







阅读本文需要的背景知识点:一丢丢编程知识
一、引言
前面几节介绍了一类分类算法——线性判别分析、二次判别分析,接下来介绍另一类分类算法——朴素贝叶斯分类算法1 (Naive Bayes Classifier Algorithm/NB)。朴素贝叶斯分类算法在文本分类和自动医疗诊断的领域中有应用到。
二、模型介绍
条件独立2
在学习朴素贝叶斯分类算法之前,先来看下在概率论中的一个概念——条件独立(conditional independence)
两个随机变量 X 和 Y 在给定第三个随机变量 Z 的情况下条件独立当且仅当它们在给定 Z 时的条件概率分布互相独立,也就是说,给定Z的任一值,X 的概率分布和Y的值无关,Y 的概率分布也和X的值无关。
根据维基百科中给出的定义,可以表示为如下式子:
P ( X , Y ∣ Z ) = P ( X ∣ Z ) P ( Y ∣ Z ) P(X, Y \mid Z)=P(X \mid Z) P(Y \mid Z) P(X,Y∣Z)=P(X∣Z)P(Y∣Z)
同时上式又等价于下式,在(1)中Y对 X 的条件概率没有影响,同理在(2)中 X 对 Y 的条件概率也没有影响:
P ( X ∣ Y , Z ) = P ( X ∣ Z ) P ( Y ∣ X , Z ) = P ( Y ∣ Z ) \begin{aligned} P(X \mid Y, Z)=P(X \mid Z) \\ P(Y \mid X, Z)=P(Y \mid Z) \end{aligned} P(X∣Y,Z)=P(X∣Z)P(Y∣X,Z)=P(Y∣Z)
朴素贝叶斯分类
同概率分布角度的判别分析一样,也是使用最大后验概率估计。朴素贝叶斯分类算法有一个前提条件——假设各特征变量之间是条件独立的,这也是被称为“朴素”的原因。
(1)假设函数表达式
(2)改写一下,特征变量 x 为 p 维
(3)用贝叶斯定理变换一下
(4)由于分母对最后的结果不影响,不依赖与分类,可以认为是一个常数
(5)根据假设各特征变量之间是条件独立的,所以可以改写成乘积的形式
(6)用连乘符号简化一下
h ( x ) = argmax k P ( k ∣ x ) ( 1 ) = argmax k P ( k ∣ x 1 , x 2 , … , x p ) ( 2 ) = argmax k P ( k ) P ( x 1 , x 2 , … , x p ∣ k ) P ( x 1 , x 2 , … , x p ) ( 3 ) = argmax k P ( k ) P ( x 1 , x 2 , … , x p ∣ k ) ( 4 ) = argmax k P ( k ) P ( x 1 ∣ k ) P ( x 2 ∣ k ) … P ( x p ∣ k ) ( 5 ) = argmax k P ( k ) ∏ i = 1 p P ( x i ∣ k ) ( 6 ) \begin{aligned} h(x) &=\underset{k}{\operatorname{argmax}} P(k \mid x) & (1) \\ &=\underset{k}{\operatorname{argmax}} P\left(k \mid x_{1}, x_{2}, \ldots, x_{p}\right) & (2) \\ &=\underset{k}{\operatorname{argmax}} \frac{P(k) P\left(x_{1}, x_{2}, \ldots, x_{p} \mid k\right)}{P\left(x_{1}, x_{2}, \ldots, x_{p}\right)} & (3) \\ &=\underset{k}{\operatorname{argmax}} P(k) P\left(x_{1}, x_{2}, \ldots, x_{p} \mid k\right) & (4) \\ &=\underset{k}{\operatorname{argmax}} P(k) P\left(x_{1} \mid k\right) P\left(x_{2} \mid k\right) \ldots P\left(x_{p} \mid k\right) & (5) \\ &=\underset{k}{\operatorname{argmax}} P(k) \prod_{i=1}^{p} P\left(x_{i} \mid k\right) & (6) \end{aligned} h(x)=kargmaxP(k∣x)=kargmaxP(k∣x1,x2,…,xp)=kargmaxP(x1,x2,…,xp)P(k)P(x1,x2,…,xp∣k)=kargmaxP(k)P(x1,x2,…,xp∣k)=kargmaxP(k)P(x1∣k)P(x2∣k)…P(xp∣k)=kargmaxP(k)i=1∏pP(xi∣k)(1)(2)(3)(4)(5)(6)
最后就得到了朴素贝叶斯分类的概率模型,针对不同的概率分布可以得到不同的朴素贝叶斯分类方法。常见的算法包括:多项式朴素贝叶斯分类、高斯朴素贝叶斯分类、伯努利朴素贝叶斯分类等。
样本数据
假设有如下水果的样本数据集,特征分别为形状(圆、椭圆),颜色(红色、绿色),大小(大、中、小),甜度(甜、不甜),水果分三类:苹果、葡萄、西瓜。
| 形状 | 颜色 | 大小 | 甜度 | 水果 |
|---|---|---|---|---|
| 圆 | 红色 | 中 | 不甜 | 苹果 |
| 椭圆 | 绿色 | 小 | 甜 | 葡萄 |
| 圆 | 红色 | 中 | 不甜 | 葡萄 |
| 圆 | 红色 | 小 | 甜 | 葡萄 |
| 椭圆 | 绿色 | 中 | 甜 | 西瓜 |
| 圆 | 绿色 | 中 | 不甜 | 苹果 |
| 椭圆 | 绿色 | 小 | 甜 | 葡萄 |
| 圆 | 绿色 | 大 | 甜 | 西瓜 |
| 圆 | 红色 | 中 | 甜 | 苹果 |
| 椭圆 | 绿色 | 中 | 不甜 | 西瓜 |
假设现在我们有一个形状为圆,颜色为绿色、大小为中、甜度为甜的样本数据,应该被分成哪一类?
多项式朴素贝叶斯分类
多项式朴素贝叶斯分类是假设样本服从多项式分布3(multinomial distribution),是通过特征出现的频率来估计特征的概率,根据大数定律4 (law of large numbers),当样本数据越多,事件出现的频率趋于稳定后,频率即为事件的概率。
分类为 k 的概率可以通过分类 k 在所有样本中出现的频率来估计,即分类为k的样本数 N_k 除以总样本数 N。在分类为 k 时,第 i 个特征为 x_i 的概率等于分类为 k 并且特征为 x_i 的样本数除以分类为 k 的样本数 N_k,数学表达式如下:
P ( k ) = N k N P ( x i ∣ k ) = N k x i N k \begin{aligned} P(k) &=\frac{N_{k}}{N} \\ P\left(x_{i} \mid k\right) &=\frac{N_{k x_{i}}}{N_{k}} \end{aligned} P(k)P(xi∣k)=NNk=NkNkxi
例如用上面的样本数据来计算当分类为西瓜时,甜度为甜的频率如下:
