







RGB 解交织
考虑一个 24 位 RGB 图像,其中图像是像素数组,每个像素都有一个红色、蓝色和绿色元素。在内存中,这可能如下图所示:
 这是因为 RGB 数据是交错的,访问和操作三个独立的颜色通道给程序员带来了问题。在简单的情况下,我们可以通过将模 3 应用于交错的 RGB 值来编写自己的单色通道运算。然而,对于更复杂的操作,例如傅立叶变换,提取和分割通道会更有意义。
这是因为 RGB 数据是交错的,访问和操作三个独立的颜色通道给程序员带来了问题。在简单的情况下,我们可以通过将模 3 应用于交错的 RGB 值来编写自己的单色通道运算。然而,对于更复杂的操作,例如傅立叶变换,提取和分割通道会更有意义。
我们在内存中有一个 RGB 值数组,我们希望对它们进行解交错并将这些值放置在单独的颜色数组中。执行此操作的 C 过程可能如下所示:
 但有一个问题。使用 Arm Compiler 6 在优化级别 -O3(非常高的优化)下进行编译并检查反汇编结果表明没有使用 Neon 指令或寄存器。每个单独的 8 位值都存储在单独的 64 位通用寄存器中。考虑到全宽 Neon 寄存器为 128 位宽,在示例中每个寄存器可以保存 16 个 8 位值,重写解决方案以使用 Neon 内在函数应该会给我们带来良好的结果。
但有一个问题。使用 Arm Compiler 6 在优化级别 -O3(非常高的优化)下进行编译并检查反汇编结果表明没有使用 Neon 指令或寄存器。每个单独的 8 位值都存储在单独的 64 位通用寄存器中。考虑到全宽 Neon 寄存器为 128 位宽,在示例中每个寄存器可以保存 16 个 8 位值,重写解决方案以使用 Neon 内在函数应该会给我们带来良好的结果。
改写后:
void rgb_deinterleave_neon(uint8_t *r, uint8_t *g, uint8_t *b, uint8_t *rgb, int
len_color) {
/*
* Take the elements of "rgb" and store the individual colors "r", "g", and "b"
*/
int num8x16 = len_color / 16;
uint8x16x3_t intlv_rgb;
for (int i=0; i < num8x16; i++) {
intlv_rgb = vld3q_u8(rgb+3*16*i); //从内存中加载数据到寄存器,
vst1q_u8(r+16*i, intlv_rgb.val[0]);
vst1q_u8(g+16*i, intlv_rgb.val[1]);
vst1q_u8(b+16*i, intlv_rgb.val[2]);
}
}
vld3q_u8:将多个三元素结构加载到三个寄存器。该指令从内存中加载多个3元素结构,并将结果写入到三个 SIMD & FP 寄存器中,同时取消交织
vst1q_u8:从一个、两个、三个或四个寄存器中存储多个单元结构。此指令存储来自一个、两个、三个或四个 SIMD & FP 寄存器的元素到内存,而不交错。存储每个寄存器的每个元素。
在此示例中,我们使用了以下类型和内在函数:
 可以使用以下命令在 Arm 机器上编译和反汇编上面的完整源代码:
可以使用以下命令在 Arm 机器上编译和反汇编上面的完整源代码:
gcc -g -o3 rgb.c -o exe_rgb_o3
objdump -d exe_rgb_o3 > disasm_rgb_o3
分析总结
(1)使用NEON interinsics 加速,实质上就是使用NEON interinsics封装的函数替代原先c中的函数,需要添加头文件,"arm_neon.h"但要注意以下几点:
(NEON interinsics封装的函数可以在这个链接里查询:https://developer.arm.com/architectures/instruction-sets/intrinsics/)
