






在桌面环境中使用网络摄像头进行眼睛注视跟踪
前言
本文为翻译搬砖和总结一些自己的心得体会。
作者:Yiu-ming Cheung; Qinmu Peng,发布于2015年
摘要
本文使用低成本、更方便的网络摄像机在桌面环境中解决视线跟踪问题,而不是使用需要特定硬件的视线跟踪技术,例如红外高分辨率摄像机和红外光源,以及繁琐的校准过程。在该方法中,我们首先在实时视频序列中跟踪人脸以提取眼睛区域。然后,我们将强度能量和边缘强度相结合来获得虹膜中心,并利用分段眼角检测器来检测眼角。我们采用正弦头部模型来模拟三维头部形状,并提出了一种自适应加权面部特征,该特征通过正交和缩放迭代算法嵌入到姿势中,从而可以估计头部姿势。最后,通过整合眼睛矢量和头部运动信息来完成眼睛注视跟踪。分别在BioID数据集和姿势数据集上进行实验以估计眼睛运动和头部姿势。此外,在桌面环境下,在实时视频序列中进行了视线跟踪实验。该方法对光照条件不敏感。实验结果表明,我们的方法在没有头部移动的情况下平均准确度约为1.28°,在头部轻微移动时平均准确度为2.27°。
1. 介绍
视线跟踪有许多潜在的诱人应用,包括人机交互、虚拟现实和眼病诊断。例如,它可以帮助残疾人有效地控制计算机[1]。此外,它还可以支持用眼睛控制鼠标指针,这样用户可以加快焦点的选择。此外,用户视线和面部信息的集成可以提高现有门禁系统的安全性。眼睛凝视已用于研究人类认知[2]、记忆[3]和多元素目标跟踪任务[4]。沿着这条线,视线跟踪与视觉显著性的检测密切相关,视觉显著性可以揭示一个人的注意力焦点。
为了完成视线跟踪的任务,人们提出了许多方法。大多数早期的视线跟踪技术都使用隐形眼镜[5]和电极[6]等侵入性设备,需要与用户进行身体接触;这种方法会给用户带来一些不适。用头戴式设备(如头饰[7]、[8])跟踪视线,侵入性较小,但从实用角度来看不方便。相比之下,基于视频的视线跟踪技术可以提供有效的非侵入性解决方案,更适合日常使用。
基于视频的凝视方法通常使用两种成像技术:红外成像和可见光成像。前者需要红外摄像机和红外光源来捕获红外图像,而后者通常使用高分辨率摄像机来拍摄图像(见图1)。由于红外成像技术利用不可见的红外光源来获得受控光和更好的对比度图像,因此可以减少光照条件的影响,并在虹膜和瞳孔之间产生鲜明的对比(即亮暗眼效应),以及瞳孔和角膜的反射特性(PCCR)[9]-[12]。因此,基于红外成像的方法能够执行视线跟踪。大多数基于视频的方法都属于这一类。不幸的是,基于红外成像的视线跟踪系统可能非常昂贵。其他缺点包括:1)红外成像系统在其他红外源的干扰下不可靠;2) 并非所有用户都会产生明暗效果,这会导致视线跟踪器失效;以及3)红外光源在眼镜上的反射仍然是一个问题。
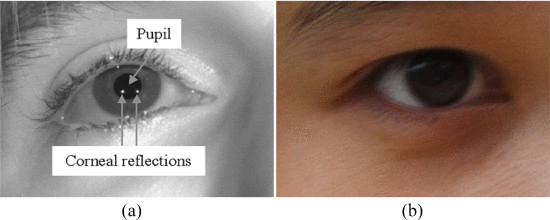
图1.(a) 红外光下的图像[12]。(b) 可见光下的图像。
与红外成像方法相比,可见光成像方法避免了上述问题,而不需要特定的红外设备和红外光源。它们对环境中的玻璃和红外源的使用不敏感。可见成像方法应在自然环境中工作,在自然环境下,环境光不受控制,通常会导致低对比度图像。虹膜中心检测将变得比瞳孔中心检测更困难,因为虹膜通常被上眼睑部分遮挡。
在这篇文章中,我们专注于可视成像,并提出了一种在桌面环境中使用网络摄像机进行视线跟踪的方法。首先,我们在实时视频序列中跟踪人脸以提取眼睛区域。然后,我们结合强度能量和边缘强度来定位虹膜中心,并利用分段眼角检测器来检测眼角。为了补偿头部运动引起的视线误差,我们采用正弦头部模型(SHM)来模拟三维头部形状,并提出了一种嵌入POSIT算法(AWPOSIT)中的自适应加权面部特征,从而可以估计头部姿态。最后,通过整合眼睛矢量和头部运动信息来执行眼睛注视跟踪。本文的主要贡献如下。
-
该方法能够容忍光照变化,鲁棒地提取眼睛区域,为虹膜中心和眼角的检测提供了一种准确的方法。
-
针对姿态估计误差,提出了一种新的加权自适应姿态估计算法;从而提高视线跟踪的准确性。
本文的其余部分组织如下:第二节介绍了相关研究。第三节介绍了所提出的视线跟踪方法的细节,包括眼睛特征检测、校准和姿态估计。在第四节中,我们对所提出的方法的性能进行了实证研究。第五节是结论。
2. 相关研究
