







本文只梳理的Lecture的知识点概念,不涉及Lab的代码实现
如有错误欢迎探讨
文章目录
- week1 进程
- week2 线程
- week3 进程同步
- week4 CPU进程调度
- week5 CPU线程调度
- week6 死锁问题
- week8 内存管理
- week9 虚拟内存
- week10 大容量存储
- week 11 文件系统
- week12 I/O系统
- week13 保护与安全
- week14 虚拟机与分布式系统
week1 进程
操作系统概述(Operating System)
An operating system acts as an intermediary between a user and the computer hardware
操作系统主要有以下操作方式:
- 管理程序的开始与结束并在程序间共享CPU
- 管理内存
- 输入输出
- 文件管理系统
- 保护
进程 (Process)
- 进程process代表一个正在运行的程序
- 程序program代表被存储在硬盘空间里的代码,是一个被动实体
进程的状态:
As a process executes, it changes state.
当进程执行时,会改变状态,状态象征着进程当前活动:
1. new:被创建
2. running:指令正在被执行
3. waiting:进程需要用户输入或其他进程运行结果而等待
4. ready:已就绪,可以被执行
5. terminated:被终止

PCB进程控制块 (Process Control Block)
本质上是数据结构-链表linked list,存储了一个进程的相关信息。所有进程的PCB都被包含在主存中。进程对于多道(multiprogramming
environment )有相当重要的作用。
单道批处理:单个程序进入计算机系统
多道:多个程序(进程)可同时进入处理机,磁带上的一批作业能自动的逐个运行
实时:要求高度可靠,响应度高,及时处理并交付任务
分时:各个进程分时间段依次占据处理机,交互性更好

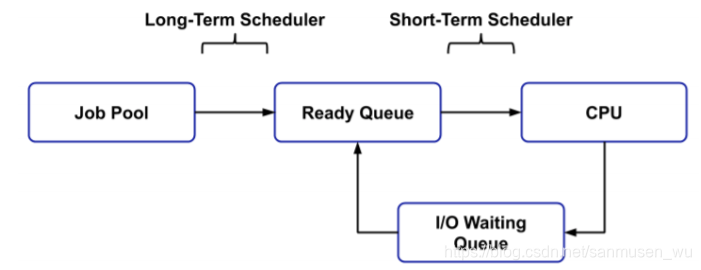
进程调度概述(Process Scheduling)
进程调度既从某个地方选择进程,将其移到另一个地方。
一般维护以下进程:
- 作业队列Job queue:系统内所有进程的集合
- 就绪队列Ready queue:处于就绪状态的进程
- 设备队列Device queues:等待I/O设备输入输出的进程队列
三种调度类型:
- 长期调度(Long-Term Scheduler,Job Scheduler)也称作业调度,根据进程池中的所有进程进行规划并调度,选择一个或一批进程进入内存,作业完成后还需负责回收系统资源。
- 中期调度(Medium-term scheduler)将需要等待I/O的进程移出内存,存储于磁盘上,降低多道设计的程度,需要时再换回内存中-swapping
- 短期调度 (Short-Term scheduler,CPU scheduler)选择一个就绪队列里的进程占据CPU运行,也是常说的调度
上下文切换Context Switch:
当CPU内的进程发生切换(中断或系统调用)时,需要将被切换的进程的相关信息(临时变量,状态等)存储进PCB,同时,读取切进来的进程的相关信息,这个过程被称为上下文切换。
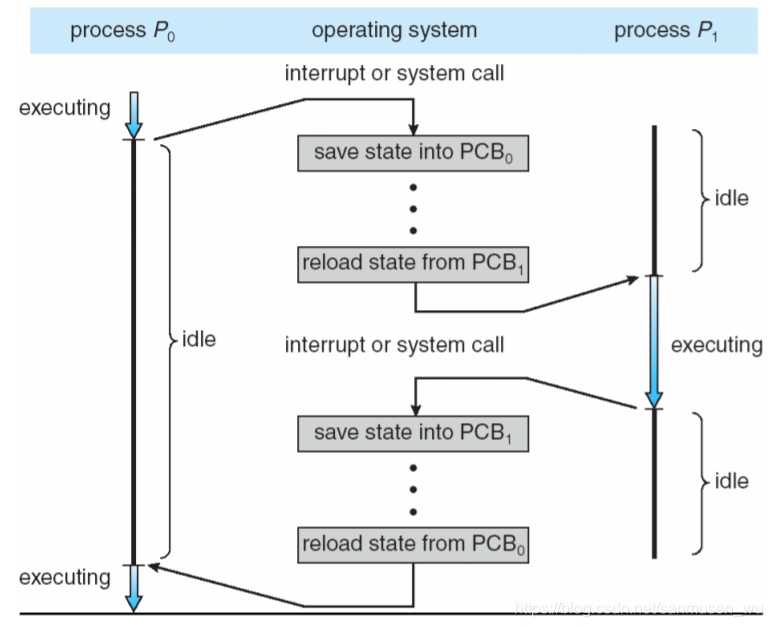
对进程的操作(Operations on Processes)
系统需要提供进程的创建creation和终止termination操作(mechanisms)。
- 创建进程:
进程可以被进程创建,例如,一个父母进程创建一个子进程。通过进程间的创建,可以形成一个进程树,进程树上的每个节点通过pid(process identifier)来唯一地被标识。
-
- 资源策略
-
父母进程与子进程共享所有资源
-
共享部分资源
-
不共享资源
-
- 终止策略
-
父母进程和子进程同时终止
-
子进程被终止后,父母进程被终止
- 终止进程:
进程执行最后一条语句,然后使用系统调用exit()让系统终止该进程。
父级进程可以调用exit()终止子进程。
进程间通信(Inter-process Communication)
- 独立进程(Independent Processes)
不与其他进程互相影响的进程。 - 合作进程(Cooperating Processes)
会被其他进程影响的进程,合作进程存在于
- 资源共享information sharing:多个用户浏览同一资源
- 计算加速computation speedup:并行计算提高速度
- 模块化modularity:按照模块化方式构造系统
- 便利性convenience:单个用户可能同时执行多个任务
进程通信方式(Communications Models )
分为两种方式:共享内存和消息传递
都使用一个叫缓冲区buffer的存储空间来存储消息:
共享内存(Shared-Memory)
processes can be able to exchange information by reading and writing all the data to the shared region
通过读写同一片缓冲区的信息去达到交换信息的目的
访问同片缓冲区代表着临界区问题
- 当缓冲区容量有限时(Bounded capacity):缓冲区的存储信息有上限
- 当缓冲区容量无限时(Unbounded capacity):缓冲区存放信息没有限制
消息传递(Message-Passing)
合作进程间通过消息发送与交换共享信息,主要有两种操作:
send(message)和receive(message):发送和接收
- 消息传递方法传递的消息存储在临时队列中(邮箱):
· 零容量(Zero capacity):临时队列中不能有未被接受的消息(每一条消息都应被接受,然后下一条消息被发送)
· 有限容量(Bounded capacity):临时队列有限,至多可以存储n条消息
· 无限容量(Unbounded capacity):临时队列长度无限。 - 如果进程P和Q想要通信,则他们之间必须要有连结。这种连结可以是直接的,也可以是间接的:
· 直接通信(direct communication):将消息直接发送给另外一个进程,在这之前接受者不知道聊天对象。
· 间接通信(indirect communication):设置临时队列(temporary queue),合作进程将消息发送给临时队列,又能够从临时队列收取消息。 - 消息传递可以是同步的,也可以是异步的:
· 同步(Synchronous):又被称为阻塞(blocking)
Blocking send: 当消息被发送,发送者会被阻塞,直到接收者接受消息。
Blocking receive: 接收者会被阻塞,直到接收新消息
· 异步(Asynchronous):又被称为非阻塞(non-blocking)
Non-blocking send: 发送者可以发送消息然后继续运行
Non-blocking receive: 接收者可以在任意时刻接受消息, 消息可能有效可能为空
week2 线程
线程(thread)
A thread is the smallest unit of processing that can be performed in an OS.
Thread is a fundamental unit of CPU utilization that forms the basis of multithreaded computer systems
- 线程是计算机操作系统执行的基本单元,也是CPU使用的基本单元。
- 线程也可以看成是简化的进程;
- 属于同一个进程的线程之间可以共享代码,数据,文件;
- 线程能够帮助程序“同时”执行多个任务。
一个线程主要包含:
线程ID,程序指针,寄存器集,栈。

线程状态(Thread states)
- 未创建的线程处于undefined状态;
- 当线程就绪时,处于ready状态;
- 同一时刻只能有一个线程处于running状态
- 当线程被中断运行(suspend),处于suspended状态,随后可调用resume()回归就绪状态
- 处于中断terminated状态的进程会被释放,随后处于销毁destroyed状态
单线程进程和多线程进程(Single and Multithreaded Processes)
传统讲的单线程进程,任务被分配给了一个进程,其内只有一个线程,发生错误这个任务就挂掉了。
多线程进程,进程其内变成了多个线程,任务被分配给了许多线程,如果一个线程挂了对其他线程没影响,it can perform more than one task at time.
并发和并行(Concurrency vs. Parallelism)
单核系统并发处理任务,进程一个一个开始,中间互相穿插运行,直到结束完成。(一会吃饭一会看手机)
多核系统并行处理任务能够同时处理多个任务(一边吃饭一边看手机)
阿姆达尔定律(Amdahl’s Law)
一个计算可通过并行加速多少运行速度的模型

多线程模型
用户线程(User Threads)
由用户实现的执行单元,这些线程受内核支持但是内核不管理这些线程。用户线程比系统线程快。
通过使用线程库thread library来调度这些线程。
核线程(Kernel Threads)
由内核安排在CPU上执行的线程。
线程管理通过OS核控制。

组合用户级线程和核线程
Many-to-One
多个用户级线程映射map到一个核线程。
因为只映射到一个核线程,所以进程只能同时执行一个用户线程,而且当这个用户线程被阻塞,整个进程被阻塞。
Used on systems that do not support kernel threads.
用于不支持内核线程的系统
One-to-One
一个用户级线程映射到一个系统线程。
每次创建一个用户线程就会创建一个系统线程,提供了并发的可能,且当一个线程发生阻塞,其他线程依旧可以运行。
大部分主流操作系统用的这个
Many-to-Many
多个用户线程映射到多个系统线程
线程库(Thread Libraries)
是个Application Programming Interface (API)接口,程序员可以用它在应用里创建和管理线程。
- 没有内核支持时,在用户空间中提供库(Library entirely in user space)。意味着库的所有代码和数据存放在用户空间,调用时不会使用系统调用。
- 实现内核级别库(kernel-level library ),库和代码放在内核空间中,调用这些函数会使用系统调用。
三个主要的线程库:POSIX Pthreads,Win32,Java
创建线程(Thread creation)
异步:父线程创建子线程然后互不影响,几乎不需要数据共享。
同步:父线程需要等待子线程结束运行,需要较多数据共享。
线程的种类
- 由程序员手动创建的叫显式线程(explicit threading)
- 编译器和即时库创建的线程叫隐式线程(implicit threading)
设计多线程程序的三种方式
- Thread pool线程池
- OpenMP是个指令集
- Grand Central Dispatch (GCD) 更多支持并行的指令集
多线程问题
- fork()和exec()调用
当fork()被调用,会产生俩,一个父级,一个子级;他们俩的代码段,数据和堆栈完全相同。
当exec()被调用,当前线程执行的程序会被替换成另一个程序,进程ID未变,以别的程序替代了该线程的代码段,数据和堆栈。 - 信号处理Signal handling
Unix/Linux系统相应某个条件或操作而生成的中断或时间,由signal handler处理,且每个信号只处理一次,信号大致有以下几种:
异步信号asynchronous signal:发信号后不等
同步信号synchronous signal :发送信号后死等 - 线程关闭Thread cancellation
在线程完成之前关闭线程(如:加载页面时点击取消)
能通过以下方式关闭:
· Asynchronous cancellation 异步取消:立即终止。
· Deferred cancellation 延期取消:允许目标线程检查然后自己终止。
week3 进程同步
进程同步(Process Synchronization)
PS is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources.
两个进程不能同时访问共享资源
竞争条件(Race condition)
当多个进程同时访问和操作统一数据,数据的结果因代码执行顺序而异,导致数据的不一致。
To prevent race conditions, concurrent processes must be synchronized
为了防止竞争,必须同步并发的进程。
同步
同步发生在协作进程之间,基础思想是需要一个任何形式的锁。
临界区(Critical Section )
临界区即是会访问共享资源的代码区(改变共同变量,读写文件等),我们需要控制程序进入这段代码的时机。
· 进入区:控制进入临界区
· 临界区:这之内的代码会访问共享资源
· 退出区:告诉其他进程该进程退出了邻接区
共享的对象:
- 可以从堆中动态分配
- 可以在全局变量中声明static而静态分配
当多线程访问共享对象:
- 如果对象是动态分配的,则每个线程都需要一个指向它的指针
- 如果对象是静态的,线程只需要通过全局变量名引用它,编译器会计算相应的地址。
临界区的三个原则
- 互斥(mutual exclusion):如果已有进程在临界区执行,其他进程不能在其临界区执行。这里讲的都是写作进程。
- 前进(progress):如果没有进程在临界区,其他进程应该被允许进入临界区。
- 有限等待(bounded waiting):进程做出进入临界区请求后,其他进程进入临界区的次数是有上限的,进程发出请求后等待允许的时间有限。
处理临界区的两种内核
- 抢占式(preemptive kernel):允许进程在内核模式下运行时被抢占。
- 非抢占式(non-preemptive kernel):进程在内核模式运行时不会被抢占。不会产生竞争。
临界区问题的解决方法
每个方法都要遵循互斥,前进,有限等待三个原则
- Peterson’s solution
- Hardware solution/Synchronization Hardware
- Mutex lock
- Semaphores
1. Peterson’s solution
维护 int turn 和 boolean flag[2]
turn表示下一张门票;flag表明现在谁在内
这一次要进去之前把自己flag设为true表示我要进去,然后把下一次进去的机会turn留给对面,对面flag是true则自己不被允许进入临界区,只有这次机会在自己这里并且对面falg为flase自己才能进去。
自己出来临界区后把自己flag设为flase表示自己出来了,这样对面就可以进入临界区。
遵循的三个原则这里不做分析,可以阅读Peterson算法:一种形象的分析
下图 i 是自己:

2. Synchronization Hardware
由硬件支持的同步,都是关于锁的
单处理器环境 Single-processor environment
临界区有全局变量lock,只有lock为F时才进入,进入时检查是否为F,申请到了后置为T,退出时置为F
boolean lock
test_and_set(&lock)

多处理器环境 Multi-processor environment
全局变量lock,只有lock为0时才进入,申请成功后交换(0,1)状态,退出时置为0,适用于多处理器环境。
int lock
compare_and_swap(&lock,0,1)

