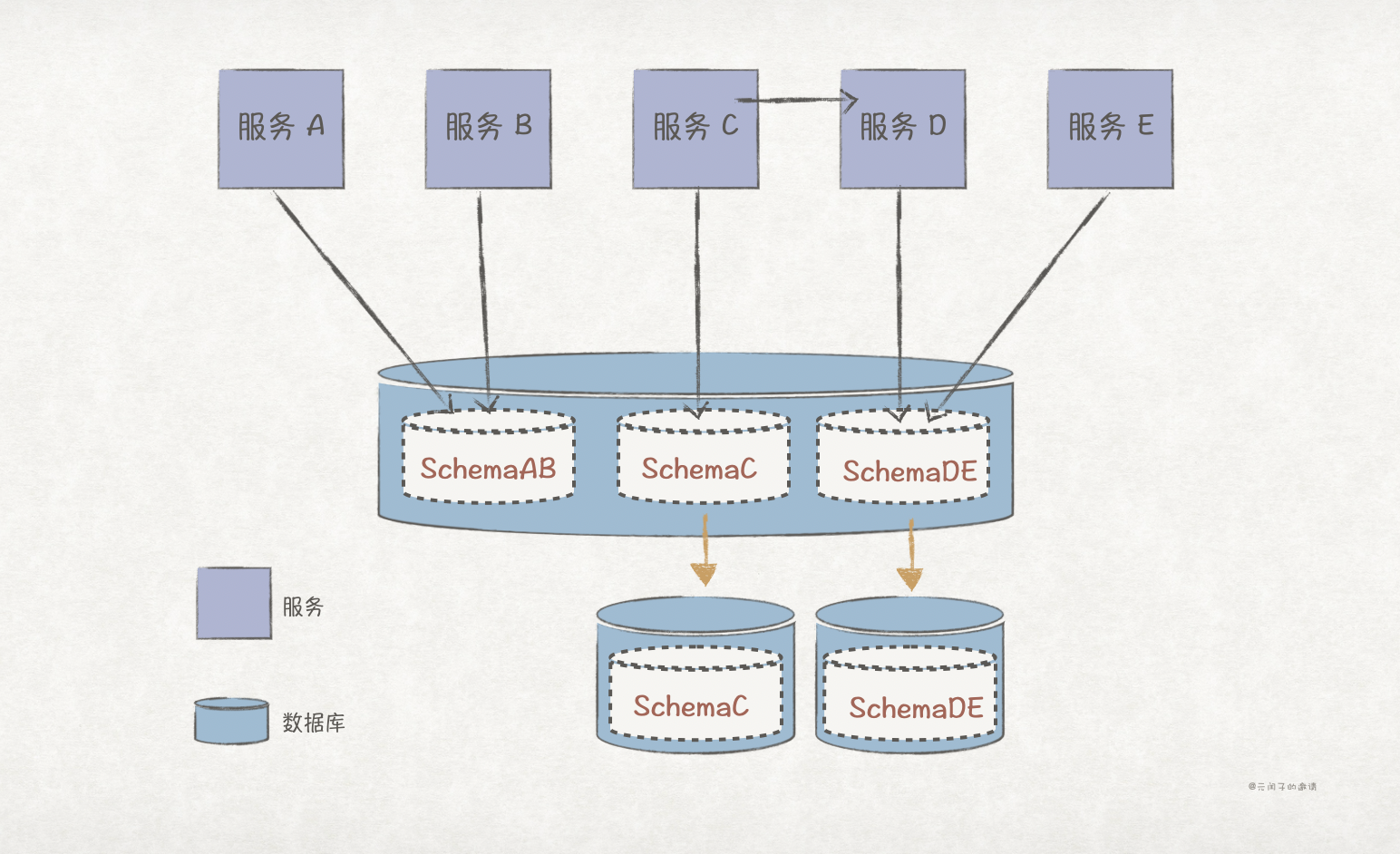
第五步:切换新的数据库
schema 同步完成后,下一步就是将业务流程切换到独立数据库中去。
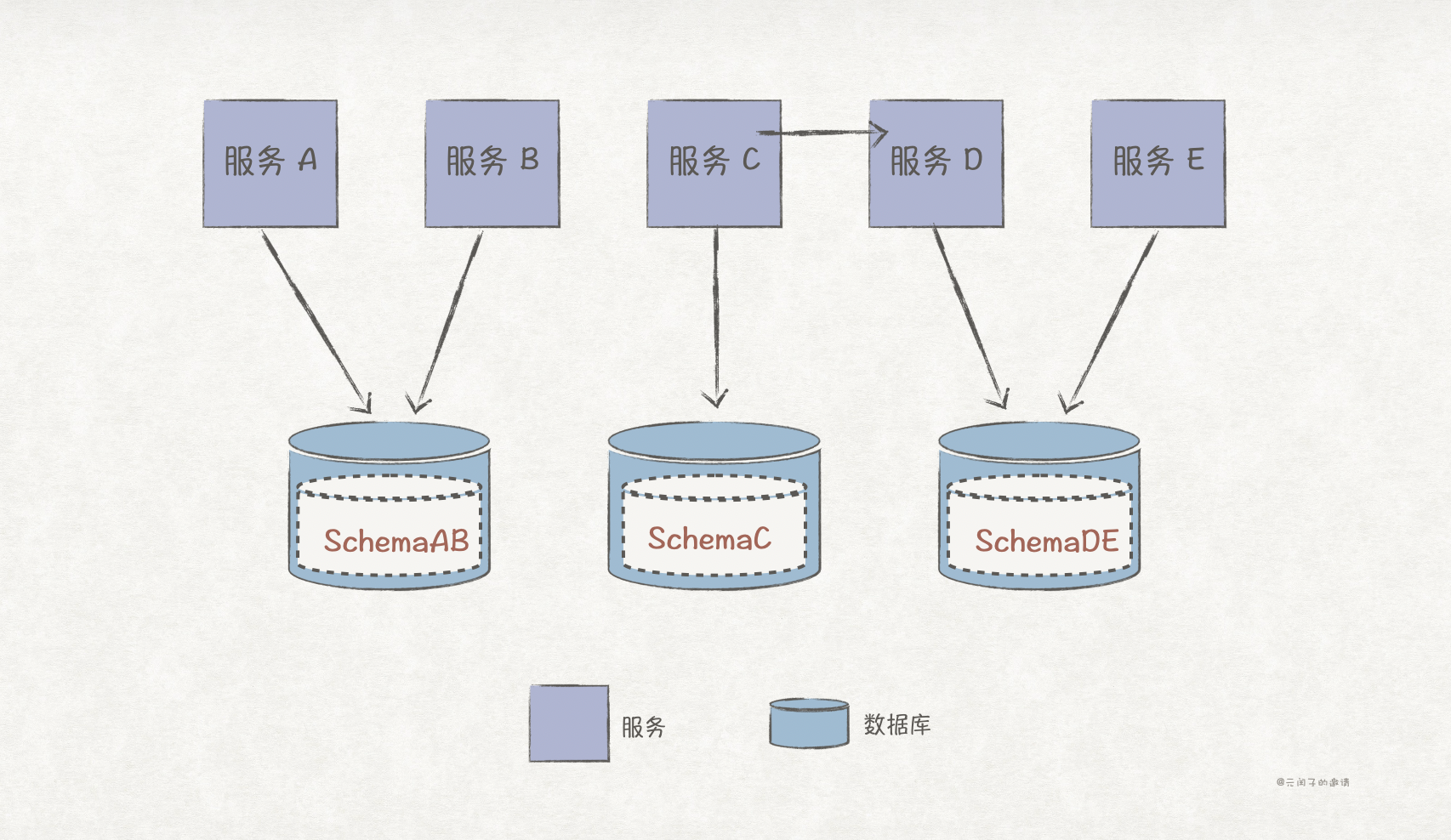
分布式数据的访问
数据拆分之后,我们将面临如何访问分布式数据的问题。
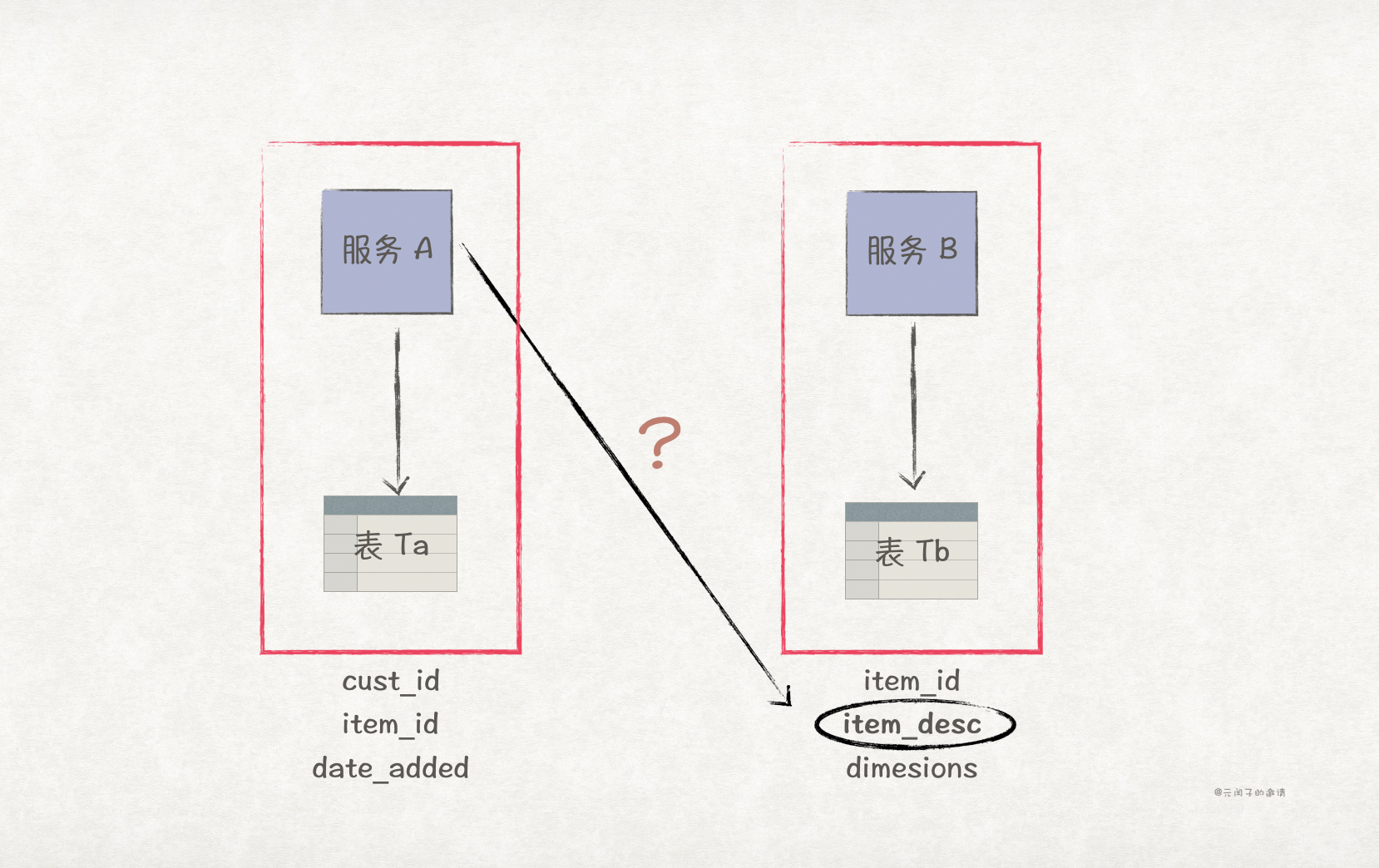
书中给出了 3 种常用的方法,服务间接口调用、数据副本、分布式缓存。
(1)服务间接口调用
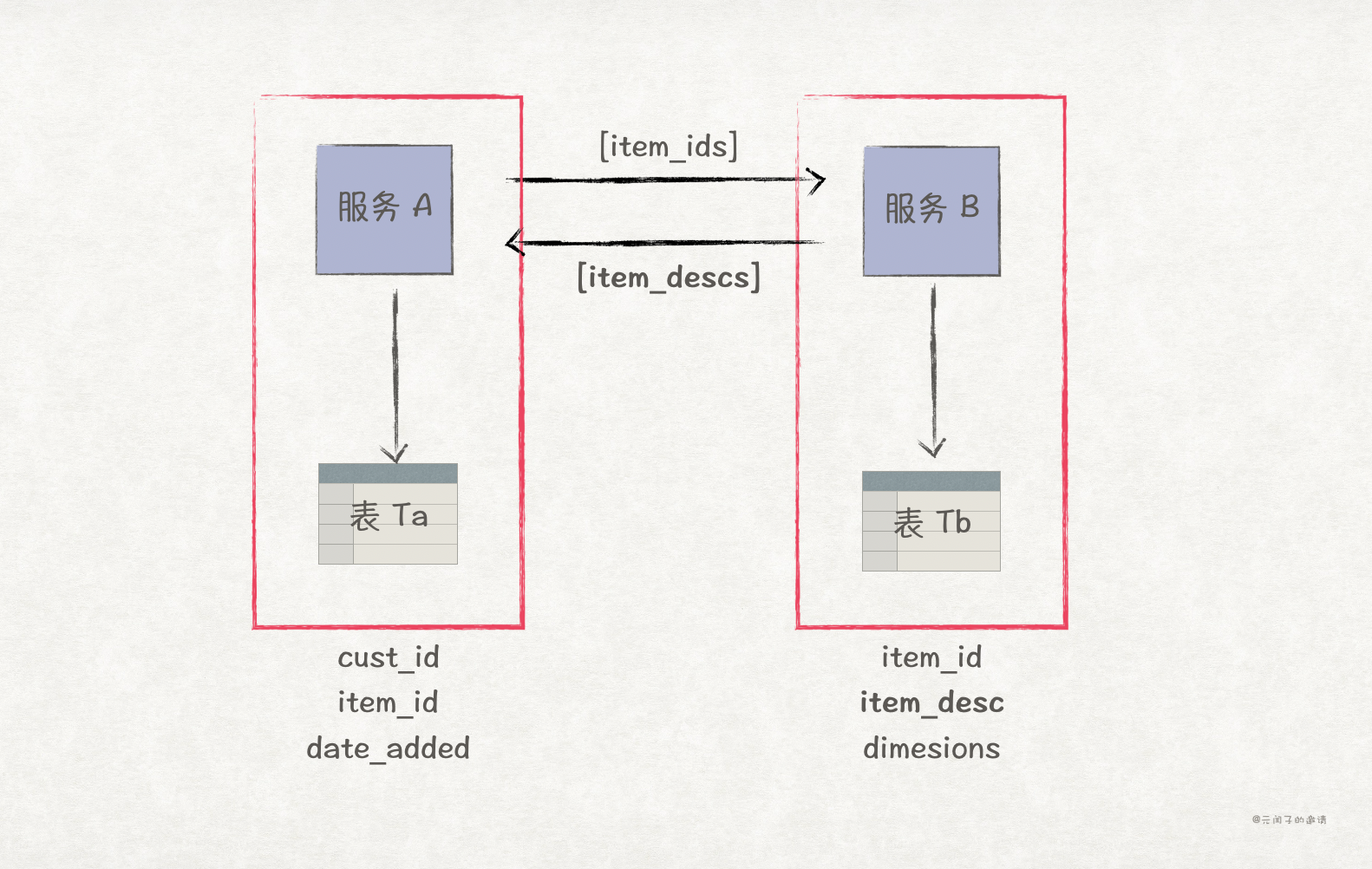
这是最常见、最简单的一种方法,优缺点总结如下:
| 优点 | 缺点 |
|---|---|
| 简单。 | 数据访问性能低下,网络时延、数据时延(比如上图例子中服务 B 查询 item_desc 数据的时延)、数据安全等因素都会影响系统性能。 |
| 数据只存一份,不会存在数据容量过大问题。 | 系统吞吐量可能存在问题。 |
| 系统可用性存在问题。直接的服务间接口调用意味着双方服务具有较强的耦合,一旦生产端服务异常宕机,消费端服务也服务对外提供业务。 | |
| 需要通信双方遵循接口契约。 |
(2)数据副本
可以针对需要跨服务传输的数据建立副本,比如,在前面的例子中,我们可以在表 Ta 上建立新增一列 item_desc,这样,服务 A 就无须调用服务 B 的接口获取 item_desc 了。
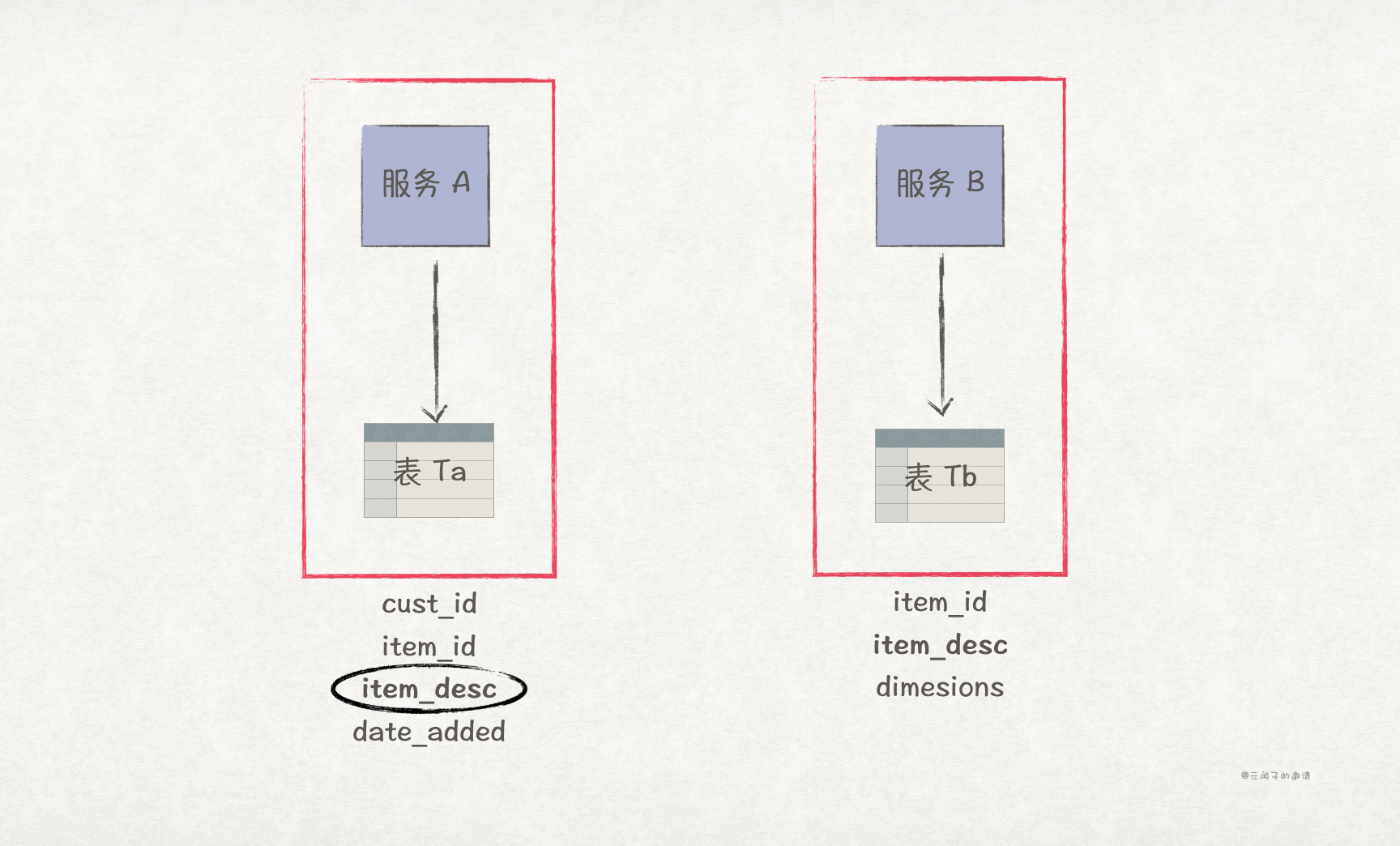
数据副本的优缺点总结如下:
| 优点 | 缺点 |
|---|---|
| 数据访问性能高。 | 同一份数据存在于不同的数据库内,容易产生数据不一致问题。 |
| 不存在数据访问吞吐量问题。 | 存在数据归属问题,这种情况下服务 A 和 B 都能够对 item_desc 进行更新,数据归属边界模糊。 |
| 不存在可用性问题。 | 需要在不同数据库间进行数据同步。 |
| 无服务依赖。 |
(3)数据缓存
缓存是最常见的提升数据访问性能的一种技术手段,也常用于分布式数据的访问和共享。普通的缓存通常是将数据库里的热点数据在本地内存中缓存一份,以提升数据访问性能,但此类型的缓存不具备分布式数据共享的能力。
而用于分布式数据访问的缓存大体上可以分成两种类型,中心化缓存和去中心化缓存。
