






RWKV-6 论文分享会回顾
6 月 23 日,RWKV-6 论文第一场分享会圆满结束。论文参与者侯皓文博士讲解论文要点,RWKV架构唯一作者彭博在线答疑。
此番分享会主要介绍了如下内容:
- RWKV 的设计理念、架构框架
- 相对 RWKV-4 架构,RWKV-5/6 架构有哪些进步?
- RWKV 与其他非 Transformer 模型架构的对比
- RWKV 的计算成本
- 新论文的基准测试和多模态工作
截下来,让我们一起回顾一下分享会的精彩内容!
RWKV 的架构设计理念
RWKV 的命名由四个重要参数组成:R、W、K、V,具体的参数含义如图:
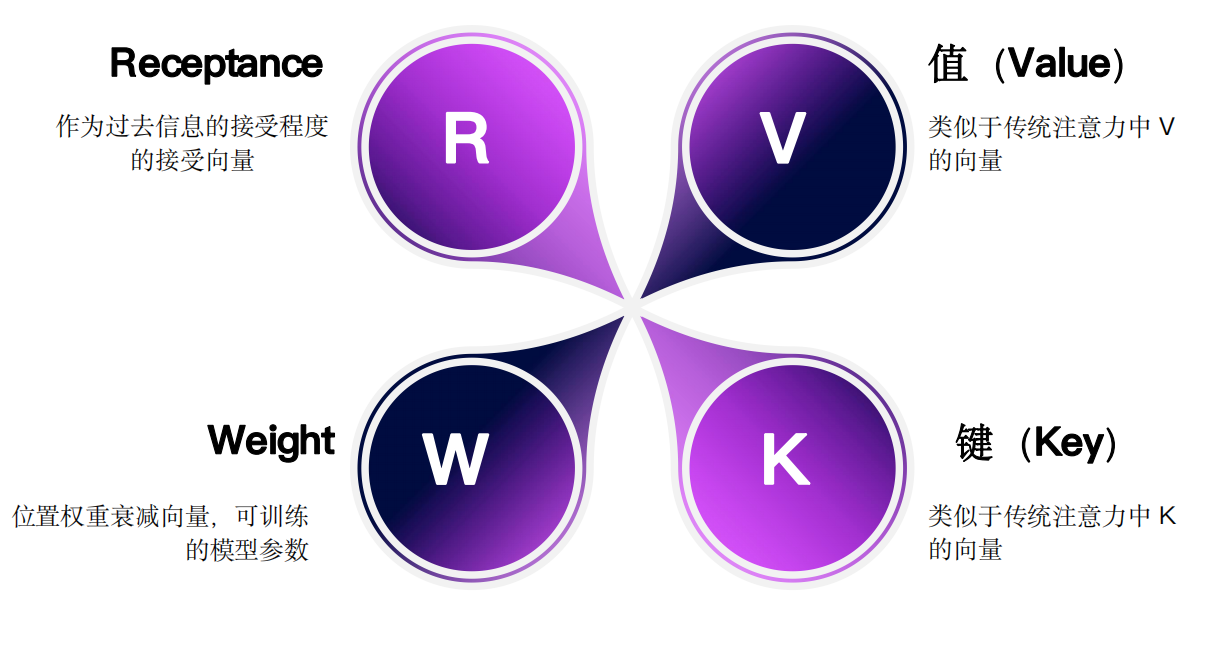
除了可训练的权重参数 w(Weight),RWKV 还使用 r (Receptance) 参数来控制对信息的接受程度。
区别于 Transformer 的 Query - Key - Value(QKV)内存寻址机制,RWKV 更像是一种联想记忆方法。
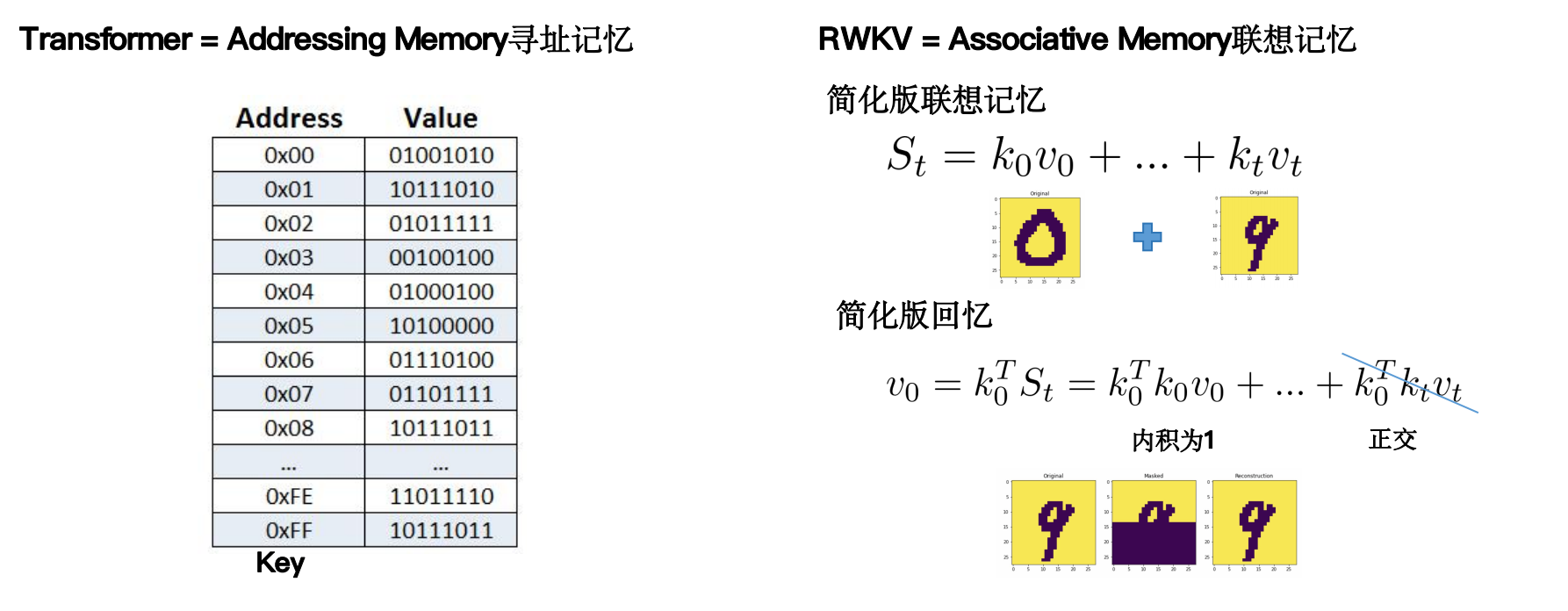
RWKV 5/6 有哪些新的东西?
