






OO第一单元总结
一、任务概览
在本单元中,我们的任务是写一个程序,处理具有固定文法的表达式字符串,并实现括号展开,合并同类项,自定义函数,三角函数化简,求导等功能,具体内容如下:
| 作业 | 要求 | 示例 |
|---|---|---|
| 1 | 解析幂函数,有前导0的整数,带括号表达式 | (x*x*3*x)**2*x*0100 |
| 2 | 新增三角函数,自定义函数,支持括号嵌套 | 1 f(x)=x*(sin(x)+cos(x)) x-(f(y)+x) |
| 3 | 新增求导算子 | 1 f(x,y)=dx((x+(x+1-x))**2+y) f(sin(x),y)+cos(z) |
二、思路分析
第一次作业
架构

在本次作业中,面向对象的程序设计思路可以让我们“所见即所得”
文法里规定的元素有表达式,项,因子,而因子有三种,分辨是常数,幂函数,表达式,直接根据文法分别建立类
表达式里有若干项,那么表达式类就需要一个容器存储这些项,使用ArrayList即可
项里由有若干因子,那项类就也需要一个容器来存储这些因子,而因子有三种,故需要用一个接口将常数,幂函数,表达式三者统一管理。同样使用ArrayList即可。
解析
刚才考虑的是如何存储数据,接下来需要考虑的是如何将一整个表达式解析成这一系列小单元,即在解析的过程中将这些对象及其嵌套关系构造出来。
经过了上个学期先导课的训练我对递归下降法有了一定的了解,本次依然采用了Lexel词法分析器+Parser语法分析器的模式。这种方法的好处是,文法所规定的各种语法成分的生成方式,刚好和我们解析的顺序是反过来的。每一种语法成分,都对应Parser类里的一个方法,调用完这个函数以后,一定可以返回一个对象用以储存解析到的这个语法成分。
-
例如:项 → [加减 空白项] 因子 | 项 空白项 '*' 空白项 因子,注意到第一个因子前可能有加减号,而后面的因子前面一定是*号,在进入parseTer函数后,首先判断一下有没有加减号,如果有则记录,随即调用parseFactor函数,解析第一个因子,接下来判断是否有*号,如果有,说明后面还跟着一个因子,继续调用parseFactor函数即可
public Term parseTerm() {
Term term = new Term();
if (lexer.check() == "+-") {
term.inverse(lexer.getOp()); //如果读到'-'处理一下系数
}
term.addFactor(parseFactor());
while (lexer.check() == "*") {
lexer.getOp();
term.addFactor(parseFactor());
}
return term;
}对于词法分析器Lexer,其主要有两个功能:
-
外界能够知道当前解析到的词法成分是什么,比如运算符,数字等等
-
可以将当前解析到的词法成分传给外界,传出所有词法成分的过程,实际就是遍历了整个字符串
语法成分是比词法成分更高级的存在,即一个表达式是由许多语法成分组合成的,而一个语法成分则是由许多更简单的词法成分组合而成的。对于整个解析过程,就好比领导层层向下级传递命令,领导不必规划好事情的全部细节,只需将大任务拆分成几个部分,就可以将命令传达给下级,由下级进一步拆分传递,最终传达到最底层时,我们发现真正要做的事其实是很简单的,在这次作业里就是Lexer,只需提取数字,字母,符号即可,将这些简单的成果向上返回,就能组合出一个看起来很复杂的成果。
最终的效果是,解析器中的一系列方法的嵌套关系,和形式化语言所规定的文法的结构,是完全一致的。在输入待解析的表达式后,我们只需要调用一次parseExpr方法,最终返回的Expr对象就是我们解析得到的结果
展开
假设我们已经完成了解析工作,得到了一个Expr型的对象,不妨先来看看他的结构,不难发现其应该是树型的
expr / | \ term term term .... / | \ / | \ / | \ expr const var ......... / | \ term term term .....
我们很难在树型的结构上进行运算,比如乘法,按照上面的结构,应当是两棵树相乘,这是十分复杂的。
而加减乘的运算最好在线性结构上进行,比如
term / | \ const var const .....