中心化缓存下,系统有一个独立的缓存服务供所有业务服务共同使用,所有服务都可以对缓存数据进行读取和写入,常见的如 Redis、Memcached 等分布式缓存系统。中心化缓存方案简单,服务通过远程调用接口读写缓存数据,但缓存服务容易成为系统单点瓶颈。另外,远程调用存在网络时延,会有一定的性能影响;而且所有服务都具备数据的读写权限,数据归属模糊。
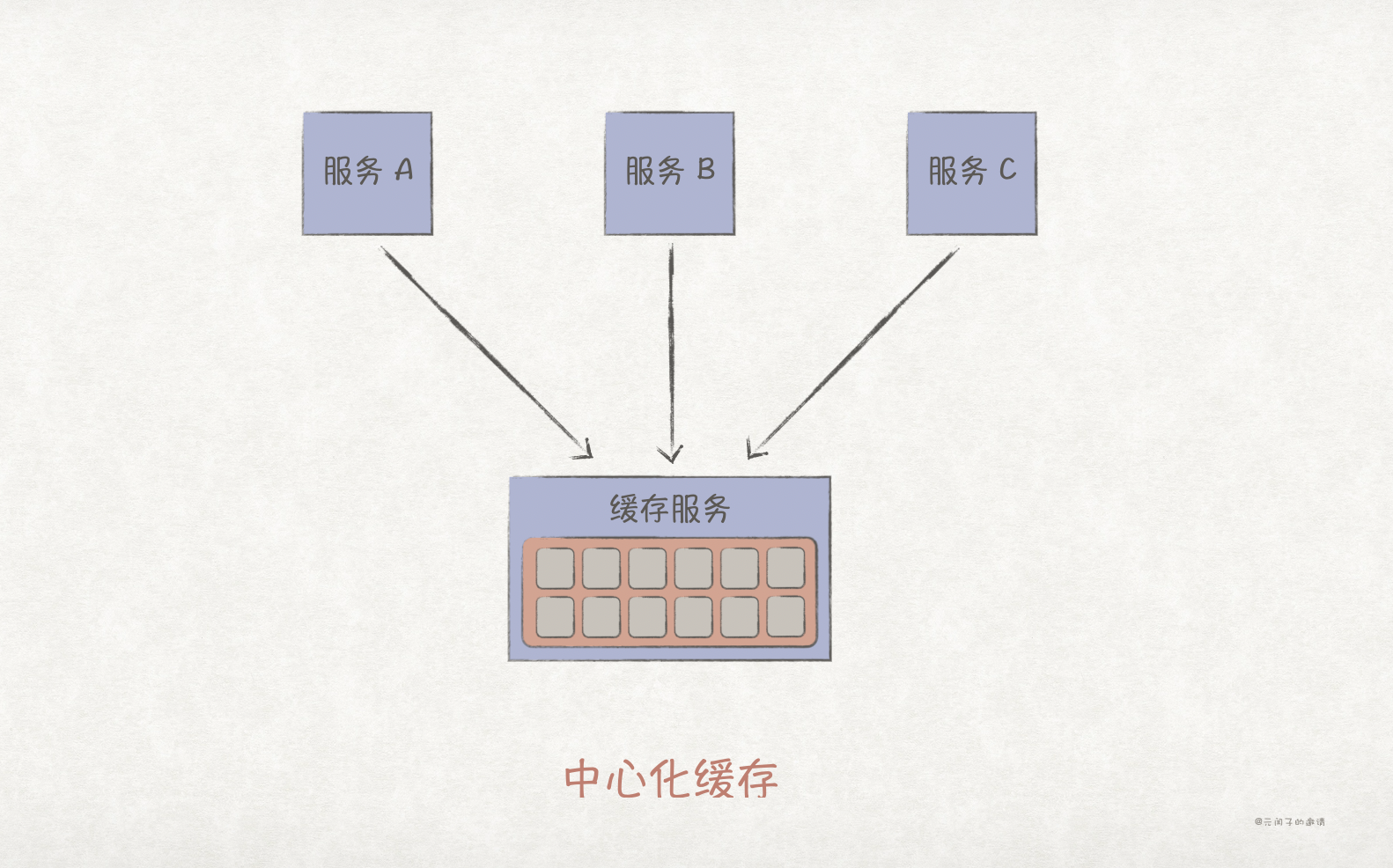
去中心化缓存下,每个服务的本地内存空间里都存有一份全量的缓存数据,而且它们之间会自动进行数据同步,常见如 Hazelcast、Apache Ignit 等内存数据网格。去中心化缓存架构下,缓存数据都在本地内存空间,具备很好的访问性能;且不存在缓存单点瓶颈,容错性、可扩展型都不错。

当然,去中心化缓存也有不少缺点:
- 服务存在启动依赖。比如,在服务 A 异常宕机后,服务 B 再次启动时需要依赖服务 A 恢复正常,以初始化缓存。
- 需要庞大的内存空间。每个服务的缓存都是全量的,如果数据量很大,所需的内存也会很大。
- 如果内存数据变更频率很快,可能存在同步不及时的情况。
- 内存数据的同步依赖 TCP 协议,如果集群庞大,节点间进行 TCP 建立连接也会很耗时。
拆分粒度的权衡
软件设计里有一项单一职责原则,这意味着拆分的服务粒度越细越好吗?其实不然,影响拆分粒度的因素很多,架构师需要做权衡。
很多人有这样的一个误区,根据代码行、类的多少来决定服务拆分的粒度。然而,每个开发者的编码风格、技术水平都有所差异,这就导致他们开发出来的代码在代码行、类数量上会存在差异。所以,这并不合适。
驱动细粒度服务的因素
服务职责
服务的职责是首要考虑因素,在 实践GoF的23种设计模式:SOLID原则 里我们提到,单一职责原则强调要从用户的视角来把握拆分的度,把面向不同用户的功能拆分开。太过聚合会导致牵一发动全身,拆分过细又会提升复杂性。
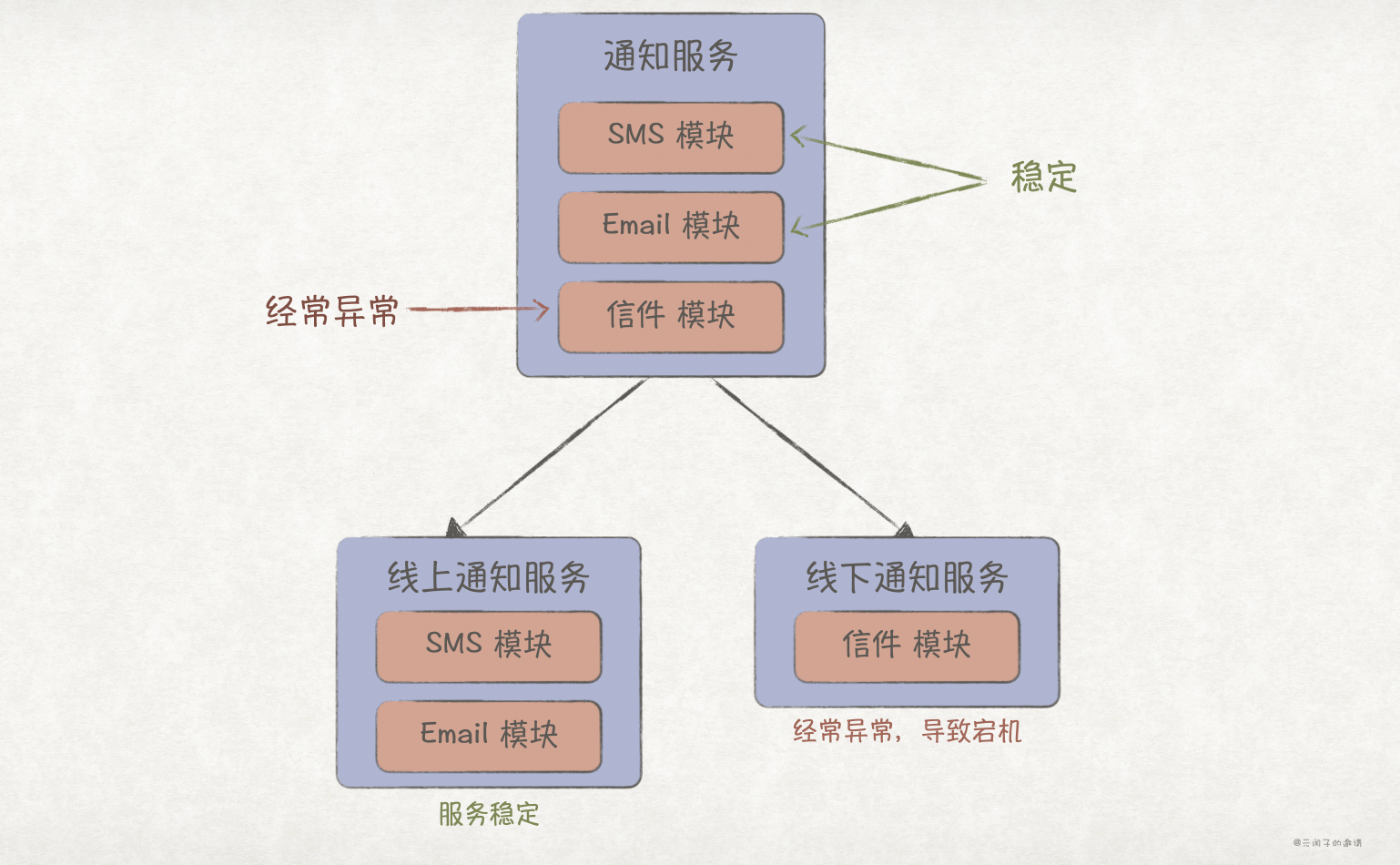
举个例子。下图 a 中,通知服务包含了 SMS 模块、Email 模块和信件模块,从职责上看似可以拆分成 3 个服务,但从业务层面考虑,它们所服务的对象都是一样的,具有强相关性,所以就不必要拆分;下图 b 中,消费者服务包含了用户资料模块、偏好模块和意见模块,它们是弱相关性,用户资料模块服务于后台管理、偏好模块服务于商品推荐、意见模块服务于 XXX,所以拆分就合理了。

代码改动频率
