









系列文章目录
[数据挖掘] clickhouse在go语言里的实践
[数据挖掘] 用户画像平台构建与业务实践
文章目录
前言
今天给大家介绍一款OLAP大数据处理软件 clickhouse ,在业界它有一个荣誉,那就是”快“,当然此快不是开车快的意思,是指clickhouse在大数据量级的查询方面,对比Spark 、MySQL 、Hive 、Hadoop,速度有很大的提升。
下面我们从clickhouse的起源、OLAP/OLTP、go语言开发实践、clickhouse的表存储引擎分析这几个方面,讲解clickhouse为何适合做大数据分析、数据挖掘,什么情况下用什么样的表引擎,以及clickhouse的缺陷等。
一、clickhouse的起源
ClickHouse起源于Yandex公司的Metrica产品团队。Metrica是一款Web流量分析工具,根据用户行为数据采集,进行数据OLAP分析。数据采集的Event由页面的点击(click)产生,然后进入数据仓库进行OLAP分析。ClickHouse的全称为Click Stream,Data WareHouse,简称ClickHouse。2021年9月20日,ClickHouse团队从Yandex独立,成立公司。
二、OLAP/OLTP
OLAP和OLTP是数据处理和交易过程中的两种不同类型的方法。
OLTP,也称为联机事务处理过程,主要侧重于前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果。这种处理方式是对用户操作快速响应的方式之一,其基本特征是处理少量的事务性数据。
