







前言
关于全局标定的介绍以及这篇文章中的用到的部分代码的完整代码可以参考我上一篇文章,这里贴下链接:
https://blog.csdn.net/s_trive_/article/details/131548298?spm=1001.2014.3001.5502
这篇文章主要是为了测试一下三种寻址方式的快慢,以及完整的全局标定代码,另外,为了方便后续的多线程加速,会把相关的代码都放在一个函数,。
完成目标
(1)测试三种寻址方式的快慢
(2)完成完整的全局标定,并且结果无误。
三种寻址方式
三种寻址方式主要包括:
举例:假如我有一个4*4的矩阵,矩阵中的元素为1-64,一次读取四个元素
第一种寻址:1,2,3,4
第二种寻址:1,5,9,13
第三种寻址:1,2,5,6
前期准备
如果只是单纯的读取数据的话,个人觉得三种方式没有太大区别,个人认为主要的区别应该在于读取之后,后续的处理。例如:
在对图像去噪时,往往会用到33邻域,如果我要将图像中的每个像素值替换为该像素的33邻域像素值之和的均值。
考虑到寄存器是128位,数据是32位,即一次只能读取4个数据。
这块遇到了一点问题,意见不统一,我觉得应该采用以空间换时间的思路,例如:
我要对一个640480的矩阵中的每个元素的邻域进行加权求和的操作,那么我是不是可以将这个矩阵改写成一个3072008的一个矩阵,改写后矩阵的每一行就是原像矩阵中每一个像素的8个邻域像素。
个人觉得应该去改变数据结构去适应加速算法。
另外,因为项目进度的原因,目前项目的操作动都是只针对单个像素操作,不涉及邻域信息。这块只能暂时先搁置,后面有时间再来做验证,如果有大佬知道这块的机理,还望不吝赐教。
全局标定
上篇文章说过,全局标定其实就是给每个像素减去一个偏差值,这篇文章主要讲述,怎么计算偏差值,以及将计算偏差值与全局标定放在一个函数里。
数学原理
偏差值的计算公式其实就是,通过相位计算距离公式。
先贴下,相位计算距离的公式:其中,d是距离,f是频率,c是光速,ψ是相位偏移。
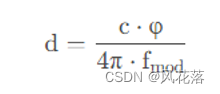
但在实际应用中,这个公式会有一点变形,这里先贴下,c的代码:
double phase2distance(double phase, int modulation_frequency)
{
double unambiguous_range = 0.5 * 299792458 / (modulation_frequency * 1000);
double coef_rad = unambiguous_range / (2 * M_PI);
double distance = (phase + M_PI) * coef_rad;
return distance;
}
这里加pi的原因为,原来相位的范围是-pi-pi,加pi使其相位范围变到0-2pi,因为距离值不能为负。
汇编逻辑
定义变量(相位,频率)–加载数据–加减乘除的逻辑
注意:neon对pi的定义:
这块我没有找到相关的概念,我这里采用的是和c++中一样,定义一个常量。
还有就是再编写neon代码前,要对计算做尽可能的优化,以减少计算步骤,还有尽可能的减少除法和减法的步骤。
neon代码
我这里将上述的步骤改写为:
d=(ψ/f)*(c/4pi)
主要是因为ψ和f是传入的参数,其余的都是固定值可以私下计算后将结果作为值传入,这样就只需要进行一次除法和一次乘法。
其实这块只需要计算一次,根本用不上neon加速。但出于学习的目的,还是写一下。
直接贴代码:
void distance_offset_correction_neon(float *mat, float *result, int n, float phase, int32_t *modulation_frequency)
{
/// 计算偏差
///**********************************************************************
//*号内代码,完全没必要采用neon实现,因为只是单个值的计算,不涉及到向量,这里仅作学习用,扩展成向量后,计算
// 定义变量,,,,neon的变量前缀统一为_,其余部分和c相同。
float32x4_t _c = vdupq_n_f32(299792458.0);
float32x4_t _neon_pi = vdupq_n_f32(3.14159265358979323846);
float32x4_t _four = vdupq_n_f32(4.f);
float32x4_t _thousand = vdupq_n_f32(1000.0);
float32x4_t _phase = vdupq_n_f32(phase);
// neon中,将int32转换为float
int32x4_t _modulation_frequency_int = vld1q_s32(modulation_frequency);
float32x4_t _modulation_frequency_float = vcvtq_f32_s32(_modulation_frequency_int);
// 如果是int16位,则需要先将int16扩展位int32位 int32x4_t vec1 = vmovl_s16(vget_low_s16(loaded)); int32x4_t vec2 = vmovl_s16(vget_high_s16(loaded));
float32x4_t _coef_rad = vmulq_f32(_four, _neon_pi);
_coef_rad = vmulq_f32(_coef_rad, _thousand);
_coef_rad = vdivq_f32(_c, _coef_rad); // vdivq_f32(a,b)=a/b
_phase = vaddq_f32(_phase, _neon_pi);
float32x4_t _distance = vdivq_f32(_phase, _modulation_frequency_float);
_distance = vmulq_f32(_distance, _coef_rad);
//std::cout << "--neon---------_distance-----------=" << _distance[0] << std::endl;