RWKV-5 的改进:多头矩阵值状态
相对 RWKV-4 版本架构, RWKV-5 的最重点改动在于引入了多头的、基于矩阵值的状态,“multi-headed matrix-valued states”。
我们结合 RWKV 的 time mixing 公式来看,会对 RWKV-5 的改动更清晰。
在 RWKV-4 架构的 time mixing 计算中,u、w、k、v 都是维度为 D 的向量,而 head size 是 1 :

而 RWKV-5 则将 u、w 分别进行对角化,而 k 和 v 从 维度为 D 的向量转化为维度为 64 * 64 的矩阵, head size 大小改为固定的 64 。
通过将原本的向量变成矩阵,使得模型的 state 计算从基于向量变成了基于 64 *64 的矩阵值,即 “matrix-valued states” 。
假设当前 RWKV 模型的维度是 512 ,则可以说当前有 512/64 = 8 个头 (八头 - 64 维),这就是 RWKV-5 的“多头-multi-headed” 概念。
RWKV-5 的 time mixing 递归公式:

在这里插入图片描述
因此,我们可以把 RWKV-5 的优化细节总结为:
- RWKV-5 消除了归一化项(RWKV-4 公式中的分母)
- RWKV-5 引入了矩阵值状态,来代替以往的向量值状态。
通过这种方式,RWKV-5 巧妙地扩大了 state 的规模,使得 RWKV 模型有更好的记忆力和模型容量。
RWKV-6 的改进:动态递归机制
如果仅仅从 time mixing 的递归公式来看, RWKV-5 和 RWKV-6 的区别并不大。
RWKV-5 time mixing 公式:

RWKV-6 time mixing 公式:

但细心的朋友可以发现: RWKV-5 公式中的的 w 是不带下标的静态参数,这也意味着它是一个可训练的值,而 RWKV-6 的 w 则是带下标的动态参数,是依赖当前输入的的递归形式。
RWKV-6 的动态递归是通过引入两个低秩适应(LoRA)模块来实现的,RWKV-6 引入了 channel-wise 的衰减率 W t {W}_{t} Wt 。
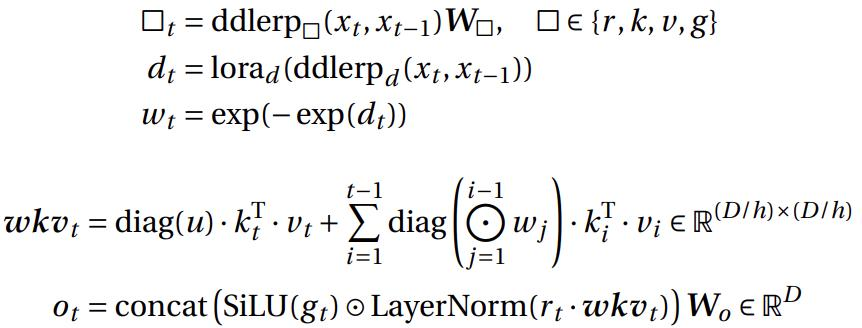
为了更好地理解 RWKV-6 如何使用 LoRA 优化架构,我们从 token shift 计算流程、 RWKV 作为 RNN 单元,以及 RWKV 的代码等角度观察 RWKV-5 和 RWKV-6 的区别:
RWKV-6 的 token shift 变化
RWKV 的 token shift 是将 RWKV 接收的每个 token 和前一个 token 做混合,类似于大小 = 2 的一维因果卷积。
token shift 是 RWKV-4 论文中提出的概念,可允许模型了解每个时间步将多少新信息与旧信息分配给每个头的接收、键、值和门向量(即 r、k、v 和 g)。
RWKV-5 的 token shift 中, x t {x}_{t} xt 和 x t − 1 {x}_{t-1} xt−1 之间的线性插值公式:
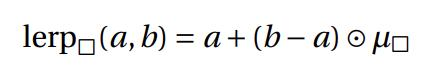
RWKV-5 的 token shift 计算流程:
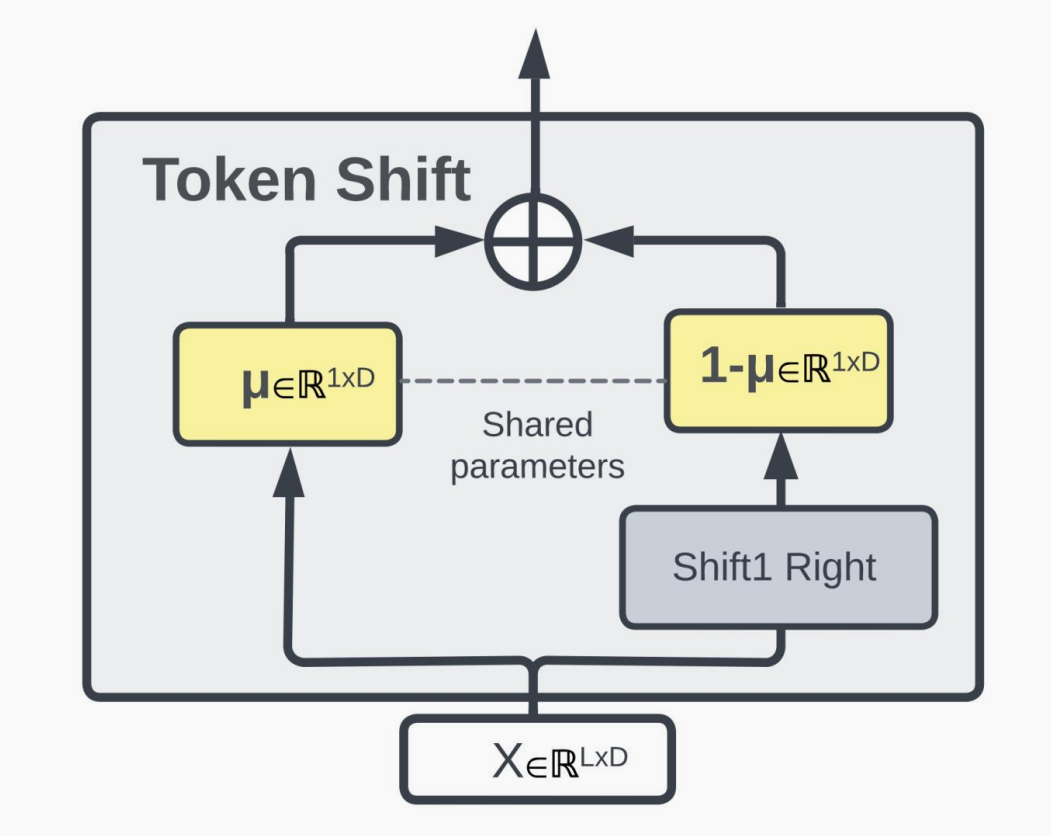
从公式可以看出: RWKV-5 的 token shift 和 RWKV-4 类似,是一个非常简单的线性插值(linear interpolation - lerp),且这个线性插值是数据无关的((data-independent),只由参数 μ 决定当前 token 和前一个 token 混合到模型输入的占比。
而 RWKV-6 则借鉴了低秩适应(LoRA)的技术,将静态的参数 μ 替换成了动态的 LoRA :为 μx 和 λ 引入维度为 D 的可训练向量,然后引入两个维度为 D×32 和 32×D 的 A、B 矩阵(对应下图中的 L1 和 L2 ),然后通过计算 y′ = y + tanh(xA)B (LoRA 算法)来生成依赖于数据的动态 token-shift。
RWKV-6 的 token shift 中, x t {x}_{t} xt 和 x t − 1 {x}_{t-1} xt−1 之间的数据相关线性插值公式:
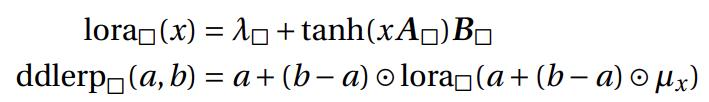
RWKV-6 的 token shift 计算流程:

通过借鉴 LoRA 技术,RWKV-6 的 token shift 从 RWKV4/5 的简单线性插值,变成了数据依赖的、动态的线性插值 (data-dependent linear interpolation - ddlerp)。
作为 RNN 单元的 RWKV
RWKV-5/RWKV-6 写成 RNN 的递归公式:
w
k
v
t
=
S
t
−
1
+
diag
(
u
)
⋅
k
T
⋅
v