1、NEON interinsics的逻辑与c语言的逻辑不同,更接近于汇编语言的逻辑。
具体来讲:
1)c语言的逻辑:
不同通道中的数据依次保存在rgb数组中的不同位置,读写时只需要依次读取。
2)NEON interinsics的逻辑:
*** 从内存中加载数据到寄存器中(因为NEON中对数据的处理都在寄存器中处理,同时应尽可能避免访问内存,访问内存是最耗费时间的操作)
***将寄存器中的数据保存到内存中
2、使用NEON interinsics时要注意位数,
int num8x16 = len_color / 16;
这是由于 rgb数组中保存的是8位值,Neon 寄存器为 128位,可以保存16个8位值,因此理论上,一次读取8*16位,相应的循环次数也减少为len_color / 16。
矩阵乘法
矩阵乘法是许多数据密集型应用程序中执行的运算。它由一组以简单方式重复的算术运算组成,如下图所示:
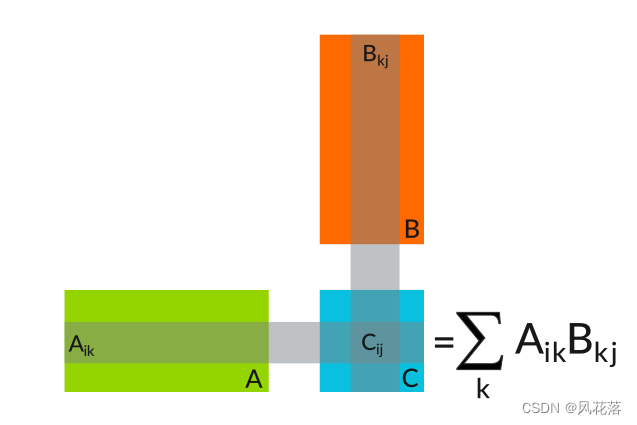
矩阵乘法过程如下:
• A - 在第一个矩阵中取一行
• B - 执行该行与第二个矩阵中的列的点积
• C - 将结果存储在新矩阵的相应行和列中矩阵
对于 32 位浮点矩阵,乘法可以写为:
C语言:
void matrix_multiply_c(float32_t *A, float32_t *B, float32_t *C, uint32_t n,
uint32_t m, uint32_t k) {
for (int i_idx=0; i_idx < n; i_idx++) {
for (int j_idx=0; j_idx < m; j_idx++) {
C[n*j_idx + i_idx] = 0;
for (int k_idx=0; k_idx < k; k_idx++) {
C[n*j_idx + i_idx] += A[n*k_idx + i_idx]*B[k*j_idx + k_idx];
}
}
}
}
我们假设内存中矩阵的列优先布局。也就是说,n x m 矩阵 M 表示为数组 M_array,其中 Mij = M_array[n*j + i]。
该代码不是最理想的,因为它没有充分利用 Neon。我们可以开始通过使用内在函数来改进它,但是让我们首先通过查看小型固定大小的矩阵来解决一个更简单的问题,然后再转向更大的矩阵。
以下代码使用内部函数将两个 4x4 矩阵相乘。由于我们要处理的值数量较少且固定,所有这些值都可以立即放入处理器的 Neon 寄存器中,因此我们可以完全展开循环.
4*4 NEON intrinsics:
void matrix_multiply_4x4_neon(float32_t *A, float32_t *B, float32_t *C) {
// these are the columns A
float32x4_t A0;
float32x4_t A1;
float32x4_t A2;
float32x4_t A3;
// these are the columns B
float32x4_t B0;
float32x4_t B1;
float32x4_t B2;
float32x4_t B3;
// these are the columns C
float32x4_t C0;
float32x4_t C1;
float32x4_t C2;
float32x4_t C3;
A0 = vld1q_f32(A);
A1 = vld1q_f32(A+4);
A2 = vld1q_f32(A+8);
A3 = vld1q_f32(A+12);
// Zero accumulators for C values
C0 = vmovq_n_f32(0);
C1 = vmovq_n_f32(0);