OLAP,全称联机分析处理,使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它帮助分析人员快速获得数据,并进行分析和预测。
2.1、主流的OLAP/OLTP数据库
以下是一些主流的OLAP和OLTP数据库:
| 数据库类型 | 数据库名 | 描述 |
|---|---|---|
| OLTP数据库 | - | - |
| - | MySQL | OLTP的代表,擅长事务处理,支持数据频繁插入或修改,适用于业务开发人员。 |
| - | Oracle | 也是一个功能强大的OLTP数据库,广泛用于企业级应用。 |
| - | TiDB | 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库。是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。 |
| OLAP数据库 | - | - |
| - | Greenplum | 一个分布式数据库,擅长对大量数据进行多维复杂分析,追求极致性能,面向分析决策人员。 |
| - | Hive | Hadoop的数据仓库工具,可以处理大规模的结构化数据,提供类似于SQL的查询功能,适用于数据仓库和BI平台。 |
| - | ClickHouse | 一个开源的列式存储数据库,适合用于数据仓库和数据湖等场景,支持复杂的数据分析查询操作。 |
| - | AWS Redshift | AWS Redshift是AWS提供的一款云上数据仓库服务。只需通过简单的鼠标点击即可得到一款高性能、高可靠的数据仓库服务。它使用密集存储 (DS) 节点,能够以非常低的价格创建超大型数据仓库。在数据仓库、运营数据库和数据湖间分析结构化和半结构化数据,使用 AWS 设计的硬件和机器学习在任意规模提供最佳性价比。 |
| - | Doris | 一个实时数仓,可以解决 PB 级别的数据量(如果高于 PB 级别,不推荐使用 Doris 解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级。Doris 是由百度大数据部研发的,之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris。 |
三、go语言开发实践
这里推荐大家使用go语言的goframe框架,且已开发支持多种数据库,包括:mysql 、mariadb、tidb、pgsql、mssql、oracle、clickhose、dm、sqllite。源码开放,可以提交pr,支持扩展其他数据库组件。
亲测,轻松支持mysql、clickhose

3.1、安装配置go语言环境,配置IDE
3.1.1、Go开发环境安装
1、下载Go开发包
访问Go国内镜像站下载页面 https://golang.google.cn/dl/,并在页面最上方的版本中选择你当前的系统版本,会下载最新版本的Go开发包:

2、安装引导
访问官方安装介绍页面 https://golang.google.cn/doc/install,按照当前系统版本执行对应的安装流程即可。
Windows(msi)和MacOS(pkg)推荐使用安装包的方式来安装。作者当前MacOS安装包(pkg)安装过程如下图所示:
3.1.2、IDE开发环境安装
目前Go的IDE有两款比较流行,一款是VSCode+Plugins(免费),另一款是JetBrains公司的Goland(收费)。由于JetBrains也是GoFrame框架的赞助商,因此我们优先推荐使用Goland来作为开发IDE,下载及注册请参考网上教程(百度 或 Google)。
JetBrains的官方网站为:https://www.jetbrains.com
**备注: 熟悉Java开发工具Idea的同学可以很快上手Goland,操作上感觉都似曾相识 **
1、Goland的使用
我们来创建第一个Go程序吧,老规矩,上hello world。

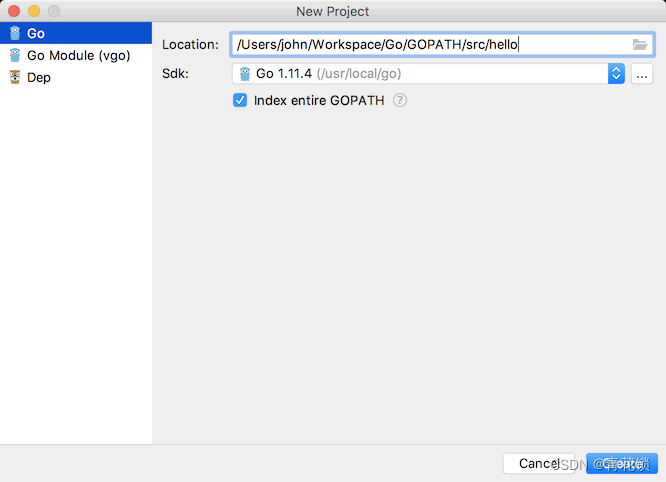
2、创建项目
这里需要注意的是Go安装文件的路径(SDK),官方安装文档有详细说明,请仔细阅读。
其中的Location随意选择一个本地路径即可。
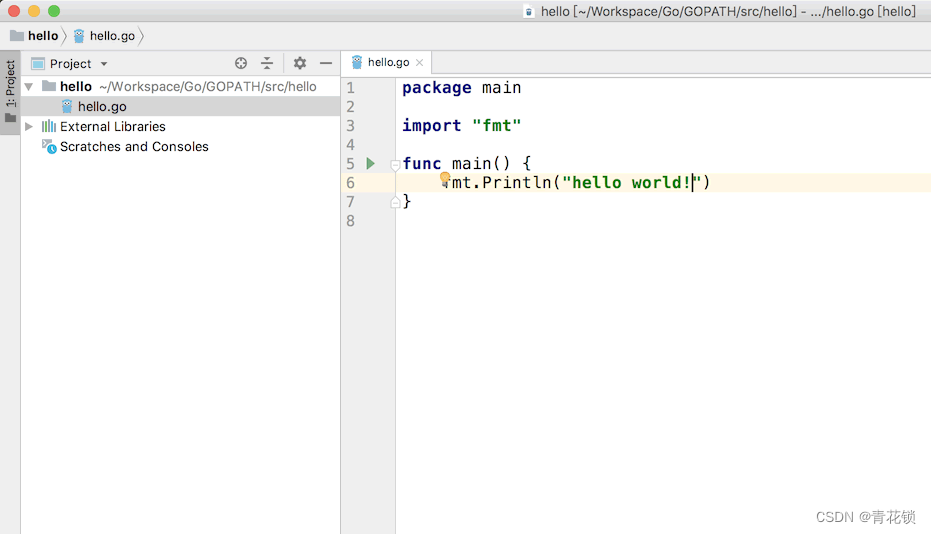
3、创建程序
新建一个go文件,叫做hello.go,并输入以下代码:
4、执行运行
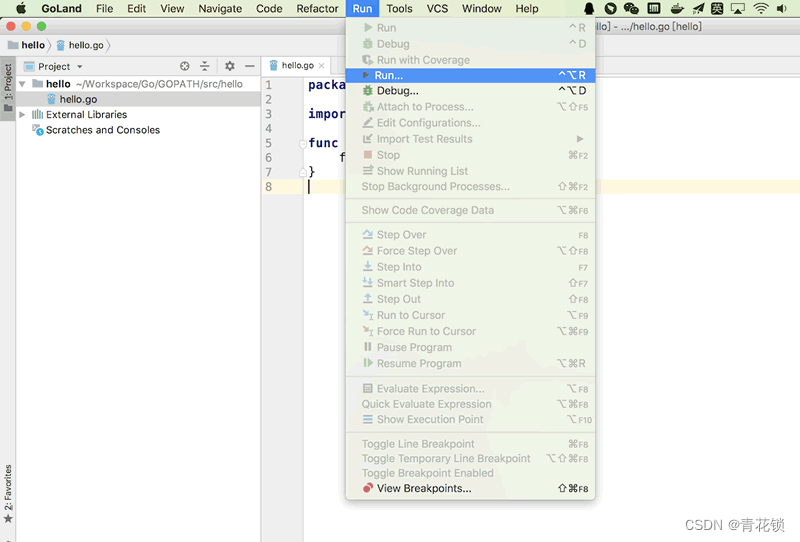
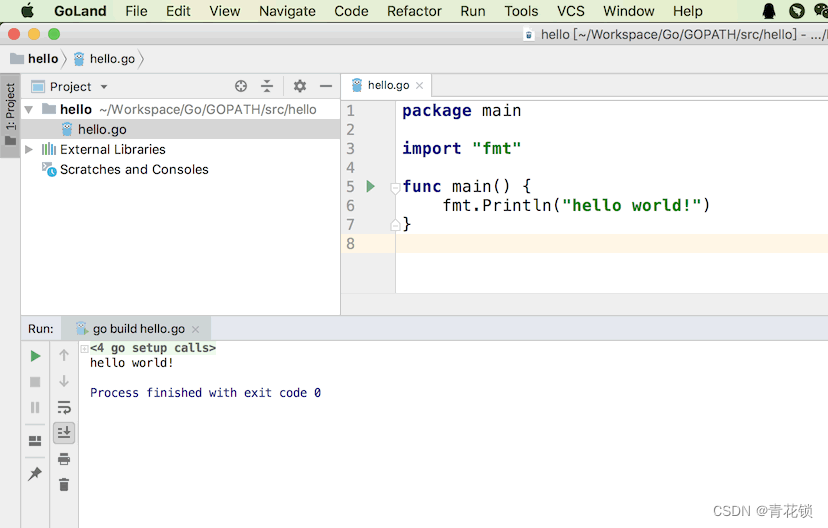
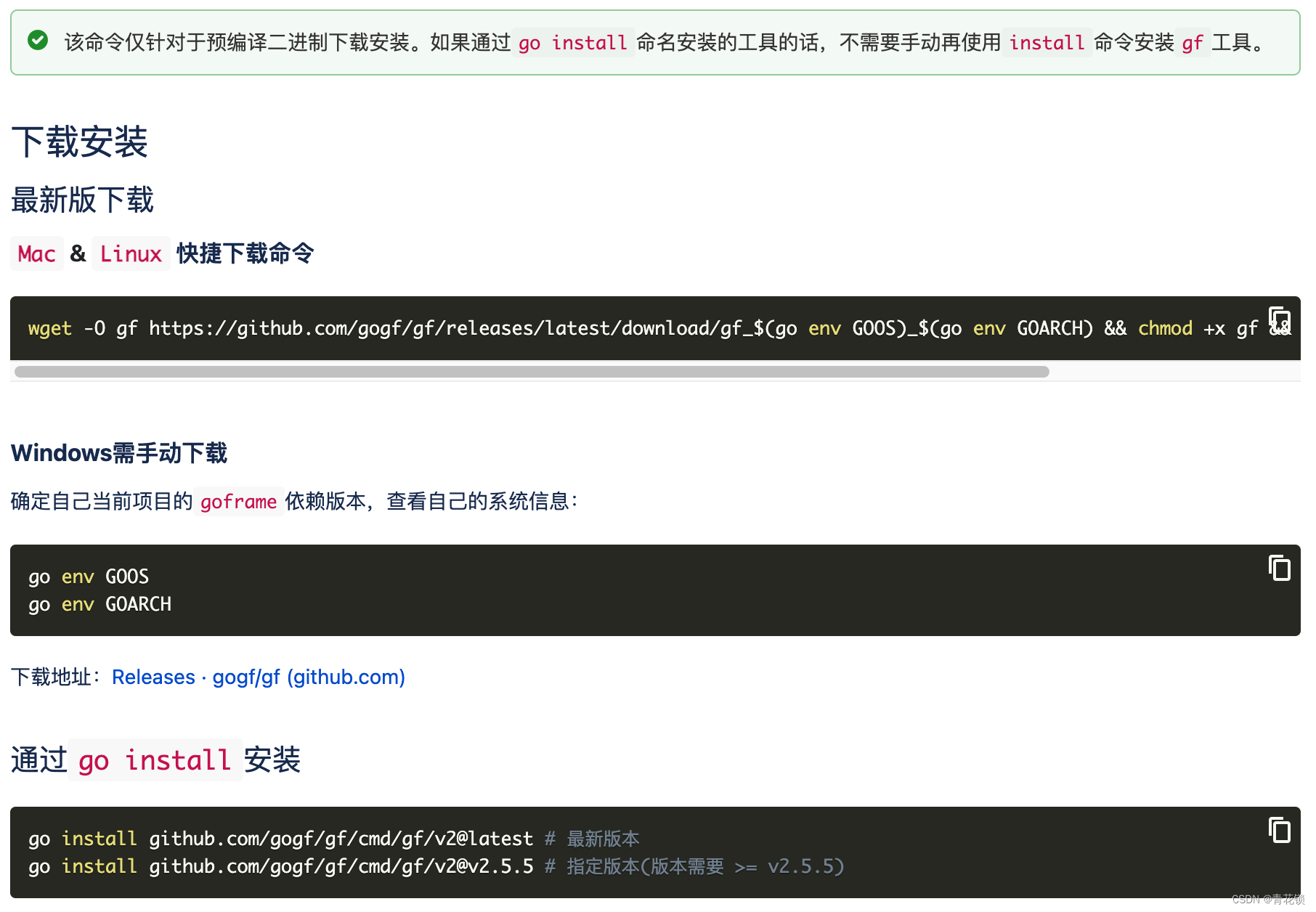
3.2、goframe工具安装
帮助文档: https://goframe.org/pages/viewpage.action?pageId=1115782
