






——- android培训、java培训、期待与您交流! ———-
1.1 字符流
字符流的由来:因为文件编码的不同,而有了对字符进行高效操作的字符流对象。原理:其实就是基于字节流读取字节时,去查了指定的码表。
1.1.1 FileReader 字符读入
例子:
package com.test.blog4;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/*
* 文件读取字符流FileReaderDemo
* 读取文件信息
* */
public class FileReaderDemo {
// 定义需要读取的数据文件的路径
private static String filePath = "d:" + File.separator
+ "FileReaderDemo.java";
public static void main(String[] args) {
FileReader fr = null;
try {
// 实例化FileReader对象
fr = new FileReader(filePath);
// 定义读取缓冲数组
char[] buf = new char[1024];
int len = 0;
// 循环读取数据,输出显示
while ((len = fr.read(buf)) != -1) {
System.out.println("FileReader读到的数据: "
+ new String(buf, 0, len));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流
if (null != fr) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
运行结果:
1.1.2 FileWriter 字符写出
例子:
package com.test.blog4;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
/*
* 文件读取字符流FileWriterDemo 往文件写入信息
*/
public class FIleWriterDemo {
// 定义需要读取的数据文件的路径
private static String filePath = "d:" + File.separator
+ "FileWriterDemo.java";
public static void main(String[] args) {
FileWriter fw = null;
try {
fw = new FileWriter(filePath);
String str = "abc测试使用FileWrieter向文件写入数据123";
fw.write(str);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != fw) {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}运行结果:
1.1.3 BufferedReader\BufferedWriter 缓冲流
BufferedXXX是在字符流的基础上增加缓冲区,提高字符读入和写出的效率,所以使用它也必须要有原始的字节流先存在才可以.
例子:
package com.test.blog4;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
/*
* 字符缓冲流BufferedReader 和 BufferedWriter 读写数据的演示
* */
public class Buffered {
public static void main(String[] args) {
// BufferedReader读入数据演示
bufferedReaderTest();
// BufferedWriter写出数据演示
bufferedWriterTest();
}
// BufferedReader 使用演示
public static void bufferedReaderTest() {
String filePath = "d:" + File.separator + "testread.txt";
// 定义原始输入字节流
FileReader fis = null;
// 定义缓冲输入流
BufferedReader br = null;
try {
fis = new FileReader(filePath);
br = new BufferedReader(fis);// 进行流的包装
String line = "";
System.out.println("FileReader读取到的数据:");
// 使用缓冲流的好处,一次可以读取一行
// br.read():这个read方法是从缓冲区中读取字符数据,所以覆盖了父类中的read方法。
// br.readLine():另外开辟了一个缓冲区,存储的是原缓冲区一行的数据,不包含换行符。
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != br) {
try {
// 关闭流
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
