







这是编译原理大作业的第一步:词法分析与语法分析,最终效果是构建出语法树。
学过编译原理都知道,词法分析要用自动机,语法分析要用 CFG。善良的老师说,我们可以不用手写自动机和 CFG,可以用工具。然后又看到实验室里做逻辑公式求解器的代码也用的是 flex 和 bison,于是我就需要学习 flex+bison 这一套现代工具链。
过程中我发誓我一定要写一篇 flex 和 bison 踩坑记
推荐资料:《flex&bison》(中文版叫《flex与bison(中文版)》)、bison官方文档,做的过程中遇到问题在谷歌里搜索,StackOverflow 的解答还是相当不错的,也有些国内的博客回答问题也很 nice,这是少有的。
环境:Ubuntu18,flex 2.6.4,bison 3.0.4。强烈推荐 Windows 用户使用 WSL,右键即可打开当前目录下的 Linux 环境,妈妈再也不用担心我没有 Linux。
项目地址。
Task
有一个语言叫 Tiny,具体规则在这里。
- 将 Tiny 扩展成 Tiny+,用 EBNF 描述 Tiny+ 的语法;
- 将 Tiny+ 源程序翻译成对应的 token 序列,并能检查一定的词法错误;
- 将 token 序列转换成语法分析树,并能检查一定的语法错误。
(听说有标准的 Tiny+ 语言,但是我没找到,老师的要求是自行扩展,那么我就自行扩展了,主要让它尽量完备。放在这里)
flex 与 bison 的组合
flex 是用来做词法分析的,bison 是用来做语法分析的。
最早的组合版本叫 lex+yacc,然后 lex 升级成了 flex,yacc 升级成了 bison,于是现代工具链就变成了 flex+bison。
flex 需要编写一个 .l 文件,然后用 flex 根据它生成一个 lex.yy.c 文件,用 C 编译器编译就可以了。这个文件读入字符串,通过调用 int yylex() 每次返回一个 token。
bison 需要编写一个 .y 文件,然后用 bison 根据它生成一个 .tab.h 和 .tab.c 文件。后者实现了一个过程 yyparse(),每次读入一个 token,根据 CFG 规则进行归约;前者则给出了相关接口(如 token 的定义)。
组合使用的方法为:lex.yy.c 里面 #include"xxx.tab.h";在 xxx.tab.c 里实现 main 函数或者单开一个文件实现 main 函数并 #include"xxx.tab.h"(推荐后者),然后使用 C/C++ 编译器联合编译。
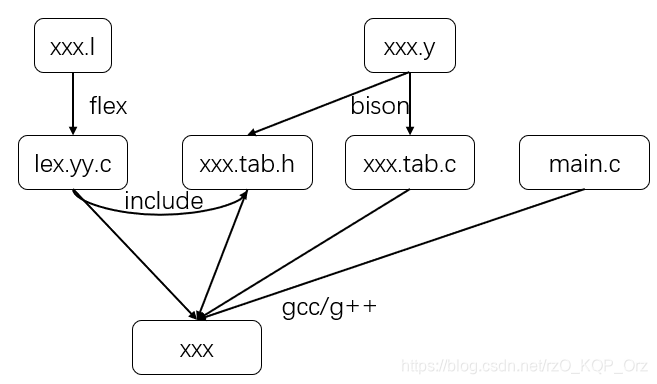
所以编译的时候最好写个 Makefile。
bison
bison 的基本格式是
%{
/* part 1 */
%}
%%
/* part 2 */
%%
/* part 3 */
part 1 将原封不动抄到生成代码的开头,part 3 将原封不动抄到生成代码的结尾,part 2 是 CFG 规则描述区,其余部分可以用来设置一些有用的开关和定义。/* 和 */ 是注释。
bison - part 1
part 1 一般用来声明头文件和接口,例如
%{
#include<bits/stdc++.h>
#include"syntax_tree.h"
using namespace std;
extern int yylex();
void yyerror(const char* s);
node *root;
%}
前面说过 int yylex() 是每次调用返回一个 token,这是与 flex 的接口之一。
这里有个坑,yyerror 过程是它生成的代码里会用到的,但是它自己没有声明!!还得我们用户来声明!!