建议安装最新版本
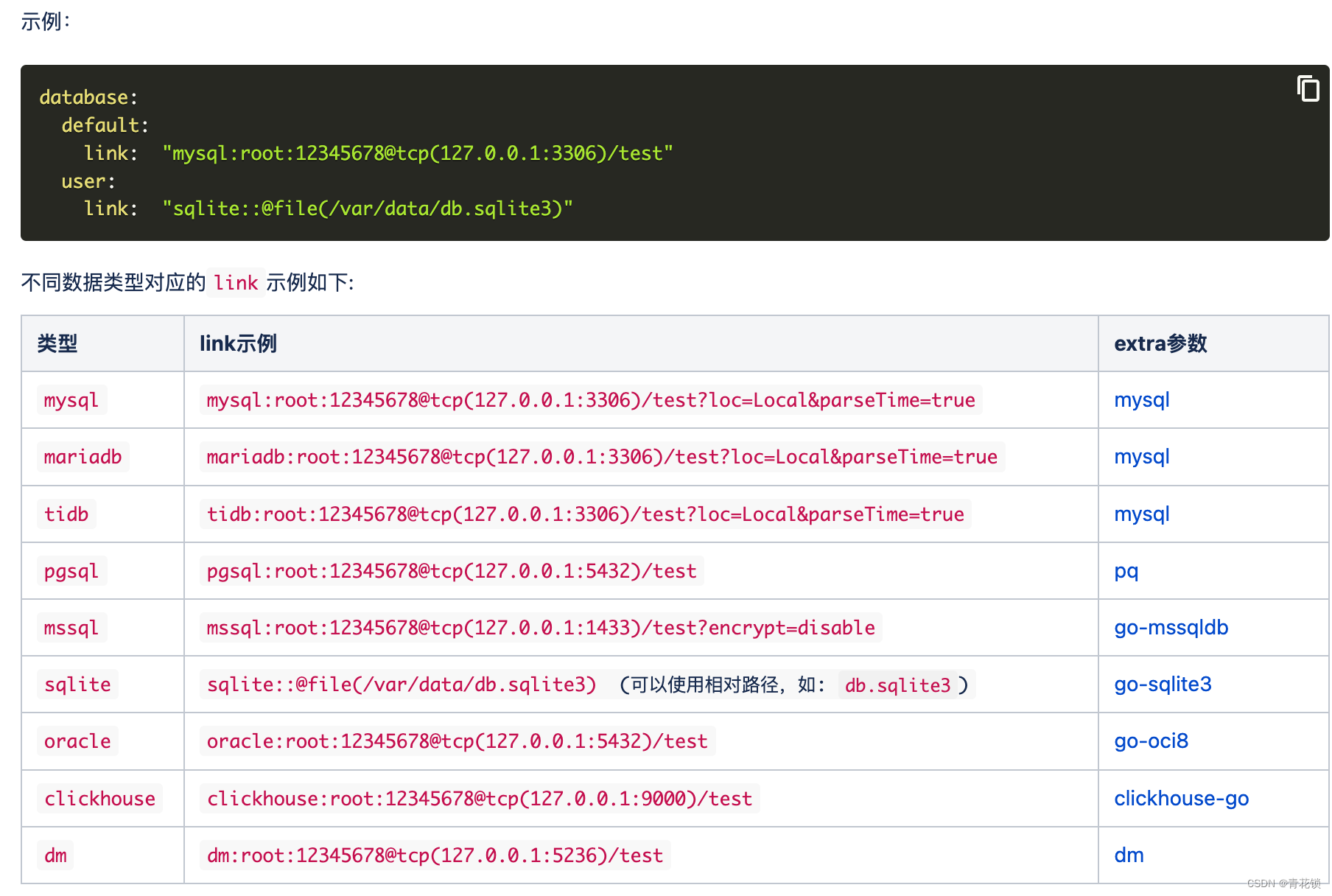
3.3、引入clickhouse组件
clickhouse帮助文档:
https://goframe.org/pages/viewpage.action?pageId=1114245#ORM%E4%BD%BF%E7%94%A8%E9%85%8D%E7%BD%AE-%E9%85%8D%E7%BD%AE%E6%96%B9%E6%B3%95
数据库配置文件:config.yaml
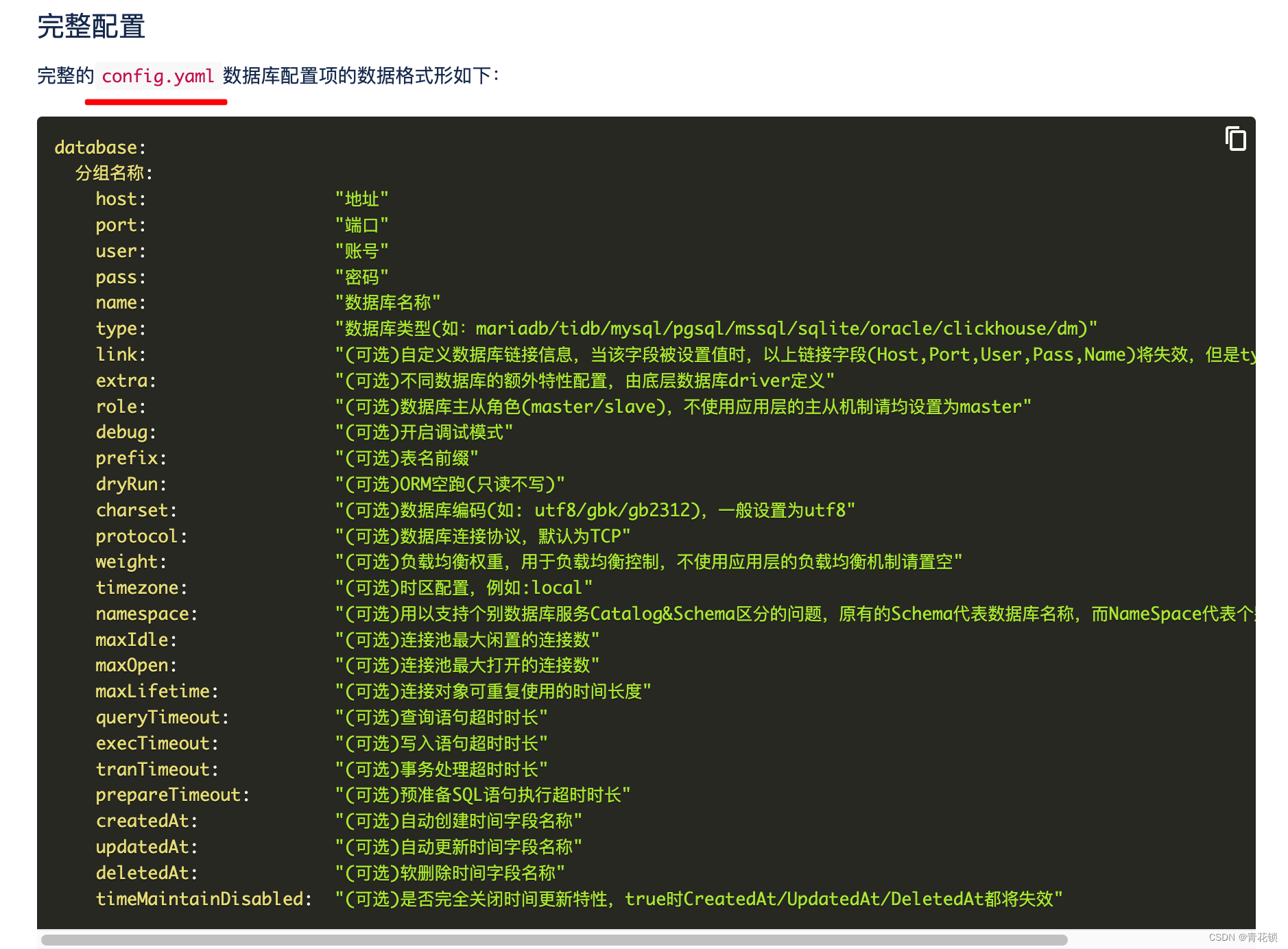
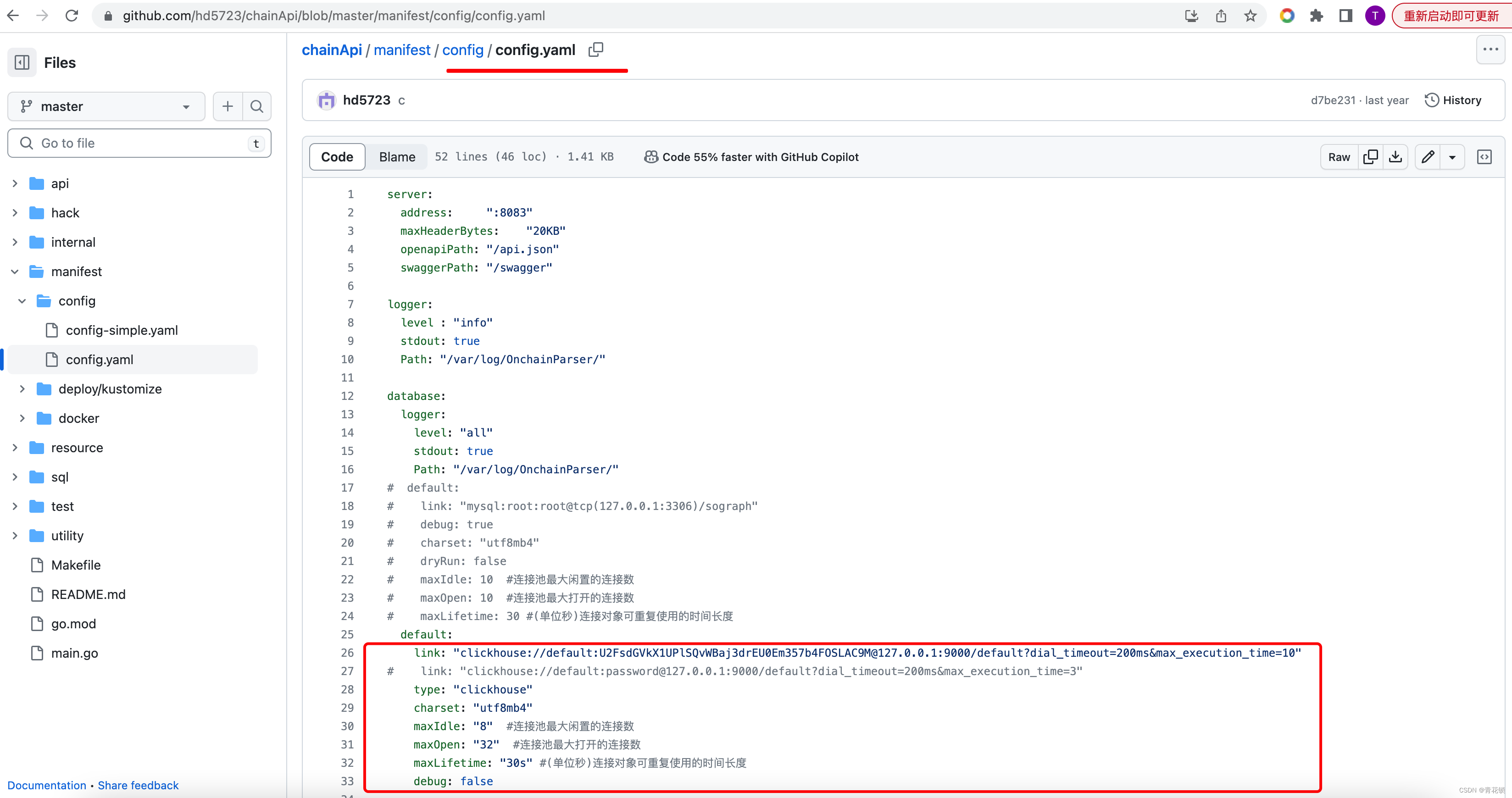
3.4、goframe使用clickhouse的完整项目
一个完整的Web3区块链项目,使用goframe + clickhouse + mysql + redis ,本人原创,完全拥有版权
地址:https://github.com/hd5723/chainApi
4、clickhouse的表引擎分析
官方文档(支持中、英、俄):https://clickhouse.com/docs/zh/engines/table-engines
简单介绍2种常用的表引擎:MergeTree、ReplacingMergeTree
4.1、MergeTree
Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
主要特点:
-
存储的数据按主键排序。
这使得您能够创建一个小型的稀疏索引来加快数据检索。 -