本节概述了基于特征和基于外观的可视成像视线跟踪方法。基于特征的注视跟踪依赖于提取眼睛区域的特征,例如虹膜中心和虹膜轮廓,这些特征提供眼睛运动信息。Zhu和Yang[13]从强度图像执行特征提取。使用预设的眼角滤波器提取眼角,并通过插值的Sobel边缘幅度检测眼睛虹膜中心。然后,通过线性映射函数确定视线方向。使用该系统,用户必须保持头部稳定,因为视线方向对头部姿势敏感。Valenti等人。[14] 计算眼睛位置和头部姿势,并将其组合。Torricelli等人。[15] 利用虹膜和角点检测方法获得几何特征,并通过通用回归神经网络(GRNN)将其映射到屏幕坐标。一般来说,系统的估计精度严重依赖于GRNN的输入向量,并且会随着输入向量的任何元素的误差而恶化。Ince和Kim[16]开发了一种低成本的视线跟踪系统,该系统利用了基于形状和强度的可变形瞳孔中心检测和运动决策算法。他们的系统在低分辨率视频序列上运行,但精度对头部姿势敏感。
基于外观的视线跟踪不明确地提取特征,而是利用整个图像来估计视线。沿着这条路线,Sugano等人。[17] 在增量学习框架内提出了一种在线学习算法,用于视线估计,该算法利用用户在PC监视器上的操作(即鼠标点击)。每次单击鼠标时,他们都会创建一个训练样本,将鼠标屏幕坐标作为与特征(即头部姿势和眼睛图像)关联的注视标签。因此,获取大量样品是很麻烦的。为了降低培训成本,Lu等人。[18] 提出了一种分解方案,包括初始估计和后续补偿。因此,使用训练样本可以有效地进行视线估计。Nguyen[19]首先利用一种新的训练模型来检测和跟踪眼睛,然后使用眼睛的裁剪图像来训练用于视线估计的高斯过程函数。在他们的应用中,用户必须在训练过程后稳定他/她的头部在相机前的位置。类似地,Williams等人。[20] 提出了一种稀疏半监督高斯过程模型来推断视线,简化了训练数据的采集过程。然而,许多未标记的样品仍在使用。Lu等人。[21]提出了一种基于局部模式模型(LPM)和支持向量回归器(SVR)的视线跟踪系统。该系统使用LPM从眼睛区域提取纹理特征,并将空间坐标输入SVR以获得视线映射函数。Lu等人。[22]引入了一种自适应线性回归模型,通过使用较少的训练样本从眼睛外观推断视线。
总之,基于外观的方法可以避免仔细设计视觉特征来表示视线。相反,他们利用整个眼睛图像作为高维输入,通过分类器预测视线。分类器的构建需要大量的训练样本,这些样本包括在不同条件下观看屏幕上不同位置的受试者的眼睛图像[17]、[19]、[21]、[23]。这些技术通常降低了对图像分辨率的要求,但它们对头部运动和光线变化以及训练样本的数量敏感。相比之下,基于特征的方法能够提取显著的视觉特征来表示注视,例如,[13]、[16],即使在光照轻微变化的情况下,也能产生可接受的注视精度,但不能容忍头部移动。[14]和[15]中的研究通过考虑头部移动来估计视线,以补偿头部移动时的视线偏移。
3.提出的方法
面部图像中最显著的注视特征是虹膜中心和眼角。当观看屏幕上的不同位置时,眼球在眼窝中移动。眼角可以被视为一个参考点,眼球中的虹膜中心会改变其位置,从而指示眼睛的凝视。因此,由眼角和虹膜中心形成的视线矢量包含视线方向信息,可用于视线跟踪。然而,当头部移动时,视线矢量对头部移动敏感,并产生视线误差。因此,应估计头部姿势以补偿头部运动。
我们的三阶段基于特征的眼睛注视跟踪方法使用眼睛特征和头部姿势信息来提高注视点估计的准确性(见图2)。在阶段1中,我们提取包含眼睛运动信息的眼睛区域。然后,我们检测虹膜中心和眼角以形成眼睛矢量。阶段2获得映射函数的参数,该映射函数描述了眼睛矢量和屏幕上的注视点之间的关系。在阶段1和阶段2中,校准过程计算从眼睛矢量到监视器屏幕坐标的映射。阶段3需要头部姿势估计和凝视点映射。它将眼睛矢量和头部姿态信息相结合以获得注视点。
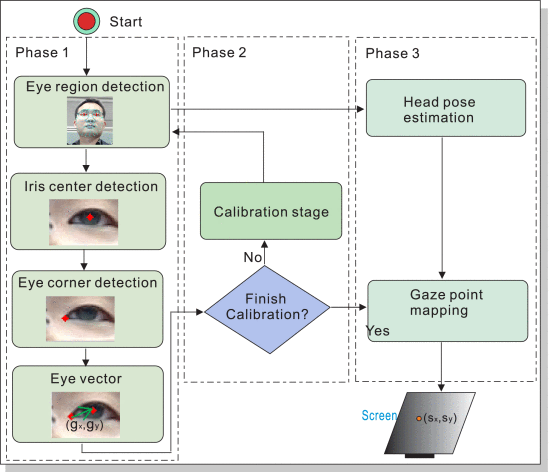
图2.基于三阶段特征的视线跟踪方法。
A. 眼睛区域检测
为了获得眼睛矢量,应该首先定位眼睛区域。传统的人脸检测方法不能在不受控制的光线下和自由的头部移动的情况下提供准确的眼睛区域信息。因此,一种有效的方法应该解决照明问题并提出问题。在这里,我们提出了一种两阶段检测眼睛区域的方法。
在第一阶段,我们利用局部敏感直方图[24]来应对各种照明。与正常强度直方图相比,局部敏感直方图嵌入了空间信息,并随直方图计算像素位置的距离呈指数下降。局部敏感直方图的使用示例如图3所示,其中三幅具有不同照明的图像已通过局部敏感直直图转换为具有一致照明的图像。