C2 = vmovq_n_f32(0);
C3 = vmovq_n_f32(0);
// Multiply accumulate in 4x1 blocks, i.e. each column in C
B0 = vld1q_f32(B);
C0 = vfmaq_laneq_f32(C0, A0, B0, 0);
C0 = vfmaq_laneq_f32(C0, A1, B0, 1);
C0 = vfmaq_laneq_f32(C0, A2, B0, 2);
C0 = vfmaq_laneq_f32(C0, A3, B0, 3);
vst1q_f32(C, C0);
B1 = vld1q_f32(B+4);
C1 = vfmaq_laneq_f32(C1, A0, B1, 0);
C1 = vfmaq_laneq_f32(C1, A1, B1, 1);
C1 = vfmaq_laneq_f32(C1, A2, B1, 2);
C1 = vfmaq_laneq_f32(C1, A3, B1, 3);
vst1q_f32(C+4, C1);
B2 = vld1q_f32(B+8);
C2 = vfmaq_laneq_f32(C2, A0, B2, 0);
C2 = vfmaq_laneq_f32(C2, A1, B2, 1);
C2 = vfmaq_laneq_f32(C2, A2, B2, 2);
C2 = vfmaq_laneq_f32(C2, A3, B2, 3);
vst1q_f32(C+8, C2);
B3 = vld1q_f32(B+12);
C3 = vfmaq_laneq_f32(C3, A0, B3, 0);
C3 = vfmaq_laneq_f32(C3, A1, B3, 1);
C3 = vfmaq_laneq_f32(C3, A2, B3, 2);
C3 = vfmaq_laneq_f32(C3, A3, B3, 3);
vst1q_f32(C+12, C3);
}
我们选择乘以固定大小的 4x4 矩阵有以下几个原因: • 某些应用程序特别需要 4x4 矩阵,例如图形或相对论物理。
• Neon 向量寄存器保存四个32 位值,因此将程序与架构相匹配可以更轻松地进行优化。
• 我们可以采用这个 4x4 内核并在更通用的内核中使用它。
让我们总结一下这里使用的内在函数:
 现在我们可以乘以 4x4 矩阵,我们可以通过将更大的矩阵视为 4x4 矩阵块来乘以它们。这种方法的一个缺陷是它只适用于两个维度都是四的倍数的矩阵大小,但是通过用零填充任何矩阵,您可以使用此方法而无需更改它。
现在我们可以乘以 4x4 矩阵,我们可以通过将更大的矩阵视为 4x4 矩阵块来乘以它们。这种方法的一个缺陷是它只适用于两个维度都是四的倍数的矩阵大小,但是通过用零填充任何矩阵,您可以使用此方法而无需更改它。
下面列出了更通用的矩阵乘法的代码。内核的结构变化很小,主要变化是增加了循环和地址计算。
与在 4x4 内核中一样,我们对 B 的列使用了唯一的变量名称,即使我们可以使用一个变量并重新加载。这充当编译器为这些变量分配不同寄存器的提示,这使得处理器能够完成一列的算术指令,同时等待另一列的加载。
void matrix_multiply_neon(float32_t *A, float32_t *B, float32_t *C, uint32_t n,
uint32_t m, uint32_t k) {
/*
* Multiply matrices A and B, store the result in C.
* It is the user's responsibility to make sure the matrices are compatible.
*/
int A_idx;
int B_idx;
int C_idx;
// these are the columns of a 4x4 sub matrix of A
