







内容都是百度AIstudio的内容,我只是在这里做个笔记,不是原创。
数据集回顾
在进行数据处理前,我们先回顾下本章使用的ml-1m电影推荐数据集。
ml-1m是GroupLens Research从MovieLens网站上收集并提供的电影评分数据集。包含了6000多位用户对近3900个电影的共100万条评分数据,评分均为1~5的整数,其中每个电影的评分数据至少有20条。该数据集包含三个数据文件,分别是:
- users.dat,存储用户属性信息的文本格式文件。
- movies.dat,存储电影属性信息的文本格式文件。
- ratings.dat, 存储电影评分信息的文本格式文件。
电影海报图像在posters文件夹下,海报图像的名字以"mov_id" + 电影ID + ".png"的方式命名。由于这里的电影海报图像有缺失,我们整理了一个新的评分数据文件,新的文件中包含的电影均是有海报数据的,因此,本次实验使用的数据集在ml-1m基础上增加了两份数据:
- posters/ , 包含电影海报图像。
- new_rating.txt, 存储包含海报图像的新评分数据文件。
数据处理流程
在计算机视觉和自然语言处理章节中,我们已经了解到数据处理是算法应用的前提,并掌握了图像数据处理和自然语言数据处理的方法。总结一下,数据处理就是将人类容易理解的图像文本数据,转换为机器容易理解的数字形式,把离散的数据转为连续的数据。在推荐算法中,这些数据处理方法也是通用的。
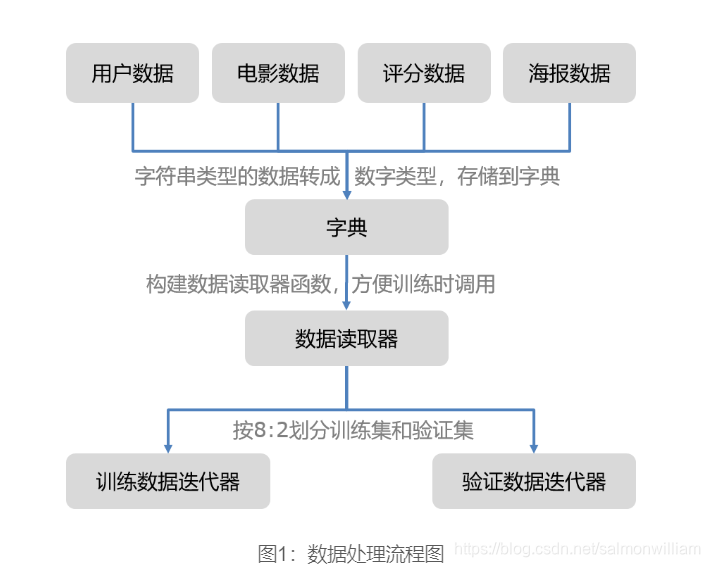
本次实验中,数据处理一共包含如下六步:
- 读取用户数据,存储到字典
- 读取电影数据,存储到字典
- 读取评分数据,存储到字典
- 读取海报数据,存储到字典
- 将各个字典中的数据拼接,形成数据读取器
- 划分训练集和验证集,生成迭代器,每次提供一个批次的数据
流程如下图所示。
用户数据文件user.dat中的数据格式为:UserID::Gender::Age::Occupation::Zip-code。
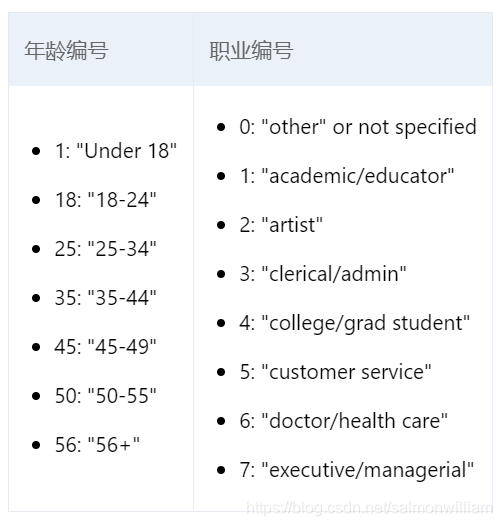

比如82::M::25::17::48380表示ID为82的用户,性别为男,年龄为25-34岁,职业technician/engineer。
至此,我们完成了用户数据的处理,完整的代码如下:
import numpy as np
def get_usr_info(path):
# 性别转换函数,M-0, F-1
def gender2num(gender):
return 1 if gender == 'F' else 0
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 建立用户信息的字典
use_info = {}
max_usr_id = 0
#按行索引数据
for item in data:
# 去除每一行中和数据无关的部分
item = item.strip().split("::")
usr_id = item[0]
# 将字符数据转成数字并保存在字典中
use_info[usr_id] = {'usr_id': int(usr_id),
'gender': gender2num(item[1]),
'age': int(item[2]),
'job': int(item[3])}
max_usr_id = max(max_usr_id, int(usr_id))
return use_info, max_usr_id
usr_file = "./work/ml-1m/users.dat"
usr_info, max_usr_id = get_usr_info(usr_file)
print("用户数量:", len(usr_info))
print("最大用户ID:", max_usr_id)
print("第1个用户的信息是:", usr_info['1'])
电影信息包含在movies.dat中,数据格式为:MovieID::Title::Genres,保存的格式与用户数据相同,每一行表示一条电影数据信息。
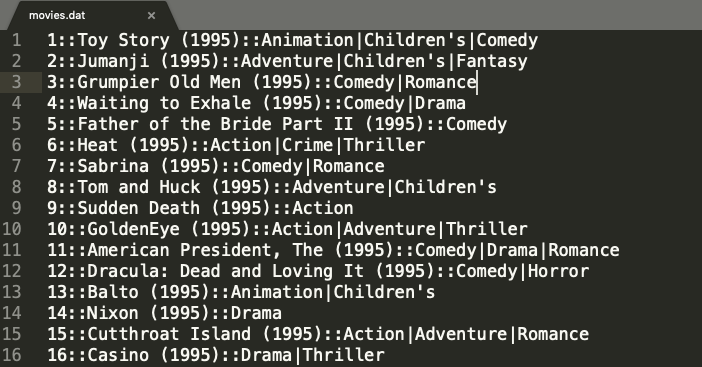

data是list,下标起始是0, movie_info是字典,我们从1开始,因为电影的编号是从1开始的。
完整的电影数据处理代码如下:
def get_movie_info(path):
# 打开文件,编码方式选择ISO-8859-1,读取所有数据到data中
with open(path, 'r', encoding="ISO-8859-1") as f:
data = f.readlines()
# 建立三个字典,分别用户存放电影所有信息,电影的名字信息、类别信息
movie_info, movie_titles, movie_cat = {}, {}, {}
