







阅读本文需要的背景知识点:拉格朗日乘数法、一丢丢编程知识
一、引言
前面学习了一种用回归的方式来做分类的算法——对数几率回归算法,下面再来学习另一种分类算法——线性判别分析算法1(Linear Discriminant Analysis Algorithm / LDA),该算法由罗纳德·艾尔默·费希尔在1936年提出,所以也被称为费希尔的线性鉴别方法(Fisher’s linear discriminant)
二、模型介绍
先来看下图,假设有二分类的数据集,“+”表示正例,“-”表示反例。线性判别分析算法就是要设法找到一条直线,使得同一个类别的点在该直线上的投影尽可能的接近,同时不同分类的点在直线上的投影尽可能的远。该算法的主要思想总结来说就是要“类内小、类间大”,非常类似于在软件设计时说的“低耦合、高内聚”。
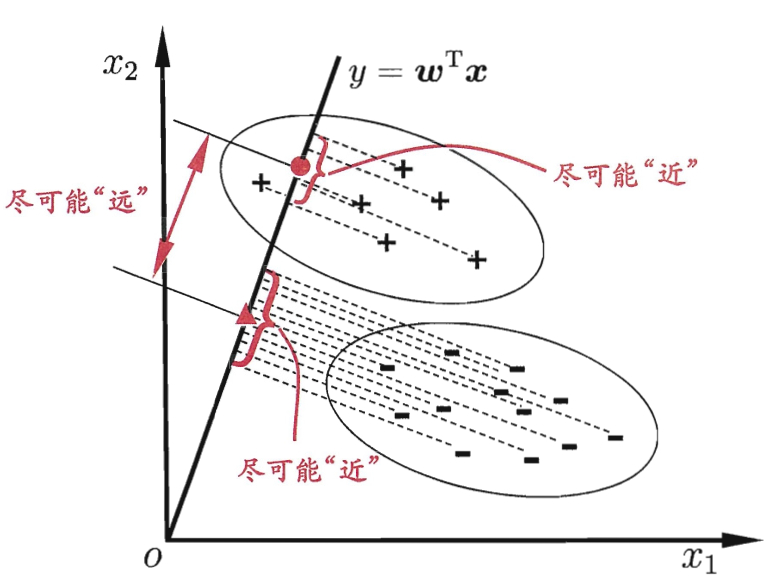
当有新的样本点需要分类时,计算该点在直线上的投影,根据投影的位置来判断新样本点的分类。那么如何用数学公式来表示上述说法呢?
三、代价函数
假设有样本数为 N 的数据集, X i X_i Xi表示第i个样本点的特征向量, y i y_i yi表示第i个样本点的标签值, w w w 表示直线的权重系数。
样本点到直线的投影向量
(1)投影向量为样本点乘以与直线夹角的余弦值
(2)带入夹角余弦值的公式
(3)由上图可以看到,我们只需要关系该直线的斜率即可,也就是
w
w
w 的方向。不妨令w为单位向量,即
∣
w
∣
=
1
|w| = 1
∣w∣=1,带入后整理可得
(4)可以看到(3)式中的第一项即为单位向量,后两项乘积为实数。投影的方向必然与
w
w
w 的方向相同,所以不妨将第一项用
w
w
w 向量代替
p
i
=
X
i
cos
θ
(
1
)
=
X
i
w
T
X
i
∣
w
∣
∣
X
i
∣
(
2
)
=
X
i
∣
X
i
∣
w
T
X
i
(
3
)
=
w
T
X
i
w
(
4
)
\begin{aligned} p_i &= X_i \cos \theta & (1)\\ &= X_i \frac{w^TX_i}{\mid w \mid \mid X_i \mid } & (2) \\ &= \frac{X_i}{\mid X_i \mid } w^TX_i & (3) \\ &= w^TX_iw & (4) \\ \end{aligned}
pi=Xicosθ=Xi∣w∣∣Xi∣wTXi=∣Xi∣XiwTXi=wTXiw(1)(2)(3)(4)
均值向量与协方差矩阵
(1)样本为二分类,
N
1
N_1
N1表示第一类样本数量,
N
2
N_2
N2表示第二类样本数量
(2)第一类样本点投影的均值向量
(3)第一类样本点投影的协方差矩阵
(4)第二类样本点投影的均值向量
(5)第二类样本点投影的协方差矩阵
N
=
N
1
+
N
2
(
1
)
μ
p
1
=
1
N
1
∑
i
=
1
N
1
p
i
(
2
)
σ
p
1
=
1
N
1
∑
i
=
1
N
1
(