两个不含表达式因子的项相乘,只需二重循环遍历所有元素即可,例如 (x+1+y)*(y+z+5)
本次作业中只允许出现xyz三个变量,可以预见的是,最终拆完括号的结果一定是若干个单项式相加的形式
例如
运算中最基本的单元形式为Ax^ay^bz^c,所以可以考虑再开两个新的类,即多项式类和单项式类,用来存储这些基本单元,目标是将树形结构转化为线性结构,多项式用一个ArrayList存储若干单项式,单项式用一个HashMap存储变量名和它所对应的指数,当然还有系数
表达式,项,常数,幂函数都有一个toPoly方法将自身转化为一个Poly类型的对象。
-
对于表达式中的若干项,将转化为若干多项式相加,也就是若干ArrayList的合并,toPoly方法中反复使用addPoly方法,将这些项转化为Poly型对象再相加。
-
对于项中的若干因子,将转化为若干多项式相乘,toPoly方法中反复使用mulPoly方法即可,将这些项转化为Poly型对象再相乘。进一步转化成多项式中的单项式两两相乘,而两个单项式相乘,就是合并两个HashMap,遵循同底数幂相乘,底数不变指数相加的原则。
-
对于表达式的幂,同样是多个Poly相乘的结果,可以写一个powPoly函数,最好可以用快速幂优化一下
-
对于常数和幂函数,它们本身的形式就符合单项式的定义,将其转化成只含一个单项式的Poly对象即可
// 单项式monomial
public class Mono {
private BigInteger coe;
private HashMap<String, Integer> vars;
public Mono(BigInteger coe) {
this.coe = coe;
this.vars = new HashMap<>();
}
public Mono mulMono(Mono mono) {
Mono newMono = new Mono(this.coe.multiply(mono.getCoe()));
......
return newMono;
}
}// 多项式polynomial
public class Poly {
private ArrayList<Mono> monoList;
public Poly() {
this.monoList = new ArrayList<>();
}
public void addMono(Mono mono) {
this.monoList.add(mono);
}
public Poly addPoly(Poly poly) {
......
}
public Poly mulPoly(Poly poly) {
......
}
}注意到树形结构的expr对象,其叶节点一定是一个常数或幂函数,toPoly方法递归调用的过程中一定可以在遇到叶节点时返回。返回的过程中,每一个表达式因子所对应的子树,都被转化成了一个线性结构的Poly对象。
我们对解析得到的最顶层Expr对象调用其toPoly方法,向下递归,最终向上返回到最顶层,整个表达式就被转化成了一个Poly对象,完成了括号的展开。
合并同类项
现在,我们已经得到了一个Poly型对象,作为拆完括号以后得到的表达式
要合并Axaybzc型的单项式,只需判断x,y,z三个变量的指数是否对应相等,指数对应相等则可以相加