可以根据模块间代码改动的频率进行服务划分,将改动频率高的模块与改动频率低的模块分开,有利于提升系统的稳定性和可用性。同样考虑通知服务,假设 SMS 模块 和 Email 模块很少改动,而信件模块则改动频繁,那么可以拆分成 2 个服务。

可扩展性和吞吐量
将具备不同吞吐量的模块拆分成服务,可以更精确地进行系统扩展,节省资源。

容错性
如果某些模块经常异常,从而导致系统不可用,那么可以考虑将它们拆分开。跟前面介绍的代码改动频率相关,通常改动频率越高,模块越不稳定,也就越容易出异常。
安全
一个系统中,每个功能模块对安全的要求不一样,因此在进行技术选型时也会有所差异,比如用户资料服务包含基本信息模块和支付信息模块,后者对安全的要求就远大于前者,可以考虑将支付信息模块单独拆分成钱包服务。
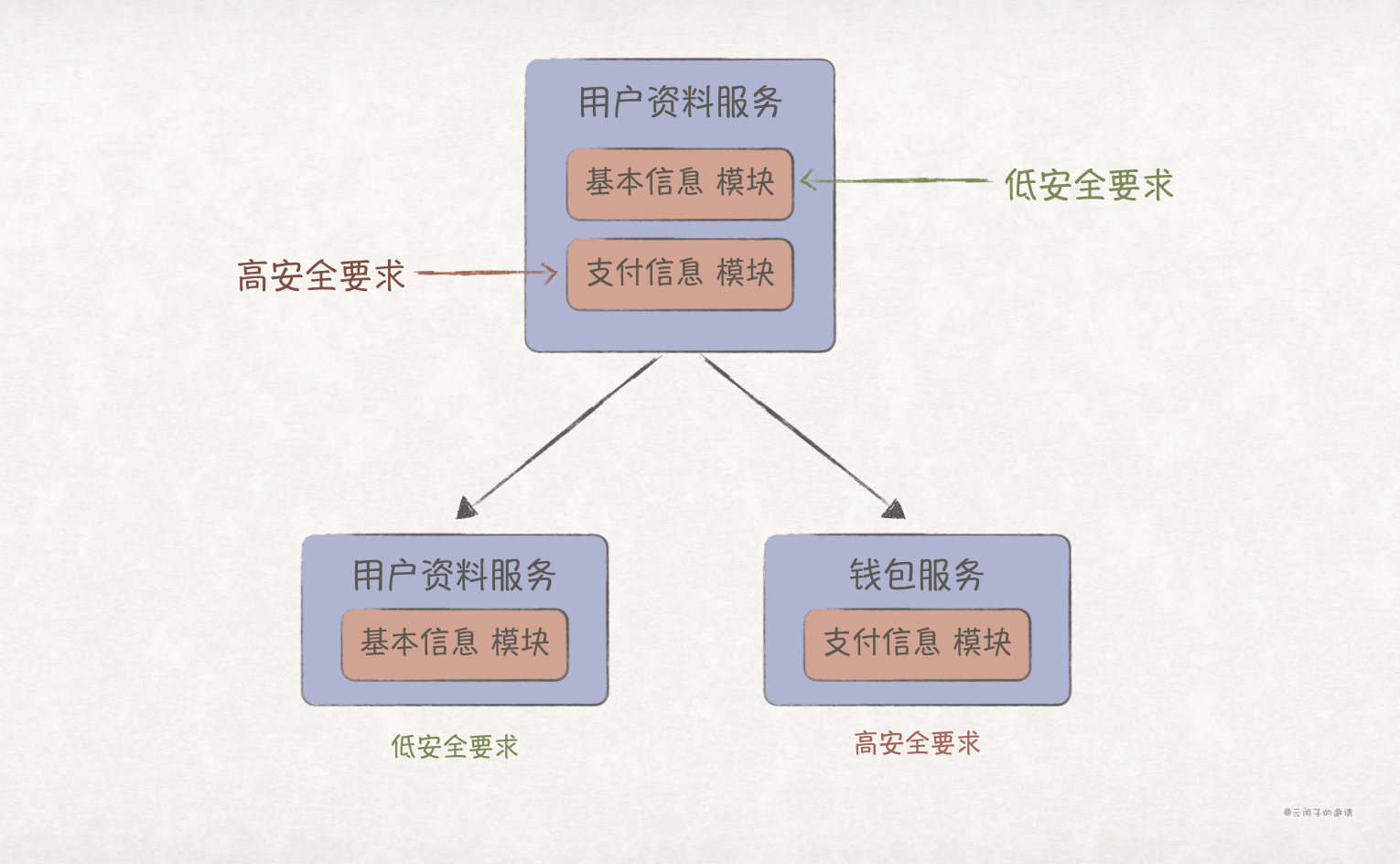
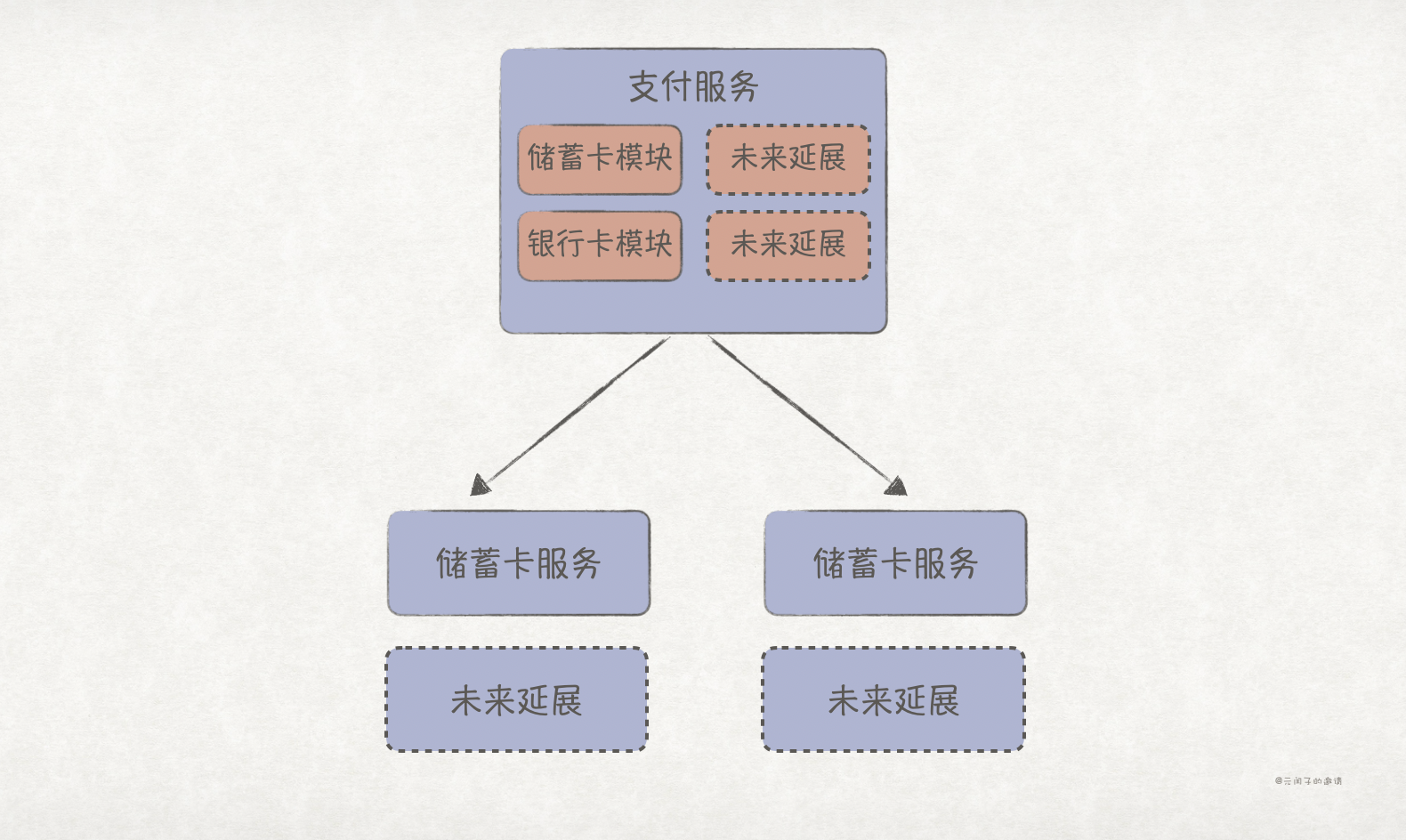
可延展性
可延展性(Extensibility)指系统业务的增长不断扩充功能的能力,更强调功能,而可扩展性(Scalability)更强调性能。举个例子,当前支付服务包含了储蓄卡、信用卡两种支付方式,在可预见的未来,还会新增如微信、支付宝、华为钱包等支付方式。如果不拆分,每次新增功能就会导致支付服务的升级部署,而且新功能的异常也会导致旧功能的不可用,从而影响了系统的可用性。
驱动粗粒度服务的因素
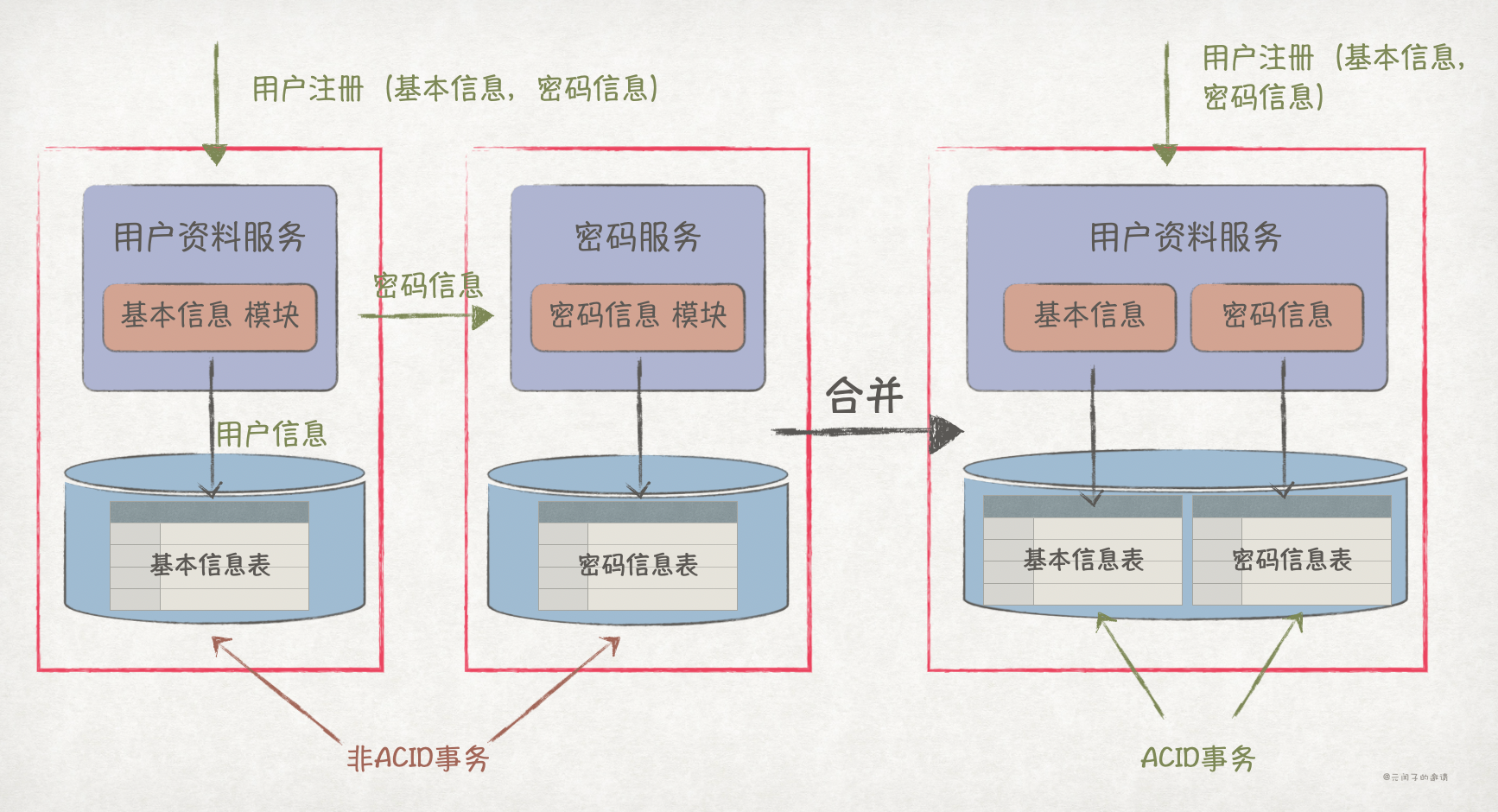
ACID 事务
分布式 ACID 事务是很复杂的,如果两个模块间的业务流需要 ACID 事务来保证,就要考虑将它们保留在一个服务内。
数据依赖
如果模块间数据依赖比较多、复杂,强行拆分会到来高昂的服务间通信代价。
工作流
工作流的影响与数据依赖类似,如果系统的工作流需要服务间紧密协作,那么服务间通信的代价会很大,最直接的影响就是性能下降。

共享代码
如果模块间共享代码具备如下特征,不建议进行更细力度的拆分了:
- 共享的代码属于领域层,带有业务逻辑。这说明模块间具有较深的业务耦合关系。
- 共享的代码变更频繁。这种情况下,各个服务也需要频繁升级适配最新版本,维护成本变大。
- 共享的代码无法实现版本控制。版本控制是当多个服务依赖公共代码库/服务时,避免因功能升级导致相互影响的重要手段。如果不能实现版本控制,系统可维护性将会大幅下降。
协作
服务间的代码复用