///***********************************************************************
全局标定
for (int i = 0; i < n; i += 4)
{
float32x4_t mat_vec = vld1q_f32(mat + i);
float32x4_t result_vec = vsubq_f32(mat_vec, _distance);
vst1q_f32(result + i, result_vec);
//std::cout << "---------------result= " << std::endl<< " " << *(result+i) << std::endl;
}
}
已测试,与c++的结果一致。
下面贴下完整代码,随着代码量的逐渐增加,为了方便后续的管理,以后就要写结构了。
总体的工作量比较简单,目前代码结构总体上就两个部分,一个是主函数,一个是算法库。
算法库部分“
algorithm_neon.h
#include <arm_neon.h>
#include "opencv2/opencv.hpp"
#include <stdio.h>
namespace tof_neon
{
void distance_offset_correction_c(cv::Mat m1, float scalar, cv::Mat result, float phase, int modulation_frequency);
void distance_offset_correction_neon(float *mat, float *result, int n, float phase, int32_t *modulation_frequency);
}
algorithm_neon.cpp
#include <arm_neon.h>
#include <algorithm_neon.h>
float c = 299792458.0;
float neon_pi = 3.14159265358979323846;
namespace tof_neon
{
void distance_offset_correction_c(cv::Mat m1, float scalar, cv::Mat result, float phase, int modulation_frequency)
{
// 计算偏差值
double unambiguous_range = 0.5 * 299792458 / (modulation_frequency * 1000);
double coef_rad = unambiguous_range / (2 * M_PI);
double distance = (phase + M_PI) * coef_rad;
//std::cout << "--neon---------_distance-----------=" << distance << std::endl;
// 全局标定
for (int i = 0; i < m1.rows; i++) // 矩阵行数循环
{
for (int j = 0; j < m1.cols; j++) // 矩阵列数循环
{
result.at<float>(i, j) = m1.at<float>(i, j) - distance;
}
}
// for (int i = 0; i < 20; i += 4)
// {
// std::cout << "---------------result= " << std::endl<< " " << result.at<float>(0, i)<< std::endl;
// }
}
void distance_offset_correction_neon(float *mat, float *result, int n, float phase, int32_t *modulation_frequency)
{
/// 计算偏差
///**********************************************************************
//*号内代码,完全没必要采用neon实现,因为只是单个值的计算,不涉及到向量,这里仅作学习用,扩展成向量后,计算
// 定义变量,,,,neon的变量前缀统一为_,其余部分和c相同。
float32x4_t _c = vdupq_n_f32(299792458.0);
float32x4_t _neon_pi = vdupq_n_f32(3.14159265358979323846);
float32x4_t _four = vdupq_n_f32(4.f);
float32x4_t _thousand = vdupq_n_f32(1000.0);
float32x4_t _phase = vdupq_n_f32(phase);
// neon中,将int32转换为float
int32x4_t _modulation_frequency_int = vld1q_s32(modulation_frequency);
float32x4_t _modulation_frequency_float = vcvtq_f32_s32(_modulation_frequency_int);
// 如果是int16位,则需要先将int16扩展位int32位 int32x4_t vec1 = vmovl_s16(vget_low_s16(loaded)); int32x4_t vec2 = vmovl_s16(vget_high_s16(loaded));
float32x4_t _coef_rad = vmulq_f32(_four, _neon_pi);
_coef_rad = vmulq_f32(_coef_rad, _thousand);
_coef_rad = vdivq_f32(_c, _coef_rad); // vdivq_f32(a,b)=a/b
_phase = vaddq_f32(_phase, _neon_pi);
float32x4_t _distance = vdivq_f32(_phase, _modulation_frequency_float);
_distance = vmulq_f32(_distance, _coef_rad);
//std::cout << "--neon---------_distance-----------=" << _distance[0] << std::endl;
