







代码参考自动手学强化学习(jupyter notebook版本):https://github.com/boyu-ai/Hands-on-RL
使用pycharm打开的请查看:https://github.com/zxs-000202/dsx-rl
理论部分



实践部分
1.定义一个简单地二维平面上的环境,在一个二维网格世界上,每个维度的位置范围时[0,5],在每一个序列的初始,智能体都位于(0,0)的位置,环境将自动从3.5<=x,y<=4.5的矩形区域内生成一个目标。每个时刻智能体可以选择纵向和横向分别移动[-1,1]作为这一时刻的动作。当智能体距离目标足够近时,它将得到值为0的奖励并结束任务,否则奖励为-1。每一条轨迹的最大长度为50。
class WorldEnv:
def __init__(self):
self.distance_threshold = 0.15
self.action_bound = 1
def reset(self): # 重置环境
# 生成一个目标状态, 坐标范围是[3.5~4.5, 3.5~4.5]
self.goal = np.array(
[4 + random.uniform(-0.5, 0.5), 4 + random.uniform(-0.5, 0.5)])
self.state = np.array([0, 0]) # 初始状态
self.count = 0
return np.hstack((self.state, self.goal)) # 水平方向上拼接
def step(self, action):
action = np.clip(action, -self.action_bound, self.action_bound)
x = max(0, min(5, self.state[0] + action[0]))
y = max(0, min(5, self.state[1] + action[1]))
self.state = np.array([x, y])
self.count += 1
dis = np.sqrt(np.sum(np.square(self.state - self.goal)))
reward = -1.0 if dis > self.distance_threshold else 0
if dis <= self.distance_threshold or self.count == 50:
done = True
else:
done = False
return np.hstack((self.state, self.goal)), reward, done
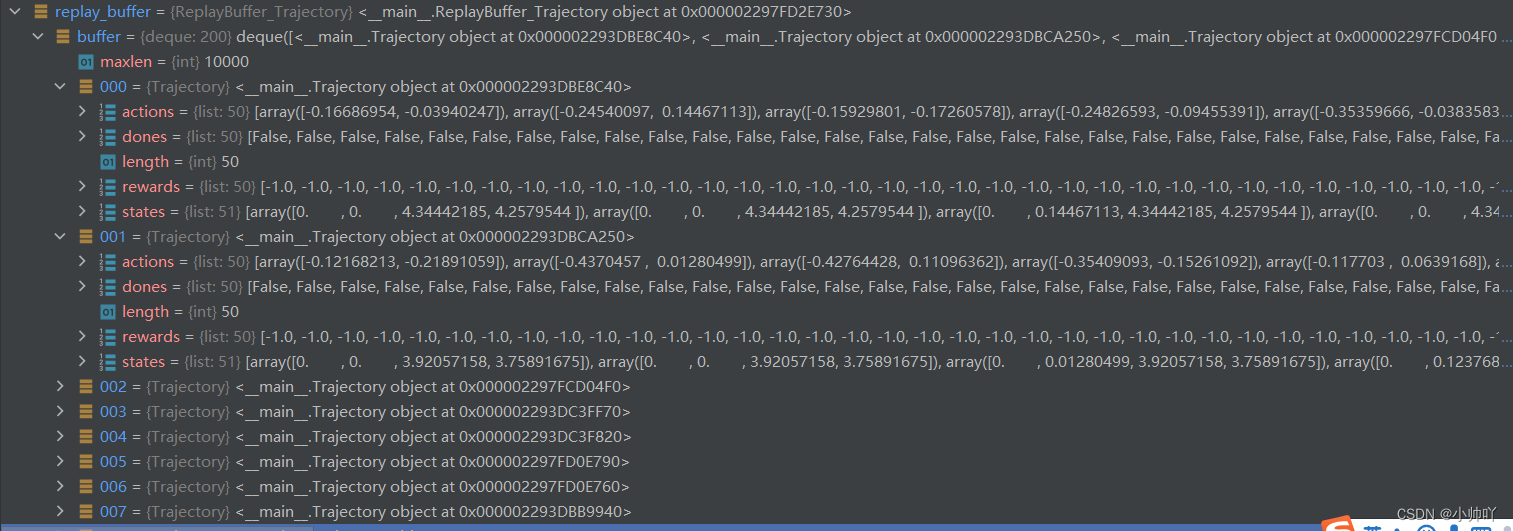
2.首先通过以下代码产生一个episode的轨迹并保存在Trajectory类实例化的traj对象中,其中存储了这条轨迹的状态序列、动作序列、奖励序列、是否完成序列、轨迹长度值。
class Trajectory:
''' 用来记录一条完整轨迹 '''
def __init__(self, init_state):
self.states = [init_state]
self.actions = []
self.rewards = []
self.dones = []
self.length = 0
def store_step(self, action, state, reward, done):
self.actions.append(action)