# 对电影名字、类别中不同的单词计数
t_count, c_count = 1, 1
# 初始化电影名字和种类的列表
titles = []
cats = []
count_tit = {}
# 按行读取数据并处理
for item in data:
item = item.strip().split("::")
v_id = item[0]
v_title = item[1][:-7]
cats = item[2].split('|')
v_year = item[1][-5:-1]
titles = v_title.split()
# 统计电影名字的单词,并给每个单词一个序号,放在movie_titles中
for t in titles:
if t not in movie_titles:
movie_titles[t] = t_count
t_count += 1
# 统计电影类别单词,并给每个单词一个序号,放在movie_cat中
for cat in cats:
if cat not in movie_cat:
movie_cat[cat] = c_count
c_count += 1
# 补0使电影名称对应的列表长度为15
v_tit = [movie_titles[k] for k in titles]
while len(v_tit)<15:
v_tit.append(0)
# 补0使电影种类对应的列表长度为6
v_cat = [movie_cat[k] for k in cats]
while len(v_cat)<6:
v_cat.append(0)
# 保存电影数据到movie_info中
movie_info[v_id] = {'mov_id': int(v_id),
'title': v_tit,
'category': v_cat,
'years': int(v_year)}
return movie_info, movie_cat, movie_titles
movie_info_path = "./work/ml-1m/movies.dat"
movie_info, movie_cat, movie_titles = get_movie_info(movie_info_path)
print("电影数量:", len(movie_info))
ID = 1
print("原始的电影ID为 {} 的数据是:".format(ID), data[ID-1])
print("电影ID为 {} 的转换后数据是:".format(ID), movie_info[str(ID)])
print("电影种类对应序号:'Animation':{} 'Children's':{} 'Comedy':{}".format(movie_cat['Animation'],
movie_cat["Children's"],
movie_cat['Comedy']))
print("电影名称对应序号:'The':{} 'Story':{} ".format(movie_titles['The'], movie_titles['Story']))
评分数据处理
有了用户数据和电影数据后,还需要获得用户对电影的评分数据,ml-1m数据集的评分数据在ratings.dat文件中。评分数据格式为UserID::MovieID::Rating::Timestamp,如下图。
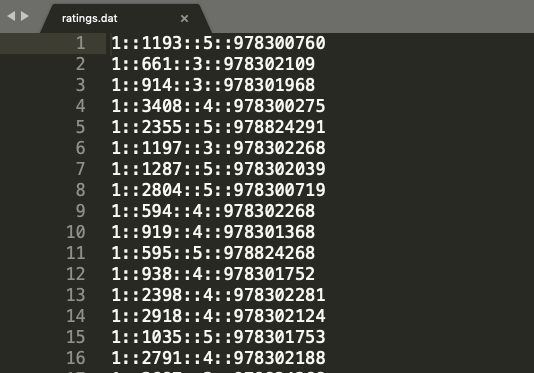
这份数据很容易理解,如1::1193::5::978300760 表示ID为1的用户对电影ID为1193的评分是5。
下面我们将评分数据封装到get_rating_info()函数中,并返回评分数据的信息。
def get_rating_info(path):
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 创建一个字典
rating_info = {}
for item in data:
item = item.strip().split("::")
# 处理每行数据,分别得到用户ID,电影ID,和评分
usr_id,movie_id,score = item[0],item[1],item[2]
if usr_id not in rating_info.keys():
rating_info[usr_id] = {movie_id:float(score)}
else:
rating_info[usr_id][movie_id] = float(score)
return rating_info
# 获得评分数据
rating_path = "./work/ml-1m/ratings.dat"
rating_info = get_rating_info(rating_path)
print("ID为1的用户一共评价了{}个电影".format(len(rating_info['1'])))
数据处理完整代码