root 则是我们要构建的语法树的根。语法树的结点基类是 node,而语法规则里的每一个非终结符对应一个自己特有的派生类。这些定义放在 syntax_tree.h 里。
这个写法比较工程,每个非终结符对应自己特有的派生类,就既可以在基类定义公有方法,也可以定义自己特有的变量和方法。比如“表达式 Expression”需要记录该表达式的类型,或者值,但是“区块 Block”就不用这些东西。同时,还可以用虚函数等多态特性,避免臃肿的 switch。
bison - part 1.5
在 part 2 之前,我们需要先定义 token 和所有标识符。
/* part 1 */
%}
%define api.value.type union
%token<int> Number_Integer
%token<double> Number_Float
%token<char*> IdString QString
%token IF ELSE FOR WRITE READ RETURN tkBEGIN END MAIN INT REAL CHAR Assign ":=" Equal "==" NEqual "!=" LE "<="
%type<node_Program*> Program
%type<node_MethodDecls*> MethodDecls MethodDeclsWithMain
%type<node_MethodDecl*> MethodDecl MethodDeclMain
%type<node_FormalParams*> FormalParams
...
%%
/* part 2 */
这里用 token 来定义终止标识符,用 type 来定义非终止标识符,后面尖括号是它的类型,无类型则不用加括号。":=" 这样的用引号括起来的表示别名。
类型是这么回事:CFG 的每条产生式在进行归约的时候,可以让你返回一个值,比如返回语法树结点的指针。从词法分析器来的 token,也可以带有值,比如常数值。
在 bison 3.0 以上的版本,可以用 %define api.value.type union 开关然后在下面尖括号里面直接写变量类型。否则,需要手动写一个 union 来把这些类型合并起来。注意这里需要使用能被 union 起来的类型,像 std::string 这类变长的就不行。
(更高级的版本特性支持 std::string,详见官方文档。)
有些 token 如果只是单个字符,则可以不用专门起名字,不用在这里声明。例如加号“+”,要用的时候用单引号引起来即可。
bison - part 2
part 2 用来写 CFG 规则,形式如
%%
<标识符>: <产生式1> {产生式1要做的事} | <产生式2> {产生式2要做的事} ;
%%
例如
%%
Program:
MethodDeclsWithMain {$$ = new node_Program(1,$1); root=$$;}
;
MethodDecls:
MethodDecl {$$ = new node_MethodDecls(1,$1);}
| MethodDecl MethodDecls {$$ = new node_MethodDecls(2,$1,$2);}
;
...
%%
$$ 表示当前标识符的返回值,$1,$2... 分别表示当前产生式的各标识符的返回值(无论是终止标识符还是非终止标识符都是有返回值的)。
把程序语言的规则逐条抄下来,这就可以把整个语法树构建起来了。
由于每个结点的子结点数量不相同,为方便维护,推荐使用可变参列表来传递子结点信息。可以在基类写一个统一的构造函数,子类的构造函数就把可变参列表传递给基类。
bison - part 3
part 3 没啥要写的,调试的时候可以在这里写个 main 函数,但最终还是分离出去好些。
这里要实现的是 void yyerror(const char *s) 函数,这玩意在 part 1 被声明,在它生成的代码里被调用,那么就在 part 3 这里实现。这个是语法分析出错时向用户输出报错信息的,把 s 输出就可以了。
/* part 2 */
%%
void yyerror(const char *msg) {
printf("%s\n",msg);
}
bison 编译
编译命令是 bison -d xxx.y,要加上 -d 才能生成 xxx.tab.h 头文件。
flex
flex 的基本格式与 bison 相同:
%{
/* part 1 */
%}
%%
/* part 2 */
%%
/* part 3 */
part 1 将原封不动抄到生成代码的开头,part 3 将原封不动抄到生成代码的结尾,part 2 是 token 的规则描述区,其余部分可以用来设置一些有用的开关和定义。/* 和 */ 是注释。
flex - part 1
part 1 一般用来声明头文件,比如
%{
#include<bits/stdc++.h>
#include"syntax_tree.h"
#include"tiny.tab.h"
using namespace std;
%}
这里要引用 bison 生成的头文件 xxx.tab.h,里面用 enum 定义了 token。因为 part 2 是要完善 int yylex(),这个的返回值就是 token 的 enum。
flex - part 1.5
这里可以用正则表达式定义一些记号,避免后面过于繁琐,比如
Integer ([1-9][0-9]*|[0])
flex - part 2
part 2 写 token 规则。基本格式是
<正则表达式> {要做的事}
例如
%%
"IF" {return IF;}
"ELSE" {return ELSE;}
"FOR" {return FOR;}
...
"+" |
"-" |
";" {return yytext[0];}
":=" {return Assign;}
...