self.states.append(state)
self.rewards.append(reward)
self.dones.append(done)
self.length += 1
episode_return = 0
state = env.reset() # state为初始位置与目标位置的拼接
traj = Trajectory(state)
done = False
while not done:
action = agent.take_action(state)
state, reward, done = env.step(action)
episode_return += reward
traj.store_step(action, state, reward, done)
生成一个轨迹之后的traj中存储的数据如下图所示:

3.之后将生成的轨迹存储到经验回放池中
replay_buffer.add_trajectory(traj)
return_list.append(episode_return)
和DDPG、DQN不同的是这里是存储的一条一条的trajectory,而那两个存储的是一个一个的transition。另外,这里的sample方法和前者有较大的差别。
class ReplayBuffer_Trajectory:
''' 存储轨迹的经验回放池 '''
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add_trajectory(self, trajectory):
self.buffer.append(trajectory)
def size(self):
return len(self.buffer)
def sample(self, batch_size, use_her, dis_threshold=0.15, her_ratio=0.8):
batch = dict(states=[],
actions=[],
next_states=[],
rewards=[],
dones=[])
for _ in range(batch_size):
traj = random.sample(self.buffer, 1)[0]
step_state = np.random.randint(traj.length)
state = traj.states[step_state]
next_state = traj.states[step_state + 1]
action = traj.actions[step_state]
reward = traj.rewards[step_state]
done = traj.dones[step_state]
if use_her and np.random.uniform() <= her_ratio:
step_goal = np.random.randint(step_state + 1, traj.length + 1)
goal = traj.states[step_goal][:2] # 使用HER算法的future方案设置目标
dis = np.sqrt(np.sum(np.square(next_state[:2] - goal)))
reward = -1.0 if dis > dis_threshold else 0
done = False if dis > dis_threshold else True