到这里,我们已完成了ml-1m数据读取和处理,接下来,我们将数据处理的代码封装到一个Python类中,完整实现如下:
import random
import numpy as np
from PIL import Image
class MovieLen(object):
def __init__(self, use_poster):
self.use_poster = use_poster
# 声明每个数据文件的路径
usr_info_path = "./work/ml-1m/users.dat"
if use_poster:
rating_path = "./work/ml-1m/new_rating.txt"
else:
rating_path = "./work/ml-1m/ratings.dat"
movie_info_path = "./work/ml-1m/movies.dat"
self.poster_path = "./work/ml-1m/posters/"
# 得到电影数据
self.movie_info, self.movie_cat, self.movie_title = self.get_movie_info(movie_info_path)
# 记录电影的最大ID
self.max_mov_cat = np.max([self.movie_cat[k] for k in self.movie_cat])
self.max_mov_tit = np.max([self.movie_title[k] for k in self.movie_title])
self.max_mov_id = np.max(list(map(int, self.movie_info.keys())))
# 记录用户数据的最大ID
self.max_usr_id = 0
self.max_usr_age = 0
self.max_usr_job = 0
# 得到用户数据
self.usr_info = self.get_usr_info(usr_info_path)
# 得到评分数据
self.rating_info = self.get_rating_info(rating_path)
# 构建数据集
self.dataset = self.get_dataset(usr_info=self.usr_info,
rating_info=self.rating_info,
movie_info=self.movie_info)
# 划分数据集,获得数据加载器
self.train_dataset = self.dataset[:int(len(self.dataset)*0.9)]
self.valid_dataset = self.dataset[int(len(self.dataset)*0.9):]
print("##Total dataset instances: ", len(self.dataset))
print("##MovieLens dataset information: \nusr num: {}\n"
"movies num: {}".format(len(self.usr_info),len(self.movie_info)))
# 得到电影数据
def get_movie_info(self, path):
# 打开文件,编码方式选择ISO-8859-1,读取所有数据到data中
with open(path, 'r', encoding="ISO-8859-1") as f:
data = f.readlines()
# 建立三个字典,分别用户存放电影所有信息,电影的名字信息、类别信息
movie_info, movie_titles, movie_cat = {}, {}, {}
# 对电影名字、类别中不同的单词计数
t_count, c_count = 1, 1
count_tit = {}
# 按行读取数据并处理
for item in data:
item = item.strip().split("::")
v_id = item[0]
v_title = item[1][:-7]
cats = item[2].split('|')
v_year = item[1][-5:-1]
titles = v_title.split()
# 统计电影名字的单词,并给每个单词一个序号,放在movie_titles中
for t in titles:
if t not in movie_titles:
movie_titles[t] = t_count
t_count += 1
# 统计电影类别单词,并给每个单词一个序号,放在movie_cat中
for cat in cats:
if cat not in movie_cat:
movie_cat[cat] = c_count
c_count += 1
# 补0使电影名称对应的列表长度为15
v_tit = [movie_titles[k] for k in titles]
