







声明
本文是博主在Coursera学习时所写的学习笔记,如有错误疏漏还望各位指正。
如果大家转载,请注明本文地址!
基础知识
什么是Dynamic Connectivity
Given a set of N objects.
Union command: connect two objects.
Find/connected query: is there a path connecting the two objects?
例如给定集合如下:
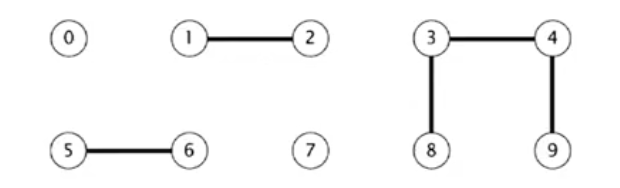
此时
coonconnected(0, 7) False
connected(8, 9) True
执行以下命令:
- union(5, 0)
- union(7, 2)
- union(1, 0)
- union(6, 1)
集合的状态改变为:
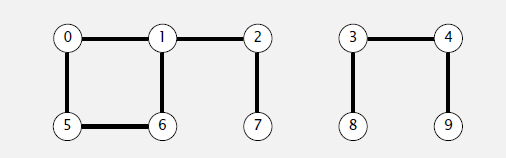
此时:
- connected(0, 7) Ture
我们设定“连接”有以下属性:
- 自反性:p和p是互相连接的
- 对称性:如果p与q是的连接,则q与p是连接的
- 传递性:如果p与q连接,q与r连接,则p与r连接
再给出一个定义
- 连接组件:相互连接的对象的最大集合。
给定如下集合:
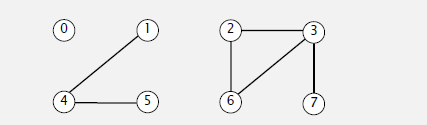
上图中包含三个连接组件
{0},{1,4,5},{2,3,6,7}
在同一个连接组件中的所有节点都是互相连接的
———————分割线——————
说明:本文介绍的算法采用Java来实现
Quick Find
根据上面的问题描述,我们所定义的类需要包含以下三个函数:
- UF(int N) 初始化,创建N个节点
- void union(int p,int q) 链接p和q
- boolean connected(int q,int q);p和q是否在同一个链接组件中
采用的数据结构
- 长度为N的数组id[],
说明:
- id[i]的值表示节点i所在的连接组件的id
- p和q相互连接的条件:当且仅当id[p] == id[q]
实现代码如下(Java)
public class QuickFindUF
{
private int[] id;
//构造函数 访问N次数组
public QuickFindUF(int N){
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
//判断p、q是否连接,访问两次数组
public boolean connected(int p, int q){
return id[p] == id[q];
}
/*
*把p,q所在的两个连接组件连接起来
*最多访问2N+2次数组
*/
public void union(int p, int q)
{
int pid = id[p];
int qid = id[q];
for (int i = 0; i < id.length; i++)
if (id[i] == pid)
id[i] = qid;
}
}Quick Union
数据结构:
- 长度为N的数组 id[]
说明:
- id[i] 表示节点 i 的父节点
- root(i)表示包含i的树的根节点
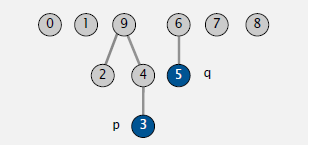
例如
root(3) 的值为9
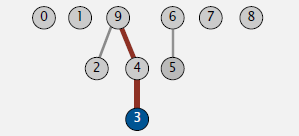
不同于方式一的地方
- find. 判断p和q的根节点是否相同
- union. 让p的根节点指向q的根节点
union(3,5)
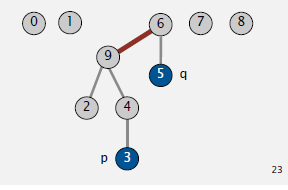
实现代码如下(Java)
public class QuickUnionUF
{
private int[] id;
public QuickUnionUF(int N)
{
id = new int[N];
/*
*让每个节点指向它自己
*访问N次数组
*/
for (int i = 0; i < N; i++)
id[i] = i;
}
/*
*寻找当前节点的根节点
*访问数组的次数取决于树的高度
*/
private int root(int i)
{
while (i != id[i]) i = id[i];
return i;
}
/*
*检测p,q是否具有相同的根节点
*访问数组的次数取决于包含p、q的树的深度
*/
public boolean connected(int p, int q)
{
return root(p) == root(q);
}
/*
*检连接p、q(讲p的根节点指向q的根节点)
*访问数组的次数取决于包含p、q的树的深度
*/
public void union(int p, int q)
{
int i = root(p);
int j = root(q);
id[i] = j;
}
}改进
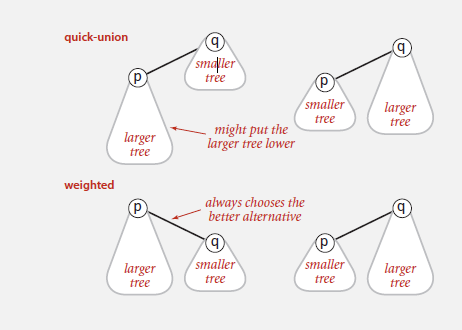
对quick union 加权
quick union 得到的森林可能树会过高,导致效率很低
这时就可以采用Weighted quick-union.