可以重写单项式类的hashcode和equals方法,哈希值必须与系数无关,只与各个变量的指数有关,equals方法本质是比较两个变量名-指数的HashMap是否相等,也就是键的集合必须相等,同时同样的元素也必须有相同的值。
而后将一个多项式中的所有单项式依次加入一个HashMap,HashMap以单项式对象为键,以它的系数为值,这样将多项式加入HashMap时,如果发现已经存在该键,证明有同类项,只需改变它所对应的值即系数(系数相加)。将所有元素加入HashMap后再全部取出,取出时依据键所对应的值修改键的系数,就完成了合并。
public Poly mergeMono() {
HashMap<Mono, BigInteger> monos = new HashMap<>();
for (Mono mono : monoList) {
if (monos.containsKey(mono)) {
BigInteger oldCoe = monos.get(mono);
monos.replace(mono, oldCoe.add(mono.getCoe()));
} else {
monos.put(mono, mono.getCoe());
}
}
Poly poly = new Poly();
for (Mono mono : monos.keySet()) {
mono.setCoe(monos.get(mono));
poly.addMono(mono);
}
return poly;
}输出
最终得到的一个没有同类项的Poly多项式,重写多项式和单项式的toString方法以输出,可以做的优化有:
-
如果单项式系数为0,则最终结果为0,
-
如果单项式系数为1和-1,则可以省略系数,简化为x**2或-x**2
-
如果单项式中变量的指数为0,等价于常数1,转化为单项式的时候可以忽略
-
如果单项式中变量的指数为1,则指数部分可以省略
-
如果单项式中变量的指数为2,则x**2可以化简为x*x
-
第一个单项式开头的+号可以省略,考虑交换多项式中单项式的顺序把系数为正的单项式换到前面
第二次作业
架构
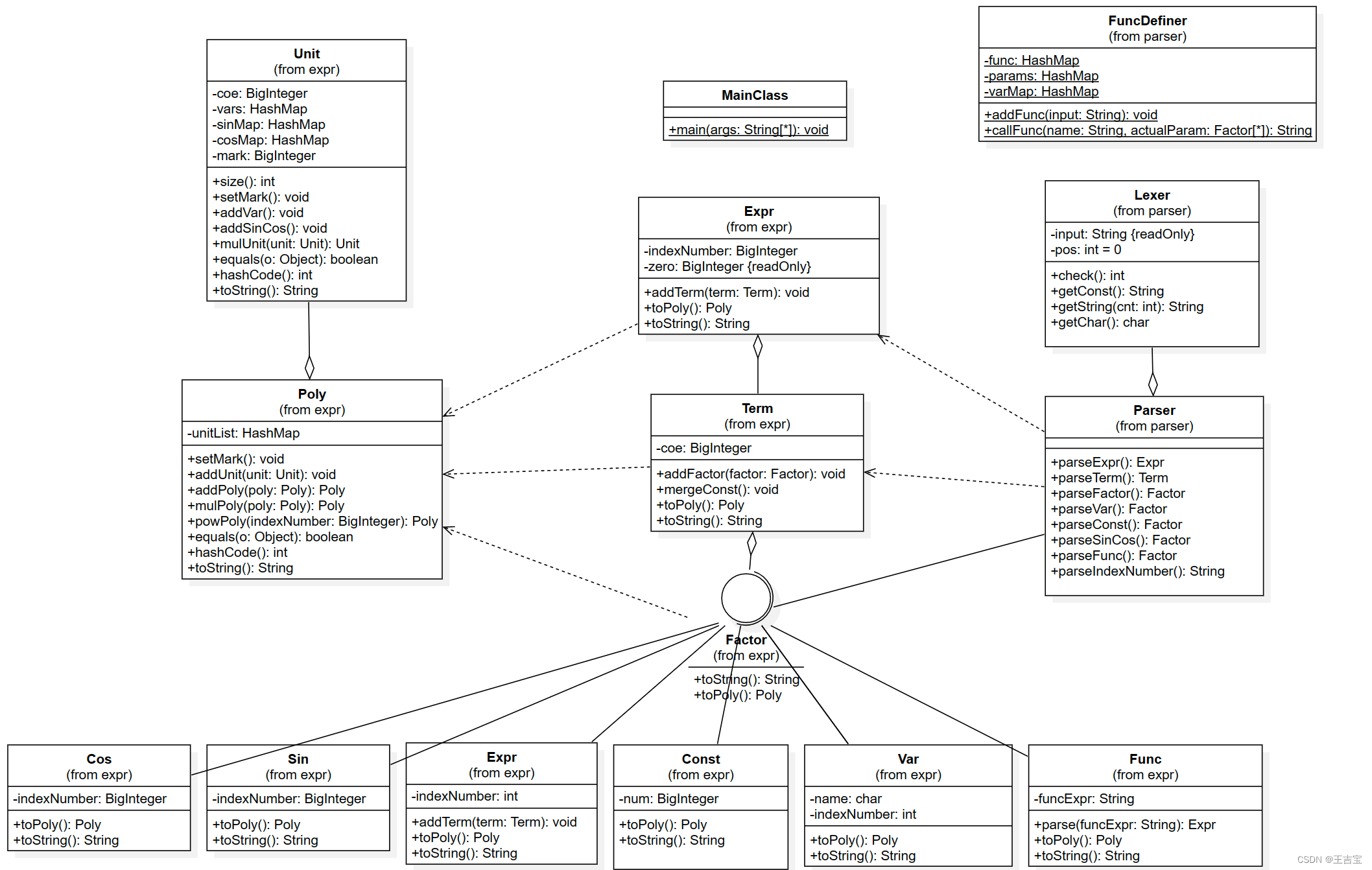
在上次作业的基础上,本次新增了如下需求:
-
嵌套括号
-
解析三角函数
-
定义,解析,调用自定义函数
使用递归下降法可以无视嵌套括号,完全不用修改
解析三角函数,首先需要修改Lexer使其能够识别三角函数,其次需要修改Parser为其增加新的方法,分别解析括号内的因子和括号外的指数。因子和指数唯一确定了一个三角函数因子,据此新建Sin类和Cos类,存储因子和指数,获取三角函数对象。三角函数因子同样作为因子,需要实现接口中的toPoly和toString方法
三角函数内的expr可以直接调用已经实现好的Expr类的toPoly方法
// Sin类,Cos类同理
public class Sin implements Factor {
private Factor factor;
private BigInteger indexNumber;
public Sin(Factor factor, String indexNumber) {
this.factor = factor;
this.indexNumber = new BigInteger(indexNumber);
}
@Override
public Poly toPoly() {
...