3. 互斥锁/互斥 Mutex Locks / Mutual exclusion
基于软件,允许多个程序线程不同时地访问同个资源。
· 核层面实现互斥时,会发生中断,导致上下文切换。为了减小中断可能对数据造成的损害,尽可能做完原语再中断,原语既完成一个数据操作的最小代码。
· 软件层面互斥,进程处于运行状态,需要忙等或产生自旋锁busy-wait mechanism or spinlock,既一直在循环检查是否被允许。
进程在进入前需要申请锁,退出临界区需要释放锁。
4. 信号量 Semaphores
是个int形非负变量,被线程间共享,与之相关两原子操作:
- wait()
信号量小于等于0就忙等,大于0就减一,代表申请到了锁。 - signal()
信号量加1,代表锁被释放
两种信号量
· 计数信号量 COUNTING SEMAPHORE
· 二进制信号量 BINARY SEMAPHORE
计数信号量
信号量S被初始化为可用资源的数量,函数wait()和signal()定义不变,S代表着当时剩余的可用资源的数量。
二进制信号量
也被称为互斥锁Mutex,值只有1和0,初始化为1,函数wait()和signal()分别在值为1和0的情况下被合法调用。
同步的一些相关问题
死锁和饥饿
· 死锁Deadlock既每个进程都持有一定的资源,又希望获得正在被其他进程占有的资源,这样每个进程都得不到完整资源。
· 饥饿Starvation既进程始终得不到它想要获得的资源。
有限缓冲问题(bounded-buffer problem)
存在一个公共且有限的缓冲空间,使用这些的进程被分为生产者和消费者,生产者只有在缓冲未满时生产,消费者只有在缓冲非空时消费,解决方案:
- 信号量mutex=1 保证对缓冲池的访问是互斥的
- empty=n 表示空闲缓冲区的信号量
- full=0 表示已使用缓冲区的信号量
读者-写者问题(The Readers–Writers Problem)
对于一个公共资源,使用资源的进程被分为读者和写者,分别只读,只写。对于这些读者没有太多限制。要避免同一时间有多名写者访问和写者和读者都在访问的情况。要求:
· 一个写者在访问时,其他写者和读者要被阻塞
· 允许多个读者在同时访问,但此时写者全部阻塞
解决方案:
- readcount=0 表示读者数量。
- mutex=1 保证更新readcount时互斥,修改读者数量时的互斥
- wrt=1 作为写者获得请求的信号量,读者和写者共用,确保读者和写者互斥,没有读者时=0
哲学家进餐问题(The Dining-Philosophers Problem)
5个人坐一圈,人与人之间放一只筷子,人要么思考要么吃饭。吃饭前需要依次拿起左手与右手的筷子,思考时放下筷子。
死锁问题:所有人都在思考,然后同一时刻吃饭,所有人拿起左手的筷子后都在请求右手的筷子,产生死锁。解决方案:
- 最多允许四个人坐下
- 一次只允许一个左右手都有筷子的哲学家拿起两只筷子。
- 奇数位置的人先拿左手,再拿右手;偶数位置的人先拿右手,再拿左手。
week4 CPU进程调度
程序由CPU执行(CPU execution)和I/O等待(I/O wait)组成。从CPU执行开始在上述运行状态间进行切换。程序据此也可被分成CPU繁忙型和I/O等待型。
短期调度既是从就绪的进程中选择一个,分配CPU给进程。
只有处于就绪ready状态的进程会被cpu调度。
抢占式与非抢占式调度
抢占式PREEMPTIVE SCHEDULING
正在运行的进程会被打断,然后下一个高优先级的进程会进入。
非抢占式NON-PREEMPTIVE SCHEDULING
正在运行的进程不会被打断,下个进程需要等待这个进程完成CPU周期。
·
何时发生调用
调度发生在四种情况下:
- 进程从运行转为就绪(因为中断)
- 从运行转为等待(因为I/O请求或wait()等待)
- 从等待转为就绪(IO完成)
- 终止进程
其中2和4是非抢占的,1和3是抢占的。
调用后谁去执行
分派程序(Dispatcher module)
控制那些短期调度的进程,主要包括:
· 切换上下文
· 切换至用户模式
· 跳转到合适的位置以重启程序
分派程序会产生延迟。
评估不同的调用策略
放图

来自操作系统(五)——CPU调度

期望一个合理的调度算法应该尽可能拥有:
- 最大CPU效率 Max CPU utilization
- 最大吞吐量 Max Throughput
- 最小周转时间 Min Turnaround time–进程提交到进程完成的时间之和
- 最小等待时间 Min Waiting time–在就绪队列中等待的时间,不包括运行时间
- 最小响应时间 Min Response time–提交请求到产生第一个响应的时间
调度算法
共7个,可以移步这位博主的总结操作系统常用调度算法,这里大部分内容不再详述。
First-Come, First-Served (FCFS) Scheduling-先到先服务
非抢占
Shortest-Job-First (SJF) Scheduling-短作业优先
抢占。
PPT里说该算法能够得出给定进程的最短等待时间。可能是个考点(?
如何知道下一个CPU请求所需的时间(burst time):
· 批处理系统中的长期调度,可以使用用户提交作业时表明每个进程的运行时间。
· 短期调度没法实现SJF,因为不知道就绪队列中进程将会运行多久。
可以用近似算法估算运行时间而使用近似SJF调度:这时假定进程的运行时间被估计

Shortest Remaining Time First-短剩余时间优先
第一个进程先来先服务,第二个进程之后根据最短剩余时间进入,第一个进程可能会被抢占。
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |

Priority Scheduling-优先级优先调度
非抢占
优先级的数字越小,代表优先级越高。
会产生饥饿–>引入岁数Aging,优先级会随着等待时间被提高
Round Robin(RR) Scheduling-时间片轮转
抢占
时间片大了会FCFS,时间片小了上下文切换过于频繁。
Multiple-Level Queues Scheduling-多级分层
层与层间平行,调度前进程被分配到固定某一层
Multilevel Feedback Queue Scheduling-多级反馈队列
进程在调度时会被转移到其他层。
需要考虑:
– number of queues
– scheduling algorithms for each queue
– method used to determine when to upgrade a process
– method used to determine when to demote a process
– method used to determine which queue a process will enter when that process needs service
week5 CPU线程调度
线程调度 Thread Scheduling
进程本地调度 Process local scheduling
适用于many-to-many和many-to-one。
线程竞争(process-contention scope, PCS):指CPU竞争发生在同一进程下的线程之间
系统全局调度 System global scheduling
适用于one-to-one,
属于系统竞争(system contention scope,SCS):指CPU竞争发生在映射的内核线程之间。
·
多处理器调度
Depends on how the multiple processors are configured within the system.
调度策略的选择取决于多个处理器的配置方式
非对称 Asymmetric (master/slave-AMP)
大哥带小弟,大哥处理器需要处理整个系统的调度,IO等,其他处理器只处理用户的代码
对称 Symmetric (SMP)
各个CPU各司其职
处理器亲和力 Processor affinity
特定的进程只在一个特定的处理器上运行,减少进程在不同处理器上的跳跃,既重复利用缓冲区
Soft affinity
OSs try to keep a process running on the same processor
Hard affinity
allows a process to specify a subset of processors on which it may run
负载平衡 Load Balancing
操作系统检查并验证(checks and validates)就绪队列中进程数
负载移出 Push migration
如果该处理器过载,将过载的进程push到空闲处理器分配负载
负载移入 Pull migration
pulls a waiting task from a busy processor
处理器空闲会从别的处理器转移进来进程
多核处理器问题
SMP:多核会复杂化调度
存储停顿 memory stall:核心为了等待数据可用而停顿
硬件层面解决 - 实现多线程处理器内核(multithreaded processor cores): 硬件的线程被分配给每个内核,如果一个线程停顿,核心切换至另一个线程。
粗粒度多线程 Coarse-grained multithreading
只有线程阻塞时发生线程切换
细粒度多线程 Fine-grained multithreading
线程按照时间片轮转切换
·
实时CPU调度
硬实时系统 Hard real-time systems:
····确保在规定时间内完成任务
软实时系统 Soft real-time systems:
····要求高优先级的进程先于低优先级的
中断延迟 interrupt latency:
····中断响应时间,中断请求到中断服务之间的时间
调度延迟 dispatch latency:
····停止一个进程到开始下一个进程之间的时间
静态调度 Static scheduling:
····程序开始前调度并处理相关资源,周期和DDL。
优先级调度 priority-based scheduling:
···· 实时分析程序,为进程分配优先级
动态调度 dynamic scheduling:
···· 创建进程时请求调度决策
优先级调度(Priority-based Scheduling)
抢占-preemptive
CPU定期j计算进程的处理时间t,截止时间d,周期p
周期速率为1/p
单调速率优先调度RMS(Rate Monotonic Scheduling )
对于周期性进程的高静态优先级抢占,目前是最优静态调度算法
优先级:周期period越短,静态优先级越高
该算法假定每个周期中,周期性进程处理的时间相同(既第一次周期,第n个周期中进程p需要执行的时间固定不变),不会随着时间推进各个周期内出现因处理时间偏差产生的误差
- 根据静态优先级开始依次运行。
- 每个进程开始它的一个新的周期时抢占CPU,同一时刻多个线程开启新周期,按照优先级抢占。
- 每个进程在它的一个周期内只会完成一次task。
以所需处理时间t / 周期period 可表示系统利用率,系统利用率之和小于1代表目前系统可以在大周期截止前完成全部任务,甚至还能留下空闲时间。


仍然有错过DDL的线程组合,如果使用RMS算法超时,那么使用任何其他算法也会超时
早截止早优先 (Earliest-Deadline-First Scheduling)
抢占,根据动态优先级抢占。
优先级:根据距离DDL时间越早截止,优先级越靠前
- 每个线程的新的周期开始时计算优先级,高优先级的抢占低优先级的
比例分享调度(Proportional Share Scheduling)
CPU享有T个门票,把门票下发给程序,程序持有多少比例的门票就占CPU多久比例
算法评估
Deterministic evaluation
算平均等待时间
Queueing Models
算cpu利用率,平均队列长度,平均等待时间
Little’s law
进程离开队列和进入队列相抵

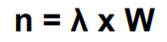
平均队列长度 = 到达速率 * 单个进程在队列内的平均等待时间 = 出去速率 * 单个进程在队列内的平均等待时间
Simulations
用不同的调度
week6 死锁问题
死锁Deadlock
什么是死锁:
Deadlock can be defined as the permanent blocking of a set of processes that compete for system resources
由于争抢资源导致的永久阻塞,一系列进程持有资源并且想要别的进程持有的资源。
死锁四特征Deadlock Characterization
互斥 MUTUAL EXCLUSION
资源同一时刻只能被一个进程访问
占有并等待 HOLD AND WAIT
进程持有一些资源,又等待获取一些资源
非抢占 NO PREEMPTION
进程不能抢占那些持有部分资源的进程
循环等待 CIRCULAR WAIT
a等b,b等c,c等a
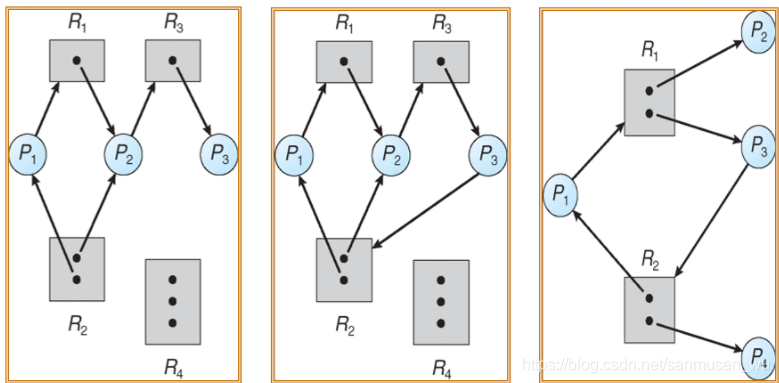
资源分配图
圆P代表进程
块R代表资源,里面的点代表资源实例
P->R箭头(request edge):P申请R的实例instance,request
Ri->P箭头(assignment edge):R的实例 i 被分配给P,granted或者allocated
当图中没有环代表不存在死锁,
如果存在环:
- 一个资源只有1个实例,形成死锁
- 一个资源有多个实例,可能死锁
下三图中一和三不存在死锁,图二中的P2,R3,P3,R2形成死锁
处理死锁 Handling Deadlocks
预防死锁
Deadlock Prevention
破坏死锁发生的4个条件之一。
·互斥:需要OS支持
·持有并等待:要求进程申请资源时没有持有的资,或一次性申请并得到所有资源。不过会造成饥饿。
·非抢占:进程申请资源时遭到部分拒绝,应释放自己的资源;或把拒绝它的进程干掉,得到资源。
·循环等待:通过定义资源的线性顺序解决,进程所需的资源排成链表
Deadlock Avoidance
当确保资源安全不会产生死锁后再释放资源
one sequence of resource allocations to processes that does not result in a deadlock 需要存在一个资源的安全状态(safe states),也就是至少存在一个已知的不会发生死锁的资源分配顺序。
两种方法:
- 如果进程的资源需求可能会导致死锁,那就不启动它
- 如果进程新的资源请求可能导致死锁,拒绝该请求
相关概念:
- max needs:一个进程最大可能需求的资源数量
- available resources:现未被分配的资源
- need:进程需要的资源数量
- allocation:已被分配给进程的资源
安全状态Safe / Unsafe state
算法寻找一个合适的授予资源的顺序,使每次当前进程结束后,将他拥有的资源释放后,资源池能确保持有能使下个进程满足的资源量。
每个进程都要提前告知自己的最大需求数量
Alloc+Need=Max
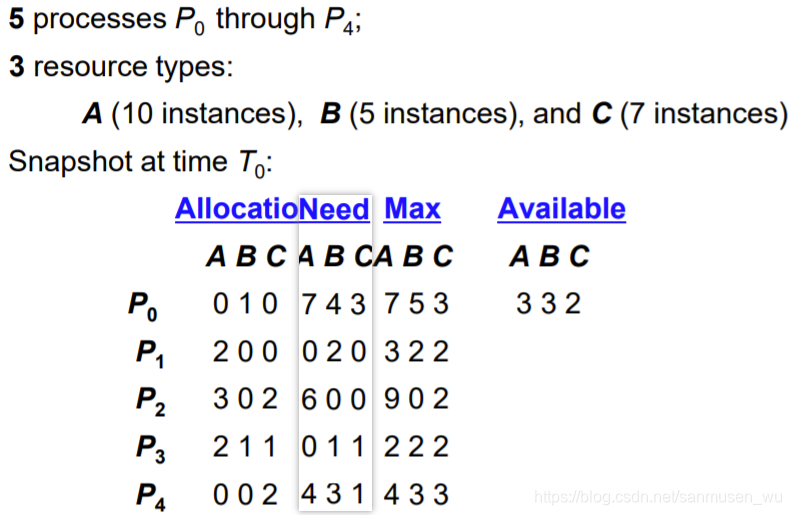
处理已发生的死锁
Deadlock Detection
使用等待图 wait-for graph :
将资源分配图的资源省略,只关注进程间关系。
相关概念:
available,allocation,request/need。