图3.(a) 输入图像[25]。(b) 结果使用局部敏感直方图。
在第二阶段,我们采用主动形状模型(ASM)[26]在灰度图像上提取面部特征,通过该特征消除了光照变化。使用ASM的面部特征提取的细节如下。
1)特征选择:选择明显的特征,每个特征表示为(xi,yi),并表示为向量x=(x1,⋅⋅⋅xn、y1,⋅⋅⋅,yn)T。因此,面部形状由一组n个界标点描述。
2) 统计形状模型:应对齐一组地标点(即训练图像),以分析新形状并将其合成到训练集中的形状。它使用主成分分析方法
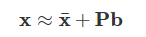 (1)
(1)
其中x¯是平均形状,P包含对应于最大特征值的顶部t个特征向量,并且b=(b1,b2,…,bn)T,其中bi是限制为±3√ λi的形状参数,以便产生合理的形状。
3) 拟合:我们通过平移t、旋转θ和缩放s使模型形状拟合新的输入形状,即
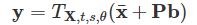 (2)
(2)
其中y是包含面部特征的向量。可以使用改进版本的ASM提取眼睛区域。在图4中,在不同的照明和头部姿势下,检测每个图像中的眼睛区域。

图4.(a) 灰度图像上的ASM结果。(b) 将ASM结果映射到原始图像并提取眼睛区域。
B. 眼睛特征检测
在眼睛区域,虹膜中心和眼角是两个显著的特征,通过这两个特征我们可以估计视线方向。因此,以下两个部分将重点讨论虹膜中心和眼角的检测。
1) 虹膜中心检测
使用前面的步骤提取眼睛区域后,将在眼睛区域中检测虹膜中心。我们首先估计虹膜的半径。然后,结合强度能量和边缘强度信息来定位虹膜中心。
为了估计半径,我们首先使用L0梯度最小化方法[27]来平滑眼睛区域,这可以去除噪声像素并同时保留边缘。随后,可以通过颜色强度获得虹膜中心的粗略估计。然后,在眼睛区域上使用精明的边缘检测器。存在一些长度较短的无效边。因此,应用距离滤波器来去除离虹膜粗糙中心太近或太远的无效边缘。随机样本一致性(RANSAC)用于估计虹膜的圆模型的参数。在RANSAC应用于虹膜的边缘点之后,可以计算虹膜的半径r。
最后,我们结合强度能量和边缘强度来定位虹膜中心。我们分别用E1和E2表示强度能量和边缘强度

