









RCNN
rcnn论文地址:https://arxiv.org/pdf/1311.2524
详细的理论学习:1.1Faster RCNN理论合集_哔哩哔哩_bilibili
论文概述
该篇论文 focuses on 两个问题:
1. 用深度网络定位物体(localizing objects with a deep network)
2. 用少量数据训练一个高精度模型(training a high-capacity model with only a small quantity of annotated detection data)
两个keys:
1. 应用cnn到候选区域(apply high-capacity convolutional neural networks (CNNs) to bottom-up region proposals in order to localize and segment objects)
2. 预训练+微调的方法(supervised pre-training for an auxiliary task, followed by domain-specific fine-tuning)
面临的挑战
1. 难以使用滑动窗口的方法
(In order to maintain high spatial resolution, these CNNs typically only have two convolutional and pooling layers. We also considered adopting a sliding-window approach. However, units high up in our network, which has five convolutional layers, have very large receptive fields (195 × 195 pixels) and strides (32×32 pixels) in the input image, which makes precise localization within the sliding-window paradigm an open technical challenge.)
CNN结构为了保持高空间分辨率,通常只包含两层卷积和池化层。因为越往后层,感受野越大,而且每经过一次池化,都会逐层减少空间分辨率。可以理解为如果卷积层过多,则高层特征对应的原始图像区域过大。就是相当于,你认为该神经元已经检测到了目标,但是实际上这个神经元对应原图很大的范围,无法进行局部精准定位。
下图的卷积操作有三个通道,padding为1,两个卷积核,每个卷积核都有一个偏置值,步长为2:
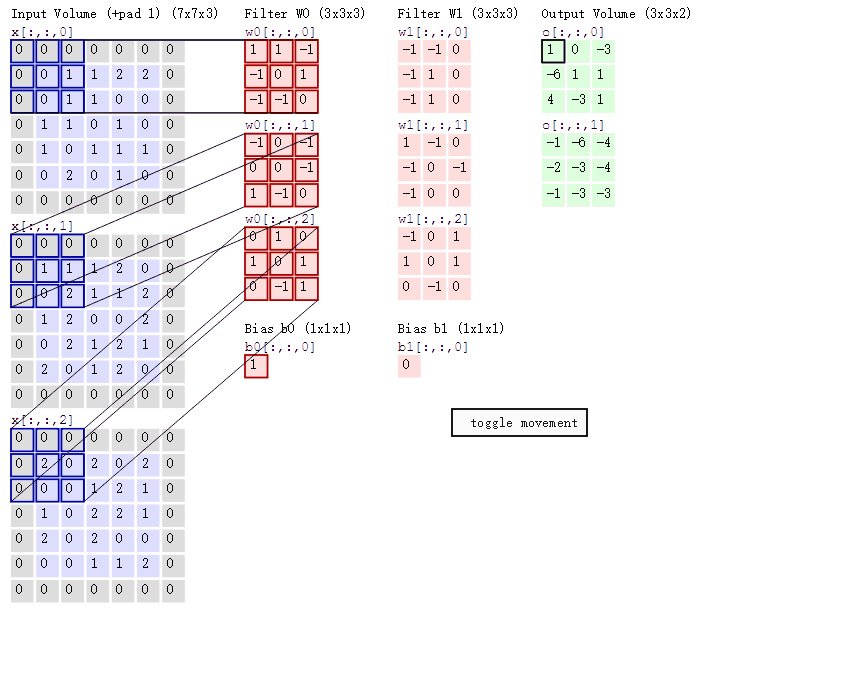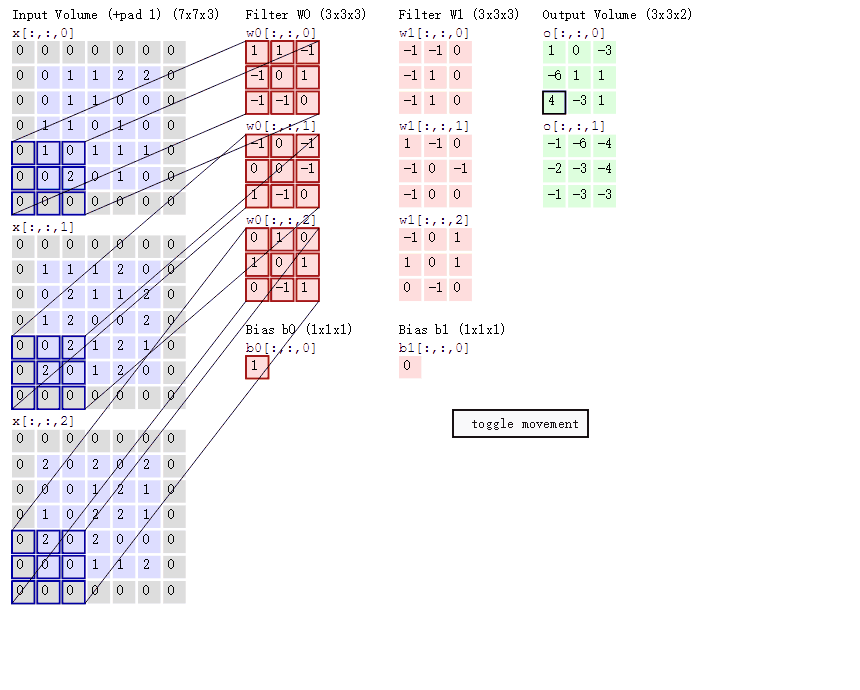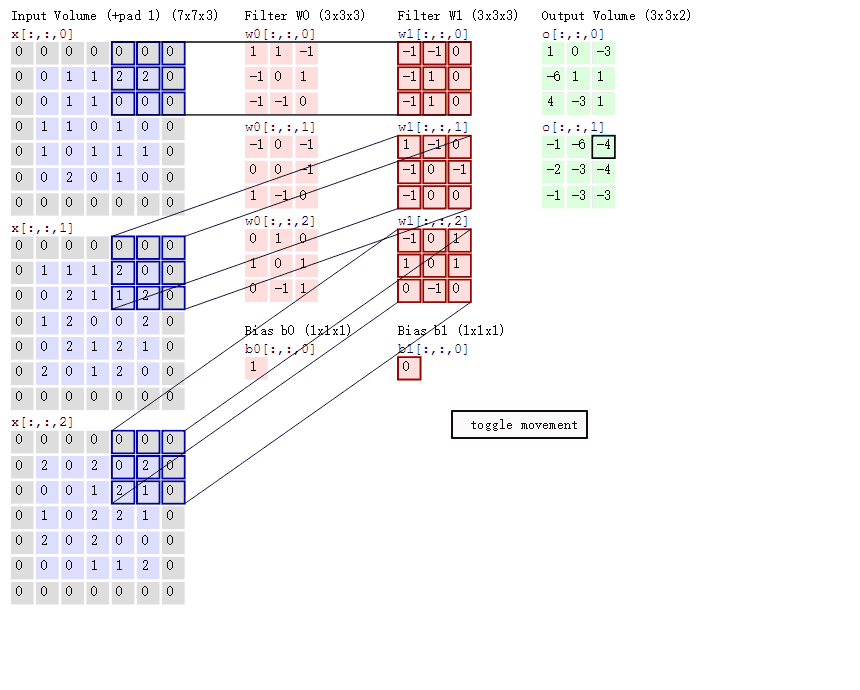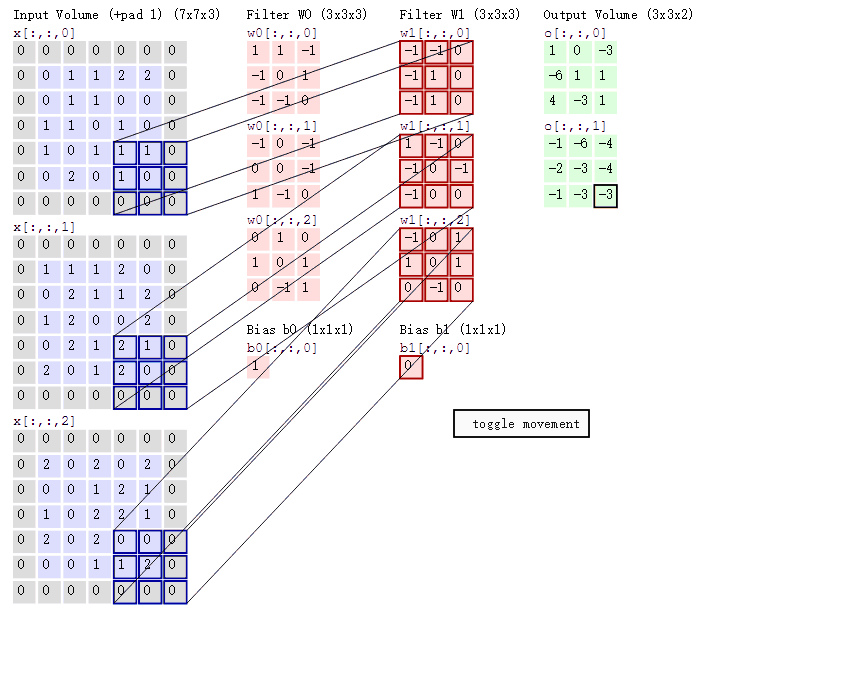
作者也考虑过使用滑动窗口,但是,该研究的CNN结构有五层卷积层,使得感受野很大(一个神经元对应195 × 195 像素);而且步长很大(32 × 32 像素),也就是说网络的某个高层神经元每次移动时,相当于在原始输入图像上跳跃 32 像素,这会导致精准定位目标变得很困难。
解决方法:候选区域内做卷积
2. 数据少,不足以支撑训练一个大的cnn网络
(A second challenge faced in detection is that labeled data is scarce and the amount currently available is insufficient for training a large CNN.)
