







动手强化学习——简述
前言
过去一年碌碌无为,浅浅的研究了下计算机视觉相关的内容,某日突发奇想,想尝试将强化学习引入计算机视觉中,介入视觉的匹配等问题中。过去也简单了解了RL相关的内容,但还是太浅了。暑期参加了RL China的短期培训中,收获颇丰,可惜课程时间太短,没有很好的消化,一直像找个机会整理下RL相关的内容。现结合Easy RL,动手强化学习两部书籍及配套视频、资料,做个类似笔记的blog,既做到了整理,又做到了分享的工作。请各位多多指教
提示:以下是本篇文章正文内容,下面案例可供参考
一、几个概念
- 强化学习:通过从交互中学习来实现目标的计算方法。
- 交互过程:在每一步t,智能体:获得观察O_t,获得奖励R_t,执行行动A_t,环境:获得行动A_t,给出观察O_{t+1},给出奖励R_{t+1}
- 历史(History):是观察、奖励、行动的序列,即一直到时间t为止的所有可观测变量。
- 状态(State):是一种用于确定接下来会发生的事情(A,R,O),状态是关于历史的函数。
状态通常是整个环境的, 观察可以理解为是状态的一部分,仅仅是agent可以观察到的那一部分。
状态的理解是有两层的:其一是关于历史的函数,可以理解成由过去得到的现在,其二是agent观测到的环境部分。
-
策略(Policy):是学习智能体在特定时间的行为方式。是从状态到行为的映射。
确定性策略:函数表示 随机策略:条件概率表示 -
奖励(Reward):立即感知到什么是好的,一般情况下就是一个标量
-
价值函数(Value function):长期而言什么是好的
价值函数是对于未来累计奖励的预测,用于评估给定策略下,状态的好坏
价值和奖励也很怪异,建议各位直接记英文;reward是及时的,而value是一个长时间的,两者的关系应该是一个个时刻的reward构成了value。
这里不能将value和reward理解成一个相似的东西。当前reward较大不能代表value较好。比如如果一个孩子由一对有精神缺陷的父母教导,可能在某一时刻,自残反而是reward较大的,但是从value的角度来看,又是较差的。
- 环境的模型(Model):用于模拟环境的行为,预测下一个状态,预测下一个立即奖励(reward)
二、强化学习智能体的分类
基于模型的分类
-
model-based RL:模型可以被环境所知道,agent可以直接利用模型执行下一步的动作,而无需与实际环境进行交互学习。
比如:围棋、迷宫
-
model_free RL:真正意义上的强化学习,环境是黑箱
比如Atari游戏,需要大量的采样
其他方式
- 基于价值:没有策略(隐含)、价值函数
- 基于策略:策略、没有价值函数
- Actor-Critic:策略、价值函数
思维导图
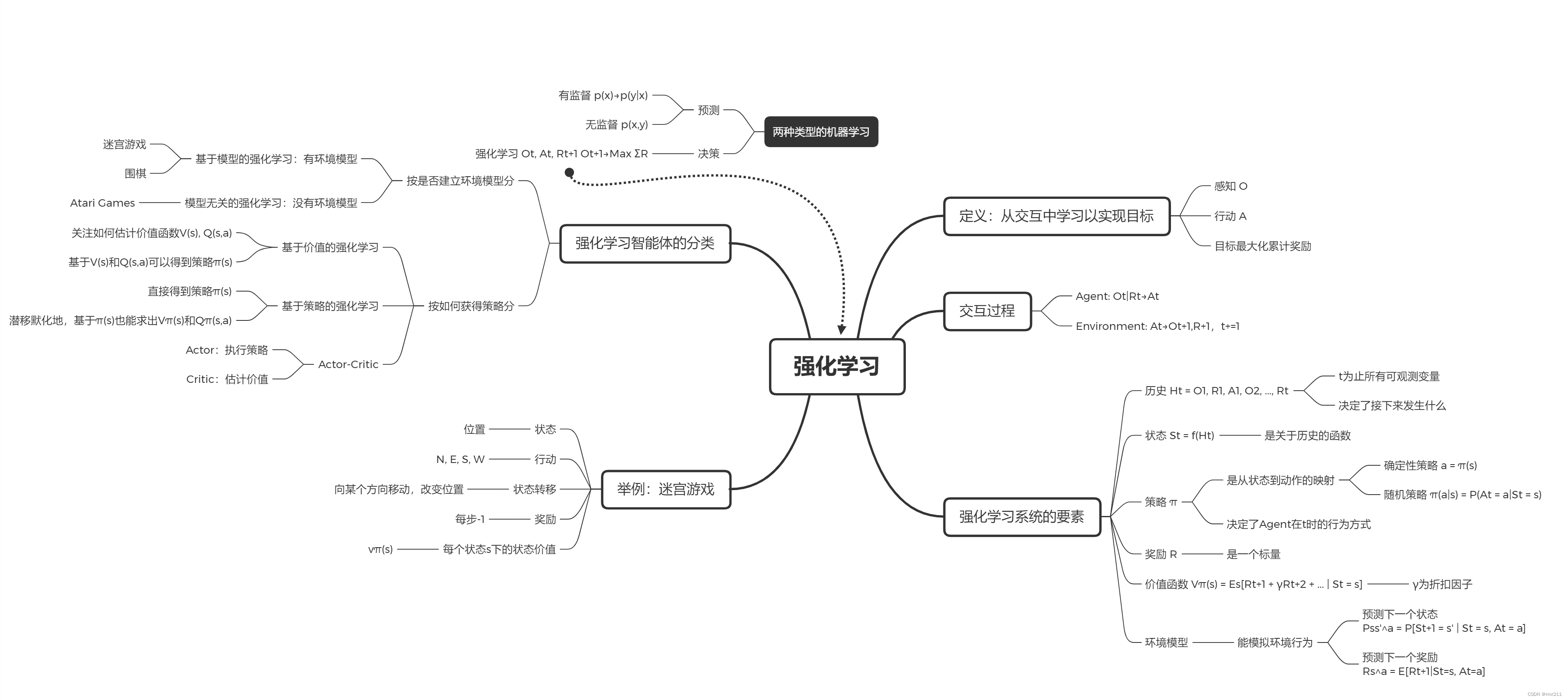
来源:伯禹人工智能学院——强化学习简介课程下陈铭城的学习笔记














 1877
1877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