while len(v_tit)<15:
v_tit.append(0)
# 补0使电影种类对应的列表长度为6
v_cat = [movie_cat[k] for k in cats]
while len(v_cat)<6:
v_cat.append(0)
# 保存电影数据到movie_info中
movie_info[v_id] = {'mov_id': int(v_id),
'title': v_tit,
'category': v_cat,
'years': int(v_year)}
return movie_info, movie_cat, movie_titles
def get_usr_info(self, path):
# 性别转换函数,M-0, F-1
def gender2num(gender):
return 1 if gender == 'F' else 0
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 建立用户信息的字典
use_info = {}
max_usr_id = 0
#按行索引数据
for item in data:
# 去除每一行中和数据无关的部分
item = item.strip().split("::")
usr_id = item[0]
# 将字符数据转成数字并保存在字典中
use_info[usr_id] = {'usr_id': int(usr_id),
'gender': gender2num(item[1]),
'age': int(item[2]),
'job': int(item[3])}
self.max_usr_id = max(self.max_usr_id, int(usr_id))
self.max_usr_age = max(self.max_usr_age, int(item[2]))
self.max_usr_job = max(self.max_usr_job, int(item[3]))
return use_info
# 得到评分数据
def get_rating_info(self, path):
# 读取文件里的数据
with open(path, 'r') as f:
data = f.readlines()
# 将数据保存在字典中并返回
rating_info = {}
for item in data:
item = item.strip().split("::")
usr_id,movie_id,score = item[0],item[1],item[2]
if usr_id not in rating_info.keys():
rating_info[usr_id] = {movie_id:float(score)}
else:
rating_info[usr_id][movie_id] = float(score)
return rating_info
# 构建数据集
def get_dataset(self, usr_info, rating_info, movie_info):
trainset = []
for usr_id in rating_info.keys():
usr_ratings = rating_info[usr_id]
for movie_id in usr_ratings:
trainset.append({'usr_info': usr_info[usr_id],
'mov_info': movie_info[movie_id],
'scores': usr_ratings[movie_id]})
return trainset
def load_data(self, dataset=None, mode='train'):
use_poster = False
# 定义数据迭代Batch大小
BATCHSIZE = 256
data_length = len(dataset)
index_list = list(range(data_length))
# 定义数据迭代加载器
def data_generator():
# 训练模式下,打乱训练数据
if mode == 'train':
random.shuffle(index_list)
# 声明每个特征的列表
usr_id_list,usr_gender_list,usr_age_list,usr_job_list = [], [], [], []
mov_id_list,mov_tit_list,mov_cat_list,mov_poster_list = [], [], [], []
score_list = []
# 索引遍历输入数据集
for idx, i in enumerate(index_list):
# 获得特征数据保存到对应特征列表中
usr_id_list.append(dataset[i]['usr_info']['usr_id'])
