






走向个性化的联合学习
本文参考论文:链接: Towards Personalized Federated Learning
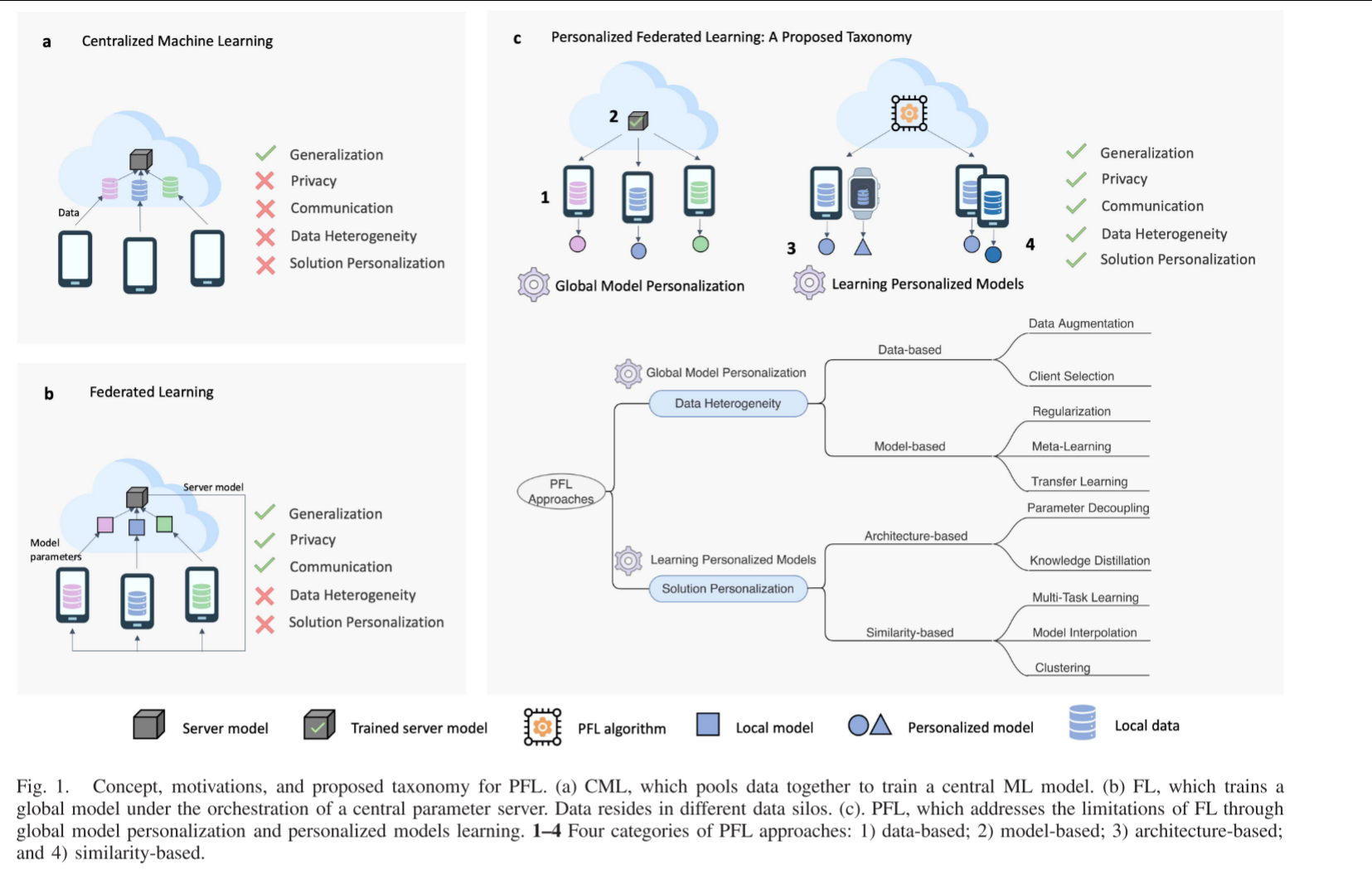
传统的“一刀切”式联邦学习在面对现实世界中普遍存在的非独立同分布(Non-IID)数据时,其性能会严重下降。因此,必须转向个性化联邦学习(PFL),为每个客户端量身定制模型,以在保护隐私的前提下实现最佳性能。具体分为两大策略。
- 战略一(Strategy I): 全局模型个性化(Global Model Personalization)
思想:先合作训练一个“强健的”全局模型作为基础,然后让各个客户端在这个好的基础上进行微调(Fine-tuning),得到自己的模型。 - 战略二(Strategy II): 学习个性化模型(Learning Personalized Models)
思想:不再追求一个统一的全局模型,而是直接为每个客户端训练截然不同的模型。在合作过程中,利用客户端之间的“相似性”来相互帮助。
全局模型个性化(Global Model Personalization)
Strategy I 的核心理念可以概括为“先合作,后微调”。它遵循经典联邦学习的训练范式,其核心目标是先训练一个强大的、泛化能力优异的全局模型。这个全局模型是所有客户端通力合作的成果,它汲取了所有数据孤岛中的知识。
在全局模型训练完成后,个性化的阶段才正式开始。每个客户端将全局模型下载到本地,**然后在自己的私有数据集上进行额外的训练(即本地微调或适配)**,从而得到一个更适合自身数据分布的个性化模型。
Strategy I 主要分为两大类方法:数据层面(Data-based) 和 模型层面(Model-based)。
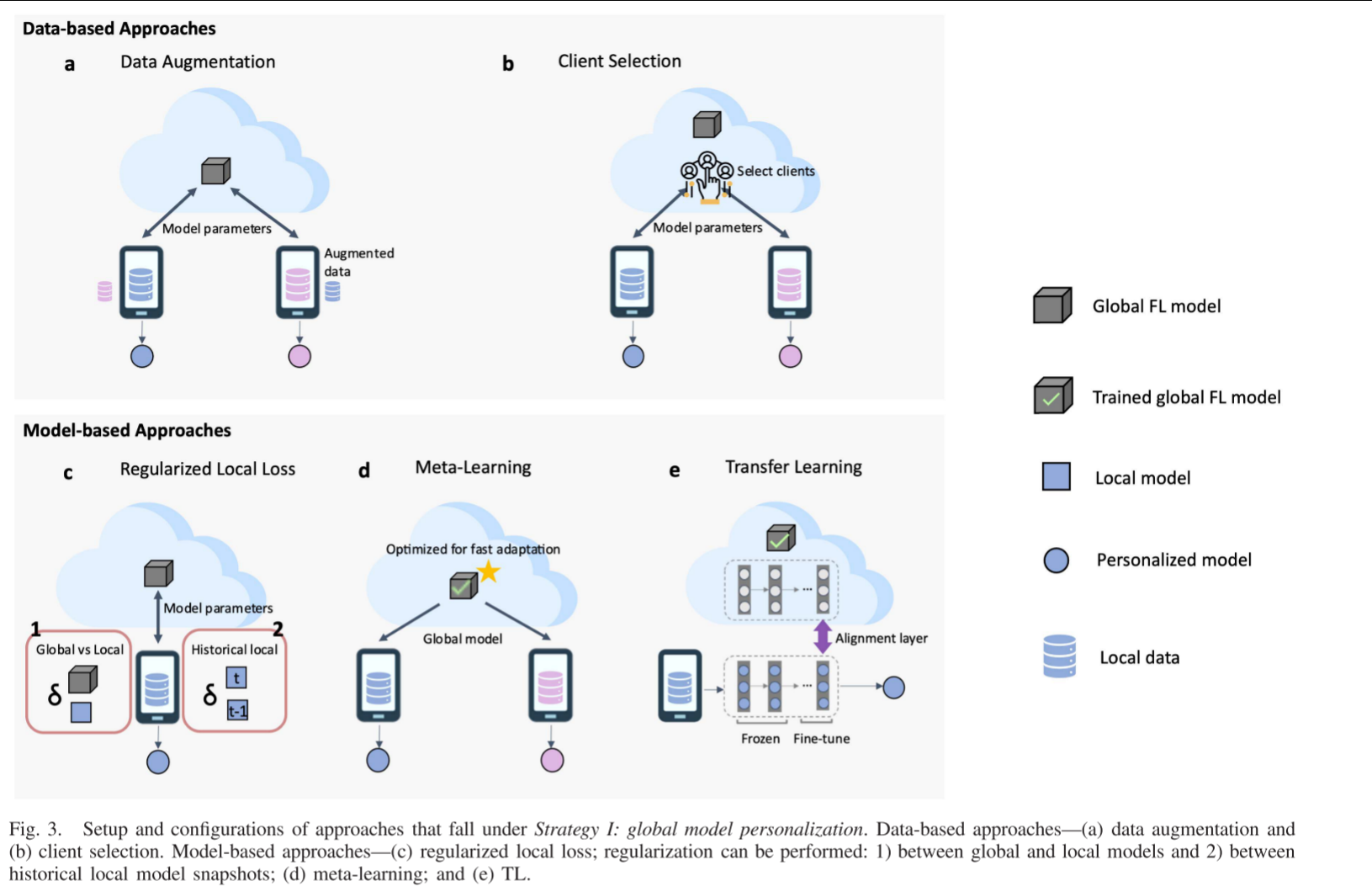
数据层面(Data-based)方法