p
i
−
μ
p
1
)
(
p
i
−
μ
p
1
)
T
(
3
)
μ
p
2
=
1
N
2
∑
i
=
1
N
2
p
i
(
4
)
σ
p
2
=
1
N
2
∑
i
=
1
N
2
(
p
i
−
μ
p
2
)
(
p
i
−
μ
p
2
)
T
(
5
)
\begin{aligned} N &=N_{1}+N_{2} & (1)\\ \mu_{p_{1}} &=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}} p_{i} & (2)\\ \sigma_{p_{1}} &=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left(p_{i}-\mu_{p_{1}}\right)\left(p_{i}-\mu_{p_{1}}\right)^{T} & (3)\\ \mu_{p_{2}} &=\frac{1}{N_{2}} \sum_{i=1}^{N_{2}} p_{i} & (4)\\ \sigma_{p_{2}} &=\frac{1}{N_{2}} \sum_{i=1}^{N_{2}}\left(p_{i}-\mu_{p_{2}}\right)\left(p_{i}-\mu_{p_{2}}\right)^{T} & (5) \end{aligned}
Nμp1σp1μp2σp2=N1+N2=N11i=1∑N1pi=N11i=1∑N1(pi−μp1)(pi−μp1)T=N21i=1∑N2pi=N21i=1∑N2(pi−μp2)(pi−μp2)T(1)(2)(3)(4)(5)
代价函数
我们知道样本点的协方差可以用于衡量两个变量的总体误差,那么可以使用协方差的大小来表示类内。而样本点的均值点可以用来表示相对位置,那么可以使用均值点来表示类间。我们的目标是让投影的“类内小、类间大”,那么可以写出对应的代价函数如下:
Cost
(
w
)
=
(
w
T
μ
p
1
−
w
T
μ
p
2
)
2
w
T
σ
p
1
w
+
w
T
σ
p
2
w
\operatorname{Cost}(w)=\frac{\left(w^{T} \mu_{p_{1}}-w^{T} \mu_{p_{2}}\right)^{2}}{w^{T} \sigma_{p_{1}} w+w^{T} \sigma_{p_{2}} w}
Cost(w)=wTσp1w+wTσp2w(wTμp1−wTμp2)2
分子为均值向量大小之差的平方,该值越大代表类间越大。分母为两类样本点的协方差之和,该值越小代表类内越小,我们的目标就是求使得该代价函数最大时的w:
w
=
argmax
w
(
(
w
T
μ
p
1
−
w
T
μ
p
2
)
2
w
T
σ
p
1
w
+
w
T
σ
p
2
w
)
w=\underset{w}{\operatorname{argmax}}\left(\frac{\left(w^{T} \mu_{p_{1}}-w^{T} \mu_{p_{2}}\right)^{2}}{w^{T} \sigma_{p_{1}} w+w^{T} \sigma_{p_{2}} w}\right)