P ( 甜度 = 甜 ∣ 水果 = 西瓜 ) = 2 3 P(\text { 甜度 }=\text { 甜 } \mid \text { 水果 }=\text { 西瓜 })=\frac{2}{3} P( 甜度 = 甜 ∣ 水果 = 西瓜 )=32
接下来我们来解决上面的样本数据的问题,分别使用多项式朴素贝叶斯分类来求出苹果、葡萄、西瓜在上述条件下的概率:
P ( 苹 果 ∣ 圆 , 绿 色 , 中 , 甜 ) ∝ P ( 苹 果 ) × P ( 圆 苹 果 ) × P ( 绿 色 ∣ 苹 果 ) × P ( 中 ∣ 苹 果 ) × P ( 甜 ∣ 苹 果 ) ∝ 3 10 × 3 3 × 1 3 × 3 3 × 1 3 ∝ 1 30 ≈ 0.033333 P ( 葡 萄 ∣ 圆 , 绿 色 , 中 , 甜 ) ∝ P ( 葡 萄 ) × P ( 圆 ∣ 葡 萄 ) × P ( 绿 色 ∣ 葡 萄 ) × P ( 中 ∣ 葡 萄 ) × P ( 甜 ∣ 葡 萄 ) ∝ 4 10 × 2 4 × 2 4 × 1 4 × 3 4 ∝ 3 160 ≈ 0.01875 P ( 西 瓜 ∣ 圆 , 绿 色 , 中 , 甜 ) ∝ P ( 西 瓜 ) × P ( 圆 ∣ 西 瓜 ) × P ( 绿 色 ∣ 西 瓜 ) × P ( 中 ∣ 西 瓜 ) × P ( 甜 ∣ 西 瓜 ) ∝ 3 10 × 1 3 × 3 3 × 2 3 × 2 3 ∝ 2 45 ≈ 0.044444 \begin{aligned} P( 苹果 \mid 圆, 绿色, 中, 甜 ) &\propto P( 苹果 ) \times P( 圆 苹果 ) \times P( 绿色 \mid 苹果 ) \times P( 中 \mid 苹果 ) \times P( 甜 \mid 苹果 ) \\ &\propto \frac{3}{10} \times \frac{3}{3} \times \frac{1}{3} \times \frac{3}{3} \times \frac{1}{3} \\ &\propto \frac{1}{30} \approx 0.033333 \\ P( 葡萄 \mid 圆, 绿色, 中, 甜 ) &\propto P( 葡萄 ) \times P( 圆 \mid 葡萄 ) \times P( 绿色 \mid 葡萄 ) \times P( 中 \mid 葡萄 ) \times P( 甜 \mid 葡萄 ) \\ &\propto \frac{4}{10} \times \frac{2}{4} \times \frac{2}{4} \times \frac{1}{4} \times \frac{3}{4} \\ &\propto \frac{3}{160} \approx 0.01875 \\ P( 西瓜|圆, 绿色, 中,甜 ) &\propto P( 西瓜 ) \times P( 圆 \mid 西瓜 ) \times P( 绿色|西瓜 ) \times P( 中 \mid 西瓜 ) \times P( 甜|西瓜 ) \\ &\propto \frac{3}{10} \times \frac{1}{3} \times \frac{3}{3} \times \frac{2}{3} \times \frac{2}{3} \\ &\propto \frac{2}{45} \approx 0.044444 \end{aligned} P(苹果∣圆,绿色,中,甜)P(葡萄∣圆,绿色,中,甜)P(西瓜∣圆,绿色,中,甜)∝P(苹果)×P(圆苹果)×P(绿色∣苹果)×P(中∣苹果)×P(甜∣苹果)∝103×33×31×33×31∝301≈0.033333∝P(葡萄)×P(圆∣葡萄)×P(绿色∣葡萄)×P(中∣葡萄)×P(甜∣葡萄)∝104×42×42×41×43∝1603≈0.01875∝P(西瓜)×P(圆∣西瓜)×P(绿色∣西瓜)×P(中∣西瓜)×P(甜∣西瓜)∝103×31×33×32×32∝452≈0.044444