死锁检测的时机:
- 关乎死锁可能发生的频率
- 关乎死锁发生时会影响到的进程数量
Recovery from Deadlock
修复死锁问题:
- 终止(abort)一个或多个发生死锁的进程以终止循环等待
·一次全部终止(环上的进程全部终止),或挨个终止直到循环等待(资源分配图里的环)消失。 - 从一个或多个死锁进程抢占(preempt)资源
·选择受害者victim–根据拥有资源数量和运行时间
·回滚Rollback–返回安全状态,重启进程
·饥饿starvation–需要避免同个进程一直被选为受害者
week8 内存管理
内存管理Memory Management
为什么需要内存管理:
- Protection-从用户进程中保护OS;用户进程之间的保护,通常是由硬件支持的
- Relocation-在内存中移动而不影响其运行
- Sharing-既要保护,又要分享
- Logical Organization of memory-逻辑上地址被认为是一个一维的线性的由比特组成的序列
- Physical Organization of memory-物理上地址有:主存访问速度快但是贵;二级存储慢但是便宜;大容量存储放的东西多,时间长。
相关概念:
·逻辑地址Logical address:又叫虚拟地址virtual address,是CPU执行时处理的地址。逻辑地址空间由基地址寄存器(base registers)和限制寄存器(limit registers)组成。逻辑地址由CPU生成, 通过内存管理单元(MMU, memory management unit)转换成物理地址
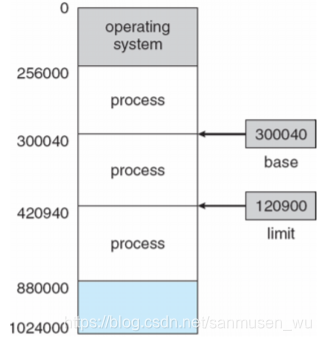
·物理地址Physical address:由物理内存条介质认为的地址,可以定位到物理内存中的地址。
一个程序内的逻辑地址可以在三个阶段与物理地址绑定:
- 编译(compile time)时期:将绝对地址编译进程序,但首地址改变时就会出错
- 加载(load time)时期:加载程序时将逻辑地址与物理地址绑定,但不支持虚拟内存
- 运行时期(execution time)时期:执行时映射逻辑地址到物理地址,这种绑定方式需要硬件支持,支持虚拟内存。
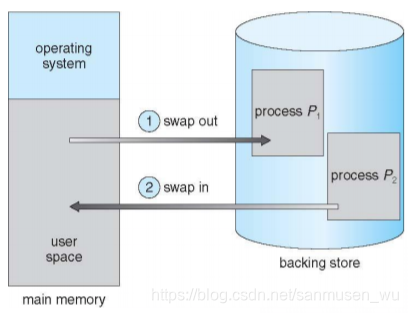
交换Swapping
交换swapping既是把一个进程在内存与备份存储间来回调换。
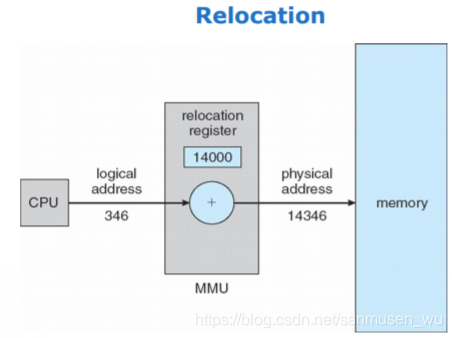
动态重定位Dynamic relocation using a relocation register
重定位relocation既是把一个逻辑地址映射成物理存储地址。
用户程序看到的地址都是逻辑地址(0 ~ M),当这些地址被使用时经过重定位即可映射到物理地址(R ~ R+M)。
内存管理单元(memory-management unit , MMU)方案中,映射时所用的重定位寄存器(relocation register)就是基地址寄存器(base register),将CPU逻辑地址加上重定位寄存器内地址完成对数据的重定位。
内存分配 Memory Allocation
连续内存分配 contiguous memory allocation
进程获得的内存块是连续的
固定/静态 分区(Fixed/Static Partitioning )
为进程分配大小够用的内存块
- 内存块之间大小不要求相同(例如:大小为40MB的内存块和另一个大小为100MB的内存块)
- 每个进程被分配到各自的一个内存块
·产生内部碎片Internal fragmentation :
····进程没有完全填充被分配的内存块(如:一个只有36MB的进程被分了40MB内存块)
·解决:
····改用可变大小的内存块而不是固定大小
变量/动态 分区(Variable/Dynamic Partitioning)
OS保留一个可用内存表list of free memory blocks,记录未被使用的内存块,每次根据需求选择大小够用的内存块分配。
· first-fit 选择第一个够用的块
· best-fit 选择最小且够用的块
· worst-fit 选择最大且够用的块
·产生外部碎片External fragmentation:
····总有过小的内存块没法被分配,变成了碎片(如:有个300kb的内存块,但是压根没有小于300kb的进程)
·解决:
····紧缩Compaction:将已分配的块向一侧集体移动
····使用非连续分配Non-contiguous memory allocation:分段和分页(Segmentation and Paging)
非连续内存分配 non-contiguous memory allocation
以非连续方式为进程分配内存块
逻辑地址空间可以看成书店,资源可以看成书。
分段可以看成把相同类型的书的分到一个集合,段表既是记录了这些集合在店里哪个地方的清单。
分页可以看成把店里划分为许多等大的区域,书的清单上也被划分了同样大小的等大表格,每个表格记录一个区域的位置,通过查找清单可以查找到相应的区域,再通过偏移地址可以知道在该区域内具体什么位置。
1. 分段Segmentation
按照程序的逻辑给程序分段,每段由段名与段长构成。
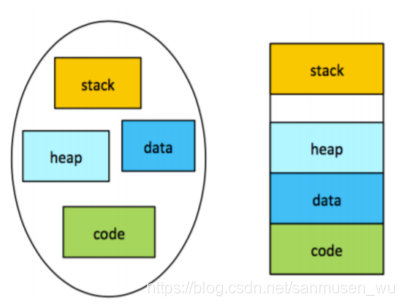
逻辑地址由段地址segment和偏移地址offset组成。
逻辑地址空间看成是由段组成的集合。
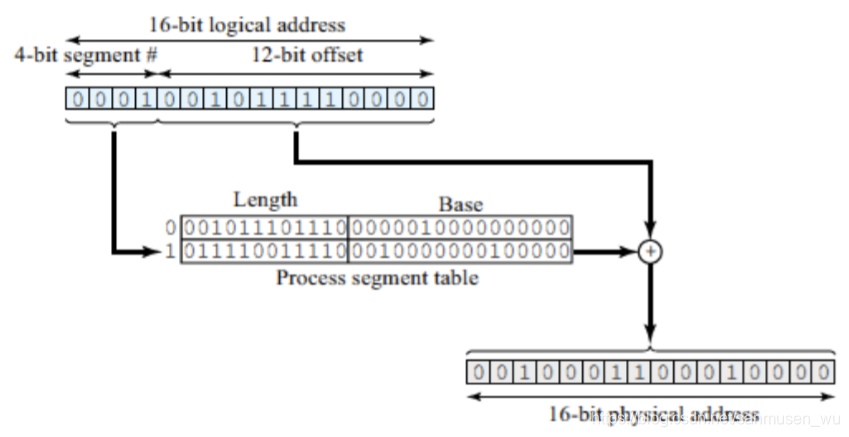
段表 Segment table
将两个维度的逻辑地址组合成一维的物理地址。
每个段表元素包含基地址base和段长度limit
下面的段表两行,查找的是第二行:
2. 分页Paging
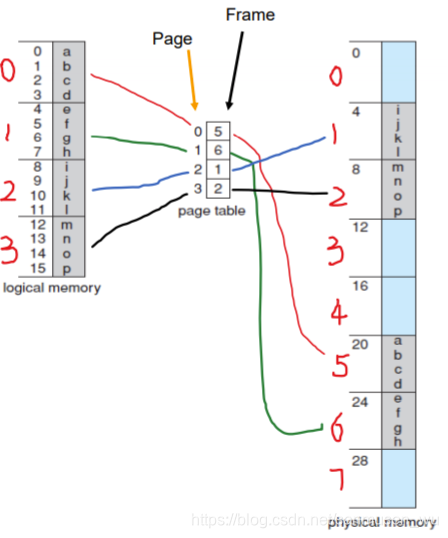
帧frames:将物理内存分为固定大小的块。当进程运行时,将其调入可用的帧中。
页page:逻辑内存也分为同样大小的块。包含页号和页偏移
页号page number:页在页表里的下标。
页大小page size:一页的大小为2的次方。
分页可以映射连续虚拟页到不连续物理帧,通过分页可以减少内存的外部碎片external fragmentation(对于一个页而言),但是其页内部internal会产生碎片,因为页是分配的最小单位,最后一页的页内会有剩余部分。