}
@Override
public String toString() {
...
}
}解析自定义函数,首先处理函数的定义,对每种自定义函数,我们首先要存储函数名,函数的形参,以及对应的表达式,我的做法是建立一个静态类,其含有两个方法:
-
addFunc,传入一整个函数定义式,解析出函数实参和表达式,存入两个HashMap,键都为函数名,值分别为实参列表和函数表达式
-
callFunc,接收函数名和实参列表,将原函数表达式中的形参替换为实参,将替换好的表达式字符串传回给parser再进行解析
public class FuncDefiner {
private static HashMap<String, String> func = new HashMap<>();
private static HashMap<String, ArrayList<String>> params = new HashMap<>();
private static HashMap<String, String> varMap = new HashMap<>();
public static void addFunc(String input) {
...
}
public static String callFunc(String name, ArrayList<Factor> actualParam) {
String expr = func.get(name);
ArrayList<String> formalParam = params.get(name);
for (int i = 0; i < formalParam.size(); i++) {
expr = expr.replaceAll(formalParam.get(i), actualParam.get(i).toString());
}
return expr;
}
}计算
展开括号的过程与第一次作业无异,在顶层调用toPoly方法即可
但在此次作业中,最基本的项不再是Ax^ay^bz^c,而是
$$
Ax^ay^bz^c\prod_{i}sin(Factor_i)^p\prod_{i}cos(Factor_i)^q
$$
每一个三角函数因子,都有一个Poly作为括号内的因子,和一个BigInteger型的数作为指数
新的基本项由于不再符合单项式的定义改名为Unit
public class Unit {
private BigInteger coe;
private HashMap<String, BigInteger> vars;
private HashMap<Poly, BigInteger> sinMap;
private HashMap<Poly, BigInteger> cosMap;
...
}多项式的相关计算依然被转化成两个Unit类型的计算,对于乘法,实际上要实现的是三个HashMap的合并
