






2024 年 5 月 7 日,我们呼吁大家使用 RWKV-6 替代 Mamba 进行科研。截至 7 月 29 日,来自全球各地的科研团队已经陆续发表了 7 篇基于 RWKV 架构、在各个领域进行深入研究的论文。
新的 RWKV 学术研究主要聚焦于具身智能、图像处理、模型架构三个方面。
机器人/具身智能
Decision-RWKV
- **论文名称:**Optimizing Robotic Manipulation with Decision-RWKV: A Recurrent Sequence Modeling Approach for Lifelong Learning
- 论文链接: https://arxiv.org/abs/2407.16306
- 仓库地址: https://github.com/ancorasir/DecisionRWKV
南方科技大学的研究团队提出了 Decision-RWKV (DRWKV) 模型,并将经验回放(experience replay)的概念与 Decision-RWKV 模型相结合,设计出适合机器人的终身学习算法。
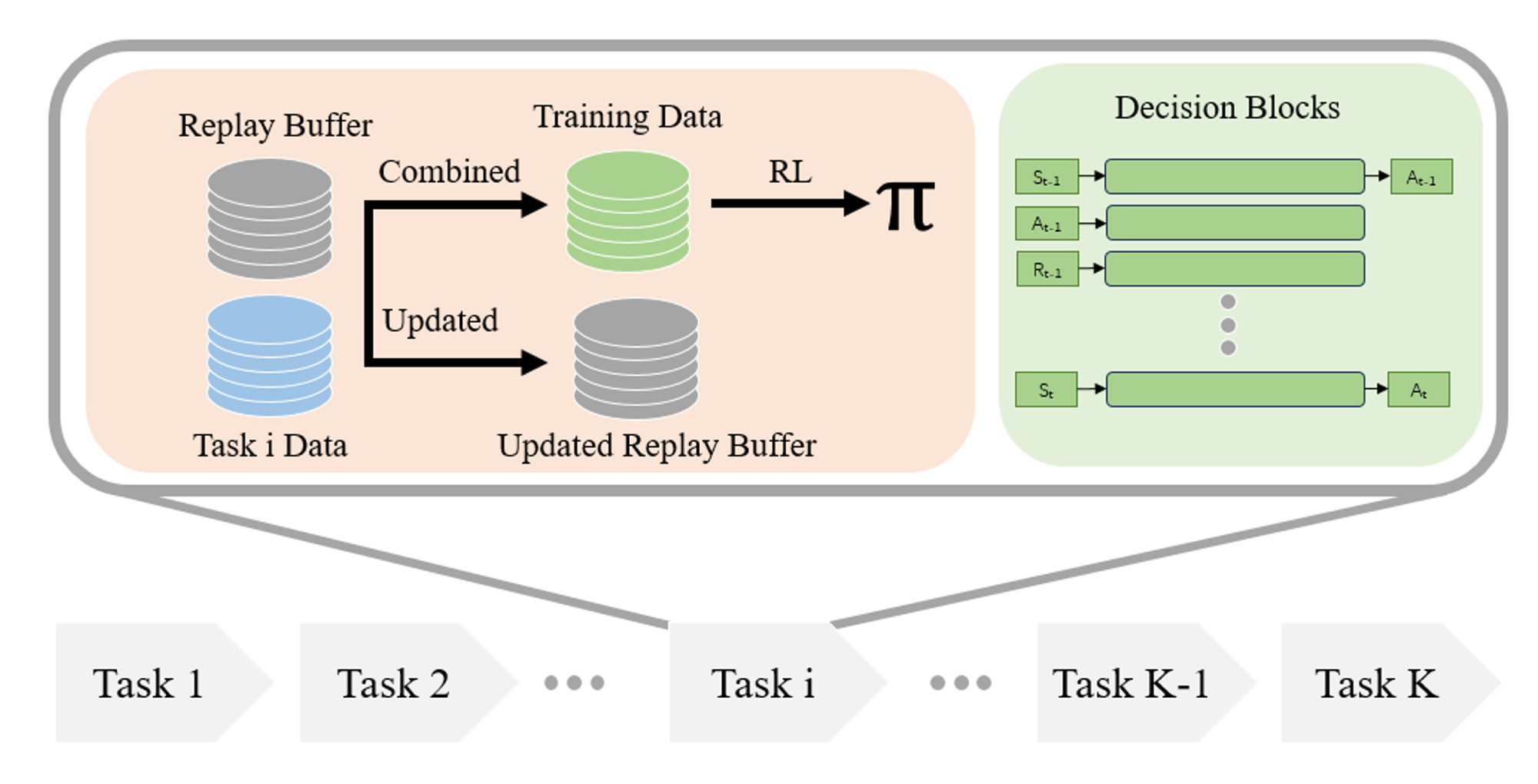
Decision-RWKV 团队在 OpenAI Gym 环境(使用 D4RL 数据库)和 D’Claw 平台(使用离线数据集)上进行了广泛的实验,以评估 DRWKV 模型在单任务测试和终身学习场景中的性能:
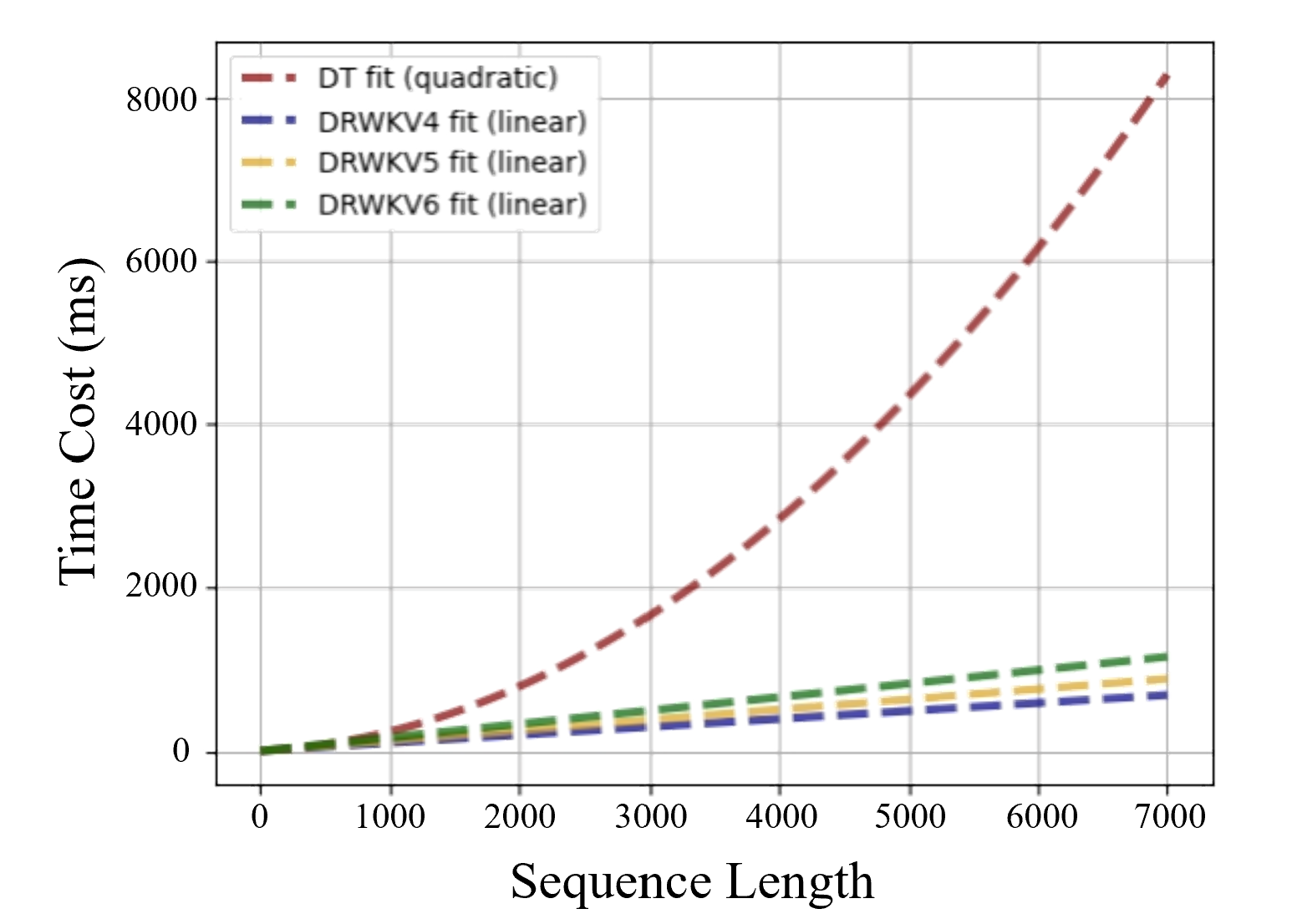
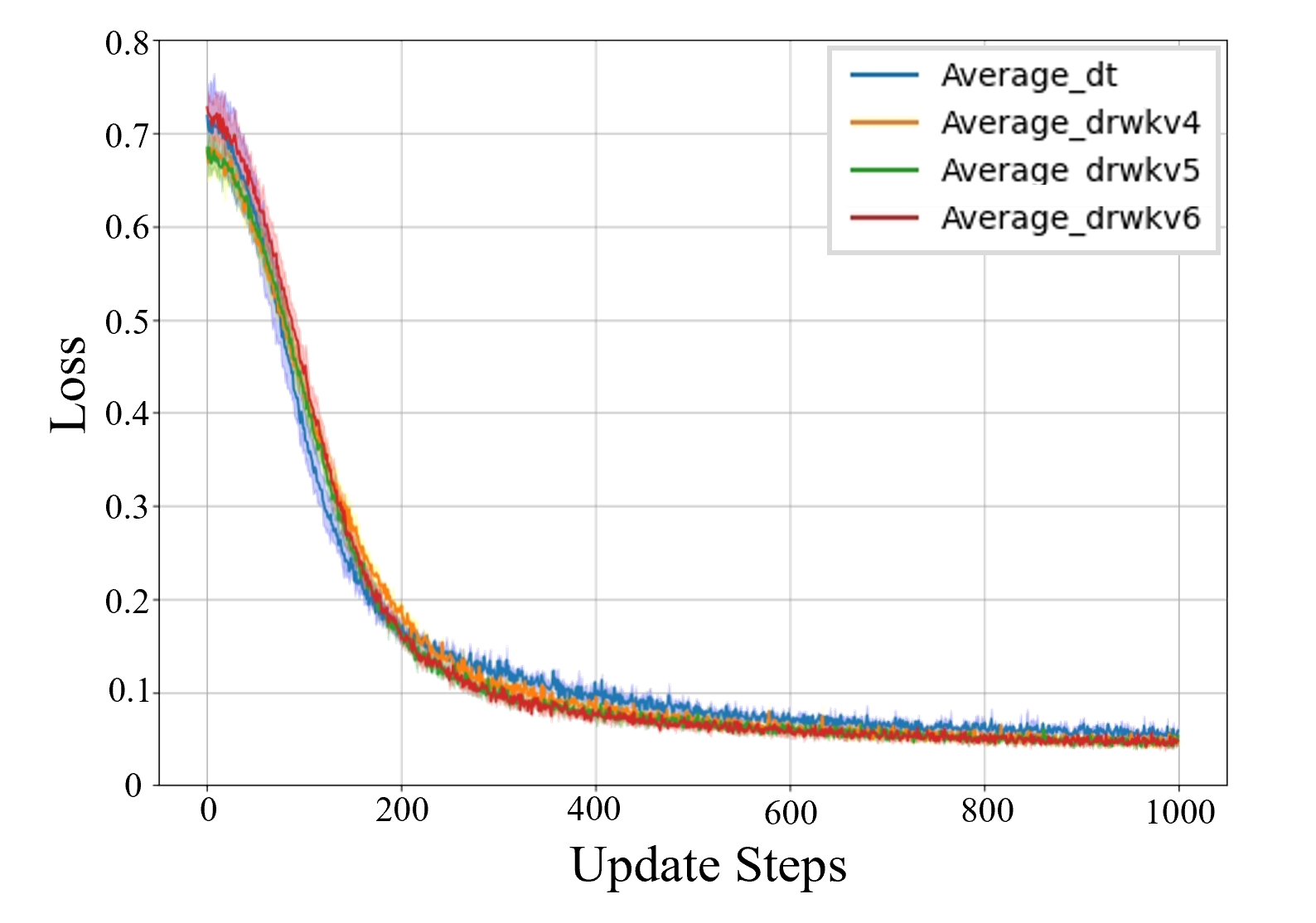
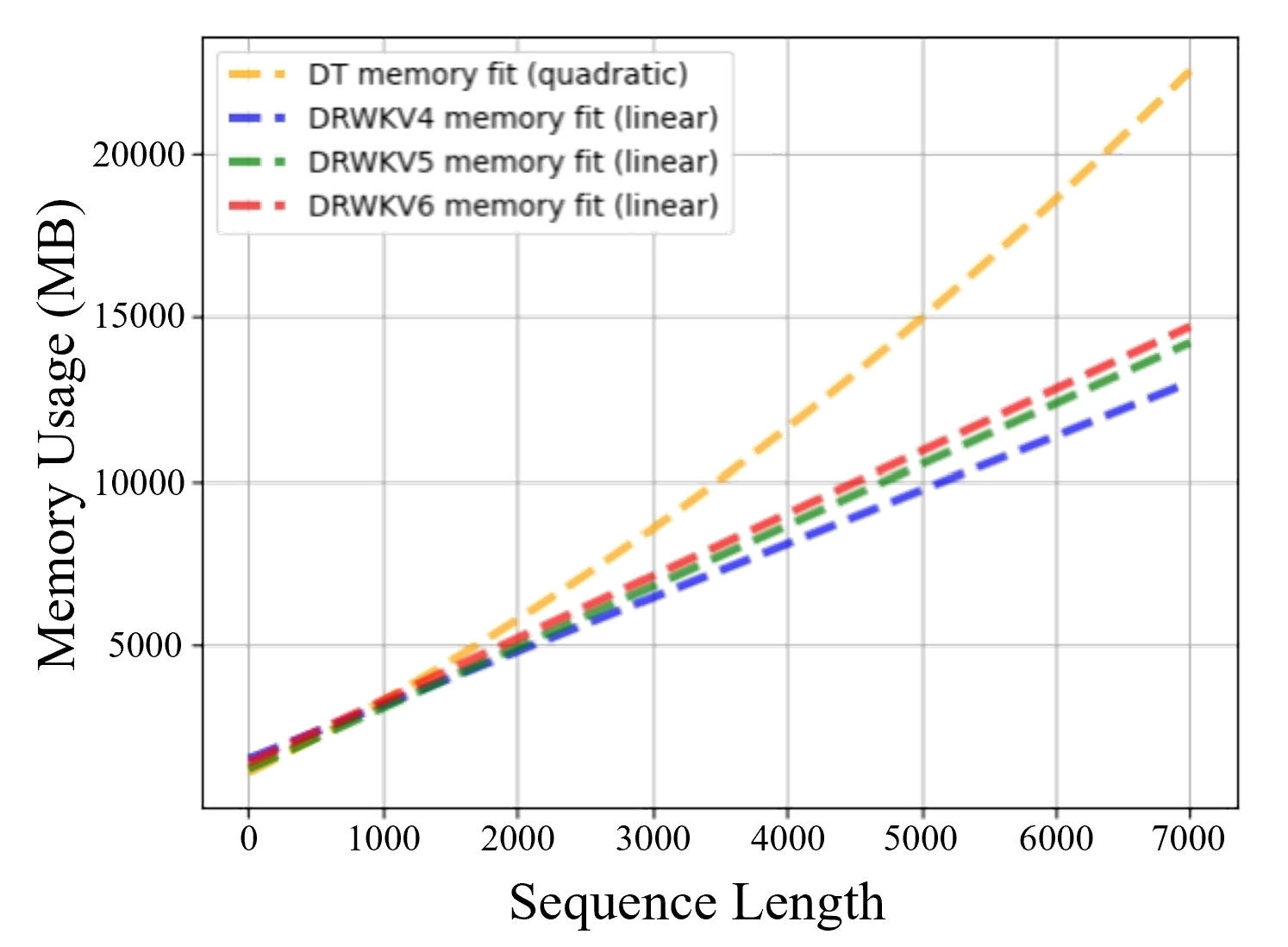
实验结果显示:Decision-RWKV 可有效地处理多个子任务。与此同时, Decision-RWKV 相比 DT(Decision-Transformer)显著地减少了推理时间和内存占用,使其成为现实应用(尤其是机器人领域)的更佳选择。