// BufferedReader 使用演示
public static void bufferedWriterTest() {
String filePath = "d:" + File.separator + "testwrite.txt";
// 定义原始出书字节流
FileWriter fw = null;
// 定义缓冲输出流
BufferedWriter bw = null;
try {
fw = new FileWriter(filePath);
bw = new BufferedWriter(fw);// 进行流的包装
for (int i = 0; i < 5; i++) {
bw.write("第 " + i + "行 测试bufferedwriter写入数据");
// 写入换行符,切换到下一行
bw.newLine();
// 刷新缓冲区,将数据写入到文件中
bw.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != bw) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
运行结果:
BufferedReader的结果:
BufferedWriter的结果:
1.1.4 LineNumberReader 加行号的流
LineNumberReader可以按照设置的行数开始给读取到的每行加上行号标记
例子:
package com.test.blog4;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.LineNumberReader;
public class LineNumberReaderDemo {
/**
* @Description: 跟踪行号的缓冲字符输入流 演示
* @param @param null
* @return void null
* @throws
*/
public static void main(String[] args) {
FileReader fr = null;
LineNumberReader lnr = null;
try {
fr = new FileReader("d:" + File.separator + "test.txt");
lnr = new LineNumberReader(fr);
String line = "";
lnr.setLineNumber(10);// 设置行号从10开始累加
while ((line = lnr.readLine()) != null) {
// 输出读到的数据,前面显示行号
System.out.println(lnr.getLineNumber() + " " + line);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != lnr) {
try {
// 关闭流
lnr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
运行结果:
1.1.5 转换流
P.S. 有时候可能我们拿到的是字节流,但是操作的都是文本数据,这个时候我们希望能够使用字符缓冲流来进行高效的操作,那么如何将字节流转换成字符流呢,就用到了转换流InputStreamReader\OutputStreamWriter
例子:
package com.test.blog4;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
/*
* 转换流,读入操作的时候将字节流转换为字符流操作
* */
public class InputStreamReaderDemo {
public static void main(String[] args) {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
//原始字节流
fis = new FileInputStream("d:" + File.separator + "test.txt");
//将字节流转换成字符流
isr = new InputStreamReader(fis);
//使用换成流包装
br = new BufferedReader(isr);
String line = "";
System.out.println("转换流转换后读取到的数据 : ");
//可以直接读取一行数据
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != fis) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != isr) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != br) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
运行结果:
package com.test.blog4;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
/*
* 转换流,写入操作的时候将字节流转换为字符流操作
* */
public class OutputStreamWriterDemo {