///***********************************************************************
全局标定
for (int i = 0; i < n; i += 4)
{
float32x4_t mat_vec = vld1q_f32(mat + i);
float32x4_t result_vec = vsubq_f32(mat_vec, _distance);
vst1q_f32(result + i, result_vec);
//std::cout << "---------------result= " << std::endl<< " " << *(result+i) << std::endl;
}
// for (int i = 0; i < 20; i += 4)
// {
// std::cout << "---------------result= " << std::endl<< " " << *(result+i) << std::endl;
// }
}
}
main.cpp
#include <arm_neon.h>
#include <iostream>
#include "algorithm_neon.h"
int main()
{
// 读入数据
static int count = 0;
cv::Mat m1(640, 480, CV_32FC1);
cv::Mat m2(640, 480, CV_32FC1);
cv::Mat m3(640, 480, CV_32FC1);
float a = 1.0;
for (int i = 0; i < m1.rows; i++) // 矩阵行数循环
{
for (int j = 0; j < m1.cols; j++) // 矩阵列数循环
{
m1.at<float>(i, j) = a+3000.0;
m2.at<float>(i, j) = 3065.0 - a;
m3.at<float>(i, j) = 1.0;
a = a + 1.0;
}
}
// std::cout << "M1= " << std::endl << " " << m1 << std::endl;
// std::cout << "M2= " << std::endl << " " << m2 << std::endl;
// std::cout << "M3= " << std::endl << " " << m3 << std::endl;
float *ptr_m1 = (float *)m1.data;
float *ptr_m2 = (float *)m2.data;
float *ptr_m3 = (float *)m3.data;
float scalar = 100.0;
int x=100;
int32_t *ptr_fre = reinterpret_cast<int32_t*>(&x);
// 全局标定
bool test_c = false;
if (test_c == true)
{
for (int i = 0; i < 1; i++)
{
//--c
double t2_c = (double)cv::getTickCount(); // 测时间
tof_neon::distance_offset_correction_c(m1,scalar, m3,1.0,100);
t2_c = (double)cv::getTickCount() - t2_c;
double time2_c = (t2_c * 1000.) / ((double)cv::getTickFrequency());
std::cout << "--cccccc--------------------------------------time=" << time2_c << " ms. " << std::endl;
}
}
else
{
for (int i = 0; i < 1; i++)
{
double t2_neon = (double)cv::getTickCount(); // 测时间
// distance_offset_correction_neon(m1,scalar,m2,64);
tof_neon::distance_offset_correction_neon(ptr_m1, ptr_m3, 307200,1.0,ptr_fre);
t2_neon = (double)cv::getTickCount() - t2_neon;
double time2_neon = (t2_neon * 1000.) / ((double)cv::getTickFrequency());
std::cout << "--neon--------------------------------------time=" << time2_neon << " ms. " << std::endl;
// std::cout << "---------------M2= " << std::endl << " " << m2 << std::endl;
std::cout << "---------------ptr_M3= " << std::endl<< " " << *ptr_m3 << std::endl;
}
}
return 0;
}
遇到的问题
(1)目前遇到的,neon中加载和保存数据,参数都是指针的形式。例如vld1q_s32函数。
(2)c++中的类型转换,除了强制转换外,还有以下几种转换方式。

(3)neon中的类型转换
上面代码中的int转float,感觉不是很有必要,完全可以直接传入想要的类型的参数。
但出于学习的角度,还是贴一下:
上文中贴了 int32转float32的代码,这块其实要注意下,不同类型所占的字节数,这里因为恰好int32 和float32 所占的字节数都是4,所以也就不涉及其他的转换。
贴下,不同类型所占的字节数。
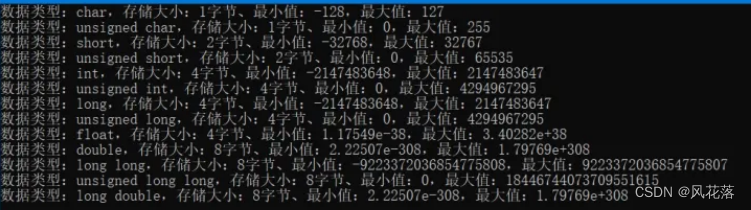

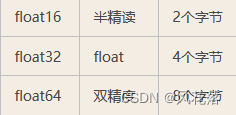














 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