图像处理
Restore-RWKV
- 论文名称: Restore-RWKV: Efficient and Effective Medical Image Restoration with RWKV
- 论文链接: https://arxiv.org/abs/2407.11087
Restore-RWKV 是首个基于 RWKV 的医学图像修复模型。文章提出了一种循环 WKV(Re-WKV)注意力机制,将双向注意力作为全局感受野的基础,并采用循环注意力来模拟来自不同扫描方向的 2D 依赖关系。
其次,Restore-RWKV 团队还开发了一个全向 token 转移(Omni-Shift)层,该层通过从各个方向和在广泛的上下文范围内转移 token 来增强局部依赖性。
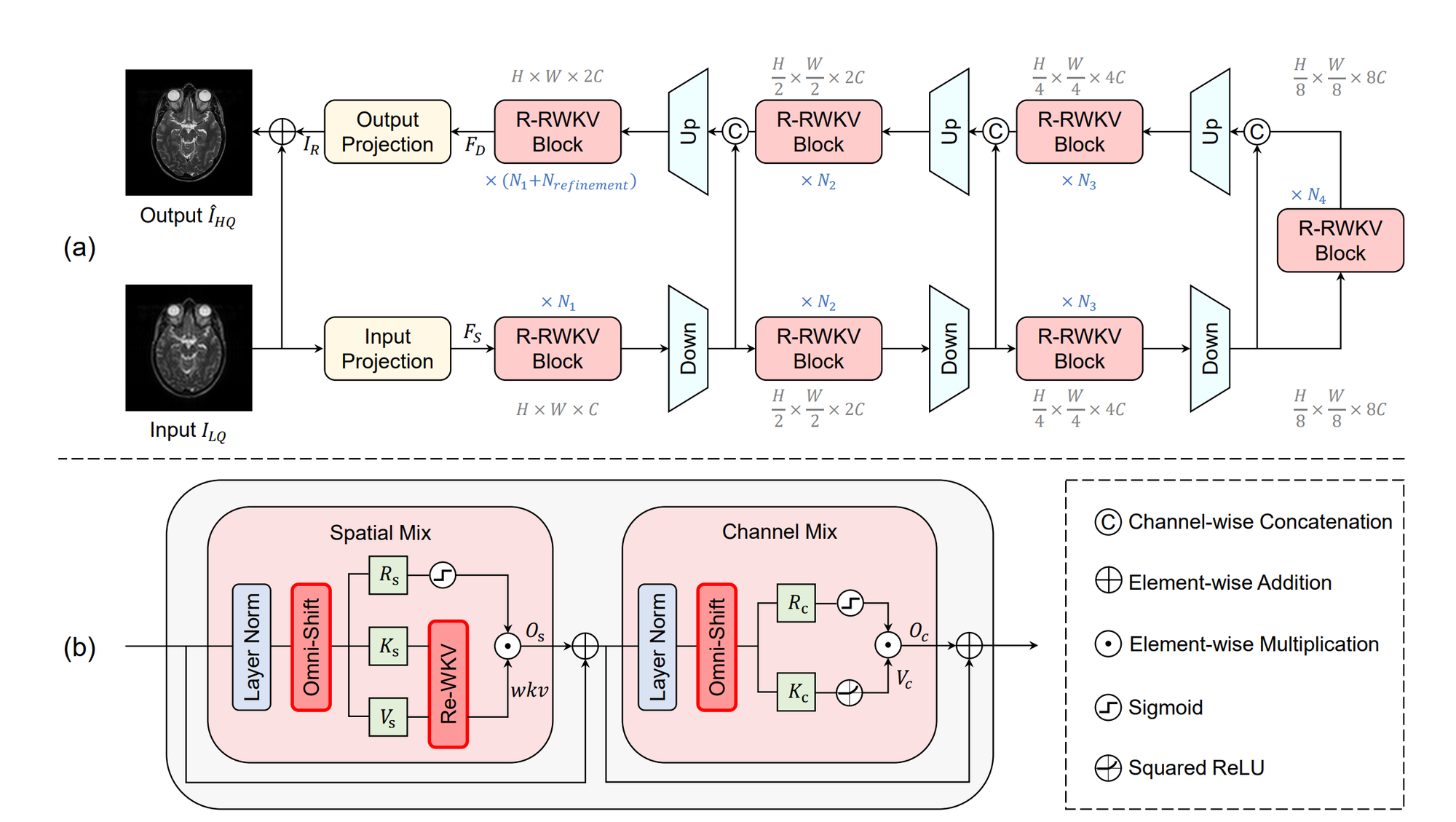
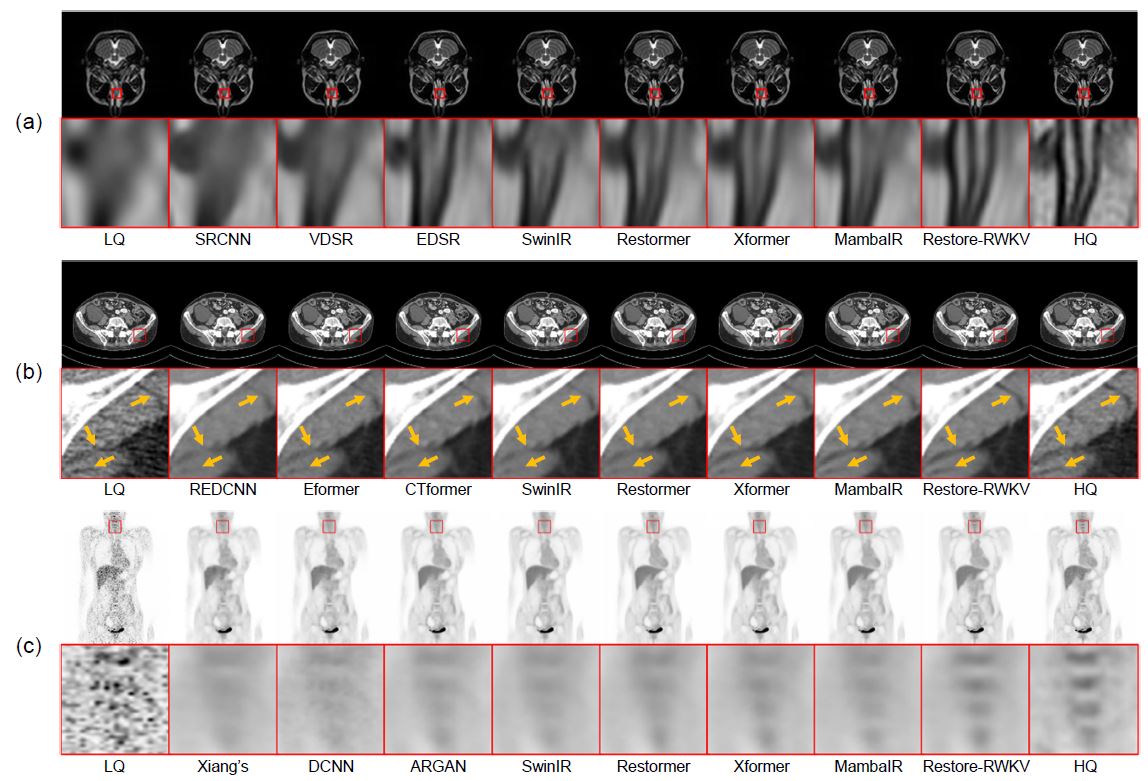