public static void main(String[] args) {
FileOutputStream fos = null;
OutputStreamWriter osr = null;
BufferedWriter bw = null;
try {
fos = new FileOutputStream("d:" + File.separator + "testNew.txt");
// 使用原始字节流转换字符流
osr = new OutputStreamWriter(fos);
bw = new BufferedWriter(osr);// 缓冲流包装
String line = "";
bw.write("OutputStreamWriter 是字符流通向字节流的桥梁:可使用指定的 charset 将要写入流中的字符编码成字节。它使用的字符集可以由名称指定或显式给定,否则将接受平台默认的字符集");
bw.newLine();
bw.write("写入完毕");
bw.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != fos) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != osr) {
try {
osr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != bw) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
运行结果:

1.1.6 序列流 SequenceInputStream
P.S. 有时候需要将多个文件合并到一个文件中。比如将多个文件的内容输入到一个文件中;或者将在上传服务器过程中文件临时保存的碎片合并成完整的文件等
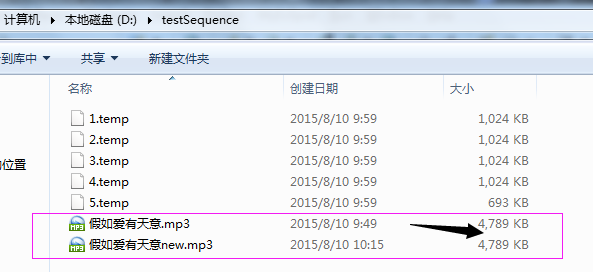
例子:演示文件分割成多分后,在将其合并成一个新的文件
package com.test.blog4;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.SequenceInputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.List;
/**
* SequenceInputStream 序列流的演示
*
* API:它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾
* ,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止
*/
public class SequenceInputStreamDemo {
private final static String filePath = "d:" + File.separator
+ "testSequence" + File.separator + "假如爱有天意.mp3";
private final static String filePathNew = "d:" + File.separator
+ "testSequence" + File.separator;
public static void main(String[] args) {
try {
// 首先将文件切割成多个部分
int count = cutFile();
System.out.println(count + "");
// 将多个文件合并成一个文件
mergeFile(count);
} catch (FileNotFoundException e) {
System.out.println("文件没找到:" + e.getMessage());
} catch (IOException e) {
System.out.println("IO读写错误:" + e.getMessage());
}
}
/*
* 将一个文件切割成多个文件保存,每个1M大小,最后不足1M的按照实际大小保存 参数返回:分割成的文件的数量
*/
public static int cutFile() throws FileNotFoundException, IOException {
int count = 0;// 保存文件分割的数量
FileInputStream fis = new FileInputStream(filePath);
FileOutputStream fos = null;
// 定义每个碎片文件的大小为1M
byte[] buf = new byte[1024 * 1024];
int len = 0;
while ((len = fis.read(buf)) != -1) {
fos = new FileOutputStream(filePathNew + (++count) + ".temp");
// 生成碎片文件,不足1M的按实际大小存
fos.write(buf, 0, len);
}
fis.close();
fos.close();
return count;
}
/*
* 将多个分割临时保存文件合并成一个正常格式文件
*/
public static void mergeFile(int count) throws IOException {