- 核心思想:从数据源头入手,通过技术手段减少或缓解客户端之间数据分布(即统计异质性)的差异,从而减轻“客户端漂移”(Client Drift)问题,使得FedAvg等算法能训练出更佳的全局模型。
数据增强(Data Augmentation):
-
做法:在客户端本地,通过对现有数据进行变换(如旋转、裁剪、添加噪声等)来生成更多训练样本,旨在使本地数据的分布更接近全局分布。更高级的方法如FAug[22] 会在服务器端训练一个生成对抗网络(GAN),然后分发给客户端生成合成数据。
-
挑战:需要谨慎设计增强策略,以避免生成无意义或误导性的数据。某些方法可能涉及数据共享,带来隐私风险。
客户端选择(Client Selection):
-
做法:在每一轮训练中,服务器不是随机选择客户端,而是通过智能算法(如强化学习、多臂老虎机)选择一组在当前阶段数据分布更能互补或更接近IID的客户端参与训练。
-
目标:通过优化选择策略,使每轮聚合所面向的数据分布更加均衡,从而改善全局模型的收敛性和性能。
-
挑战:增加了额外的计算开销,且需要设计有效的选择指标。
模型层面(Model-based)方法
- 核心思想:不改变本地数据,而是修改本地训练的目标函数或优化过程,约束本地模型的更新方向,防止其偏离全局模型太远,从而得到一个更利于后续微调的全局模型。
正则化本地损失(Regularized Local Loss):
这是最重要、最主流的一类方法。其本地训练的目标函数为:
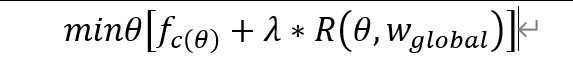
其中 f_c(θ)是本地损失,R是正则项,λ是正则化强度。
- 经典算法:
FedProx[29]: 使用L2正则,R = ||θ - w_global||²。直接强制本地参数靠近全局参数。
SCAFFOLD[12]: 引入了“控制变量”来估计和修正客户端更新方向的偏差,能更有效地解决异质性带来的漂移问题。
MOON[32]: 利用对比学习(Contrastive Learning),在表示层进行约束,让本地模型的特征表示靠近全局模型,而远离其上一轮的特征表示,从而同时缓解漂移和加速收敛。