w=wargmax(wTσp1w+wTσp2w(wTμp1−wTμp2)2)
我们先来看下代价函数分子的部分:
(1)将投影的均值向量带入分子中
(2)可以将公共的
w
w
w 的转置与
w
w
w 提出来,观察后可以写成两类样本点的均值向量之差
(3)中间两项为实数可以提到前面,
w
w
w 为单位向量,与自己相乘为1
(4)将平方写成向量乘积的形式
(
w
T
μ
p
1
−
w
T
μ
p
2
)
2
=
(
w
T
(
1
N
1
∑
i
=
1
N
1
w
T
X
i
w
)
−
w
T
(
1
N
2
∑
i
=
1
N
2
w
T
X
i
w
)
)
2
(
1
)
=
(
w
T
(
w
T
(
μ
1
−
μ
2
)
w
)
)
2
(
2
)
=
(
w
T
(
μ
1
−
μ
2
)
)
2
(
3
)
=
w
T
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
(
4
)
\begin{aligned} \left(w^{T} \mu_{p_{1}}-w^{T} \mu_{p_{2}}\right)^{2} &=\left(w^{T}\left(\frac{1}{N_{1}} \sum_{i=1}^{N_{1}} w^{T} X_{i} w\right)-w^{T}\left(\frac{1}{N_{2}} \sum_{i=1}^{N_{2}} w^{T} X_{i} w\right)\right)^{2} & (1)\\ &=\left(w^{T}\left(w^{T}\left(\mu_{1}-\mu_{2}\right) w\right)\right)^{2} & (2) \\ &=\left(w^{T}\left(\mu_{1}-\mu_{2}\right)\right)^{2} & (3) \\ &=w^{T}\left(\mu_{1}-\mu_{2}\right)\left(\mu_{1}-\mu_{2}\right)^{T} w & (4) \end{aligned}
(wTμp1−wTμp2)2=(wT(N11i=1∑N1wTXiw)−wT(N21i=1∑N2wTXiw))2=(wT(wT(μ1−μ2)w))2=(wT(μ1−μ2))2=wT(μ1−μ2)(μ1−μ2)Tw(1)(2)(3)(4)
再来看下其中一类的协方差矩阵的部分:
(1)协方差矩阵的定义
(2)带入投影向量与投影的均值向量
(3)可以将公共的
w
w
w 的转置与
w
w
w 提出来,中间改写成样本点向量与样本点均值向量之差
(4)展开后一项的转置,将实数部分写到前面
(5)将两个实数相乘写成向量的乘法并将公共的
w
w
w 的转置与
w
w
w 提出来
(6)观察中括号中的部分,可以写成样本点的协方差矩阵的形式
σ
p
1
=
1
N
1
∑
i
=
1
N
1
(
p
i
−
μ
p
1
)
(
p
i
−
μ
p
1
)
T
(
1