其中I是眼睛区域并且Sr是具有与虹膜相同半径的圆形窗口。gx和gy分别是像素的水平梯度和垂直梯度。为了检测虹膜中心,我们应该最小化圆形窗口中的强度能量,最大化虹膜边缘的边缘强度。权衡由参数τ控制。那就是
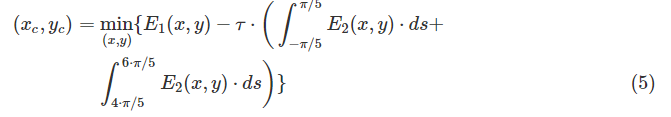
其中(xc,yc)是虹膜中心的坐标。积分间隔为[−15π,15π]和[45π,65π],因为虹膜边缘的这些范围不与眼睑重叠。此外,虹膜边缘的弧对应于半径为r的圆中相同范围的弧。我们通过位于弧上的每个像素的边缘强度之和计算积分。图5显示了虹膜中心检测的结果,其中图5(a)-(c)位于同一视频序列中。也就是说,图5(a)是第一帧,其中可以使用所提出的算法精确地检测虹膜中心。因此,我们获得虹膜的半径,作为后续帧中虹膜检测的先验知识。因此,假设虹膜半径不随用户与计算机屏幕之间的大距离而改变,我们可以检测眼睛图像的虹膜中心,如图5(b)和(c)所示。
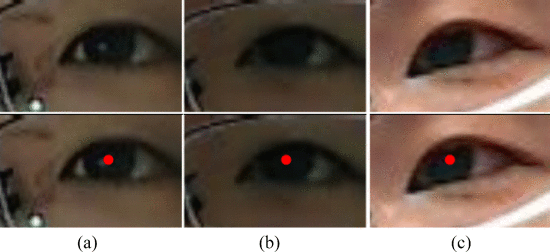
图5. 第一行显示了不同的眼睛区域,而第二行给出了虹膜中心的检测结果。
2) 眼角检测
通常,内眼角被视为视线估计的参考点,因为它对面部表情变化和眼睛状态不敏感[28],并且比外眼角更显著。因此,我们应该检测内眼角以保证视线方向的准确性。我们提出了一种基于曲率尺度空间和模板匹配复查方法的分段眼角检测方法。我们对前面提到的平滑眼睛图像执行步骤。使用canny算子生成边缘图;然后从边缘图中提取边缘轮廓并填充小间隙。每个点μ的曲率定义如下
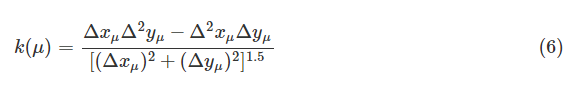
其中Δxμ=(xμ+l−xμ−l) /2,Δyμ=(yμ+l−yμ−l) /2,Δ2xμ=(Δxμ+l−Δxμ−l) /2,Δ2yμ=(Δyμ+l−Δyμ−l) /2,并且l是一小步。根据原始线段的平均曲率(k_ori),在不同比例下计算每个线段的曲率。高斯滤波器的尺度参数σG=exp(−x2/σ2)设为σ2=0.3∗k_ori。我们将局部极大值视为初始角点,其绝对曲率应大于阈值,该阈值是相邻局部极小值的两倍。然后,当T形连接点非常靠近其他拐角时,我们将其删除。此外,我们计算每个角的角度。候选内眼角的角度落入限制范围[120∘,250∘] 因为眼角是两条眼睑曲线的交点。因此,基于该条件选择真正的候选眼睛内角。然后,我们使用从训练眼睛图像中生成的眼睛模板来寻找最佳匹配角作为内眼角。为了构建眼角模板,从不同年龄的10名男性和10名女性的眼睛图像中选择20个内眼片。每个补丁的大小为13×13,每个补丁的中心对应于手动标记的眼角。内眼模板由20个斑块的平均值构成,如图6所示。
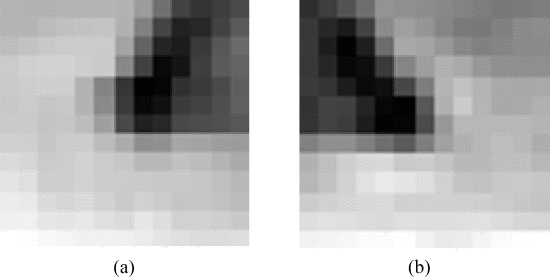
图6. 内眼角模板,其中(a)左眼角模板,(b)右眼角模板。
最后,使用模板匹配方法来定位具有最佳响应的眼角。该度量使用归一化相关系数
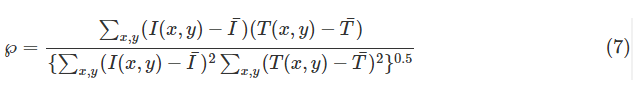
其中I(x,y)是眼睛图像,I是平均值,T(x,y)是模板,T是平均值。角点检测结果如图7所示。
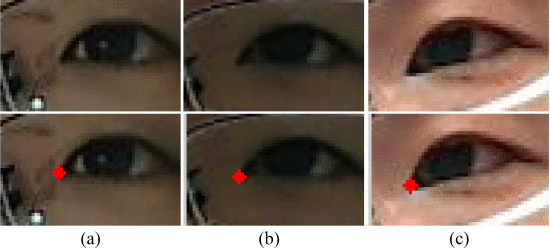
图7. 第一行:眼睛区域,第二行:眼角检测结果。
C. 眼睛矢量和校准
当我们观察屏幕平面上的不同位置,同时保持头部稳定时,眼睛矢量由虹膜中心p_iris和眼角p_corner定义,即g=p_corner−p_iris。它通过映射功能提供视线信息以获得屏幕坐标。校准程序是在记录相应的眼睛矢量的同时,向用户提供一组要查看的目标点。然后,眼睛矢量和屏幕上的坐标之间的关系由映射函数确定。可以使用不同的映射函数,例如简单线性模型[13]、SVR模型[21]和多项式模型[29]。在实践中,简单线性模型的精度不够,SVR模型需要更多的校准数据。幸运的是,二阶多项式函数是校准点数量和近似精度之间的良好折衷[30]。在我们的校准阶段,使用二阶多项式函数,要求用户查看九个点(见图8);计算眼睛矢量并且知道相应的屏幕位置。然后,二阶多项式可以用作映射函数,它通过眼睛矢量计算屏幕上的注视点,即场景位置
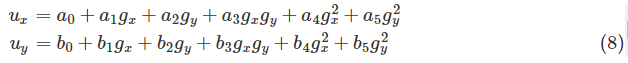
其中(ux,uy)是屏幕位置,(gx,gy)是眼睛矢量,(a1,…,a5)和(b1,……,b5)是可以使用最小二乘法求解的映射函数的参数。我们量化了计算机屏幕上的投影误差,发现虹膜中心或眼角的像素偏差将导致屏幕上大约100像素的偏差。因此,利用映射函数,可以在每个帧中有效地计算用户的注视点。
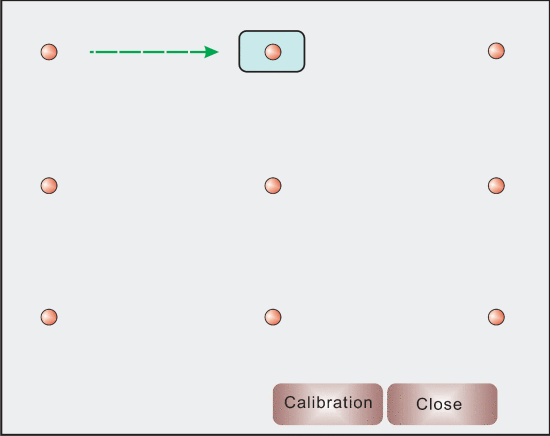
图8. 屏幕上的九个位置(1024×1280像素)。
D、 头部姿势估计
本节详细介绍了视频序列中的面部特征跟踪和头部姿态估计算法。先前的头部姿势估计方法主要使用立体相机[21]、[31]、头部形状的精确3D数据[32]或有限的头部旋转[33]。实时解决方案受到头部模型复杂表示或精确初始化的限制[14]。通常,为了简单起见,可以将人头建模为椭球体或圆柱体,并使用人头的实际宽度和半径进行测量。一些人使用圆柱形头部模型(CHM)来估计头部姿势[34]–[36],这可以实时执行并大致跟踪头部的状态。
为了改善头部姿势的估计,我们使用SHM来模拟三维头部形状,因为椭球体和圆柱体不突出面部特征。SHM可以更好地近似不同面的形状。2-D面部特征可以与正弦表面上的3-D位置相关。当在每个视频帧中跟踪二维人脸特征时,可以利用二维-三维转换方法获得头部姿态信息。正射和缩放迭代(POSIT)的姿势[37]是一种2-D–3-D转换方法,用于在给定一组2-D图像和3-D对象点的情况下获得3-D模型的姿势(即旋转和平移)。为了更好地估计头部姿势,我们提出了AWPOSIT算法,因为经典的POSIT算法基于一组2D点和3D对象点通过均匀考虑它们的贡献来估计3D模型的姿势。对于二维面部特征,由于其可靠性,它们在重构姿势方面具有不同的意义。如果某些特征没有被准确检测到,使用经典的POSIT算法,估计姿态的总体精度可能会急剧下降。所提出的AWPOSIT可以使用关键特征信息获得更准确的姿态估计。实施细节如下。
SHM假设头部形状为三维正弦(见图9),面部由正弦曲面近似。因此,3-D正弦的运动是一种刚性运动,可由帧Fi处的姿态矩阵M参数化。姿势矩阵包括第i帧处的旋转矩阵R和平移矩阵T。