解决方法:预训练+微调+边界框回归方法
(we demonstrate that a simple bounding-box regression method significantly reduces mislocalizations)
方法
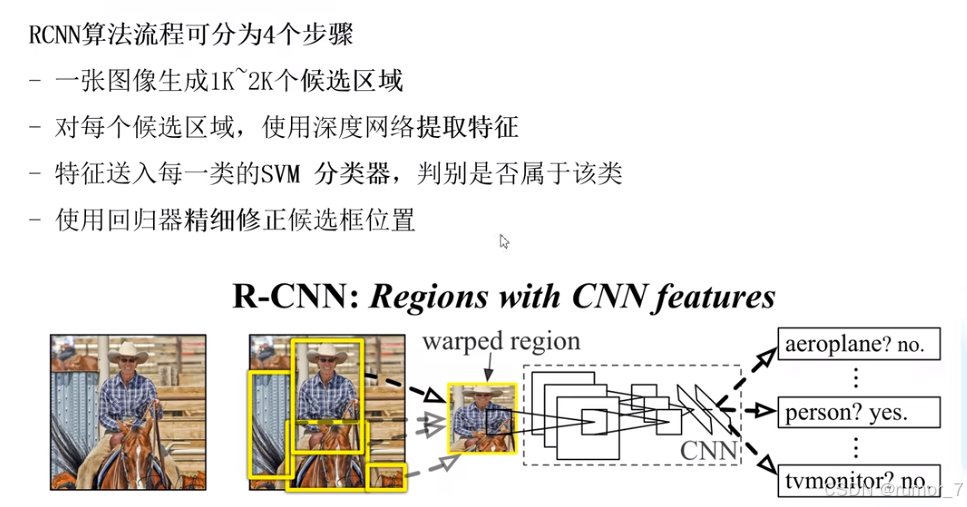
系统由三个模块组成。第一个模块是用来生成若干个与目标类别无关的候选区域。第二个模块从每一个候选区域中提取固定长度特征向量的深度神经网络。第三个模块是一组与具体目标类别相关的线性支持向量机。(Our object detection system consists of three modules. The first generates category-independent region proposals.The second module is a large convolutional neural network that extracts a fixed-length feature vector from each region. The third module is a set of classspecific linear SVMs.)
生成候选区域

(we use selective search to enable a controlled comparison with prior detection work)
特征提取

在直接缩放之前,RCNN 先对候选区域的边界框进行扩展,在四周添加 p=16 像素的背景,以保留一定的上下文信息。而后,对拓展后的候选区域进行仿射变换,统一缩放到227*227像素大小,候选区域的大小和形状不必相同。warping操作可以采用双线性插值等方法。