- 保存每棵树的大小(节点数,而非高度)
- 每次union让小的树指向大的树
下面是quick-union 与Weighted quick-union的区别
对一百个节点进行88次union操作,结果如下
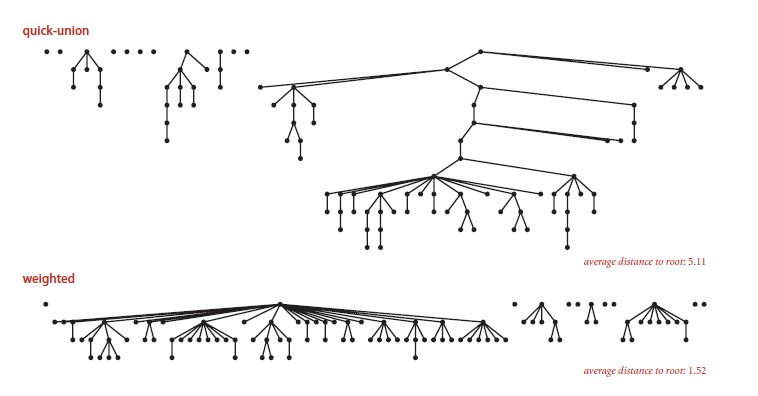
显然,采用Weighted quick-union会使得到的树更加扁平化,加快算法效率
说明:
- 最终结果深度小于lgN
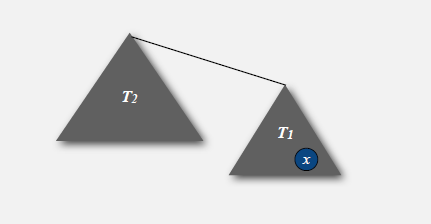
- 父节点的大小大于任一子节点的大小*2;
x的深度小于lgx
|T2 | > 2|T1 |
算法实现(Java)
修改quick-union的两个函数
int sz[];//增加一个数组记录大小
public QuickUnionUF(int N)
{
id = new int[N];
sz = new int[N];
/*
*让每个节点指向它自己
*访问N次数组
*/
for (int i = 0; i < N; i++)
{
id[i] = i;
sz[i] = 1; //初始化大小为1
}
}
public void union(int p, int q)
{
int i = root(p);
int j = root(q);
if (i == j)
return;
//判断两棵树的大小
if (sz[i] < sz[j]){
id[i] = j;
sz[j] += sz[i];
}
else{
id[j] = i;
sz[i] += sz[j];
}
}
路径压缩
每次计算p的根节点后,直接让p指向根节点
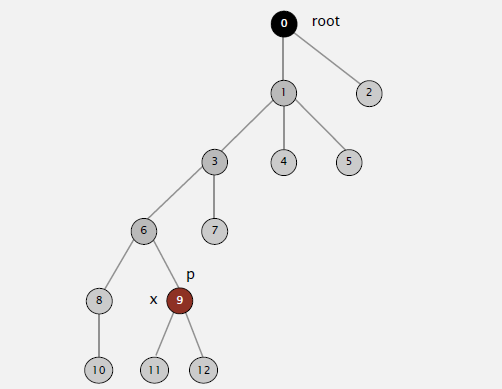
对p节点进行路径压缩
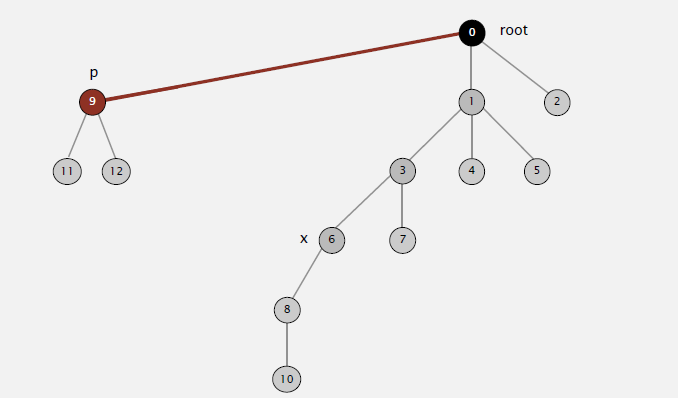
路径压缩可以显著的提高结果扁平化的程度,从而加快算法效率
代码实现(Java)
修改int root(int i)
private int root(int i)
{
while (i != id[i])
{
id[i] = id[id[i]]; //只需要增加这一行代码
i = id[i];
}
return i;
}比较
对包含N个节点的集合进行M次union-find操作
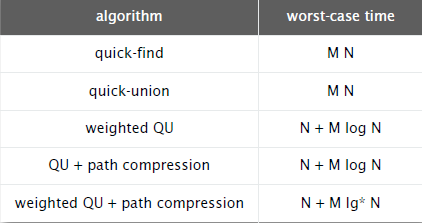















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