float32x4_t A0;
float32x4_t A1;
float32x4_t A2;
float32x4_t A3;
// these are the columns of a 4x4 sub matrix of B
float32x4_t B0;
float32x4_t B1;
float32x4_t B2;
float32x4_t B3;
// these are the columns of a 4x4 sub matrix of C
float32x4_t C0;
float32x4_t C1;
float32x4_t C2;
float32x4_t C3;
for (int i_idx=0; i_idx<n; i_idx+=4 {
for (int j_idx=0; j_idx<m; j_idx+=4){
// zero accumulators before matrix op
c0=vmovq_n_f32(0);
c1=vmovq_n_f32(0);
c2=vmovq_n_f32(0);
c3=vmovq_n_f32(0);
for (int k_idx=0; k_idx<k; k_idx+=4){
// compute base index to 4x4 block
a_idx = i_idx + n*k_idx;
b_idx = k*j_idx k_idx;
// load most current a values in row A0=vld1q_f32(A+A_idx);
A1=vld1q_f32(A+A_idx+n);
A2=vld1q_f32(A+A_idx+2*n);
A3=vld1q_f32(A+A_idx+3*n);
// multiply accumulate 4x1 blocks, i.e. each column C
B0=vld1q_f32(B+B_idx);
C0=vfmaq_laneq_f32(C0,A0,B0,0);
C0=vfmaq_laneq_f32(C0,A1,B0,1);
C0=vfmaq_laneq_f32(C0,A2,B0,2);
C0=vfmaq_laneq_f32(C0,A3,B0,3);
B1=v1d1q_f32(B+B_idx+k);
C1=vfmaq_laneq_f32(C1,A0,B1,0);
C1=vfmaq_laneq_f32(C1,A1,B1,1);
C1=vfmaq_laneq_f32(C1,A2,B1,2);
C1=vfmaq_laneq_f32(C1,A3,B1,3);
B2=vld1q_f32(B+B_idx+2*k);
C2=vfmaq_laneq_f32(C2,A0,B2,0);
C2=vfmaq_laneq_f32(C2,A1,B2,1);
C2=vfmaq_laneq_f32(C2,A2,B2,2);
C2=vfmaq_laneq_f32(C2,A3,B3,3);
B3=vld1q_f32(B+B_idx+3*k);
C3=vfmaq_laneq_f32(C3,A0,B3,0);
C3=vfmaq_laneq_f32(C3,A1,B3,1);
C3=vfmaq_laneq_f32(C3,A2,B3,2);
C3=vfmaq_laneq_f32(C3,A3,B3,3);
}
//Compute base index for stores
C_idx = n*j_idx + i_idx;
vstlq_f32(C+C_idx, C0);
vstlq_f32(C+C_idx+n,Cl);
vstlq_f32(C+C_idx+2*n,C2);
vstlq_f32(C+C_idx+3*n,C3);
}
}
}
编译和反汇编该函数,并将其与我们的 C 函数进行比较,结果显示:
• 给定矩阵乘法的算术指令更少,因为我们利用具有完整寄存器封装的高级SIMD 技术。纯C 代码通常不会这样做。