(first convert the image data in that region into a form that is compatible with the CNN (its architecture requires inputs of a fixed 227 × 227 pixel size).Regardless of the size or aspect ratio of the candidate region, we warp all pixels in a tight bounding box around it to the required size.Prior to warping, we dilate the tight bounding box so that at the warped size there are exactly p pixels of warped image context around the original box (we use p = 16).)
而后将拓展后的候选区域输入图像分类器(cnn去掉了全连接层)获取4096维特征。
2000个候选框则得到2000*4096矩阵,每一行分别代表每个候选框的特征。
SVMs判断类别
在测试时间阶段,先用fast mode的selective search方法提取候选框,而后使用CNN提取特征,最后,对于每个类别使用训练好的SVMs打分。
(We warp each proposal and forward propagate it through the CNN in order to compute features. Then, for each class, we score each extracted feature vector using the SVM trained for that class.)
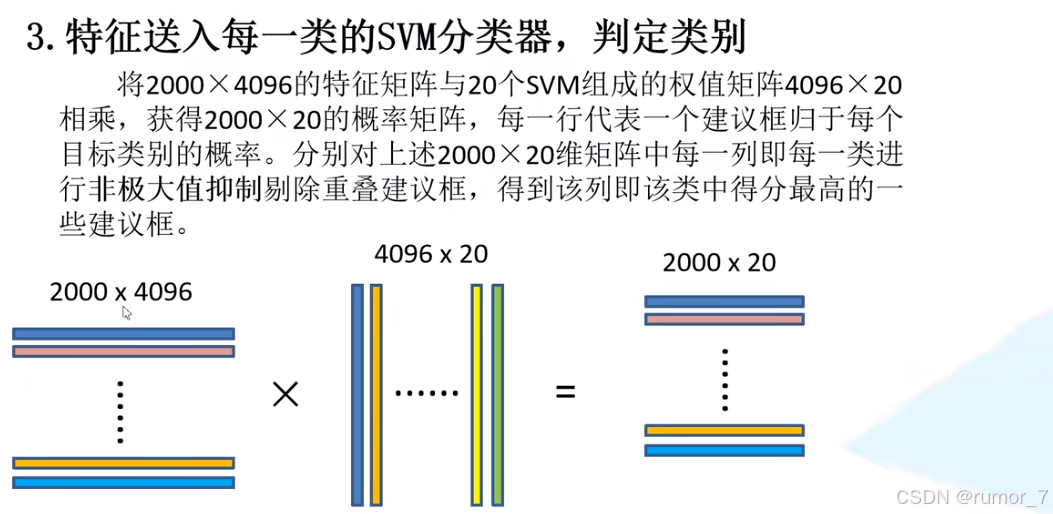