仍然遵循键相等,则值相加的原则
注意到Unit里的HashMap是以Poly为键的,因此我们还需要重写Poly类的hashcode和equals方法
合并
在这次作业中,我稍微修改了合并同类项的时机
上次作业中,我在得到了输入表达式完整的Poly对象后,才进行合并同类相的操作,Poly用一个ArrayList来存储所有的Mono
在这次作业中,我将ArrayList更改为HashMap,维护Unit对象到其系数的映射,将合并同类项的操作融入到Poly类中的若干计算方法中,例如每加入一个Unit,就判断一下能否合并
public class Poly {
private HashMap<Unit, BigInteger> unitList;
public Poly() {
this.unitList = new HashMap<>();
}
...
}
输出
本次可以做的优化有:
-
三角函数内的因子不是表达式,可以省略一层括号
-
三角函数内表达式的符号可以提出来,有可能减小长度
-
二倍角,平方和
-
sin(0)=0,cos(0)=1
三角函数的优化可以在两个三角函数类内都实现一个类型转换的方法,将Sin转换为Cos,Cos转为Sin
对于平方和:
-
对于一个多项式poly,遍历每一个单项式的每一个三角函数因子,若其次数大于等于2,将其取出,将该三角函数的因子类型转换为另一种三角函数因子,利用HashMap寻找有没有与其匹配的项,如果有,则可以优化,将合并后的结果存存回,终止此次遍历。
-
重新开始一次遍历,如果还存在可以合并的项则继续合并,如果没有则结束。
对于二倍角:
-
遍历sinMap,利用类型转换函数寻找有没有与其能够合并的cos项。
第三次作业
架构
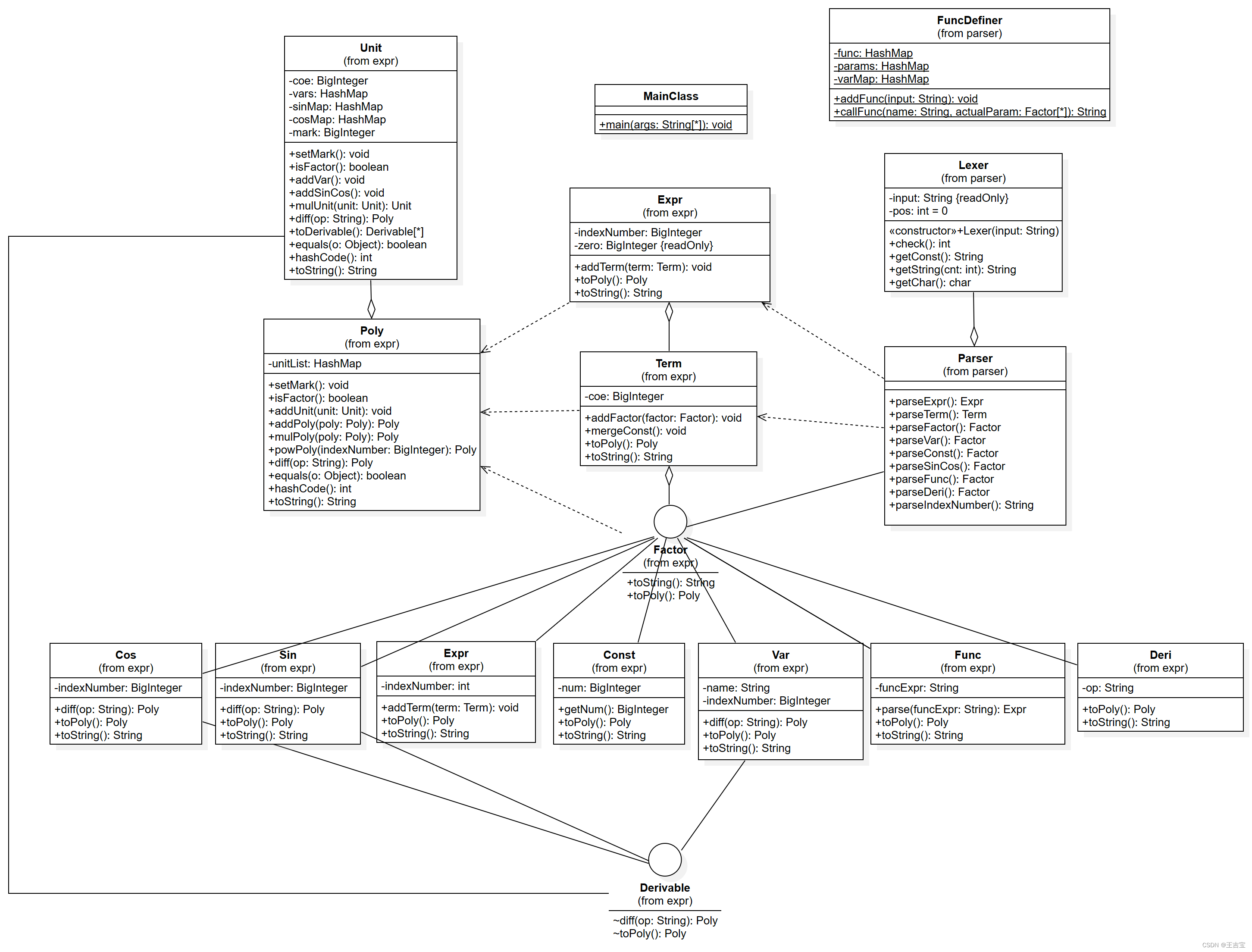
在上次作业的基础上,本次新增了如下需求:
-
函数定义时也可以调用其它函数,可以存在求导因子,要求先求导再代入
-
求导因子
对于函数定义,可以先将定义式解析,直接存储化简后的函数定义式,并处理求导因子,这样调用函数时继续沿用上一次的做法即可
对于求导,求导因子携带的信息包括括号内的表达式和待求导的变量,新建类分别存储,用Factor管理
public class Deri implements Factor {
private String op;
private Expr expr;
public Deri(String name, Expr expr) {
this.op = name.substring(1);
this.expr = expr;
}
@Override
public Poly toPoly() {
return expr.toPoly().diff(op);
}
@Override
public String toString() {
...