可以看到最后的结果是 P(西瓜|圆,绿色,中,甜)最大,所以形状为圆,颜色为绿色、大小为中、甜度为甜的样本数据应该被分为西瓜。
上面的结果看上去似乎没什么问题,但当一种特征中某个分类下没有出现过,例如分类为西瓜时颜色为红色、分类为葡萄时大小为大的情况下,会发现用上面的方式计算出的概率为零,这会使得最后的后验概率也等于零。
P ( 颜色 = 红色 ∣ 水果 = 西瓜 ) = 0 3 = 0 P(\text { 颜色 }=\text { 红色 } \mid \text { 水果 }=\text { 西瓜 })=\frac{0}{3}=0 P( 颜色 = 红色 ∣ 水果 = 西瓜 )=30=0
那么如何解决这个问题呢?这里可以对数据做平滑处理,在计算频率时引入一个平滑参数来避免计算中出现 0 的问题,数学表达式如下:
P ( k ) = N k + α N + M α P ( x i ∣ k ) = N k x i + α N k + M i α \begin{aligned} P(k) &=\frac{N_{k}+\alpha}{N+M \alpha} \\ P\left(x_{i} \mid k\right) &=\frac{N_{k x_{i}}+\alpha}{N_{k}+M_{i} \alpha} \end{aligned} P(k)P(xi∣k)=N+MαNk+α=Nk+MiαNkxi+α
其中 α 为平滑参数,M 为分类的数量,M_i 为第 i 个特征的类型数量,在上面水果的例子中,水果有苹果、葡萄、西瓜三种,所以 M=3,特征形状有圆、椭圆两种,所以 M_1=2,依此类推。
该方式被称为拉普拉斯平滑5(Laplace smoothing)。当样本数足够多时,即 N >> M,这种平滑处理对结果的影响较小。
同上面一样,分别使用多项式朴素贝叶斯分类来求出苹果、葡萄、西瓜在上述条件下的概率,这次加上拉普拉斯平滑处理:
P ( 苹 果 ∣ 圆 , 绿 色 , 中 , 甜 ) ∝ P ( 苹 果 ) × P ( 圆 苹 果 ) × P ( 绿 色 ∣ 苹 果 ) × P ( 中 ∣ 苹 果 ) × P ( 甜 ∣ 苹 果 ) ∝ 4 13 × 4 5 × 2 5 × 4 6 × 2 5 ∝ 128 4875 ≈ 0.026256 P ( 葡 萄 ∣ 圆 , 绿 色 , 中 , 甜 ) ∝ P ( 葡 萄 ) × P ( 圆 ∣ 葡 萄 ) × P ( 绿 色 ∣ 葡 萄 ) × P ( 中 ∣ 葡 萄 ) × P ( 甜 ∣ 葡 萄 ) ∝ 5 13 × 3 6 × 3 6 × 2 7 × 4 6 ∝ 5 273 ≈ 0.018315 P ( 西 瓜 ∣ 圆 , 绿 色 , 中 , 甜 ) ∝ P ( 西 瓜 ) × P ( 圆 ∣ 西 瓜 ) × P ( 绿 色 ∣ 西 瓜 ) × P ( 中 ∣ 西 瓜 ) × P ( 甜 ∣ 西 瓜 ) ∝ 4 13 × 2 5 × 4 5 × 3 6 × 3 5 ∝ 48 1625 ≈ 0.029538 \begin{aligned} P( 苹果 \mid 圆, 绿色, 中, 甜 ) &\propto P( 苹果 ) \times P( 圆 