如果指定了 分区键 的话,可以使用分区。
-
在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
4.2、ReplacingMergeTree
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写。
因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
5、clickhouse为何适合做大数据分析、数据挖掘,什么情况下用什么样的表引擎,以及clickhouse的缺陷
5.1、clickhouse为何适合做大数据分析、数据挖掘
clickhouse 与MySQL性能对比
ClickHouse和MySQL是两种不同的数据库管理系统,它们在性能方面有一些区别。以下是ClickHouse和MySQL性能的对比:
- 数据存储结构:ClickHouse是一种列式存储数据库,适合处理大量数据,特别是在分析查询方面表现出色。而MySQL是一种行式存储数据库,以行为单位存储数据,适合事务处理和常规查询。
- 处理能力:ClickHouse在处理大规模数据集时表现出色,提供快速的聚合和分析能力。MySQL在小规模数据和事务处理方面表现较好。
- 查询语言:ClickHouse使用自己的查询语言ClickHouse SQL(类似于标准SQL),支持复杂的分析查询和聚合操作。MySQL则使用标准SQL。
- 数据一致性:MySQL是一种关系型数据库,支持事务和ACID特性,确保数据的一致性。ClickHouse主要用于分析型查询,对于数据的一致性要求较低。
- 性能和扩展性:ClickHouse在处理大规模数据和高并发查询时具有优势,可以水平扩展,并提供在分布式环境中运行的能力。MySQL在小规模应用和事务处理方面表现较好。
总的来说,MySQL适合事务处理和一般查询。ClickHouse适合处理大规模数据和分析查询,ClickHouse的适合大宽表(上百个字段、海量数据)统计分析查询。
5.2、ClickHouse查询缺陷
5.2.1、单机时的查询处理缺陷
ClickHouse在查询时,会调动尽可能多的服务器资源,一般CPU占用会高达80%以上,因此不合适高并发查询。
5.2.2、集群成本高
如果要处理高并发问题, 需要增加服务器,成本非常高
5.3.3、多表联查性能不佳
适合适合大宽表(上百个字段)查询,多表查询就算字段不多,性能也不佳
5.3.4、修改、删除支持非常差
ClickHouse支持实时统计查询,但是修改、删除性能非常差,一般使用表引擎ReplacingMergeTree来解决修改、删除问题。
对ClickHouse进行修改可能会引发以下问题:
- 数据类型不一致:如果在对表结构进行修改时,改变了字段的数据类型,而后续插入的数据类型与修改后的表结构不匹配,可能会导致数据插入失败或数据不一致。例如,如果在ClickHouse中更改了字段类型从int变为float,但是后续插入的数据仍然是int类型,那么这些数据会被截断,导致数据不一致。
- 高频删除数据:如果在短时间内删除大量数据,ClickHouse可能会出现“Cannot allocate memory”的错误。因为ClickHouse在处理删除操作时,会先在内存中构建删除树,如果删除操作过于频繁,可能会耗尽内存。