usr_gender_list.append(dataset[i]['usr_info']['gender'])
usr_age_list.append(dataset[i]['usr_info']['age'])
usr_job_list.append(dataset[i]['usr_info']['job'])
mov_id_list.append(dataset[i]['mov_info']['mov_id'])
mov_tit_list.append(dataset[i]['mov_info']['title'])
mov_cat_list.append(dataset[i]['mov_info']['category'])
mov_id = dataset[i]['mov_info']['mov_id']
if use_poster:
# 不使用图像特征时,不读取图像数据,加快数据读取速度
poster = Image.open(self.poster_path+'mov_id{}.jpg'.format(str(mov_id[0])))
poster = poster.resize([64, 64])
if len(poster.size) <= 2:
poster = poster.convert("RGB")
mov_poster_list.append(np.array(poster))
score_list.append(int(dataset[i]['scores']))
# 如果读取的数据量达到当前的batch大小,就返回当前批次
if len(usr_id_list)==BATCHSIZE:
# 转换列表数据为数组形式,reshape到固定形状
usr_id_arr = np.array(usr_id_list)
usr_gender_arr = np.array(usr_gender_list)
usr_age_arr = np.array(usr_age_list)
usr_job_arr = np.array(usr_job_list)
mov_id_arr = np.array(mov_id_list)
mov_cat_arr = np.reshape(np.array(mov_cat_list), [BATCHSIZE, 6]).astype(np.int64)
mov_tit_arr = np.reshape(np.array(mov_tit_list), [BATCHSIZE, 1, 15]).astype(np.int64)
if use_poster:
mov_poster_arr = np.reshape(np.array(mov_poster_list)/127.5 - 1, [BATCHSIZE, 3, 64, 64]).astype(np.float32)
else:
mov_poster_arr = np.array([0.])
scores_arr = np.reshape(np.array(score_list), [-1, 1]).astype(np.float32)
# 放回当前批次数据
yield [usr_id_arr, usr_gender_arr, usr_age_arr, usr_job_arr], \
[mov_id_arr, mov_cat_arr, mov_tit_arr, mov_poster_arr], scores_arr
# 清空数据
usr_id_list, usr_gender_list, usr_age_list, usr_job_list = [], [], [], []
mov_id_list, mov_tit_list, mov_cat_list, score_list = [], [], [], []
mov_poster_list = []
return data_generator
# 声明数据读取类
dataset = MovieLen(False)
# 定义数据读取器
train_loader = dataset.load_data(dataset=dataset.train_dataset, mode='train')
# 迭代的读取数据, Batchsize = 256
for idx, data in enumerate(train_loader()):
usr, mov, score = data
print("打印用户ID,性别,年龄,职业数据的维度:")
for v in usr:
print(v.shape)
print("打印电影ID,名字,类别数据的维度:")
for v in mov:
print(v.shape)
break
dataset具体长这样。


















 3254
3254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