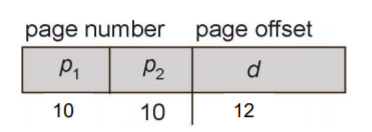
页表 Page Table
页表记录了物理地址的起始地址(基地址)。
页号page number:页表的号码,通过页号在页表里找到物理地址的基地址。
页偏移page offset:页偏移加上上述基地址构成精确的物理地址。
页表长度=页的总数=逻辑地址空间大小除以页大小。
帧的总数:物理地址空间大小除以帧大小。
使用分页方法时,偏移地址不变,
通过页号在页表里查找物理地址的基地址,乘上基大小(既左移偏移地址位数)加上偏移地址,得到物理地址。
下面的页表共3行,查找的第二行:
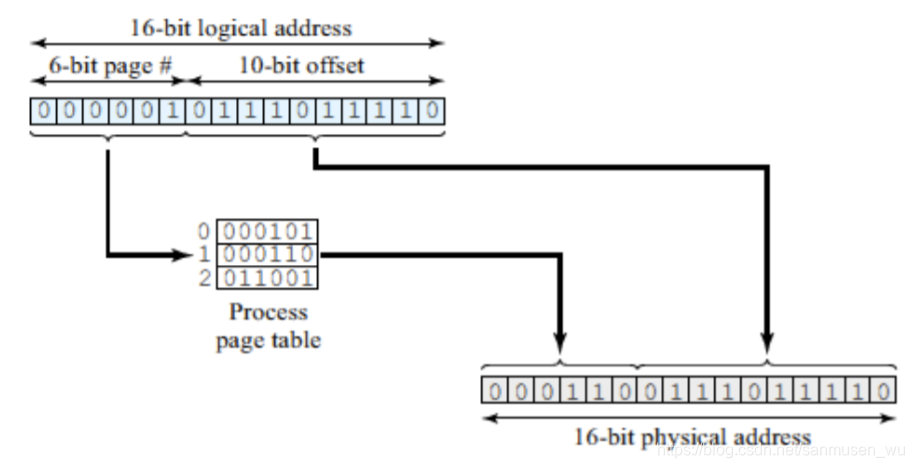
页表的硬件实现:
- 使用正在执行的进程的页表放入内存,使用寄存器指向列表。
·页表基地址寄存器 Page-table base register (PTBR):
页表被记录在内存里,PTBR记录了页表在内存内的位置。
·页表长度寄存器 Page-table length register (PTLR) i:
记录了页表长度。
·总内存访问时间=访问列表条目+内存地址:
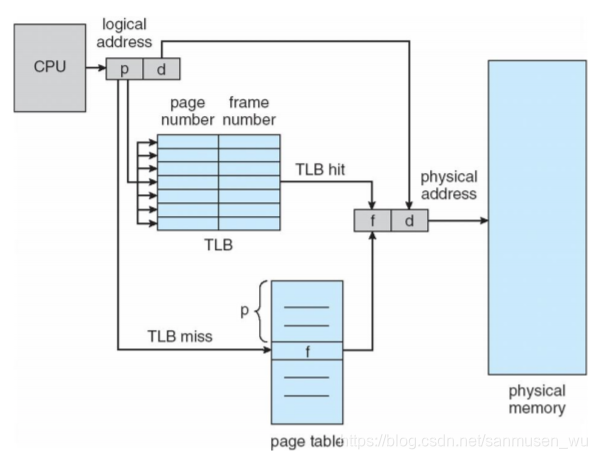
Total memory access time = Time to access page table + Time to access memory location - 使用转换表缓冲区(translation look-aside buffers,TLB):
高速缓冲区,专门放页表。
使用高速缓存尝试映射物理地址时,首先
- E: 访问高速缓冲TLB里查找页号,找到页号得到基地址后就转到第3步
- 如果没有,M: 就访问内存用页表基寄存器寻找页表。
- 找到页号对应的物理基地址后,M:访问内存的物理地址。
TLB命中率(hit radio):能够在缓冲里找到页号的概率A
有效访问时间 the effective memory-access time (EAT):
EAT=A(E+M)+(1-A)(E+2 x M)
有效无效位 Valid-invalid bit
每个进程间都有独立的内存空间和内存空间保护。
在页表上对每个帧设置有效或无效
有效位代表相关页在进程的逻辑空间内
无效位代表相关页不在进程逻辑空间内
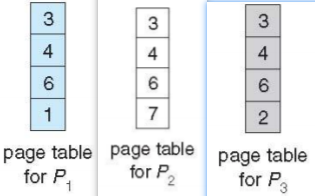
共享页Shared Pages
不仅要保护,还要共享一些资源以节约运算。
· Efficient communication:进程通过写入共享页达到交流
·Memory efficiency:在进程间共享一份只读数据
以下进程的页表间看出共享了3,4,6帧
页表的结构
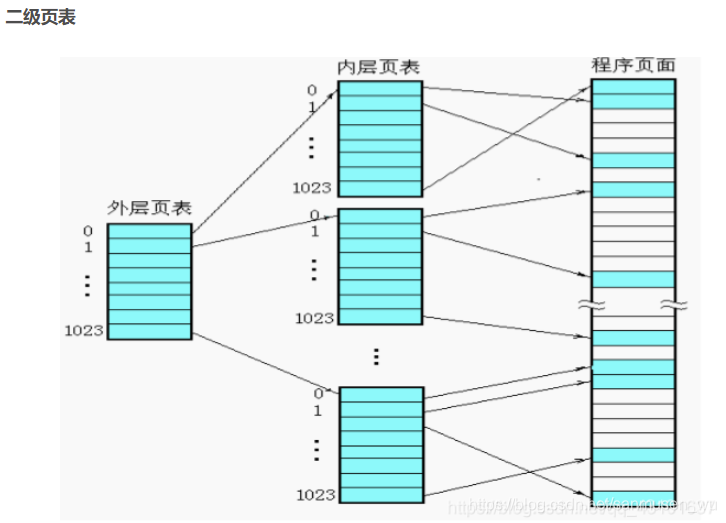
层次页表(Hierarchical Paging )
页表再分页
不妨先按照单级页表做计算
假如:
一页的页面大小为4kB(212B)
页表项(entry size,也就是页表一行的大小)大小为4B(22B)。
操作系统32位(2的32方B),也就是虚拟地址空间为2的32方B,
则可有以下计算结果:
- 单个页能装下212B/22B=210个页表项
- 一个进程有 232B/212B = 220页,意味着页表共有220行,也就是220个页表项
- 页表需要占220/210=210页去存放
- 这存放页表的210页占了210 * 4kB=212kB=4MB空间
我们需要210个页去存放页表,这意味着页表被分散开来了,所以需要一个类似于一张记录书目清单的纸一样的一个页表,记录这些存放了页表的页,这个书目页大小也是4kB(212B)正好可以放下212B/22B=210个记录了页表的页。
因此,将页表分为外层页号和内层页号
p1指向一个小页表,通过小页表偏移p2找到页元素所在小页表位置,这样的页表叫做二级页表
那么有没有可能页表项总数过多,导致一个页表不够索引这些存放了页表的页的情况(一张书目清单不够用)?
有的,这个时候就要使用多个书目清单,然后再建立一个总的记录了书目清单的目录,这样子就叫做三级页表。就需要p1,p2,p3三个值去定位页表项。
哈希页表(Hashed Page Tables)
用来处理超过32位的地址空间,
通过哈希运算将页号转换成固长,
页表的数据结构采用前缀树形式,
用虚拟页号按位匹配前缀树直至最后到达叶子节点,
反转页表(Inverted Page Table)
建立物理内存地址到逻辑内存地址的映射,页表长度为物理帧数量。
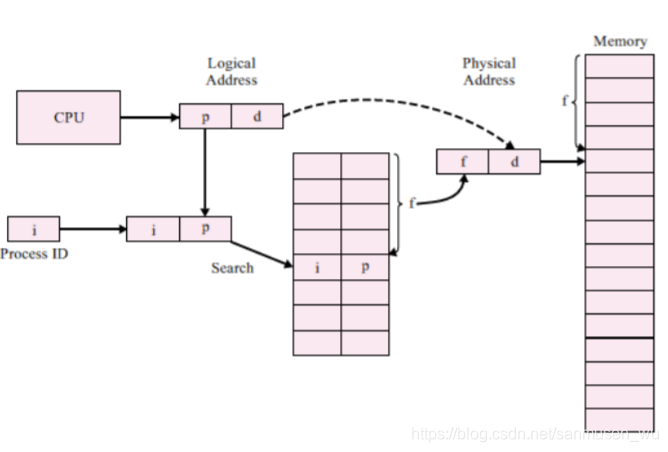
week9 虚拟内存
论16G内存是怎么运行50个G的彩六的.jpg
以下将帧和页都称为页
Virtual Memory 虚拟内存
进程在运行时,往往只需要一部分程序中的数据而不是全部。因此,程序的某一部分只有在被需要的时候才会被加载(移入内存),那些在内存中的部分被称为驻留集resident set。
Demand Paging 按需调页
Lazy swapper:除非页被需要,否则页不会被调入内存。
pager:一个控制程序,控制换页
如何确定页是页否在内存里:
- valid:代表页合法且已进驻内存
- invalid:代表页不合法或未进驻内存
如果进程试图访问内存内没有的页:
- 页不在逻辑地址空间内中→ page fault页无效
- 当发现无效页→ a trap抛出页错误陷阱,让系统注意page fault然后把页换进来
按需调页的有效访问时间The Effective Access Time (EAT)
如果没有无效页(p=0),有效访问时间=访问内存的时间
如果页错误概率是p:
The Effective Access Time (EAT)=(1-p)x 访问内存时间+ p x 页错误处理时间
页错误处理时间包含:
- Service the page-fault interrupt.
- Read in the page.
- Restart the process.
Copy-on-Write 写时复制
创建一些共享页,创建一个空的页缓冲池,当共享页指向的内容遭到写操作,利用缓冲池内的空白页复制这些共享页内容形成一个副本。
常发生于父子进程之间。
写时复制的问题
- 如果形成副本时没有空帧了-》页置换Page replacement,尽可能选择不会发生页无效的那些页。
- 每个进程需要被分配多少帧-》帧分配Frame allocation,发生页置换时,考虑更改帧分配。
Page Replacement 页置换
为什么要页置换-》多道要求使得内存分配过多,没有空闲帧。
页置换的目的-》将重度需要的页保存,将一段时间内不怎么需要的页换出去
页置换的第二个目的-》减少因为页错误导致的延迟
操作步骤:
- 在磁盘上找到需要的页
- 找到空闲帧,如果没有,使用页置换算法选择一个受害者,使用修改位dirty bit记录页是否发生了修改,如果修改了的话,将修改后的数据写回,如果没有发生修改,直接删。
- 把页带到空闲帧里,更新页表
- 继续运行引起trap的进程
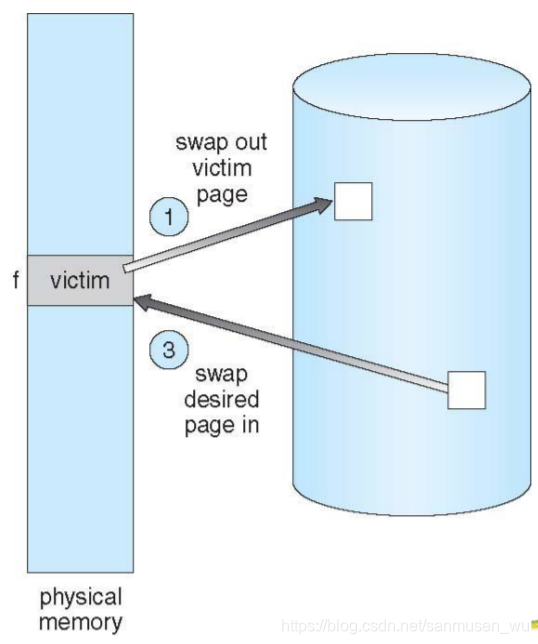
页置换算法
评估算法时,往往是给定请求队列↓进行模拟换页
Reference string : the sequence of pages being referenced.
参考:牛客网
First-In First-Out (FIFO) Algorithm
先入先出
Optimal Algorithm(最佳页面替换算法)
往请求队列后看,谁接下来最晚被用到谁被替换
Least Recently Used (LRU) Algorithm(最近最久未使用算法)
基于“如果数据最近被访问过,它在未来也极有可能访问过”,请求队列向前看,谁之前最长时间没被再次使用谁被替换
- counter implementation
给每个页记录一个最新的被使用时刻,当需要选受害者时,选择时间最小的。 - stack implemantation
用一个栈记录每个页,每当页被使用,将其移动到栈顶,当选择受害者时,选择栈底的。
Second-Chance (Clock) Algorithm
类似于FIFO,添加硬件支持:
页表中加一个reference bit=0,表明该页是否被使用过。每当页被进程访问,bit位被置为1。
维护一个页的换入循环队列c-queue,每次从旧到新遍历队列,如果bit为1,将其置为0,跳过;如果bit=0,将其移出。循环遍历直到找到第一个bit为0的页被置换,置换进来的页放入队列尾部,bit位初始化为0。
Counting Algorithms
记录每页的引用次数
- Least Frequently Used (LFU) Algorithm (最近最不常用算法):
选访问次数最少的页移除 - Most Frequently Used (MFU) Algorithm (最常使用算法):
移除访问次数最多的页
Frames Allocation 帧分配
固定分配 Fixed allocation
平均分配 Equal allocation
100个帧,5个进程,每个进程分20个
按比例分配 Proportional allocation
根据进程规模分,10个帧,两进程一个2成一个8成,那么一个进程分2个另一个进程分8个
·
优先级分配 Priority allocation
考虑了进程的优先级,如果进程抛出页错误,既可以从自己已分配的页更换,又可以去抢低优先级的页。
Thrashing 系统颠簸
由于分配帧不够,进程频繁地换页导致换页时间多于执行时间。
week10 大容量存储
二级存储可以永久存放数据,比内存慢但是偏移。
两种二级存储:
- 顺序访问设备 Sequential access devices
- 直接访问设备 Direct access devices
相关名词:
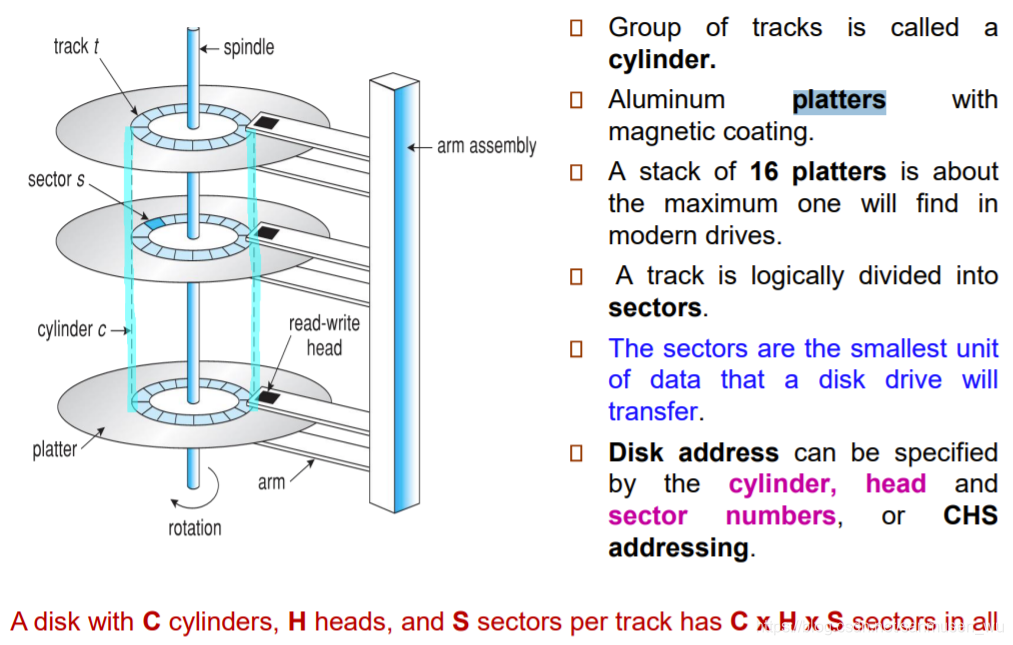