实验结果表明,Restore-RWKV 在各种医学图像修复任务中均具有卓越的性能,包括 MRI 图像超分辨率、CT 图像去噪、PET 图像合成和一体化医学图像修复。
有效感受野

可视化对比实验
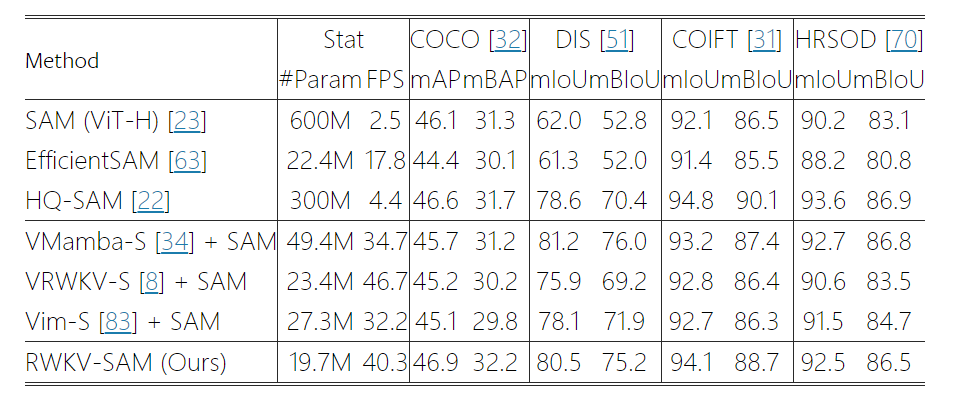
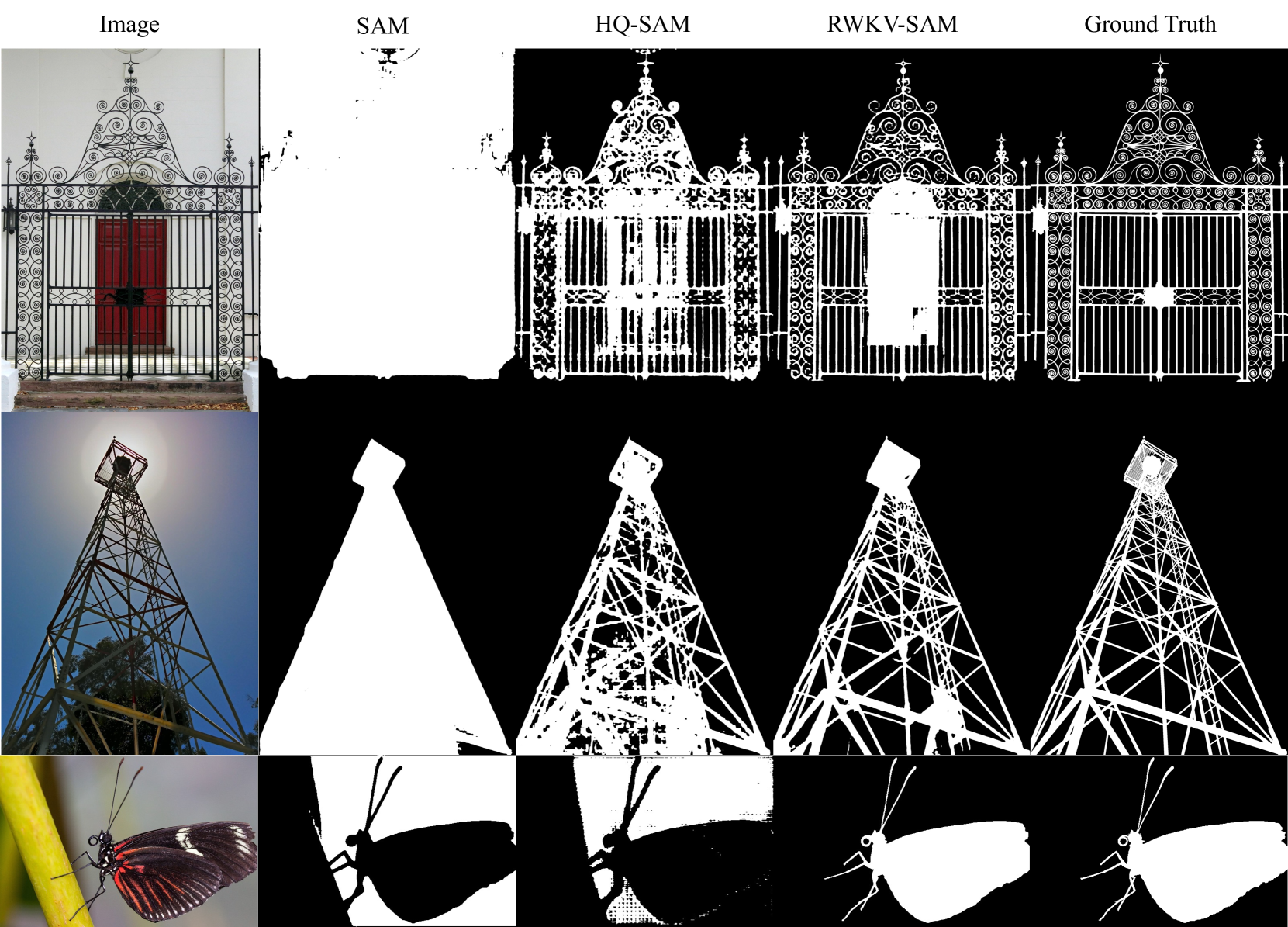
RWKV-SAM
- **论文名称:**Mamba or RWKV: Exploring High-Quality and High-Efficiency Segment Anything Model
- **论文链接:**https://arxiv.org/abs/2406.19369
“RWKV-SAM”(Segment Anything Model)是基于 RWKV 的图像分段切割方法。
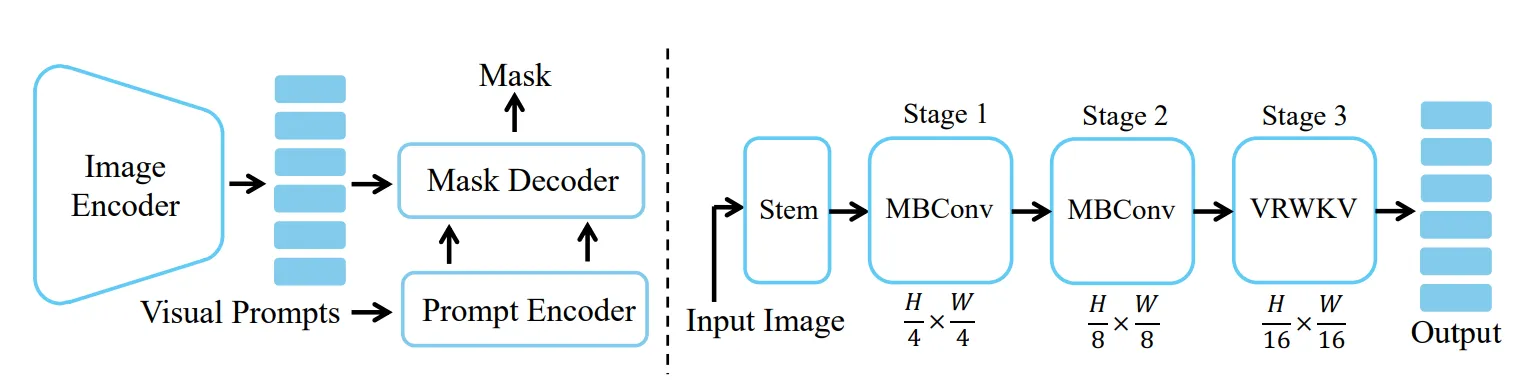