在分布式系统中,服务间多多少少会存在着代码复用,下面我们将介绍几种常见的代码复用方法。
代码复制
最简单的代码复用方法是将同样的代码复制到各个服务上。
| 优点 | 缺点 |
|---|---|
| 真正实现了“零共享架构”。 | 功能变更需要在每个服务进行代码修改,工作量大。 |
| 可能存在因同步不全而导致的代码不一致的问题。 |
适用场景:需要共享的代码是比较简单的静态代码,如属性、简答的工具类等。
共享库
共享库是最常见的代码复用方法,它将需要复用的代码打包成共享库文件,比如 Java 中的 jar 文件、C++ 中的 so 文件,在编译时集成到服务中去。

根据每个服务依赖的类文件的不同,我们可以将粗粒度的共享库拆分,避免不必要的耦合出现。
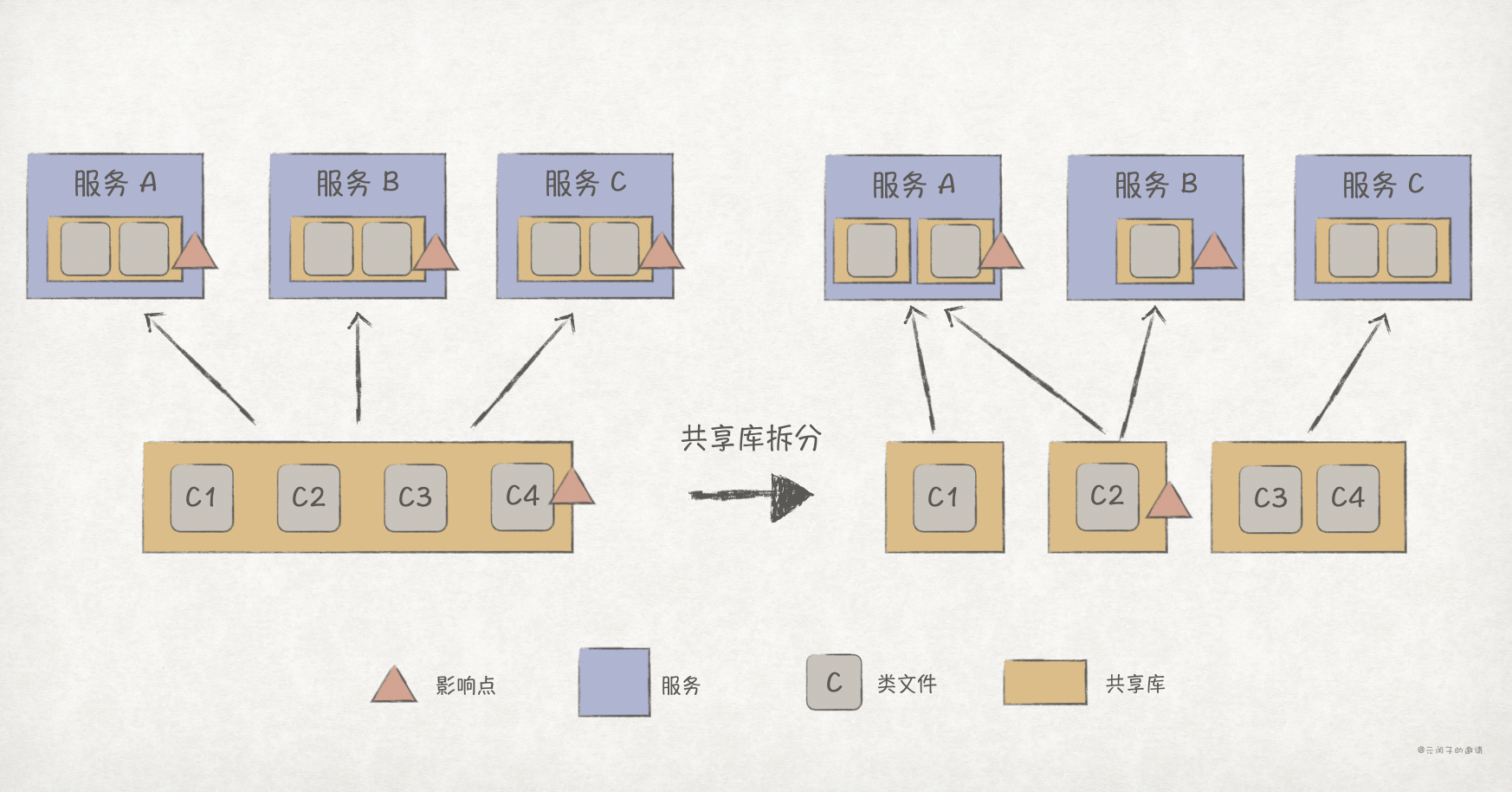
另外,我们也可以通过版本管理来控制共享库的影响范围。比如,服务 C 需要类文件 C3 和 C4 升级功能,而服务 A 和 B 并不需要,我们可以给共享库进行版本升级,只需服务 C 更新依赖版本即可。

| 优点 | 缺点 |
|---|---|
| 可以实现版本管理。 | 依赖管理比较困难。 |
| 共享库在编译器集成,能够减少运行时的错误。 | 在存在多种编程语言的系统中,仍然会存在代码重复。 |
| 功能变更只需修改共享库即可,工作量小。 | 废弃老旧版本会很困难,某些原本无须升级的也会被迫切换到新版本。 |
| 编译时集成,不影响系统的性能、可扩展性、容错性 | 版本变更对某些用户必然存在着信息滞后。 |
适用场景:适用于同构的、编程语言相同的系统下的代码复用。
共享服务
如果系统是异构的、有多种编程语言的,那么我们可以使用共享服务来实现代码复用。该方法将公共的代码抽离出一个服务,通过接口对外开放能力,因此,只要消费端服务遵循同样的接口协议,就能使用该功能,无论系统异构或者由不同编程语言开发而成。

共享服务的一大好处是,消费端服务与它的依赖是运行时依赖,共享服务的改变不会导致消费端服务的重新部署;当然,如果共享服务出现异常宕机,所有服务都会受此影响。
| 优点 | 缺点 |
|---|---|
| 在共享代码变更频繁的场景,无须升级消费端服务。 | 版本管理比较困难,与共享库有着类似的缺点。 |
| 完全不存在代码重复。 | 功能的使用,从服务内接口调用变成服务间接口调用,网络时延影响系统性能。 |
| 无静态代码依赖。 | 共享服务的异常会影响整个系统的可用性 |