传输速率transfer rate:驱动器和计算机之间的数据传输速率
寻道时间Seek time:磁盘头移动到相应的道所需时间
寻转延迟时间rotational latency:磁盘旋转到相应扇区所需时间
定位时间Random access time:包括寻道时间和旋转等待时间
磁盘访问时间disk access time:包括寻道,旋转,传输的时间。
磁盘结构Disk Structure
可将磁盘看成卷饼,由相连的逻辑块号卷起来
磁盘驱动器Disk controller将逻辑块号映射为柱面surface,磁道track,扇区sector
磁盘访问Disk Attachment
- 通过IO接口
Host-attached storage,直接插在IO接口上,本地访问。 - 通过网络
Network-Attached Storage,NAS,通过网络远程访问。
Storage Area Network,SAN,常见的存储协议,高速访问
磁盘调度Disk Scheduling
为了减少磁盘头寻道的时间等,需要使用合适的算法
需要起始位置和访问顺序。
First-Come First-Served FCFS
谁先来先找锥,最公平
Shortest Seek Time First SSTF
离谁近先找谁,利用率高
SCAN (Elevator)
磁盘头从一侧顶部移动到另一侧顶部,沿途处理请求,到顶后再反向移动到顶,沿途处理请求,更好的服务贡献
Circular-SCAN C-SCAN
磁盘头从一侧顶部移动到另一侧顶部,沿途处理请求,到顶后反向移动回来到顶,沿途不处理请求,灵活性较低
LOOK
SCAN的变种,磁盘头向一个方向移动,同时处理请求,直到移动方向没有请求,再反向移动,同时处理请求。更好的服务贡献
C-LOOK
C-SCAN的变种,磁盘头向一个方向移动,直到移动方向没有请求,再反向移动回初始侧的第一个请求,沿途不处理请求。灵活性较低
磁盘管理Disk Management
· 低级格式化(Low-level formatting, or physical formatting)
分成扇区以便磁盘控制器读写。
·Partition,将磁盘分成由一个或多个柱面组成的扇区
·逻辑格式化(Logical formatting)
将文件系统结构写入盘
引导块 Boot block
自举(bootstrap)存储在ROM中,负责在开机时找到磁盘上的系统引导区,系统引导区中有引导加载程序(Bootstrap loader program),它会找到磁盘上的操作系统内核,装入内存,开始执行系统。
交换空间Swap-Space Management
虚拟内存使用磁盘空间作为主存上的扩展
考虑交换空间的设立:
- 在文件系统中创建交换文件swap file
改变交换文件大小很方便 - 在独立的交换分区 swap partition内
会更快但是因为初始化的限制无法应对过多的系统交换需求
交换空间的管理:
核使用交换映射跟踪交换空间的使用
解决:先使用交换空间,随后建立交换分区
磁盘冗余阵列技术 RAID Structure
Redundant Arrays of Independent Disks
硬盘滞销 帮帮我们.jpg
a system of data storage that uses multiple hard disk drives,viewed by the operating system as a single logical drive.
将多个磁盘组合在一起的磁盘存储系统,操作系统将它们看成一个盘,有不同的存储方式,叫做级别levels,还有个RAID控制器来控制这些磁盘(基于硬件层面或软件层面)
Mirroring镜像,将完整数据写入两个以上盘
Striping分散,将数据拆分成块chunks,写入不同的盘。提高了数据传递速率,因为可以从多个盘同时读不同部分的数据。
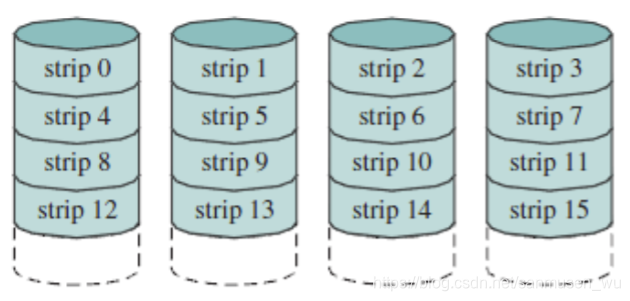
RAID-0:
不提供冗余盘,数据被按照块级分散到各个盘,一个盘出错数据就丢失了。
不提供冗余盘,所以是0级。
RAID-1:
disk mirroring磁盘镜像
每个盘有一个冗余盘,数据被备份了一次。
RAID-2:
memory-style error-correcting-code内存差错纠正代码
需要多个奇偶检测盘,记录数据盘的一个字节中置为1的个数是偶数还是奇数,如果字节的一位损坏或者奇偶位损坏就会被内存系统检测到。磁盘内数据被分散为一个字节或比特。除了奇偶位之外,还会存储多个其他额外位,用来将出错数据重新构造。
RAID-3:
比二级省,因此几乎没有用二级的。
bit-interleaved parity organization 位交织奇偶结构
只需要一个奇偶检测盘,
将字节按照位级分散(一个字节的第k位放在第k个数据盘内)计算得出每个字节的位的奇偶位。由于磁盘能够检测到一个扇区内是否正确读取,再加上奇偶位就可以恢复数据了。
其中奇偶检测盘可以放在额外磁盘上dedicated disk,
RAID-4:
与三级类似,将横向的位分散扩大成了块分散。
block-interleaved parity organization块交织奇偶结构
只需要一个奇偶检测盘,
将字节按照块级分散,然后计算每个磁盘上相对块号相同的块的奇偶块。由于磁盘能够检测到一个扇区内是否正确读取,再加上奇偶块上的奇偶位就可以恢复数据了。
其中奇偶检测盘可以放在额外磁盘上dedicated disk,
RAID-5:
与四级相似,将检测盘平均分布在磁盘中,避免校正资源过于聚集
block-interleaved distributed parity块交织分布奇偶结构
将数据和奇偶检测盘分布在所有资源盘+1块盘上,例如,相对块号为0的奇偶块放0盘,相对块号为1的奇偶块放1盘…
RAID-6:
P + Q redundancy scheme P+Q冗余方案
与级别5类似,但是检验算法不仅仅采用奇偶,
生成P,Q:
P和Q是由两种算法求出的检测位
只有一位错误,使用P就可以恢复,当有两位出错,用P和Q联立求解。
RAID 0+1:
数据先是被块分散,然后对这些已经被分散了的raid0创建数据镜像.
RAID 1+0
数据先被挨个镜像,然后这些raid1互相被块分散
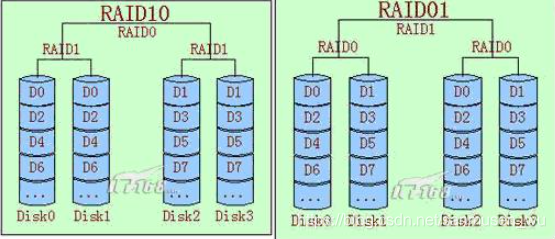
磁盘冗余总结
- RAID is secure because mirroring duplicates all your data
- RAID is fast because the data is striped across multiple disks; chunks of data can be read and written to different disks simultaneously.
- RAID is not a backup. A backup is a copy of data, which
is stored somewhere else and is detached from the original
data both in space and time.
·
- 安全,镜像保存了数据
- 快速,多个磁盘共读写
- 冗余不是备份,备份的数据空间时间与原始数据分离,冗余的数据必须与原始数据放一起
week 11 文件系统
文件属性Attribute:
·name-人可以看懂的形式
·identifier-由文件系统特殊标识的标签
·type-需要系统支持
·location-指向文件位置
·size-文件大小
·protection-控制用户权限
·time,data and user identification-记录文件创建,最后编辑时间,最后使用时间等
文件操作Operations:
·create创建-OS必须能够使用空闲空间创建文件
·write写-通过写指针
·read读-通过读指针
·save保存-保存文件到磁盘上的空间空间
·reposition within file文件重定位
·delete删除
·truncate截断-删除文件内容但是保留属性
·open打开-在进程操作文件之前,文件必须被打开,以加载入内存
·close关闭-不需要的时候移出内存。
Open File Table:因为打开操作会获取相应文件的基础属性,用一个表来记录这些已打开的文件的属性。
文件逻辑策略 logical categories:
· 共享文件shareable files:可以被本地访问和网络共享
· 非共享文件unsharable files:只能本地访问
· 变量文件variable files:可以在任意时刻改变
· 静态文件static files:如果没有系统管理员操作,则不能改变
访问文件的方法 Access Methods
顺序访问 Sequential Access
模拟磁带操作,文件里的内容按顺序被以字节的形式访问
直接访问 Direct Access
直接跳转到相应记录然后读取
下标访问 Indexed Access
使用多个下标,每个下标对应一个文件属性,通过这些索引筛选并搜索主文件中的记录
目录和磁盘结构 Directory and Disk Structure
一个磁盘既可以一整个作为文件系统提供服务,也可以被划分成多个分区,片或小磁盘(multiple partitions, slices, or mini-disks)各自拥有自己的文件系统。
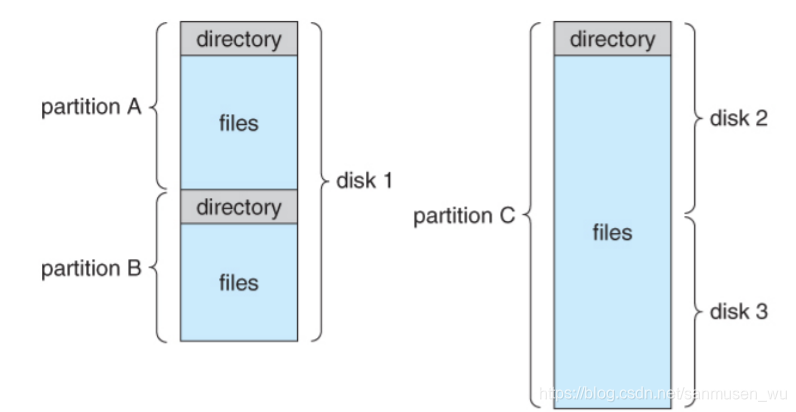
Directory目录
目录逻辑结构 logical structure of a directory
-
single-level directory
单一目录,根目录下记录所有文件

-
two-level directory
为每个用户指定各自的目录,形成主目录和用户目录
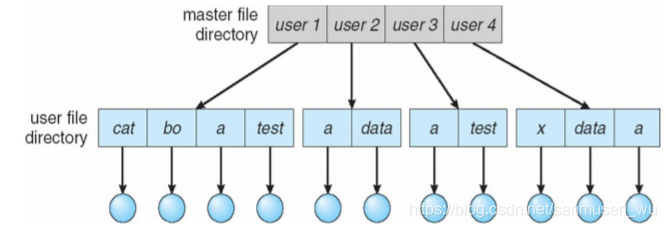
-
hierarchical/tree-structured directories
分层目录,绝对路径absolute path和相对路径relative path
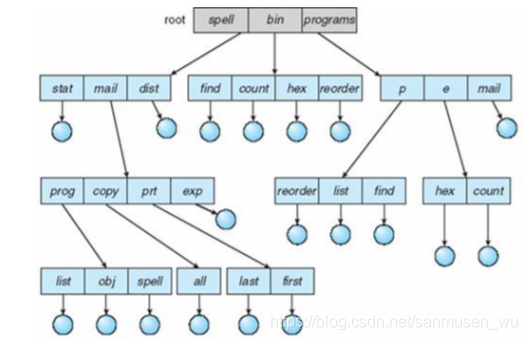
-
acyclic-graph directories
文件目录支持对同一个文件的共享操作,既多个用户操作同一文件
文件被删除后仍然保留指向文件位置的悬挂指针
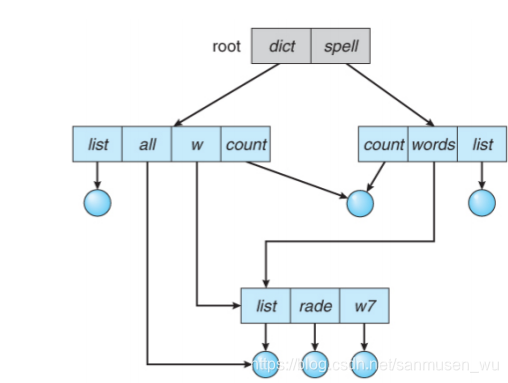
依靠目录可以完成的操作:
- 文件查找 2 文件创建 3. 删除文件 4. 建立目录 5. 重命名文件 6. 遍历文件系统。
系统装载File-System Mounting
· 装载mounting:将设备添加到用户设备上,如:插入U盘
· 装载位置mounting point:附加设备的目录在原文件环境的附加位置,如:U盘在电脑文件目录的位置
Linux or UNIX OS - the user needs to mount all the devices or hard disk partitions explicitly
文件分享 File Sharing
- 通过保护方案protection scheme进行共享
- 在分布式系统中,使用网络共享
- Network File System (NFS)通常是可行方法
多用户分享
在多用户系统中,使用访问权限access rights和同时访问管理the management of simultaneous access。
拥有者owner和组group的概念:
其中user ID区分用户,group ID区分群组,各自有各自的权限范围。
远程分享
手动的FTP;半自动的world wide web;自动的分布式文件系统(distributed file systems)
客户端-服务端模型Client-server model
· 允许用户从服务器装载远程文件系统。
· 服务器可以服务多个客户端
· Network File System NFS是标准的UNIX客户机
· Common Internet File System-CIFS采用Windows协议
· Distributed Information Systems分布式信息系统实现了对远程计算所需信息的同一访问。
远程共享的问题
可能会产生网络或服务器故障,导致文件系统需要应对的故障变多,
复原信息时涉及到了每个远程请求的状态
无状态协议(如NFS)在每个请求中明文展示信息,安全性低,但可以轻松恢复文件
保护Protection
通过限制可以访问的文件类型控制访问
文件创建者应当设定文件操作权限和用户访问权限。
访问控制列表access-control list (ACL)
记录了每个文件的有权限的用户名和每个用户允许的访问类型。
访问模式分为:读read, 写write, 运行execute
· 写包括了打开,读取,编辑等一系列权限。
访问用户分为:拥有者owner,组group,访客public access / universe