)
=
1
N
1
∑
i
=
1
N
1
(
w
T
X
i
w
−
1
N
1
∑
j
=
1
N
1
w
T
X
j
w
)
(
w
T
X
i
w
−
1
N
1
∑
j
=
1
N
1
w
T
X
j
w
)
T
(
2
)
=
1
N
1
∑
i
=
1
N
1
(
w
T
(
X
i
−
μ
1
)
w
)
(
w
T
(
X
i
−
μ
1
)
w
)
T
(
3
)
=
1
N
1
∑
i
=
1
N
1
(
w
T
(
X
i
−
μ
1
)
)
(
w
T
(
X
i
−
μ
1
)
)
w
w
T
(
4
)
=
(
w
T
(
1
N
1
∑
i
=
1
N
1
(
X
i
−
μ
1
)
(
X
i
−
μ
1
)
T
)
w
)
w
w
T
(
5
)
=
w
T
σ
1
w
w
w
T
(
6
)
\begin{aligned} \sigma_{p_{1}} &=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left(p_{i}-\mu_{p_{1}}\right)\left(p_{i}-\mu_{p_{1}}\right)^{T} & (1)\\ &=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left(w^{T} X_{i} w-\frac{1}{N_{1}} \sum_{j=1}^{N_{1}} w^{T} X_{j} w\right)\left(w^{T} X_{i} w-\frac{1}{N_{1}} \sum_{j=1}^{N_{1}} w^{T} X_{j} w\right)^{T} & (2) \\ &=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left(w^{T}\left(X_{i}-\mu_{1}\right) w\right)\left(w^{T}\left(X_{i}-\mu_{1}\right) w\right)^{T} & (3) \\ &=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left(w^{T}\left(X_{i}-\mu_{1}\right)\right)\left(w^{T}\left(X_{i}-\mu_{1}\right)\right) w w^{T} & (4)\\ &=\left(w^{T}\left(\frac{1}{N_{1}} \sum_{i=1}^{N_{1}}\left(X_{i}-\mu_{1}\right)\left(X_{i}-\mu_{1}\right)^{T}\right) w\right) w w^{T} & (5)\\ &=w^{T} \sigma_{1} w w w^{T} & (6) \end{aligned}