}
}这个类的toPoly方法依旧先将其expr表达式转换为Poly,并在此基础上求导,返回的仍是一个Poly
对多项式求导,就是对其中每一个Unit求导,每一个Unit都是幂函数和三角函数的积,依据求导法则
$$
[f(x)g(x)]′=f′(x)g(x)+f(x)g′(x)
$$
发现此时Unit并不是求导计算所需要的最小单元,Unit中的项还需要进一步拆分,可以求导的基础单位有:
-
常数
$$
(const)'=0
$$
-
幂函数
$$
(x^k)'=kx^{k-1}
$$
-
三角函数
$$
(sin(Factor)^k)'=ksin(Factor)^{k-1}cos(Factor)(Factor)' \\ (cos(Factor)^k)'=-kcos(Factor)^{k-1}sin(Factor)(Factor)'
$$
因此,这三个类需要用接口Derivable统一管理,实现求导方法diff,求导的结果仍是Poly
Poly类的求导结果,就是若干个Unit求导结果的和
// Poly
public Poly diff(String op) {
Poly poly = new Poly();
for (Unit unit : unitList.keySet()) {
poly = poly.addPoly(unit.diff(op));
}
return poly;
}Unit类的求导结果,首先先将其中的若干函数分离开来,再按照乘法法则计算,双重循环遍历待求导列表,每次只求一个因子的导,剩下的因子不求导直接与之相乘,得到一项,将所有的项相加即可
// Unit
public ArrayList<Derivable> toDerivable() {
ArrayList<Derivable> factors = new ArrayList<>();
for (String name : vars.keySet()) {
Derivable var = new Var(name, vars.get(name));
factors.add(var);
}
for (Poly sinPoly : sinMap.keySet()) {
Derivable sin = new Sin(sinPoly, sinMap.get(sinPoly));
factors.add(sin);
}
for (Poly cosPoly : cosMap.keySet()) {
Derivable cos = new Cos(cosPoly, cosMap.get(cosPoly));
factors.add(cos);
}
return factors;
}
public Poly diff(String op) {
Poly ans = new Poly();
ArrayList<Derivable> factors = toDerivable();
for (int i = 0; i < factors.size(); i++) {
Poly poly = new Poly();
poly = poly.addPoly(factors.get(i).diff(op));
... //系数不参与求导,直接乘到Poly上
for (int j = 0; j < factors.size(); j++) {
if (j != i) {
poly = poly.mulPoly(factors.get(j).toPoly());
}
}
ans = ans.addPoly(poly);
}
return ans;
}之后按照公式分别实现常数,幂函数,三角函数类的求导方法diff即可
这次作业的工作量不大,其余部分几乎不需要修改
三、可能的问题
完成第二次作业的过程中我遇到了不少bug
函数调用:
考虑如下数据
1 f(x,y,z)=x*y+z f(y,x,z)
按照上面给出的做法,首先将第一个形参替换成第一个实参,也就是把x替换成y,函数表达式变成y*y+z
接下来替换第二个形参,也就是将表达式中所有的y替换成x,函数表达式变成x*x+z,出现bug
原因在于已经代入的实参仍有可能被替换
由于作业中规定变量名只可能是xyz,不妨将原始函数表达式中的xyz替换成uvw
如此,带入的实参中不可能含有uvw,也就不会出现重复替换的情况
函数替换
这是本次作业中最严重的一个bug,也是提交后唯一的bug,但有些弱智,,,,
例如:
1 f(x)=x**2 f(x**2) 替换后结果:x**2**2
原因是:我重写了用以存储解析结果的类的toString方法,来查看解析结果是否正确,为了化简输出,我省略了括号,0,1次幂等等信息,方便查看。而我在调用函数实参替换时,用了这个toString方法,导致生成的表达式不符合文法,解析错误。
解决办法是多加一层括号。
三角函数内的Poly:
上次作业中,我们重写了Mono类的hashcode,判断同类相是不需要判断系数的,因此hashcode不是系数的函数
但在本次作业中,要想两个合并Unit,就需要判断两个三角函数因子是否可以合并
比如sin(x)和sin(2x)是不能合并的,但对于三角函数括号内的Poly,按照上次的方法,不去考虑系数,计算出的hashcode是相同的,两者会被判定为可以合并,出现了bug
原因在于,当Poly作为三角函数括号内的因子时,要想合并,就要保证两个Poly是完全相同的,此时,是要考虑Poly里所有Unit的系数的,否则,一旦x+2*x**2和3*x+4*x**2被判定为同样的Poly,合并时就会出错
解决办法是为Unit类增加一个标志,当调用三角函数类内的toPoly方法时,必须标记Poly内的所有Unit,这些Unit是三角函数内的因子,并更改其计算hashcode的方法,将标志同等的作为hashcode的参数
// 不在三角函数里,mark=null, 否则mark=系数
@Override
public int hashCode() {
return Objects.hash(mark, vars, sinMap, cosMap);
}为Poly类和Unit类都增加一个setMark方法
// Poly
public void setMark() {
for (Unit unit : unitList.keySet()) {
unit.setMark();
}
}
// Unit
public void setMark() {
this.mark = this.coe;
}发现原有的bug解决了,不该合并的的确不会合并了,但应当合并的多项式却无法合并了
以sin(x)+sin(x)为例,这两个sin(x)都存储在sinMap中,键均为多项式'x',值均为1,
初始状态:
初始:两个完全相等的poly中各有一个unit,现在需要将两个poly合并,实际上就是判断两个unit是否能合并 poly: sin(x) |-keyset |-unit //待比较unit |-vars空 |-sinMap | |-(poly->1) | |-keyset | |-poly //setMark作用在这个poly上 | |-keyset | |-unit | |-vars(x->1) | |-sinMap空 | |-cosMap空 |-cosMap空
equals方法会逐层比较两个unit直到setMark作用的那个poly上,我直接用了自带的HashMap.keySet.equals()方法,去比较两个keySet是否相同。
java自带的方法中,需要遍历另一个keySet中的元素,依次判断这些元素是否在当前keySet中
// AbstractSet.java
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))
return false;
Collection<?> c = (Collection<?>) o;
if (c.size() != size())
return false;
try {
return containsAll(c); // 元素个数相等的情况下,是否"containsAll"
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}// AbstractCollection.java
public boolean containsAll(Collection<?> c) {
for (Object e : c)
if (!contains(e)) //返回false
return false;
return true;
}经过调试,发现当前集合中的唯一元素,与待比较元素的hashcode一样,且equals方法返回true,但contains方法依旧返回false。
原因是HashMap的keySet里的元素被加入HashMap时,应当会依据hashcode确定位置,但setMark这一操作改变了元素计算hashCode方式,hashcode改变,新的hashcode所对应的位置是没有元素的,取不出来任何东西,因此contains返回false,表示不包含该元素
解决方法就是把HashMap里的元素取出来,开一个新的HashMap,再装回去,这样就会依据新的hashcode确定位置了
public void setMark() {
for (Unit unit : unitList.keySet()) {
unit.setMark();
}
HashMap<Unit, BigInteger> newUnitList = new HashMap<>();
for (Unit unit : unitList.keySet()) {
newUnitList.put(unit, unitList.get(unit));
}
unitList = newUnitList;
}四、复杂度分析
使用Metrics插件计算了类中方法的复杂度,在这里我只统计统计了第三次作业中Parser,Lexer,Funcdefiner,Poly,Unit五个类中的方法。
三次作业的难度复杂度是递增的,且解析,计算部分方法的复杂度最高,其余类基本只用作存储,复杂度很低,没什么统计的必要
代码总规模:871行,15个类,2个接口
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expr.Poly.Poly() | 0 | 1 | 1 | 1 |
| expr.Poly.addPoly(Poly) | 2 | 1 | 3 | 3 |
| expr.Poly.addUnit(Unit) | 2 | 1 | 2 | 2 |
| expr.Poly.diff(String) | 1 | 1 | 2 | 2 |
| expr.Poly.equals(Object) | 3 | 3 | 2 | 4 |
| expr.Poly.equalsZero() | 0 | 1 | 1 | 1 |
| expr.Poly.hashCode() | 0 | 1 | 1 | 1 |
| expr.Poly.isFactor() | 3 | 3 | 3 | 3 |
| expr.Poly.mulPoly(Poly) | 3 | 1 | 3 | 3 |
| expr.Poly.powPoly(BigInteger) | 3 | 1 | 3 | 3 |
| expr.Poly.setMark() | 2 | 1 | 3 | 3 |
| expr.Poly.toString() | 3 | 3 | 3 | 4 |
| expr.Unit.Unit(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Unit.addSinCos(int, Poly, BigInteger) | 3 | 1 | 3 | 4 |
| expr.Unit.addVar(String, BigInteger) | 2 | 1 | 3 | 3 |
| expr.Unit.diff(String) | 6 | 1 | 4 | 4 |
| expr.Unit.equals(Object) | 3 | 3 | 3 | 5 |
| expr.Unit.getCoe() | 0 | 1 | 1 | 1 |
| expr.Unit.hashCode() | 0 | 1 | 1 | 1 |
| expr.Unit.isFactor() | 4 | 4 | 3 | 4 |
| expr.Unit.mulUnit(Unit) | 6 | 1 | 7 | 7 |
| expr.Unit.setCoe(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Unit.setMark() | 0 | 1 | 1 | 1 |
| expr.Unit.size() | 0 | 1 | 1 | 1 |
| expr.Unit.toDerivable() | 3 | 1 | 4 | 4 |
| expr.Unit.toString() | 36 | 3 | 17 | 17 |
| parser.FuncDefiner.addFunc(String) | 1 | 1 | 2 | 2 |
| parser.FuncDefiner.callFunc(String, ArrayList<Factor>) | 1 | 1 | 2 | 2 |