文件系统结构File System Structure

文件系统的实现File-System Implementation
文件系统需要包含磁盘上的存储和内存内的访问
On disk structure
- Boot control block:引导控制块,位于每个卷的第一块,负责引导操作系统所需要的核心
- File Control Block:文件控制块,包含文件的信息,如大小,所有者,访问权限,创建日期等。
- Volume control block:卷控制块,包含卷的信息,如分区块数,块大小,空闲块数量等。
- Free list:记录未被分配的块
- Files and directories
On disk structure
- mount table:安装表,包含文件系统安装指针,文件系统类型等。
- system-wide open-file table SOFT:打开文件表,记录每个已打开文件的FCB副本
- per-process open-file table POFT:打开文件表,记录被进程打开的文件信息,每个条目还指向SOFT
- Buffers:缓存,保存访问过的目录信息
打开文件步骤
- 在SOFT中查询,该文件是否已经被其他进程所使用
- 如果是,将会在POFT中创建一个指向SOFT的指针
- 如果不是,遍历所有FCB,找到该文件的FCB,将该文件的FCB移入内存中读取
- FCB在内存中被复制给SOFT,POFT里创建一个指向SOFT的指针
- 文件系统返回指向POFT元素的指针,这个指针被称为file descriptor or file handle
分配方法 Allocation Methods
将文件分配给物理磁盘的不同策略
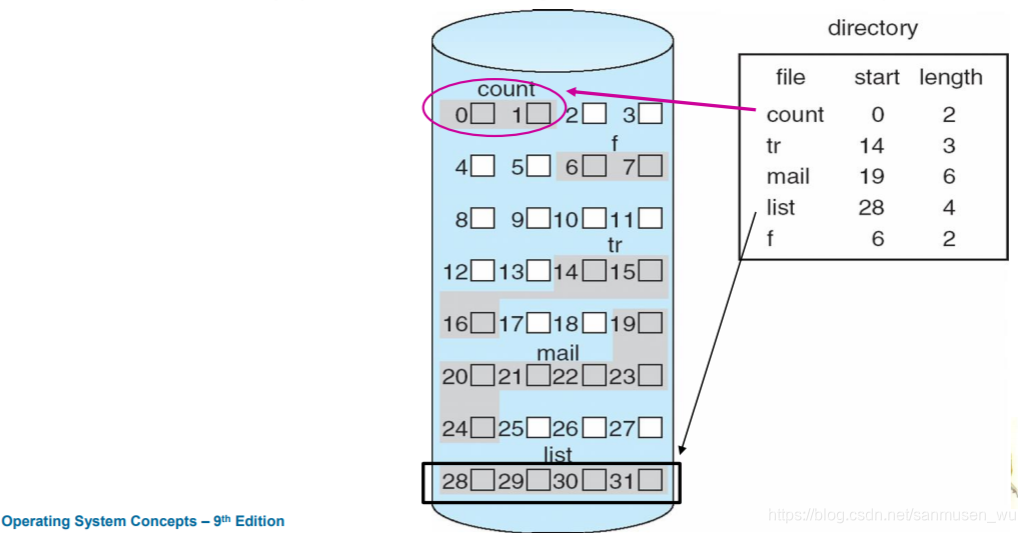
连续分配contiguous
文件会被分配给连续的块
优点:简单,可顺序,可随机
缺点:得找合适的空闲区域,产生碎片fragmentation,
解决方法:
- compaction off-line(downtime) :用一个额外盘转移全部文件清理碎片
- on-line:本地移动文件清理碎片
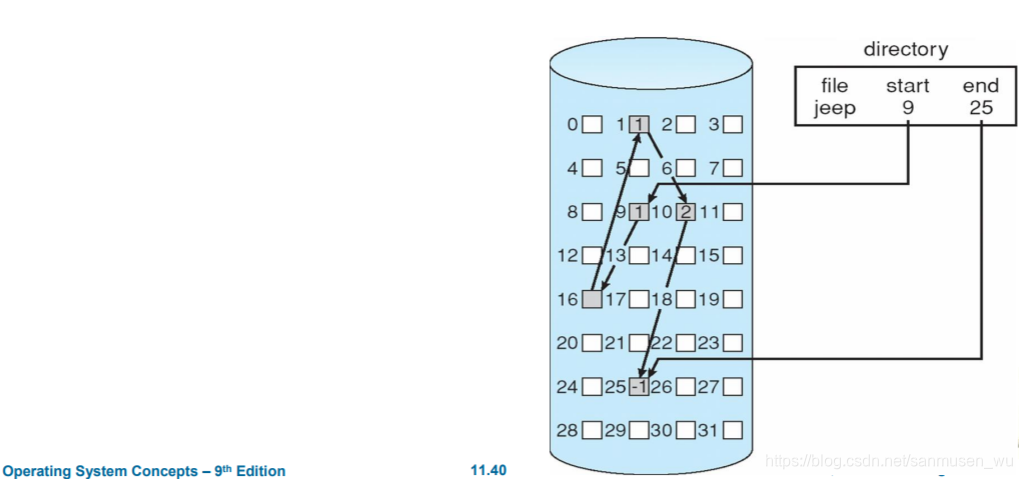
链接分配linked
文件被分配给分散的块,块与块之间以链表形式相连。
优点:简单,没有碎片,文件可以轻松拓展
缺点:存放指针占空间,只能挨个读取,容易断链子
解决:
- 将块聚合成簇(cluster)减少指针数量
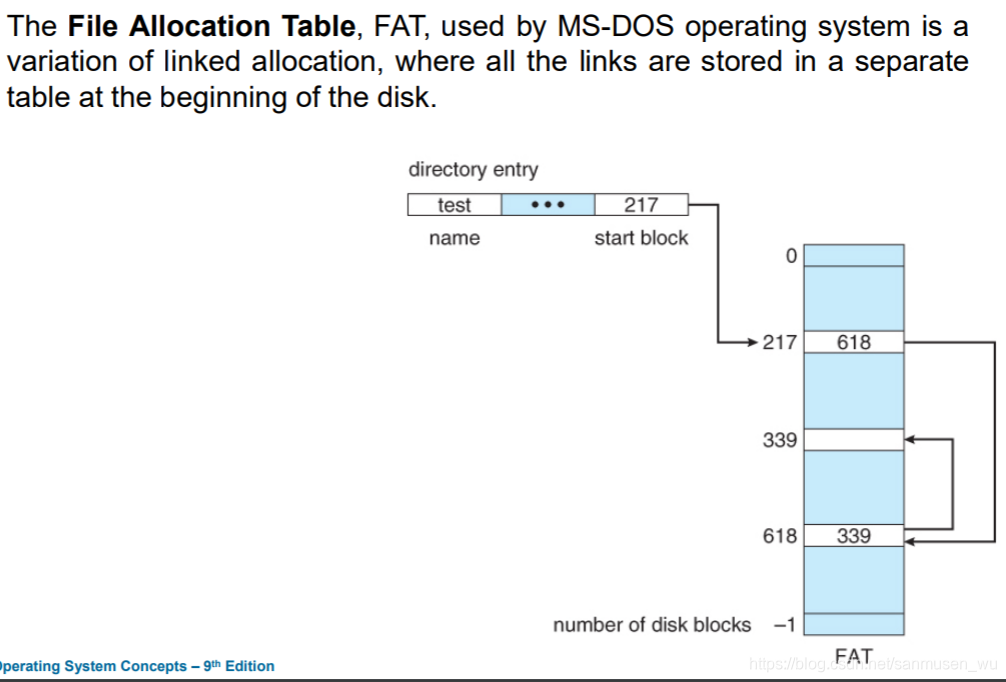
- 采用文件分配表File Allocation Table, FAT:将链表间关系存储为一维链表,放在簇的开头。
File Allocation Table: FAT, used by MS-DOS operating system is a variation of linked allocation, where all the links are stored in a separate table at the beginning of the disk
索引分配indexed
相比于FAT更灵活,把每个文件分散给分散的块,文件系统指向的索引块记录了所有这些分散块的索引和顺序
索引块index block的实现:通过链表(一个索引块连一个索引块),通过多层(第一个索引块连多个索引块)
优点:支持顺序,随机访问,文件大小可变,没有碎片
缺点:小文件也会占据一个完整的块作为索引块,小文件数量多时浪费空间
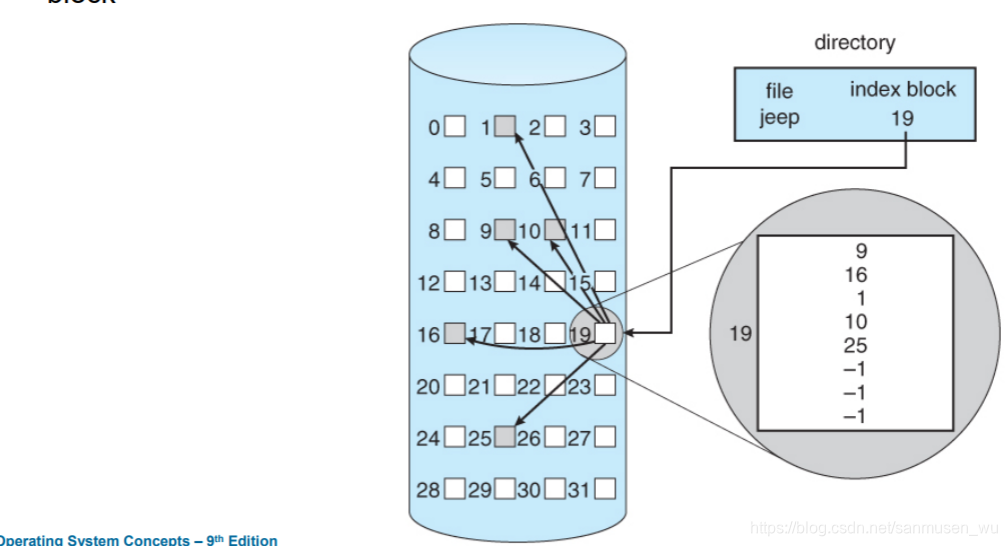
空闲空间管理Free-Space Management
使用空闲空间列表free-space list 记录可用块,五种方法
- bit vector:1表示块可用,0表示块已用
- Linked List:用链表链接所有空闲块
- Grouping:在第一个空闲块内存储其余空闲块索引
- Counting:记录每一个空闲块之后连续空闲块数量
- Space Maps:建立位图,块的使用状态改变时修改位图。
week12 I/O系统
为什么需要设计好的IO系统,
· IO设备五花八门,为此也存在很多控制方法,同时又要面对设备的更新换代
····端口Ports, 总线busses, 设备管理器device controllers与各种设备相连
····设备驱动器device drivers封装了各种运行细节,IO子系统只需要调用相应的接口完成任务即可
数据传输:
····面向字符设备character-oriented device :接受和传递字节流
····面向块设备block-oriented device:接受和传递固定大小的块
访问:
····顺序访问sequential device
····随机访问random access
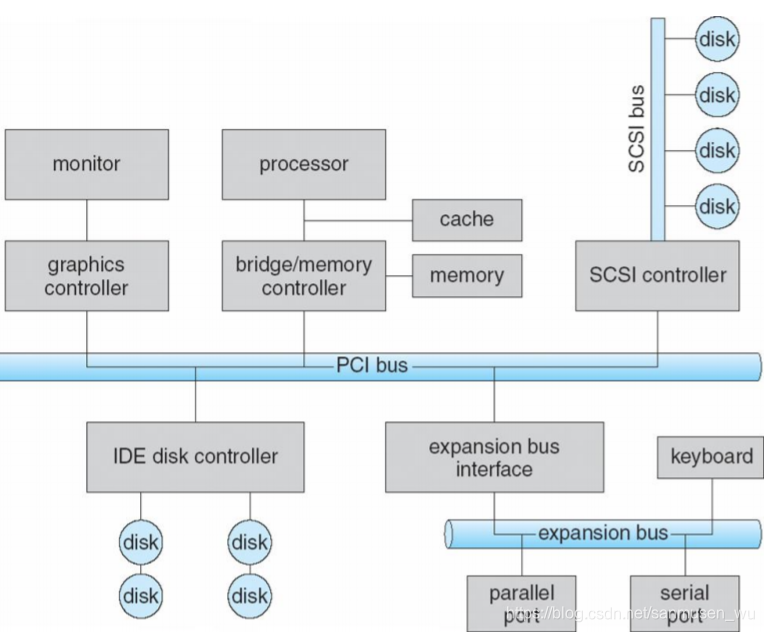
IO硬件 I/O Hardware
Port端口:设备之间的连接点。
Bus总线:daisy chain or shared direct access
····PCI:PC中常见的总线
····expansion bus:连结相对较慢的设备
Controller主机适配器:操作端口,总线和设备的集成电子器件或额外电路板。包含处理器和私有内存,能够通过总线控制器和内存与各种控制器对话。
处理器如何向控制器发送命令执行IO传输:
- 每个控制器中有用于通话CPU的寄存器
- 此外,许多设备还有操作系统可以读写的缓冲区(打印机)
控制器中的寄存器种类:
· data-in register数据输入寄存器
· data-out register数据输出寄存器
· status register状态寄存器-提供任务相关信息(是否完成,是否故障)
· control register控制寄存器-接受主机发送的命令
CPU如何与控制寄存器和设备缓存交流:
- 直接IO指令-Direct I/O instructions
每个寄存器被分配一个8bit或16bit的端号,然后CPU通过IO指令读写控制寄存器 - 内存映射IO-Memory-mapped I/O
把寄存器映射到内存空间,CPU通过内存访问的方式读写
IO通信技术:处于用户请求和设备之间的交流模式
Polling轮询
CPU忙等并定期检测通道状态位,如果通道繁忙,CPU执行其他处理任务直到通道空闲。
Interrupt-driven I/O 中断
CPU使用中断与设备交流,当设备有数据要传输或操作完成时抛出中断请求给CPU,CPU在每个指令周期后会检测中断,随后CPU将控制转到中断处理程序,开始IO传输。
Non-maskable:非屏蔽中断用于严重错误情况
Maskable:可屏蔽中断又设备控制器发起请求
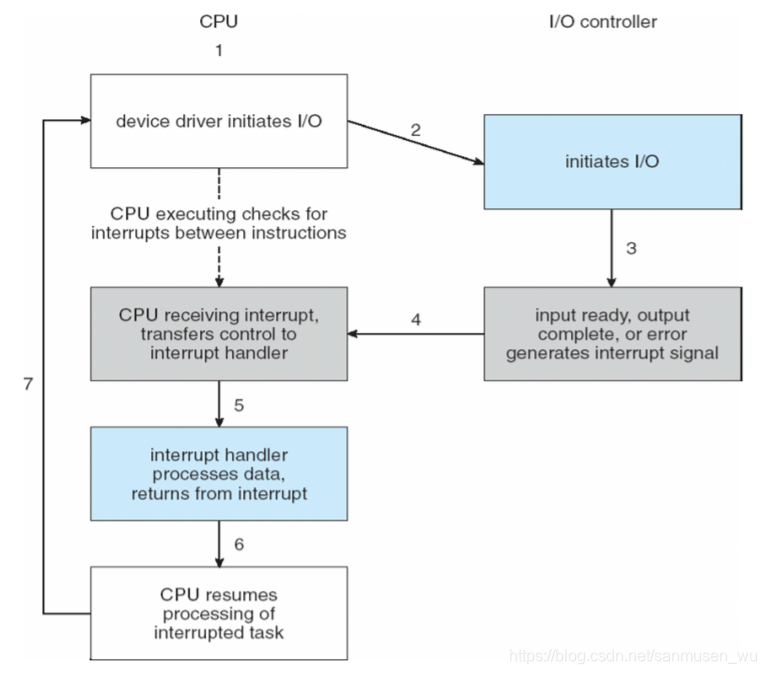
与设备交互的基本协议:
·Wait for drive to be ready
·Write parameters to control registers
·Start the I/O
·Data transfer
·Handle interrupts-简单方法是块中断,更灵活的方法是当传输完成时抛出结束中断
·Error handling
Direct Memory Access直接内存访问
需要硬件支持(DMA controller),适合数据较大的情况,一次读取一个字符块,IO设备和内存间直接传输数据,中断请求由DMA在传输完成时发出。
如果知道虚拟内存,可以更加高效-Direct Virtual Memory Access DVMA
处理IO由DMA完成,通知处理操作又CPU向DMA通知,CPU需要告知DMA以下内容:
· type of request:请求类型(读/写)
· address of the IO device:需要IO的设备地址
· the start address of the data:需要写入或读取的数据在内存中的空间
应用IO接口 Application I/O Interface
设备驱动程序隐藏了IO控制器之间的差异:
- Character-stream or block
- Sequential or random-access
- Synchronous or asynchronous (or both)
- Sharable or dedicated
- Speed of operation
- Read-write, Read only, or Write only
块与字符设备Block and Character Devices
块设备一次访问一块,指令有read,write,seek,包括生IO,直接IO和内存映射。
字符设备一次访问一字节,指令有get,put
网络设备Network Devices
linux,unix,windows和许多其他系统中都包含了socket接口,其中又分为管道(pipes),FIFO,流(streams),队列(queues),邮箱(mailboxes)
时钟与定时器Clocks and Timers
· 当前时间
· 从上个事件过后经过的时间
· 定时器
Programmable Interrupt Timer:
trigger operations and to measure elapsed time
阻塞与非阻塞Blocking and Non-blocking
都是针对发起IO请求的用户操作(进程)而言的:
阻塞 需要内核IO操作彻底完成,才返回用户空间执行用户操作。用户空间操作在这期间被阻塞。
非阻塞无论IO操作是否完全发生,IO请求都会立即返回到用户空间执行用户操作,允许进程检查可用的数据。
内核IO子系统 Kernel I/O Subsystem
调度scheduling
有的IO请求会用队列进行排序,有的会公平对待。
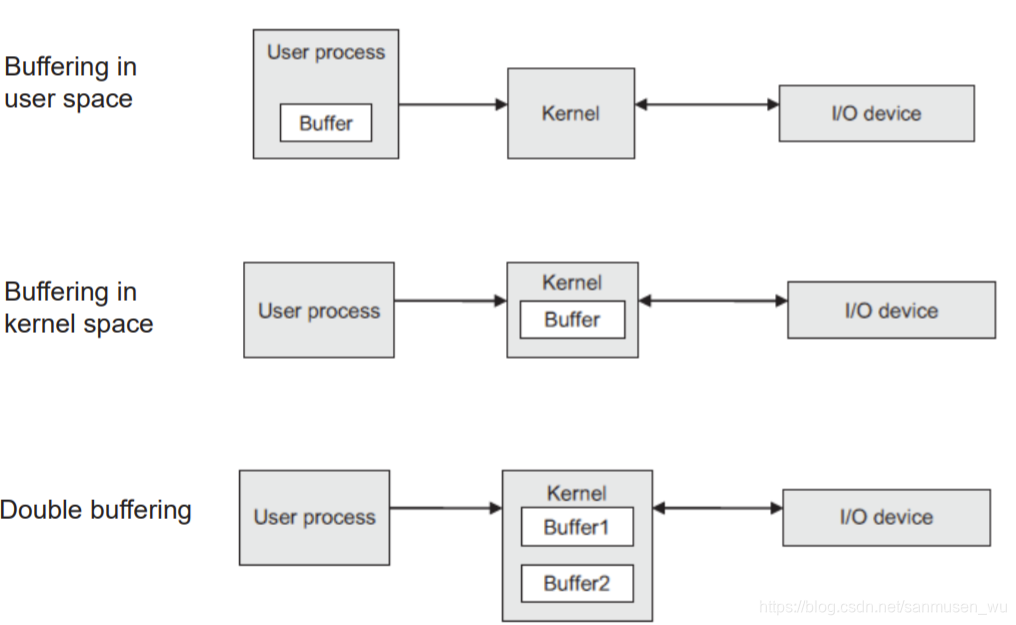
缓冲buffering
存储数据进缓冲,让IO设备能按照自己的处理速度处理。(比如打印机的连续打印)
又被分为:
· Single buffering单缓冲(以用户进程为基础,以核为基础)
· Double buffering双缓冲:允许一个缓冲被使用,另一个缓冲收集信息
有种高速缓存Caching
假脱机Spooling
对于一次只支持一个请求的IO设备,将所有要输出的东西先脱机到一起,放在独立的磁盘文件上,然后添加输出结束时,假脱机系统将这个脱机文件发送到打印机。
设备保留Device reservation
提供对设备的独占访问,由系统分配,会有死锁的问题
错误处理Error Handling
使用受保护的内存的操作系统可以避免多种错误
· IO请求失败可能是暂时的,也可能是永久的
· IO请求通常会返回一个错误位来指示问题
· UNIX系统还有哥全局errno变量
IO保护 I/O Protection
用户进程可能会通过非法IO来中断操作,因此
- 所有IO指令都是特权privileged指令
- IO属于系统调用且内存映射和IO接口内存位置被内存管理系统所保护
核数据结构Kernel Data Structures
核需要为各种IO设备提供:
- 打开文件表
- 网络连结
- 字符设备状态
- 其他东西
流Streams
STREAM – a full-duplex communication channel between a user-level process and a device in Unix System V and beyond
STREAMS(流)是系统V提供的构造内核设备驱动程序和网络协议包的一种通用方法,在用户进程和设备驱动程序之间提供了一条全双工通路。可以想象成一条回环的河流,数据在这些河流之间流动,被用户进程和IO设备所使用。接近用户进程这头叫做流首,
包括:
- stream head:用户进程使用read和write与流首进行交互,在用户进程和流首之间,消息由下列几部分组成:消息类型、可选择的控制信息以及可选择的数据。
- driver end:IO设备拥有的流驱动程序(streams driver)与流尾交互。
- stream modules:0或多个流处理模块被压入流
每个模块包含一个读队列和一个写队列。消息被用于在队列间交流。
· 可以使用流控制Flow control c:如果没有流控制,数据一准备好就被传递。
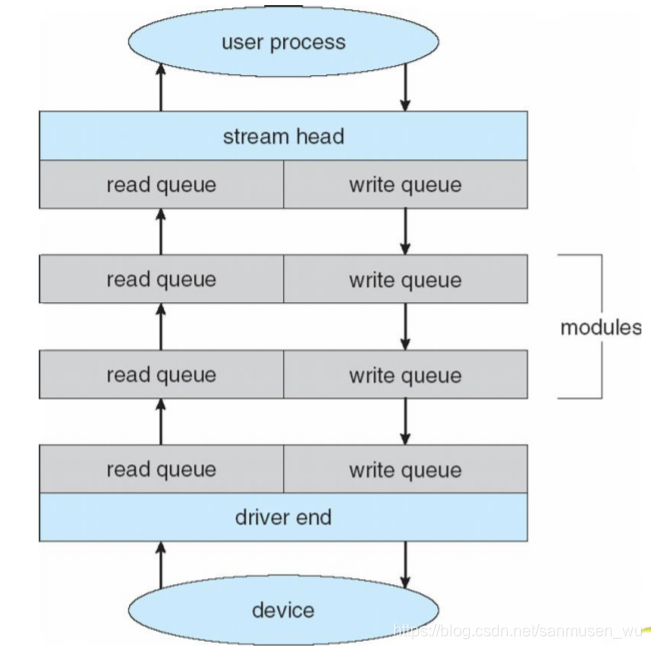
改善空间Iproving Performance
- 减少上下文切换
- 减少数据复制
- 使用大型传输,智能控制器,轮询减少中断
- 使用DMA
- 使用更智能的硬件
- 平衡CPU,内存,总线,IO性能以提高最高吞吐量
- 将用户模式进程,守护进程移到内核线程
week13 保护与安全
后半段全是单词。。。
保护的目的Goals of Protection
- prevent the access of unauthorized users阻止未授权用户的访问
- ensure that each active programs or processes in the system uses resources only as the stated policy确保系统内每个活动的程序按照策略使用资源
- ensure that errant programs cause the minimal amount of damage possible将错误程序造成的伤害尽可能减少
- improve reliability by detecting latent errors检测潜在错误以提高可靠性
保护的准则Principles of Protection
Principle of least privilege:
每个进程,程序,用户,系统都被赋予了足够的权限以执行任务
· 权限可以是静态分配的(static),持续一整个进程周期
· 权限也可以是动态的(dynamic),请求/分配,涉及到domain switching, privilege escalation
保护域Domain of Protection
电脑可以看成进程和物体(软硬件)的集合。
准则之一:Need to know principle:
每个进程应该刚好被允许以访问足够完成任务的任务(不是自己需要的东西就不去请求)