与 Transformer 模型相比,RWKV-SAM(图像分割模型) 实现了 2 倍以上的加速,且可以在各种数据集上实现更好的图像分割性能。
此外,RWKV-SAM 的分类和语义分割结果优于最新的视觉 Mamba 模型。
VisualRWKV
- **论文名称:**VisualRWKV: Exploring Recurrent Neural Networks for Visual Language Models
- **论文链接:**https://arxiv.org/abs/2406.13362
VisualRWKV-6 是基于 RWKV 的可视化语言模型,能够处理各种可视化任务。
VisualRWKV-6 的架构设计是 Data-dependent Recurrence + Sandwich Prompt + Bidirectional Scanning 。
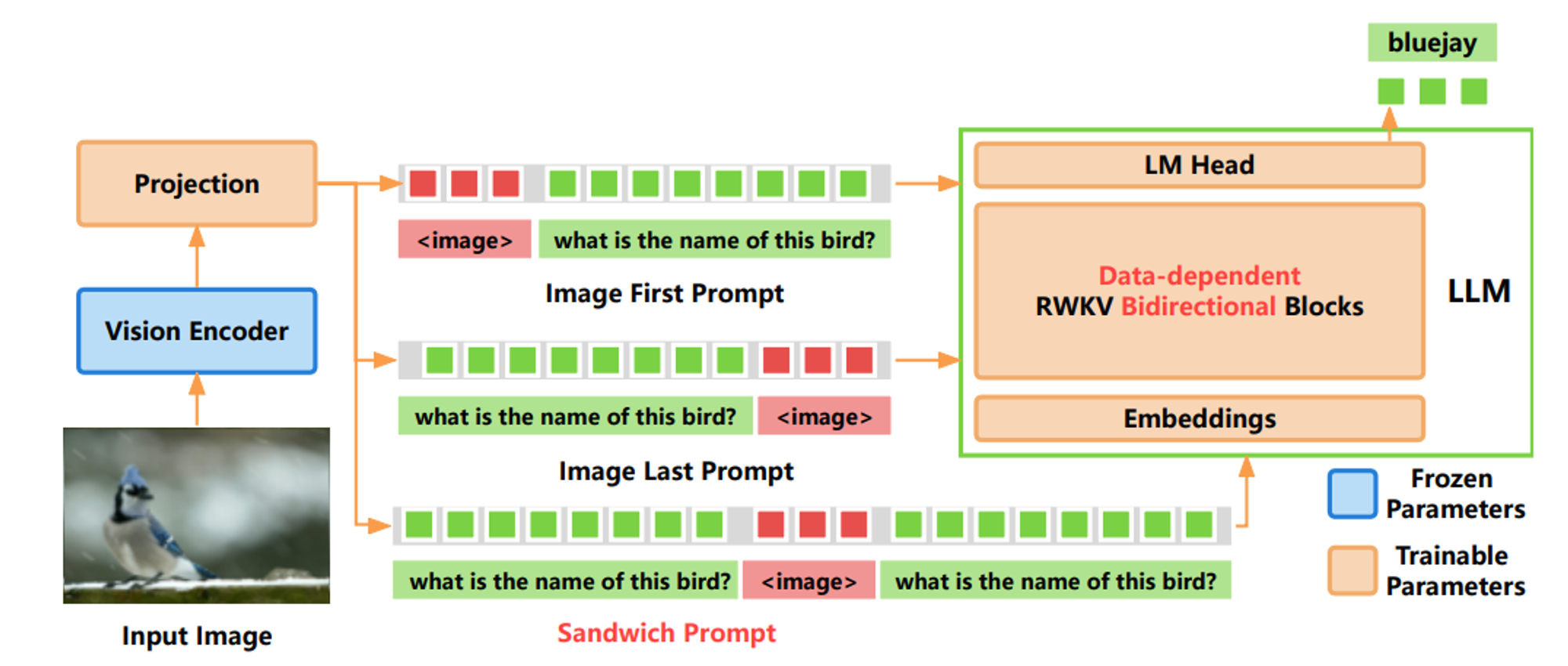
