






Perplexica是一款开源的AI驱动搜索引擎,在GitHub上获得了22.2K颗星的关注,成为搜索引擎技术领域最受瞩目的项目之一。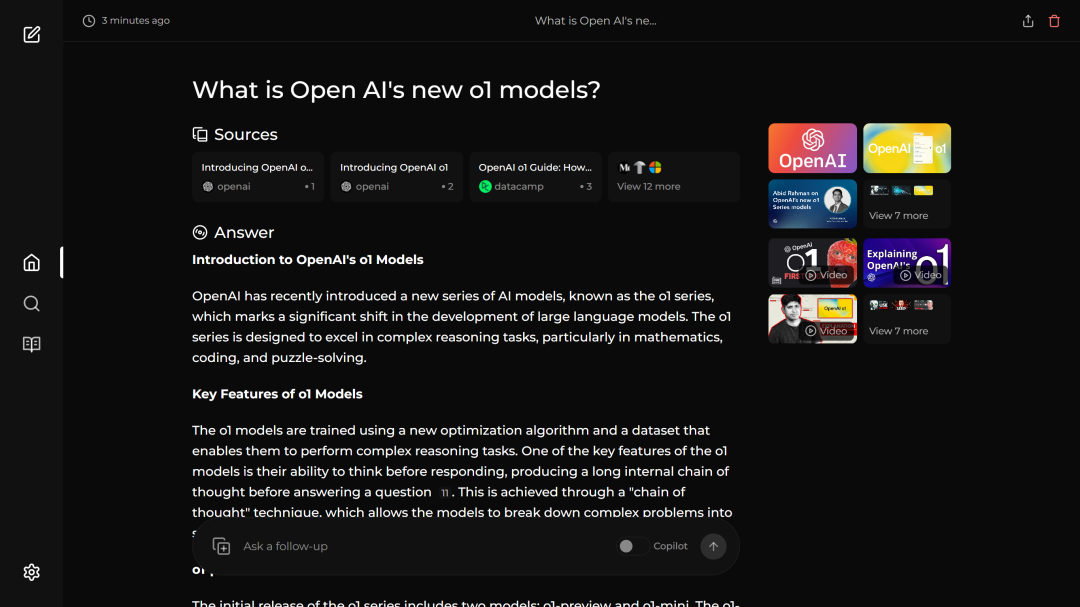
作为商业化产品Perplexity AI的开源替代方案,Perplexica不仅提供了强大的搜索功能,更重要的是保护用户隐私,并通过先进的机器学习算法提供准确、实时的搜索结果。
该项目的核心理念是让AI搜索技术变得更加开放和可控,用户可以完全掌握自己的搜索数据,同时享受到媲美商业产品的搜索体验。
技术特色
1. 智能搜索理解
Perplexica采用先进的自然语言处理技术,能够深度理解用户的搜索意图。它不仅仅是关键词匹配,而是真正理解问题的语义,提供更准确的搜索结果。
2. 实时信息获取
与传统的搜索工具不同,Perplexica使用SearxNG元搜索引擎获取最新信息,确保搜索结果的时效性。系统会实时抓取网络信息,而不是依赖预先建立的索引数据库。
3. 多种搜索模式
Perplexica提供了6种专业的聚焦搜索模式:
• 全网模式:搜索整个互联网,找到最佳结果
• 写作助手模式:专为写作任务优化,无需网络搜索
• 学术搜索模式:专门查找学术文章和论文
• YouTube搜索模式:基于搜索查询找到相关视频
• Wolfram Alpha模式:处理需要计算或数据分析的查询
• Reddit搜索模式:搜索Reddit上的讨论和观点
4. 本地LLM支持
支持使用本地大语言模型(如Llama3和Mixtral),通过Ollama集成,确保数据隐私和离线使用能力。
核心功能
1. Copilot模式(开发中)
这是Perplexica的创新功能,通过生成不同的查询语句来增强搜索效果,访问顶级匹配页面,直接从页面中寻找与用户查询相关的信息源。
2. 相似性搜索
使用高级的机器学习算法,包括相似性搜索和嵌入技术来优化结果,提供清晰的答案并引用信息源。
3. API集成
为开发者提供完整的API接口,可以将Perplexica的搜索能力集成到现有应用程序中。
4. 多媒体搜索
支持图片和视频搜索功能,提供全方位的信息检索体验。
技术架构
前端技术栈
• Next.js:现代化的React框架
• TypeScript:类型安全的JavaScript
• Tailwind CSS:实用优先的CSS框架
后端技术
• Node.js:高性能的JavaScript运行时
• SearxNG:开源元搜索引擎
• 机器学习模型:支持多种AI模型集成
数据库
• Drizzle ORM:类型安全的数据库工具
部署方案
1. Docker部署(推荐)
# 克隆项目
git clone https://github.com/ItzCrazyKns/Perplexica.git
# 配置环境
cp sample.config.toml config.toml
# 启动服务
docker compose up -d2. 原生部署
# 安装依赖
npm install
# 构建项目
npm run build
# 启动服务
npm run start3. 一键部署
支持多个云平台的一键部署:
• Sealos
• RepoCloud
• ClawCloud
应用场景
1. 个人知识管理
为研究人员和学者提供专业的信息检索工具,特别是学术搜索模式能够精准定位学术资源。
2. 企业内部搜索
企业可以部署私有的Perplexica实例,确保敏感信息的安全性。
3. 开发者工具集成
通过API接口,开发者可以将AI搜索功能集成到自己的应用中。
4. 教育机构
为教育机构提供安全、可控的搜索环境,特别适合学术研究场景。
隐私保护
1. 数据本地化
所有搜索数据和用户信息都可以保存在本地,完全掌控数据隐私。
2. 开源透明
完全开源的代码确保了系统的透明性,用户可以审查和修改源代码。
3. 无用户追踪
与商业搜索引擎不同,Perplexica不会追踪用户行为或建立用户画像。
技术优势
1. 模块化设计
采用微服务架构,各个组件可以独立部署和扩展。
2. 高性能
基于现代Web技术栈,提供快速响应的用户体验。
3. 易于扩展
插件化的架构设计,方便添加新的搜索引擎和AI模型。
4. 跨平台支持
支持Windows、macOS和Linux等多个平台。
项目地址: https://github.com/ItzCrazyKns/Perplexica

















 8028
8028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