域结构Domain Structure
· Protection domain:
specifies the resources that a process may access
告知进程它可以访问哪些资源(包含 对象set of objects 以及 操作权限types of operations)
· objects:所有计算机内对象:代码,数据,各种硬件
· Access right:访问/操作权限→the ability to execute an operation on an object
· Domain:被定义为对象和权限的集合,其内元素为< object, { access right set } >
访问控制矩阵Access Matrix
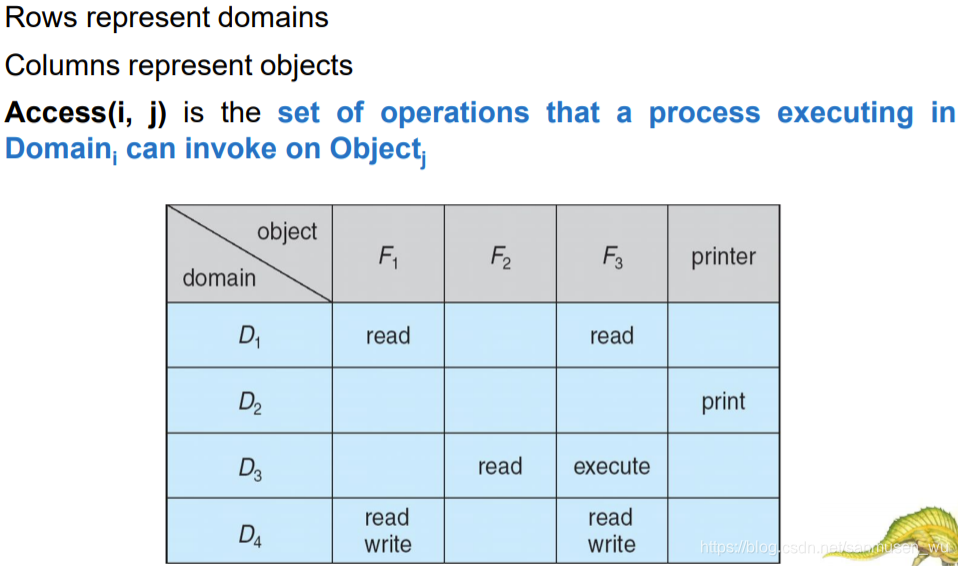
实现控制矩阵Implementation of Access Matrix
- Global Table
最简单的方法是,存储一个总的全局矩阵,包含所有domain元素< object, { access right set } > - Access Lists for Objects
把每列看成对一个对象的访问权限集合列表。 - Capability Lists for Domains
一个列表,存储了对象及其被允许的操作 - A Lock-Key Mechanism
· 每个资源都有一个locks列表,存储了许多二进制数(bit patterns)作为锁
· 每个进程有个keys列表,也存储了许多二进制数作为钥匙
· 当进程想要访问对象时,如果自己钥匙与那个对象锁一样的就被允许。
访问控制Access Control
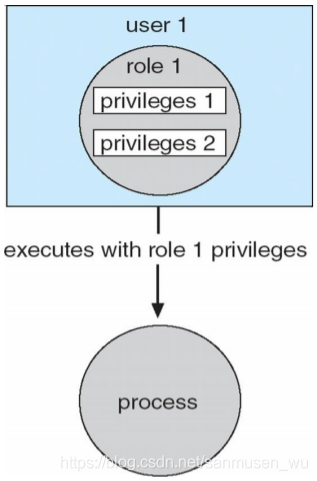
Role-based access control (RBAC)
is a security feature for controlling user access to tasks that would normally be restricted to the root user.
RBAC根据需要为用户或程序提供合适的特权(privileges),以这种安全措施限制通常仅限于root用户的操作
· 特权privileges:指调用某些系统调用,或对系统调用使用某些参数的权限
· 角色roles:特权和程序可以被赋予给角色
访问权限的撤销Revocation of Access Rights
分为许多策略:
· Immediate vs. Delayed
· Selective vs. General
· Partial vs. Total
· Temporary vs. Permanent
安全问题The Security Problem
Security is a measure of confidence that the integrity of a system and its data will be preserved
安全性水平意味着 保护系统及其数据的完整性 的能力
· Secure:如果资源使用和访问如预期的一样,则称系统是安全的
· Intruders (crackers) : 黑客
· Threat :潜在安全问题 potential security violation
· Attack :主动攻击attempt to breach security
···· 无意或有意 accidental or malicious
···· 无意的好对付一点 Easier to protect against accidental than malicious misuse
攻击类型 Security Violation Methods
- Breach of confidentiality 机密
Unauthorized reading of data 未经授权读取 - Breach of integrity 完整性
Unauthorized modification of data 未经授权修改 - Breach of availability 可用性
Unauthorized destruction of data 未经授权销毁 - Theft of service 窃取服务
Unauthorized use of resources 未经授权使用资源 - Denial of service (DOS) 拒绝服务
Prevention of legitimate use 阻碍别人正常使用 - Masquerading伪装 (breach authentication破坏身份验证)
pretending to be an authorized user to escalate privileges 伪装成受权用户进行攻击 - Replay attack
attack in which the attacker delays, replays, or repeats data transmission between the user and the site. 阻碍正常的数据传输 - Man-in-the-middle attack
intruder sits in data flow, masquerading as sender to receiver and vice versa 伪装成发送者 - Session hijacking 会话劫持(cookie side-jacking)
Intercept an already-established session to bypass authentication. 拦截会话
Attackers can perform actions that the original user is authorized to do 然后可执行原本用户可执行操作
安全措施 Security Measure Levels
四个防范层面:
Physical:数据库与服务器安全
Human:人为钓鱼邮件,密码破解
Operating System:系统本身处理危险和防范攻击
Network:对网络的攻击和来自网络的攻击
程序威胁Program Threats
木马,陷阱门,逻辑炸弹,栈溢出,病毒
· Trojan Horse - exploits mechanisms for allowing programs written by users to be executed by other users (Spyware, pop-up browser windows, covert channels)
· Trap Door - is when a designer or a programmer (or hacker) deliberately inserts a security hole that they can use later to access the system.
· Logic Bomb - is a piece of code intentionally inserted into a software system that will set off a malicious function when specified conditions are met.
· Stack and Buffer Overflow exploits a bug in a program (overflow either the stack or heap buffers)
· Viruses - fragment of code embedded in an otherwise legitimate program, designed to replicate itself (by infecting other programs), and (eventually) wreaking havoc.
系统和网络危险System and Network Threats
蠕虫病毒,端口扫描,DOS拒绝服务
· Worm - is a process that uses the fork / spawn process to make copies of itself in order to wreak havoc on a system. Worms consume system resources, often blocking out other, legitimate processes.
· Port Scanning is technically not an attack, but rather a search for vulnerabilities to attack.
· Denial of Service ( DOS ) attacks do not attempt to actually access or damage systems, but merely to clog them up so badly that they cannot be used for any useful work. DOS attacks can also involve social engineering.
密码学工具 Cryptography as a Security Tool
Encryption 加密
使用安全的方式传递密码,需要使用不安全方式传递机密信息之前加密信息,接受信息之后解密信息。
Symmetric Encryption 对称加密
使用同一个密钥(Same key),进行加密( encrypt)和解密 (decrypt)
· 数据加密标准Data Encryption Standard (DES) :is most commonly used symmetric blockencryption algorithm (created by US Govt)
· 三重加密(Triple-DES): 安全性更高
· 高级加密标准-(Advanced Encryption Standard) (AES)
· Rivest Cipher RC4 is most common symmetric stream cipher, but known to have vulnerabilities
Asymmetric Encryption 非对称加密
公开密钥加密数据只有用对应的私有密钥才能解密,反之亦然,私有密钥加密的数据只有公开密钥才能解密。通常,生成一对密钥后,将其中一把作为公钥公开给对方,自己收到对方使用公钥加密后的信息后使用自己保留的私钥解密。
· public key:作为公钥分发
· private key:作为私钥解密
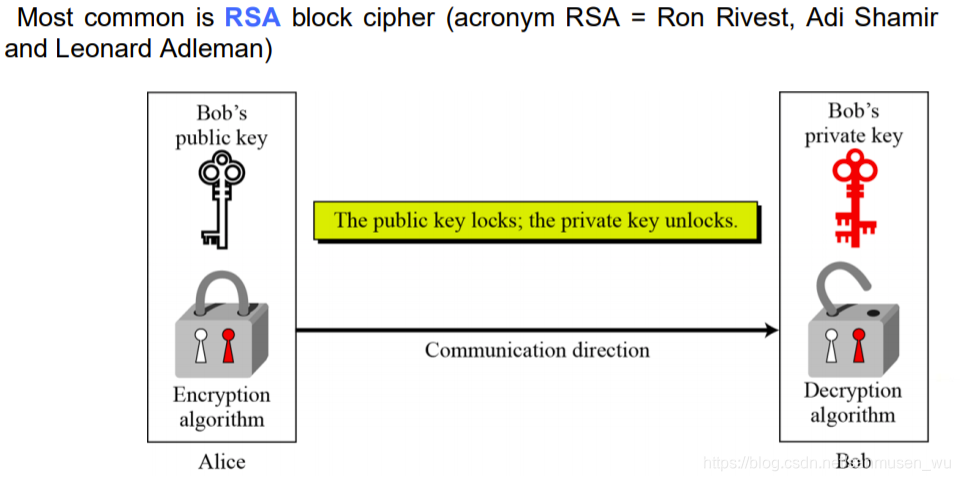
Authentication 身份验证
身份验证识别消息传递方的身份。
服务器记录了每个用户的身份密钥,当特定用户访问时,服务器发送一串随机数给用户,用户将随机数按照身份密钥进行加密,回传给服务器,服务器用自己保存的该用户的密钥进行解密,如果与一开始发送的随机值相同,则通过。
· 签名signatures - an authenticator - a value to be used to authenticate a message.
· 验证verification-produces a value of “true” if the authenticator was created from the message, and “false” otherwise.
- Message Authentication Code (MAC):
使用对称加密,双方密钥一样
a cryptographic checksum is generated from the message using a secret key
使用密钥根据消息生成加密值 - Digital-signature algorithm
使用非对称加密,双方密钥可以互相解密对方加密的内容
Key Distribution 分发密钥
· 对称密钥的分发需要小心,一旦密钥泄露,窃听者就可以解码所有内容。
···· 通过纸传递
· 非对称密钥解决了部分问题,公钥不是机密的(not confidential),可以自由传输,而且方便管理(key-ring is simply a file with keys in it);私钥是私有的,不需要传输,只要确保私钥没有被泄露。但是也需要防范窃听者。
公钥是否安全
解决方法:数字认证digital certificates
证明谁合法拥有一个公钥:
- Public key digitally signed a trusted party
- Trusted party receives proof of identification from entity and certifies that public key belongs to entity
- Certificate authority are trusted party – their public keys included with web browser distributions
- They vouch for other authorities via digitally signing their keys
服务器信任身份认证机构,用户客户端向身份认证机构注册,注册通过后,身份认证机构通过颁发数字证书来证明公钥合法属于该用户端----客户端收到的证书被包含在web浏览器一起被发给服务器----服务器再向身份认证机构核实。
用户身份识别User Authentication
使用密码识别Passwords
· Password Vulnerabilities
密码漏洞
· Securing Passwords - modern systems do not store passwords in clear-text form.
不以明文存储以保护密码
· One-time passwords resist shoulder surfing and other attacks .
一次性密码可抵御攻击
使用生物信息识别Biometrics
Biometrics involve a physical characteristic of the user. 使用用户的生物特征识别用户