与基于 Transformer 的模型(如 LLaVA-1.5)相比,VisualRWKV 在各种基准测试中实现了具有竞争力的性能。

RWKV-CLIP
- **论文名称:**RWKV-CLIP: A Robust Vision-Language Representation Learner
- **论文链接:**https://arxiv.org/abs/2406.06973
RWKV-CLIP 是一个 RWKV 驱动的视觉-语言表示学习模型,该框架在多个下游任务中实现了最先进的性能,包括线性探测、零样本分类,以及零样本图像文本检索。
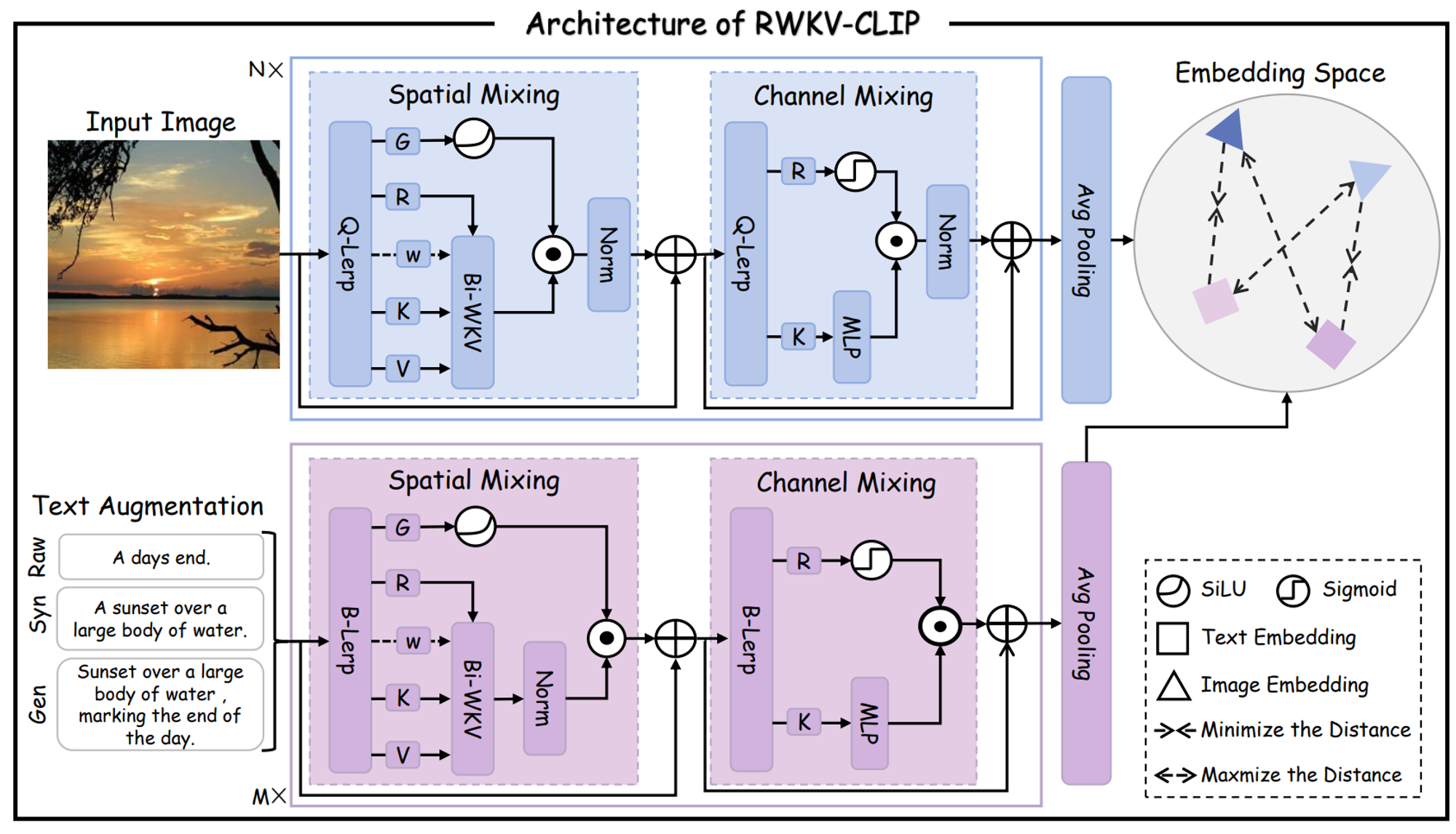
实验结果显示:与 ALIP 相比,RWKV-CLIP 在图像文本模态空间中表现出更近的距离,表明具有卓越的跨模态对齐性能。

PointRWKV