• FMLA 代替FMUL 指令。由内在函数指定。
• 更少的循环迭代。如果使用得当,内部函数可以轻松展开循环。
• 然而,由于内存分配和数据类型(例如float32x4_t)的初始化,存在不必要的加载和存储,而纯C 代码中未使用这些数据类型。
碰撞检测
此示例展示了如何使用 Neon 内在函数来矢量化简单的碰撞检测算法。
碰撞检测算法使游戏软件能够识别物体何时接触或碰撞。
简单的碰撞检测算法为了判断两个物体是否发生碰撞,我们可以将它们的形状简化为圆形。
如果我们首先考虑沿单个轴的碰撞检测,我们可以看到当这些圆重叠时会发生碰撞。下图显示了这一点:
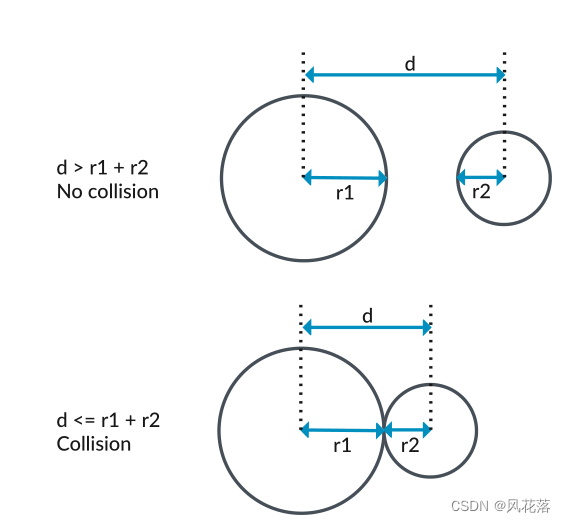 当一个圆的半径为r1,另一个圆的半径为r2 时:
当一个圆的半径为r1,另一个圆的半径为r2 时:
• 当圆心之间的距离d 大于r1 和r2 之和时,圆发生碰撞。
• 当圆心之间的距离d 小于或等于r1 和r2 之和时,圆不会发生碰撞。
在二维中,每个对象都有一对指定圆心的 (x,y) 坐标。
考虑分别位于 (c1x,c1y) 和 (c2x,c2y) 位置的相同两个圆 c1 和 c2,如下图所示:
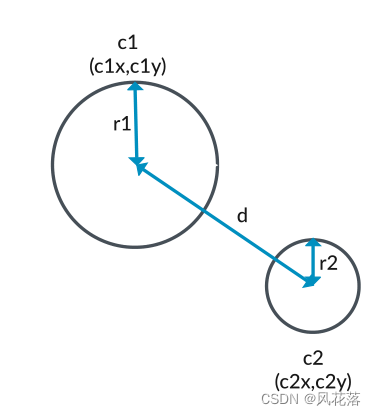 二维中的碰撞检测与单轴上的碰撞检测相同:
二维中的碰撞检测与单轴上的碰撞检测相同:
• 当圆中心之间的距离 d 大于 r1 和 r2 之和时,圆发生碰撞。
• 当圆心之间的距离d 小于或等于r1 和r2 之和时,圆不会发生碰撞。
要计算圆心之间的距离,请想象一个叠加在圆位置上的直角三角形,如下图所示:
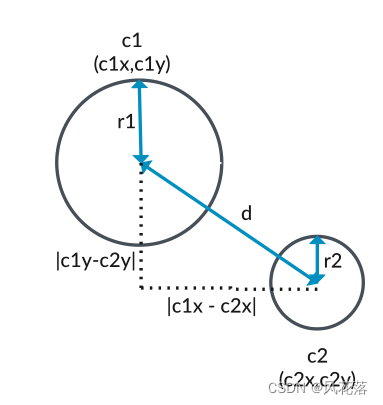 • 三角形的高度是圆的y 坐标之间的绝对差,| c1y - c2y| • 三角形的底边是圆的x 坐标之间的绝对差|c1x - c2x| • 三角形的斜边d 是圆C1 和C2 圆心之间的距离。
• 三角形的高度是圆的y 坐标之间的绝对差,| c1y - c2y| • 三角形的底边是圆的x 坐标之间的绝对差|c1x - c2x| • 三角形的斜边d 是圆C1 和C2 圆心之间的距离。
为了计算斜边 d,我们使用毕达哥拉斯定理。这表明斜边上的平方等于其他两侧的平方和:
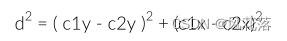 通过计算 d2 而不是 d,我们可以省去计算平方根的麻烦,这可能是一个相对昂贵的操作。对于我们的碰撞检测算法,d2 与 d 一样有效:如果 d 小于半径之和,则 d2 也小于它们的平方和。使用平方值还意味着我们不需要计算 x 和 y 差值的绝对值,因为平方值始终为正。
通过计算 d2 而不是 d,我们可以省去计算平方根的麻烦,这可能是一个相对昂贵的操作。对于我们的碰撞检测算法,d2 与 d 一样有效:如果 d 小于半径之和,则 d2 也小于它们的平方和。使用平方值还意味着我们不需要计算 x 和 y 差值的绝对值,因为平方值始终为正。
没有矢量化的算法实现碰撞检测算法获取两个圆的中心点并检查中心点之间的距离。如果这个距离小于它们的半径之和,则两个圆发生碰撞。
以下示例显示了没有矢量化的代码:
#include <stdio.h>
struct circle
{
float radius;
float x;
float y;
};
bool does_collide(circle& c1, circle& c2)
{
// Two circles collide if the distance from c1 to c2 is less
// than the sum of their radii, or equivalently if the squared
// distance is less than the square of the sum of the radii.