// 定义集合用来添加所有碎片文件的输入流数据
List<FileInputStream> list = new ArrayList<FileInputStream>();
for (int i = 1; i <= count; i++) {
list.add(new FileInputStream(filePathNew + i + ".temp"));
}
// 使用结合工具将list中的所有输入流转换为Enumeration对象
Enumeration<FileInputStream> en = Collections.enumeration(list);
// 使用Enumeration对象为构造函数参数来创建序列流对象
SequenceInputStream sis = new SequenceInputStream(en);
// 定义生成新文件的输出流
FileOutputStream fos = new FileOutputStream(filePathNew
+ "假如爱有天意new.mp3");
byte[] buf = new byte[1024];
int len = 0;
// 序列流的读操作和其他流没有区别,它按顺序读取保存在其中的数据流
while ((len = sis.read(buf)) != -1) {
fos.write(buf, 0, len);
}
// 关闭流
sis.close();
fos.close();
}
}
运行结果:
1.2 字节流在使用缓冲流包装前后效率
P.S. 为什么会出现缓冲包装流,因为可以极大的提高读取效率,下面演示一个例子说明,如果读取更大的数据,效率提高更加明显
例子:
package com.test.io;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Day21_3 {
/*
* 字节流在假如缓冲包装前后的读写的效率比较演示
*/
public static void main(String[] args) {
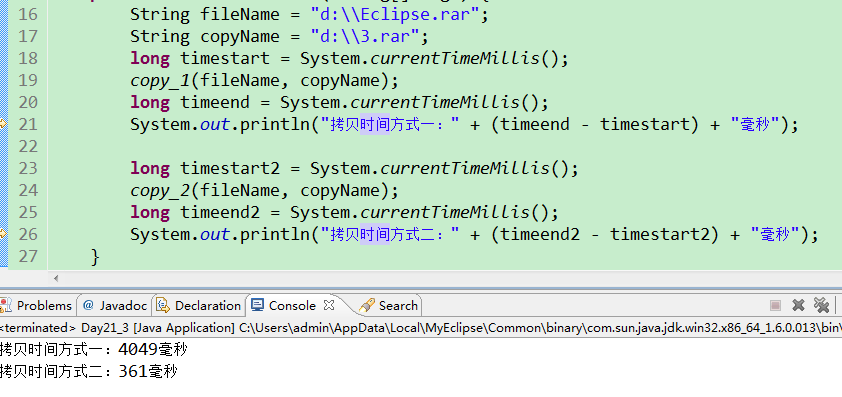
String fileName = "d:\\Eclipse.rar";
String copyName = "d:\\3.rar";
long timestart = System.currentTimeMillis();
copy_1(fileName, copyName);
long timeend = System.currentTimeMillis();
System.out.println("拷贝时间方式一:" + (timeend - timestart) + "毫秒");
long timestart2 = System.currentTimeMillis();
copy_2(fileName, copyName);
long timeend2 = System.currentTimeMillis();
System.out.println("拷贝时间方式二:" + (timeend2 - timestart2) + "毫秒");
}
/*
* 通过一般字节读写方式,和加入缓冲区的方式拷贝MP3文件,比较效率 缓冲区为BufferedInputStream
* ,BufferedOutputSteam
*/
// copy 一般字节读取方式
public static void copy_1(String filePath, String copyPath) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(filePath);
fos = new FileOutputStream(copyPath);
byte[] buf = new byte[1024];
int len = 0;
while ((len = fis.read(buf)) != -1) {
fos.write(buf, 0, len);// 注意不需要flush方法,调用没有意义
}
} catch (Exception e) {
System.out.println("文件打开写入过程失败");
} finally {
try {
if (null != fis) {
fis.close();
}
} catch (Exception e2) {
System.out.println("fis关闭失败");
}
try {
if (null != fos) {
fos.close();
}
} catch (Exception e2) {
System.out.println("fos关闭失败");
}
}
}
// 加入缓冲区的拷贝方式
public static void copy_2(String filePath, String copyPath) {
FileInputStream fis = null;
FileOutputStream fos = null;
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
fis = new FileInputStream(filePath);
fos = new FileOutputStream(copyPath);
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