- 论文名称: PointRWKV: Efficient RWKV-Like Model for Hierarchical Point Cloud Learning
- 论文链接: https://arxiv.org/abs/2405.15214
PointRWKV 项目是一种基于 RWKV 的 3D 点云学习框架,在下游点云任务上性能优于基于 Transformer 和 Mamba 的同类工作,显著节省了约 46% 的 FLOPS。
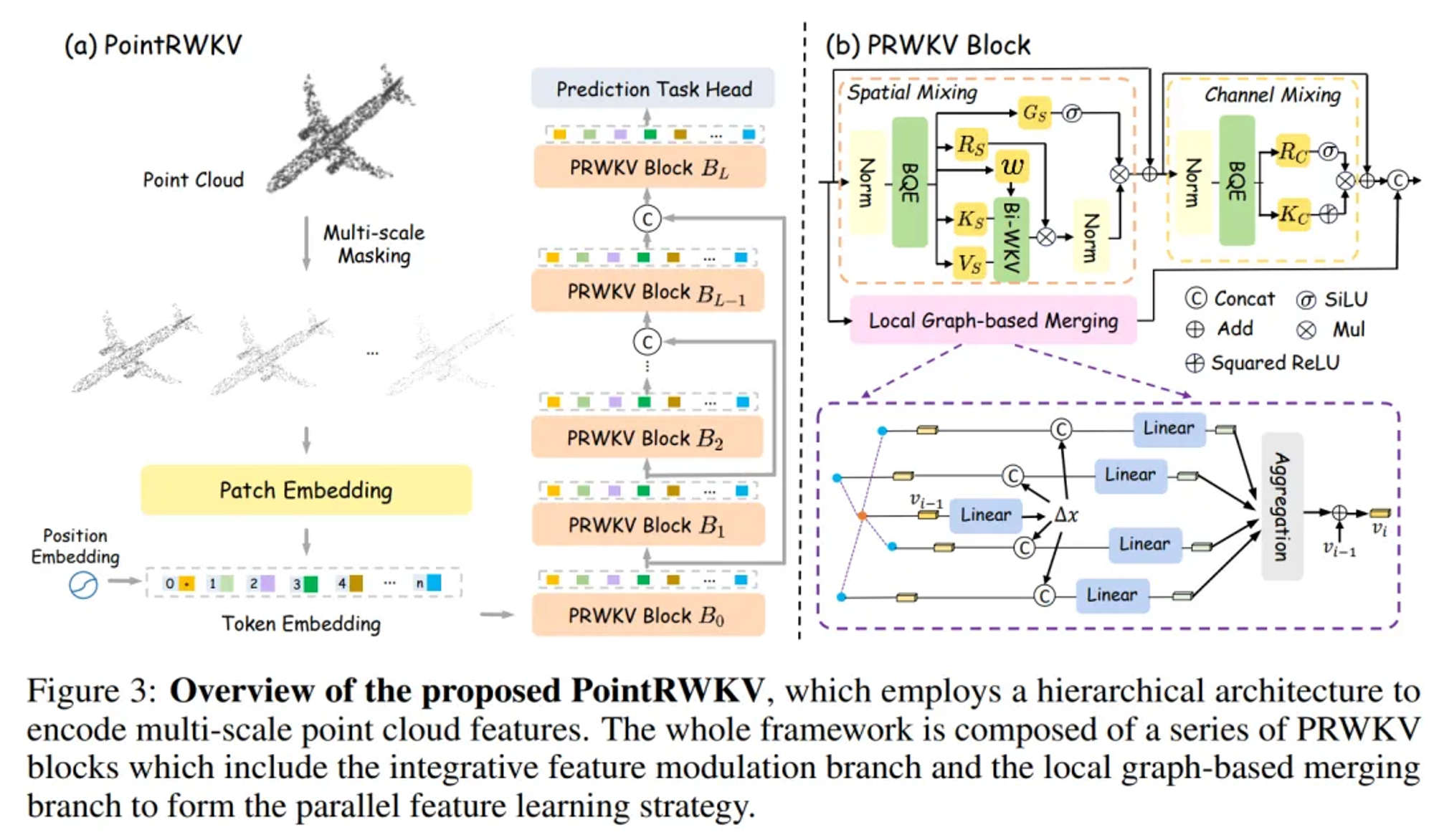
大量实验表明,PointRWKV 优于基于 Transformer 和 mamba 的同类产品,同时展示了构建基础 3D 模型的潜在选择。

混合模型
GoldFinch
- **论文名称:**GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression
- **论文链接:**https://arxiv.org/abs/2407.12077