float delta_x = c1.x - c2.x;
float delta_y = c1.y - c2.y;
float deltas_squared = (delta_x * delta_x) + (delta_y * delta_y);
float radius_sum_squared = (c1.radius * c1.radius) + (c2.radius * c2.radius);
return deltas_squared <= radius_sum_squared;
}
int main()
{
circle c1;
c1.radius = 2.0;
c1.x = 2.0;
c1.y = 4.0;
circle c2;
c2.radius = 1.0;
c2.x = 6.0;
c2.y = 1.0;
if (does_collide(c1, c2)) {
printf("Circles collide\n");
} else {
printf("Circles do not collide\n");
}
return (0);
}
此代码创建两个圆,如下所示:
• c1,在坐标 (2,4) 处半径为 2
• c2,在坐标 (6,1) 处半径为 1 x 坐标之间的差为 4 (6-2),并且y 坐标之间的差为 3 (4-1)。
这意味着圆心之间的距离为 5 (32 + 42 = 52)。
下图显示了此计算:
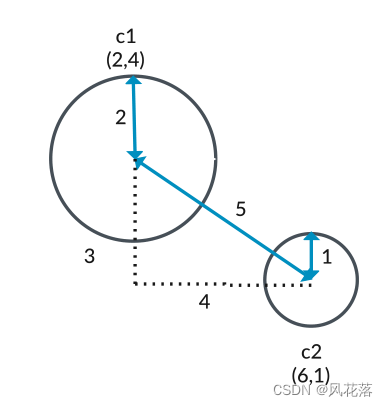 这些圆不会碰撞,因为圆之间的距离 (5) 大于半径之和 (3)。
这些圆不会碰撞,因为圆之间的距离 (5) 大于半径之和 (3)。
编译不进行向量化的 C 代码会生成以下汇编代码:
ldr s0, [x0] // Load c1.x (first data at c1 base address)
ldr s1, [x1] // Load c2.x (first data at c2 base address)
fsub s0, s0, s1 // Calculate (c1.x - c2.x)
ldr s2, [x0, 4] // Load c1.y (offset 4 from c1 base address)
ldr s1, [x1, 4] // Load c2.y (offset 4 from c2 base address)
fsub s2, s2, s1 // Calculate (c1.y - c2.y)
ldr s1, [x0, 8] // Load c1.radius (offset 8 from c1 base address)
ldr s3, [x1, 8] // Load c2.radius (offset 8 from c2 base address)
fmul s0, s0, s0 // Calculate (c1.x - c2.x)2
fmul s2, s2, s2 // Calculate (c1.y - c2.y)2
fadd s0, s0, s2 // Calculate ((c1.x - c2.x)2 + (c1.y - c2.y)2 )
fmul s1, s1, s1 // Calculate c1.radius2
fmul s3, s3, s3 // Calculate c2.radius2
fadd s1, s1, s3 // Calculate (c1.radius2 + c2.radius2)
fcmpe s0, s1 // Test ((c1.x - c2.x)2 + (c1.y - c2.y)2 ) against
// (c1.radius2 + c2.radius2)
cset w0, mi // If the result is negative (mi),
// set the result (w0) to 1
ret
使用 Neon 内在函数的基本矢量化 Neon 指令同时对多个数据值执行相同的计算。
我们的碰撞检测算法包含多个实例,其中对不同的数据值执行相同的数学运算。这些操作是使用 Neon 内在函数进行优化的候选操作:
• 减法:
◦ 我们从 c1.x 中减去 c2.x 以计算 x 坐标的差值。
◦ 我们从 c1.x 中减去 c2.y 以计算 y 坐标的差值。
• 乘法:
◦ 我们将c1.radius 与其本身相乘来计算平方。
◦ 我们将 c2.radius 乘以它本身来计算平方。
以下代码使用 Neon 内在函数来优化碰撞检测算法:
#include <arm_neon.h>
#include <stdio.h>
struct circle
{
float x;
float y; float radius;
} __attribute__((aligned (64)));
bool does_collide_neon(circle const& c1, circle const& c2)
{
float32x2_t c1_coords = vld1_f32(&c1.x);
float32x2_t c2_coords = vld1_f32(&c2.x);
float32x2_t deltas = vsub_f32(c1_coords, c2_coords);
float32x2_t deltas_squared = vmul_f32(deltas, deltas);
float sum_deltas_squared = vpadds_f32(deltas_squared);
float radius_sum = c1.radius + c2.radius;
float radius_sum_squared = radius_sum * radius_sum;
return sum_deltas_squared <= radius_sum_squared;
}
int main()
{
circle c1;
c1.radius = 2.0;
c1.x = 2.0;
c1.y = 4.0;
circle c2;
c2.radius = 1.0;
c2.x = 6.0; c2.y = 1.0;
if (does_collide_neon(c1, c2)) {
printf("Circles collide\n");
} else {
printf("Circles do not collide\n");
}
return (0);
}














 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