其中R∈R3×3是旋转矩阵,T∈R3×1是平移向量,T=(tix,tiy,tiz)T,M1至M4是列向量。相对于初始姿势计算每个帧处的头部姿势,并且对于初始帧(即,标准正面),旋转和平移矩阵可以设置为0。在初始帧上使用ASM模型来获得二维面部特征。然后,随着时间的推移,在后续帧中使用Lucas–Kanade(LK)特征跟踪器[38]算法跟踪这些特征。由于这些面部特征与正弦模型上的3-D点有关,这些点的运动被视为头部运动的总结,因此我们利用针孔相机模型的透视投影来建立正弦表面上3-D点与其在2-D图像平面上的对应投影之间的关系。图9显示了正弦曲面上的3-D点p=(x,y,z)T与其在图像平面上的投影点q=(u,v)T之间的关系,其中u和v通过

其中f是相机的焦距.
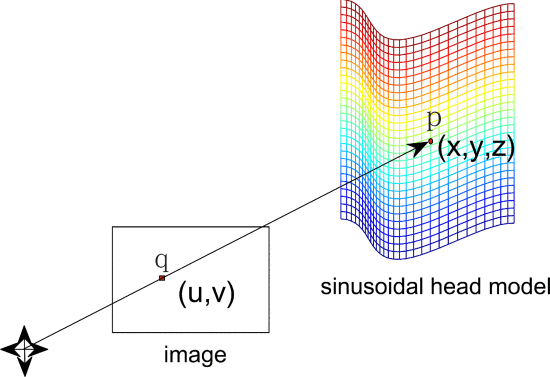
图9. 三维点p在图像平面上的透视投影。
由于二维面部特征对于重构姿态信息具有不同的意义,我们考虑两个因素来衡量面部特征:1)面部特征的鲁棒性,以及2)面部特征在三维表面中的法线方向。第一因子w1将值分配给面部特征以指示其重要性。特别地,强特征应该被分配更大的权重,因为它们可以为姿态估计提供更可靠的信息。这些特征(见图10)分为六类,每一类根据其在实验中的鲁棒性获得不同的权重:
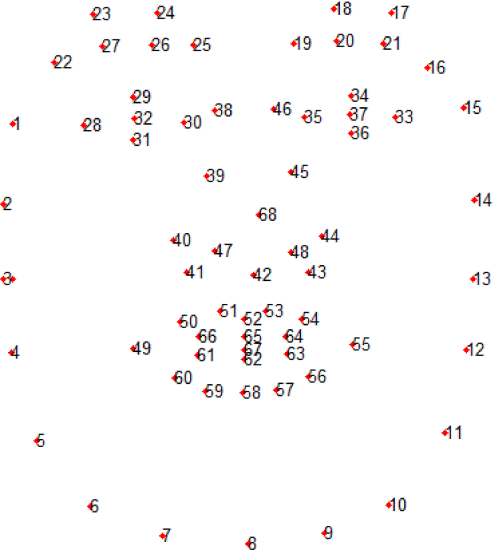
图10. 面部特征的位置。
- 颊点w1(1:15)=0.011;
- 眉毛点w1(16:27)=0.017;
- 眼点w1(28:37)=0.011;
- 鼻点w1(38:48)=0.026;
- 口点w1(49:67)=0.011;
- 鼻尖点w1(68)=0.03。
第二个因素利用面部特征的法线方向来衡量其贡献。法线方向可以通过先前的姿势来估计。设单位向量h表示初始正面姿势的法线方向。每个面部特征点都有一个法线向量bi,和
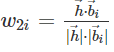
表示第i个面部特征的重要性。wi向量=w1i⋅w2i表示第i个特征的总权重。然后,将wi向量归一化以获得权重wi,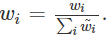
二维面部点表示为P2D,正弦模型上的三维点表示为P3D。AWPOSIT算法在算法1中给出。
跟踪模式通过初始正面上的2-D面部特征获取全局头部运动的值。然后,使用LK跟踪器算法跟踪这些特征,AWPOSIT确定视频帧中的姿势信息。如果AWPOSIT无法收敛,跟踪模式将停止,重新初始化将再次检测二维面部特征。然后,可以恢复跟踪模式。图11显示了头部姿态估计的示例,其中可以从旋转矩阵R中获得三维旋转角度(即偏航、俯仰、侧倾)。