σp1=N11i=1∑N1(pi−μp1)(pi−μp1)T=N11i=1∑N1(wTXiw−N11j=1∑N1wTXjw)(wTXiw−N11j=1∑N1wTXjw)T=N11i=1∑N1(wT(Xi−μ1)w)(wT(Xi−μ1)w)T=N11i=1∑N1(wT(Xi−μ1))(wT(Xi−μ1))wwT=(wT(N11i=1∑N1(Xi−μ1)(Xi−μ1)T)w)wwT=wTσ1wwwT(1)(2)(3)(4)(5)(6)
代价函数的分母部分:
(1)带入上式中协方差矩阵
(2)将实数部分提到前面,后面
w
w
w 为单位向量,与自己相乘为 1
(3)化简可得
(4)提出公共部分
w
T
σ
p
1
w
+
w
T
σ
p
2
w
=
w
T
(
w
T
σ
1
w
w
w
T
)
w
+
w
T
(
w
T
σ
2
w
w
w
T
)
w
(
1
)
=
w
T
σ
1
w
(
w
T
w
)
(
w
T
w
)
+
w
T
σ
2
w
(
w
T
w
)
(
w
T
w
)
(
2
)
=
w
T
σ
1
w
+
w
T
σ
2
w
(
3
)
=
w
T
(
σ
1
+
σ
2
)
w
(
4
)
\begin{aligned} w^{T} \sigma_{p_{1}} w+w^{T} \sigma_{p_{2}} w &=w^{T}\left(w^{T} \sigma_{1} w w w^{T}\right) w+w^{T}\left(w^{T} \sigma_{2} w w w^{T}\right) w & (1)\\ &=w^{T} \sigma_{1} w\left(w^{T} w\right)\left(w^{T} w\right)+w^{T} \sigma_{2} w\left(w^{T} w\right)\left(w^{T} w\right) & (2)\\ &=w^{T} \sigma_{1} w+w^{T} \sigma_{2} w & (3)\\ &=w^{T}\left(\sigma_{1}+\sigma_{2}\right) w & (4) \end{aligned}
wTσp1w+wTσp2w=wT(wTσ1wwwT)w+wT(wTσ2wwwT)w=wTσ1w(wTw)(wTw)+wTσ2w(wTw)(wTw)=wTσ1w+wTσ2w=wT(σ1+σ2)w(1)(2)(3)(4)
代价函数:
(1)代价函数的定义
(2)带入上面推出的分子分母部分
(3)使用
S
b
S_b
Sb、
S
w
S_w
Sw 来代替中间部分,得到新的代价函数
(4)其中
S
b
S_b
Sb 被称为"类间散度矩阵"(between-class scatter matrix)
(5)其中
S
w
S_w
Sw 被称为"类内散度矩阵"(within-class scatter matrix)
Cost
(
w
)
=
(
w
T
μ
p
1
−
w
T
μ
p
2
)
2
w
T
σ
p
1
w
+
w
T
σ
p
2
w
(
1
)
=
w
T
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
w
T
(
σ
1
+
σ
2
)
w
(
2
)
=
w
T
S
b