state = np.hstack((state[:2], goal))
next_state = np.hstack((next_state[:2], goal))
batch['states'].append(state)
batch['next_states'].append(next_state)
batch['actions'].append(action)
batch['rewards'].append(reward)
batch['dones'].append(done)
batch['states'] = np.array(batch['states'])
batch['next_states'] = np.array(batch['next_states'])
batch['actions'] = np.array(batch['actions'])
return batch
4.当经验回放池中的轨迹数大于等于200开始进行更新
首先,通过从replay_buffer中sample数据,具体而言就是:sample256条数据到batch中,其中每条是通过从replay_buffer中抽样一个trajectory,然后从trajectory中抽样一个transition;如果应用HER算法,那么在一定几率下,对transition中得数据做一些处理再添加到batch中。处理的操作就是:从该trajectory随机抽样一个该transition之后的transition,我们叫它step_goal吧,然后将这个transition的状态的前两个数(即该transition的初始位置)和原transition的状态的后两个数进行替换,即新的要存到batch中的transition的状态的前两个是原来的,然后目标是后面transition的初始位置。
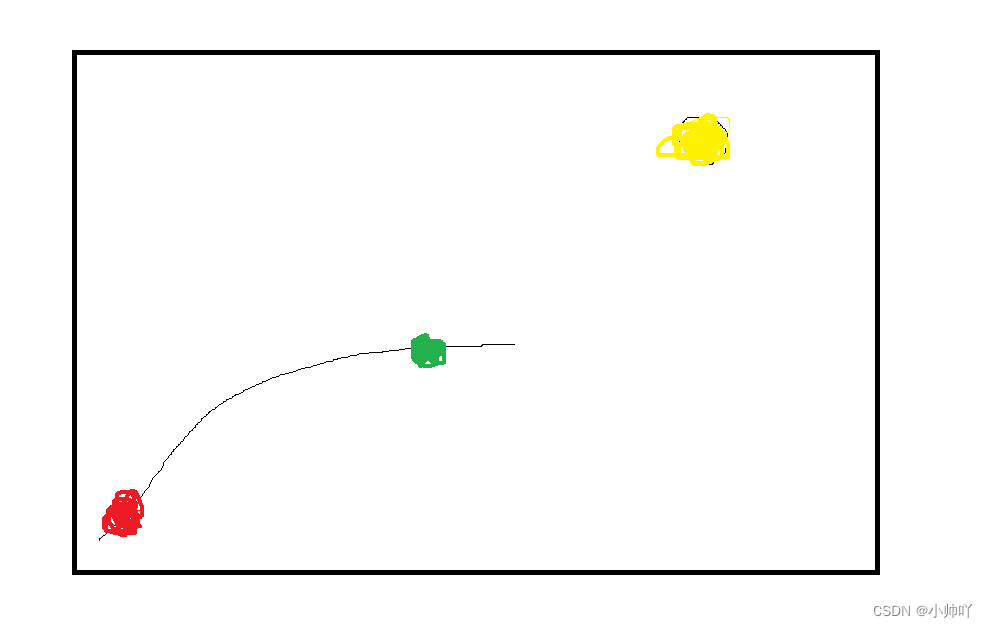
就比如红色是原来的transition对应位置,黄色是终极目标,通过随机抽样整个轨迹中红色之后的一个transition,这里假设就是绿色的点的位置。我们原来的状态是红色,想要到达红色,很明显比较困难。此时,我们可以先假设我们的目标是绿色,通过这种方式,更换transition中state的信息。最终,可以更容易的训练实现物体到达目标位置。
for _ in range(n_train): # n_train=20 batch_size = 256
transition_dict = replay_buffer.sample(batch_size, True)
agent.update(transition_dict)
class ReplayBuffer_Trajectory:
''' 存储轨迹的经验回放池 '''
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add_trajectory(self, trajectory):
self.buffer.append(trajectory)
def size(self):
return len(self.buffer)
def sample(self, batch_size, use_her, dis_threshold=0.15, her_ratio=0.8):
batch = dict(states=[],
actions=[],
next_states=[],
rewards=[],
dones=[])