实施安全性防御Implementing Security Defenses
主要方法和技术:
· Security Policy
· Vulnerability Assessment
· Intrusion Detection
· Virus Protection
· Auditing, Accounting, and Logging
纵深保护Defense in depth
Defense in depth is most common security theory – multiple layers of security
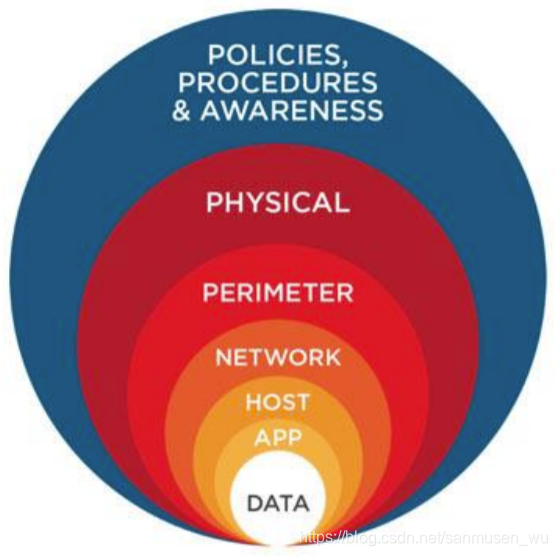
评估脆弱性 Vulnerability Assessment
如何评估安全性策略的有效性
定期检查系统:
Periodically examine the system to detect vulnerabilities:
❑ Port scanning.端口扫描
❑ Check for bad passwords. 密码检查
❑ Unauthorized programs in system directories. 系统目录下的未授权程序
❑ Incorrect permission bits set. 权限位不对
❑ Program checksums / digital signatures which have changed.被篡改的程序校验和数字签名
❑ Unexpected or hidden network daemons. 意料之外或隐藏的网络守护进程
❑ New entries in startup scripts, shutdown scripts or other system scripts or configuration files. 启动脚本,关机脚本或其他系统脚本中的新条目
❑ New unauthorized accounts. 新的未授权账户
入侵检测 Intrusion Detection
尝试检测攻击
· 基于标志 Signature-based:扫描网络上/系统文件,扫描已知的那些被攻击时展现的特征(敏感权限/端口)
· 异常检测 Anomaly detection:将已知的正常活动与观测到的事件进行比较,以确定不正常操作(“unusual” patterns of traffic or operation)
· Intrusion Detection Systems(IDSs)
入侵检测系统,检测到入侵时警告用户
Intrusion Detection and Prevention Systems(IDPs)
过滤路由器(filtering routers),当检测出时可疑流量(suspicious traffic)时关闭它。
病毒防护 Virus Protection
Modern anti-virus programs are basically signature-based detection systems, which the ability (in some cases) of disinfecting the affected files and returning them back to their original condition.现代反病毒程序基本上都是基于病毒特征码进行检测,某些情况下能够对受影响的文件进行消毒并使其恢复。
帮助检测异常行为:
Auditing, Accounting, and Logging
• can be used to detect anomalous behavior.
week14 虚拟机与分布式系统
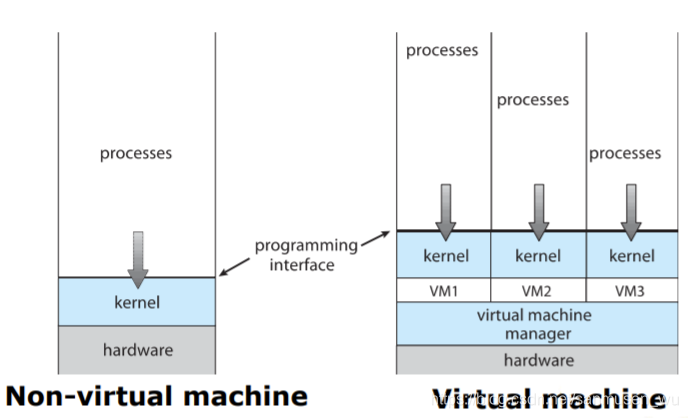
虚拟机Virtual Machines
将一个电脑的硬件分成多个高效的、隔离的环境,并且可以同时运行许多操作系统。
组成部分
- Host:最基本的,可以支持运行这些虚拟机的硬件系统(Windows/Linux/MacOS这些)
- VMM(Virtual machine manager):也叫hypervisor,是个系统软件,管理计算机系统的真实资源,负责将host的各种接口提供给虚拟机
- Guest:操作系统(Windows/Linux/MacOS这些),就像客人一样寄宿在真实硬件系统里。
虚拟机监控技术Hypervisor technology/VMM
A layer between the hardware (the physical host machine) and the Virtual Machines (guest machines). hypervisor essentially separates the operating system and applications in a computer from the underlying physical hardware.
提供了位于硬件和虚拟机之间的层,使得计算机中的操作系统和应用程序互相分割开,并同时使他们与底层物理硬件分隔。
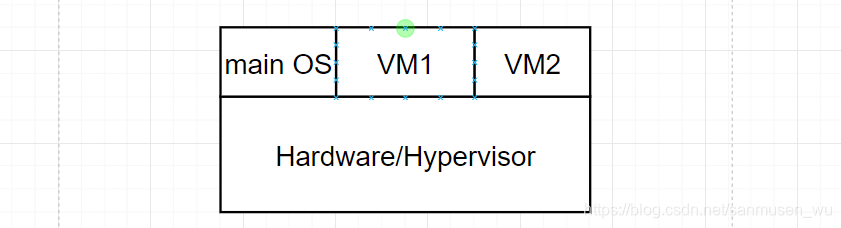
VMM的实现-Implementation of VMMs
1. Type 0 hypervisors
Hardware-based solutions that provide support for virtual machine creation and management via firmware直接基于硬件本身对虚拟机的解决方案
例子:IBM LPARs and Oracle LDOMs
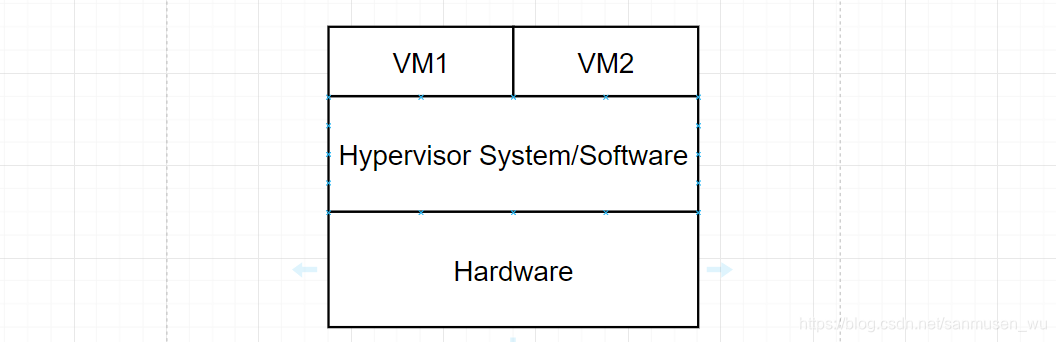
2. Type 1 hypervisors
Operating-system-like software built to provide virtualization
在硬件上建立一个类似于操作系统一样的VMM软件,这个软件支持虚拟化操作
例子:VMware ESX, Joyent SmartOS, and Citrix XenServer
注意:这个VMM软件(Type 1 hypervisors) 是直接运行在系统硬件上的,因此虚拟机获得硬件的完全权限
例子:Microsoft Windows Server with HyperV and RedHat Linux with
KVM
3. Type 2 hypervisors
Applications that run on standard operating systems but provide VMM features to guest operating systems
硬件上有个操作系统(Host OS)作为基础,VMM软件在这个操作系统之上建立,虚拟机权限被Host系统限制
例子:VMware Workstation and Fusion, Parallels Desktop, and Oracle VirtualBox
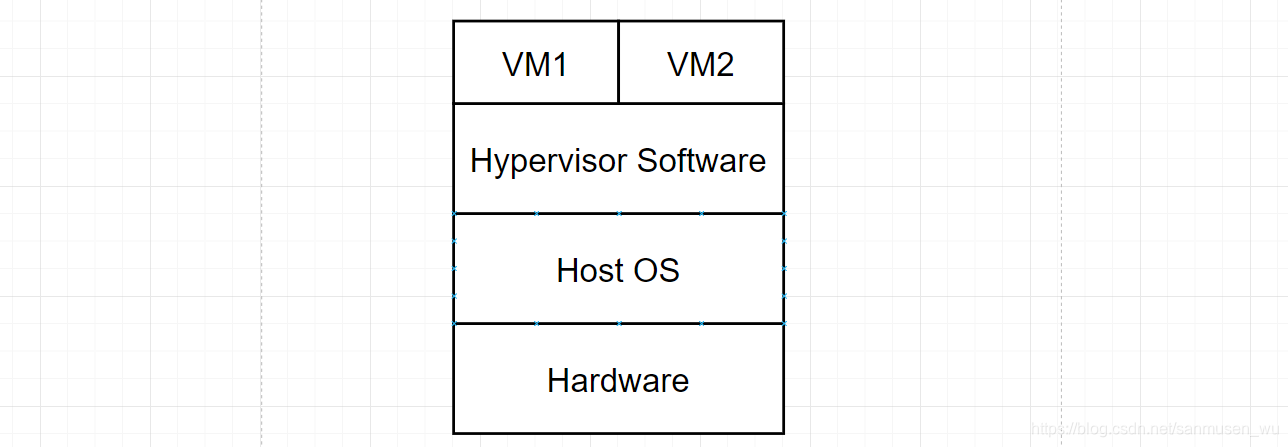
4. Paravirtualization
technique in which the guest operating system is modified to work in cooperation with the VMM to optimize performance
5. Programming-environment virtualization
VMMs do not virtualize real hardware but create an optimized virtual system
例子:used by Oracle Java and Microsoft.Net
6. Emulators
allow applications written for one hardware environment to run on a very different hardware environment, such as a different type of CPU
7. Application containment
provides virtualization-like features by segregating applications from the operating system, making them more secure, manageable
例子:Oracle Solaris Zones, BSD Jails, and IBM AIX WPARs
VMM的好处
· 在同个硬件上同时运行不同的操作系统的好处:
- Host 与 Guest 互相分离,Guest之间互相隔离,使得病毒不太可能传播,进而保护了各种系统。
· 互相隔离(isolation)的缺点:阻止了资源的共享 - a perfect for operating-system research and development
便于研究操作系统 - virtualized workstation allows for rapid porting and testing of programs in varying environments.更方便的移植与调试程序
- Consolidation involves taking two or more separate systems and running them in virtual machines on one system.整合分离的系统
- improve resource utilization and resource management. 提高资源利用和资源管理
- Live migration – move a running VM from one host to another.实时迁移,既VM可在host之间转移
分布式系统Distributed Systems
Distributed system is a loosely-coupled architecture, wherein processors are inter-connected by a communication network. 分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。----博客园
名词解释: Processors=nodes=computers=machines=hosts 以下都称为节点
The processors and their respective resources for a specific processor in a distributed system are remote, while its(指的是分布式系统) own resources are considered as local.
分布式系统内的各个节点和节点所属资源是远程的,但是当用户面对分布式系统时,这些资源被认为是系统的本地资源。
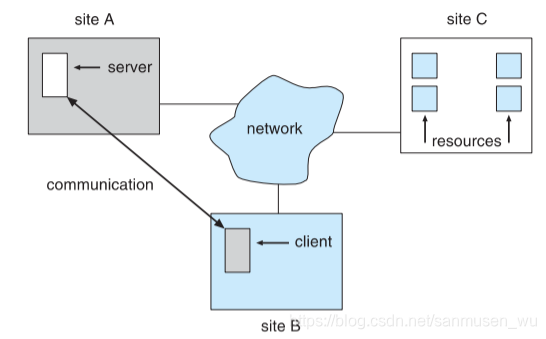
为什么要分布式系统
- 资源共享 Resource sharing
· 远程共享资源或打印文件;在分散的数据库(distributed database)中处理数据;使用某些远程专用设备(remote specialized hardware devices) - 计算速度的提升 Computation speedup
load sharing or job migration
分散在不同的节点上同时进行计算 - 可靠性 Reliability
detect and recover from site failure, function transfer, reintegrate failed site; may utilize an alternative path in the network, in case of any failure.
个别节点错误时可以有效检测和恢复,重新整合,也可用网络中的备选节点替代失效节点 - 交流 Communication
通过网络远距离传输数据 - 经济 Economy and Incremental growth
当提升单机系统算力所需要的高端设备而耗费的价钱高昂到得不偿失的时候,就可以考虑使用分布式系统,用一堆中端设备组成分布式系统,提供了一种高性价比的解决方案。同时,DS的规模也可以随着设备的增加随时扩大。
面向网络的操作系统 Types of Network-oriented OS
Network Operating Systems
· Remote logging into the appropriate remote machine (telnet, ssh)-登录
· Remote File Transfer - transferring data from remote machines to local machines, via the File Transfer Protocol (FTP) mechanism-文件传输
· Users must establish a session-用户必须与服务器建立会话
Distributed Operating Systems
· Data Migration – transfer data by transferring entire file, or transferring only those portions of the file necessary for the immediate task-数据传输
· Computation Migration – transfer the computation, rather than the data, across the system-传输算力,而不是将数据
· Process Migration – execute an entire process, or parts of it, at different sites-进程可以在不同节点间迁移
完

















 2325
2325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