GoldFinch 是一种 RWKV/Transformer 混合序列模型,将新的 GOLD transformer 叠加在 Finch(RWKV-6)架构的增强版本之上,有效地在线性时间和空间中生成高度压缩和可重用的 KV-Cache。
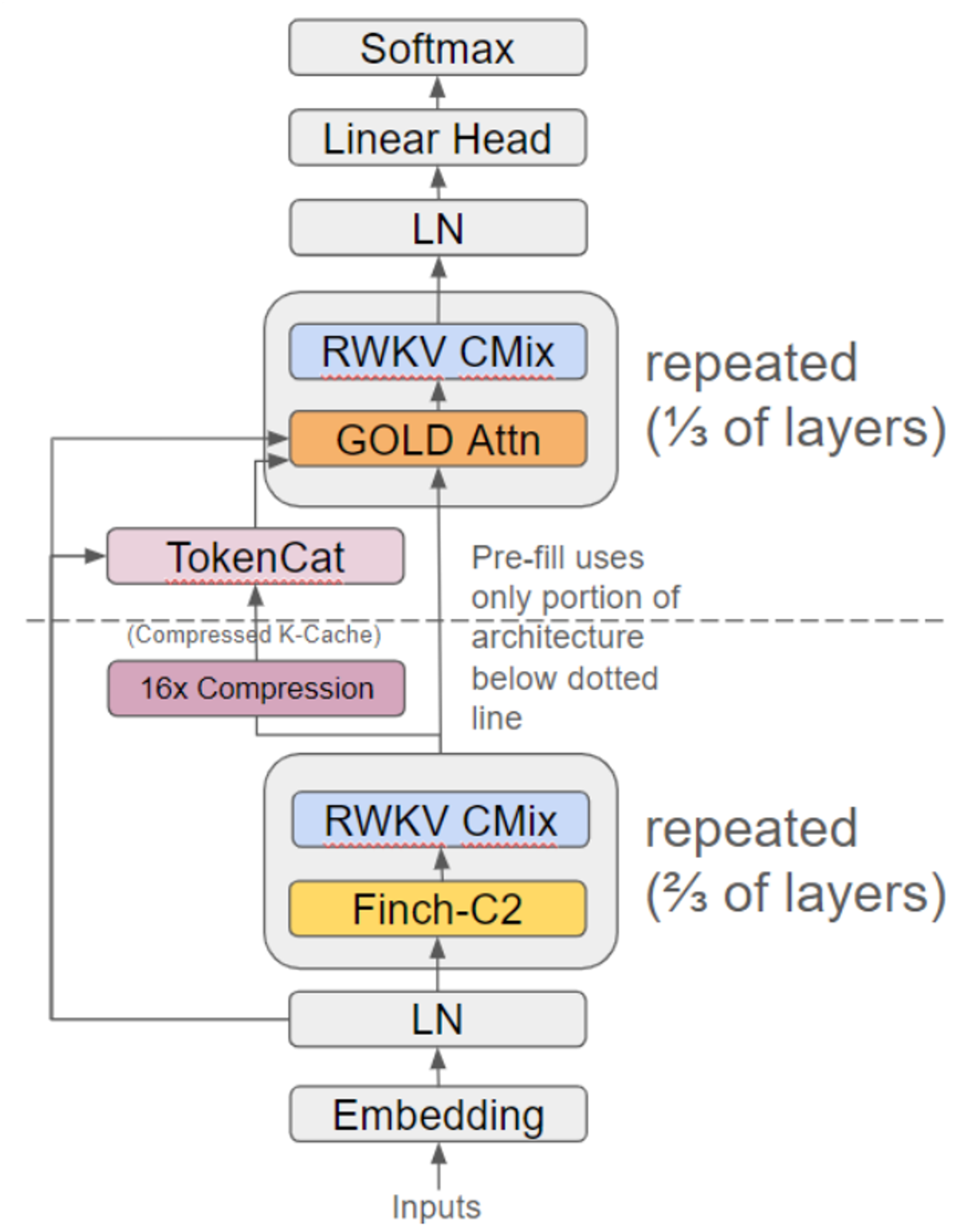
相对于 1.5B 参数的 Finch 和 Llama 模型而言,GoldFinch 的建模性能显着提高。
欢迎大家使用 RWKV 在更多领域深耕,我们也会为基于 RWKV 的项目提供技术支持和一定的资源支持。
如果您的团队有任何沟通交流的意向,请联系我们!(在“RWKV元始智能”微信公众号留言您的联系方式,或发送邮件到“contact@rwkvos.com”)















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