元学习(Meta-Learning):
-
核心思想:不追求一个表现好的全局模型,而是追求一个“善于学习”的模型初始化点。这个初始化模型经过任何客户端本地几步微调,就能快速适应其任务。
-
经典算法:Per-FedAvg[37](基于MAML)。其优化目标不是 f_c(w),而是 f_c(w - α∇f_c(w)),即“微调一步后的性能”。这直接优化了模型的可微调性。
-
挑战:涉及二阶导数计算,计算和通信开销较大。
迁移学习(Transfer Learning):
-
做法:将训练好的全局模型视为一个预训练模型。个性化阶段就是在其上进行领域自适应(Domain Adaptation),例如在模型中添加特定的适配层(如CORAL层),并只对这些层进行微调,以适应本地数据分布。
-
优势:非常直观,且与计算机视觉、自然语言处理中的微调范式一致。
学习个性化模型(Learning Personalized Models)
与Strategy I的“先合作,后微调”不同,Strategy II 的核心理念是“在协同中独立学习”。它摒弃了训练单一全局模型的目标,转而直接为每个客户端训练一个独立的、个性化的模型。这些模型在训练过程中通过某种机制相互协作、借鉴知识,但最终产出是多个异构的模型,而不再是一个统一的模型。
该策略的逻辑在于:当数据异质性非常严重时,强行融合了一个“四不像”的全局模型可能对所有客户端都不是最优解。不如承认差异,直接为每个客户端定制模型,并通过技术手段让数据分布相似的客户端之间更多地交流,从而在保持个性化的同时,又能利用他人数据的信息来提升自身模型的泛化能力。
Strategy II 主要分为两大类方法:架构层面(Architecture-based) 和 相似性层面(Similarity-based)。
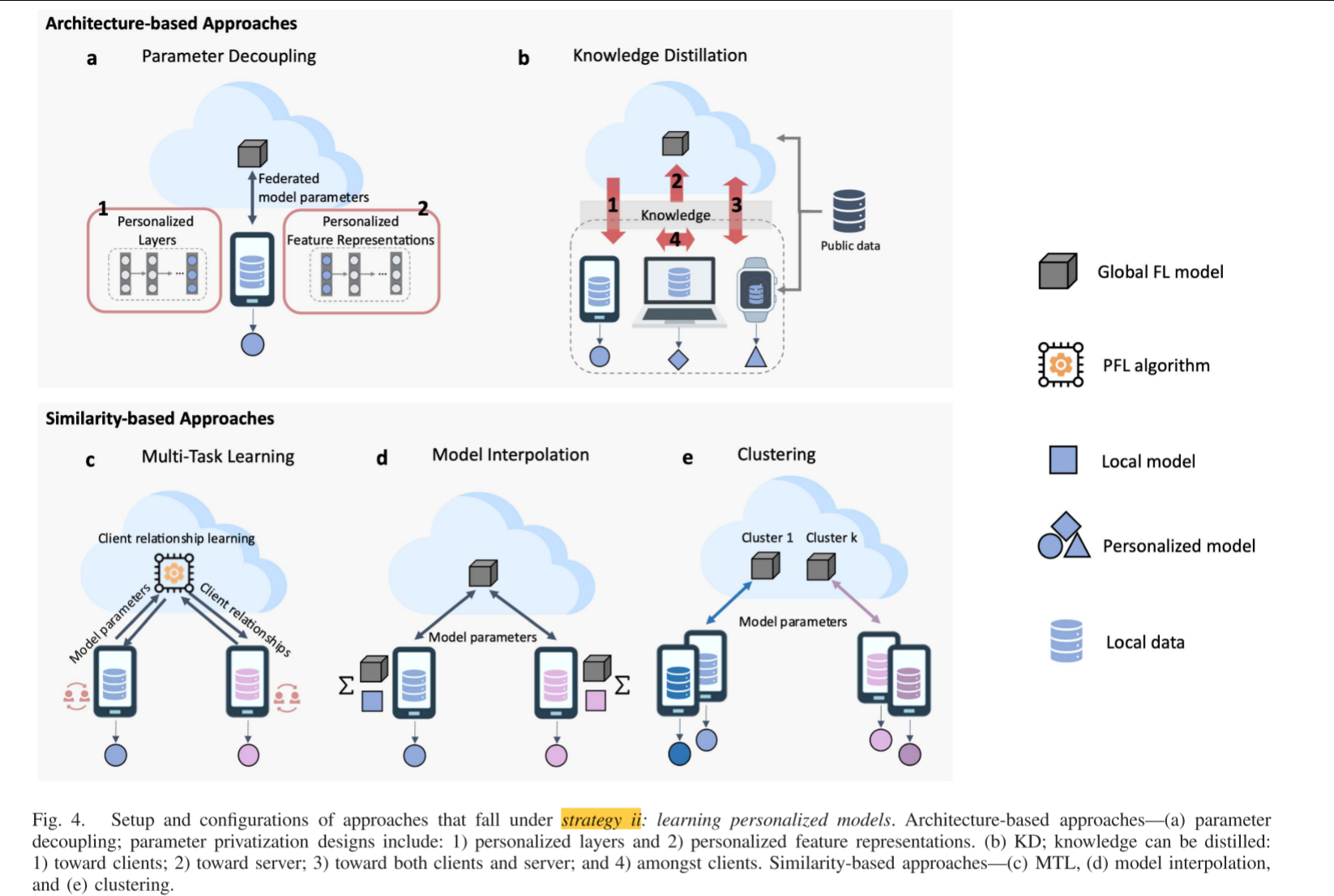
架构层面(Architecture-based)方法