图11.姿势估计示例。
当头部姿态算法可用时,我们可以通过头部运动来补偿视线误差。它估计头部姿态,并计算头部运动引起的相应位移(Δux,Δuy)。假设头部的初始3-D坐标表示为(x0,y0,z0),其在图像平面上的投影位置为(u0,v0)。头部移动时,头部的坐标为(x′,y′,z′)。相应的参数R和T由AWPOSIT估计

因此,位移(Δux,Δuy)可以通过

提取眼睛矢量并采用校准映射函数来获得屏幕上的注视点(ux,uy)。结合来自眼睛矢量的注视方向和来自头部姿势的位移,最终注视点(sx,sy)可以通过

算法2中总结了所提出系统的实现步骤。

4. 评估
对眼睛特征检测、头部姿态估计和视线估计进行了评估。
A. 眼睛中心检测
眼睛中心的检测是眼睛特征检测中的一项困难任务。眼睛中心检测的准确性直接影响视线估计。为了通过所提出的算法评估眼睛中心的检测精度,使用了数据集BioID[39],该数据集由在不同照明和尺度变化下从23个对象收集的1521个灰度图像组成。在某些情况下,眼睛会被眼镜遮住。数据集中提供了眼睛中心的地面真实情况。
为了测量精度,Jesorsky等人提出了归一化误差e。使用[39]

其中,dleft和dright是估计的眼睛中心与地面真实中的眼睛中心之间的欧几里德距离,d是地面真实中眼睛之间的欧氏距离。
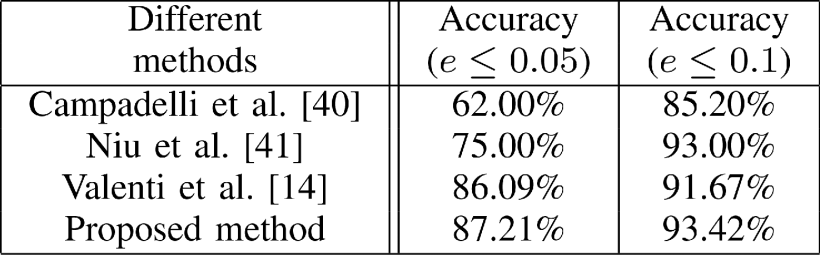
表I显示了与其他方法相比,归一化误差小于0.05和0.1的结果≤0.1),所提出的方法优于其他方法。在更准确的情况下(即≤与其他方法相比,所提出的方法实现了更好的精度。图12显示了BioID数据集上虹膜中心的示例结果。所提出的方法可以在不同的条件下工作,例如姿势、照明和比例的变化。在大多数闭眼和眼镜情况下,由于眼睛区域的鲁棒检测,它仍然可以粗略估计虹膜中心。由于ASM无法提取面部特征,因此会出现较高角度的头部姿势。

图12. BioID数据集上的结果示例[39]。
表I.不同方法Bioid数据集的性能
B. 头部姿势估计
由于眼睛注视是由眼睛矢量和头部运动确定的,所以头部姿态估计用于补偿眼睛注视,从而可以减少注视误差。波士顿大学[36]提供了用于性能评估的头部姿势数据集。通常,姿态估计误差由三个旋转角度(即俯仰、偏航和侧倾)的均方根误差测量。
表II给出了使用An和Chung[42]、Sung等人提出的方法评估姿态估计的结果。[35]和Valenti等人。[14]. An和Chung[42]使用三维椭球模型模拟头部并获得姿势信息。Sung等人。[35]建议结合主动外观模型和CHM来估计姿态。与本研究类似,Valenti等人。[14] 提出了一种结合眼睛位置线索和CHM来估计姿态的混合方法。在[14]中,结果与[35]相当。所提出的方法使用SHM和自适应加权POSIT提高了头部姿态的精度。
表II.波士顿大学头位数据集四种方法的性能
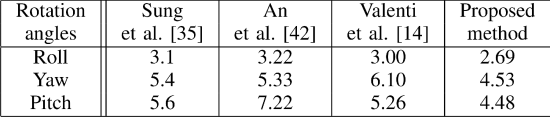
图13(a)-©显示了头部运动的三个跟踪例子,包括俯仰、偏航和滚转。每个姿态跟踪的例子都是在一个包含200帧的视频序列上进行的。图13(d)-(f)显示了估计的水头旋转角度和地面真实度。
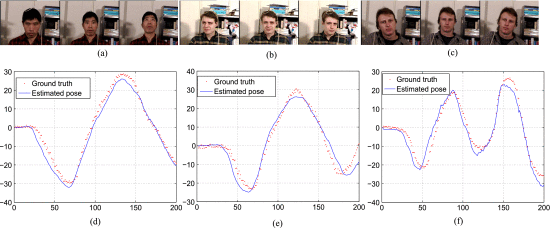
图13.波士顿大学头部姿势数据集中的头部运动示例(a)俯仰(llm6)(b)偏航(jim1)(c)侧倾(jam1))(d)估计俯仰(e)估计偏航(f)估计侧倾。
C. 凝视估计
眼睛注视跟踪系统包括一个网络摄像机,用于获取图像序列(见图14)。它使用了一台分辨率为960×720像素的罗技网络摄像头,安装在电脑显示器下方。计算机硬件配置为Intel Core(TM)i7 CPU 3.40 GHz。受试者与屏幕之间的距离约为70厘米,每个受试者都坐在电脑屏幕前,使其头部完全被摄像机捕捉。每个受试者看屏幕上的9个目标点40次,通常在不到15分钟内完成。实验在桌面环境中进行,其中光线可以来自荧光灯、LED或阳光。
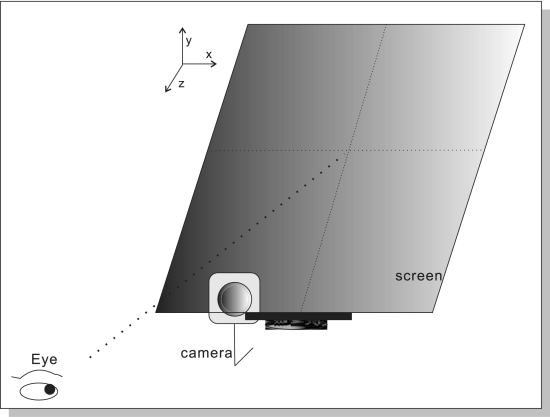
图14. 设置注视跟踪系统,屏幕尺寸为1024×1280像素。
所提出的系统的性能包括无头部运动的注视跟踪和有头部运动的视线跟踪。眼睛注视跟踪系统的精度通过角度(Adg)来测量

