







云服务器单机部署Kafka&Springboot远程连接测试
环境概述
- 运行环境:Kafka部署在腾讯云的轻量应用型服务器linux系统
- Kafka:3.1.0
- Springboot:2.6.5
本人是第一次使用购买云服务进行环境搭建,采了不少坑才完成的Kafka环境搭建,只有一个服务器所以配置的单机部署,亲测有效,如果有写的不清楚的地方会持续修改
Kafka安装配置
1.下载Kafka
首先进行Kafka的安装,采用的是最新版本3.1,可以去官网下载或点下面的百度云链接自行领取:
链接:https://pan.baidu.com/s/1sfJcq13Jh7y6BVvTGNkY2Q
提取码:1234
2.解压文件
下载成功后将Kafka压缩包拖到服务器进行解压
tar -zxvf kafka_2.12-3.1.0.tgz
3.修改文件名
一般解压后的文件名会很长,可以将其重命名简单的名字
mv kafka_2.12-3.1.0 kafka
4.修改配置文件
1)进入kafka配置文件路径
cd kafka/config
2)修改配置文件
vi server.properties
这一步是kafka在云服务上配置最关键的一步:
其中里面有那个属性要分清,就是listeners和advertised.listeners
linsteners:监听内网
advertised.listeners:对外开放,外网
如果你不需要外网进行生产者和消费者的操作,就只需设置linsteners,需要用到外网的远程连接就设置advertised.listeners,window本地远程访问腾讯云服务器就要同时设置内外网
listeners=PLAINTEXT://10.0.X.X:9092 #这里设置服务器内网ip
advertised.listeners=PLAINTEXT://101.34.X.X:9092 #这里设置服务器外网的ip
zookeeper.connect=10.0.X.X:2181 #zookeeper也是服务器内网IP
5.运行测试
这里用到的是Kafka自带的zookeeper,启动kafka前要先启动zookeeper,再启动kafka
返回kafka路径
刚刚修改完config里面的配置文件,运行记得返回kafka主目录路径
cd ..
启动zookeeper
./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
启动Kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
查看进程
jps
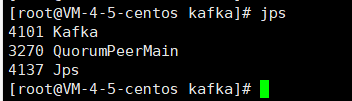
如果出现以上的进程,说明启动成功,如果第一次没有出现Kafka进程,可以再试两遍启动Kafka命令,我这边测试有时启动失败,再试一下就好了
开启端口
云服务器需要手动开启端口才行,你需要把2181和9092端口打开才能进行访问,这个在你购买的服务器网站上会有相应的教程,腾讯云轻量应用服务器只需在服务器的防火墙里面添加端口开放规则即可
但是在连接服务器的远程终端你还需要再次检查端口是否开放,这点很关键
查看开放的端口列表是否有9092和2181
firewall-cmd --zone=public --list-ports
如果有的话就开放成功,否则需要执行开放

开放端口
firewall-cmd --query-port=9092/tcp #开放9092
firewall-cmd --query-port=2181/tcp #开放2181
firewall-cmd --reload #重新加载,使配置生效
好,当你设置完这些,就可以用操作命令进行连接测试了
6.常用操作命令
由于我用的Kafka新的版本,以前的使用到–zookeeper的操作命令并不适用,下面使用的新版本操作命令
1.创建Topic
./bin/kafka-topics.sh --create --bootstrap-server 101.34.175.40:9092 --replication-factor 1 --partitions 1 --topic sandmswift
创建一个sandmswift主题,该主题有一个分区(partitions),一个副本(replication-factor),副本的数量不能超过broker的数量。
新版本使用的是bootstrap.servers启动集群:
这个参数是常用的KafkaProducer和KafkaConsumer用来连接Kafka集群的入口参数,这个参数对应的值通常是Kafka集群中部分broker的地址
之前配置了公网,这里启动语句的IP:port要对应,不然会报错broker不可靠,相当于名字不一样它找不到对应的broker

2.查看指定主题
./bin/kafka-topics.sh --bootstrap-server 101.34.175.40:9092 --describe --topic sandmswift

3.查看所有主题
./bin/kafka-topics.sh --bootstrap-server 101.34.175.40:9092 --list

4.删除指定主题
./bin/kafka-topics.sh --delete --bootstrap-server 101.34.175.40:9092 --delete --topic sandmswift
5.生产者
./bin/kafka-console-producer.sh --broker-list 101.34.175.40:9092 --topic sandmswift
指定Topic 进行生产者操作

为了看到生产者和消费者数据交互变化情况,不要关闭此生产者终端,打开一个新的连接终端进行消费者操作
6.消费者
./bin/kafka-console-consumer.sh --bootstrap-server 101.34.175.40:9092 --topic test --from-beginning
springboot连接测试
这里用于测试客户端连接服务器上的Kafka,只要服务器上命令操作没问题,下面的连接就试简单的复制粘贴
1.kafka依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.1</version>
</dependency>
2.消费者
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = KafkaProducer.TOPIC, groupId = KafkaProducer.TOPIC_GROUP1)
public void topicTest(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
log.info("消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
}
3.生产者
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import javax.annotation.PostConstruct;
@Component
@Slf4j
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
//定义已存在的Topic名称
public static final String TOPIC = "test";
public static final String TOPIC_GROUP1 = "topic.group1";
@PostConstruct
public void send() {
String message = "发送测试生产者的消息";
String obj2String = JSONObject.toJSONString(message);
log.info("准备发送消息为:{}", obj2String);
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC,"key1", message);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable throwable) {
//发送失败的处理
log.info(TOPIC + " - 生产者 发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> stringObjectSendResult) {
//成功的处理
log.info(TOPIC + " - 生产者 发送消息成功:" + stringObjectSendResult.toString());
}
});
}
}
4. application.yml
spring:
kafka:
bootstrap-servers: 101.34.175.40:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
client-id: 200
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
client-id: 200
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false















 1801
1801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