- 重复数据处理:ClickHouse对重复数据的处理可能会出现问题。如果在同一个分片上插入的数据已经存在,ClickHouse会进行去重。然而,如果在不同分片间插入重复数据,ClickHouse不保证去重。这可能会导致数据重复的问题。
因此,在对ClickHouse进行修改时,一定要小心谨慎,并做好相应的测试,以避免可能的问题。如遇到修改后无法存入数据等问题,可以检查是否是上述情况导致,并按照相应的方法解决。如果是数据源数据进行了多次调整,数据字段进行过调整,要确保调整后的数据兼容旧的数据格式。
6、架构设计
在实际的项目中,数据操作方面我们采用了Clickhouse + MySQL + Redis,分工明确。
6.1、Clickhouse
功效:实时统计查询
数据来源:设置定时任务,汇总mysql多个表几十个上百个字段,通过go程序写入Clickhouse
策略:定时增量更新、很少根据主键修改/删除
6.2、MySQL
功效:定时任务,查询多表数据
数据来源:通过ETH rpc接口获取数据,并写入
策略:频繁的写入数据,定时查询(分钟级、小时级等),少量修改/删除
6.3、Redis
用于维护版本号,缓存业务的第一页数据等
总结
OLAP/OLTP数据库发展很多年了,也有很多争论,但总体来说,符合自己业务的才是好的。不同的业务、数据体量的增长、公司技术栈的储备等,都是影响因素。















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











