







1.基础环境介绍
pytorch 1.8.1
python 3.8(ubuntu18.04)
cuda 11.1
我是租的云服务器,按照这个配置选镜像即可,安装基础环境这块就搞定了;如果想自己安装环境,参照网上给的三者版本对应关系去安装即可。
本文中需要下载的包,我在百度网盘有提供哈,需要的文末自取。
2.yolov3源码下载
1、模型代码下载地址:GitHub - ultralytics/yolov3: YOLOv3 in PyTorch > ONNX > CoreML > TFLite
2.点进去网址如下界面,点击’下载ZIP‘
3.下载完,放到准备好环境的服务器上,解压;解压之后的目录如下:

3.下载VOCdevkit2007数据集
下载地址:
# 训练验证集
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
# 测试集
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# 开发工具包代码和文档
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
windows系统在浏览器地址栏复制以上三个网址会自动下载得到以下三个压缩包:
 此时注意不要直接解压:分别解压缩会生成3个文件夹,这并不是我们想要的,我们需要的是他们在同一个文件夹下
此时注意不要直接解压:分别解压缩会生成3个文件夹,这并不是我们想要的,我们需要的是他们在同一个文件夹下
解压正确操作方法:
a).新建一个文件夹,比如我给起名voc
b).将三个压缩包文件分别解压到voc文件夹里,一定要手动选择解压路径(你刚刚创建的voc文件夹)完成后如图所示,如果你是win10及其以上系统,会发现voc下自动创建了一个VOCdevkit文件夹,解压的所有文件都在路径voc/VOCdevkit中,win10以下的系统则需要手动复制粘贴一下了:

本次训练使用的数据只有如下两个标注出的文件夹,Annotationa文件和JPEGimages文件。前者包含9963个.xml文件,后者包含对应的9963个.jpg文件,前者文件里包含的是后者对应图片文件的标签信息.

将文件夹VOCdevkit压缩,复制到yolov3-master/datasets/VOC/下(datasets、VOC文件夹自己新建),然后解压完如下:

4.下载预训练模型
加载预训练权重进行训练可以减小缩短网络训练时间,并且提高精度。预训练权重越大,训练出来的精度就会越高,但是其检测的速度就会越慢.
下载方式1:
下载地址:(不知道为啥直接粘贴过来只有github.com了,所以只能截图了,而且这个网址不稳定,时而登录的上时而登录不上...)
![]()
进入页面到最底下可以选择想下载的模型文件,我下载的是yolov3-tiny.pt
下载方式2:
也可以采用download_weights.sh脚本进行自动下载,脚本路径如图,这种方式我没试过,但是据其他小伙伴说下载很慢:

将下载下来的模型,保存到如下路径,weights需要自己新建:

5.搭建运行环境
终端命令:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/用清华镜像源地址下载更快,requirements.txt位置:yolov3-master/requirements.txt
运行代码之前,确认一下是否正确安装了支持gpu运行的pytorch环境。
验证方法:只需要在pycharm项目下的Terminal中输入python,进入python环境→然后输入代码:
>>>import torch
>>>torch.cuda.is_available()
6.使用预训练模型检测图片
一切搭建好了,可以使用我们之前下载的yolov3-tiny.pt模型来进行图片检测推理,试试效果。
python detect.py --source ./data/images/bus.jpg --weights ./weights/best.pt
参数解释:--source 需要检测的图片路径 --weights 使用的检测模型的路径
7.用VOCdevkit数据集训练yolov3
a).首先查看我们之前下载的VOCdevkit数据集,之前提到我们需要的只有Annotationa文件和JPEGimages文件,前者包含9963个.xml文件,后者包含对应的9963个.jpg文件,前者文件里包含的是后者对应图片文件的标签信息.但是在实际训练过程中,由于要保证图片和标签一一对应,在训练数据之前,需要使用脚本生成txt文档。python在读取文件时,读取的顺序并不确定是否是文件夹中文件显示的顺序,所以要生成txt文档。
生成txt文档的脚本如下:
import xml.etree.ElementTree as ET
import os
from tqdm import tqdm
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(root,year, image_id):
in_file = open(os.path.join(root,'VOC%s/Annotations/%s.xml' % (year, image_id)))
out_file = open(os.path.join(root,'VOC%s/labels/%s.txt' % (year, image_id)), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
sets_2007 = [('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#sets_2012 = [('2012', 'train'), ('2012', 'val')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog",
"horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
root = r'./datasets/VOC/VOCdevkit'
output_dir = r'../datasets'
#sets_07_12 = [sets_2007,sets_2012]
sets_07_12 = [sets_2007]
for sets in sets_07_12:
for year, image_set in sets:
if not os.path.exists(os.path.join(root,'VOC%s/labels/' % year)):
os.makedirs(os.path.join(root,'VOC%s/labels/' % year))
image_ids = open(os.path.join(root,'VOC%s/ImageSets/Main/%s.txt' % (year, image_set))).read().strip().split()
list_file = open('%s/%s%s.txt' % (output_dir,image_set,year), 'a')
for image_id in tqdm(image_ids):
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n' % (root, year, image_id))
convert_annotation(root,year, image_id)
list_file.close()
如果想一起训练VOCdevkit2007和VOCdevkit2012的数据,则将43、50行代码注释打开,将42、51行代码注释即可。目前我用的是2007的数据集,所以使用的是42、51行代码。
将此脚本命名为voc2txt.py,放到路径yolov3-master文件夹下,如图:

执行 cd .. 再创建一个datasets文件夹,创建完如图:

然后进入到yolov3-master,运行脚本 python voc2txt.py
运行完之后,cd .. ,进入datasets,可以看到datasets下生成如下三个文件,(如果是同时训练2012和2007数据集,应该是5个文件):

回到yolov3-master目录下,新建如下脚本makedata.py,内容如下:

import shutil
import os
from tqdm import tqdm
file_List = ["train2007", "val2007", "test2007"]
#file_List = ["train2007", "val2007", "test2007","train2012", "val2012"]
for file in file_List:
if not os.path.exists('../datasets/VOC/images/%s' % file):
os.makedirs('../datasets/VOC/images/%s' % file)
if not os.path.exists('../datasets/VOC/labels/%s' % file):
os.makedirs('../datasets/VOC/labels/%s' % file)
f = open('../datasets/%s.txt' % file, 'r')
lines = f.readlines()
for line in tqdm(lines):
line = line.strip()
if os.path.exists(line):
shutil.copy(line, "../datasets/VOC/images/%s" % file)
line = line.replace('JPEGImages', 'labels')
line = line.replace('jpg', 'txt')
shutil.copy(line, "../datasets/VOC/labels/%s/" % file)
else:
print(line)执行脚本 python makedata.py
执行完成后,cd .. 进入datasets文件夹,会发现有一个VOC文件夹,进入VOC文件夹,如图:

进入images,和它同级的labels文件夹也有同样的三个文件夹,test 测试集,train 训练集, val 验证集:

至此,训练数据终于准备好,接下来开始训练啦。
8.训练模型
进入到如下路径,打开voc.yaml,这个文件是VOC数据集的配置文件:

将下图部分代码修改成如下的样子,(去掉训练2012数据集的相关路径信息):
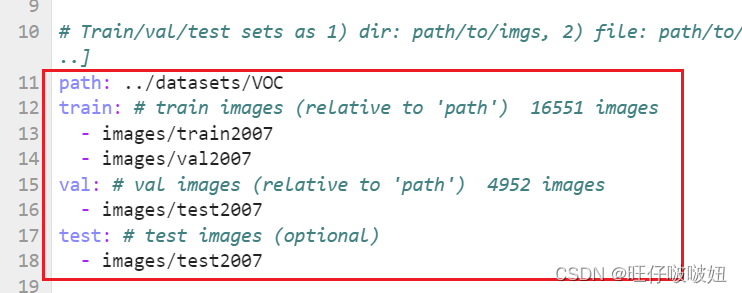
然后,回到yolov3-master目录下,运行脚本train.py
python train.py --img 640 --batch 24 --epoch 50 --data data/voc.yaml --cfg models/yolov3-tiny.yaml --weights weights/yolov3-tiny.pt
参数解释:
python train.py: 这部分命令使用Python来运行一个名为train.py的脚本。这个脚本通常包含了用于训练模型的代码。--img 640: 这是一个命令行参数,指示输入图像的尺寸应被调整为640像素。在目标检测中,通常需要将输入图像调整到固定的尺寸以便于模型处理。--batch 24: 这指定了每个批次(batch)应该包含24张图像。批次是在训练过程中一次处理的图像数量,调整批次大小可以影响训练速度和模型性能。--epoch 50: 这意味着整个数据集将被遍历50次。在机器学习中,一个epoch指的是使用整个数据集进行一次前向和一次反向传播。--data data/voc.yaml: 这告诉脚本数据集的配置信息存储在data/voc.yaml文件中。YAML文件通常用于存储配置参数,如数据集的路径、类别、标注格式等。--cfg models/yolov3-tiny.yaml: 这指定了模型的配置信息存储在models/yolov3-tiny.yaml文件中。这个配置文件可能包含了模型的结构、参数、训练策略等信息。--weights weights/yolov3-tiny.pt: 这告诉脚本预训练模型的权重存储在weights/yolov3-tiny.pt文件中。.pt是PyTorch框架用于保存模型权重的文件格式。
运行中,这样的:


训练完成,模型保存地址他会给你提示,一般是yolov3-master/runs/train,里边有每次训练的结果:

去它提示的路径下找到best.pt,这就是本次训练完成的模型,测试模型的效果,则参照本文第6章修改模型路径即可。
有任何问题留言大家一起交流哈,初学小白一枚,大家一起进步呀。
资源链接:
链接:https://pan.baidu.com/s/1UHie-7eMkbUSauEpoIySEQ
提取码:g39z















 5159
5159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