其中Ad是估计的注视位置和实际观察位置之间的距离,Ag表示对象和屏幕平面之间的距离。Adg越小,眼睛注视跟踪的精度越高。
1) 无头部移动的注视跟踪
12名受试者,其中4名戴眼镜,在不同的照明条件下参与。受试者被要求看屏幕上的不同位置。记录估计的注视点。我们计算了相对于目标点位置的角度。图15显示了受试者的平均准确度。由于眼睛、头部运动和坐姿的不同特征,注视的准确性也不同。
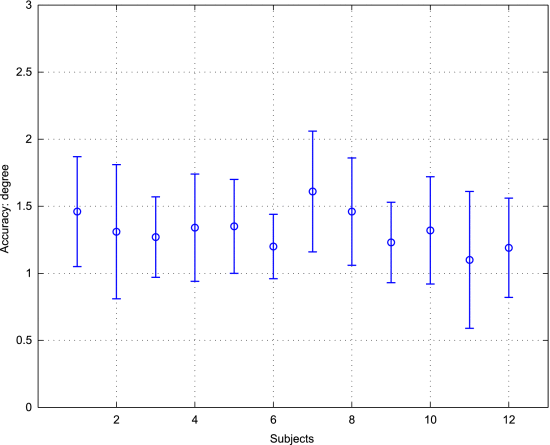
图15. 受试者无头部运动时的平均准确度和标准偏差。
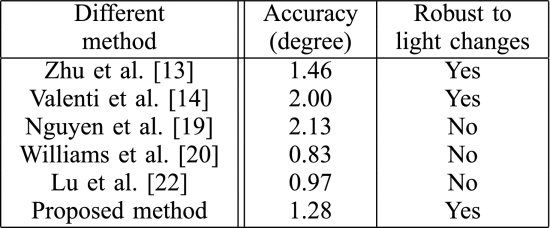
我们将所提出的方法与Williams等人进行了比较。[20] ,Lu等人。[22],Valenti等人。[14] 表III中的Zhu和Yang[13],以及Nguyen[19]。正如Williams等人。[20] 和Lu等人。[22]是基于外观的方法,他们以及Zhu和Yang[13]和Nguyen[19]可以在头部固定的情况下估计注视。所提出的方法对光照条件具有鲁棒性,并且能够检测眼睛特征(见图16)。建议的跟踪系统的精度约为1.28∘, 其表现优于Valenti等人。[14] ,Zhu和Yang[13]和Nguyen[19],但Williams等人没有。[20] 和Lu等人。[22]. 然而,所提出的模型对光照变化具有鲁棒性,而Williams等人。[20] 和Lu等人。[22]不是。此外,所提出的模型不需要用于凝视估计的训练样本。相比之下,Williams等人的模型。[20] 和Lu等人。[22]分别需要91个和9个训练样本。
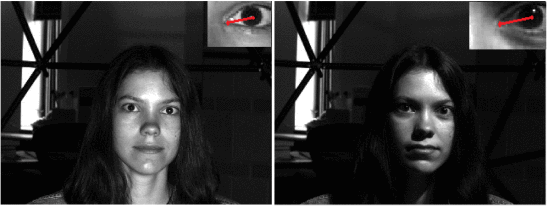
图16. 当光线变化很大时,可以检测到眼睛特征(位于图像的右上角)。图像源为[25]。
表III.不同方法在不移动头部的情况下的性能
屏幕上的注视点如图17所示。在大多数情况下,y方向上的注视误差大于x方向上的误差,因为部分虹膜被眼睑遮挡,导致y方向的精确度降低。另一个原因是眼睛在y方向上的移动范围小于x方向上的范围。因此,眼睛在y方向上的运动被认为是较难检测的微小运动。
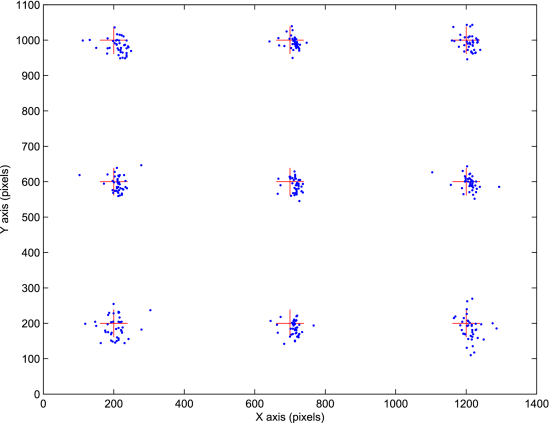
图17. 没有头部移动的注视点标记为圆点,而目标点标记为十字。x轴和y轴对应于屏幕坐标。
2) 头部移动的注视跟踪
在这个实验中,受试者被允许在注视屏幕上的点的同时移动头部。图18显示了受试者的平均准确度。头部移动时的误差比磁头固定时的误差大得多。增加的误差在很大程度上是由头部姿态估计和检测非正面人脸上的眼睛特征的难度增加引起的。为了避免较大的凝视误差,根据经验,头部运动被限制在大约±15.5∘的范围内、±15.5∘、 和±5∘ 围绕x、y和z轴的旋转偏差;x平移、y平移和z平移分别为±12、±12和±10mm。如果旋转和平移超出了限制范围,凝视误差可能会导致数百像素的偏差。从实际角度来看,头部移动的范围足以让受试者覆盖他们在屏幕上的注视点。