| 共享服务可能成为单点瓶颈,从而影响系统的可扩展性和吞吐量。 | |
| 相比于编译时依赖,运行时依赖存在更多意料之外的异常。 |
适用场景:异构或多编程语言系统、公共功能变化频繁的场景。值得注意的是,如果系统对性能或时延要求很高,这不适合使用该方法。
分布式事务
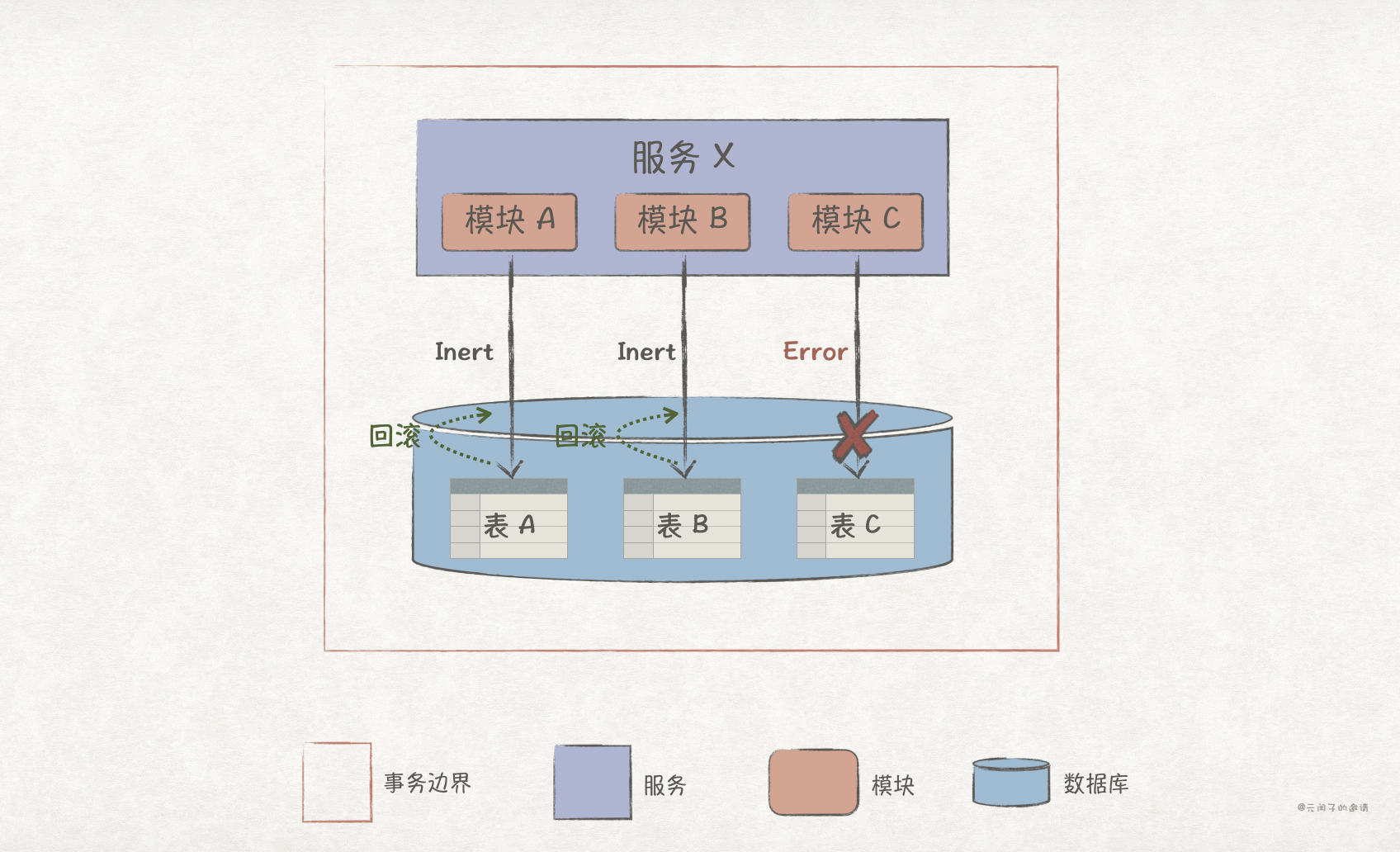
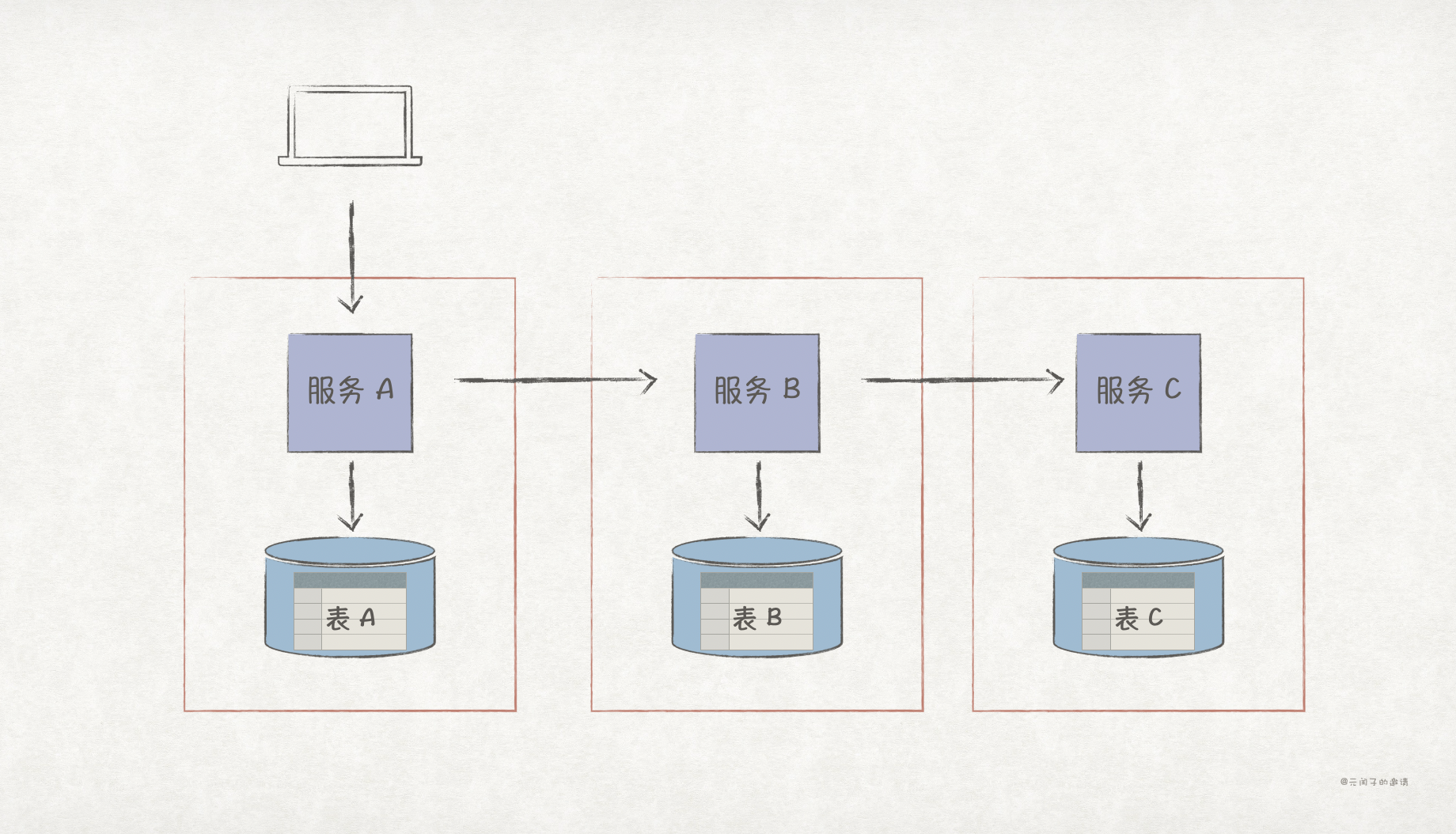
在单体架构或多个服务共享一个数据库的服务化架构之下,我们可以利用数据库的能力实现 ACID 事务。比如在下图中,在一个 ACID 事务内有三次 Insert,当最后一次失败时,数据库会将两次的 Insert 操作回滚。
ACID 指的是数据库为保证事务的正确可靠所必须具备的 4 个特性。
- 原子性(Atomicity):一个事务的所有操作要么全部 commit 成功,要么全部失败 rollback。
- 一致性(Consistency):事务执行前后,数据库的完整性约束没有被破坏。比如,A 给 B 转账事务中,转账前后总金额应该保持一致。
- 隔离性(Isolation):多事务并发访问时,事务之间是隔离的,不会看到中间状态的数据。
- 持久性(Durability):事务完成后,所有对数据的更改都不会丢失。
然而,在微服务架构之下,服务间的数据库是隔离的,分布式事务并不会遵循 ACID 性质。
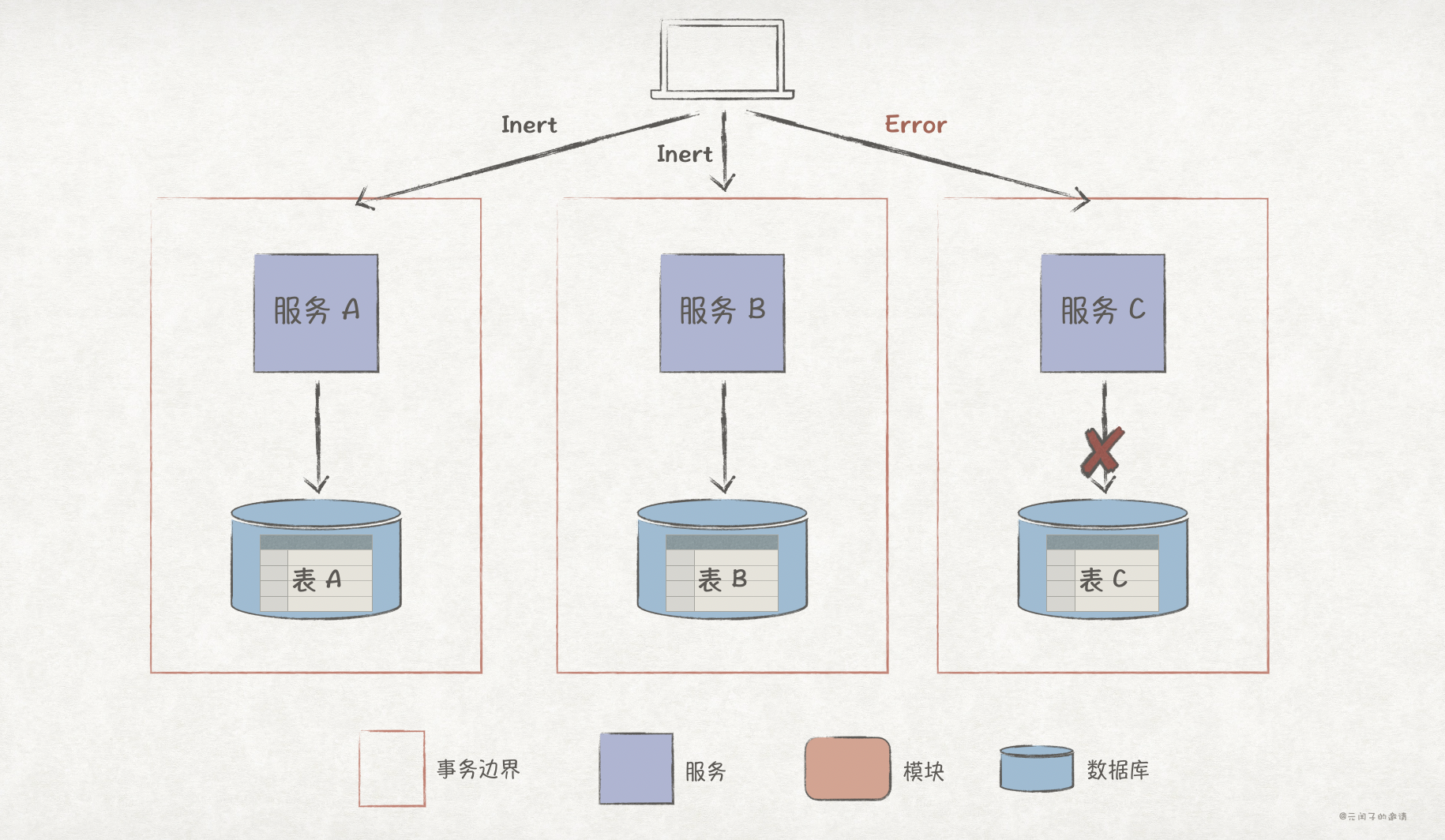
1、每个服务的 Insert 操作都独自 commit,原子性只限于当前服务内,在业务流程上并不具备原子性;
2、当前服务 C Insert 失败后,服务 A 和 B 并不会自动实现回滚,从而产生了数据不一致,因此不具备一致性。
3、服务 A 插入数据成功后,其他服务就能通过 服务 A 访问到该数据,此时业务流程可能并未结束,因此不具备隔离性。
4、持久性只局限于当前服务内,也即服务 A 插入成功,数据持久化了,但并不能保证服务 B 和 C 也如此。
分布式事务通常会遵循 BASE 性质,也即
- 基本可用(Basically Available),出现故障时系统仍然可用,只会牺牲响应时间或功能降级;
- 软状态(Soft State),允许系统中的数据存在中间状态;