{Integer} {yylval.Number_Integer=atoi(yytext); return Number_Integer;}
{Integer}"."[0-9]+ {yylval.Number_Float=atof(yytext); return Number_Float;}
[a-zA-Z_][a-zA-Z_0-9]* {yylval.IdString=yytext; return IdString;}
\"..*\" {yylval.QString=yytext; return QString;}
[ \t\n\r]+
"/**".*"**/"
. {printf("%d: Undefined token\n",yylineno);}
%%
return 的值是该 token 的 enum 值;变量 yylval 用来记录这个 token 的值,在 bison 里的 $1,$2... 被用到;变量 yytext 记录了当前匹配到的输入字符串。
第一部分用引号引起来的是关键字,直接返回相应的无类型 token。
第二部分是字符 token,如果是单个字符,在 bison 里没有声明,就直接返回字符本身即可(也就是 yytext[0])。
注意有个坑,每个正则表达式都要放在行首,不能因为 | 符号就接在别人后面,一定要另起一行。
第三部分是复杂一点的 token:整数、浮点数、变量名函数名、双引号非空字符串。这里不仅要返回 token 的 enum,还要记录 token 的值,token 的值的类型就是 bison part 1.5 里的大 union,如果用了 %define api.value.type union 开关的话,标识符的名称就是值的类型的名称。
第四部分是空白字符和注释,它们不做任何操作。
第五部分是一个简单的词法分析报错,如果匹配不上以上规则,就输出非法字符。
flex - part 3
没啥做的。调试的话可以在这里写 main 函数。
flex 编译
flex xxx.l
余下的事情
经过上面两步,已经生成好词法分析和语法分析的 C 代码了,接下来只要把 syntax_tree.h 和 main.c/cpp 完成,就可以编译了。
main 里要做的,就是调用 int yyparse() 函数,进行语法分析。该函数正常结束时返回 0。当然,还有必要的用户交互要在这里写。
如果要画出语法树,那么就在基类里写一个 dfs 就好了,每个子类实现一个虚函数 get_type 返回它的类型和相关信息即可。
简单的 Makefile 如下:
tiny: tiny.tab.c lex.yy.c main.cpp syntax_tree.h syntax_tree.cpp
g++ main.cpp syntax_tree.cpp tiny.tab.c lex.yy.c -o tiny -g
tiny.tab.c: tiny.y
bison -d tiny.y
lex.yy.c: tiny.l
flex tiny.l
高级特性
使用 g++ 编译
flex 里使用开关 %option noyywrap。写在 part 1.5 的地方。
因为 flex 生成的代码用到了 yywrap 这个东西,这个东西在动态链接库 -lfl 中,而这个库会导致不能用 g++。
因此直接把 yywrap 禁了就好了。这个东西是历史遗留功能,用不上的。
flex 文件读入
flex 生成的代码里有个 FILE *yyin 变量,默认是指向 stdin。在 main.cpp 里 extern 出来,然后指向一个文件,就可以文件读入了。
通常应该像命令行操作的编译器一样,由运行参数指定文件名。
语法分析器的 debug
观察 bison 生成的 .tab.c 文件,发现它 printf 了很多调试信息,怎么把它们用起来呢?