wkv_t = S_{t-1} + \operatorname{diag}(u) \cdot k^T \cdot v
wkvt=St−1+diag(u)⋅kT⋅v
S
t
=
diag
(
w
)
⋅
S
t
−
1
+
k
T
⋅
v
S_t = \operatorname{diag}(w) \cdot S_{t-1} + k^T \cdot v
St=diag(w)⋅St−1+kT⋅v
虽然递归形式一样,但是 RWKV-5 中的 w 是 data-independent 的,而 RWKV-6 中的 w 是 data-dependent 的 W t {W}_{t} Wt
下图为 RWKV-5/6 作为 RNN 单元的流程图,图中虚线是 RWKV-6 中有而 RWKV-5 没有的,也就是动态的 W t {W}_{t} Wt 。:
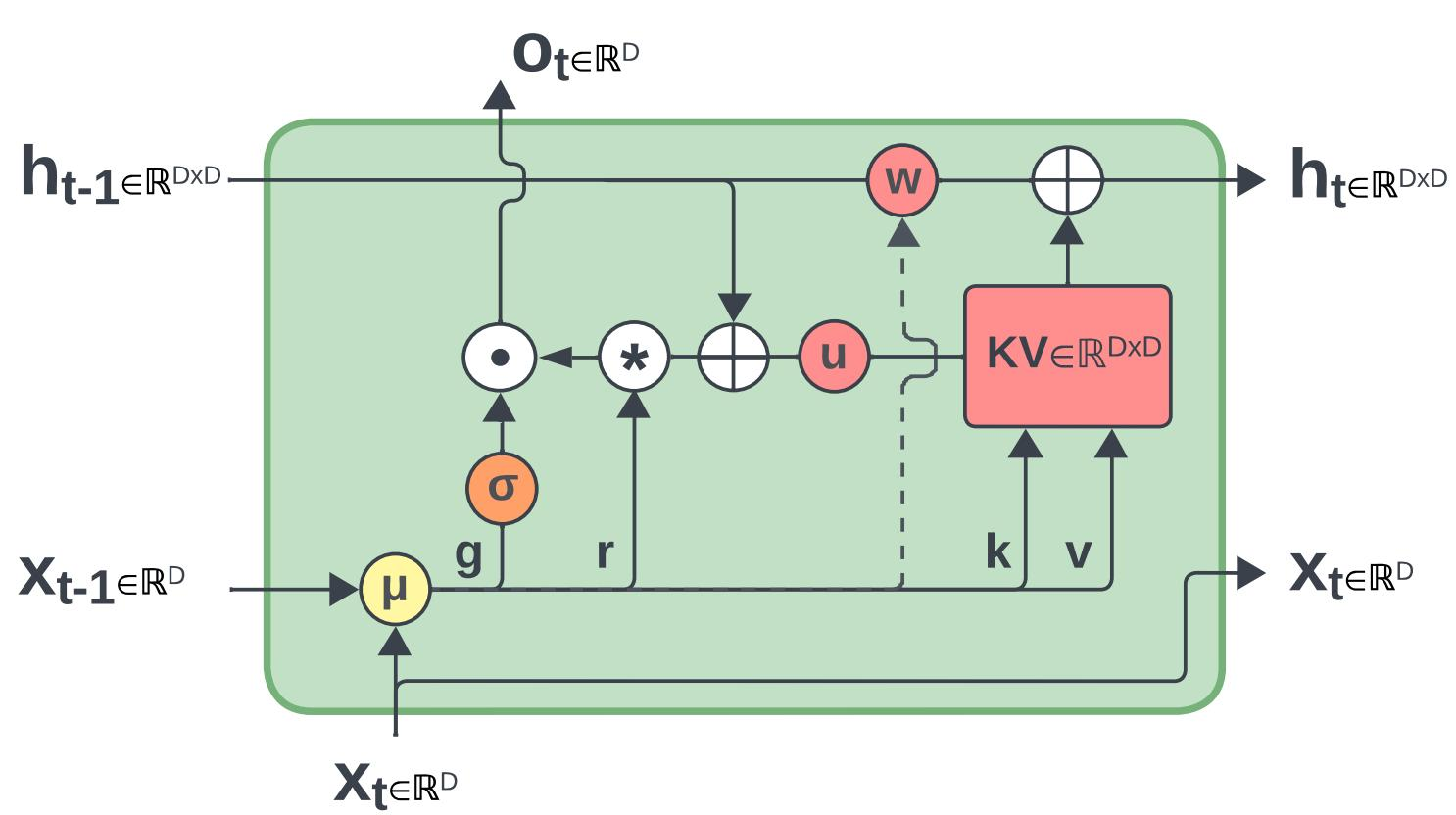
从 RWKV-5/6 的 Linear Attention 公式(PyTorch 实现)代码也可以看出 RWKV-5 和 RWKV-6 的区别,RWKV-6 的 W 参数形状新增了 B(batch size),使得其拥有独立的、动态的 W ,而非 RWKV-5 的共享 W :
# r, k, v parameter shape (B,H,1,D//H)
# w parameter of shape (1,H,1,D//H) for Eagle (RWKV-5),
# (B,H,1,D//H) for Finch (RWKV-6)
# u parameter of shape (1,H,1,D//H)
def rwkv_5_or_6_recurrent(r, k, v, w, u, wkv_state):
kv = k.mT @ v # x.mT is equivalent to x.transpose(-2, -1)
out = r @ (wkv_state + u.mT * kv)
wkv_state = w.mT * wkv_state + kv # (B,H,D//H,D//H)
return out, wkv_state
RWKV 与其他非 Transformer 架构的对比
分享会上还列举了 RWKV 和其他非 Transformer 线性递归架构的 Time mixing 模块对比,数据来源于 《Parallelizing Linear Transformers with the Delta Rule over Sequence Length》 - https://arxiv.org/abs/2406.06484