苹果 ) \times P( 绿色|苹果 ) \times P( 中 \mid 苹果 ) \times P( 甜 \mid 苹果 ) \\ &\propto \frac{4}{13} \times \frac{4}{5} \times \frac{2}{5} \times \frac{4}{6} \times \frac{2}{5} \\ &\propto \frac{128}{4875} \approx 0.026256 P( 葡萄 \mid 圆, 绿色, 中, 甜 ) &\propto P( 葡萄 ) \times P( 圆 \mid 葡萄 ) \times P( 绿色 \mid 葡萄 ) \times P( 中 \mid 葡萄 ) \times P( 甜 \mid 葡萄 ) \\ &\propto \frac{5}{13} \times \frac{3}{6} \times \frac{3}{6} \times \frac{2}{7} \times \frac{4}{6} \\ &\propto \frac{5}{273} \approx 0.018315 P( 西瓜 \mid 圆, 绿色, 中, 甜 ) &\propto P( 西瓜 ) \times P( 圆 \mid 西瓜 ) \times P( 绿色 \mid 西瓜 ) \times P( 中 \mid 西瓜 ) \times P( 甜 \mid 西瓜 ) \\ &\propto \frac{4}{13} \times \frac{2}{5} \times \frac{4}{5} \times \frac{3}{6} \times \frac{3}{5} \\ &\propto \frac{48}{1625} \approx 0.029538 \end{aligned} P(苹果∣圆,绿色,中,甜)∝P(苹果)×P(圆苹果)×P(绿色∣苹果)×P(中∣苹果)×P(甜∣苹果)∝134×54×52×64×52∝4875128≈0.026256P(葡萄∣圆,绿色,中,甜)∝135×63×63×72×64∝2735≈0.018315P(西瓜∣圆,绿色,中,甜)∝134×52×54×63×53∝162548≈0.029538∝P(葡萄)×P(圆∣葡萄)×P(绿色∣葡萄)×P(中∣葡萄)×P(甜∣葡萄)∝P(西瓜)×P(圆∣西瓜)×P(绿色∣西瓜)×P(中∣西瓜)×P(甜∣西瓜)
最后的结果与前面的一致,该样本数据应该被分为西瓜。为了避免连乘在计算时存在精确度的问题,一般实现时都会改成将条件概率估计取对数后连加。
伯努利朴素贝叶斯分类
伯努利朴素贝叶斯分类是假设样本数据服从伯努利分布6 (Bernoulli distribution),该分类同多项式朴素贝叶斯分类一样适用于离散特征,不同点是伯努利分布的取值只能为 0、1,例如水果甜与不甜,硬币正反面等,当特征的取值多于两类时,需要对其进行二值化操作。
伯努利朴素贝叶斯分类使用如下式中的规则,可以看到相比于多项式朴素贝叶斯分类,未出现的特征也会被加上,而多项式朴素贝叶斯分类会忽略未出现的特征。
P ( X i ∣ y ) = P ( i ∣ y ) x i + ( 1 − P ( i ∣ y ) ) ( 1 − x i ) P\left(X_{i} \mid y\right)=P(i \mid y) x_{i}+(1-P(i \mid y))\left(1-x_{i}\right) P(Xi∣y)=P(i∣y)xi+(1−P(i∣y))(1−xi)
高斯朴素贝叶斯分类
