







ARCS过程中的步骤包括
- 分箱(根据不同分箱方法创建一个2-D数组),本步骤的目的在于减少量化属性相对应的巨大的值个数,使得2-D栅格的大小可控
- 等宽分箱
- 等深分箱
- 基于同质的分箱
- 找出频繁谓词集
- 扫描分箱后形成的2-D数组, 找出满足最小支持度和置信度的频繁谓词集
- 扫描分箱后形成的2-D数组, 找出满足最小支持度和置信度的频繁谓词集
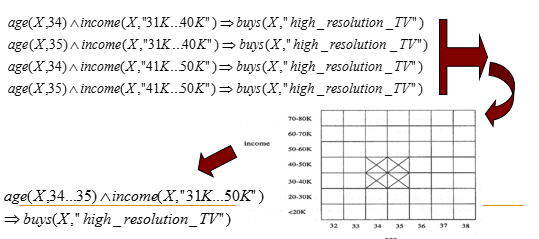
ARCS的局限性
- 所挖掘的关联规则左手边只能是量化属性
- 规则的左手边只能有两个量化属性(2-D栅格的限制)
一种基于栅格的, 可以发现更一般关联规则的技术, 其中任意个数的量化属性和分类属性可以出现在规则的两端
- 等深分箱动态划分
- 根据部分完全性的度量进行聚类
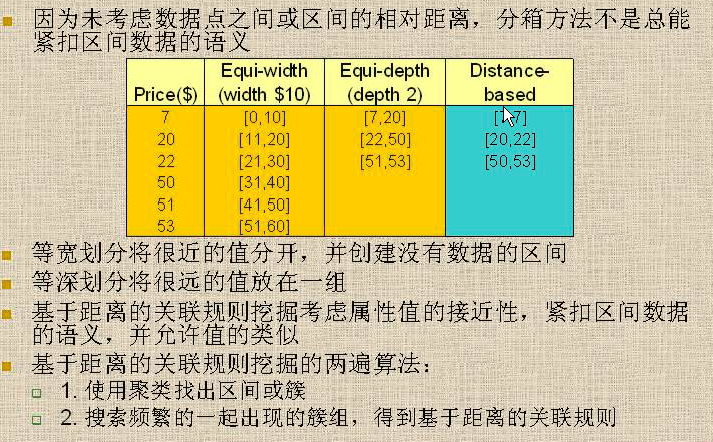
挖掘基于距离的关联规则
关联规则的兴趣度度量
- 客观度量
- 两个流行的度量指标
- -支持度
- -置信度
- 主观度量
- 挖掘了关联规则后, 哪些规则使用户感兴趣的? 强关联规则是否就是有趣的?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