在 bison 里打开两个开关,一个是 %define parse.trace,写在 part 1.5 的地方;另一个是将 yydebug 这个变量赋一个非零值(这个变量在 .tab.h 里声明了,因此随时随地可以直接赋值)。
这个 debug 信息非常详细,bison 是用 LALR 的,它把它每一步进入了什么状态、栈里有什么、移进归约选择全部列出来了,十分好用,就是有点长。
查看 LALR 状态以及哪个规则发生冲突
有时候 bison 编译 warning 说有移进归约冲突 / 归约归约冲突,所以想看看是哪条规则搞的。
bison 编译的时候加个 -v,即可生成一个 .output 文件,里面列出了 LALR 的详细信息,包括状态、移进归约指示。被方括号括起来的规则,就是因冲突而弃用的规则。
优先级
这是个比较大的话题。
flex 的默认冲突处理是:匹配尽量长的输入字符串,等长时匹配写在最前面的规则。
bison 的默认冲突处理是:移进归约冲突优先移进。
一般来说,出现二义性,多数情况下是语法本身有问题,应当优先修改语法。
但是也有例外,例如运算表达式,虽然可以修改语法使得加减乘除之间不具有二义性,但是运算符变多了以后这个方法就很蠢了。例如 if-else,可以用龙书的 matched_stmt 和 open_stmt 来使得它没有歧义,但是相关的 stmt 的定义会变得很丑。
运算表达式的解决方法:优先级符号,在 bison part 1.5 的部分定义优先级
%nonassoc "==" "!=" '<' "<="
%left '+' '-'
%left '*' '/'
%nonassoc UMINUS
优先级从上往下依次递增,同一行优先级相同。left 表示该符号左结合,right 表示该符号右结合,nonassoc 表示不具有结合性。
一个规则的优先级取决于该规则最右边的 token 的优先级。于是就可以直接像下面这么写了:
Expression:
| Expression '+' Expression {$$ = new node_Expression(OP_PLUS,2,$1,$3);}
| Expression '-' Expression {$$ = new node_Expression(OP_MINUS,2,$1,$3);}
| Expression '*' Expression {$$ = new node_Expression(OP_MUL,2,$1,$3);}
| Expression '/' Expression {$$ = new node_Expression(OP_DIV,2,$1,$3);}
| Expression Equal Expression {$$ = new node_Expression(OP_EQUAL,2,$1,$3);}
| Expression LE Expression {$$ = new node_Expression(OP_LE,2,$1,$3);}
| '-' Expression %prec UMINUS {$$ = new node_Expression(OP_UMINUS,1,$2);}
...
;
这里还定义了负数。'-' Expression 这里用了 %prec,这表示规定这条规则的优先级是后面那个符号,而不是减号的优先级。
if-else 的解决方法:一般来说不用解决,因为有默认规则“移进归约冲突优先移进”。如果看 warning 不顺眼非要消除,可以用优先级符号把 else 的优先级抬高。
报错输出行号
可以在 flex 里使用开关 %option yylineno,这样你就拥有了一个变量 yylineno 记录当前的行号。
在 void yyerror(const char *s) 过程里,就可以输出行号了:
void yyerror(const char *msg) {
printf("%d: %s\n",yylineno,msg);
}
但是要在 bison 的 part 1 的部分 extern int yylineno;。
输出更多报错信息
传给 yyerror 的报错信息默认只有 “syntax error”。但是观察 .tab.c,发现它还有诸如这样的代码:
switch (yycount)
{
YYCASE_(0, YY_("syntax error"));
YYCASE_(1, YY_("syntax error, unexpected %s"));
YYCASE_(2, YY_("syntax error, unexpected %s, expecting %s"));
YYCASE_(3, YY_("syntax error, unexpected %s, expecting %s or %s"));
...
于是我们知道又有开关没用起来。
这个只需要在 bison 使用 %error-verbose(写在 part 1.5)即可。这样,我们的报错信息就又稍微丰富了些。
error 标识符
但是这个报错信息还是简陋了些,怎样才能像 g++ 那样有丰富的报错信息呢?
在 bison 中可以使用 error 标识符,它不用提前声明,作用有点类似万能匹配符。在语法分析出现错误的时候,它就开始退栈,直到能匹配带有 error 标识符的规则。
因此可以针对性地输出错误信息了:
AssignStatement:
...
| Id error Expression ';' {yyerror(“expect \":=\" before Expression."); $$ = nullptr;}
| Id ':=' Expression {yyerror("expect \";\" at the end of the statement."); $$ = nullptr;}
可以自行搞一些交互变量来阻止默认的 yyerror 调用以避免重复报错。详见《flex&bison》得到更加丰富的报错信息,例如加上当前所在文件、错误发生的列号等。
destructor
上面还存在一个问题:语法分析出错要退栈的时候,树结点是要析构的!
因此在 bison part 1.5 要写有 %destructor{要做的事} 标识符或<类型>,例如
%destructor{} <int> <double> <char*>
%destructor{ clear($$); } <*>
<*> 表示匹配任意类型,因为每个标识符有自己的子类所以类型挺多的。然后普通的类型不用析构,所以把普通类型又单列了出来。clear(node*) 是自己写的递归析构。
yynerrs
直接上面这样写是有问题的。凡是非归约退栈都会调用 destructor,这不仅包括遇到错误退栈,还包括整个语法分析完成后的根节点退栈。于是你发现,根节点被析构了。。。
因此要加一点判断,只有遇到错误时才进行析构。.tab.c 里有一个 yynerrs 变量记录了当前总共发生了多少次错误,把它 extern 出来,将它作为析构条件。
%destructor{ if (yynerrs) clear($$); } <*>














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