w
w
T
S
w
w
(
3
)
S
b
=
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
(
4
)
S
w
=
σ
1
+
σ
2
(
5
)
\begin{aligned} \operatorname{Cost}(w) &=\frac{\left(w^{T} \mu_{p_{1}}-w^{T} \mu_{p_{2}}\right)^{2}}{w^{T} \sigma_{p_{1}} w+w^{T} \sigma_{p_{2}} w} & (1)\\ &=\frac{w^{T}\left(\mu_{1}-\mu_{2}\right)\left(\mu_{1}-\mu_{2}\right)^{T} w}{w^{T}\left(\sigma_{1}+\sigma_{2}\right) w} & (2)\\ &=\frac{w^{T} S_{b} w}{w^{T} S_{w} w} & (3) \\ S_{b} &=\left(\mu_{1}-\mu_{2}\right)\left(\mu_{1}-\mu_{2}\right)^{T} & (4)\\ S_{w} &=\sigma_{1}+\sigma_{2} & (5) \end{aligned}
Cost(w)SbSw=wTσp1w+wTσp2w(wTμp1−wTμp2)2=wT(σ1+σ2)wwT(μ1−μ2)(μ1−μ2)Tw=wTSwwwTSbw=(μ1−μ2)(μ1−μ2)T=σ1+σ2(1)(2)(3)(4)(5)
代价函数最优化
(1)代价函数的新形式,为
S
b
S_b
Sb 与
S
w
S_w
Sw 的"广义瑞利商2(generalized Rayleigh quotient)"
(2)可以看到代价函数分子分母都是
w
w
w 的二次项,所以代价函数与
w
w
w 的长度无关,即缩放
w
w
w 不影响代价函数,不妨令分母为 1。可以将问题转化为当分母为 1 时,求分子前面加一个负号的最小值。
(3)可以运用拉格朗日乘数法3,引入一个新的变量
λ
λ
λ,可以将(2)式改写成新的形式
(4)对(3)式求偏导并令其等于零向量
(5)观察后发现
S
b
w
S_bw
Sbw 的方向恒为两类样本点的均值向量之差的方向,不妨令其为
λ
λ
λ 倍的两类样本点的均值向量之差
(6)这样就可以求出了
w
w
w 的方向
Cost ( w ) = w T S b w w T S w w ( 1 ) ⇒ min w − w T S b w s . t . w T S w w = 1 ( 2 ) L ( w , λ ) = − w T S b w + λ ( w T S w w − 1 ) ( 3 ) ∂ L ( w , λ ) ∂ w = − 2 S b w + 2 λ S w w = 0 ( 4 ) S b w = λ ( μ 1 − μ 2 ) ( 5 ) w = S w − 1 ( μ 1 − μ 2 ) ( 6 ) \begin{aligned} \operatorname{Cost}(w) &=\frac{w^{T} S_{b} w}{w^{T} S_{w} w} & (1)\\ \Rightarrow & \begin{aligned} \min _{w} \quad-w^{T} S_{b} w \\ s . t . \quad w^{T} S_{w} w=1 \end{aligned} & (2)\\ L(w, \lambda) &= -w^{T} S_{b} w+\lambda\left(w^{T} S_{w} w-1\right) & (3)\\ \frac{\partial L(w, \lambda)}{\partial w} &= -2 S_{b} w+2 \lambda S_{w} w=0 & (4)\\ S_{b} w &=\lambda\left(\mu_{1}-\mu_{2}\right) & (5)\\ w &=S_{w}^{-1}\left(\mu_{1}-\mu_{2}\right) & (6) \end{aligned} Cost(w)⇒L(w,λ)∂w∂L(w,λ)Sbww=wTSwwwTSbwwmin−wTSbws.t.wTSww=1=−wTSbw+λ(wTSww−1)=−2Sbw+2λSww=0=λ(μ1−μ2)=Sw−1(μ1−μ2)(1)(2)(3)(4)(5)(6)
四、算法步骤
线性判别分析的核心思想在前面也介绍过——“类内小、类间大”,按照最后求得的公式直接计算即可。
(1)分别计算每一类的均值向量
(2)分别计算每一类的协方差矩阵
(3)计算每类协方差矩阵之和的逆矩阵,可以使用 SVD 矩阵分解来简化求逆的复杂度
(4)带入公式求出权重系数
w
w
w
求新样本的分类时,只需判断新样本点离哪一个分类的均值向量更近,则新样本就是哪个分类,如下所示:
k
=
argmin
k
∣
w
T
x
−
w
T
μ
k
∣
k=\underset{k}{\operatorname{argmin}}\left|w^{T} x-w^{T} \mu_{k}\right|
k=kargmin∣∣wTx−wTμk∣∣
五、代码实现
使用 Python 实现线性判别分析(LDA):
def lda(X, y):
"""
线性判别分析(LDA)
args:
X - 训练数据集
y - 目标标签值
return:
w - 权重系数
"""
# 标签值
y_classes = np.unique(y)
# 第一类
c1 = X[y==y_classes[0]][:]
# 第二类
c2 = X[y==y_classes[1]][:]
# 第一类均值向量
mu1 = np.mean(c1, axis=0)
# 第二类均值向量
mu2 = np.mean(c2, axis=0)
sigma1 = c1 - mu1
# 第一类协方差矩阵
sigma1 = sigma1.T.dot(sigma1) / c1.shape[0]
sigma2 = c2 - mu2
# 第二类协方差矩阵
sigma2 = sigma2.T.dot(sigma2) / c2.shape[0]