- 最终一致性(Eventually Consistent),系统不能一直处于软状态之下,经过一定时间后,系统数据要能够达到一个最终一致的状态。
基本可用通常基于服务间异步通信实现。如下图所示,在同步通信下,如果服务 C 异常宕机,客户端将得不到响应;在异步通信下,则不会受到影响。

实现最终一致性的方法主要有以下几种:
1、后台服务数据同步。该方法会专门独立出一个后台数据同步服务,通过离线同步达成最终一致性。这里的关键点是后台服务需要知道哪些数据需要同步,可以通过数据库触发器、事件流等技术手段实现。

后台服务数据同步的优缺点如下:
| 优点 | 缺点 |
|---|---|
| 服务间解耦。 | 所有的数据都因为后台同步服务而产生了耦合。 |
| 良好的用户响应时间。 | 需要新增一个同步服务,实现起来比较复杂。 |
| 数据同步过程可能涉及业务逻辑,从而导致这部分代码重复于业务服务和同步服务上。 | |
| 数据离线同步通常发生在深夜业务空闲间隙,从而导致实现最终一致性的时间很长 |
2、服务间同步通信。服务间采用同步通信方式,就能实现在业务流程结束后达成最终一致性。同步通信的最大缺点是,当服务 C 故障时,整个系统将处于不可用状态,表现为用户得不到正常响应。
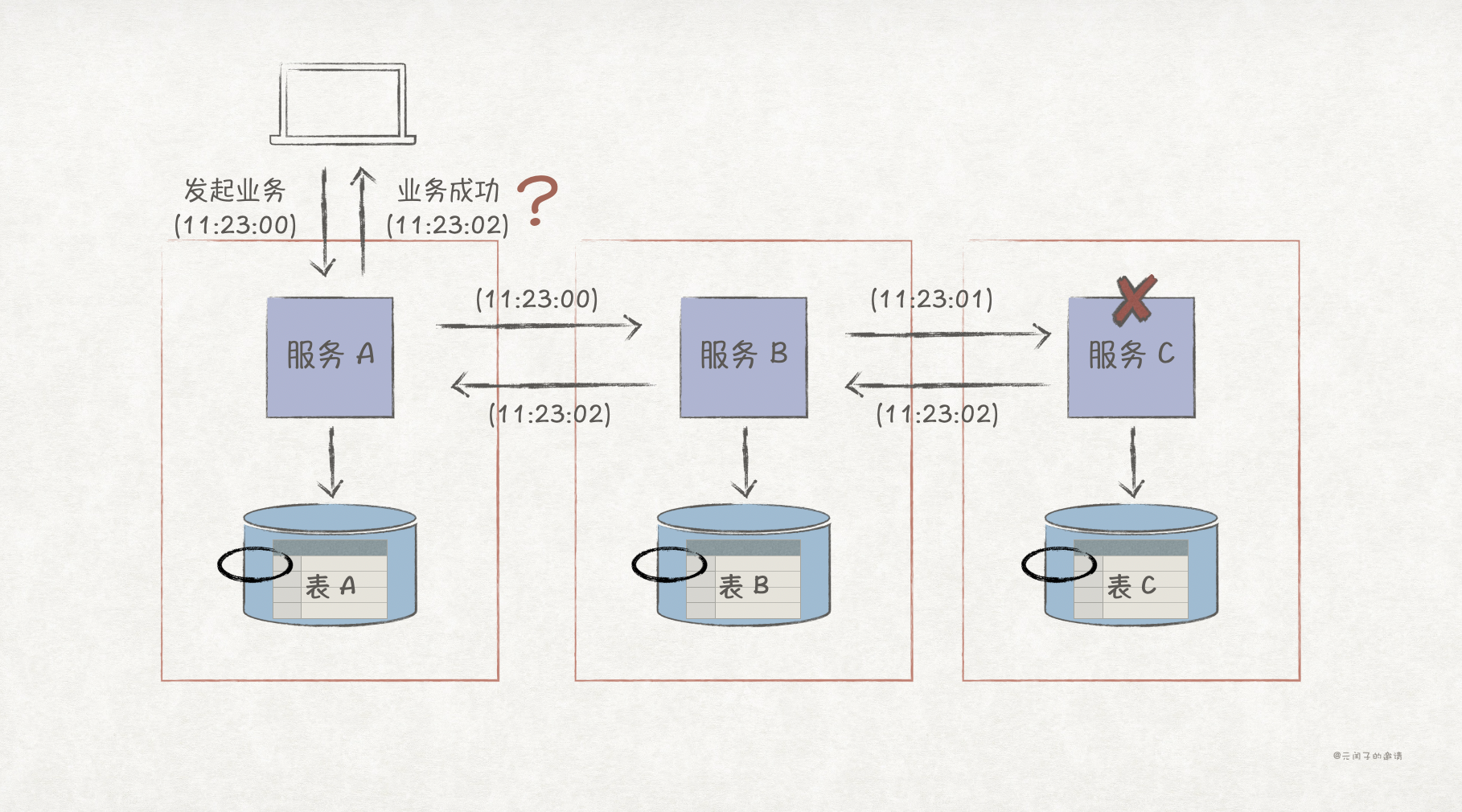
服务间同步通信的优缺点如下:
| 优点 | 缺点 |
|---|---|
| 服务间解耦。 | 糟糕的用户响应时间。 |
| 能够及时达成最终一致性。 | 异常处理复杂,因为没有统一的控制中心,需要各个服务自己实现错误回滚逻辑。 |
| 业务流程具备原子性。 |
3、事件通知。相当于基于消息队列的异步通信方式,综合了前面两种方式的优点,但错误处理仍然会很复杂。
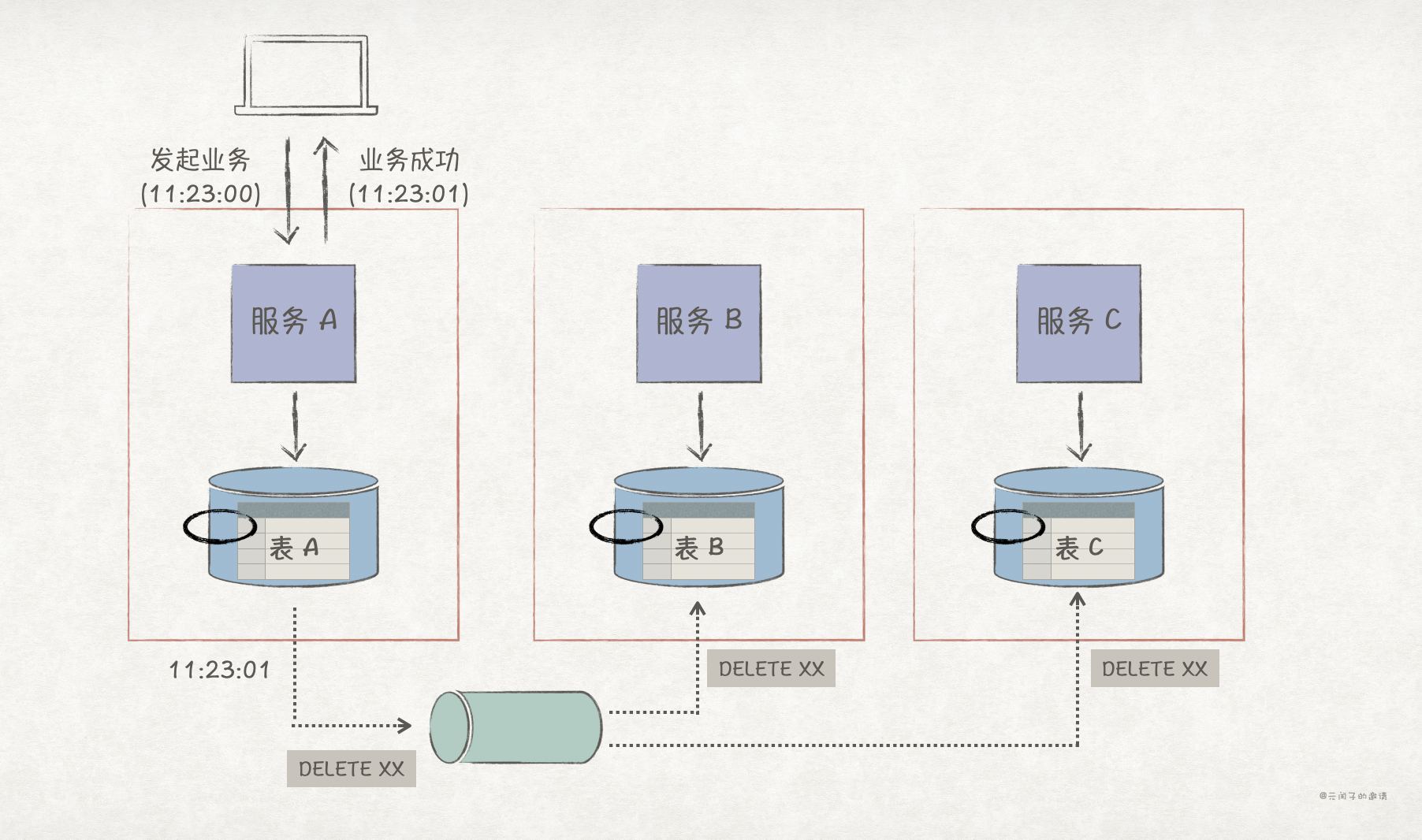
事件通知的优缺点如下:
| 优点 | 缺点 |
|---|---|
| 服务间解耦。 | 异常处理复杂。 |
| 能够及时达成最终一致性。 | |
| 良好的用户响应时间。 |
工作流编排
工作流(Workflow)指让各个服务协作起来共同完成的业务流程。分布式架构之下,工作流的编排通常可以分成两大类,中心化的 Orchestration 和 去中心化的 Choreography。
Orchestration 编排方式
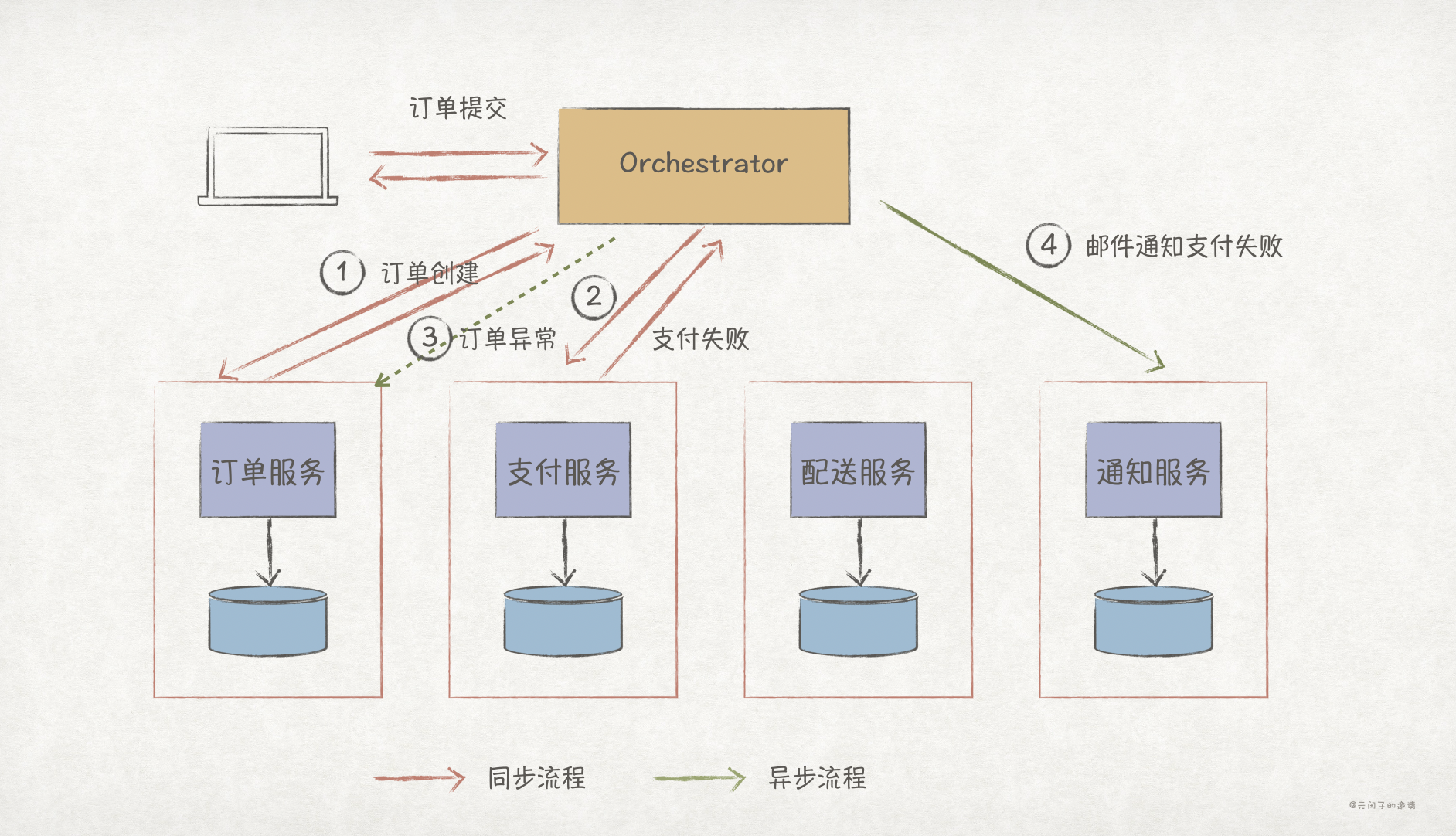