byte[] buf = new byte[1024];
int len = 0;
while ((len = bis.read(buf)) != -1) {
bos.write(buf, 0, len);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
if (null != bis) {
bis.close();
}
} catch (Exception e2) {
System.out.println("bis关闭失败");
}
try {
if (null != bos) {
bos.close();
}
} catch (Exception e2) {
System.out.println("bos关闭失败");
}
}
}
}
运行结果:
1.3 字符编码
字符流的出现方便操作字符,还可以以指定的编码进行转换,一般在构造函数中加入编码参数。
常见的编码表:
--ASCII:美国标准信息交换码,用一个字节的七位表示
--ISO8859-1:拉丁码表,欧洲码表,用一个字节的八位表示
--GB2312:中文编码表,用两个字节表示
--GBK:中文编码表升级,融合录入更多的中文字符,用两个字节表示,两字节的最高位都是1,即汉字都是用负数表示
--Unicode:国际标准码,融合了多种文字,所有文字都用两个字节表示
--UTF-8:用一个字节到三个字节表示。
注:Unicode能识别中文,UTF-8也能识别中文,但两种编码表示一个汉字所用的字节数不同Unicode用两个字节,UTF-8用三个字节,故涉及到编码转换。
当写入文件的汉字乱码或者读取文件中的汉字出现乱码的时候就是编码和解码不一致导致的。定义编码类型只在转换流中有,如下:
public static void write() throws IOException
{
OutputStreamWriter osw1 = new OutputStreamWriter(new FileOutputStream("gbk.txt"),"GBK");
osw1.write("你好");
osw1.close();
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream("utf-8.txt"),"UTF-8");
osw2.write("你好");
osw2.close();
}
public static void read() throws IOException
{
InputStreamReader isr = new InputStreamReader(new FileInputStream("gbk.txt"),"GBK");
byte[] buf = new byte[1024];
int len = isr.read(buf);
sop(new String(buf,0,len));
}
public static void read2() throws IOException
{
InputStreamReader isr = new InputStreamReader(new FileInputStream("gbk.txt"),"UTF-8");
byte[] buf = new byte[1024];
int len = isr.read(buf);
sop(new String(buf,0,len));
}其他需要注意字符编码的地方(在使用指定编码后仍出现乱码):
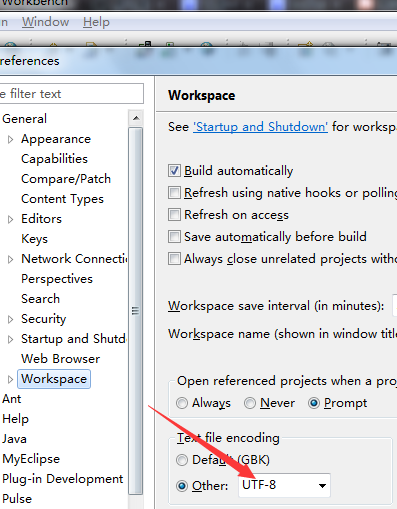
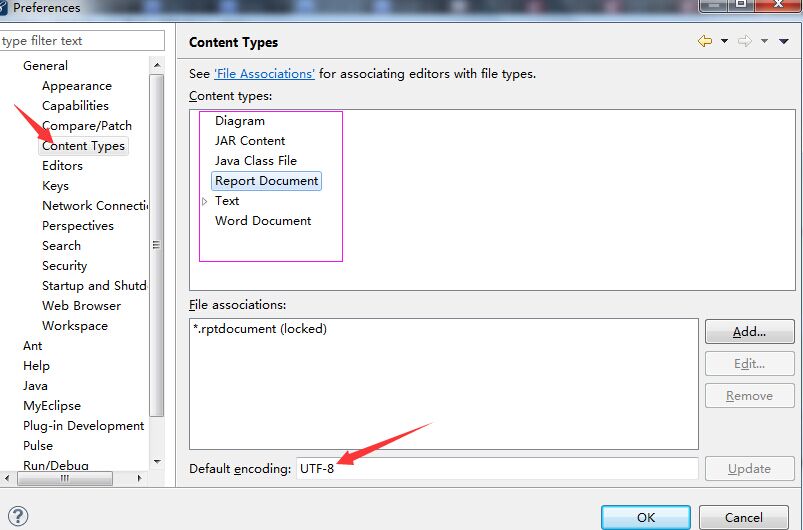
- 默认环境 检查myeclipse的设置,一般设置为UTF-8,如图:
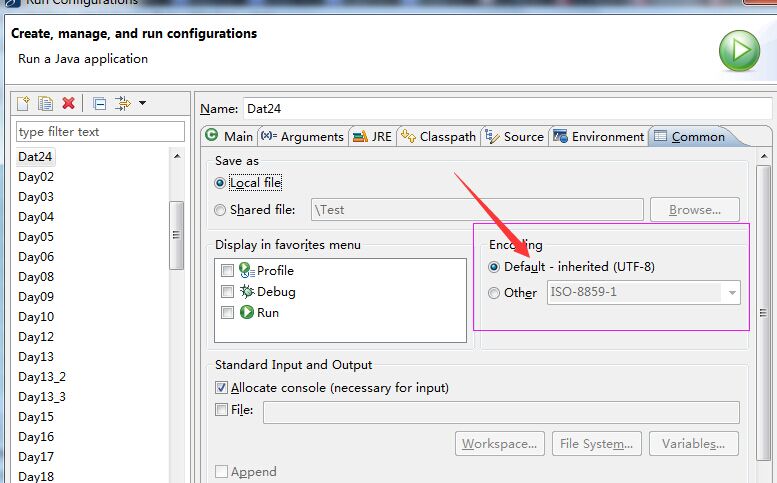
- 还有一种情况,控制台输出有时候也会出现中文乱码的问题,看如下设置(此处容易忽略):
在runDialog里设置:
run ->run Configurations->common->
1.4 流的使用规律
- 明确源和目的
源:InputStream Reader
目的:OutputStream Writer - 明确数据是否是纯文本数据
源:是纯文本:Reader
否:InputStream
目的:是纯文本:Writer
否:OutputStream - 明确具体的设备
硬盘:File
键盘:System.in
内存:数组
网络:Socket流
目的设备:
硬盘:File
控制台:System.out
内存:数组
网络:Socket流 - 是否需要其他额外功能
是否需要高效(缓冲区):是,就加上buffer
1.5 总结
P.S.流操作需要格外注意的一些地方:
- 字节流写入的时候没有刷新,字符流中有缓冲包装的需要有刷新flush()
- 字符编码一般统一使用UTF-8
- 使用包装的时候一般使用简写 new BufferedReader(new InputStreamReader(new FileInputStream(filePath)));
- 使用包装流的时候关闭流关闭包装流即可
- 流的关闭放到finally里,确保会被执行
- -















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