权重矩阵(4096*20)中每一列代表某一类型的权重,20表示有20个类。相乘的结果为2000*20,第 i 行第 j 列的那个元素代表第 i 个候选框为 j 类别的概率。所以每一行的元素,即,该候选框分别是这20个类的概率。
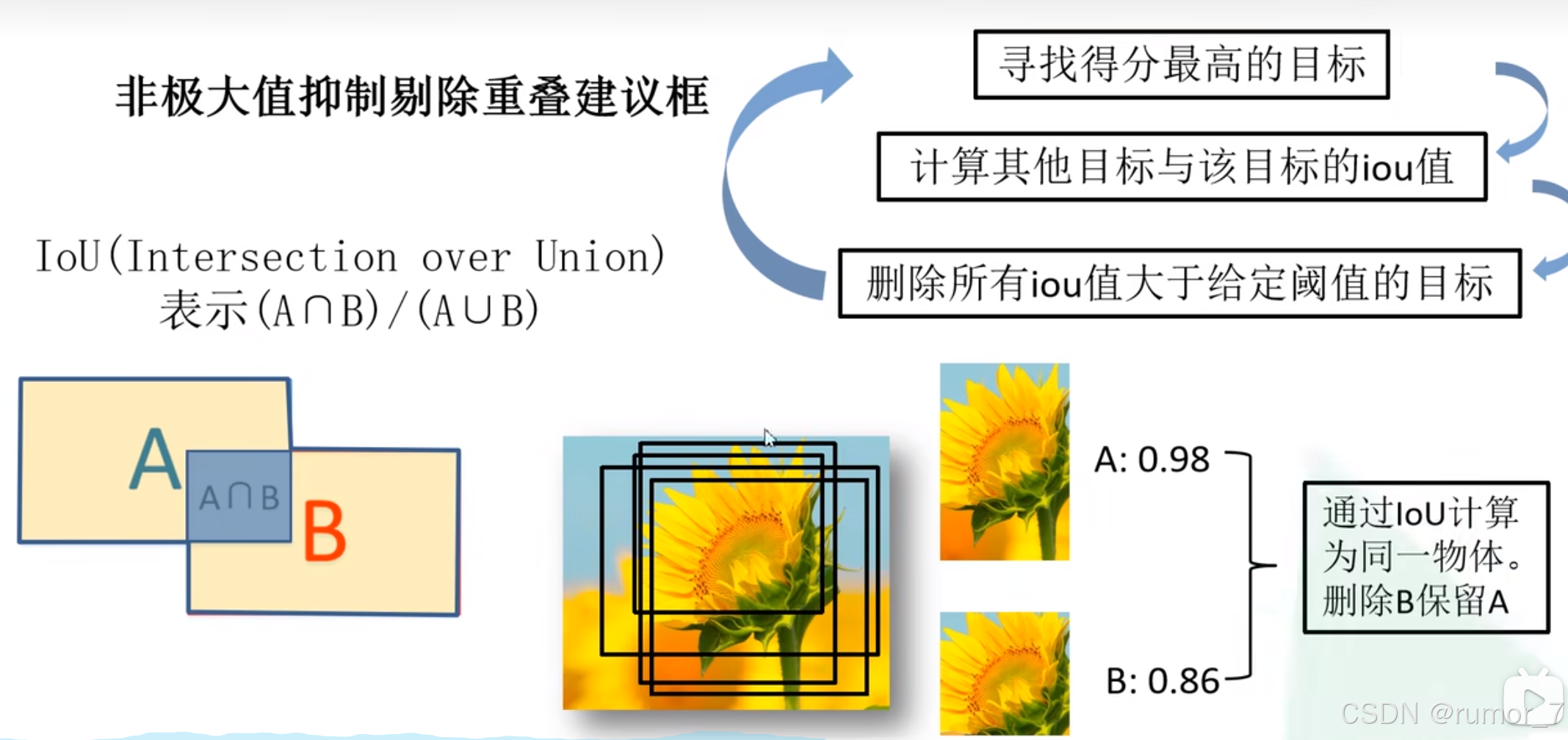
对于图片中所有打分了的候选区域,按照贪婪非极大抑制(NMS)方法,如果该区域的交并比(IoU)大于阈值,则移除该区域。
(Given all scored regions in an image, we apply a greedy non-maximum suppression (for each class independently) that rejects a region if it has an intersection-overunion (IoU) overlap with a higher scoring selected region larger than a learned threshold.)
IoU(intersection over union)交并比。详细步骤见文末“补充-非极大抑制(NMS)方法”

局限性

具体理解:
1. 测试速度慢:候选框之间大量重叠,在计算候选框的特征向量时,对重叠区域进行多次卷积操作。(在faster rcnn被优化了)
2. 训练速度慢:需要训练图像分类网络,svm分类器和bbox回归器。
3. 训练所需空间大:先每个图像的每个候选框的特征信息提取,再保存到电脑的磁盘中,再利用特征信息单独训练分类器和回归器。硬盘占用大。
补充
SVM (Support Vector Machines)
【数之道】支持向量机SVM是什么,八分钟直觉理解其本质_哔哩哔哩_bilibili
16. Learning: Support Vector Machines (youtube.com)
Karush-Kuhn-Tucker (KKT)条件 - 知乎 (zhihu.com)