Orchestration 编排的架构如下,Orchestrator 服务作为控制节点,也是业务流程的起始点,负责整个工作流的编排、任务下发,各个业务服务只须处理 Orchestrator 下发的任务即可。

下面以购物订单流程举例,用户提交订单后,Orchestrator 完成工作流编排,总共需要执行 4 个业务流程,其中订单创建和订单支付为同步流程,执行结束后即可响应用户;商品配送和邮件通知为异步流程。
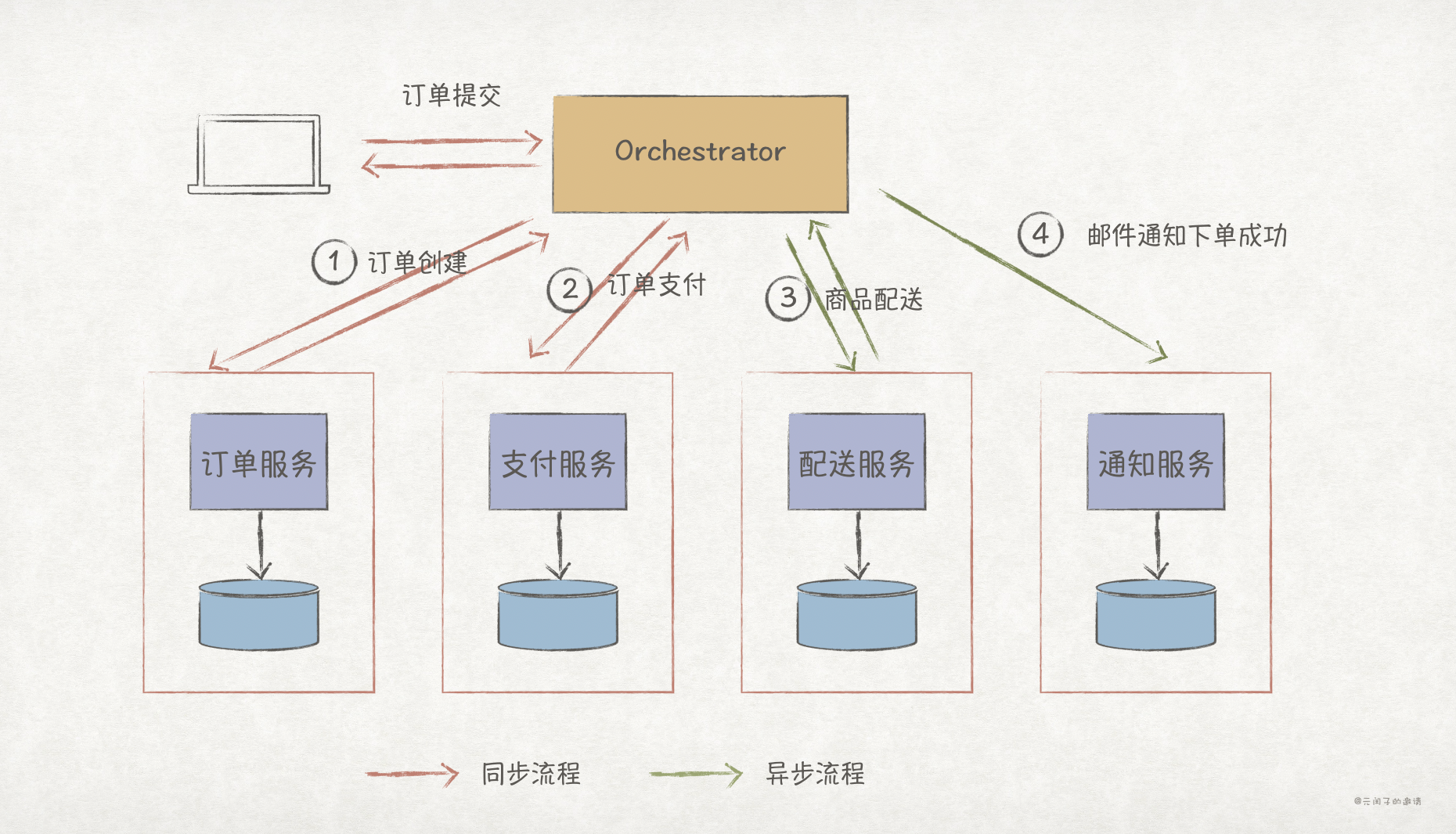
Orchestration 编排架构方案简单,各业务服务只须处理任务即可,这在在错误处理和状态管理上具有明显的优势,下面是支付失败场景的举例:
Orchestration 编排架构下,Orchestrator 服务容易成为单点瓶颈,因此容错性、可扩展性、性能是劣势。
Choreography 编排方式
Choreography 编排的架构如下,是去中心化的编排方式,各个业务服务需要管理与自身业务相关的工作流,既负责任务执行,也要负责下一步流程的选择与触发。
同样以购物订单流程举例,与Orchestration 编排架构相比,去除了Orchestrator 单点瓶颈,因此在容错性、可扩展性和性能得到了提升。值得注意的是,例子中我们使用了异步流程,这是为了更能发挥 Choreography 编排的性能优势:

Choreography 编排架构下,错误处理的逻辑遍布在各个业务服务之上,随着业务的不断增长,错误处理将会越来越复杂。以下是支付失败的场景举例:

Choreography 编排架构在状态管理上也存在劣势,没了统一编排服务,每个业务服务需要维护整个工作流的处理状态,状态同步上会存在不少挑战,稍有不慎可能就出现状态不一致的问题。
Saga 分布式事务
Saga 事务是分布式事务中的一种,也是我们实现分布式事务最常用的模式之一。Saga 由一系列事务组成,事务间通过消息或事件来触发。 如果某个事务失败,则 Saga 将执行补偿事务,以抵消上一个事务的影响。
书中根据通信、一致性、编排三个维度的不同对 Saga 事务模式进行了划分,共有八种类型,名称系作者根据类似的实际生活例子命名,可以不用深究:
| Saga 模式名称 | 通信方式 | 一致性 | 工作流编排方式 |
|---|---|---|---|
| Epic Saga | 同步 | 强一致性 | Orchestration 编排 |