可以看到多项式朴素贝叶斯分类更善于处理如上面水果例子一样的离散特征,当样本的特征是连续的,例如身高、体重时,可能使用高斯朴素贝叶斯分类来处理更合适一些。
高斯朴素贝叶斯分类顾名思义是假设样本数据服从正太分布(Normal distribution)或者也叫作高斯分布(Gaussian distribution),计算出对应分类下每个特征的方差与均值,利用正态分布的概率密度函数,估计对应的概率值。
f ( x ; μ ; σ ) = 1 σ 2 π exp ( − ( x − μ ) 2 2 σ 2 ) f(x ; \mu ; \sigma)=\frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right) f(x;μ;σ)=σ2π1exp(−2σ2(x−μ)2)
三、代码实现
使用 Python 实现多项式朴素贝叶斯分类:
import numpy as np
def mnb(X, y, alpha = 1):
"""
多项式朴素贝叶斯分类
args:
X - 训练数据集
y - 目标标签值
alpha - 平滑参数
return:
priors - 先验概率的对数
pss - 每种特征对应每种标签分类的条件概率的对数
x_classes - 特征分类
y_classes - 标签分类
"""
# 标签分类、每类数量
y_classes, y_counts = np.unique(y, return_counts=True)
y_counts += alpha
# 先验概率
priors = np.log(y_counts / np.sum(y_counts))
# 每种特征对应每种标签分类的条件概率的对数
pss = []
# 特征分类
x_classes = []
for idx in range(X.shape[1]):
# 第 idx 个特征
x_idx = X[:, idx]
# 第 idx 个特征分类、每类数量
x_idx_classes, x_idx_counts = np.unique(x_idx, return_counts=True)
x_classes.append(x_idx_classes)
# 第 idx 个特征对应每种标签分类的条件概率的对数
ps = []
for jdx in range(len(y_classes)):
# 第 idx 个特征对应第 jdx 个标签分类的分类、每类数量
x_jdx_classes, x_jdx_counts = np.unique(x_idx[y==y_classes[jdx]], return_counts=True)
# 第 idx 个特征对应第 jdx 个标签分类的条件概率的对数
p = []
for kdx in range(len(x_idx_classes)):
# 同时满足特征与标签的下标
idxs = np.where(x_jdx_classes == x_idx_classes[kdx])[0]
# 平滑后的分子
a = alpha
if (len(idxs) != 0):
a = x_jdx_counts[idxs[0]] + alpha
# 平滑后的分母
b = np.sum(x_jdx_counts) + len(x_idx_classes) * alpha
p.append(np.log(a/b))
ps.append(np.array(p))
pss.append(np.array(ps))
return priors, pss, x_classes, y_classes
def predict(X, priors, pss, x_classes, y_classes):