# 求权重系数
return np.linalg.pinv(sigma1 + sigma2).dot(mu1 - mu2), mu1, mu2
def discriminant(X, w, mu1, mu2):
"""
判别新样本点
args:
X - 训练数据集
w - 权重系数
mu1 - 第一类均值向量
mu2 - 第二类均值向量
return:
分类结果
"""
a = np.abs(X.dot(w) - mu1.dot(w))
b = np.abs(X.dot(w) - mu2.dot(w))
return np.argmin(np.array([a, b]), axis=0)
六、第三方库实现
scikit-learn4 实现线性判别分析:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 初始化线性判别分析器
lda = LinearDiscriminantAnalysis()
# 拟合线性模型
lda.fit(X, y)
# 权重系数
w = lda.coef_
# 截距
b = lda.intercept_
如果你使用 sklearn 提供的线性判别分析的方法,会发现求解出来的结果与上面自己实现的结果不同,这是因为 sklearn 使用的是另一种方法,并有没使用广义瑞利商的形式,而是从概率分布的角度来做分类,后面一节再来介绍该方法。
七、示例演示
下图展示了存在二种分类时的演示数据,其中红色表示标签值为 0 的样本、蓝色表示标签值为 1 的样本:
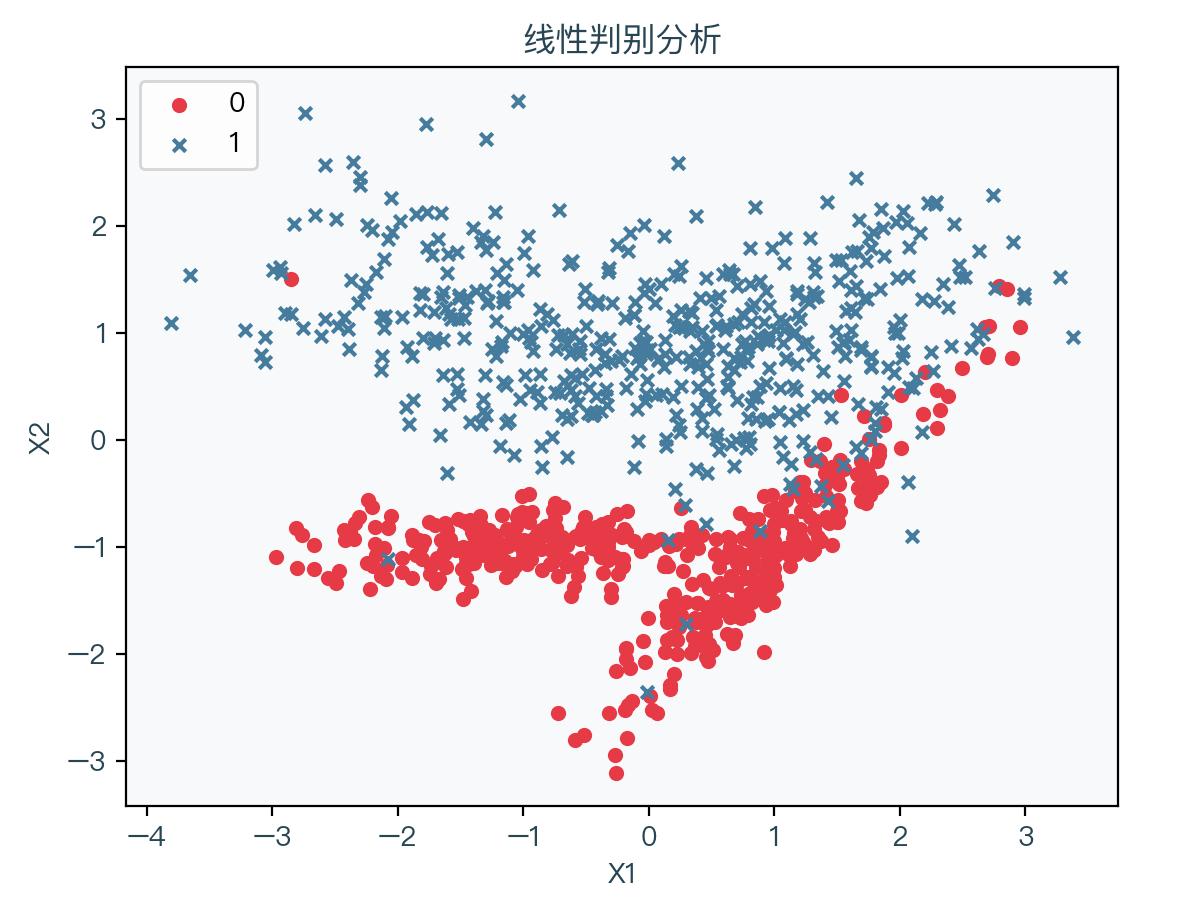
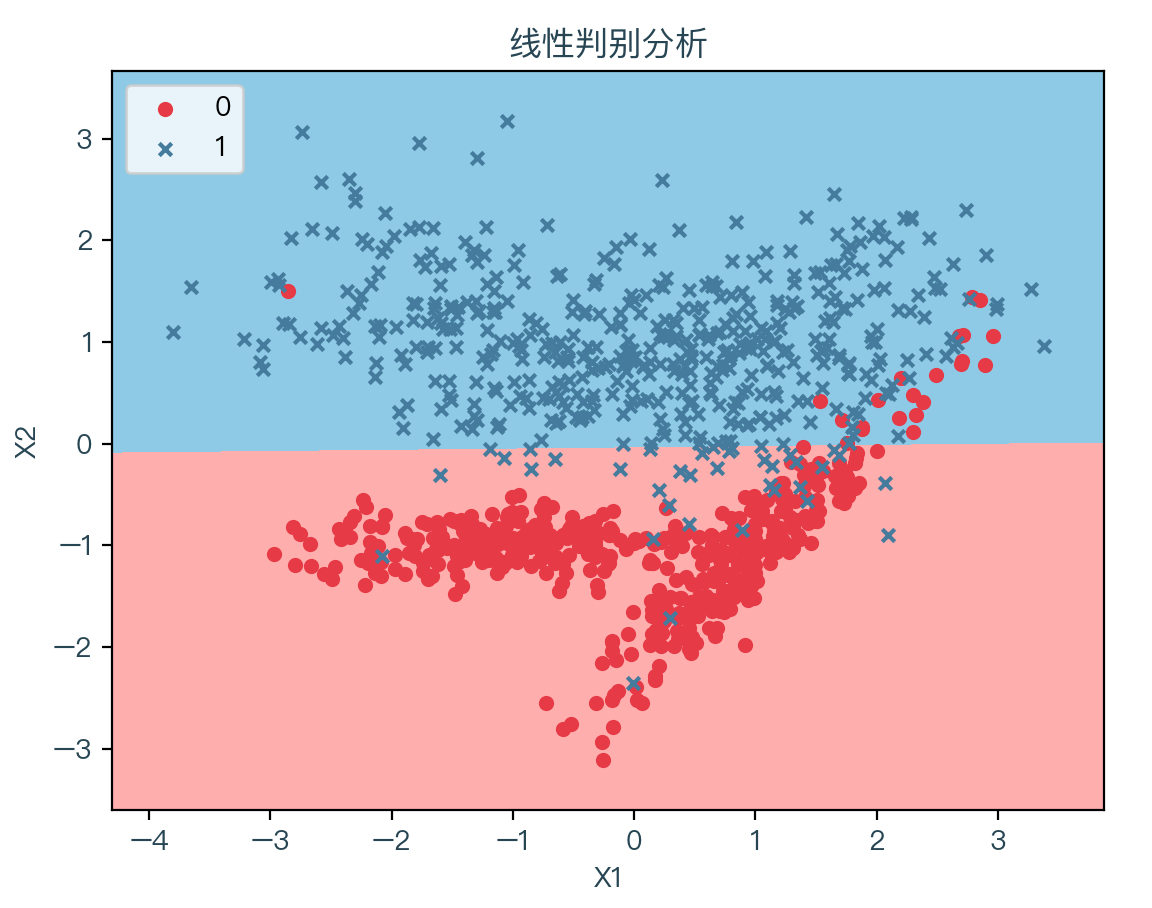
下图为拟合数据的结果,其中浅红色表示拟合后根据权重系数计算出预测值为 0 的部分,浅蓝色表示拟合后根据权重系数计算出预测值为 1 的部分:
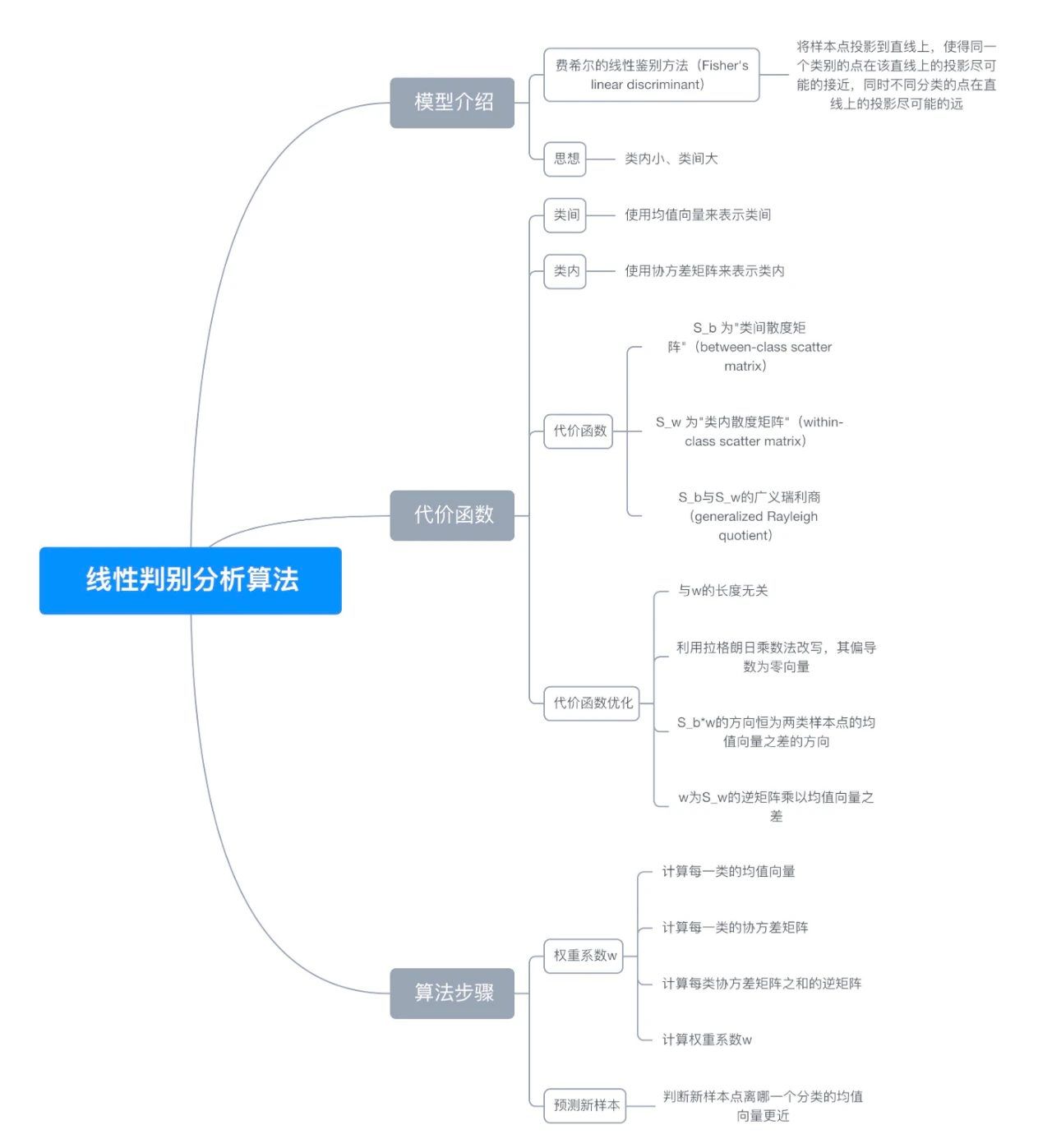
八、思维导图
九、参考文献
- https://en.wikipedia.org/wiki/Linear_discriminant_analysis
- https://en.wikipedia.org/wiki/Rayleigh_quotient
- https://en.wikipedia.org/wiki/Lagrange_multiplier
- https://scikit-learn.org/stable/modules/generated/sklearn.discriminant_analysis.LinearDiscriminantAnalysis.html
完整演示请点击这里
注:本文力求准确并通俗易懂,但由于笔者也是初学者,水平有限,如文中存在错误或遗漏之处,恳请读者通过留言的方式批评指正
本文首发于——AI导图,欢迎关注















 6145
6145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