| Phone Tag Saga | 同步 | 强一致性 | Choreography 编排 |
| Fairy Tale Saga | 同步 | 最终一致性 | Orchestration 编排 |
| Time Travel Saga | 同步 | 最终一致性 | Choreography 编排 |
| Fantasy Fiction Saga | 异步 | 强一致性 | Orchestration 编排 |
| Horror Story Saga | 异步 | 强一致性 | Choreography 编排 |
| Parallel Saga | 异步 | 最终一致性 | Orchestration 编排 |
| Anthology Saga | 异步 | 最终一致性 | Choreography 编排 |
每种模式都是在性能、可扩展性、可用性、复杂性等方面的权衡,同步通信 VS 异步通信、强一致性 VS 最终一致性、Orchestration 编排 VS Choreography 编排,它们之间的优缺点在前文中已进行了介绍,我们需要根据实际的业务场景去做出选择。
不过在这八种模式中,有一种连作者也不推荐使用,那就是 Horror Story Saga,它在通信方式、一致性、工作流编排方式上都选择了相对更复杂的一种,组合起来会使得整个架构变得极其复杂。而且选择异步通信和 Choreography 编排通常是为了提升系统的性能和可用性,但强一致性又限制了它们,所以,这是一个矛盾的模式!
最后
SAHP 书中,作者构造了一个虚拟的设计案例,各个章节都基于该案例串联起来,通过阅读该案例,读者对各个知识点会有更深的理解。
本文只是介绍了 SAHP 重要的知识点,书中还有关于服务通信协议(JSON、XML等)、如何利用数据分析技术来更好地做权衡等内容,感兴趣的可以直接阅读原书。
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
[1] Software Architecture: The Hard Parts, Neal Ford, Mark Richards
[2] Saga 分布式事务模式, Microsoft Azure architecture reference
更多文章请关注微信公众号:元闰子的邀请















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