二分类模型,为使“几何间隔最大化”。即在量化两类数据差异时,选择差异最大的分割方法。
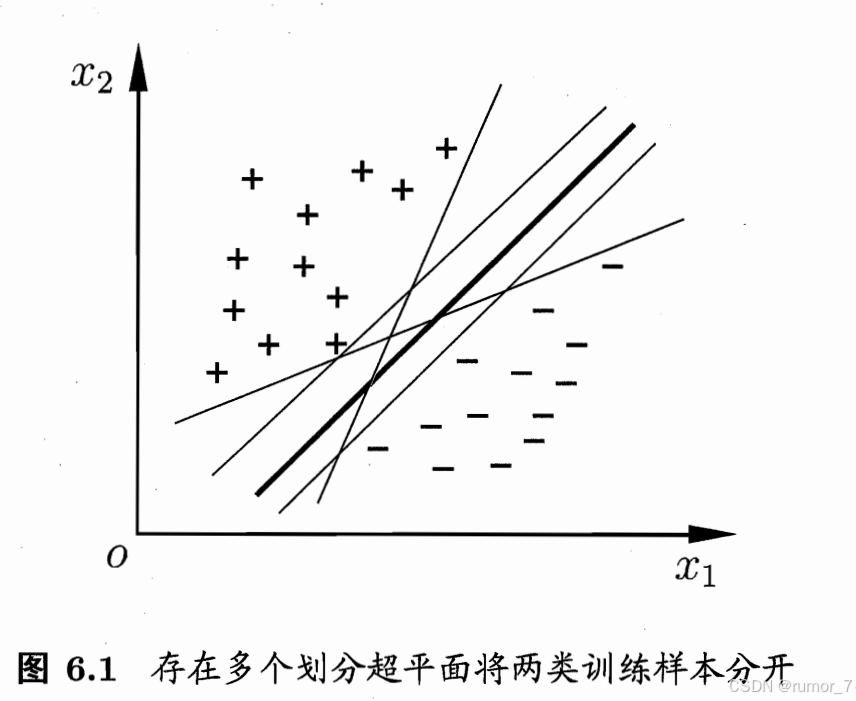
对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
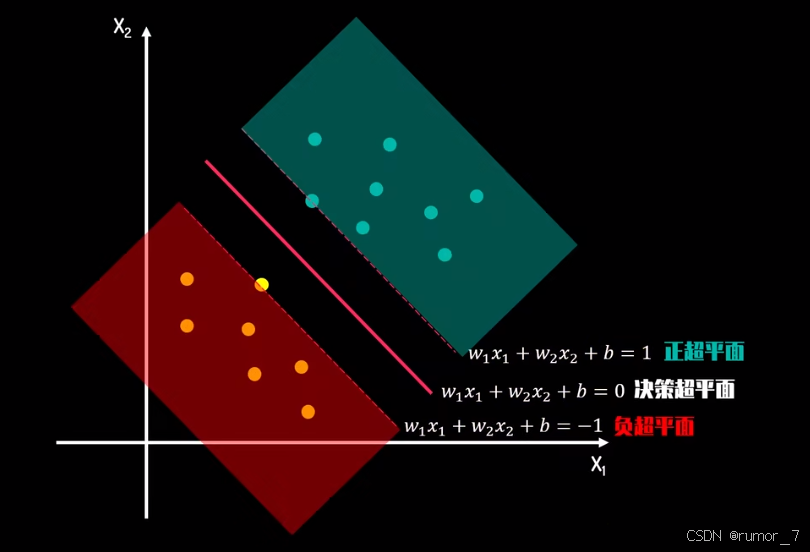
划分超平面可被法向量w和位移b确定。
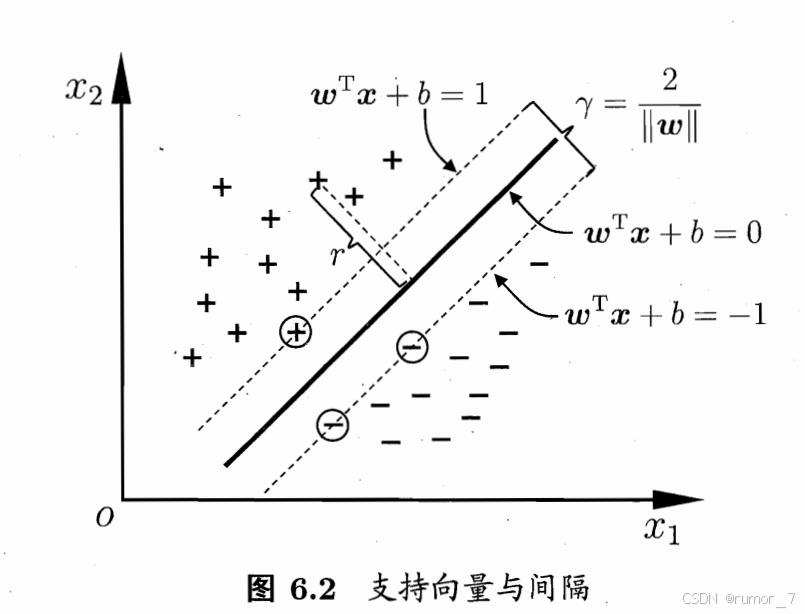
目的是求解w与b。
图中边界的点为支持向量。
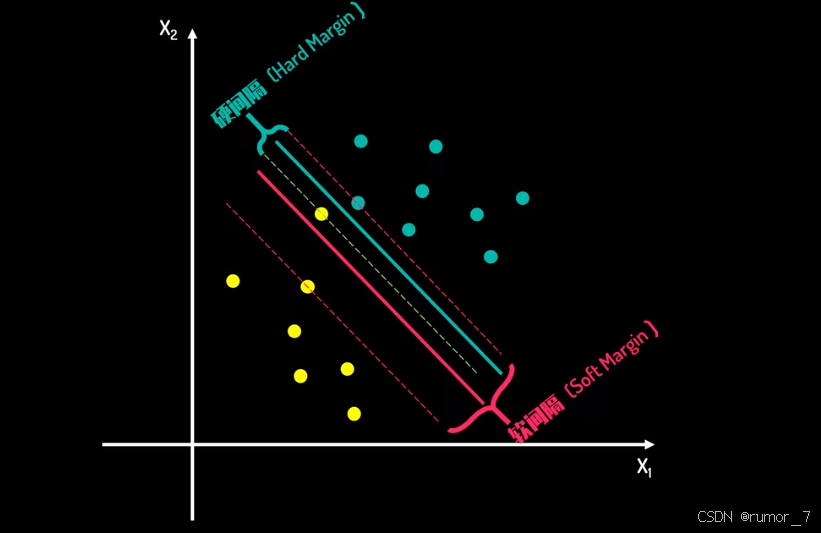
剔除异常点后的间隔为软间隔,将异常点考虑进入的是硬间隔。
样本空间中任意点x 到超平面( w ,b) 的间距 可写为
![]() (即直接代入点到直线的距离公式,
(即直接代入点到直线的距离公式,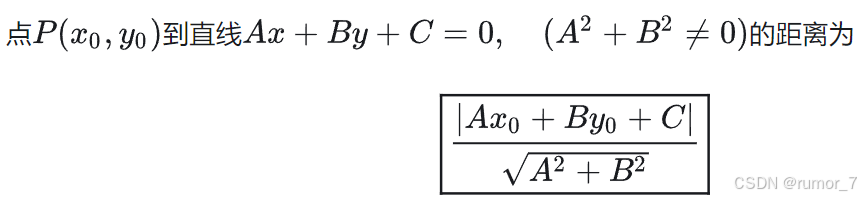 ),所以两个超平面直接的间隔为
),所以两个超平面直接的间隔为![]() 。
。
最大间隔,即
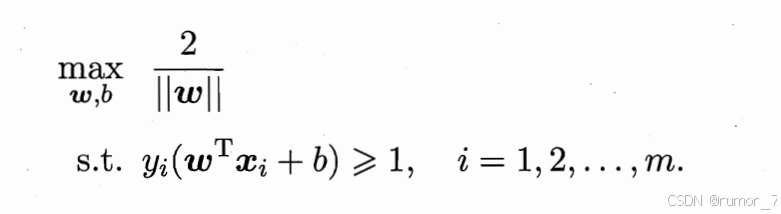
(max 间隔 ,并且满足约束在超平面中)
由于最大化 等价于最小化
,但是,
包含平方根,不易求导和优化。为了方便计算,问题可以转化为:
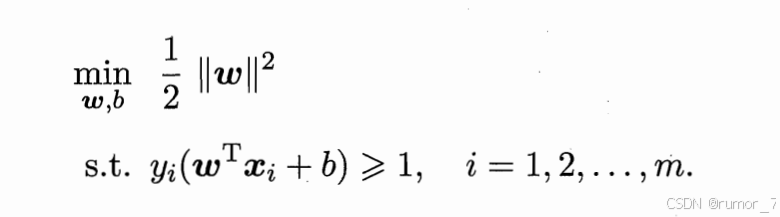

因为不是等式约束,所以引入一个非负数 ,而后再使用拉格朗日乘子法。


④先左右两边同乘pi 而后将③带入④后得到两种可能解, ,
此时对应数据在间隔外面,对决策边界没有影响。
另一个解 ,此时可以有
且对应数据在间隔边界上,是 支持向量,影响决策边界。此外
可视为违背约束条件的惩罚系数,所以
(毕竟不能鼓励违背约束以取到成极值)