- 核心思想:通过设计特殊的模型架构,将“共享”与“私有”部分解耦,从模型结构上根本性地支持个性化。
参数解耦(Parameter Decoupling):
-
做法:将模型的参数划分为两部分:
-
全局参数:所有客户端共享的部分,用于学习通用的、底层的特征(如图像中的边缘、纹理)。这部分参数参与联邦聚合。
-
私有参数:每个客户端独有的部分,用于学习特定于自身数据分布的高层、个性化特征。这部分参数永不离开客户端,不参与聚合。
-
常见设计:
个性化层:在深度网络中,将底层作为全局参数,顶层作为私有参数。 个性化特征表示:例如,在推荐系统中,用户嵌入向量(User Embedding)作为私有参数,物品嵌入向量及其他网络层作为全局参数。 -
优势:概念清晰,隐私性好,直观易懂。
-
挑战:需要先验知识来确定哪些层共享、哪些层私有,这本身是一个需要优化的超参数。
知识蒸馏(Knowledge Distillation, KD):
-
做法:客户端不直接共享模型参数,而是共享其模型的“知识”(通常以对公共数据集产生的软标签/输出概率的形式)。服务器或其他客户端通过这些知识来提炼、精进自己的模型。
-
经典流程:
各客户端在本地训练自己的个性化模型。 各客户端使用本地模型对一份公共的无标签数据集进行预测,得到“软标签”(Soft Labels)。 客户端将软标签上传至服务器。 服务器聚合这些软标签(如取平均),形成一个“共识”。 各客户端下载这个共识,并以此为目标,在自己的本地数据上通过蒸馏损失(如KL散度)继续训练自己的模型,使其输出向共识靠近,从而吸收其他模型的知识。 -
优势:支持模型异质性(不同客户端可以使用完全不同的模型架构),通信效率高(软标签比模型参数小得多)。
-
挑战:需要一份有代表性的公共数据集,且蒸馏过程可能需要多轮迭代。
相似性层面(Similarity-based)方法
- 核心思想:利用客户端之间数据分布的相似性来指导个性化模型的训练。相似的客户端应该相互学习更多,不相似的客户端则应减少影响。