概括而言:
- S4 架构是可训练的静态 decay
- Mamba-1 像是 dynamic 版本的 S4 架构
- RetNet 是 head-wise static decay,其衰减参数 γ 仍然是不可训练的
- Mamba-2 走回了 linear attention 路线,改成了 head-wise dynamic decay,可能有参考 RetNet 的思路
- RWKV-5.1 架构采用的是 head-wise trainable decay,采用了可训练的 γ 参数,相对 RetNet static decay 有所改进
- RWKV 5.2 架构将 head-wise 转变成了 channel-wise decay
- RWKV-6 是 channel-wise dynamic decay,其中 w 依赖于当前输入,是目前表达力最高的设计
RWKV 的计算成本
下表中:D 表示模型维度,L 表示层数,h = D/64 表示头数,V 表示词汇表大小,T 表示序列长度
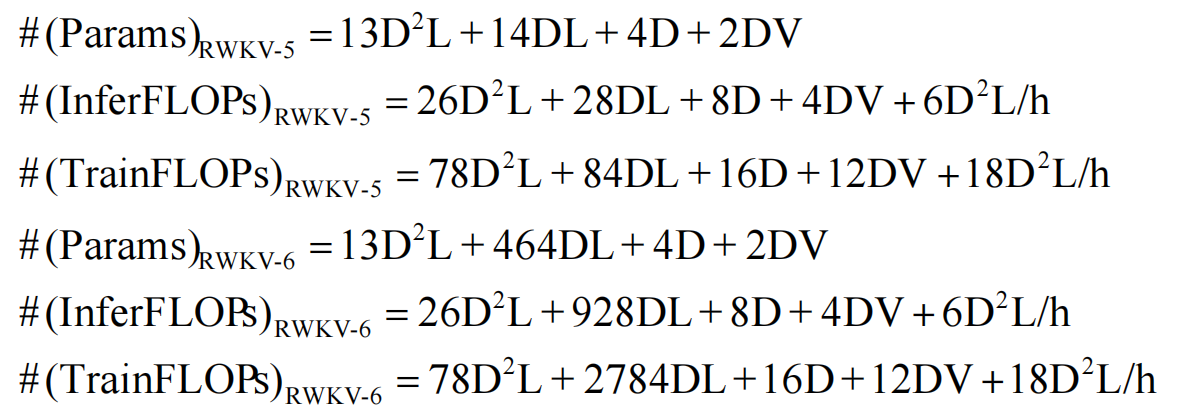
- RWKV-5 和 RWKV-6 的内部状态总大小: #(State)RWKV-5/6 = 66DL
- RWKV-4的内部状态总大小:#(State)RWKV-4 = 5DL
- Transformer 的内部状态总大小:#(State)Transformer = 2DLT
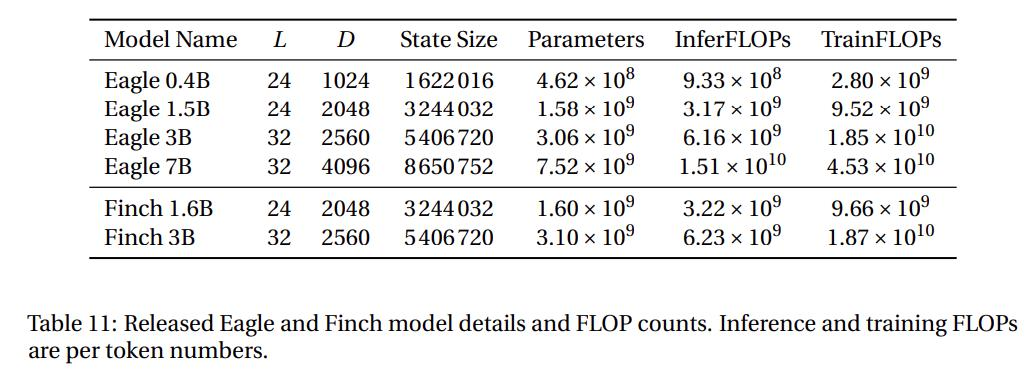
RWKV5/6 仅需消耗相当于 Transformer 的 33 个 KV cache ,即可达到 Transformer 的性能效果。
RWKV 的训练时间/硬件需求
许多朋友关心从头 RWKV 训练的硬件需求和训练时间,分享会中提出了一个简单的计算方式:
模型参数量(B)* 数据token(T) / H100 台数 = 训练所需的月数
- 训练 1B 参数 + 1T 数据,有 1 台 H100 = 1 个月
- 训练 30B 参数 + 1T 数据,有 30 台 H100 = 1 个月
- 训练 30B 参数 + 3T 数据,有 30 台 H100 = 3 个月
RWKV 的全新分词器
RWKV 新论文介绍了全新分词器 rwkv_vocab_v20230424 ,这个分词器合并了以下分词器的词汇表,并手动为非欧洲语言选择了 token:
RWKV World 分词器是一个通过 Trie(前缀树)实现的贪心分词器,编码过程通过从左到右匹配词汇表中最长的元素与输入字符串进行,在提高速度的同时保持简洁性。
RWKV World 分词器的词汇量大小为 V = 65536,编号从 0 到 65535,token 按其在字节中的长度排列。以下是简要描述:
- token 0:表示文本文档之间的边界,称为
<EOS>或<SOS>。此 token 不编码任何特定内容,仅用于文档分隔。 - token 1-256:由字节编码组成(tokenk 编码字节 k−1),其中 token 1-128 对应于标准 ASCII 字符。
- token 257-65529:至少具有 2 个 UTF-8 字节长度的 token,包括单词、前缀和后缀、带重音的字母、汉字、韩文、平假名、片假名和表情符号。例如,汉字被分配在 token 10250 至 18493 之间。
- token 65530-65535:预留 token,供将来使用。
RWKV 的数据集
RWKV-6 论文中采用了 RWKV V2 多语言数据集,70% 内容为英语,15% 多语言内容,15% 代码,没有进行上采样或下采样。
最新的 RWKV-6 模型使用 V2.1 数据集,大小约 1.42T tokens。
此外,我们即将推出约 3T tokens 的 RWKV v3 数据集。
RWKV 基准测试
RWKV 对新架构和模型进行了各类语言建模实验和基准测试,以下为部分基准测试展示:
MQAR 测试结果
MQAR (Multiple Query Associative Recall - 多查询关联记忆) 是设计来“模拟人类如何建立联系并提取信息”的合成任务。MQAR 衡量模型在多次查询下检索信息的能力,随着任务中序列长度的延长,其难度也随之上升。

下图为 RWKV-4、RWKV-5 Eagle、RWKV-6 Finch 和其他非 Transformer 架构的 MQAR 任务测试结果:
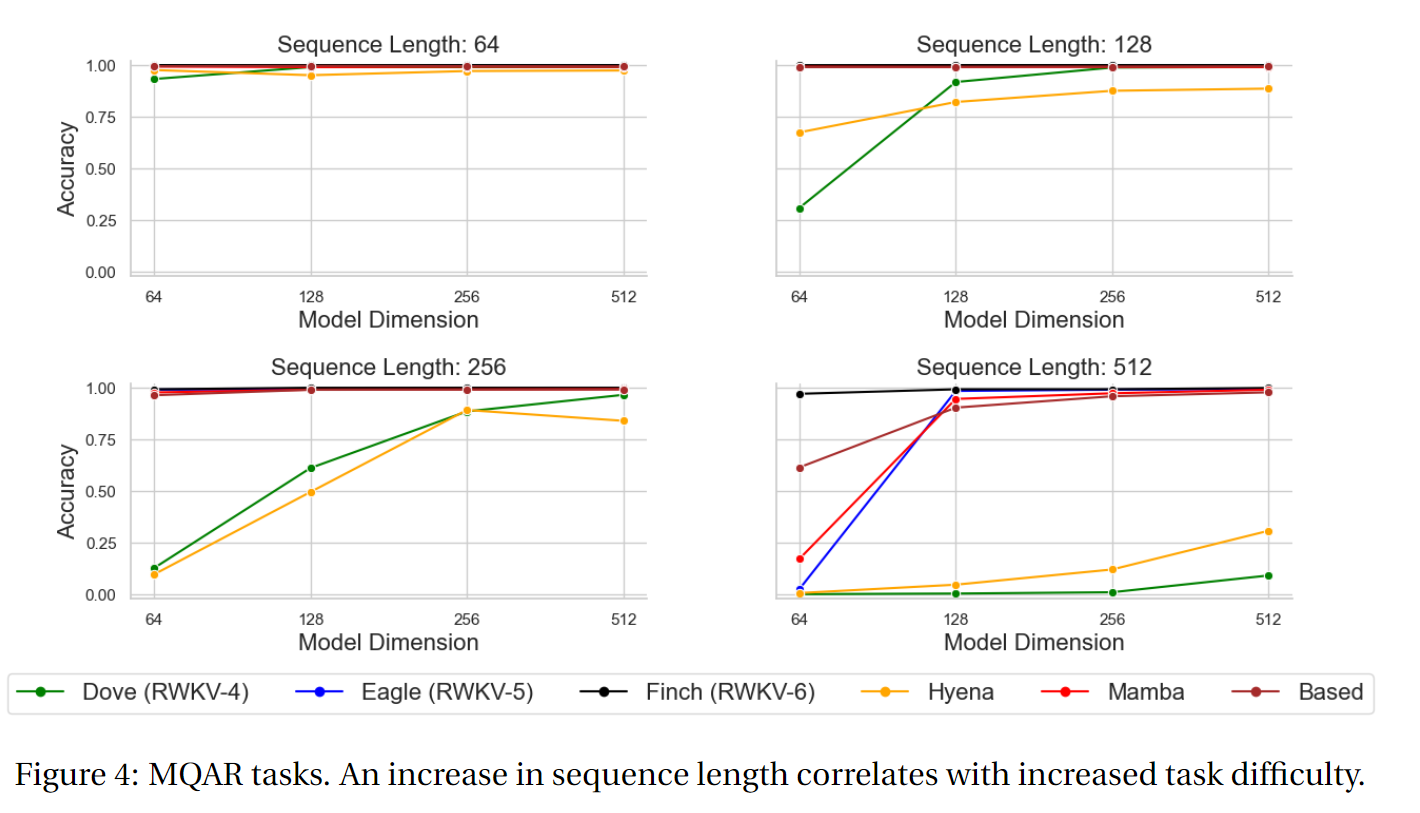
可以看出,在 MQAR 任务的准确度测试中, Finch (RWKV-6) 在多种序列长度测试中的准确度表现都非常稳定,对比 RWKV-4、RWKV-5 和其他非 Transformer 架构的模型有显著的性能优势。
长上下文实验