这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需保留,最终模型仅与支持向量有关。
(引入
再经过③④步骤将其消去,最后是为了得到结果
,
以作为KKT条件的一部分。)
最后得到KKT条件如下:

升维转换与核技巧
当在低维空间中无法将数据集有效划分时,可以将其升维后再划分,但是升维后的数据需要更大的存储空间和计算需求。此外还需要选择合适的维度转换函数。
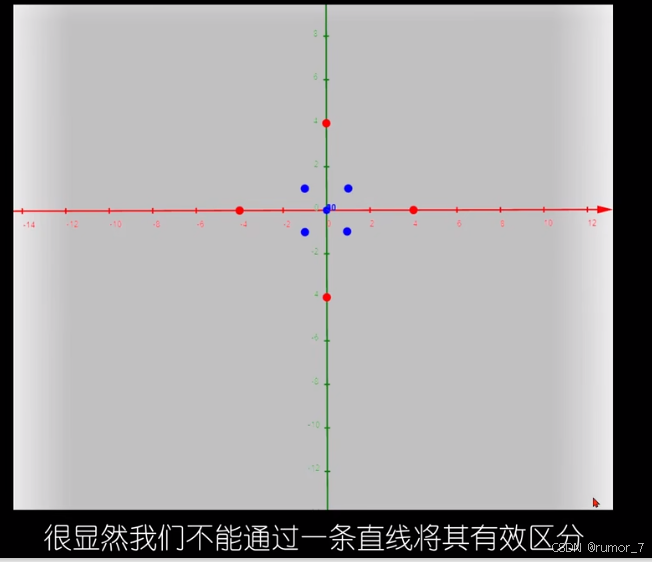
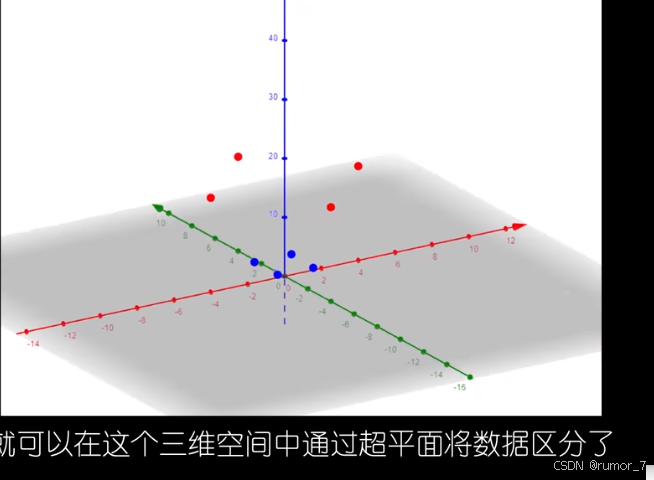


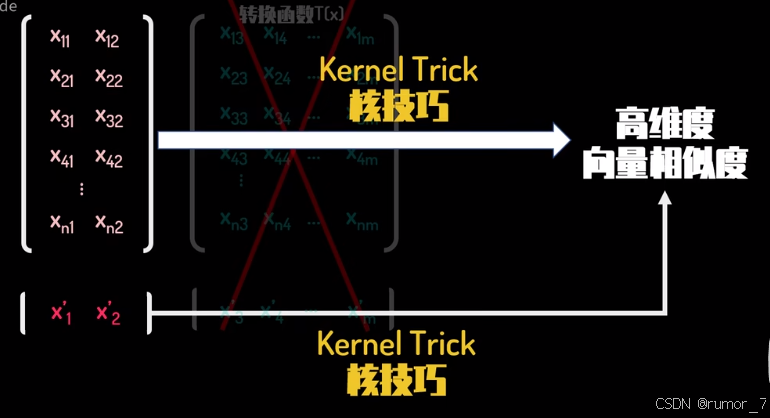
简而言之,我们可以通过升维转换将原始空间中的低维数据映射到高维的特征空间,使其在高维空间中线性可分。但是使用升维转换我们需要显式构造升维函数 ,然后计算高维特征,再计算内积。
核函数是不需要显式构造升维函数,而是直接计算高维空间中的内积。既避免了高维计算的复杂度,提高计算效率,又保留了非线性映射能力。

高斯核函数(Radial Basis Function Kernel,RBF)
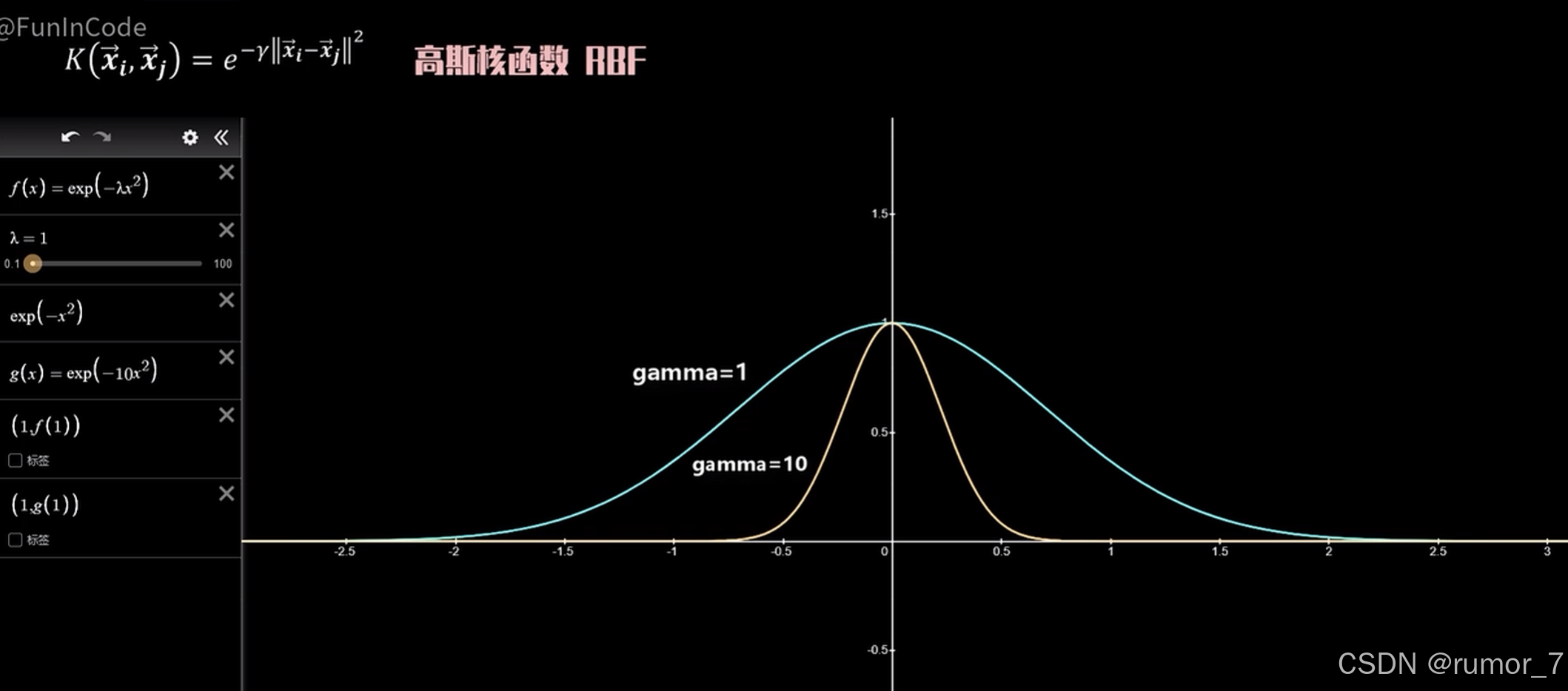
越小,图像越宽胖,距离即使较远也能有较为明显的相似度值;
越大,图像越瘦高,距离远时二者的相似性较低。
可以结合正态分布来进行记忆,正态分布,其中
表示所有点到均值
的距离平方的平均值。当
越大,表示所有样本点到期望的平均距离越大,也就是说,每个点要尽可能远离期望值,图像越宽胖。将两个式子结合看,
越大不就是
越小吗,所以
越小,图像越宽胖。
在小 值的情况下,数据点之间的相似性被放大了,使得数据更易被简单超平面划分,相比于大
不易出现过拟合情况。可以理解为,
越大,划分越严格。

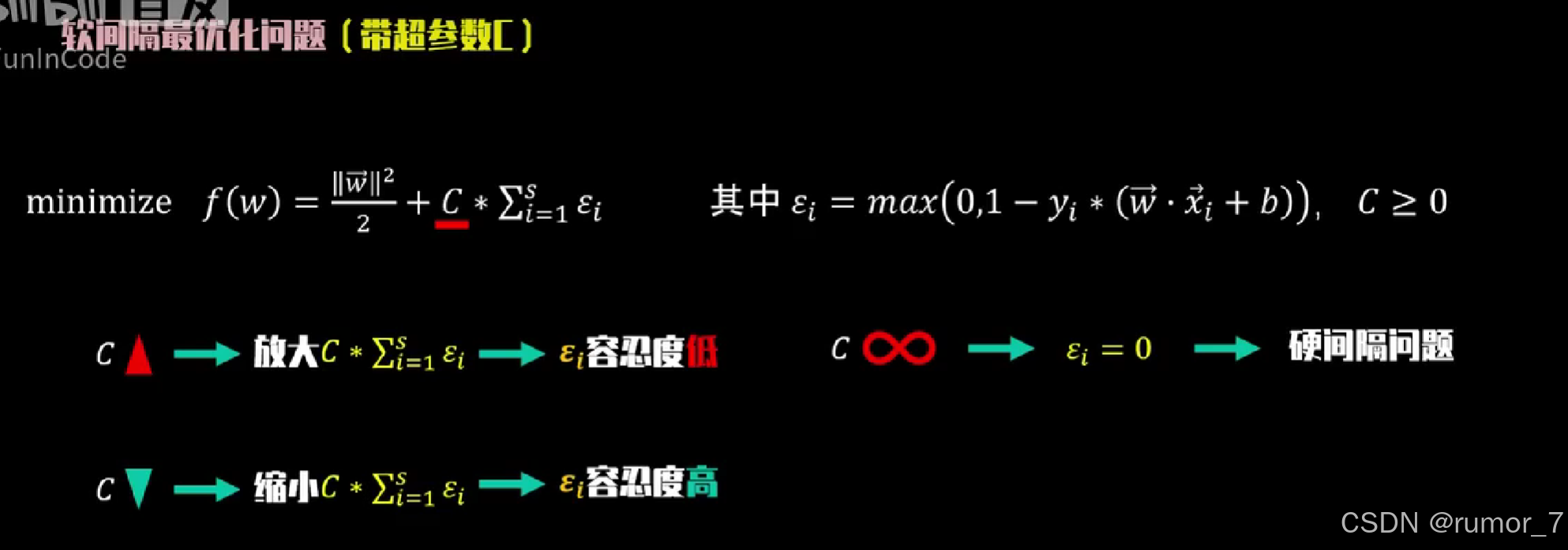
软间隔