多任务学习(Multi-Task Learning, MTL):
-
做法:将每个客户端的学习任务视为一个相关的子任务。通过建模任务之间的关系(相似性矩阵),在联合优化所有任务的过程中,使得相似客户端的模型参数也更加接近。
-
经典算法:MOCHA[59] 框架,它通过一个对偶形式来共同学习所有客户端的模型和它们之间的相关性。
-
优势:理论优美,能显式地建模客户端关系。
-挑战:计算和通信开销大,难以扩展到大量客户端。
聚类(Clustering):
-
做法:这是最直观的相似性方法。核心假设是:客户端会自然地形成几个群体,群体内数据分布相似。为每个群体训练一个集群模型,而不是为每个人或所有人训练一个模型。
-
经典流程:
服务器初始化多个模型(如K个,对应K个集群)。 将所有这些模型广播给客户端。 每个客户端用所有模型在自己的数据上计算损失,选择损失最小的那个模型作为其所属集群。 客户端仅下载其所属集群的模型进行本地训练。 服务器收集同一集群内客户端的模型更新,进行集群内的联邦平均(FedAvg)。 重复步骤2-5,集群分配和模型同时优化。 -
经典算法:IFCA[68]。
-
优势:非常适用于存在明显数据分组场景(如不同地区、不同医院)。
-
挑战:需要预先指定或能自动确定集群数量K;初始化敏感;通信开销大(需广播多个模型)。
模型插值(Model Interpolation):
-
做法:每个客户端的最终模型是其本地训练得到的模型与全局模型(或其所属的集群模型)的一个加权平均。
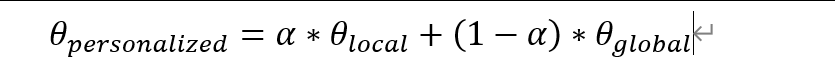
-
超参数α:控制个性化程度。α=1代表完全本地模型(无协作);α=0代表全局模型(无个性化)。α可以自适应地学习。
-
优势:实现简单,计算开销小。
-
挑战:如何为每个客户端自动学习最优的α值是一个关键问题。

















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