"""
预测
args:
X - 数据集
priors - 先验概率的对数
pss - 每种特征对应每种标签分类的条件概率的对数
x_classes - 特征分类
y_classes - 标签分类
return:
预测结果
"""
ys = []
for idx in range(X.shape[0]):
y = np.array(priors)
for jdx in range(X.shape[1]):
for kdx in range(len(y_classes)):
y[kdx] = y[kdx] + pss[jdx][kdx][x_classes[jdx] == X[idx][jdx]]
ys.append(y)
return y_classes[np.argmax(ys, axis=1)]
使用 Python 实现高斯朴素贝叶斯分类:
import numpy as np
def gnb(X, y):
"""
高斯朴素贝叶斯分类
args:
X - 训练数据集
y - 目标标签值
alpha - 平滑参数
return:
priors - 先验概率的对数
means - 均值向量
stds - 标准差向量
y_classes - 标签分类
"""
# 标签分类、每类数量
y_classes, y_counts = np.unique(y, return_counts=True)
# 先验概率
priors = np.log(y_counts / np.sum(y_counts))
# 均值向量
means = []
# 标准差向量
stds = []
for y_class in y_classes:
x = X[y==y_class][:]
means.append(np.mean(x, axis=0))
stds.append(np.std(x, axis=0))
return priors, means, stds, y_classes
def predict(X, priors, means, stds, y_classes):
"""
预测
args:
X - 数据集
priors - 先验概率的对数
means - 均值向量
stds - 标准差向量
y_classes - 标签分类
return:
预测结果
"""
ys = []
for kdx in range(len(y_classes)):
ys.append(np.sum(np.log(normal(X, means[kdx], stds[kdx])), axis=1) + priors[kdx])
return y_classes[np.argmax(ys, axis=0)]
def normal(x, mean, std):
"""
正态分布概率密度函数
args:
x - 特征值
mean - 均值
std - 标准差
return:
概率估计
"""
exponent = np.exp(-(np.power(x - mean, 2) / (2 * np.power(std, 2))))
return (1 / (np.sqrt(2 * np.pi) * std)) * exponent
四、第三方库实现
scikit-learn7 实现多项式朴素贝叶斯分类:
from sklearn.naive_bayes import MultinomialNB
# 初始化多项式朴素贝叶斯分类器
mnb = MultinomialNB()
# 拟合数据
mnb.fit(X, y)
# 预测
mnb.predict(X)