论文在 PG19 测试集上测试了从 2048 tokens 开始的 RWKV-4、RWKV-5 Eagle 和 RWKV-6 Finch 的 loss 与序列位置。(所有模型均基于上下文长度 4096 进行预训练。)
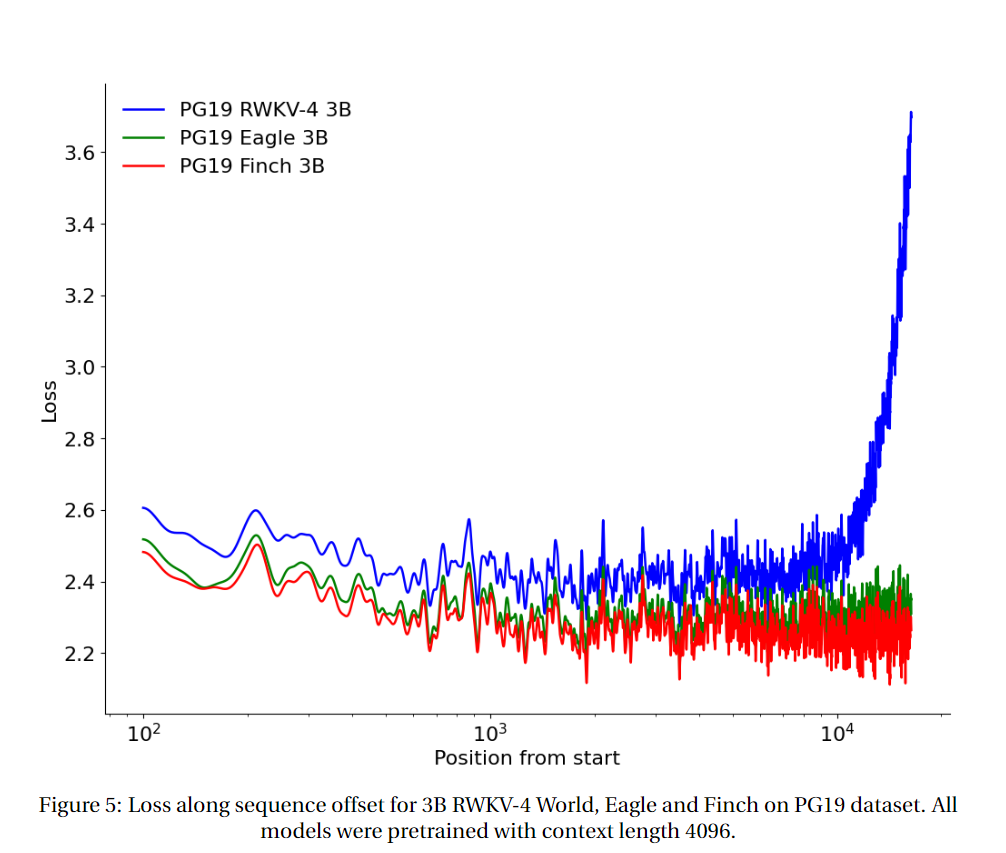
测试结果显示, RWKV-6 > RWKV-5 > RWKV-4。RWKV-5 在长序列任务上比 RWKV-4 有了显著的改进,但 Finch (RWKV-6) 的表现比 Eagle 更好,可以良好地自动适应到 20000 以上的上下文长度。
速度和显存基准测试
速度和内存基准测试比较了 Finch、Mamba 和 Flash Attention 的类 Attention 内核的速度和显存利用率。
测试基准:批量大小为 8,模型维度为 4096,并且 Flash Attention 和 RWKV-6 的 head_size 均设为 64 。测试结果如下:
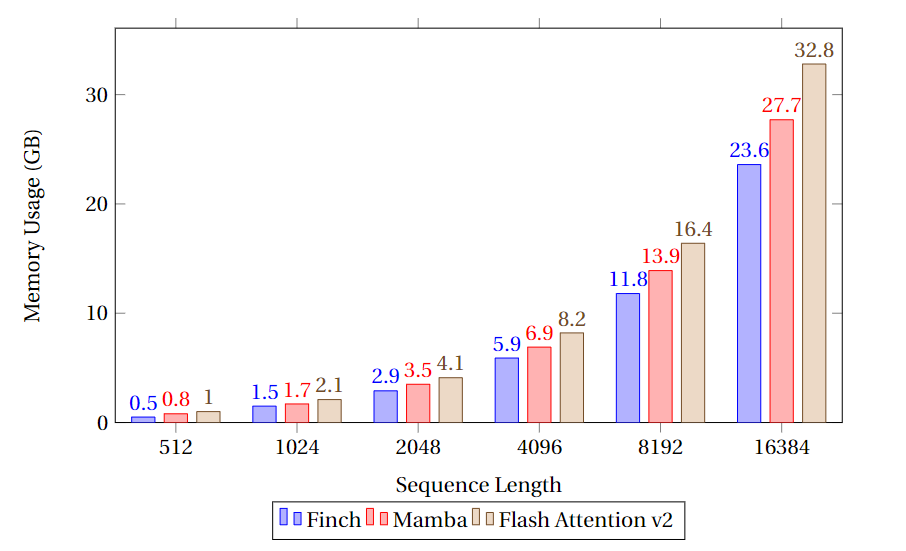
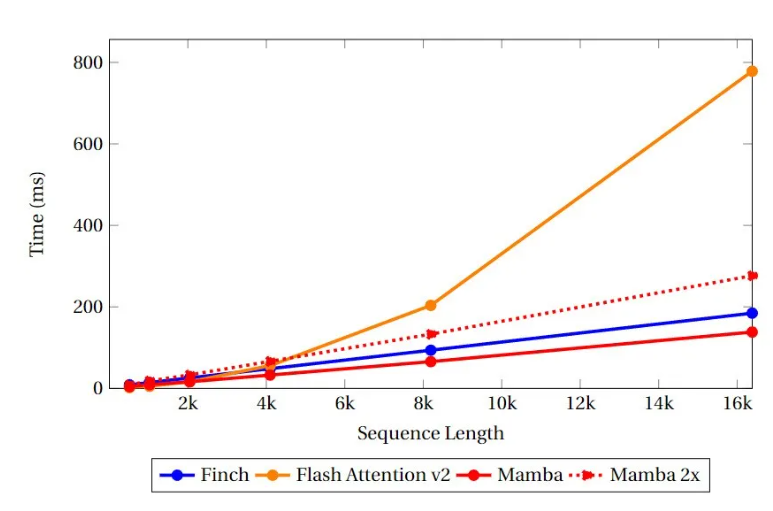
可以看到,RWKV-6 Finch 在内存使用方面始终优于 Mamba 和 Flash Attention,内存使用量分别比 Flash Attention 和 Mamba 少 40% 和 17%。
未来 RWKV 团队会对 Finch 的 CUDA 实现做进一步优化(包括算法改进),带来速度的提升和更大的并行化。
RWKV 的多模态实验
RWKV音乐建模
RWKV-5-Music 音乐模型采用了 lrishman ABC 乐谱数据集的 2162 首音乐作品,模型共有 24 层,模型维度设为 512 。
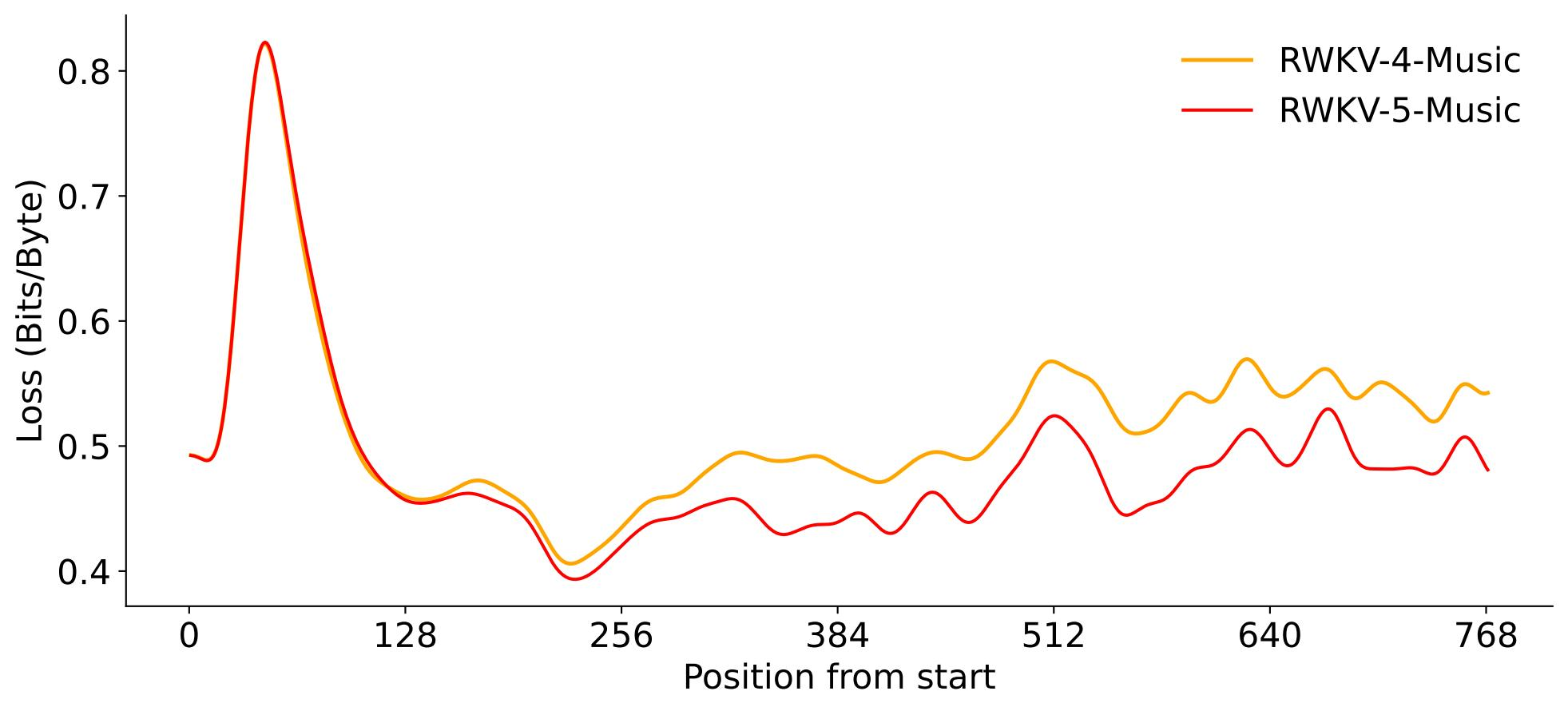
实验结果证明,RWKV-5 在乐谱部分的损失比 RWKV-4 降低了 2% 左右,表明 RWKV-5 在音乐的建模和泛化方面的能力都有所增强。
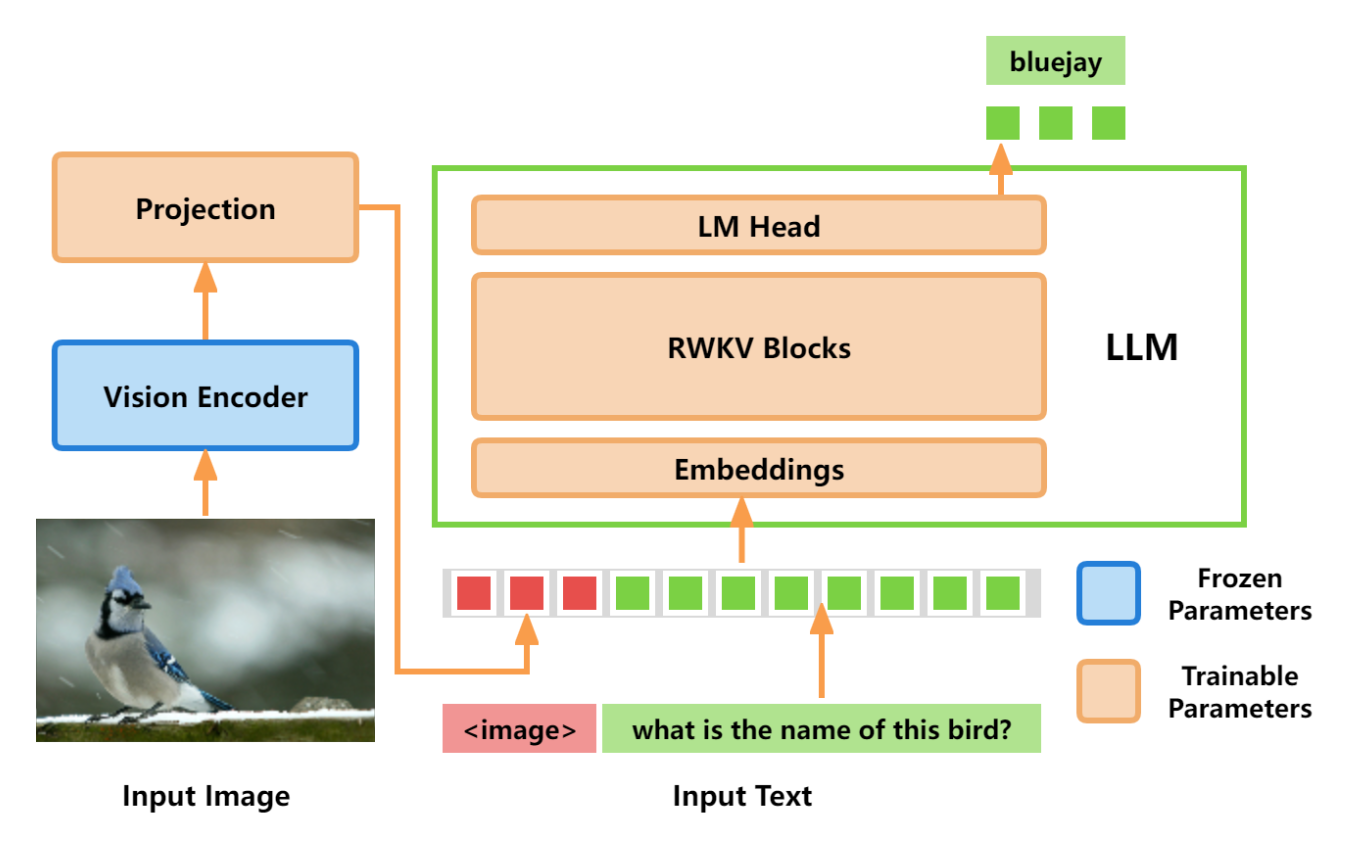
VisualRWKV-5 视觉语言模型
VisualRWKV 是 RWKV 语言模型的视觉增强版本,使 RWKV 模型能够处理各种视觉任务。通过利用松耦合的适配器设计,可以显著增强视觉能力,同时保留 RWKV 语言模型的性能。
VisualRWKV 相关链接:
-
GitHub 仓库:https://github.com/howard-hou/VisualRWKV