非极大抑制(Non_Maximum suppression, NMS)方法
非极大值抑制Non-Maximum Suppression(NMS)一文搞定理论+多平台实现 - 知乎 (zhihu.com)
NMS可以简单理解为局部最大搜索。
算法输入
一幅图产生的所有的候选框,每个候选框包含坐标信息和类别置信度。
这些候选框和对应的置信度通常以一个 N × 5 维的数组表示,其中:
- N 代表某个类别的待处理候选框数量。
- 前 4 维(X_max, X_min, Y_max, Y_min)表示框的坐标。
- 第 5 维 表示该框属于当前类别的置信度。
如一组5维数组:
- 每个组表明某个类别的一个边框,组数是某个类别待处理边框数
- 4个数表示框的坐标:X_max,X_min,Y_max,Y_min
- 1个数表示对应分类下的置信度
注意:每次输入的不是一张图所有的边框,而是一张图中属于某个类的所有边框(因此极端情况下,若所有框的都被判断为背景类,则NMS不执行;反之若存在物体类边框,那么有多少类物体则分别执行多少次NMS)。
除此之外还有一个自行设置的参数:阈值 TH,用于确定两个候选框是否属于同一个目标。
具体来说,先计算两个候选框的 IoU,若 IoU 大于 TH,则认为这两个候选框属于同一个目标,保留置信度较高的框,去除置信度较低的框。
NMS 处理流程
- 将所有的框按类别划分,并剔除背景类,因为无需NMS。
- 对每个物体类中的边界框(B_BOX),按置信度降序排列。
- 对各个类别逐一操作:选取置信度最高的框作为基准框,然后计算它与其他框的 IoU。
- 去除 IoU 大于 TH 的框。
- 对剩下的框重复步骤 2 和 3,直到处理完所有框。
如有错误,请多指正!感谢您的观阅!

















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