scikit-learn8 实现伯努利朴素贝叶斯分类:
from sklearn.naive_bayes import BernoulliNB
# 初始化伯努利朴素贝叶斯分类器
bnb = BernoulliNB()
# 拟合数据
bnb.fit(X, y)
# 预测
bnb.predict(X)
scikit-learn9 实现高斯朴素贝叶斯分类:
from sklearn.naive_bayes import GaussianNB
# 初始化高斯朴素贝叶斯分类器
gnb = GaussianNB()
# 拟合数据
gnb.fit(X, y)
# 预测
gnb.predict(X)
在scikit-learn实现中还存在几种其他的朴素贝叶斯分类10:补充朴素贝叶斯分类、类别朴素贝叶斯分类等,基本上都是对上述朴素贝叶斯分类的优化版本,具体方式可以参看对应的实现。
五、动画展示
下图依然使用上几节的二分类演示数据,其中红色表示标签值为 0 的样本、蓝色表示标签值为 1 的样本:
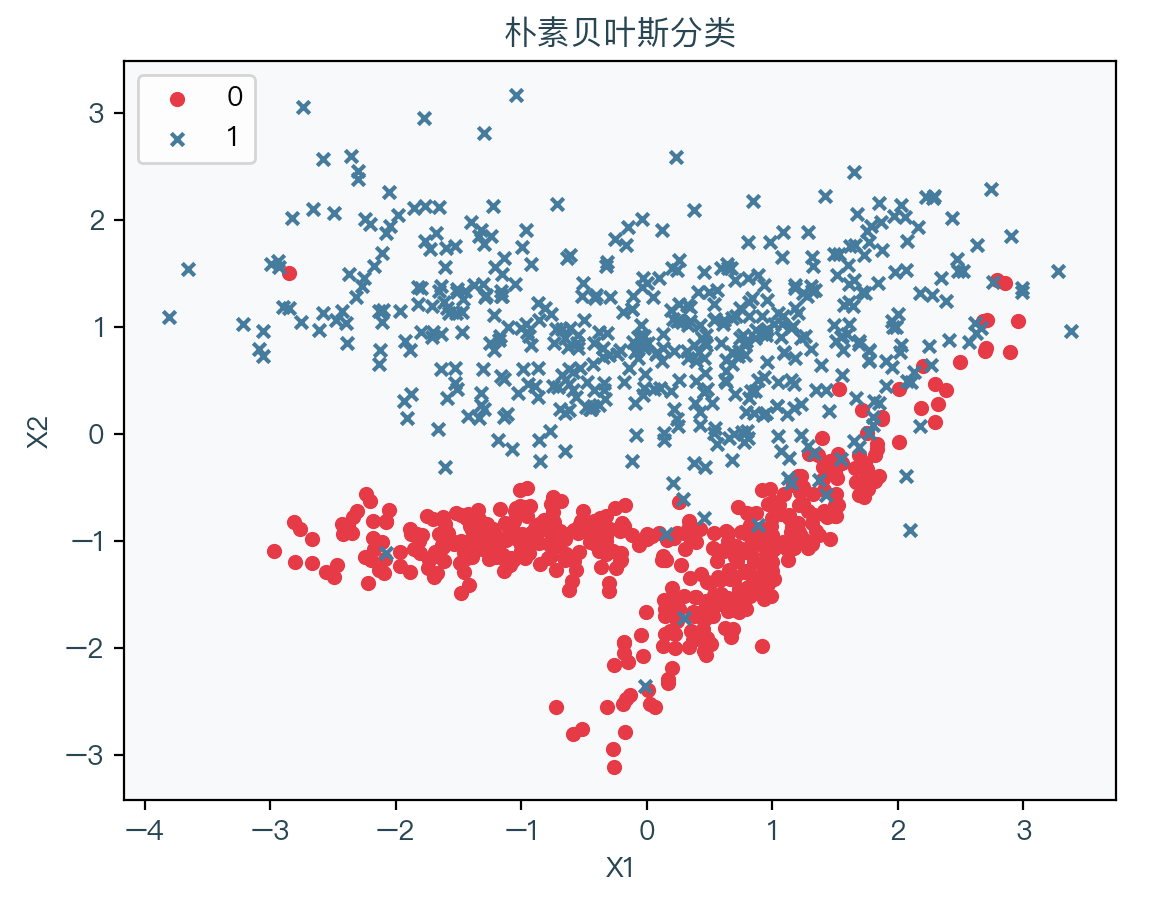
下图展示了使用高斯朴素贝叶斯分类拟合数据的结果,其中浅红色表示拟合后根据权重系数计算出预测值为0的部分,浅蓝色表示拟合后根据权重系数计算出预测值为1的部分:
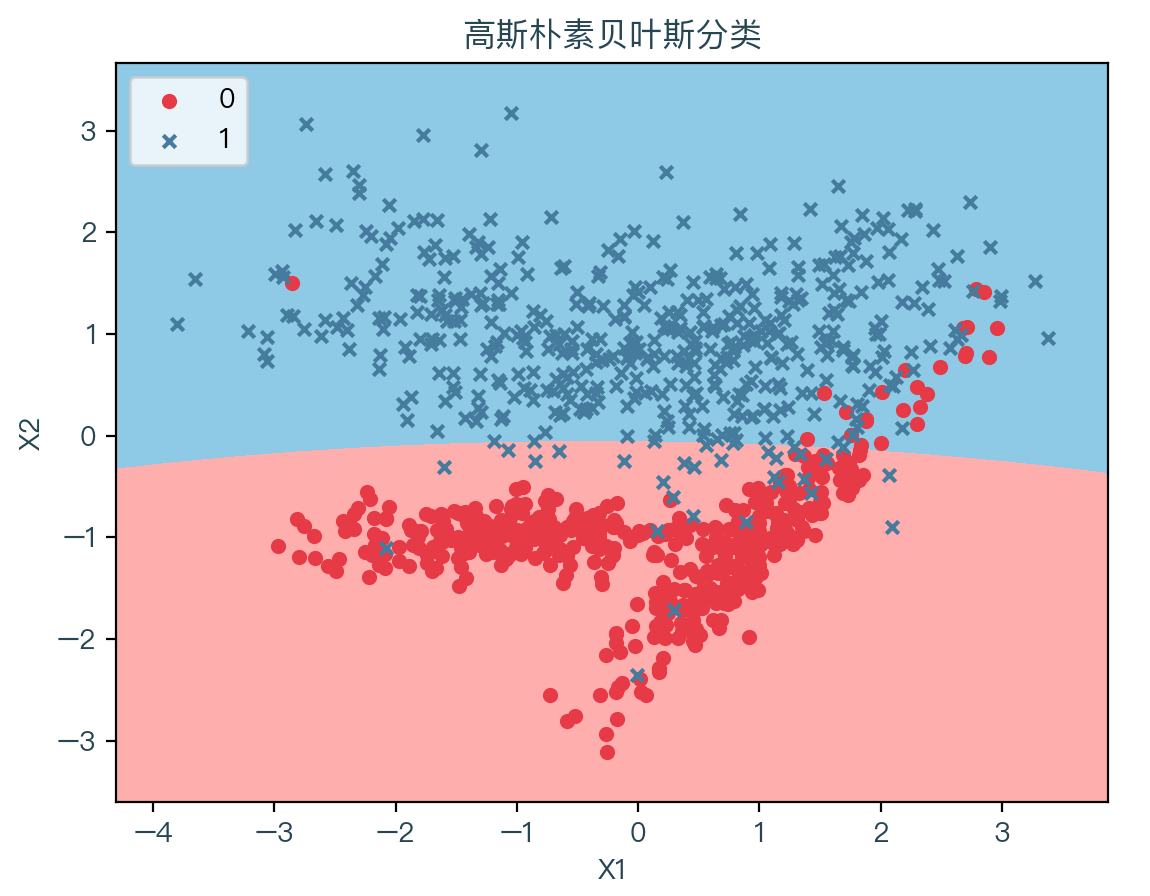
回忆一下二次判别分析一节中最后的结果,会发现结果是一致的。这说明在二次判别分析模型中,假设协方差矩阵是对角矩阵,在每个类中,输入都是条件独立的,那么所得到的分类器等价于高斯朴素贝叶斯分类器11。
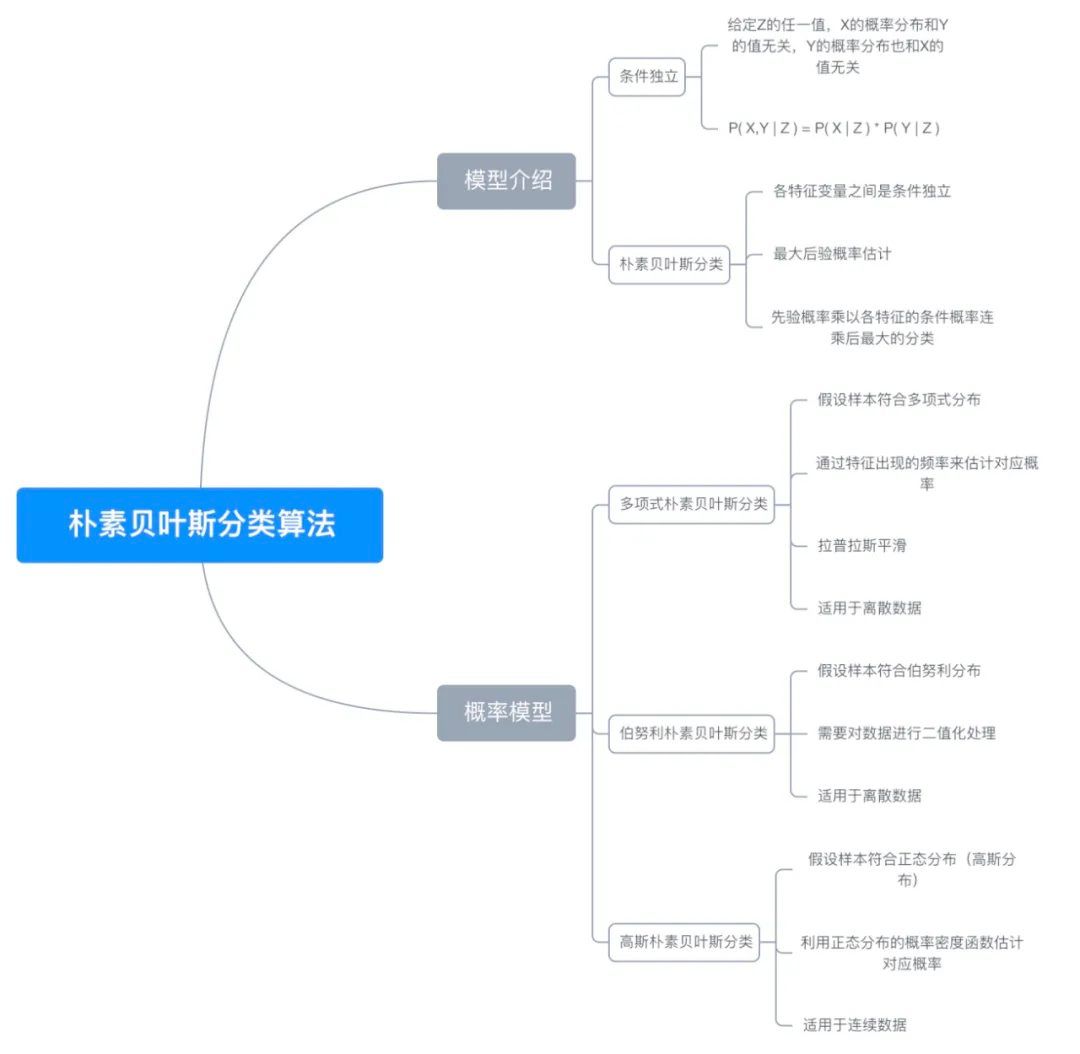
六、思维导图
七、参考文献
- https://en.wikipedia.org/wiki/Naive_Bayes_classifier
- https://en.wikipedia.org/wiki/Conditional_independence
- https://en.wikipedia.org/wiki/Multinomial_distribution
- https://en.wikipedia.org/wiki/Law_of_large_numbers
- https://en.wikipedia.org/wiki/Additive_smoothing
- https://en.wikipedia.org/wiki/Bernoulli_distribution
- https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html
- https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.BernoulliNB.html
- https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
- https://scikit-learn.org/stable/modules/naive_bayes.html
- https://scikit-learn.org/stable/modules/lda_qda.html#qda
完整演示请点击这里
注:本文力求准确并通俗易懂,但由于笔者也是初学者,水平有限,如文中存在错误或遗漏之处,恳请读者通过留言的方式批评指正
本文首发于——AI导图,欢迎关注

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