-
在线 Demo:https://huggingface.co/spaces/howard-hou/VisualRWKV-Gradio-1
VisualRWKV-5 采用 CLIP 模型作为视觉编码器,RWKV-5 作为 LLM ,架构设计是 Data-independent Recurrence + Image First Prompt + Unidirectional Scanning 。
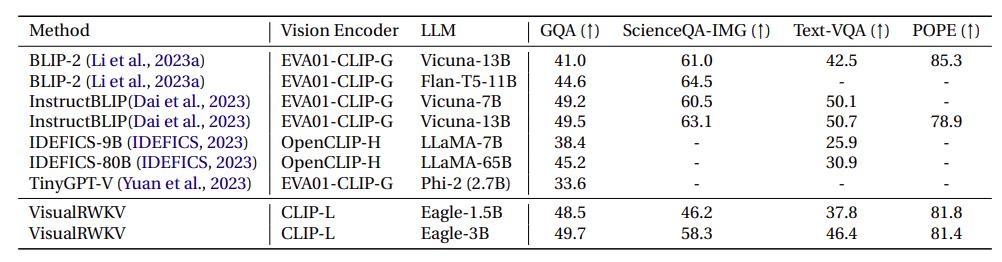
VisualRWKV-6 视觉语言模型
VisualRWKV-6 的架构设计是 Data-dependent Recurrence + Sandwich Prompt + Bidirectional Scanning 。
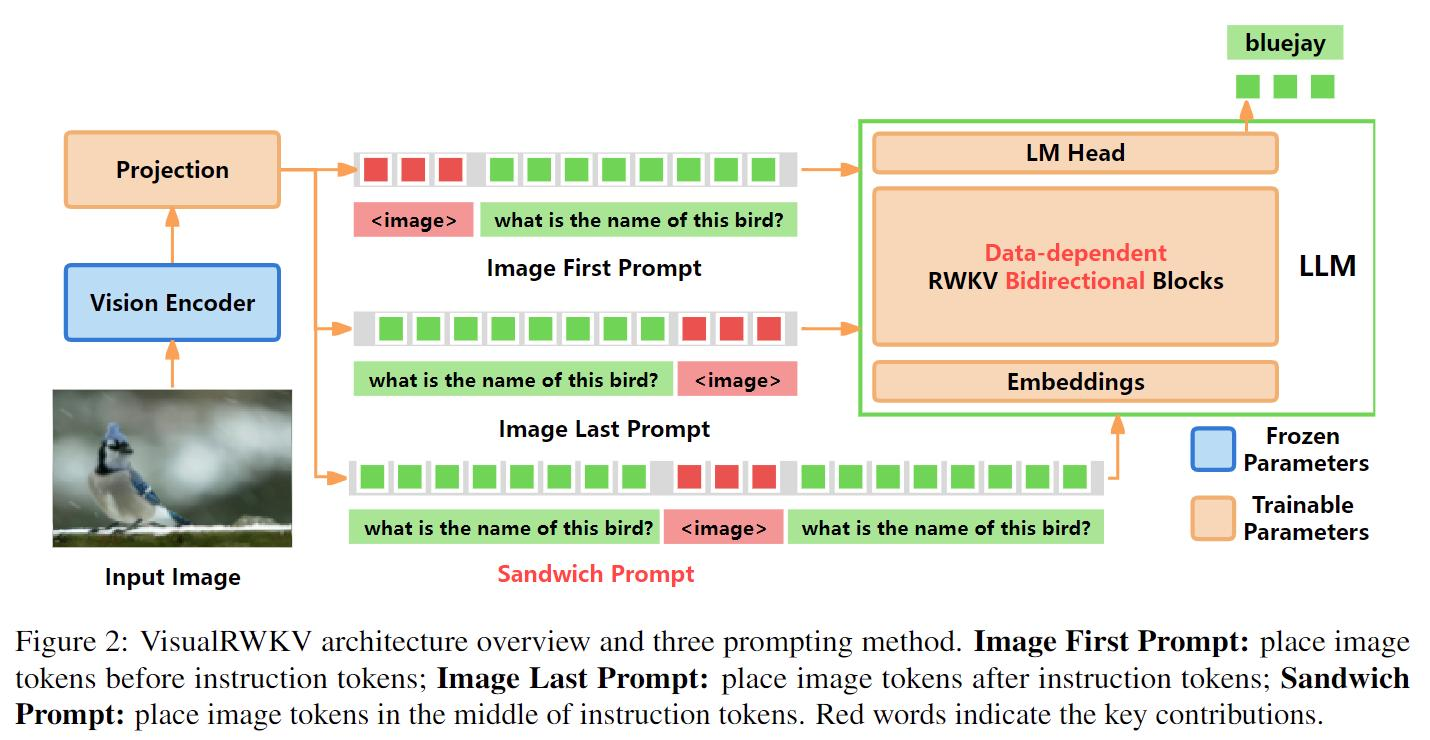

VisualRWKV-6 在多个 Benchmark 上超过 LLaVA-1.5,同时保持计算效率优势。
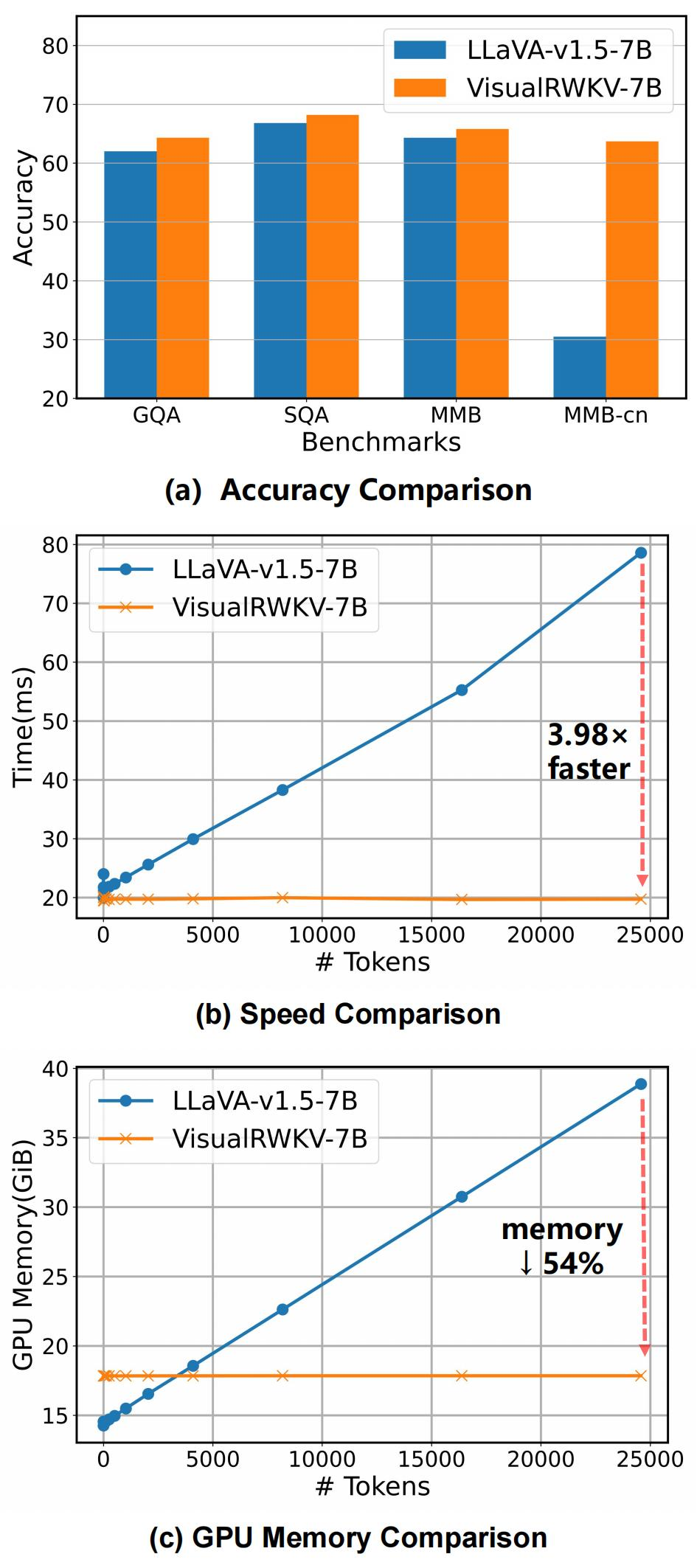
RWKV-CLIP
RWKV-CLIP (Contrastive Language-Image Pre-training)是一个 RWKV 驱动的视觉语言表示学习模型,该框架可以利用大型语言模型(LLMs)来合成和细化基于网络的文本、合成标题和检测标签的内容。
RWKV-CLIP 由 AI 计算机视觉企业“格灵深瞳”牵头开发。
论文结果显示,在同时使用 RWKV image 和 text的情况下,RWKV-CLIP 在图像和文本之间的交互中,可以获得更好的性能。

RWKV-CLIP 项目相关链接:
PointCloud RWKV
PointRWKV 项目是一种基于 RWKV 的 3D 点云学习框架,在下游点云任务上性能优于基于 Transformer 和 Mamba 的同类工作,显著节省了约 46% 的 FLOPS。
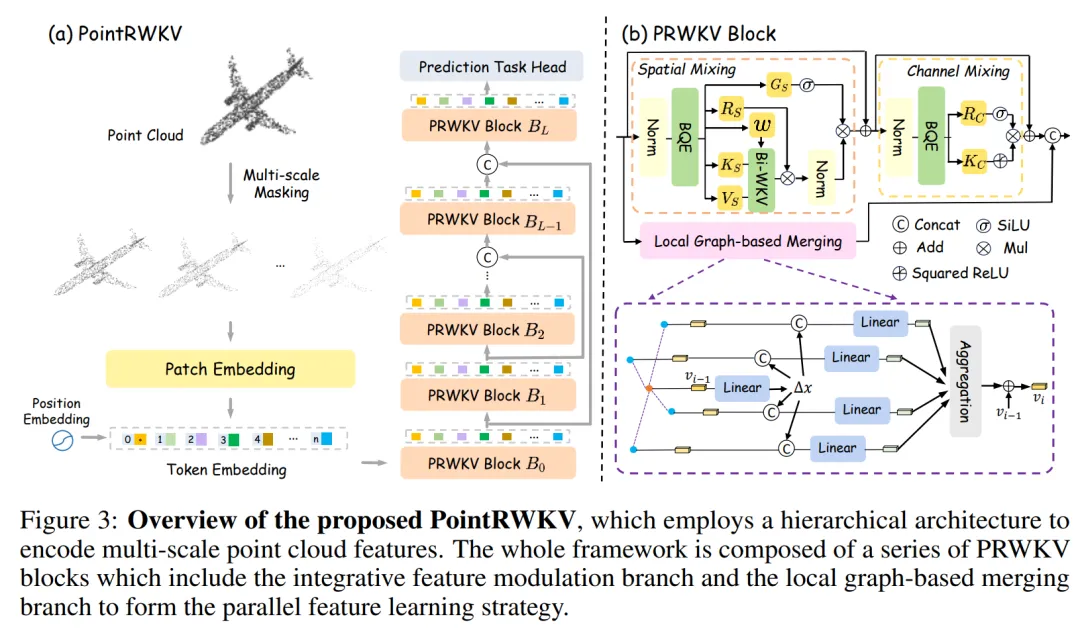
PointRWKV 项目由腾讯优图团队主导开发,相关链接:
以上是本次 RWKV-6 论文分享会的内容回顾,感兴趣的朋友可以在“RWKV元始智能”视频号中观看整场 RWKV-6 论文分享会的回放。















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