for _ in range(batch_size): # batch_size=256
traj = random.sample(self.buffer, 1)[0]
# 从buffer中随机抽样一个轨迹
step_state = np.random.randint(traj.length)
# 从抽样的轨迹中随机抽样出一个transition
state = traj.states[step_state]
# 抽样出的transition的state
next_state = traj.states[step_state + 1]
# 抽样出的transition的next_state
action = traj.actions[step_state]
# 抽样出的transition的动作
reward = traj.rewards[step_state]
# 抽样出的transition的奖励
done = traj.dones[step_state]
# 抽样出的transition是否done
if use_her and np.random.uniform() <= her_ratio:
step_goal = np.random.randint(step_state + 1, traj.length + 1)
# 从上面transition之后的轨迹选择一个设置之后的goal
goal = traj.states[step_goal][:2]
# 使用HER算法的future方案设置目标,选择此transition的当前位置作为goal
dis = np.sqrt(np.sum(np.square(next_state[:2] - goal)))
reward = -1.0 if dis > dis_threshold else 0
done = False if dis > dis_threshold else True
state = np.hstack((state[:2], goal))
# 将原来的初始位置和后来挑选的goal拼接
next_state = np.hstack((next_state[:2], goal)) # 将原来的下一个transition的初始位置和goal拼接
batch['states'].append(state)
batch['next_states'].append(next_state)
batch['actions'].append(action)
batch['rewards'].append(reward)
batch['dones'].append(done)
batch['states'] = np.array(batch['states'])
# 256*4
batch['next_states'] = np.array(batch['next_states'])
# 256*4
batch['actions'] = np.array(batch['actions'])
# 256*2
return batch
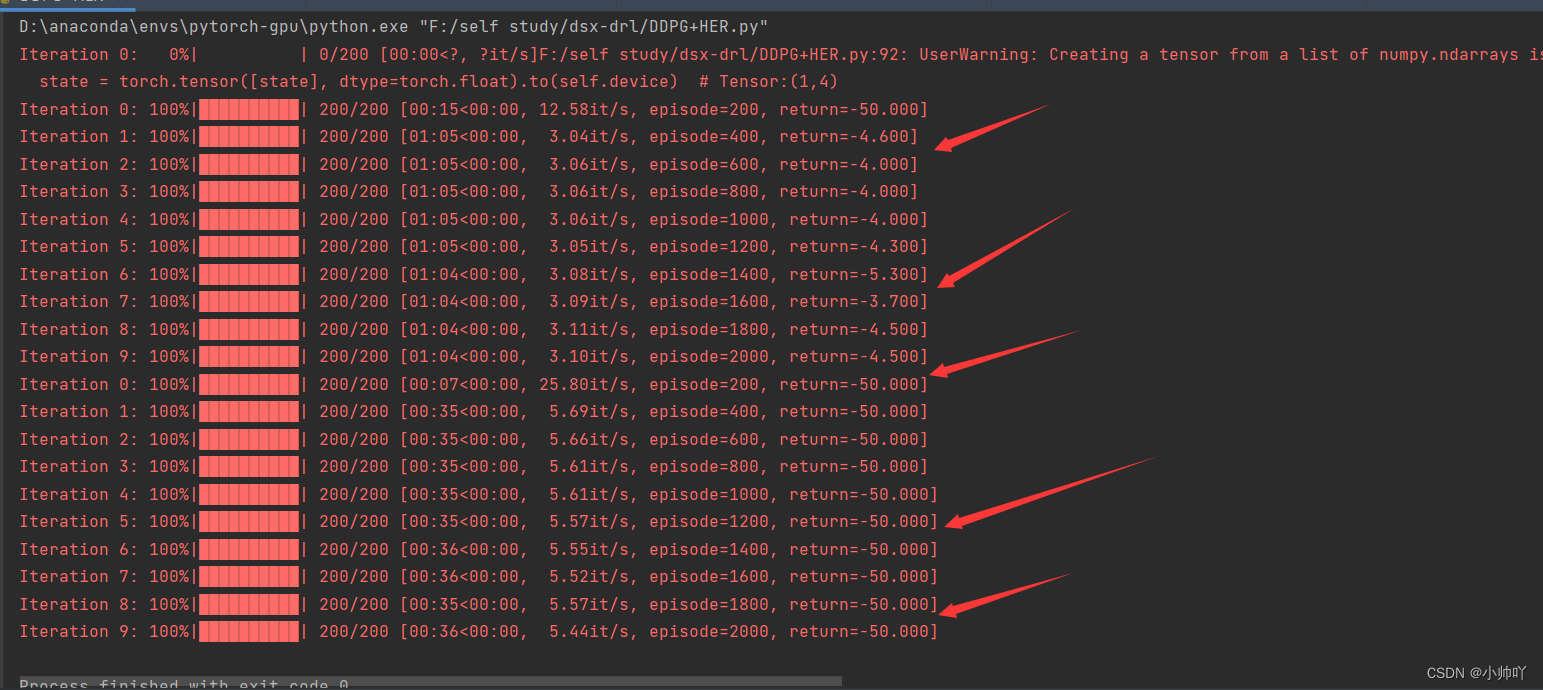
5.实验过程和结果
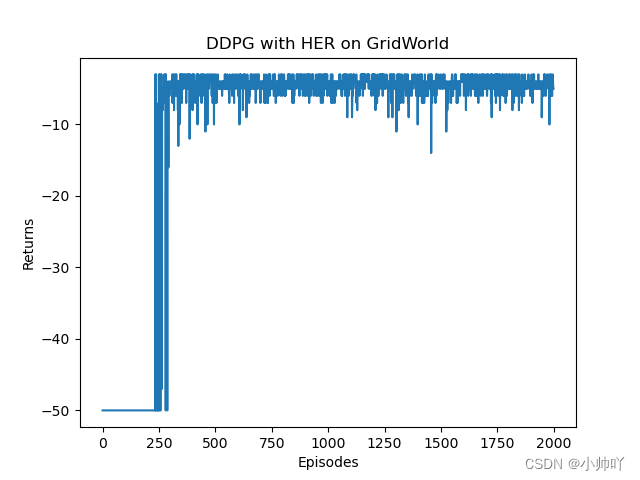
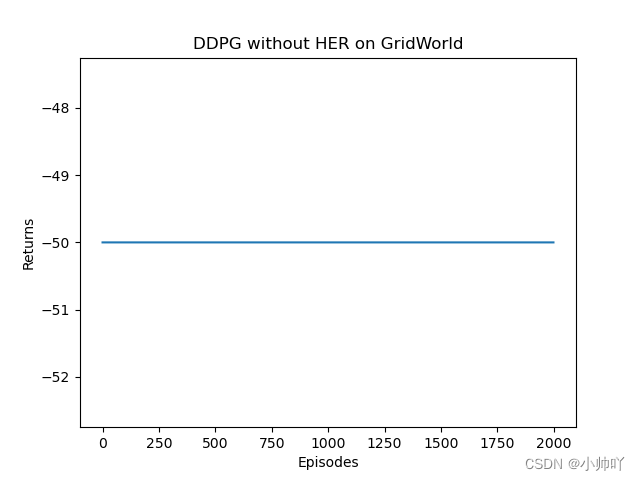















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