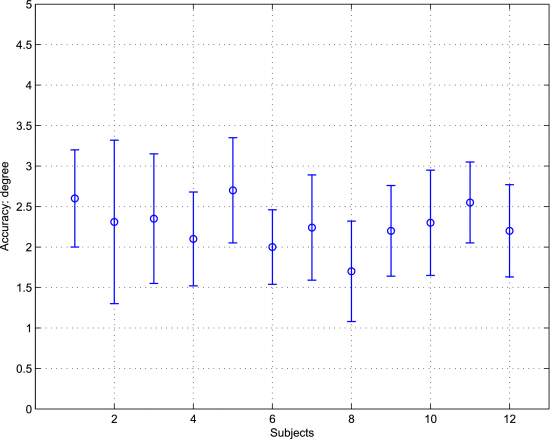
图18. 受试者头部运动的平均准确度和标准偏差。
表IV显示了与Torricelli等人相比,所提出的头部移动方法的性能。[15] ,Valenti等人。[14] ,Sugano等人。[17] ,和Lu等人。[18]. 很难利用相同的数据集来评估不同方法的性能。尽管如此,我们明确显示了我们在每种方法中使用的头部运动范围,并在相似的实验条件下进行了比较,以进行公平的比较。
表IV.不同方法的头部运动性能
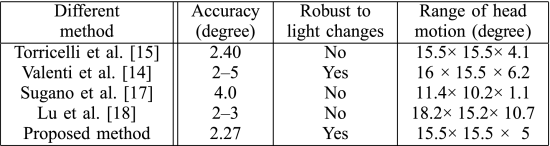
所提出的视线跟踪系统的精度约为2.27∘. Valenti等人的工作。[14] 获得的精度介于2∘ 和5∘, 其中最佳结果,即2∘ , 当受试者保持头部稳定时得到的结果,而最差的结果约为5∘ 头部运动较大。Lu等人。[18] 获得了与所提出的方法相当的结果。该方法是基于外观的,需要更多的训练样本。在本例中,它包括33个静态图像和一个5秒视频剪辑,这在使用中有些不便。即使在使用1000个训练样本后,[17]中的注视精度也不高。相比之下,所提出的凝视系统利用网络摄像机捕捉面部视频,并且在桌面环境中工作良好。尽管如此,我们提出的系统仍然存在故障案例。例如,一种情况是注视方向与头部姿势方向不一致,即我们转过头,但朝相反的方向看。另一种情况是面部表情,例如笑,这会导致面部特征位置的大偏差。在这种情况下,屏幕上的投影误差将超过100像素。然而,我们能够轻松地规避这些情况,并利用拟议的系统。
屏幕上的注视点如图19所示。y方向的精确度大于x方向的精确度。注视误差在屏幕上不均匀。相反,朝向屏幕边缘的精度略有提高。当我们观察屏幕边缘点时,眼球移动到眼窝边缘时,虹膜与眼睑重叠。结果,注视向量的检测精度将恶化。
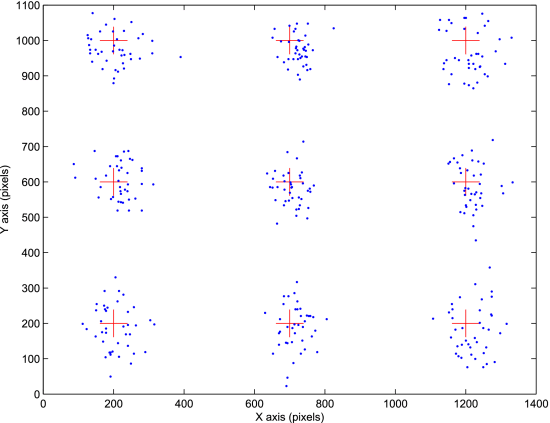
图19. 头部移动的注视点标记为圆点,而目标点标记为十字。x轴和y轴对应于屏幕坐标。
5. 结论
使用桌面环境中的网络摄像机构建了视线跟踪模型。它的主要新颖之处是使用强度能量和边缘强度来定位虹膜中心,并利用分段眼角检测器来检测眼角。此外,我们还提出了AWPOSIT算法来改进头部姿态的估计。因此,由眼睛中心、眼角和头部运动信息形成的眼睛矢量的组合可以实现视线估计的改进的准确性和鲁棒性。实验结果表明了该方法的有效性。
博主总结
不愧是IEEE的文章,数学公式就是多。第三部分算法介绍中A部分是通过人脸模型拟合人脸的算法介绍,B介绍的检测瞳孔中心位置和眼角位置的算法,C部分定义了眼睛矢量和校准过程,D部分介绍了头部姿态估计算法。第四部分分别对眼睛中心检测、头部姿势检测、凝视估计检测进行了实验评估。该篇文章的贡献在于给出了多个步骤算法的数学推导公式,给出了一种眼动预测的具体算法。
论文原地址:https://ieeexplore.ieee.org/abstract/document/7055334

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