| parser.Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| parser.Lexer.check() | 19 | 13 | 9 | 22 |
| parser.Lexer.getChar() | 0 | 1 | 1 | 1 |
| parser.Lexer.getConst() | 2 | 1 | 3 | 3 |
| parser.Lexer.getString(int) | 0 | 1 | 1 | 1 |
| parser.Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| parser.Parser.parseConst() | 1 | 1 | 2 | 2 |
| parser.Parser.parseDeri() | 0 | 1 | 1 | 1 |
| parser.Parser.parseExpr() | 1 | 1 | 2 | 2 |
| parser.Parser.parseFactor() | 7 | 6 | 7 | 7 |
| parser.Parser.parseFunc() | 1 | 1 | 2 | 2 |
| parser.Parser.parseIndexNumber() | 4 | 2 | 3 | 3 |
| parser.Parser.parseSinCos() | 1 | 1 | 1 | 2 |
| parser.Parser.parseTerm() | 3 | 1 | 4 | 4 |
| parser.Parser.parseVar() | 0 | 1 | 1 | 1 |
标黄的几个方法复杂度较高,已经用高亮标出,观察后发现主要是由于其中if-else分支太多
-
Unit.isFactor()方法是为了判断能否省去三角函数因子内的那层括号,如果符合因子的定义,如x, x**2等直接写sin(x),sin(x**2)即可。里面有一些判断,并不复杂,函数总共才8行
-
Unit.toString()方法复杂度很高,这是因为Unit里存储着幂函数和三角函数,都需要转化为字符串,而输出的过程中还要加各种判断优化减小输出长度,sin和cos的输出除了函数名不同其它完全一致,我直接双倍码量,最终该函数接近60行。可以考虑拆一拆
-
Lexer.check()方法作用是词法分析器对外传递当前解析到了什么词法成分。例如当前字符为加减号返回1,乘号返回2,数字返回3等等,需要大量的if-else判断。我使用整数作为返回值,可以改成枚举型变量,可读性更好。
-
Parser.parseFactor()方法的作用是解析各种因子,文法中规定的因子有表达式,常数,三角函数,求导等等,同样需要较多if-else判断,造成复杂度比较高。
五、测试方法
采用随机数据生成器+python sympy化简对比搭建评测机
关于生成数据:
生成数据和解析很相似,要生成表达式,就要生成若干项,要生成项,就要生成若干因子......一步步递归下去就可以返回表达式
我造的数据感觉不是很强,很多都是无效测试,需要手工构造一些坑点再随机
别人的bug大多来自于优化,如sin(0)**0等,可以多测试优化相关的部分,构造一些优化/不优化具有明显区别的数据
public class MainClass {
public static final Random random = new Random();
public static boolean hasBracket = false;
public static void main(String[] args) {
for(int i=1;i<=100;i++) {
System.out.println(getExpr());
}
}
public static String getExpr() {
StringBuilder sb = new StringBuilder();
int cnt = random.nextInt(4) + 1;
sb.append(getAddSub(3) + getEmpty() + getTerm());
for (int i = 2; i <= cnt; i++) {
sb.append(getEmpty() + getAddSub(2) + getEmpty());
sb.append(getTerm());
}
return sb.toString();
}
public static String getTerm() {
StringBuilder sb = new StringBuilder();
int cnt = random.nextInt(4) + 1;
sb.append(getAddSub(3) + getEmpty() + getFactor());
for (int i = 2; i <= cnt; i++) {
sb.append(getEmpty() + "*" + getEmpty());
sb.append(getFactor());
}
return sb.toString();
}
public static String getFactor() {...}
public static String getEmpty() {...}
public static String getAddSub() {...}
public static String getConst() {...}
public static String getVar() {...}
public static String getExp() {...}
......
}关于自动测试:
sympy包中有expand,simplify,diff等等函数,可以形式化计算表达式,用来生成标准输出。两个表达式相减为0说明相等。主要手段就是命令行+jar包+sympy
关于生成jar:
#!/bin/bash
# 当前目录下有src文件夹,里面存有源码
# 主类名:MainClass
# jar包名:my.jar
mkdir -p classes/
rm -rf classes/*
find ./src/ -name "*.java"
javac -encoding utf8 -d ./classes `find ./src/ -name "*.java"`
jar cvfe my.jar MainClass -C ./classes .六、心得体会
-
一个良好的架构可以避免很多麻烦,比较容易定位错误
-
使用java自带的一些函数要小心,最好看看具体机制
-
不一定要无脑全部深克隆
-
优化<<正确性















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









